- 大資料分析教程
- 大資料分析 - 首頁
- 大資料分析 - 概述
- 大資料分析 - 特徵
- 大資料分析 - 資料生命週期
- 大資料分析 - 架構
- 大資料分析 - 方法論
- 大資料分析 - 核心交付成果
- 大資料採用與規劃注意事項
- 大資料分析 - 關鍵利益相關者
- 大資料分析 - 資料分析師
- 大資料分析 - 資料科學家
- 大資料分析有用資源
- 大資料分析 - 快速指南
- 大資料分析 - 資源
- 大資料分析 - 討論
大資料分析 - 架構
什麼是大資料架構?
大資料架構專門設計用於管理資料攝取、資料處理和分析資料量太大或過於複雜的資料。大規模資料無法由傳統的關聯資料庫進行儲存、處理和管理。解決方案是將技術組織成大資料架構的結構。大資料架構能夠管理和處理資料。
大資料架構的關鍵方面
以下是大資料架構的一些關鍵方面:
- 儲存和處理100 GB大小的大型資料。
- 聚合和轉換各種非結構化資料以進行分析和報告。
- 即時訪問、處理和分析流資料。
大資料架構圖
下圖顯示了大資料架構及其不同元件的順序排列。一個元件的結果作為另一個元件的輸入,此流程一直持續到處理資料的輸出。以下是大資料架構圖:
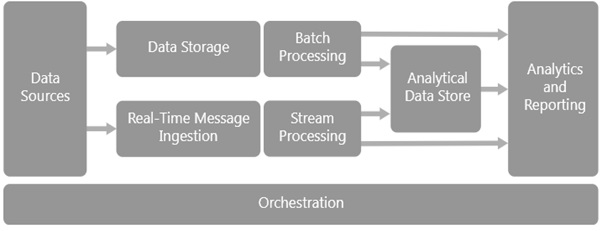
大資料架構的元件
以下是大資料架構的不同元件:
資料來源
所有大資料解決方案都始於一個或多個數據源。大資料架構可容納各種資料來源並有效地管理各種資料型別。大資料架構中的一些常見資料來源包括事務資料庫、日誌、機器生成資料、社交媒體和網路資料、流資料、外部資料來源、基於雲的資料、NOSQL資料庫、資料倉庫、檔案系統、API和Web服務。
這些只是一些例項;實際上,資料環境很廣闊並且不斷變化,隨著時間的推移,新的來源和技術不斷發展。大資料架構的主要挑戰是成功地整合、處理和分析來自各種來源的資料,以便獲得相關的見解並推動決策。
資料儲存
資料儲存是大資料架構中用於儲存和管理大量資料的系統。大資料包括處理大量結構化、半結構化和非結構化資料;由於可擴充套件性和效能限制,傳統的關聯資料庫通常被證明不足。
分散式檔案儲存通常儲存用於批處理操作的資料,這些儲存能夠以各種格式儲存大量檔案。人們通常將這種型別的儲存稱為資料湖。為此,您可以使用 Azure Data Lake Storage 或 Azure 儲存中的 Blob 容器。在大資料架構中,下圖顯示了資料儲存的關鍵方法:
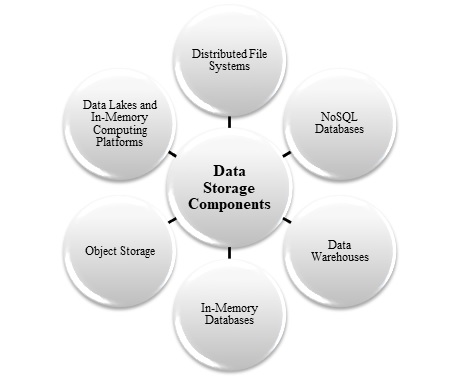
資料儲存系統的選擇取決於不同的方面,包括資料型別、效能要求、可擴充套件性和財務限制。不同的大資料架構使用這些儲存系統的混合來有效地滿足不同的用例和目標。
批處理
使用長時間執行的批處理作業處理資料以過濾、聚合和準備資料以進行分析,這些作業通常涉及讀取和處理原始檔,然後將輸出寫入新檔案。批處理是大資料架構的一個基本組成部分,它允許使用預定的批次有效地處理大量資料。它包括以預定的間隔而不是即時地批次收集、處理和分析資料。
批處理對於不需要立即響應的操作(例如資料分析、報告和基於批次的資料庫轉換)特別有用。您可以在 Azure Data Lake Analytics 中執行 U-SQL 作業,在 HDInsight Hadoop 群集中使用 Hive、Pig 或自定義 Map/Reduce 作業,或在 HDInsight Spark 群集中使用 Java、Scala 或 Python 程式。
大資料架構在即時訊息攝取中發揮著重要作用,因為它需要在資料流生成或接收時即時捕獲和處理資料流。此功能幫助企業處理高速資料來源,例如感測器饋送、日誌檔案、社交媒體更新、點選流和物聯網裝置等。
即時訊息攝取
即時訊息攝取系統對於提取重要見解、識別異常並立即響應事件至關重要。下圖顯示了在大資料架構中用於即時訊息攝取的不同方法:
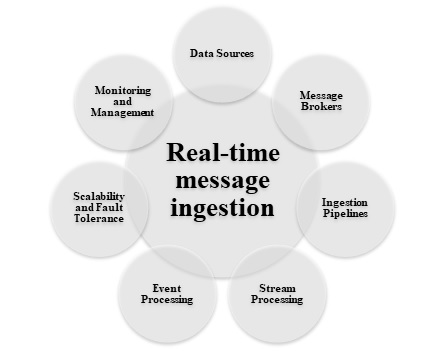
該架構包含一種用於捕獲和儲存即時訊息以進行流處理的方法;如果解決方案包含即時源。這可能是一個數據儲存系統,其中傳入的訊息被放入一個資料夾以供處理。但是,訊息攝取儲存對於不同的方法至關重要,因為它充當訊息的緩衝區,並有助於擴充套件處理、可靠交付和其他訊息佇列語義。一些有效的解決方案是 Azure 事件中心、Azure IoT 中心和 Kafka。
流處理
流處理是一種資料處理型別,它會持續處理資料記錄,這些記錄會即時生成或接收。它使企業能夠快速分析、轉換和響應資料流,從而獲得及時的見解、警報和操作。流處理是大資料架構的一個關鍵組成部分,尤其是在處理感測器資料、日誌、社交媒體更新、金融交易和物聯網裝置遙測等大量資料來源時。
下圖說明了流處理在大資料架構中的工作原理:
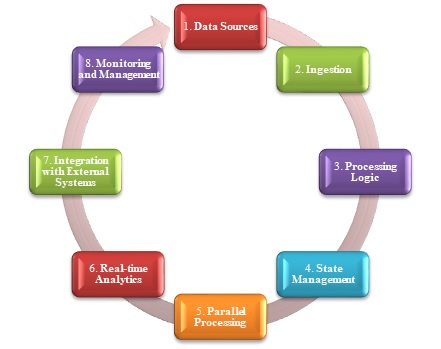
在收集即時訊息後,一個提議的解決方案透過過濾、聚合和準備資料來處理資料,以便進行分析。隨後,處理後的流資料儲存在輸出接收器中。Azure 流分析提供了一種託管的流處理服務,該服務基於在無界流上持續執行 SQL 查詢。此外,我們可以在 HDInsight 群集上使用開源 Apache 流式技術(如 Storm 和 Spark Streaming)。
分析資料儲存
在大資料分析中,分析資料儲存 (ADS) 是一個定製的資料庫或資料儲存系統,旨在處理複雜的分析查詢和海量資料。ADS 旨在促進臨時查詢、資料探索、報告和高階分析任務,使其成為大資料系統中業務智慧和分析的重要組成部分。下圖總結了大資料分析中分析資料儲存的關鍵特徵:
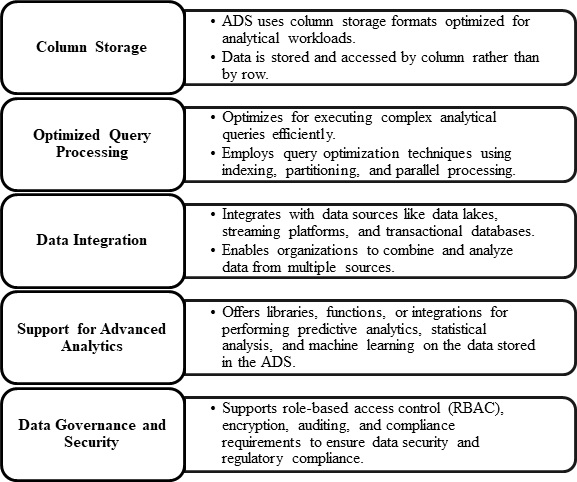
分析工具可以查詢結構化資料。低延遲 NoSQL 技術(如 HBase 或互動式 Hive 資料庫)可以透過從分散式資料儲存系統中的資料檔案中提取資訊來呈現資料。Azure Synapse Analytics 是一種用於大規模基於雲的資料倉庫的託管解決方案。您可以使用 HDInsight 中的 Hive、HBase 和 Spark SQL 來服務和分析資料。
分析和報告
大資料分析和報告是從海量和複雜資訊中提取見解、模式和趨勢的過程,以幫助決策、戰略規劃和運營改進。它包括用於分析資料和以有用和實用方式呈現結果的不同策略、工具和方法。
下圖簡要介紹了大資料分析中不同的分析和報告方法:

大多數大資料解決方案旨在透過分析和報告從資料中提取見解。為了使使用者能夠分析資料,架構可能包含一個數據建模層,例如 Azure Analysis Services 中的多維 OLAP 多維資料集或表格資料模型。它還可以透過利用 Microsoft Power BI 或 Excel 中找到的建模和視覺化功能來提供自助式商業智慧。資料科學家或分析師可能會在他們的分析和報告過程中進行互動式資料探索。
編排
在大資料分析中,編排是指協調和管理用於執行資料使用的不同任務、流程和資源。為了確保大資料分析工作流高效且可靠地執行,有必要自動化資料和處理流程的流向、安排作業、管理依賴關係並監控任務效能。
下圖包含編排中使用的不同步驟:
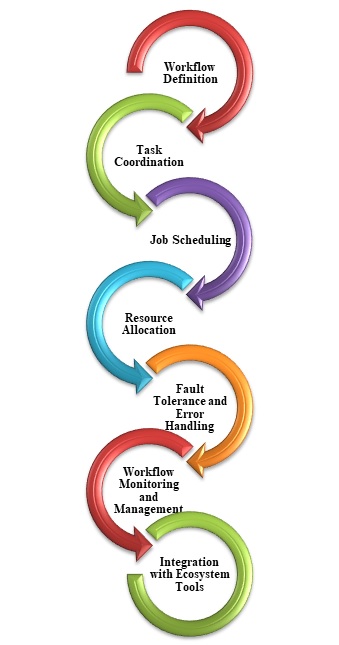
轉換源資料、跨不同源和接收器傳輸資料、將處理後的資料載入到分析資料儲存中或將結果直接輸出到報表或儀表板的工作流構成了大多數大資料解決方案。要自動化這些活動,請使用 Azure Data Factory、Apache Oozie 或 Sqoop 等編排工具。