- 機器學習基礎
- ML - 首頁
- ML - 簡介
- ML - 入門
- ML - 基本概念
- ML - 生態系統
- ML - Python 庫
- ML - 應用
- ML - 生命週期
- ML - 技能要求
- ML - 實現
- ML - 挑戰與常見問題
- ML - 限制
- ML - 現實生活中的例子
- ML - 資料結構
- ML - 數學
- ML - 人工智慧
- ML - 神經網路
- ML - 深度學習
- ML - 獲取資料集
- ML - 分類資料
- ML - 資料載入
- ML - 資料理解
- ML - 資料準備
- ML - 模型
- ML - 監督學習
- ML - 無監督學習
- ML - 半監督學習
- ML - 強化學習
- ML - 監督學習與無監督學習
- 機器學習資料視覺化
- ML - 資料視覺化
- ML - 直方圖
- ML - 密度圖
- ML - 箱線圖
- ML - 相關矩陣圖
- ML - 散點矩陣圖
- 機器學習統計學
- ML - 統計學
- ML - 平均數、中位數、眾數
- ML - 標準差
- ML - 百分位數
- ML - 資料分佈
- ML - 偏度和峰度
- ML - 偏差和方差
- ML - 假設
- ML 中的迴歸分析
- ML - 迴歸分析
- ML - 線性迴歸
- ML - 簡單線性迴歸
- ML - 多元線性迴歸
- ML - 多項式迴歸
- ML 中的分類演算法
- ML - 分類演算法
- ML - 邏輯迴歸
- ML - K 近鄰演算法 (KNN)
- ML - 樸素貝葉斯演算法
- ML - 決策樹演算法
- ML - 支援向量機
- ML - 隨機森林
- ML - 混淆矩陣
- ML - 隨機梯度下降
- ML 中的聚類演算法
- ML - 聚類演算法
- ML - 基於中心點的聚類
- ML - K 均值聚類
- ML - K 中值聚類
- ML - 均值漂移聚類
- ML - 層次聚類
- ML - 基於密度的聚類
- ML - DBSCAN 聚類
- ML - OPTICS 聚類
- ML - HDBSCAN 聚類
- ML - BIRCH 聚類
- ML - 親和傳播
- ML - 基於分佈的聚類
- ML - 凝聚層次聚類
- ML 中的降維
- ML - 降維
- ML - 特徵選擇
- ML - 特徵提取
- ML - 後向消除法
- ML - 前向特徵構造
- ML - 高相關性過濾器
- ML - 低方差過濾器
- ML - 缺失值比率
- ML - 主成分分析
- 強化學習
- ML - 強化學習演算法
- ML - 利用與探索
- ML - Q 學習
- ML - REINFORCE 演算法
- ML - SARSA 強化學習
- ML - 演員-評論家方法
- 深度強化學習
- ML - 深度強化學習
- 量子機器學習
- ML - 量子機器學習
- ML - 使用 Python 的量子機器學習
- 機器學習雜項
- ML - 效能指標
- ML - 自動工作流
- ML - 提升模型效能
- ML - 梯度提升
- ML - 自舉匯聚 (Bagging)
- ML - 交叉驗證
- ML - AUC-ROC 曲線
- ML - 網格搜尋
- ML - 資料縮放
- ML - 訓練和測試
- ML - 關聯規則
- ML - Apriori 演算法
- ML - 高斯判別分析
- ML - 成本函式
- ML - 貝葉斯定理
- ML - 精確率和召回率
- ML - 對抗性
- ML - 堆疊
- ML - 時期
- ML - 感知器
- ML - 正則化
- ML - 過擬合
- ML - P 值
- ML - 熵
- ML - MLOps
- ML - 資料洩露
- ML - 機器學習的貨幣化
- ML - 資料型別
- 機器學習 - 資源
- ML - 快速指南
- ML - 速查表
- ML - 面試問題
- ML - 有用資源
- ML - 討論
機器學習 - 相關矩陣圖
相關矩陣圖是資料集變數之間成對相關性的圖形表示。該圖由散點圖和相關係數矩陣組成,其中每個散點圖表示兩個變數之間的關係,相關係數表示關係的強度。矩陣的對角線通常顯示每個變數的分佈。
相關係數是衡量兩個變數之間線性關係的指標,其範圍從 -1 到 1。係數為 1 表示完全正相關,其中一個變數的增加與另一個變數的增加相關聯。係數為 -1 表示完全負相關,其中一個變數的增加與另一個變數的減少相關聯。係數為 0 表示變數之間沒有相關性。
相關矩陣圖的 Python 實現
現在我們已經對相關矩陣圖有了基本的瞭解,讓我們在 Python 中實現它們。在我們的示例中,我們將使用 Sklearn 中的 Iris 花資料集,其中包含 150 朵鳶尾花的花萼長度、花萼寬度、花瓣長度和花瓣寬度的測量值,這些鳶尾花屬於三個不同的物種 - 山鳶尾、變色鳶尾和維吉尼亞鳶尾。
示例
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.datasets import load_iris
iris = load_iris()
data = pd.DataFrame(iris.data, columns=iris.feature_names)
target = iris.target
plt.figure(figsize=(7.5, 3.5))
corr = data.corr()
sns.set(style='white')
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
f, ax = plt.subplots(figsize=(11, 9))
cmap = sns.diverging_palette(220, 10, as_cmap=True)
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5})
plt.show()
輸出
此程式碼將生成 Iris 資料集的相關矩陣圖,其中每個方塊代表兩個變數之間的相關係數。
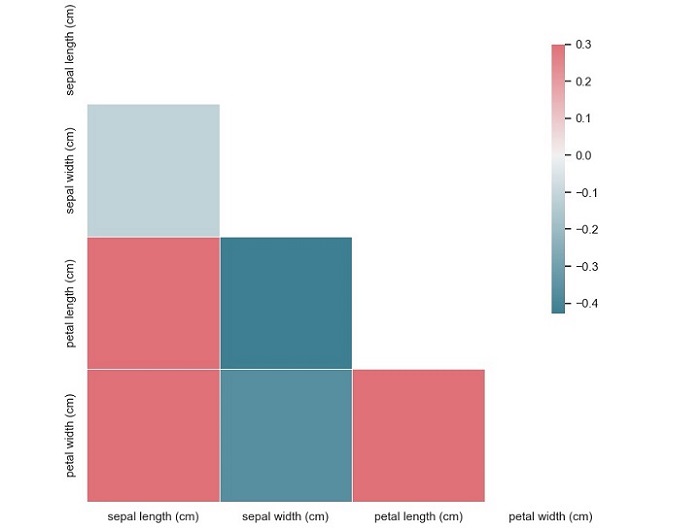
從該圖中,我們可以看到變數“花萼寬度 (cm)”和“花瓣長度 (cm)”具有中等負相關性 (-0.37),而變數“花瓣長度 (cm)”和“花瓣寬度 (cm)”具有強正相關性 (0.96)。我們還可以看到變數“花萼長度 (cm)”與變數“花瓣長度 (cm)”具有弱正相關性 (0.87)。
廣告