- 資料結構與演算法
- DSA - 首頁
- DSA - 概述
- DSA - 環境設定
- DSA - 演算法基礎
- DSA - 漸近分析
- 資料結構
- DSA - 資料結構基礎
- DSA - 資料結構和型別
- DSA - 陣列資料結構
- 連結串列
- DSA - 連結串列資料結構
- DSA - 雙向連結串列資料結構
- DSA - 迴圈連結串列資料結構
- 棧與佇列
- DSA - 棧資料結構
- DSA - 表示式解析
- DSA - 佇列資料結構
- 搜尋演算法
- DSA - 搜尋演算法
- DSA - 線性搜尋演算法
- DSA - 二分搜尋演算法
- DSA - 插值搜尋
- DSA - 跳躍搜尋演算法
- DSA - 指數搜尋
- DSA - 斐波那契搜尋
- DSA - 子列表搜尋
- DSA - 雜湊表
- 排序演算法
- DSA - 排序演算法
- DSA - 氣泡排序演算法
- DSA - 插入排序演算法
- DSA - 選擇排序演算法
- DSA - 歸併排序演算法
- DSA - 希爾排序演算法
- DSA - 堆排序
- DSA - 桶排序演算法
- DSA - 計數排序演算法
- DSA - 基數排序演算法
- DSA - 快速排序演算法
- 圖資料結構
- DSA - 圖資料結構
- DSA - 深度優先遍歷
- DSA - 廣度優先遍歷
- DSA - 生成樹
- 樹資料結構
- DSA - 樹資料結構
- DSA - 樹的遍歷
- DSA - 二叉搜尋樹
- DSA - AVL樹
- DSA - 紅黑樹
- DSA - B樹
- DSA - B+樹
- DSA - 伸展樹
- DSA - 字典樹
- DSA - 堆資料結構
- 遞迴
- DSA - 遞迴演算法
- DSA - 使用遞迴實現漢諾塔
- DSA - 使用遞迴實現斐波那契數列
- 分治法
- DSA - 分治法
- DSA - 最大最小問題
- DSA - Strassen矩陣乘法
- DSA - Karatsuba演算法
- 貪心演算法
- DSA - 貪心演算法
- DSA - 旅行商問題(貪心法)
- DSA - Prim最小生成樹
- DSA - Kruskal最小生成樹
- DSA - Dijkstra最短路徑演算法
- DSA - 地圖著色演算法
- DSA - 分數揹包問題
- DSA - 帶截止期限的作業排序
- DSA - 最優合併模式演算法
- 動態規劃
- DSA - 動態規劃
- DSA - 矩陣鏈乘法
- DSA - Floyd-Warshall演算法
- DSA - 0-1揹包問題
- DSA - 最長公共子序列演算法
- DSA - 旅行商問題(動態規劃法)
- 近似演算法
- DSA - 近似演算法
- DSA - 頂點覆蓋演算法
- DSA - 集合覆蓋問題
- DSA - 旅行商問題(近似演算法)
- 隨機化演算法
- DSA - 隨機化演算法
- DSA - 隨機化快速排序演算法
- DSA - Karger最小割演算法
- DSA - Fisher-Yates洗牌演算法
- DSA有用資源
- DSA - 問答
- DSA - 快速指南
- DSA - 有用資源
- DSA - 討論
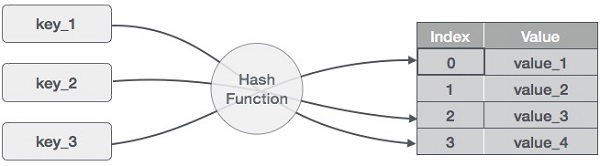
雜湊表資料結構

雜湊表是一種以關聯方式儲存資料的資料結構。在雜湊表中,資料以陣列格式儲存,每個資料值都有其唯一的索引值。如果我們知道所需資料的索引,則訪問資料變得非常快。
因此,它成為一種資料結構,其中插入和搜尋操作非常快,而不管資料的大小如何。雜湊表使用陣列作為儲存介質,並使用雜湊技術生成要插入元素或從中定位元素的索引。
雜湊
雜湊是一種將一系列鍵值轉換為陣列索引範圍的技術。我們將使用取模運算子來獲取一系列鍵值。考慮一個大小為 20 的雜湊表的例子,並且要儲存以下專案。專案採用 (鍵,值) 格式。
- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| 序號 | 鍵 | 雜湊值 | 陣列索引 |
|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 |
| 4 | 4 | 4 % 20 = 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 |
線性探測
正如我們所看到的,雜湊技術可能會建立陣列中已使用的索引。在這種情況下,我們可以透過查詢下一個單元格直到找到空單元格來搜尋陣列中的下一個空位置。這種技術稱為線性探測。
| 序號 | 鍵 | 雜湊值 | 陣列索引 | 線性探測後,陣列索引 |
|---|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 | 3 |
| 4 | 4 | 4 % 20 = 4 | 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 | 18 |
基本操作
以下是雜湊表的基本主要操作。
搜尋 - 在雜湊表中搜索元素。
插入 - 在雜湊表中插入元素。
刪除 - 從雜湊表中刪除元素。
資料項
定義一個包含一些資料和鍵的資料項,根據該鍵在雜湊表中進行搜尋。
struct DataItem {
int data;
int key;
};
雜湊方法
定義一個雜湊方法來計算資料項鍵的雜湊碼。
int hashCode(int key){
return key % SIZE;
}
搜尋操作
每當要搜尋元素時,計算傳遞的鍵的雜湊碼,並使用該雜湊碼作為陣列中的索引來定位元素。如果在計算的雜湊碼處找不到元素,則使用線性探測來獲取前面的元素。
struct DataItem *search(int key) {
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL) {
if(hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
示例
以下是各種程式語言中此操作的實現:
#include <stdio.h>
#define SIZE 10 // Define the size of the hash table
struct DataItem {
int key;
};
struct DataItem *hashArray[SIZE]; // Define the hash table as an array of DataItem pointers
int hashCode(int key) {
// Return a hash value based on the key
return key % SIZE;
}
struct DataItem *search(int key) {
// get the hash
int hashIndex = hashCode(key);
// move in array until an empty slot is found or the key is found
while (hashArray[hashIndex] != NULL) {
// If the key is found, return the corresponding DataItem pointer
if (hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
// go to the next cell
++hashIndex;
// wrap around the table
hashIndex %= SIZE;
}
// If the key is not found, return NULL
return NULL;
}
int main() {
// Initializing the hash table with some sample DataItems
struct DataItem item2 = {25}; // Assuming the key is 25
struct DataItem item3 = {64}; // Assuming the key is 64
struct DataItem item4 = {22}; // Assuming the key is 22
// Calculate the hash index for each item and place them in the hash table
int hashIndex2 = hashCode(item2.key);
hashArray[hashIndex2] = &item2;
int hashIndex3 = hashCode(item3.key);
hashArray[hashIndex3] = &item3;
int hashIndex4 = hashCode(item4.key);
hashArray[hashIndex4] = &item4;
// Call the search function to test it
int keyToSearch = 64; // The key to search for in the hash table
struct DataItem *result = search(keyToSearch);
printf("The element to be searched: %d", keyToSearch);
if (result != NULL) {
printf("\nElement found");
} else {
printf("\nElement not found");
}
return 0;
}
輸出
The element to be searched: 64 Element found
#include <iostream>
#include <unordered_map>
using namespace std;
#define SIZE 10 // Define the size of the hash table
struct DataItem {
int key;
};
unordered_map<int, DataItem*> hashMap; // Define the hash table as an unordered_map
int hashCode(int key) {
// Return a hash value based on the key
return key % SIZE;
}
DataItem* search(int key) {
// get the hash
int hashIndex = hashCode(key);
// move in the map until an empty slot is found or the key is found
while (hashMap[hashIndex] != nullptr) {
// If the key is found, return the corresponding DataItem pointer
if (hashMap[hashIndex]->key == key)
return hashMap[hashIndex];
// go to the next cell
++hashIndex;
// wrap around the table
hashIndex %= SIZE;
}
// If the key is not found, return nullptr
return nullptr;
}
int main() {
// Initializing the hash table with some sample DataItems
DataItem item2 = {25}; // Assuming the key is 25
DataItem item3 = {64}; // Assuming the key is 64
DataItem item4 = {22}; // Assuming the key is 22
// Calculate the hash index for each item and place them in the hash table
int hashIndex2 = hashCode(item2.key);
hashMap[hashIndex2] = &item2;
int hashIndex3 = hashCode(item3.key);
hashMap[hashIndex3] = &item3;
int hashIndex4 = hashCode(item4.key);
hashMap[hashIndex4] = &item4;
// Call the search function to test it
int keyToSearch = 64; // The key to search for in the hash table
DataItem* result = search(keyToSearch);
cout<<"The element to be searched: "<<keyToSearch;
if (result != nullptr) {
cout << "\nElement found";
} else {
cout << "\nElement not found";
}
return 0;
}
輸出
The element to be searched: 64 Element found
import java.util.HashMap;
public class Main {
static final int SIZE = 10; // Define the size of the hash table
static class DataItem {
int key;
}
static HashMap<Integer, DataItem> hashMap = new HashMap<>(); // Define the hash table as a HashMap
static int hashCode(int key) {
// Return a hash value based on the key
return key % SIZE;
}
static DataItem search(int key) {
// get the hash
int hashIndex = hashCode(key);
// move in map until an empty slot is found or the key is found
while (hashMap.get(hashIndex) != null) {
// If the key is found, return the corresponding DataItem
if (hashMap.get(hashIndex).key == key)
return hashMap.get(hashIndex);
// go to the next cell
++hashIndex;
// wrap around the table
hashIndex %= SIZE;
}
// If the key is not found, return null
return null;
}
public static void main(String[] args) {
// Initializing the hash table with some sample DataItems
DataItem item2 = new DataItem();
item2.key = 25; // Assuming the key is 25
DataItem item3 = new DataItem();
item3.key = 64; // Assuming the key is 64
DataItem item4 = new DataItem();
item4.key = 22; // Assuming the key is 22
// Calculate the hash index for each item and place them in the hash table
int hashIndex2 = hashCode(item2.key);
hashMap.put(hashIndex2, item2);
int hashIndex3 = hashCode(item3.key);
hashMap.put(hashIndex3, item3);
int hashIndex4 = hashCode(item4.key);
hashMap.put(hashIndex4, item4);
// Call the search function to test it
int keyToSearch = 64; // The key to search for in the hash table
DataItem result = search(keyToSearch);
System.out.print("The element to be searched: " + keyToSearch);
if (result != null) {
System.out.println("\nElement found");
} else {
System.out.println("\nElement not found");
}
}
}
輸出
The element to be searched: 64 Element found
SIZE = 10 # Define the size of the hash table
class DataItem:
def __init__(self, key):
self.key = key
hashMap = {} # Define the hash table as a dictionary
def hashCode(key):
# Return a hash value based on the key
return key % SIZE
def search(key):
# get the hash
hashIndex = hashCode(key)
# move in map until an empty slot is found or the key is found
while hashIndex in hashMap:
# If the key is found, return the corresponding DataItem
if hashMap[hashIndex].key == key:
return hashMap[hashIndex]
# go to the next cell
hashIndex = (hashIndex + 1) % SIZE
# If the key is not found, return None
return None
# Initializing the hash table with some sample DataItems
item2 = DataItem(25) # Assuming the key is 25
item3 = DataItem(64) # Assuming the key is 64
item4 = DataItem(22) # Assuming the key is 22
# Calculate the hash index for each item and place them in the hash table
hashIndex2 = hashCode(item2.key)
hashMap[hashIndex2] = item2
hashIndex3 = hashCode(item3.key)
hashMap[hashIndex3] = item3
hashIndex4 = hashCode(item4.key)
hashMap[hashIndex4] = item4
# Call the search function to test it
keyToSearch = 64 # The key to search for in the hash table
result = search(keyToSearch)
print("The element to be searched: ", keyToSearch)
if result:
print("Element found")
else:
print("Element not found")
輸出
The element to be searched: 64 Element found
插入操作
每當要插入元素時,計算傳遞的鍵的雜湊碼,並使用該雜湊碼作為陣列中的索引來定位索引。如果在計算的雜湊碼處找到元素,則使用線性探測來查詢空位置。
void insert(int key,int data) {
struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem));
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1) {
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
hashArray[hashIndex] = item;
}
示例
以下是各種程式語言中此操作的實現:
#include <stdio.h>
#include <stdlib.h>
#define SIZE 4 // Define the size of the hash table
struct DataItem {
int key;
};
struct DataItem *hashArray[SIZE]; // Define the hash table as an array of DataItem pointers
int hashCode(int key) {
// Return a hash value based on the key
return key % SIZE;
}
void insert(int key) {
// Create a new DataItem using malloc
struct DataItem *newItem = (struct DataItem*)malloc(sizeof(struct DataItem));
if (newItem == NULL) {
// Check if malloc fails to allocate memory
fprintf(stderr, "Memory allocation error\n");
return;
}
newItem->key = key;
// Initialize other data members if needed
// Calculate the hash index for the key
int hashIndex = hashCode(key);
// Handle collisions (linear probing)
while (hashArray[hashIndex] != NULL) {
// Move to the next cell
++hashIndex;
// Wrap around the table if needed
hashIndex %= SIZE;
}
// Insert the new DataItem at the calculated index
hashArray[hashIndex] = newItem;
}
int main() {
// Call the insert function with different keys to populate the hash table
insert(42); // Insert an item with key 42
insert(25); // Insert an item with key 25
insert(64); // Insert an item with key 64
insert(22); // Insert an item with key 22
// Output the populated hash table
for (int i = 0; i < SIZE; i++) {
if (hashArray[i] != NULL) {
printf("Index %d: Key %d\n", i, hashArray[i]->key);
} else {
printf("Index %d: Empty\n", i);
}
}
return 0;
}
輸出
Index 0: Key 64 Index 1: Key 25 Index 2: Key 42 Index 3: Key 22
#include <iostream>
#include <vector>
#define SIZE 4 // Define the size of the hash table
struct DataItem {
int key;
};
std::vector<DataItem*> hashArray(SIZE, nullptr); // Define the hash table as a vector of DataItem pointers
int hashCode(int key)
{
// Return a hash value based on the key
return key % SIZE;
}
void insert(int key)
{
// Create a new DataItem using new (dynamic memory allocation)
DataItem *newItem = new DataItem;
newItem->key = key;
// Initialize other data members if needed
// Calculate the hash index for the key
int hashIndex = hashCode(key);
// Handle collisions (linear probing)
while (hashArray[hashIndex] != nullptr) {
// Move to the next cell
++hashIndex;
// Wrap around the table if needed
hashIndex %= SIZE;
}
// Insert the new DataItem at the calculated index
hashArray[hashIndex] = newItem;
}
int main()
{
// Call the insert function with different keys to populate the hash table
insert(42); // Insert an item with key 42
insert(25); // Insert an item with key 25
insert(64); // Insert an item with key 64
insert(22); // Insert an item with key 22
// Output the populated hash table
for (int i = 0; i < SIZE; i++) {
if (hashArray[i] != nullptr) {
std::cout << "Index " << i << ": Key " << hashArray[i]->key << std::endl;
} else {
std::cout << "Index " << i << ": Empty" << std::endl;
}
}
return 0;
}
輸出
Index 0: Key 64 Index 1: Key 25 Index 2: Key 42 Index 3: Key 22
import java.util.Arrays;
public class Main {
static final int SIZE = 4; // Define the size of the hash table
static class DataItem {
int key;
}
static DataItem[] hashArray = new DataItem[SIZE]; // Define the hash table as an array of DataItem pointers
static int hashCode(int key) {
// Return a hash value based on the key
return key % SIZE;
}
static void insert(int key) {
// Create a new DataItem
DataItem newItem = new DataItem();
newItem.key = key;
// Initialize other data members if needed
// Calculate the hash index for the key
int hashIndex = hashCode(key);
// Handle collisions (linear probing)
while (hashArray[hashIndex] != null) {
// Move to the next cell
hashIndex++;
// Wrap around the table if needed
hashIndex %= SIZE;
}
// Insert the new DataItem at the calculated index
hashArray[hashIndex] = newItem;
}
public static void main(String[] args) {
// Call the insert function with different keys to populate the hash table
insert(42); // Insert an item with key 42
insert(25); // Insert an item with key 25
insert(64); // Insert an item with key 64
insert(22); // Insert an item with key 22
// Output the populated hash table
for (int i = 0; i < SIZE; i++) {
if (hashArray[i] != null) {
System.out.println("Index " + i + ": Key " + hashArray[i].key);
} else {
System.out.println("Index " + i + ": Empty");
}
}
}
}
輸出
Index 0: Key 64 Index 1: Key 25 Index 2: Key 42 Index 3: Key 22
SIZE = 4 # Define the size of the hash table
class DataItem:
def __init__(self, key):
self.key = key
hashArray = [None] * SIZE # Define the hash table as a list of DataItem pointers
def hashCode(key):
# Return a hash value based on the key
return key % SIZE
def insert(key):
# Create a new DataItem
newItem = DataItem(key)
# Initialize other data members if needed
# Calculate the hash index for the key
hashIndex = hashCode(key)
# Handle collisions (linear probing)
while hashArray[hashIndex] is not None:
# Move to the next cell
hashIndex += 1
# Wrap around the table if needed
hashIndex %= SIZE
# Insert the new DataItem at the calculated index
hashArray[hashIndex] = newItem
# Call the insert function with different keys to populate the hash table
insert(42) # Insert an item with key 42
insert(25) # Insert an item with key 25
insert(64) # Insert an item with key 64
insert(22) # Insert an item with key 22
# Output the populated hash table
for i in range(SIZE):
if hashArray[i] is not None:
print(f"Index {i}: Key {hashArray[i].key}")
else:
print(f"Index {i}: Empty")
輸出
Index 0: Key 64 Index 1: Key 25 Index 2: Key 42 Index 3: Key 22
刪除操作
每當要刪除元素時,計算傳遞的鍵的雜湊碼,並使用該雜湊碼作為陣列中的索引來定位索引。如果在計算的雜湊碼處找不到元素,則使用線性探測來獲取前面的元素。找到後,在那裡儲存一個虛擬項以保持雜湊表的效能完整。
struct DataItem* delete(struct DataItem* item) {
int key = item->key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] !=NULL) {
if(hashArray[hashIndex]->key == key) {
struct DataItem* temp = hashArray[hashIndex];
//assign a dummy item at deleted position
hashArray[hashIndex] = dummyItem;
return temp;
}
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
示例
以下是各種程式語言中雜湊表刪除操作的實現:
#include <stdio.h>
#include <stdlib.h>
#define SIZE 5 // Define the size of the hash table
struct DataItem {
int key;
};
struct DataItem *hashArray[SIZE]; // Define the hash table as an array of DataItem pointers
int hashCode(int key) {
// Implement your hash function here
// Return a hash value based on the key
}
void insert(int key) {
// Create a new DataItem using malloc
struct DataItem *newItem = (struct DataItem*)malloc(sizeof(struct DataItem));
if (newItem == NULL) {
// Check if malloc fails to allocate memory
fprintf(stderr, "Memory allocation error\n");
return;
}
newItem->key = key;
// Initialize other data members if needed
// Calculate the hash index for the key
int hashIndex = hashCode(key);
// Handle collisions (linear probing)
while (hashArray[hashIndex] != NULL) {
// Move to the next cell
++hashIndex;
// Wrap around the table if needed
hashIndex %= SIZE;
}
// Insert the new DataItem at the calculated index
hashArray[hashIndex] = newItem;
// Print the inserted item's key and hash index
printf("Inserted key %d at index %d\n", newItem->key, hashIndex);
}
void delete(int key) {
// Find the item in the hash table
int hashIndex = hashCode(key);
while (hashArray[hashIndex] != NULL) {
if (hashArray[hashIndex]->key == key) {
// Mark the item as deleted (optional: free memory)
free(hashArray[hashIndex]);
hashArray[hashIndex] = NULL;
return;
}
// Move to the next cell
++hashIndex;
// Wrap around the table if needed
hashIndex %= SIZE;
}
// If the key is not found, print a message
printf("Item with key %d not found.\n", key);
}
int main() {
// Call the insert function with different keys to populate the hash table
printf("Hash Table Contents before deletion:\n");
insert(1); // Insert an item with key 42
insert(2); // Insert an item with key 25
insert(3); // Insert an item with key 64
insert(4); // Insert an item with key 22
int ele1 = 2;
int ele2 = 4;
printf("The key to be deleted: %d and %d", ele1, ele2);
delete(ele1); // Delete an item with key 42
delete(ele2); // Delete an item with key 25
// Print the hash table's contents after delete operations
printf("\nHash Table Contents after deletion:\n");
for (int i = 1; i < SIZE; i++) {
if (hashArray[i] != NULL) {
printf("Index %d: Key %d\n", i, hashArray[i]->key);
} else {
printf("Index %d: Empty\n", i);
}
}
return 0;
}
輸出
Hash Table Contents before deletion: Inserted key 1 at index 1 Inserted key 2 at index 2 Inserted key 3 at index 3 Inserted key 4 at index 4 The key to be deleted: 2 and 4 Hash Table Contents after deletion: Index 1: Key 1 Index 2: Empty Index 3: Key 3 Index 4: Empty
#include <iostream>
using namespace std;
const int SIZE = 5; // Define the size of the hash table
struct DataItem {
int key;
};
struct DataItem* hashArray[SIZE]; // Define the hash table as an array of DataItem pointers
int hashCode(int key) {
// Implement your hash function here
// Return a hash value based on the key
// A simple hash function (modulo division)
return key % SIZE;
}
void insert(int key) {
// Create a new DataItem using new
struct DataItem* newItem = new DataItem;
newItem->key = key;
// Initialize other data members if needed
// Calculate the hash index for the key
int hashIndex = hashCode(key);
// Handle collisions (linear probing)
while (hashArray[hashIndex] != nullptr) {
// Move to the next cell
++hashIndex;
// Wrap around the table if needed
hashIndex %= SIZE;
}
// Insert the new DataItem at the calculated index
hashArray[hashIndex] = newItem;
// Print the inserted item's key and hash index
cout << "Inserted key " << newItem->key << " at index " << hashIndex << endl;
}
void deleteItem(int key) {
// Find the item in the hash table
int hashIndex = hashCode(key);
while (hashArray[hashIndex] != nullptr) {
if (hashArray[hashIndex]->key == key) {
// Mark the item as deleted (optional: free memory)
delete hashArray[hashIndex];
hashArray[hashIndex] = nullptr;
return;
}
// Move to the next cell
++hashIndex;
// Wrap around the table if needed
hashIndex %= SIZE;
}
// If the key is not found, print a message
cout << "Item with key " << key << " not found." << endl;
}
int main() {
// Call the insert function with different keys to populate the hash table
cout<<"Hash Table Contents before deletion:\n";
insert(1); // Insert an item with key 42
insert(2); // Insert an item with key 25
insert(3); // Insert an item with key 64
insert(4); // Insert an item with key 22
int ele1 = 2;
int ele2 = 4;
cout<<"The key to be deleted: "<<ele1<<" and "<<ele2<<"\n";
deleteItem(2); // Delete an item with key 42
deleteItem(4); // Delete an item with key 25
cout<<"Hash Table Contents after deletion:\n";
// Print the hash table's contents after delete operations
for (int i = 1; i < SIZE; i++) {
if (hashArray[i] != nullptr) {
cout << "Index " << i << ": Key " << hashArray[i]->key << endl;
} else {
cout << "Index " << i << ": Empty" << endl;
}
}
return 0;
}
輸出
Hash Table Contents before deletion: Inserted key 1 at index 1 Inserted key 2 at index 2 Inserted key 3 at index 3 Inserted key 4 at index 4 The key to be deleted: 2 and 4 Hash Table Contents after deletion: Index 1: Key 1 Index 2: Empty Index 3: Key 3 Index 4: Empty
public class Main {
static final int SIZE = 5; // Define the size of the hash table
static class DataItem {
int key;
DataItem(int key) {
this.key = key;
}
}
static DataItem[] hashArray = new DataItem[SIZE]; // Define the hash table as an array of DataItem objects
static int hashCode(int key) {
// Implement your hash function here
// Return a hash value based on the key
return key % SIZE; // A simple hash function using modulo operator
}
static void insert(int key) {
// Calculate the hash index for the key
int hashIndex = hashCode(key);
// Handle collisions (linear probing)
while (hashArray[hashIndex] != null) {
// Move to the next cell
hashIndex = (hashIndex + 1) % SIZE;
}
// Insert the new DataItem at the calculated index
hashArray[hashIndex] = new DataItem(key);
// Print the inserted item's key and hash index
System.out.println("Inserted key " + key + " at index " + hashIndex);
}
static void delete(int key) {
// Find the item in the hash table
int hashIndex = hashCode(key);
while (hashArray[hashIndex] != null) {
if (hashArray[hashIndex].key == key) {
// Mark the item as deleted (optional: free memory)
hashArray[hashIndex] = null;
// Print the deleted item's key and hash index
return;
}
// Move to the next cell
hashIndex = (hashIndex + 1) % SIZE;
}
// If the key is not found, print a message
System.out.println("Item with key " + key + " not found.");
}
public static void main(String[] args) {
// Call the insert function with different keys to populate the hash table
System.out.println("Hash Table Contents before deletion: ");
insert(1); // Insert an item with key 1
insert(2); // Insert an item with key 2
insert(3); // Insert an item with key 3
insert(4); // Insert an item with key 4
int ele1 = 2;
int ele2 = 4;
System.out.print("The keys to be deleted: " + ele1 + " and " + ele2);
delete(ele1); // Delete an item with key 2
delete(ele2); // Delete an item with key 4
// Print the hash table's contents after delete operations
System.out.println("\nHash Table Contents after deletion:");
for (int i = 1; i < SIZE; i++) {
if (hashArray[i] != null) {
System.out.println("Index " + i + ": Key " + hashArray[i].key);
} else {
System.out.println("Index " + i + ": Empty");
}
}
}
}
輸出
Hash Table Contents before deletion: Inserted key 1 at index 1 Inserted key 2 at index 2 Inserted key 3 at index 3 Inserted key 4 at index 4 The keys to be deleted: 2 and 4 Hash Table Contents after deletion: Index 1: Key 1 Index 2: Empty Index 3: Key 3 Index 4: Empty
SIZE = 5 # Define the size of the hash table
class DataItem:
def __init__(self, key):
self.key = key
def hashCode(key):
# Implement your hash function here
# Return a hash value based on the key
return key % SIZE
def insert(key):
global hashArray # Access the global hashArray variable
# Calculate the hash index for the key
hashIndex = hashCode(key)
# Handle collisions (linear probing)
while hashArray[hashIndex] is not None:
# Move to the next cell
hashIndex = (hashIndex + 1) % SIZE
# Insert the new DataItem at the calculated index
hashArray[hashIndex] = DataItem(key)
# Print the inserted item's key and hash index
print(f"Inserted key {key} at index {hashIndex}")
def delete(key):
global hashArray # Access the global hashArray variable
# Find the item in the hash table
hashIndex = hashCode(key)
while hashArray[hashIndex] is not None:
if hashArray[hashIndex].key == key:
# Mark the item as deleted (optional: free memory)
hashArray[hashIndex] = None
return
# Move to the next cell
hashIndex = (hashIndex + 1) % SIZE
# If the key is not found, print a message
print(f"Item with key {key} not found.")
# Initialize the hash table as a list of None values
hashArray = [None] * SIZE
print("Hash Table Contents before deletion:")
# Call the insert function with different keys to populate the hash table
insert(1) # Insert an item with key 1
insert(2) # Insert an item with key 2
insert(3) # Insert an item with key 3
insert(4) # Insert an item with key 4
ele1 = 2
ele2 = 4
print("The keys to be deleted: ", ele1, " and ", ele2)
delete(2) # Delete an item with key 2
delete(4) # Delete an item with key 4
# Print the hash table's contents after delete operations
print("Hash Table Contents after deletion:")
for i in range(1, SIZE):
if hashArray[i] is not None:
print(f"Index {i}: Key {hashArray[i].key}")
else:
print(f"Index {i}: Empty")
輸出
Hash Table Contents before deletion: Inserted key 1 at index 1 Inserted key 2 at index 2 Inserted key 3 at index 3 Inserted key 4 at index 4 The keys to be deleted: 2 and 4 Hash Table Contents after deletion: Index 1: Key 1 Index 2: Empty Index 3: Key 3 Index 4: Empty
完整實現
以下是各種程式語言中上述操作的完整實現:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
#define SIZE 20
struct DataItem {
int data;
int key;
};
struct DataItem* hashArray[SIZE];
struct DataItem* dummyItem;
struct DataItem* item;
int hashCode(int key) {
return key % SIZE;
}
struct DataItem *search(int key) {
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL) {
if(hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
void insert(int key,int data) {
struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem));
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1) {
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
hashArray[hashIndex] = item;
}
struct DataItem* delete(struct DataItem* item) {
int key = item->key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL) {
if(hashArray[hashIndex]->key == key) {
struct DataItem* temp = hashArray[hashIndex];
//assign a dummy item at deleted position
hashArray[hashIndex] = dummyItem;
return temp;
}
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
void display() {
int i = 0;
for(i = 0; i<SIZE; i++) {
if(hashArray[i] != NULL)
printf("(%d,%d) ",hashArray[i]->key,hashArray[i]->data);
}
printf("\n");
}
int main() {
dummyItem = (struct DataItem*) malloc(sizeof(struct DataItem));
dummyItem->data = -1;
dummyItem->key = -1;
insert(1, 20);
insert(2, 70);
insert(42, 80);
insert(4, 25);
insert(12, 44);
insert(14, 32);
insert(17, 11);
insert(13, 78);
insert(37, 97);
printf("Insertion done: \n");
printf("Contents of Hash Table: ");
display();
int ele = 37;
printf("The element to be searched: %d", ele);
item = search(ele);
if(item != NULL) {
printf("\nElement found: %d\n", item->key);
} else {
printf("\nElement not found\n");
}
delete(item);
printf("Hash Table contents after deletion: ");
display();
}
輸出
Insertion done: Contents of Hash Table: (1,20) (2,70) (42,80) (4,25) (12,44) (13,78) (14,32) (17,11) (37,97) The element to be searched: 37 Element found: 37 Hash Table contents after deletion: (1,20) (2,70) (42,80) (4,25) (12,44) (13,78) (14,32) (17,11) (-1,-1)
#include <iostream>
#include <vector>
using namespace std;
using namespace std;
#define SIZE 20
struct DataItem {
int data;
int key;
};
std::vector<DataItem*> hashArray(SIZE, nullptr);
DataItem* dummyItem;
DataItem* item;
int hashCode(int key) {
return key % SIZE;
}
DataItem* search(int key) {
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while (hashArray[hashIndex] != nullptr) {
if (hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
//wrap around the table
hashIndex = (hashIndex + 1) % SIZE;
}
return nullptr;
}
void insert(int key, int data) {
DataItem* item = new DataItem;
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while (hashArray[hashIndex] != nullptr && hashArray[hashIndex]->key != -1) {
hashIndex = (hashIndex + 1) % SIZE;
}
hashArray[hashIndex] = item;
}
DataItem* deleteItem(DataItem* item) {
int key = item->key;
int hashIndex = hashCode(key);
while (hashArray[hashIndex] != nullptr) {
if (hashArray[hashIndex]->key == key) {
DataItem* temp = hashArray[hashIndex];
hashArray[hashIndex] = dummyItem;
return temp;
}
hashIndex = (hashIndex + 1) % SIZE;
}
return nullptr;
}
void display() {
for (int i = 0; i < SIZE; i++) {
if (hashArray[i] != nullptr)
cout << " (" << hashArray[i]->key << "," << hashArray[i]->data << ")";
}
cout << std::endl;
}
int main() {
dummyItem = new DataItem;
dummyItem->data = -1;
dummyItem->key = -1;
insert(1, 20);
insert(2, 70);
insert(42, 80);
insert(4, 25);
insert(12, 44);
insert(14, 32);
insert(17, 11);
insert(13, 78);
insert(37, 97);
cout<<"Insertion Done";
cout<<"\nContents of Hash Table: ";
display();
int ele = 37;
cout<<"The element to be searched: "<<ele;
item = search(ele);
if (item != nullptr) {
cout << "\nElement found: " << item->key;
} else {
cout << "\nElement not found" << item->key;
}
// Clean up allocated memory
delete(item);
cout<<"\nHash Table contents after deletion: ";
display();
}
輸出
Insertion Done Contents of Hash Table: (1,20) (2,70) (42,80) (4,25) (12,44) (13,78) (14,32) (17,11) (37,97) The element to be searched: 37 Element found: 37 Hash Table contents after deletion: (1,20) (2,70) (42,80) (4,25) (12,44) (13,78) (14,32) (17,11) (5,1666768001)
public class HashTableExample {
static final int SIZE = 20;
static class DataItem {
int data;
int key;
DataItem(int data, int key) {
this.data = data;
this.key = key;
}
}
static DataItem[] hashArray = new DataItem[SIZE];
static DataItem dummyItem = new DataItem(-1, -1);
static DataItem item;
static int hashCode(int key) {
return key % SIZE;
}
static DataItem search(int key) {
int hashIndex = hashCode(key);
while (hashArray[hashIndex] != null) {
if (hashArray[hashIndex].key == key)
return hashArray[hashIndex];
hashIndex = (hashIndex + 1) % SIZE;
}
return null;
}
static void insert(int key, int data) {
DataItem item = new DataItem(data, key);
int hashIndex = hashCode(key);
while (hashArray[hashIndex] != null && hashArray[hashIndex].key != -1) {
hashIndex = (hashIndex + 1) % SIZE;
}
hashArray[hashIndex] = item;
}
static DataItem deleteItem(DataItem item) {
int key = item.key;
int hashIndex = hashCode(key);
while (hashArray[hashIndex] != null) {
if (hashArray[hashIndex].key == key) {
DataItem temp = hashArray[hashIndex];
hashArray[hashIndex] = dummyItem;
return temp;
}
hashIndex = (hashIndex + 1) % SIZE;
}
return null;
}
static void display() {
for (int i = 0; i < SIZE; i++) {
if (hashArray[i] != null)
System.out.print(" (" + hashArray[i].key + "," + hashArray[i].data + ")");
}
System.out.println();
}
public static void main(String[] args) {
insert(1, 20);
insert(2, 70);
insert(42, 80);
insert(4, 25);
insert(12, 44);
insert(14, 32);
insert(17, 11);
insert(13, 78);
insert(37, 97);
System.out.print("Insertion done");
System.out.print("\nContents of Hash Table:");
display();
int ele = 37;
System.out.print("The element to be searched: " + ele);
item = search(37);
if (item != null) {
System.out.println("\nElement found: " + item.key);
} else {
System.out.println("\nElement not found");
}
deleteItem(item);
System.out.print("Hash Table contents after deletion:");
display();
}
}
輸出
Insertion done Contents of Hash Table: (1,20) (2,70) (42,80) (4,25) (12,44) (13,78) (14,32) (17,11) (37,97) The element to be searched: 37 Element found: 37 Hash Table contents after deletion: (1,20) (2,70) (42,80) (4,25) (12,44) (13,78) (14,32) (17,11) (-1,-1)
SIZE = 20
class DataItem:
def __init__(self, data, key):
self.data = data
self.key = key
# Initialize the hash array with None values
hashArray = [None] * SIZE
# Create a dummy item to mark deleted cells in the hash table
dummyItem = DataItem(-1, -1)
# Variable to hold the item found in the search operation
item = None
# Hash function to calculate the hash index for the given key
def hashCode(key):
return key % SIZE
# Function to search for an item in the hash table by its key
def search(key):
# Calculate the hash index using the hash function
hashIndex = hashCode(key)
# Traverse the array until an empty cell is encountered
while hashArray[hashIndex] is not None:
if hashArray[hashIndex].key == key:
# Item found, return the item
return hashArray[hashIndex]
# Move to the next cell (linear probing)
hashIndex = (hashIndex + 1) % SIZE
# If the loop terminates without finding the item, it means the item is not present
return None
# Function to insert an item into the hash table
def insert(key, data):
# Create a new DataItem object
item = DataItem(data, key)
# Calculate the hash index using the hash function
hashIndex = hashCode(key)
# Handle collisions using linear probing (move to the next cell until an empty cell is found)
while hashArray[hashIndex] is not None and hashArray[hashIndex].key != -1:
hashIndex = (hashIndex + 1) % SIZE
# Insert the item into the hash table at the calculated index
hashArray[hashIndex] = item
# Function to delete an item from the hash table
def deleteItem(item):
key = item.key
# Calculate the hash index using the hash function
hashIndex = hashCode(key)
# Traverse the array until an empty or deleted cell is encountered
while hashArray[hashIndex] is not None:
if hashArray[hashIndex].key == key:
# Item found, mark the cell as deleted by replacing it with the dummyItem
temp = hashArray[hashIndex]
hashArray[hashIndex] = dummyItem
return temp
# Move to the next cell (linear probing)
hashIndex = (hashIndex + 1) % SIZE
# If the loop terminates without finding the item, it means the item is not present
return None
# Function to display the hash table
def display():
for i in range(SIZE):
if hashArray[i] is not None:
# Print the key and data of the item at the current index
print(" ({}, {})".format(hashArray[i].key, hashArray[i].data), end="")
else:
# Print ~~ for an empty cell
print(" ~~ ", end="")
print()
if __name__ == "__main__":
# Test the hash table implementation
# Insert some items into the hash table
insert(1, 20)
insert(2, 70)
insert(42, 80)
insert(4, 25)
insert(12, 44)
insert(14, 32)
insert(17, 11)
insert(13, 78)
insert(37, 97)
print("Insertion done")
print("Hash Table contents: ");
# Display the hash table
display()
display()
# Search for an item with a specific key (37)
item = search(37)
# Check if the item was found or not and print the result
if item is not None:
print("Element found:", item.data)
else:
print("Element not found")
# Delete the item with key 37 from the hash table
deleteItem(item)
# Search again for the item with key 37 after deletion
item = search(37)
# Check if the item was found or not and print the result
if item is not None:
print("Element found:", item.data)
else:
print("Element not found")
輸出
~~ (1, 20) (2, 70) (42, 80) (4, 25) ~~ ~~ ~~ ~~ ~~ ~~ ~~ (12, 44) (13, 78) (14, 32) ~~ ~~ (17, 11) (37, 97) ~~ Element found: 97 Element not found
廣告