- TensorFlow 教程
- TensorFlow - 主頁
- TensorFlow - 簡介
- TensorFlow - 安裝
- 瞭解人工智慧
- 數學基礎
- 機器學習與深度學習
- TensorFlow - 基礎知識
- 卷積神經網路
- 迴圈神經網路
- TensorBoard 視覺化
- TensorFlow - 詞嵌入
- 單層感知器
- TensorFlow - 線性迴歸
- 關於 TFLearn 及其安裝
- CNN 與 RNN 之間的差異
- TensorFlow - Keras
- TensorFlow - 分散式計算
- TensorFlow - 匯出
- 多層感知器學習
- 感知器的隱藏層
- TensorFlow - 最佳化器
- TensorFlow - XOR 實現
- 梯度下降最佳化
- TensorFlow - 形成圖
- 使用 TensorFlow 進行影像識別
- 神經網路訓練建議
- TensorFlow 的有用資源
- TensorFlow - 快速指南
- TensorFlow - 有用資源
- TensorFlow - 討論
TensorFlow - 梯度下降最佳化
梯度下降最佳化被認為是資料科學中一個重要的概念。
考慮以下所示步驟來了解梯度下降最佳化 −
步驟 1
透過我們用來定義梯度下降最佳化的變數 X 和 Y 包含必要模組和宣告。
import tensorflow as tf x = tf.Variable(2, name = 'x', dtype = tf.float32) log_x = tf.log(x) log_x_squared = tf.square(log_x) optimizer = tf.train.GradientDescentOptimizer(0.5) train = optimizer.minimize(log_x_squared)
步驟 2
初始化必要變數,並呼叫最佳化器用相應函式進行定義和呼叫。
init = tf.initialize_all_variables()
def optimize():
with tf.Session() as session:
session.run(init)
print("starting at", "x:", session.run(x), "log(x)^2:", session.run(log_x_squared))
for step in range(10):
session.run(train)
print("step", step, "x:", session.run(x), "log(x)^2:", session.run(log_x_squared))
optimize()
上面這行程式碼生成的結果如以下螢幕截圖所示 −
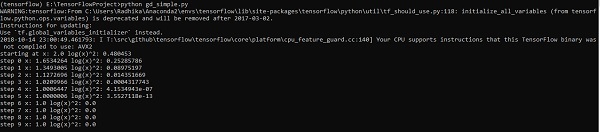
我們可以看到,必要時段和迭代次數按輸出所示計算出來。
廣告