- 大資料分析教程
- 大資料分析 - 首頁
- 大資料分析 - 概述
- 大資料分析 - 特性
- 大資料分析 - 資料生命週期
- 大資料分析 - 架構
- 大資料分析 - 方法論
- 大資料分析 - 核心交付成果
- 大資料採用與規劃考慮
- 大資料分析 - 關鍵利益相關者
- 大資料分析 - 資料分析師
- 大資料分析 - 資料科學家
- 大資料分析有用資源
- 大資料分析 - 快速指南
- 大資料分析 - 資源
- 大資料分析 - 討論
大資料分析 - 方法論
在方法論方面,大資料分析與傳統的實驗設計統計方法有顯著區別。分析始於資料。通常,我們以能夠回答業務專業人員問題的方式對資料進行建模。這種方法的目標是預測響應行為或瞭解輸入變數如何與響應相關。
通常,統計實驗設計會先設計實驗,然後獲取結果資料。這使得能夠在獨立性、正態性和隨機化的假設下生成適合統計模型的資料。大資料分析方法從問題識別開始,一旦定義了業務問題,就需要一個研究階段來設計方法。但是,一些通用準則幾乎適用於所有問題。
下圖展示了大資料分析中常用的方法論:
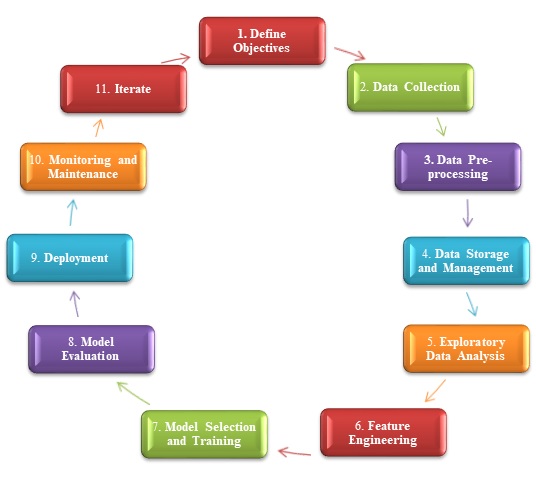
大資料分析方法論
大資料分析的方法如下:
定義目標
明確分析的目標和目的。你尋求什麼見解?你試圖解決什麼業務問題?這一階段對於引導整個過程至關重要。
資料收集
從各種來源收集相關資料。這包括來自資料庫的結構化資料,來自日誌或JSON檔案的半結構化資料,以及來自社交媒體、電子郵件和文件的非結構化資料。
資料預處理
此步驟包括清理和預處理資料,以確保其質量和一致性。這包括處理缺失值、刪除重複項、解決不一致性以及將資料轉換為可用的格式。
資料儲存和管理
將資料儲存在合適的儲存系統中。這可能包括傳統的SQL資料庫、NoSQL資料庫、資料湖或Hadoop分散式檔案系統(HDFS)等分散式檔案系統。
探索性資料分析 (EDA)
此階段包括識別資料特徵、查詢模式和檢測異常值。我們經常使用直方圖、散點圖和箱線圖等視覺化工具。
特徵工程
建立新特徵或修改現有特徵以提高機器學習模型的效能。這可能包括特徵縮放、降維或構建組合特徵。
模型選擇和訓練
根據問題的性質和資料的特性選擇相關的機器學習演算法。如果有標記資料,則訓練模型。
模型評估
使用準確率、精確率、召回率、F1分數和ROC曲線來衡量訓練模型的效能。這有助於確定用於部署的最佳效能模型。
部署
在生產環境中部署模型以供實際使用。這可能包括將模型與現有系統整合、建立用於模型推理的API以及建立監控工具。
監控和維護
根據變化的業務需求或資料特性調整分析流程。
迭代
大資料分析是一個迭代過程。分析資料,收集反饋,並根據需要更新模型或過程,以隨著時間的推移提高準確性和有效性。
大資料分析中最重要的任務之一是統計建模,即監督和非監督分類或迴歸問題。在清理和預處理用於建模的資料後,請使用適當的損失度量仔細評估各種模型。模型實施後,進行進一步評估並報告結果。預測建模中的一個常見陷阱是僅實施模型而從未衡量其效能。