- 生成式AI教程
- 生成式AI - 首頁
- 生成式AI基礎
- 生成式AI基礎
- 生成式AI發展歷程
- 機器學習與生成式AI
- 生成式AI模型
- 判別式模型與生成式模型
- 生成式AI模型的型別
- 機率分佈
- 機率密度函式
- 最大似然估計
- 生成式AI網路
- GAN的工作原理?
- GAN - 架構
- 條件GAN
- StyleGAN和CycleGAN
- 訓練GAN
- GAN應用
- 生成式AI Transformer
- 生成式AI中的Transformer
- 生成式AI中Transformer的架構
- Transformer中的輸入嵌入
- 多頭注意力機制
- 位置編碼
- 前饋神經網路
- Transformer中的殘差連線
- 生成式AI自編碼器
- 生成式AI中的自編碼器
- 自編碼器的型別和應用
- 使用Python實現自編碼器
- 變分自編碼器
- 生成式AI與ChatGPT
- 一個生成式AI模型
- 生成式AI雜項
- 生成式AI在製造業中的應用
- 生成式AI為開發者
- 生成式AI在網路安全中的應用
- 生成式AI在軟體測試中的應用
- 生成式AI在市場營銷中的應用
- 生成式AI在教育領域的應用
- 生成式AI在醫療保健領域的應用
- 生成式AI為學生
- 生成式AI在工業領域的應用
- 生成式AI在電影製作中的應用
- 生成式AI在音樂創作中的應用
- 生成式AI在烹飪領域的應用
- 生成式AI在媒體領域的應用
- 生成式AI在通訊領域的應用
- 生成式AI在攝影領域的應用
- 生成式AI資源
- 生成式AI - 有用資源
- 生成式AI - 討論
Transformer中的前饋神經網路
Transformer模型已經改變了自然語言處理(NLP)以及其他基於序列的任務領域。正如我們在前面的章節中討論的那樣,Transformer主要依賴於多頭注意力和自注意力機制,但還有一個關鍵元件同樣有助於該模型的成功。這個關鍵元件就是前饋神經網路 (FFNN)。
FFNN 子層幫助 Transformer 捕獲輸入資料序列中的複雜模式和關係。閱讀本章以瞭解 FFNN 子層、其在 Transformer 中的作用以及如何使用 Python 程式語言在 Transformer 架構中實現 FFNN。
前饋神經網路 (FFNN) 子層
在 Transformer 架構中,FFNN 子層位於多頭注意力子層之上。它的輸入是前一層後層歸一化的輸出 $\mathrm{d_{model} \: = \: 512}$。FFNN 是 Transformer 的一個簡單但功能強大的元件,它獨立地對序列的每個位置進行操作。
在下圖中,它是 Transformer 架構的編碼器堆疊,您可以看到 FFNN 子層的位置(用黑圈突出顯示)−
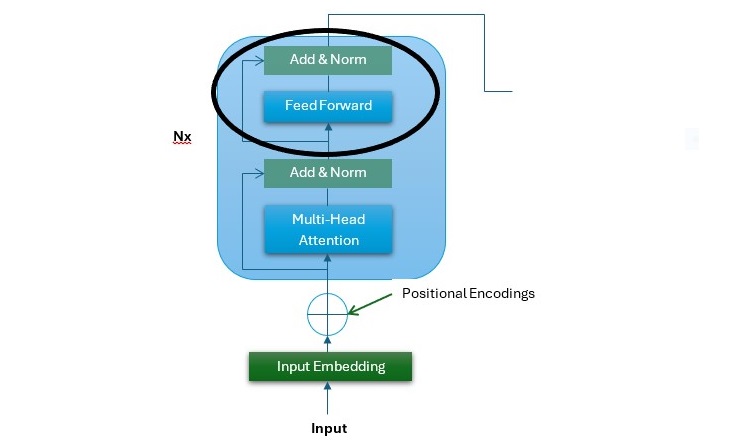
以下幾點描述了 FFNN 子層 −
- Transformer 編碼器和解碼器中的 FFNN 子層是全連線的。
- FFNN 是一個位置感知網路,其中每個位置都被單獨處理,但方式相似。
- FFNN 包含兩個線性變換,並在它們之間應用啟用函式。最常見的啟用函式之一是 ReLU。
- FFNN 子層的輸入和輸出都是 $\mathrm{d_{model} \: = \: 512}$。
- 與輸入和輸出層相比,FFNN 子層的內部層更大,為 $\mathrm{d_{ff} \: = \: 2048}$。
FFNN 子層的數學表示
FFNN 子層可以用如下數學公式表示 −
第一次線性變換
$$\mathrm{X_{1} \: = \: XW_{1} \: + \: b_{1}}$$
這裡,X 是 FFNN 子層的輸入。$\mathrm{W_{1}}$ 是第一次線性變換的權重矩陣,$\mathrm{b_{1}}$ 是偏差向量。
ReLU 啟用函式
ReLU 啟用函式透過在網路中引入非線性來使網路能夠學習複雜的模式。
$$\mathrm{X_{2} \: = \: max(0, X_{1})}$$
第二次線性變換
$$\mathrm{Output \: = \: X_{2}W_{2} \: + \: b_{2}}$$
這裡,$\mathrm{W_{2}}$ 是第二次線性變換的權重矩陣,$\mathrm{b_{2}}$ 是偏差向量。
讓我們結合以上步驟來總結 FFNN 子層 −
$$\mathrm{Output \: = \: max(0, XW_{1} \: + \: b_{1})W_{2} \: + \: b_{2}}$$
FFNN 子層在 Transformer 中的重要性
以下是 FFNN 子層在 Transformer 中的作用和重要性 −
特徵變換
FFNN 子層對輸入資料序列執行復雜的變換。藉助它,模型可以從資料序列中學習詳細和高階的特徵。
位置獨立性
正如我們在上一章中討論的那樣,自注意力機制檢查輸入資料序列中各個位置之間的關係。但是,另一方面,FFNN 子層獨立地作用於輸入資料序列中的每個位置。此功能增強了多頭注意力子層生成的表示。
前饋神經網路的 Python 實現
下面是一個分步的 Python 實現指南,演示瞭如何在 Transformer 架構中實現前饋神經網路子層 −
步驟 1:初始化 FFNN 引數
在 Transformer 架構中,FFNN 子層由兩個線性變換以及它們之間的 ReLU 啟用函式組成。在此步驟中,我們將初始化這些變換的權重矩陣和偏差向量 −
import numpy as np
class FeedForwardNN:
def __init__(self, d_model, d_ff):
# Weight and bias for the first linear transformation
self.W1 = np.random.randn(d_model, d_ff) * 0.01
self.b1 = np.zeros((1, d_ff))
# Weight and bias for the second linear transformation
self.W2 = np.random.randn(d_ff, d_model) * 0.01
self.b2 = np.zeros((1, d_model))
def forward(self, x):
# First linear transformation followed by ReLU activation
x = np.dot(x, self.W1) + self.b1
x = np.maximum(0, x) # ReLU activation
# Second linear transformation
x = np.dot(x, self.W2) + self.b2
return x
步驟 2:建立示例輸入資料
在此步驟中,我們將建立一些示例輸入資料以透過我們的 FFNN。在 Transformer 架構中,輸入通常是形狀為 (batch_size, seq_len, d_model) 的張量。
# Example input dimensions batch_size = 64 # Number of sequences in a batch seq_len = 10 # Length of each sequence d_model = 512 # Dimensionality of the model (input/output dimension) # Random input tensor with shape (batch_size, seq_len, d_model) x = np.random.rand(batch_size, seq_len, d_model)
步驟 3:例項化和使用 FFNN
最後,我們將例項化 'FeedForwardNN' 類並使用上述示例輸入張量執行前向傳遞 −
# Create FFNN instance
ffnn = FeedForwardNN(d_model, d_ff=2048) # Set d_ff as desired dimensionality for inner layer
# Perform forward pass
output = ffnn.forward(x)
# Print output shape (should be (batch_size, seq_len, d_model))
print("Output shape:", output.shape)
完整的實現示例
將上述三個步驟組合起來以獲得完整的實現示例 −
# Step 1 - Initializing Parameters for FFNN
import numpy as np
class FeedForwardNN:
def __init__(self, d_model, d_ff):
# Weight and bias for the first linear transformation
self.W1 = np.random.randn(d_model, d_ff) * 0.01
self.b1 = np.zeros((1, d_ff))
# Weight and bias for the second linear transformation
self.W2 = np.random.randn(d_ff, d_model) * 0.01
self.b2 = np.zeros((1, d_model))
def forward(self, x):
# First linear transformation followed by ReLU activation
x = np.dot(x, self.W1) + self.b1
x = np.maximum(0, x) # ReLU activation
# Second linear transformation
x = np.dot(x, self.W2) + self.b2
return x
# Step 2 - Creating Example Input Data
# Example input dimensions
batch_size = 64 # Number of sequences in a batch
seq_len = 10 # Length of each sequence
d_model = 512 # Dimensionality of the model (input/output dimension)
# Random input tensor with shape (batch_size, seq_len, d_model)
x = np.random.rand(batch_size, seq_len, d_model)
# Step 3 - Instantiating and Using the FFNN
# Create FFNN instance
# Set d_ff as desired dimensionality for inner layer
ffnn = FeedForwardNN(d_model, d_ff=2048)
# Perform forward pass
output = ffnn.forward(x)
# Print output shape (should be (batch_size, seq_len, d_model))
print("Output shape:", output.shape)
輸出
執行上述指令碼後,它應該列印輸出張量的形狀以驗證計算 −
Output shape: (64, 10, 512)
結論
前饋神經網路 (FFNN) 子層是 Transformer 架構中的一個重要組成部分。它增強了模型捕獲輸入資料序列中複雜模式和關係的能力。
FFNN 透過獨立應用逐位置變換來補充自注意力機制。這使得 Transformer 成為用於自然語言處理和其他基於序列的任務的強大模型。
在本章中,我們全面概述了 FFNN 子層、其在 Transformer 中的作用和重要性,以及逐步指導說明如何在 Transformer 中實現 FFNN 的 Python 實現。與多頭注意力機制一樣,瞭解和使用 FFNN 對於充分利用 NLP 應用中的 Transformer 模型也很重要。