- 機器學習基礎
- ML - 首頁
- ML - 簡介
- ML - 入門
- ML - 基本概念
- ML - 生態系統
- ML - Python 庫
- ML - 應用
- ML - 生命週期
- ML - 所需技能
- ML - 實現
- ML - 挑戰與常見問題
- ML - 侷限性
- ML - 現實生活中的例子
- ML - 資料結構
- ML - 數學
- ML - 人工智慧
- ML - 神經網路
- ML - 深度學習
- ML - 獲取資料集
- ML - 分類資料
- ML - 資料載入
- ML - 資料理解
- ML - 資料準備
- ML - 模型
- ML - 監督學習
- ML - 無監督學習
- ML - 半監督學習
- ML - 強化學習
- ML - 監督學習 vs. 無監督學習
- 機器學習資料視覺化
- ML - 資料視覺化
- ML - 直方圖
- ML - 密度圖
- ML - 箱線圖
- ML - 相關矩陣圖
- ML - 散點矩陣圖
- 機器學習統計學
- ML - 統計學
- ML - 平均值、中位數、眾數
- ML - 標準差
- ML - 百分位數
- ML - 資料分佈
- ML - 偏度和峰度
- ML - 偏差和方差
- ML - 假設
- ML中的迴歸分析
- ML - 迴歸分析
- ML - 線性迴歸
- ML - 簡單線性迴歸
- ML - 多元線性迴歸
- ML - 多項式迴歸
- ML中的分類演算法
- ML - 分類演算法
- ML - 邏輯迴歸
- ML - K近鄰演算法 (KNN)
- ML - 樸素貝葉斯演算法
- ML - 決策樹演算法
- ML - 支援向量機
- ML - 隨機森林
- ML - 混淆矩陣
- ML - 隨機梯度下降
- ML中的聚類演算法
- ML - 聚類演算法
- ML - 基於中心點的聚類
- ML - K均值聚類
- ML - K中心點聚類
- ML - 均值漂移聚類
- ML - 層次聚類
- ML - 基於密度的聚類
- ML - DBSCAN聚類
- ML - OPTICS聚類
- ML - HDBSCAN聚類
- ML - BIRCH聚類
- ML - 親和傳播
- ML - 基於分佈的聚類
- ML - 凝聚層次聚類
- ML中的降維
- ML - 降維
- ML - 特徵選擇
- ML - 特徵提取
- ML - 後向消除法
- ML - 前向特徵構建
- ML - 高相關性過濾器
- ML - 低方差過濾器
- ML - 缺失值比率
- ML - 主成分分析
- 強化學習
- ML - 強化學習演算法
- ML - 利用與探索
- ML - Q學習
- ML - REINFORCE演算法
- ML - SARSA強化學習
- ML - 演員-評論家方法
- 深度強化學習
- ML - 深度強化學習
- 量子機器學習
- ML - 量子機器學習
- ML - 使用Python的量子機器學習
- 機器學習雜項
- ML - 效能指標
- ML - 自動工作流
- ML - 提升模型效能
- ML - 梯度提升
- ML - 自舉匯聚 (Bagging)
- ML - 交叉驗證
- ML - AUC-ROC曲線
- ML - 網格搜尋
- ML - 資料縮放
- ML - 訓練和測試
- ML - 關聯規則
- ML - Apriori演算法
- ML - 高斯判別分析
- ML - 成本函式
- ML - 貝葉斯定理
- ML - 精確率和召回率
- ML - 對抗性
- ML - 堆疊
- ML - 時期
- ML - 感知器
- ML - 正則化
- ML - 過擬合
- ML - P值
- ML - 熵
- ML - MLOps
- ML - 資料洩露
- ML - 機器學習的貨幣化
- ML - 資料型別
- 機器學習 - 資源
- ML - 快速指南
- ML - 速查表
- ML - 面試問題
- ML - 有用資源
- ML - 討論
機器學習中的資料視覺化
資料視覺化是機器學習 (ML) 的一個重要方面,因為它有助於分析和傳達資料中的模式、趨勢和見解。資料視覺化涉及建立資料的圖形表示,這有助於識別可能無法從原始資料中顯而易見的模式和關係。
什麼是資料視覺化?
資料視覺化是對資料和資訊的圖形表示。藉助資料視覺化,我們可以看到資料的外觀以及資料的屬性之間存在何種關聯。它是快速檢視特徵是否對應於輸出的最快方法。
資料視覺化在機器學習中的重要性
資料視覺化在機器學習中發揮著重要作用。我們可以在機器學習中以多種方式使用它。以下是資料視覺化在機器學習中的一些用途:
- 探索資料 - 資料視覺化是探索和理解資料的必不可少的工具。視覺化可以幫助識別模式、相關性和異常值,還可以幫助檢測資料質量問題,例如缺失值和不一致性。
- 特徵選擇 - 資料視覺化可以幫助為ML模型選擇相關的特徵。透過視覺化資料及其與目標變數的關係,您可以識別與目標變數高度相關的特徵,並排除預測能力較弱的無關特徵。
- 模型評估 - 資料視覺化可用於評估ML模型的效能。ROC曲線、精確率-召回率曲線和混淆矩陣等視覺化技術可以幫助理解模型的準確率、精確率、召回率和F1分數。
- 傳達見解 - 資料視覺化是向可能沒有技術背景的利益相關者傳達見解和結果的有效方法。散點圖、折線圖和條形圖等視覺化可以幫助以易於理解的格式傳達複雜資訊。
用於資料視覺化的流行Python庫
以下是機器學習中用於資料視覺化最流行的Python庫。這些庫提供了廣泛的視覺化技術和自定義選項,以滿足不同的需求和偏好。
1. Matplotlib
Matplotlib是用於資料視覺化最流行的Python包之一。它是一個跨平臺庫,用於根據陣列中的資料繪製二維圖。它提供了一個面向物件的API,有助於使用Python GUI工具包(如PyQt、WxPython或Tkinter)將繪圖嵌入應用程式中。它也可用於Python和IPython shell、Jupyter Notebook以及Web應用程式伺服器。
2. Seaborn
Seaborn是一個開源的、基於BSD許可的Python庫,它提供用於使用Python程式語言視覺化資料的高階API。
3. Plotly
Plotly是一家位於蒙特利爾的科技計算公司,參與開發資料分析和視覺化工具,如Dash和Chart Studio。它還為Python、R、MATLAB、Javascript和其他計算機程式語言開發了開源圖形應用程式程式設計介面 (API) 庫。
4. Bokeh
Bokeh是Python的一個數據視覺化庫。與Matplotlib和Seaborn不同,它們也是Python資料視覺化包,Bokeh使用HTML和JavaScript呈現其繪圖。因此,它被證明對開發基於Web的儀表板非常有用。
資料視覺化的型別
機器學習資料的資料視覺化可以分為以下兩類:
- 單變數圖
- 多變數圖
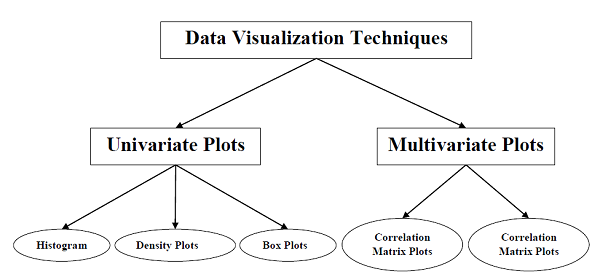
讓我們詳細瞭解上述兩種型別的資料視覺化圖。
單變數圖:獨立理解屬性
最簡單型別的視覺化是單變數或“單變數”視覺化。藉助單變數視覺化,我們可以獨立地理解資料集的每個屬性。以下是使用Python實現單變數視覺化的一些技術:
我們將在各自的章節中詳細學習上述技術。讓我們簡要了解一下這些技術。
直方圖
直方圖將資料分組到箱中,並且是快速瞭解資料集中每個屬性分佈的最快方法。以下是直方圖的一些特徵:
- 它為我們提供了為視覺化建立的每個箱中觀察值的計數。
- 從箱的形狀,我們可以很容易地觀察到分佈,即它是高斯分佈、偏態分佈還是指數分佈。
- 直方圖還有助於我們看到可能的異常值。
示例
以下程式碼是建立直方圖的Python指令碼示例。在這裡,我們將使用NumPy陣列上的hist()函式生成直方圖,並使用matplotlib進行繪圖。
import matplotlib.pyplot as plt
import numpy as np
# Generate some random data
data = np.random.randn(1000)
# Create the histogram
plt.hist(data, bins=30, color='skyblue', edgecolor='black')
plt.xlabel('Values')
plt.ylabel('Frequency')
plt.title('Histogram Example')
plt.show()
輸出

由於隨機數生成,當您執行上述程式時,您可能會注意到輸出之間存在細微差異。
密度圖
密度圖是另一種快速簡便的技術,用於獲取每個屬性的分佈。它也類似於直方圖,但在每個箱子的頂部繪製一條平滑的曲線。我們可以將其稱為抽象的直方圖。
示例
在下面的示例中,Python指令碼將為鳶尾花資料集的屬性分佈生成密度圖。
import seaborn as sns
import matplotlib.pyplot as plt
# Load a sample dataset
df = sns.load_dataset("iris")
# Create the density plot
sns.kdeplot(data=df, x="sepal_length", fill=True)
# Add labels and title
plt.xlabel("Sepal Length")
plt.ylabel("Density")
plt.title("Density Plot of Sepal Length")
# Show the plot
plt.show()
輸出

從上面的輸出中,可以很容易地理解密度圖和直方圖之間的區別。
箱線圖
箱線圖,簡稱箱圖,是另一種用於檢視每個屬性分佈的有用技術。以下是此技術的特點:
- 它是單變數的,並總結了每個屬性的分佈。
- 它繪製一條代表中間值(即中位數)的線。
- 它在25%和75%處繪製一個箱體。
- 它還繪製須線,這將使我們瞭解資料的離散程度。
- 須線外的點表示異常值。異常值將是中間資料離散程度的1.5倍。
示例
在下面的示例中,Python指令碼將為鳶尾花資料集的屬性分佈生成箱線圖。
import matplotlib.pyplot as plt
# Sample data
data = [10, 15, 18, 20, 22, 25, 28, 30, 32, 35]
# Create a figure and axes
fig, ax = plt.subplots()
# Create the boxplot
ax.boxplot(data)
# Set the title
ax.set_title('Box and Whisker Plot')
# Show the plot
plt.show()
輸出

多變數圖:多個變數之間的互動
另一種視覺化型別是多變數或“多元”視覺化。藉助多元視覺化,我們可以理解資料集的多個屬性之間的互動。以下是Python中實現多元視覺化的一些技術:
相關矩陣圖
相關性是兩個變數之間變化的指示。我們可以繪製相關矩陣圖來顯示哪個變數相對於另一個變數具有高或低相關性。
示例
在下面的示例中,Python指令碼將生成一個相關矩陣圖。它可以藉助Pandas DataFrame上的corr()函式生成,並藉助Matplotlib pyplot進行繪製。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Sample data
data = {'A': [1, 2, 3, 4, 5],
'B': [5, 4, 3, 2, 1],
'C': [2, 3, 1, 4, 5]}
df = pd.DataFrame(data)
# Calculate the correlation matrix
c_matrix = df.corr()
# Create a heatmap
sns.heatmap(c_matrix, annot=True, cmap='coolwarm')
plt.title("Correlation Matrix")
plt.show()
輸出

從上面相關矩陣的輸出中,我們可以看到它是對稱的,即左下角與右上角相同。
散點矩陣圖
散點矩陣圖使用二維空間中的點來顯示一個變數受另一個變數影響的程度或它們之間的關係。從概念上講,散點圖非常類似於線形圖,它們都使用水平和垂直軸來繪製資料點。
示例
在下面的示例中,Python指令碼將為鳶尾花資料集生成並繪製散點矩陣。它可以藉助Pandas DataFrame上的scatter_matrix()函式生成,並藉助pyplot進行繪製。
import pandas as pd import matplotlib.pyplot as plt from sklearn import datasets # Load the iris dataset iris = datasets.load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) # Create the scatter matrix plot pd.plotting.scatter_matrix(df, diagonal='hist', figsize=(8, 7)) plt.show()
輸出

在接下來的幾章中,我們將瞭解機器學習中一些流行且廣泛使用的視覺化技術。