- TensorFlow教程
- TensorFlow - 主頁
- TensorFlow - 簡介
- TensorFlow - 安裝
- 理解人工智慧
- 數學基礎
- 機器學習與深度學習
- TensorFlow - 基礎
- 卷積神經網路
- 迴圈神經網路
- TensorBoard視覺化
- TensorFlow - 詞向量
- 單層感知器
- TensorFlow - 線性迴歸
- TFLearn及其安裝
- CNN和RNN的區別
- TensorFlow - Keras
- TensorFlow - 分散式計算
- TensorFlow - 匯出
- 多層感知器學習
- 感知器隱藏層
- TensorFlow - 最佳化器
- TensorFlow - XOR實施
- 梯度下降最佳化
- TensorFlow - 形成圖
- TensorFlow影像識別
- 神經網路培訓建議
- TensorFlow有用資源
- TensorFlow - 快速指南
- TensorFlow - 有用資源
- TensorFlow - 討論
TensorFlow影像識別
TensorFlow包括影像識別的特殊功能,這些影像儲存在特定資料夾中。對於相對相同的影像,將很容易實現此邏輯以用於安全目的。
影像識別程式碼實現的資料夾結構如下所示 −
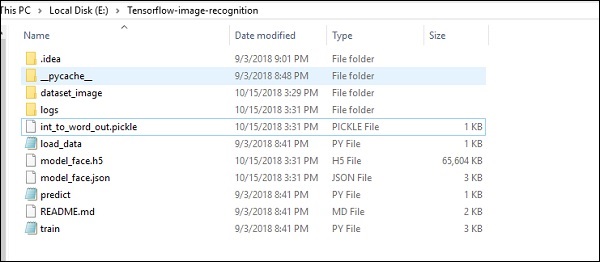
dataset_image包括需要載入的相關影像。我們將專注於其中定義了我們徽標的影像識別。使用“load_data.py”指令碼載入影像,該指令碼有助於記錄其中的各種影像識別模組。
import pickle
from sklearn.model_selection import train_test_split
from scipy import misc
import numpy as np
import os
label = os.listdir("dataset_image")
label = label[1:]
dataset = []
for image_label in label:
images = os.listdir("dataset_image/"+image_label)
for image in images:
img = misc.imread("dataset_image/"+image_label+"/"+image)
img = misc.imresize(img, (64, 64))
dataset.append((img,image_label))
X = []
Y = []
for input,image_label in dataset:
X.append(input)
Y.append(label.index(image_label))
X = np.array(X)
Y = np.array(Y)
X_train,y_train, = X,Y
data_set = (X_train,y_train)
save_label = open("int_to_word_out.pickle","wb")
pickle.dump(label, save_label)
save_label.close()
影像的訓練有助於將可識別的模式儲存在指定資料夾中。
import numpy
import matplotlib.pyplot as plt
from keras.layers import Dropout
from keras.layers import Flatten
from keras.constraints import maxnorm
from keras.optimizers import SGD
from keras.layers import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.utils import np_utils
from keras import backend as K
import load_data
from keras.models import Sequential
from keras.layers import Dense
import keras
K.set_image_dim_ordering('tf')
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load data
(X_train,y_train) = load_data.data_set
# normalize inputs from 0-255 to 0.0-1.0
X_train = X_train.astype('float32')
#X_test = X_test.astype('float32')
X_train = X_train / 255.0
#X_test = X_test / 255.0
# one hot encode outputs
y_train = np_utils.to_categorical(y_train)
#y_test = np_utils.to_categorical(y_test)
num_classes = y_train.shape[1]
# Create the model
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), padding = 'same',
activation = 'relu', kernel_constraint = maxnorm(3)))
model.add(Dropout(0.2))
model.add(Conv2D(32, (3, 3), activation = 'relu', padding = 'same',
kernel_constraint = maxnorm(3)))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Flatten())
model.add(Dense(512, activation = 'relu', kernel_constraint = maxnorm(3)))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation = 'softmax'))
# Compile model
epochs = 10
lrate = 0.01
decay = lrate/epochs
sgd = SGD(lr = lrate, momentum = 0.9, decay = decay, nesterov = False)
model.compile(loss = 'categorical_crossentropy', optimizer = sgd, metrics = ['accuracy'])
print(model.summary())
#callbacks = [keras.callbacks.EarlyStopping(
monitor = 'val_loss', min_delta = 0, patience = 0, verbose = 0, mode = 'auto')]
callbacks = [keras.callbacks.TensorBoard(log_dir='./logs',
histogram_freq = 0, batch_size = 32, write_graph = True, write_grads = False,
write_images = True, embeddings_freq = 0, embeddings_layer_names = None,
embeddings_metadata = None)]
# Fit the model
model.fit(X_train, y_train, epochs = epochs,
batch_size = 32,shuffle = True,callbacks = callbacks)
# Final evaluation of the model
scores = model.evaluate(X_train, y_train, verbose = 0)
print("Accuracy: %.2f%%" % (scores[1]*100))
# serialize model to JSONx
model_json = model.to_json()
with open("model_face.json", "w") as json_file:
json_file.write(model_json)
# serialize weights to HDF5
model.save_weights("model_face.h5")
print("Saved model to disk")
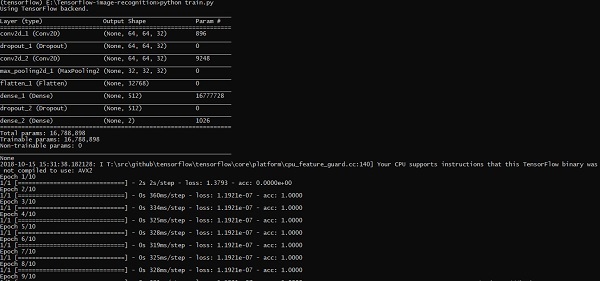
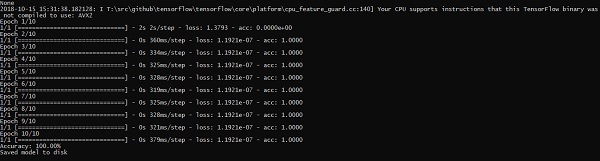
上述程式碼行生成如下所示的輸出 −
廣告