- 生成式AI教程
- 生成式AI - 首頁
- 生成式AI基礎
- 生成式AI基礎
- 生成式AI發展
- 機器學習與生成式AI
- 生成式AI模型
- 判別式模型與生成式模型
- 生成式AI模型型別
- 機率分佈
- 機率密度函式
- 最大似然估計
- 生成式AI網路
- GAN的工作原理?
- GAN - 架構
- 條件GAN
- StyleGAN和CycleGAN
- 訓練GAN
- GAN應用
- 生成式AI Transformer
- 生成式AI中的Transformer
- 生成式AI中Transformer的架構
- Transformer中的輸入嵌入
- 多頭注意力機制
- 位置編碼
- 前饋神經網路
- Transformer中的殘差連線
- 生成式AI自編碼器
- 生成式AI中的自編碼器
- 自編碼器型別及應用
- 使用Python實現自編碼器
- 變分自編碼器
- 生成式AI和ChatGPT
- 一個生成式AI模型
- 生成式AI雜項
- 生成式AI在製造業中的應用
- 生成式AI為開發者賦能
- 生成式AI在網路安全中的應用
- 生成式AI在軟體測試中的應用
- 生成式AI在營銷中的應用
- 生成式AI在教育中的應用
- 生成式AI在醫療保健中的應用
- 生成式AI為學生賦能
- 生成式AI在工業中的應用
- 生成式AI在電影製作中的應用
- 生成式AI在音樂創作中的應用
- 生成式AI在烹飪中的應用
- 生成式AI在媒體中的應用
- 生成式AI在通訊中的應用
- 生成式AI在攝影中的應用
- 生成式AI資源
- 生成式AI - 有用資源
- 生成式AI - 討論
判別式模型與生成式模型
人類思維啟發了機器學習 (ML) 和深度學習 (DL) 技術,即我們如何從經驗中學習,以便在現在和將來做出更好的選擇。這些技術是研究中最具活力和不斷變化的領域,雖然我們已經在許多方面使用它們,但可能性是無限的。
這些進步使機器能夠從過去的資料中學習,甚至可以從未見過的資料輸入中進行預測。為了從原始資料中提取有意義的見解,機器依賴於數學、模型/演算法和資料處理方法。我們可以透過兩種方式提高機器效率;一種是增加資料量,另一種是開發新的、更強大的演算法。
獲取新的資料很容易,因為每天都會生成數萬億位元組的資料。但是要處理如此龐大的資料,我們需要構建新的模型/演算法或擴充套件現有模型/演算法。數學是這些模型/演算法的支柱,這些模型/演算法可以大致分為兩類,即判別式模型和生成式模型。
在本章中,我們將研究判別式和生成式機器學習模型,以及它們之間的核心區別。
什麼是判別式模型?
判別式模型是機器學習模型,顧名思義,它專注於使用機率估計和最大似然法對幾類資料的決策邊界進行建模。這些主要用於監督學習的模型也被稱為條件模型。
判別式模型受異常值的影響不大。儘管這使它們比生成式模型更好,但也導致了誤分類問題,這可能是一個很大的缺點。
從數學角度來看,訓練分類器的過程包括估計:
- 表示為f : X → Y 的函式,或
- 機率P(Y│X)。
然而,判別式分類器:
- 假設機率P(Y|X)的特定函式形式,以及
- 直接從訓練資料集中估計機率P(Y|X)的引數。
流行的判別式模型
下面討論了一些廣泛使用的判別式模型的示例:
邏輯迴歸
邏輯迴歸是一種用於二元分類任務的統計技術。它使用邏輯函式對因變數和一個或多個自變數之間的關係進行建模。它產生0到1之間的輸出。
邏輯迴歸可用於各種分類問題,如癌症檢測、糖尿病預測、垃圾郵件檢測等。
支援向量機
支援向量機 (SVM) 是一種強大而靈活的監督式機器學習演算法,可應用於迴歸和分類場景。支援向量使用決策邊界將n維資料空間劃分為多個類別。
K近鄰 (KNN)
KNN 是一種監督式機器學習演算法,它使用特徵相似性來預測新資料點的值。分配給新資料點的值取決於它們與訓練集中的點的匹配程度。
決策樹、神經網路、條件隨機場 (CRF)、隨機森林是其他一些常用的判別式模型的例子。
什麼是生成式模型?
生成式模型是機器學習模型,顧名思義,其目標是捕捉資料的潛在分佈,並生成與原始訓練資料相媲美的新資料。這些主要用於無監督學習的模型被歸類為能夠生成新的資料例項的一類統計模型。
與判別式模型相比,生成式模型唯一的缺點是它們容易受到異常值的影響。
如上所述,從數學角度來看,訓練分類器包括估計:
- 表示為f : X → Y 的函式,或
- 機率P(Y│X)。
然而,生成式分類器:
- 假設機率的特定函式形式,例如P(Y), P(X|Y)
- 直接從訓練資料集中估計機率的引數,例如P(X│Y), P(Y)。
- 使用貝葉斯定理計算後驗機率P(Y|X)。
流行的生成式模型
下面重點介紹一些廣泛使用的生成式模型的示例:
貝葉斯網路
貝葉斯網路,也稱為貝葉斯網路,是一種機率圖模型,它使用有向無環圖 (DAG) 來表示變數之間的關係。它在醫療保健、金融和自然語言處理等各個領域都有許多應用,用於決策、風險評估和預測等任務。
生成對抗網路 (GAN)
這些基於深度神經網路架構,包含兩個主要元件:生成器和判別器。生成器訓練並建立新的資料例項,而判別器將這些生成的資料評估為真實或虛假例項。
變分自編碼器 (VAE)
這些模型是一種自編碼器,經過訓練可以學習輸入資料的機率潛在表示。它透過從學習到的機率分佈中取樣來學習生成類似於輸入資料的新樣本。VAE 可用於諸如根據文字描述生成影像(如DALL-E-3所示)或創作類似人類的文字響應(如ChatGPT)之類的任務。
自迴歸模型、樸素貝葉斯、馬爾可夫隨機場、隱馬爾可夫模型 (HMM)、潛在狄利克雷分配 (LDA) 是其他一些常用的生成式模型的例子。
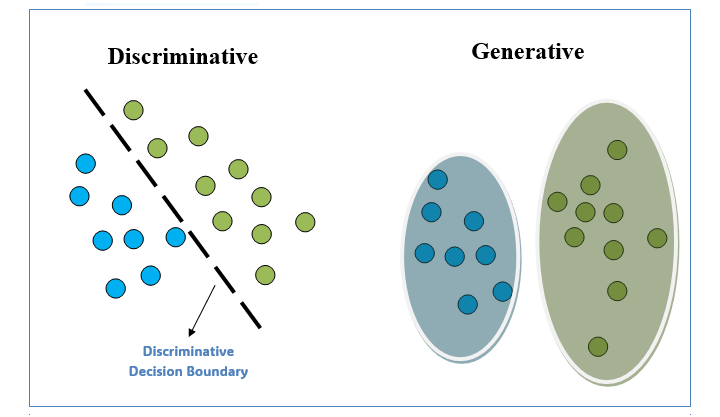
判別式模型和生成式模型的區別
資料科學家和機器學習專家需要了解這兩種模型之間的區別,才能為特定任務選擇最合適的模型。
下表描述了判別式模型和生成式模型之間的核心區別:
| 特徵 | 判別式模型 | 生成式模型 |
|---|---|---|
| 目標 | 專注於直接從資料中學習不同類別之間的邊界。它們的主要目標是根據學習到的決策邊界準確地對輸入資料進行分類。 | 旨在瞭解潛在的資料分佈並生成類似於訓練資料的新資料點。它們專注於對資料生成過程進行建模,使它們能夠建立合成數據實例。 |
| 機率分佈 | 從訓練資料集中估計機率P(Y|X)的引數。 | 使用貝葉斯定理計算後驗機率P(Y|X)。 |
| 處理異常值 | 對異常值相對穩健 | 容易受到異常值的影響 |
| 屬性 | 它們不具有生成屬性。 | 它們具有判別屬性。 |
| 應用 | 通常用於分類任務,例如影像識別和情感分析。 | 通常用於資料生成、異常檢測和資料增強等任務,超越傳統的分類任務。 |
| 示例 | 邏輯迴歸、支援向量機、決策樹、神經網路等。 | 變分自編碼器 (VAE)、生成對抗網路 (GAN)、樸素貝葉斯等。 |
結論
判別式模型建立類別之間的邊界,這使得它們成為分類任務的理想選擇。相比之下,生成式模型瞭解潛在的資料分佈並生成新的樣本,這使得它們適合於資料生成和異常檢測等任務。
我們還解釋了判別式模型和生成式模型之間的一些核心區別。這些差異使資料科學家和機器學習專家能夠為特定任務選擇最合適的方法,並提高機器學習系統的效率。