- TensorFlow 教程
- TensorFlow - 主頁
- TensorFlow - 介紹
- TensorFlow - 安裝
- 瞭解人工智慧
- 數學基礎
- 機器學習和深度學習
- TensorFlow - 基礎知識
- 卷積神經網路
- 迴圈神經網路
- TensorBoard 視覺化
- TensorFlow - 詞嵌入
- 單層感知器
- TensorFlow - 線性迴歸
- TFLearn 及其安裝
- CNN 和 RNN 的區別
- TensorFlow - Keras
- TensorFlow - 分散式計算
- TensorFlow - 匯出
- 多層感知器學習
- 感知器的隱藏層
- TensorFlow - 最佳化器
- TensorFlow - XOR 實現
- 梯度下降最佳化
- TensorFlow - 形成圖形
- 使用 TensorFlow 進行影像識別
- 神經網路訓練建議
- TensorFlow 有用資源
- TensorFlow - 快速指南
- TensorFlow - 有用資源
- TensorFlow - 討論
TensorFlow - 感知器的隱藏層
在本章中,我們將重點關注我們必須從稱為 x 和 f(x) 的已知點集中學習的網路。單個隱藏層將構建這個簡單的網路。
用於解釋感知器隱藏層的程式碼如下所示 −
#Importing the necessary modules
import tensorflow as tf
import numpy as np
import math, random
import matplotlib.pyplot as plt
np.random.seed(1000)
function_to_learn = lambda x: np.cos(x) + 0.1*np.random.randn(*x.shape)
layer_1_neurons = 10
NUM_points = 1000
#Training the parameters
batch_size = 100
NUM_EPOCHS = 1500
all_x = np.float32(np.random.uniform(-2*math.pi, 2*math.pi, (1, NUM_points))).T
np.random.shuffle(all_x)
train_size = int(900)
#Training the first 700 points in the given set x_training = all_x[:train_size]
y_training = function_to_learn(x_training)
#Training the last 300 points in the given set x_validation = all_x[train_size:]
y_validation = function_to_learn(x_validation)
plt.figure(1)
plt.scatter(x_training, y_training, c = 'blue', label = 'train')
plt.scatter(x_validation, y_validation, c = 'pink', label = 'validation')
plt.legend()
plt.show()
X = tf.placeholder(tf.float32, [None, 1], name = "X")
Y = tf.placeholder(tf.float32, [None, 1], name = "Y")
#first layer
#Number of neurons = 10
w_h = tf.Variable(
tf.random_uniform([1, layer_1_neurons],\ minval = -1, maxval = 1, dtype = tf.float32))
b_h = tf.Variable(tf.zeros([1, layer_1_neurons], dtype = tf.float32))
h = tf.nn.sigmoid(tf.matmul(X, w_h) + b_h)
#output layer
#Number of neurons = 10
w_o = tf.Variable(
tf.random_uniform([layer_1_neurons, 1],\ minval = -1, maxval = 1, dtype = tf.float32))
b_o = tf.Variable(tf.zeros([1, 1], dtype = tf.float32))
#build the model
model = tf.matmul(h, w_o) + b_o
#minimize the cost function (model - Y)
train_op = tf.train.AdamOptimizer().minimize(tf.nn.l2_loss(model - Y))
#Start the Learning phase
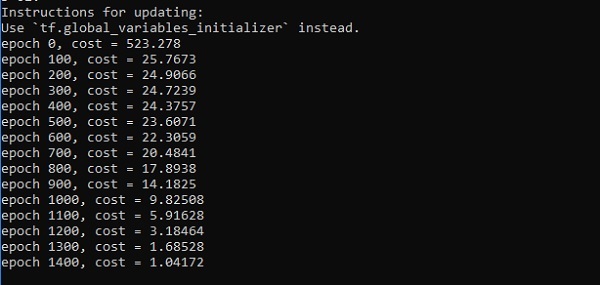
sess = tf.Session() sess.run(tf.initialize_all_variables())
errors = []
for i in range(NUM_EPOCHS):
for start, end in zip(range(0, len(x_training), batch_size),\
range(batch_size, len(x_training), batch_size)):
sess.run(train_op, feed_dict = {X: x_training[start:end],\ Y: y_training[start:end]})
cost = sess.run(tf.nn.l2_loss(model - y_validation),\ feed_dict = {X:x_validation})
errors.append(cost)
if i%100 == 0:
print("epoch %d, cost = %g" % (i, cost))
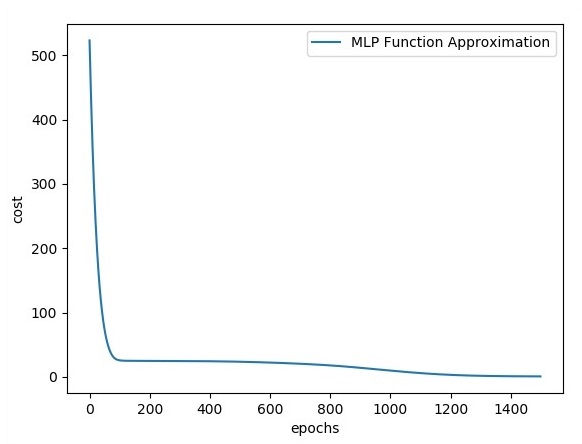
plt.plot(errors,label='MLP Function Approximation') plt.xlabel('epochs')
plt.ylabel('cost')
plt.legend()
plt.show()
輸出
以下是函式層近似的表示法 −
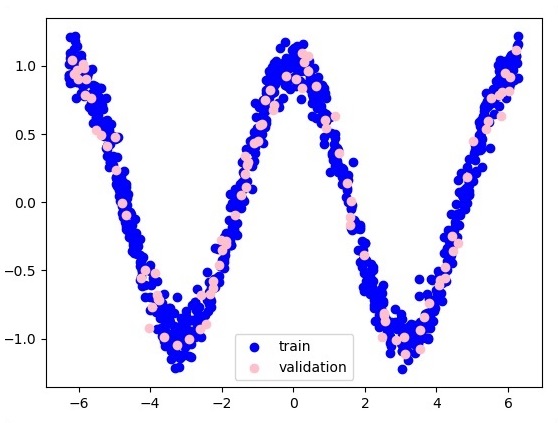
這裡有兩個資料以 W 的形式表示。兩個資料是:在圖例部分以不同的顏色顯示的訓練和驗證。
廣告