- 大資料分析教程
- 大資料分析 - 首頁
- 大資料分析 - 概述
- 大資料分析 - 特徵
- 大資料分析 - 資料生命週期
- 大資料分析 - 架構
- 大資料分析 - 方法論
- 大資料分析 - 核心交付成果
- 大資料採用及規劃考慮
- 大資料分析 - 主要利益相關者
- 大資料分析 - 資料分析師
- 大資料分析 - 資料科學家
- 大資料分析有用資源
- 大資料分析 - 快速指南
- 大資料分析 - 資源
- 大資料分析 - 討論
大資料分析 - 資料生命週期
生命週期是一個過程,它表示大資料分析中涉及的一個或多個活動的順序流程。在學習大資料分析生命週期之前,讓我們先了解傳統的資料探勘生命週期。
傳統資料探勘生命週期
為了為組織系統地組織工作提供框架;該框架支援整個業務流程,並提供寶貴的業務洞察力,以便做出戰略決策,在競爭激烈的世界中生存,並最大限度地提高利潤。
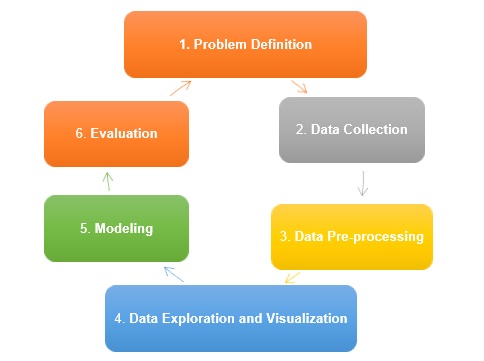
傳統資料探勘生命週期包括以下階段:
- 問題定義 - 這是資料探勘過程的初始階段;它包括需要發現或解決的問題定義。問題定義始終包括需要實現的業務目標以及需要探索的資料,以識別模式、業務趨勢和流程流程,以實現定義的目標。
- 資料收集 - 下一步是資料收集。此階段涉及從資料庫、網路日誌或社交媒體平臺等不同來源提取資料,這些資料需要進行分析和進行商業智慧。收集到的資料被認為是原始資料,因為它包含雜質,並且可能不是所需的格式和結構。
- 資料預處理 - 資料收集後,我們對其進行清理和預處理,以去除噪聲、缺失值插補、資料轉換、特徵選擇,並將資料轉換為所需的格式,然後才能開始分析。
- 資料探索和視覺化 - 完成資料的預處理後,我們對其進行探索以瞭解其特徵,並識別模式和趨勢。此階段還包括使用散點圖、直方圖或熱圖等資料視覺化方法,以圖形形式顯示資料。
- 建模 - 此階段包括建立資料模型來解決在階段 1 中定義的實際問題。這可能包括有效的機器學習演算法;訓練模型,並評估其效能。
- 評估 - 資料探勘的最後階段是評估模型的效能,並確定它是否符合步驟 1 中的業務目標。如果模型效能不佳,則可能需要再次進行資料探索或特徵選擇。
CRISP-DM方法論
CRISP-DM代表跨行業標準資料探勘流程;這是一種方法,它描述了資料探勘專家用來解決傳統BI資料探勘中問題的常用方法。它仍在傳統BI資料探勘團隊中使用。下圖對此進行了說明。它描述了CRISP-DM週期的主要階段以及它們是如何相互關聯的。
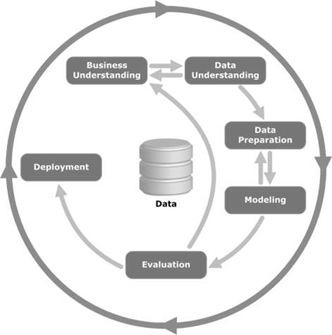
CRISP-DM於1996年推出,次年作為歐盟在ESPRIT資助計劃下的一個專案啟動。該專案由五家公司牽頭:SPSS、Teradata、戴姆勒股份公司、NCR公司和OHRA(一家保險公司)。該專案最終被納入SPSS。
CRISP-DM生命週期的階段 | CRISP-DM生命週期的步驟
- 業務理解 - 此階段包括從業務角度定義問題、專案目標和要求,然後將其轉換為資料探勘。制定初步計劃以實現目標。
- 資料理解 - 資料理解階段最初從資料收集開始,以識別資料質量、發現數據洞察力或檢測有趣的子集,以形成對隱藏資訊的假設。
- 資料準備 - 資料準備階段涵蓋所有活動,以從初始原始資料構建最終資料集(將饋送到建模工具的資料)。資料準備任務可能會多次執行,並且不會按照任何規定的順序執行。任務包括表、記錄和屬性選擇以及資料的轉換和清理,以用於建模工具。
- 建模 - 在此階段,選擇和應用不同的建模技術;可能有多種技術可用於處理相同型別的資料;專家總是選擇有效且高效的技術。
- 評估 - 建立建議模型後;在最終部署模型之前,務必對其進行徹底評估,並審查為構建模型而執行的步驟,以確保模型實現預期的業務目標。
- 部署 - 模型的建立通常不是專案的結束。即使模型的目的是提高對資料的瞭解,獲得的知識也需要以對客戶有用的方式進行組織和呈現。在許多情況下,將是客戶而不是資料分析師來執行部署階段。即使分析師部署了模型,客戶也需要預先了解需要採取哪些行動才能使用建立的模型。
SEMMA方法論
SEMMA是SAS為資料探勘建模開發的另一種方法。它代表樣本、探索、修改、模型和評估。

其階段的描述如下:
- 樣本 - 該過程從資料取樣開始,例如,選擇用於建模的資料集。資料集應足夠大,以包含足夠的資訊來檢索,但又足夠小,以便有效使用。此階段還處理資料分割槽。
- 探索 - 此階段涵蓋透過發現變數之間預期和意外的關係以及異常值(藉助資料視覺化)來了解資料。
- 修改 - “修改”階段包含為資料建模準備選擇、建立和轉換變數的方法。
- 模型 - 在“模型”階段,重點是將各種建模(資料探勘)技術應用於準備好的變數,以建立可能提供所需結果的模型。
- 評估 - 對建模結果的評估顯示了建立模型的可靠性和實用性。
CRISM-DM和SEMMA的主要區別在於,SEMMA側重於建模方面,而CRISP-DM更重視建模之前的週期階段,例如理解要解決的業務問題,理解和預處理要用作輸入的資料,例如機器學習演算法。
大資料生命週期
大資料分析是一個涉及管理整個資料生命週期的領域,包括資料收集、清洗、組織、儲存、分析和治理。在大資料環境下,傳統方法對於分析大批次資料、具有不同值的資料、資料速度等並不是最佳的。
例如,SEMMA方法論摒棄了不同資料來源的資料收集和預處理。這些階段通常構成成功大資料專案的大部分工作。大資料分析涉及識別、獲取、處理和分析大量原始資料、非結構化和半結構化資料,其目標是提取有價值的資訊,用於趨勢識別、增強現有公司資料和進行廣泛搜尋。
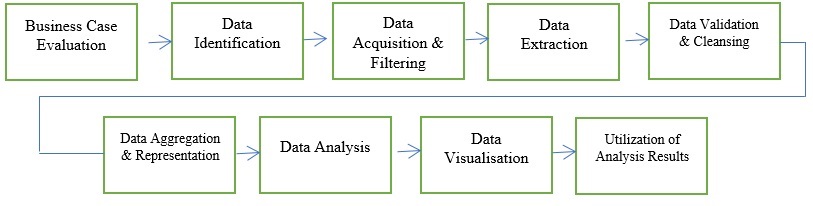
大資料分析生命週期可以分為以下階段:
- 業務案例評估
- 資料識別
- 資料獲取和過濾
- 資料提取
- 資料驗證和清洗
- 資料聚合和表示
- 資料分析
- 資料視覺化
- 分析結果的利用
大資料分析與傳統資料分析的主要區別在於處理的資料的價值、速度和多樣性。為了滿足大資料分析的特定要求,需要一種有組織的方法。大資料分析生命週期階段的描述如下:
業務案例評估
大資料分析生命週期始於明確定義的業務案例,該案例概述了進行分析的問題識別、目標和目標。在開始實際的動手分析工作之前,業務案例評估需要建立、評估和批准業務案例。
對大資料分析業務案例的檢查為決策者提供了方向,以瞭解所需業務資源和需要解決的業務問題。案例評估檢查正在解決的業務問題定義是否確實是大型資料問題。
資料識別
資料識別階段側重於識別分析專案所需的資料集及其來源。識別更大範圍的資料來源可以提高發現隱藏模式和關係的機會。根據公司正在解決的業務問題的性質,公司可能需要內部或外部資料集和來源。
資料獲取和過濾
資料獲取過程包括從上一階段提到的所有來源收集資料。我們將資料進行自動過濾,以去除與研究目標無關的損壞資料或記錄。根據資料來源的型別,資料可能作為檔案的集合出現,例如從第三方資料提供商那裡獲取的資料,或者作為API整合,例如與Twitter。
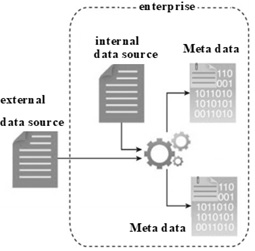
一旦生成或進入企業邊界,我們就必須儲存內部和外部資料。我們將此資料儲存到磁碟,然後使用批處理分析對其進行分析。在即時分析中,我們在將資料儲存到磁碟之前先對其進行分析。
資料提取
此階段側重於提取不同的資料並將其轉換為底層大資料解決方案可用於資料分析的格式。
資料驗證和清洗
不正確的資料可能會使分析結果產生偏差和誤導。與具有預定義結構並經過驗證可以饋入分析的典型企業資料不同;如果在分析之前未驗證資料,則大資料分析可能是非結構化的。其複雜性可能使得難以制定一套適當的驗證要求。資料驗證和清洗負責定義複雜的驗證標準並刪除任何已知的錯誤資料。
資料聚合和表示
資料聚合和表示階段側重於組合多個數據集以建立連貫的檢視。由於以下方面的差異,執行此階段可能會變得棘手:
資料結構 - 資料格式可能相同,但資料模型可能不同。
語義 - 在兩個資料集中標籤不同的變數可能表示相同的意思,例如“姓氏”和“姓”。
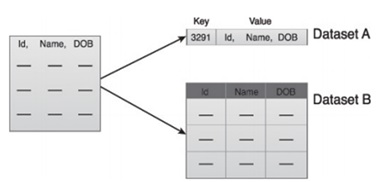
資料分析
資料分析階段負責執行實際的分析工作,通常包括一種或多種型別的分析。特別是如果資料分析是探索性的,我們可以迭代地繼續這個階段,直到我們發現正確的模式或關聯。
資料視覺化
資料視覺化階段以圖形方式視覺化資料,以便業務使用者有效地解讀結果。最終結果有助於執行視覺化分析,使他們能夠發現他們尚未提出的問題的答案。
分析結果的利用
向業務人員提供可用於支援業務決策的結果,例如透過儀表板。所有提到的九個階段都是大資料分析生命週期的主要階段。
以下階段也應考慮在內:
研究
分析其他公司在相同情況下所做的事情。這包括尋找對貴公司合理的解決方案,即使這需要根據貴公司的資源和要求調整其他解決方案。在這個階段,應該定義未來階段的方法。
人力資源評估
一旦問題定義明確,就可以繼續分析現有員工是否能夠成功完成專案。傳統的BI團隊可能無法為所有階段提供最佳解決方案,因此在專案開始之前,應該考慮是否有必要外包部分專案或招聘更多人員。
資料採集
此部分在大資料生命週期中至關重要;它定義了交付最終資料產品所需的哪種型別的配置檔案。資料收集是一個非平凡的步驟;它通常涉及從不同來源收集非結構化資料。例如,這可能涉及編寫爬蟲程式以從網站檢索評論。這涉及處理文字,可能使用不同的語言,通常需要大量時間才能完成。
資料清洗
例如,一旦資料從網路檢索到,就需要將其儲存為易於使用的格式。繼續以評論為例,假設資料是從不同的網站檢索的,每個網站的資料顯示方式都不同。
假設一個數據源以星級評分的形式提供評論,因此可以將其解讀為響應變數$\mathrm{y\:\epsilon \:\lbrace 1,2,3,4,5\rbrace}$的對映。另一個數據源使用箭頭系統提供評論,一個用於點贊,另一個用於點踩。這意味著響應變數的形式為$\mathrm{y\:\epsilon \:\lbrace positive,negative \rbrace}$。
為了組合這兩個資料來源,必須做出決定以使這兩個響應表示等效。這可能涉及將第一個資料來源響應表示轉換為第二種形式,將一顆星視為負面,五顆星視為正面。此過程通常需要大量時間才能高質量地交付。
資料儲存
資料處理完畢後,有時需要將其儲存在資料庫中。大資料技術在這方面提供了許多替代方案。最常見的替代方案是使用Hadoop檔案系統進行儲存,該系統為使用者提供了SQL的有限版本,稱為HIVE查詢語言。從使用者的角度來看,這允許大多數分析任務以與傳統BI資料倉庫中類似的方式完成。其他需要考慮的儲存選項包括MongoDB、Redis和SPARK。
生命週期的這個階段與人力資源的知識有關,涉及他們實施不同架構的能力。傳統資料倉庫的修改版本仍在大型應用程式中使用。例如,Teradata和IBM提供可以處理TB級資料的SQL資料庫;PostgreSQL和MySQL等開源解決方案仍在大型應用程式中使用。
儘管不同儲存在後臺的工作方式存在差異,但從客戶端來看,大多數解決方案都提供了SQL API。因此,對SQL有良好的理解仍然是大資料分析的關鍵技能。這個階段先驗地似乎是最重要的主題,實際上並非如此。它甚至不是一個必要的階段。可以實現一個使用即時資料的大資料解決方案,因此在這種情況下,我們只需要收集資料來開發模型,然後即時地實現它。因此根本不需要正式儲存資料。
探索性資料分析
一旦資料被清理並以可以從中檢索見解的方式儲存,資料探索階段是必須的。此階段的目標是理解資料,這通常使用統計技術以及繪製資料來完成。這是一個評估問題定義是否有意義或是否可行的良好階段。
建模和評估的資料準備
此階段涉及重塑先前檢索到的清理資料,並使用統計預處理進行缺失值插補、異常值檢測、歸一化、特徵提取和特徵選擇。
建模
前一階段應該已經產生了幾個用於訓練和測試的資料集,例如預測模型。此階段涉及嘗試不同的模型,並期望解決手頭的業務問題。實際上,通常希望模型能夠提供一些對業務的見解。最後,選擇最佳模型或模型組合,評估其在遺漏資料集上的效能。
實施
在這個階段,開發的資料產品被整合到公司的資料管道中。這包括在資料產品執行時設定驗證方案以跟蹤其效能。例如,在實施預測模型的情況下,此階段將涉及將模型應用於新資料,並且一旦響應可用,就評估模型。