- 敏捷資料科學教程
- 敏捷資料科學 - 首頁
- 敏捷資料科學 - 簡介
- 方法論概念
- 敏捷資料科學 - 流程
- 敏捷工具及安裝
- 敏捷中的資料處理
- SQL 與 NoSQL
- NoSQL 與資料流程式設計
- 收集和顯示記錄
- 資料視覺化
- 資料豐富
- 使用報表
- 預測的作用
- 使用 PySpark 提取特徵
- 構建迴歸模型
- 部署預測系統
- 敏捷資料科學 - SparkML
- 修復預測問題
- 提高預測效能
- 用敏捷和資料科學創造更好的場景
- 敏捷的實施
- 敏捷資料科學有用資源
- 敏捷資料科學 - 快速指南
- 敏捷資料科學 - 資源
- 敏捷資料科學 - 討論
敏捷資料科學 - 預測的作用
在本章中,我們將瞭解預測在敏捷資料科學中的作用。互動式報表揭示了資料的不同方面。預測構成敏捷衝刺的第四層。

在進行預測時,我們總是參考過去的資料並將其用作未來迭代的推論。在這個完整過程中,我們將資料從歷史資料的批次處理過渡到關於未來的即時資料。
預測的作用包括以下內容 -
預測有助於預測。一些預測基於統計推斷。一些預測基於專家的意見。
統計推斷涉及各種預測。
有時預測是準確的,有時預測是不準確的。
預測分析
預測分析包括來自預測建模、機器學習和資料探勘的各種統計技術,這些技術分析當前和歷史事實以預測未來和未知事件。
預測分析需要訓練資料。訓練資料包括自變數和因變數。因變數是使用者試圖預測的值。自變數是描述我們想要根據因變數預測的事物的特徵。
對特徵的研究稱為特徵工程;這對於進行預測至關重要。資料視覺化和探索性資料分析是特徵工程的一部分;這些構成了敏捷資料科學的核心。
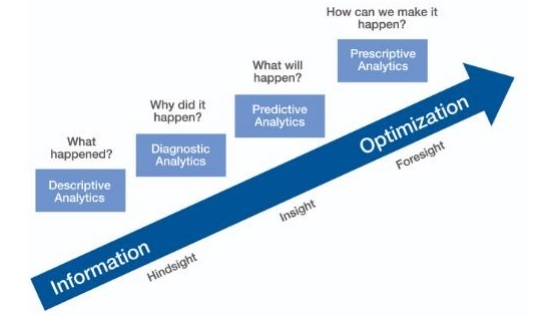
進行預測
在敏捷資料科學中,有兩種進行預測的方法 -
迴歸
分類
構建迴歸或分類完全取決於業務需求及其分析。連續變數的預測導致迴歸模型,而分類變數的預測導致分類模型。
迴歸
迴歸考慮包含特徵的示例,從而產生數值輸出。
分類
分類獲取輸入併產生分類分類。
注意 - 定義統計預測輸入並使機器能夠學習的示例資料集稱為“訓練資料”。
廣告