- 機器學習基礎
- ML - 首頁
- ML - 簡介
- ML - 入門
- ML - 基本概念
- ML - 生態系統
- ML - Python 庫
- ML - 應用
- ML - 生命週期
- ML - 所需技能
- ML - 實現
- ML - 挑戰與常見問題
- ML - 限制
- ML - 現實案例
- ML - 資料結構
- ML - 數學
- ML - 人工智慧
- ML - 神經網路
- ML - 深度學習
- ML - 獲取資料集
- ML - 分類資料
- ML - 資料載入
- ML - 資料理解
- ML - 資料準備
- ML - 模型
- ML - 監督學習
- ML - 無監督學習
- ML - 半監督學習
- ML - 強化學習
- ML - 監督學習 vs. 無監督學習
- 機器學習資料視覺化
- ML - 資料視覺化
- ML - 直方圖
- ML - 密度圖
- ML - 箱線圖
- ML - 相關矩陣圖
- ML - 散點矩陣圖
- 機器學習統計學
- ML - 統計學
- ML - 均值、中位數、眾數
- ML - 標準差
- ML - 百分位數
- ML - 資料分佈
- ML - 偏度和峰度
- ML - 偏差和方差
- ML - 假設
- ML中的迴歸分析
- ML - 迴歸分析
- ML - 線性迴歸
- ML - 簡單線性迴歸
- ML - 多元線性迴歸
- ML - 多項式迴歸
- ML中的分類演算法
- ML - 分類演算法
- ML - 邏輯迴歸
- ML - K近鄰演算法 (KNN)
- ML - 樸素貝葉斯演算法
- ML - 決策樹演算法
- ML - 支援向量機
- ML - 隨機森林
- ML - 混淆矩陣
- ML - 隨機梯度下降
- ML中的聚類演算法
- ML - 聚類演算法
- ML - 基於中心點的聚類
- ML - K均值聚類
- ML - K中心點聚類
- ML - 均值漂移聚類
- ML - 層次聚類
- ML - 基於密度的聚類
- ML - DBSCAN聚類
- ML - OPTICS聚類
- ML - HDBSCAN聚類
- ML - BIRCH聚類
- ML - 親和傳播
- ML - 基於分佈的聚類
- ML - 凝聚層次聚類
- ML中的降維
- ML - 降維
- ML - 特徵選擇
- ML - 特徵提取
- ML - 後退消除法
- ML - 前向特徵構建
- ML - 高相關性過濾器
- ML - 低方差過濾器
- ML - 缺失值比率
- ML - 主成分分析
- 強化學習
- ML - 強化學習演算法
- ML - 利用與探索
- ML - Q學習
- ML - REINFORCE演算法
- ML - SARSA強化學習
- ML - 演員-評論家方法
- 深度強化學習
- ML - 深度強化學習
- 量子機器學習
- ML - 量子機器學習
- ML - 使用Python的量子機器學習
- 機器學習雜項
- ML - 效能指標
- ML - 自動工作流
- ML - 提升模型效能
- ML - 梯度提升
- ML - 自舉匯聚 (Bagging)
- ML - 交叉驗證
- ML - AUC-ROC曲線
- ML - 網格搜尋
- ML - 資料縮放
- ML - 訓練和測試
- ML - 關聯規則
- ML - Apriori演算法
- ML - 高斯判別分析
- ML - 成本函式
- ML - 貝葉斯定理
- ML - 精確率和召回率
- ML - 對抗性
- ML - 堆疊
- ML - 輪次
- ML - 感知器
- ML - 正則化
- ML - 過擬合
- ML - P值
- ML - 熵
- ML - MLOps
- ML - 資料洩露
- ML - 機器學習的盈利化
- ML - 資料型別
- 機器學習 - 資源
- ML - 快速指南
- ML - 速查表
- ML - 面試問題
- ML - 有用資源
- ML - 討論
機器學習 - 自動工作流
介紹
為了成功地執行併產生結果,機器學習模型必須自動化一些標準工作流程。自動化這些標準工作流程的過程可以在Scikit-learn管道(Pipelines)的幫助下完成。從資料科學家的角度來看,管道是一個廣義但非常重要的概念。它基本上允許資料從其原始格式流向一些有用的資訊。可以透過以下圖表瞭解管道的運作方式:
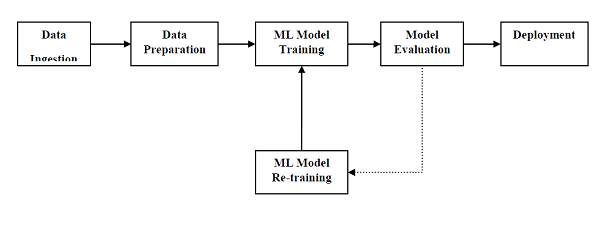
ML管道的模組如下:
資料攝取 - 顧名思義,它是匯入資料以用於ML專案的過程。可以從單個或多個系統即時或批次提取資料。這是最具挑戰性的步驟之一,因為資料的質量會影響整個ML模型。
資料準備 - 匯入資料後,我們需要準備資料以用於我們的ML模型。資料預處理是資料準備中最重要的技術之一。
ML模型訓練 - 下一步是訓練我們的ML模型。我們有各種ML演算法,如監督學習、無監督學習、強化學習,可以從資料中提取特徵並進行預測。
模型評估 - 接下來,我們需要評估ML模型。在AutoML管道的情況下,可以使用各種統計方法和業務規則來評估ML模型。
ML模型再訓練 - 在AutoML管道的情況下,第一個模型不一定是最佳模型。第一個模型被認為是基線模型,我們可以重複訓練它以提高模型的準確性。
部署 - 最後,我們需要部署模型。此步驟涉及將模型應用和遷移到業務運營中供其使用。
ML管道伴隨的挑戰
為了建立ML管道,資料科學家面臨著許多挑戰。這些挑戰分為以下三類:
資料質量
任何ML模型的成功都嚴重依賴於資料的質量。如果我們提供給ML模型的資料不準確、可靠且健壯,那麼我們將得到錯誤或誤導性的輸出。
資料可靠性
與ML管道相關的另一個挑戰是我們提供給ML模型的資料的可靠性。眾所周知,資料科學家可以從各種來源獲取資料,但為了獲得最佳結果,必須確保資料來源是可靠且可信的。
資料可訪問性
為了從ML管道中獲得最佳結果,資料本身必須是可訪問的,這需要整合、清理和整理資料。由於資料可訪問性特性,元資料將使用新標籤更新。
ML管道和資料準備建模
資料洩露,從訓練資料集到測試資料集,是資料科學家在為ML模型準備資料時需要處理的一個重要問題。通常,在資料準備時,資料科學家會在學習之前對整個資料集使用標準化或歸一化等技術。但是,這些技術無法幫助我們防止資料洩露,因為訓練資料集會受到測試資料集中資料規模的影響。
透過使用ML管道,我們可以防止這種資料洩露,因為管道確保資料準備(如標準化)僅限於交叉驗證過程的每個摺疊。
示例
以下是用Python編寫的示例,演示了資料準備和模型評估工作流。為此,我們使用Sklearn中的Pima印第安人糖尿病資料集。首先,我們將建立一個標準化資料的管道。然後建立一個線性判別分析模型,最後使用10倍交叉驗證評估管道。
首先,匯入所需的包,如下所示:
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.preprocessing import StandardScaler from sklearn.pipeline import Pipeline from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
現在,我們需要載入Pima糖尿病資料集,就像在之前的示例中所做的那樣:
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values
接下來,我們將使用以下程式碼建立一個管道:
estimators = []
estimators.append(('standardize', StandardScaler()))
estimators.append(('lda', LinearDiscriminantAnalysis()))
model = Pipeline(estimators)
最後,我們將評估此管道並輸出其準確性,如下所示:
kfold = KFold(n_splits=20, random_state=7) results = cross_val_score(model, X, Y, cv=kfold) print(results.mean())
輸出
0.7790148448043184
以上輸出是資料集上設定的準確性摘要。
ML管道和特徵提取建模
資料洩露也可能發生在ML模型的特徵提取步驟中。因此,特徵提取過程也應受到限制,以停止訓練資料集中的資料洩露。與資料準備一樣,透過使用ML管道,我們也可以防止這種資料洩露。為此,可以使用ML管道提供的工具FeatureUnion。
示例
以下是用Python編寫的示例,演示了特徵提取和模型評估工作流。為此,我們使用Sklearn中的Pima印第安人糖尿病資料集。
首先,使用PCA(主成分分析)提取3個特徵。然後,使用統計分析提取6個特徵。特徵提取後,將使用
FeatureUnion工具組合多個特徵選擇和提取過程的結果。最後,將建立一個邏輯迴歸模型,並使用10倍交叉驗證評估管道。
首先,匯入所需的包,如下所示:
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.pipeline import Pipeline from sklearn.pipeline import FeatureUnion from sklearn.linear_model import LogisticRegression from sklearn.decomposition import PCA from sklearn.feature_selection import SelectKBest
現在,我們需要載入Pima糖尿病資料集,就像在之前的示例中所做的那樣:
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values
接下來,將建立特徵聯合,如下所示:
features = []
features.append(('pca', PCA(n_components=3)))
features.append(('select_best', SelectKBest(k=6)))
feature_union = FeatureUnion(features)
接下來,將使用以下指令碼行建立管道:
estimators = []
estimators.append(('feature_union', feature_union))
estimators.append(('logistic', LogisticRegression()))
model = Pipeline(estimators)
最後,我們將評估此管道並輸出其準確性,如下所示:
kfold = KFold(n_splits=20, random_state=7) results = cross_val_score(model, X, Y, cv=kfold) print(results.mean())
輸出
0.7789811066126855
以上輸出是資料集上設定的準確性摘要。