- 敏捷資料科學教程
- 敏捷資料科學 - 首頁
- 敏捷資料科學 - 簡介
- 方法論概念
- 敏捷資料科學 - 流程
- 敏捷工具及安裝
- 敏捷中的資料處理
- SQL 與 NoSQL
- NoSQL 與資料流程式設計
- 收集和顯示記錄
- 資料視覺化
- 資料豐富
- 使用報表
- 預測的作用
- 使用 PySpark 提取特徵
- 構建迴歸模型
- 部署預測系統
- 敏捷資料科學 - SparkML
- 修復預測問題
- 改進預測效能
- 使用敏捷和資料科學建立更好的場景
- 敏捷的實施
- 敏捷資料科學有用資源
- 敏捷資料科學 - 快速指南
- 敏捷資料科學 - 資源
- 敏捷資料科學 - 討論
敏捷資料科學 - 快速指南
敏捷資料科學 - 簡介
敏捷資料科學是一種將資料科學與敏捷方法論結合用於Web應用程式開發的方法。它關注資料科學過程的輸出,適用於對組織產生影響的變革。資料科學包括構建描述研究過程的應用程式,包括分析、互動式視覺化以及現在應用的機器學習。
敏捷資料科學的主要目標是:
記錄和指導解釋性資料分析,以發現並遵循通往引人注目的產品的關鍵路徑。
敏捷資料科學遵循以下原則:
持續迭代
此過程涉及持續迭代,建立表格、圖表、報告和預測。構建預測模型需要多次迭代特徵工程,包括特徵提取和洞察力生成。
中間輸出
這是生成的輸出跟蹤列表。甚至可以說失敗的實驗也有輸出。跟蹤每次迭代的輸出將有助於在下次迭代中建立更好的輸出。
原型實驗
原型實驗涉及分配任務並根據實驗生成輸出。在給定的任務中,我們必須迭代以獲得洞察力,這些迭代可以最好地解釋為實驗。
資料整合
軟體開發生命週期包括不同的階段,資料對於以下方面至關重要:
客戶
開發者,以及
企業
資料整合為更好的前景和輸出鋪平了道路。
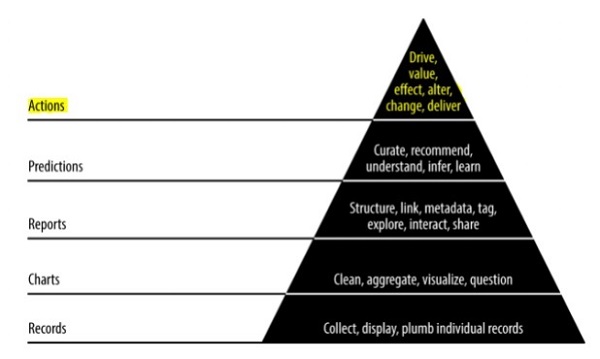
金字塔資料價值
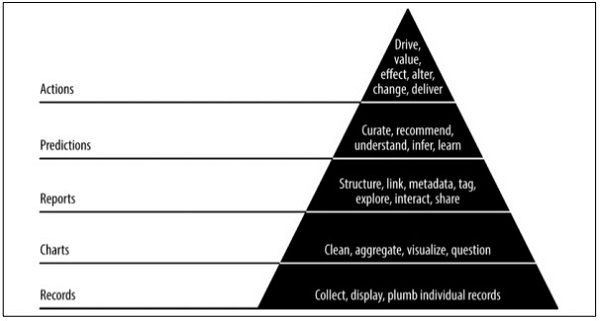
上述金字塔價值描述了“敏捷資料科學”開發所需的層次。它始於基於需求的記錄收集和單個記錄的整合。在資料清洗和聚合之後建立圖表。聚合資料可用於資料視覺化。報表以適當的結構、元資料和資料標籤生成。從頂部算起的第二層包括預測分析。預測層是創造更多價值的地方,但它有助於建立專注於特徵工程的良好預測。
頂層涉及行動,有效地驅動資料的價值。“人工智慧”是這一實施的最佳例證。
敏捷資料科學 - 方法論概念
在本章中,我們將重點關注稱為“敏捷”的軟體開發生命週期概念。敏捷軟體開發方法有助於透過短迭代(1到4周)的增量會話構建軟體,因此開發與不斷變化的業務需求保持一致。
有12項原則詳細描述了敏捷方法論:
客戶滿意度
最高優先順序是關注客戶,透過儘早並持續交付有價值的軟體來滿足他們的需求。
歡迎變化
在軟體開發過程中是可以接受變化的。敏捷流程旨在運作以匹配客戶的競爭優勢。
交付
在1到4周內向客戶交付可執行的軟體。
協作
業務分析師、質量分析師和開發人員必須在專案的整個生命週期中通力合作。
激勵
專案應該由一群積極主動的個人設計。它提供了一個支援團隊成員的環境。
面對面交流
面對面交流是在開發團隊內部以及向開發團隊傳送資訊的最高效和最有效的方法。
進度衡量
衡量進度是幫助定義專案和軟體開發進度的關鍵。
保持持續的節奏
敏捷流程專注於可持續發展。企業、開發人員和使用者都應該能夠與專案保持一致的步伐。
監控
必須保持對技術卓越和良好設計的持續關注,以增強敏捷功能。
簡潔
敏捷流程保持一切簡潔,並使用簡單的術語來衡量未完成的工作。
自我組織團隊
敏捷團隊應該能夠自我組織,並且應該獨立於最佳架構;需求和設計源於自我組織的團隊。
回顧工作
定期回顧工作非常重要,以便團隊能夠反思工作進展情況。及時回顧模組將提高績效。
每日站會
每日站會是指團隊成員之間的每日狀態會議。它提供與軟體開發相關的更新。它還指的是解決專案開發中的障礙。
每日站會是強制性的實踐,無論敏捷團隊如何建立,無論其辦公地點如何。
每日站會的特點如下:
每日站會的時間應大約為15分鐘。不應延長更長時間。
站會應包括關於狀態更新的討論。
此次會議的參與者通常站著,目的是快速結束會議。
使用者故事
故事通常是一個需求,它以簡單的語言用幾句話來表達,並且應該在一個迭代內完成。使用者故事應包括以下特徵:
所有相關程式碼都應該有相關的簽入。
指定迭代的單元測試用例。
所有驗收測試用例都應定義。
產品負責人定義故事時的驗收。

什麼是Scrum?
Scrum可以被認為是敏捷方法論的一個子集。它是一個輕量級流程,包括以下功能:
它是一個流程框架,包括一組需要按一致順序遵循的實踐。Scrum 的最佳例證是遵循迭代或衝刺。
它是一個“輕量級”流程,這意味著該流程儘可能精簡,以在指定的持續時間內最大化生產性輸出。
Scrum 流程以其與其他傳統敏捷方法相比的獨特流程而聞名。它分為以下三類:
角色
工件
時間盒
角色定義了團隊成員及其在整個過程中所扮演的角色。Scrum 團隊由以下三個角色組成:
Scrum主管
產品負責人
團隊
Scrum 工件提供了每個成員都應該瞭解的關鍵資訊。資訊包括產品詳情、計劃的活動和已完成的活動。Scrum 框架中定義的工件如下:
產品待辦事項列表
衝刺待辦事項列表
燃盡圖
增量
時間盒是為每個迭代計劃的使用者故事。這些使用者故事有助於描述構成 Scrum 工件一部分的產品特性。產品待辦事項列表是使用者故事的列表。這些使用者故事按優先順序排序,並轉發到使用者會議,以決定應該採用哪一個。
為什麼需要 Scrum 主管?
Scrum 主管與團隊的每個成員互動。現在讓我們看看 Scrum 主管與其他團隊和資源的互動。
產品負責人
Scrum 主管與產品負責人的互動方式如下:
尋找技術以實現使用者故事的有效產品待辦事項列表並對其進行管理。
幫助團隊理解清晰簡潔的產品待辦事項列表項的需求。
在特定環境中進行產品規劃。
確保產品負責人知道如何提高產品的價值。
根據需要促進 Scrum 活動。
Scrum 團隊
Scrum 主管與團隊的互動方式多種多樣:
指導組織採用 Scrum。
規劃 Scrum 在特定組織中的實施。
幫助員工和利益相關者瞭解產品開發的需求和階段。
與其他團隊的 Scrum 主管合作,以提高指定團隊 Scrum 應用的有效性。
組織
Scrum 主管與組織的互動方式多種多樣。下面提到了一些:
指導和 Scrum 團隊與自我組織互動,幷包含跨功能特性。
在 Scrum 尚未完全採用或未被接受的領域指導組織和團隊。
Scrum 的好處
Scrum 有助於客戶、團隊成員和利益相關者之間的協作。它包括時間盒方法和來自產品負責人的持續反饋,確保產品處於可執行狀態。Scrum 為專案的不同角色帶來了好處。
客戶
衝刺或迭代被認為是較短的持續時間,使用者故事是根據優先順序設計的,並在衝刺計劃中採用。它確保每個衝刺交付都滿足客戶需求。如果沒有,則會記錄需求,並計劃並在衝刺中進行。
組織
藉助 Scrum 和 Scrum 主管的組織可以專注於使用者故事開發所需的努力,從而減少工作過載並避免任何返工。這也有助於保持開發團隊效率的提高和客戶滿意度。這種方法還有助於提高市場潛力。
產品經理
產品經理的主要責任是確保產品的質量。在 Scrum 主管的幫助下,很容易促進工作、收集快速響應並在出現任何變化時吸收變化。產品經理還驗證在每個衝刺中設計的 product 是否符合客戶的要求。
開發團隊
由於時間盒的性質和衝刺持續時間較短,開發團隊變得熱情洋溢,看到工作得到正確反映和交付。在每次迭代之後,或我們可以稱之為“衝刺”之後,可執行的產品增量都會提高一個級別。為每個衝刺設計的使用者故事成為客戶的優先事項,為迭代增加了更多價值。
結論
Scrum 是一個高效的框架,您可以在其中透過團隊合作開發軟體。它完全基於敏捷原則。Scrum 主管隨時準備以各種可能的方式幫助和配合 Scrum 團隊。他就像一位私人教練,幫助您堅持既定計劃並按照計劃執行所有活動。Scrum 主管的權力不應超出流程。他/她應該有能力處理各種情況。
敏捷資料科學 - 資料科學流程
本章我們將瞭解資料科學流程以及理解該流程所需的術語。
“資料科學是資料介面、演算法開發和技術相結合,以解決複雜的分析問題”。

資料科學是一個跨學科領域,它包含科學方法、流程和系統,其中包括機器學習、數學和統計知識以及傳統的科研方法。它還包括駭客技能與專業知識的結合。資料科學汲取了數學、統計學、資訊科學和計算機科學、資料探勘和預測分析的原理。
構成資料科學團隊的不同角色如下所示:
客戶
客戶是使用產品的人。他們的興趣決定了專案的成功,他們的反饋在資料科學中非常寶貴。
業務拓展
資料科學團隊透過直接或建立登陸頁面和推廣的方式簽署早期客戶。業務拓展團隊交付產品的價值。
產品經理
產品經理重視創造最有價值的產品。
互動設計師
他們專注於圍繞資料模型設計互動,以便使用者找到合適的價值。
資料科學家
資料科學家以新的方式探索和轉換資料,以建立和釋出新功能。這些科學家還將來自不同來源的資料結合起來,創造新的價值。他們在與研究人員、工程師和網頁開發人員一起建立視覺化方面發揮著重要作用。
研究人員
顧名思義,研究人員參與研究活動。他們解決資料科學家無法解決的複雜問題。這些問題需要專注於機器學習和統計模組,並投入大量時間。
適應變化
所有資料科學團隊成員都需要適應新的變化並根據需求開展工作。為了將敏捷方法應用於資料科學,需要進行一些改變,如下所示:
選擇通才而不是專家。
更偏好小型團隊而不是大型團隊。
使用高階工具和平臺。
持續迭代地分享中間成果。
注意
在敏捷資料科學團隊中,一個小型的通才團隊使用可擴充套件的高階工具,並透過迭代將資料完善到越來越高的價值狀態。
考慮以下與資料科學團隊成員工作相關的示例:
設計師交付CSS。
網頁開發人員構建完整的應用程式,瞭解使用者體驗和介面設計。
資料科學家應該同時從事研究和構建包括 Web 應用程式在內的 Web 服務。
研究人員在程式碼庫中工作,展示解釋中間結果的結果。
產品經理試圖識別和理解所有相關領域的缺陷。
敏捷工具和安裝
本章我們將學習不同的敏捷工具及其安裝。敏捷方法的開發棧包括以下元件:
事件
事件是發生的或被記錄的事件,以及其特徵和時間戳。
事件可以有多種形式,例如伺服器、感測器、金融交易或使用者在我們應用程式中採取的操作。在本教程中,我們將使用 JSON 檔案,這將促進不同工具和語言之間的資料交換。
收集器
收集器是事件聚合器。它們以系統的方式收集事件,以儲存和聚合大量資料,並將它們排隊等待即時工作者的處理。
分散式文件
這些文件包括多節點(多個節點),它們以特定格式儲存文件。在本教程中,我們將重點關注 MongoDB。
Web 應用伺服器
Web 應用伺服器透過客戶端以 JSON 形式提供資料,用於視覺化,且開銷最小。這意味著 Web 應用伺服器有助於測試和部署使用敏捷方法建立的專案。
現代瀏覽器
它使現代瀏覽器或應用程式能夠將資料作為互動式工具呈現給我們的使用者。
本地環境設定
為了管理資料集,我們將重點關注包含用於管理 excel、csv 和更多檔案的工具的 python 的 Anaconda 框架。安裝後 Anaconda 框架的儀表板如下所示。它也稱為“Anaconda Navigator”:

導航器包括“Jupyter 框架”,這是一個筆記本系統,有助於管理資料集。啟動框架後,它將在瀏覽器中託管,如下所示:

敏捷資料科學 - 敏捷中的資料處理
本章我們將重點介紹結構化資料、半結構化資料和非結構化資料之間的區別。
結構化資料
結構化資料是指以 SQL 格式儲存在具有行和列的表中的資料。它包括一個關係鍵,該關係鍵對映到預先設計的欄位。結構化資料在大規模使用。
結構化資料僅佔所有資訊資料 5% 到 10%。
半結構化資料
半結構化資料包括不駐留在關係資料庫中的資料。它們包含一些組織屬性,使分析更容易。它包括將它們儲存在關係資料庫中的相同過程。半結構化資料庫的示例包括 CSV 檔案、XML 和 JSON 文件。NoSQL 資料庫被認為是半結構化的。
非結構化資料
非結構化資料佔資料的 80%。它通常包括文字和多媒體內容。非結構化資料的最佳示例包括音訊檔案、簡報和網頁。機器生成的非結構化資料的示例包括衛星影像、科學資料、照片和影片、雷達和聲納資料。

上述金字塔結構特別關注資料量及其分佈比例。
準結構化資料介於非結構化資料和半結構化資料之間。在本教程中,我們將重點關注半結構化資料,因為它有利於敏捷方法和資料科學研究。
半結構化資料沒有正式的資料模型,但具有明顯、自描述的模式和結構,這些模式和結構是透過其分析而發展起來的。
敏捷資料科學 - SQL 與 NoSQL
本教程的重點是遵循敏捷方法,減少步驟,並實施更多有用的工具。要理解這一點,重要的是要知道 SQL 和 NoSQL 資料庫之間的區別。
大多數使用者都瞭解 SQL 資料庫,並且對 MySQL、Oracle 或其他 SQL 資料庫都有很好的瞭解。在過去的幾年裡,NoSQL 資料庫已被廣泛採用,以解決各種業務問題和專案需求。

下表顯示了 SQL 和 NoSQL 資料庫之間的區別:
| SQL | NoSQL |
|---|---|
| SQL 資料庫主要被稱為關係資料庫管理系統 (RDBMS)。 | NoSQL 資料庫也稱為面向文件的資料庫。它是非關係型和分散式的。 |
| 基於 SQL 的資料庫包括具有行和列的表結構。表和其他模式結構的集合稱為資料庫。 | NoSQL 資料庫包含文件作為主要結構,文件的集合稱為集合。 |
| SQL 資料庫包含預定義的模式。 | NoSQL 資料庫具有動態資料,幷包含非結構化資料。 |
| SQL 資料庫是垂直可擴充套件的。 | NoSQL 資料庫是水平可擴充套件的。 |
| SQL 資料庫非常適合複雜的查詢環境。 | NoSQL 沒有用於複雜查詢開發的標準介面。 |
| SQL 資料庫不適合分層資料儲存。 | NoSQL 資料庫更適合分層資料儲存。 |
| SQL 資料庫最適合指定應用程式中的大量事務。 | NoSQL 資料庫在高負載下對於複雜的交易應用程式仍然不被認為是可比的。 |
| SQL 資料庫得到了其供應商的出色支援。 | NoSQL 資料庫仍然依賴於社群支援。只有少數專家可以進行大規模 NoSQL 部署的設定和部署。 |
| SQL 資料庫專注於 ACID 屬性——原子性、一致性、隔離性和永續性。 | NoSQL 資料庫專注於 CAP 屬性——一致性、可用性和分割槽容錯性。 |
| SQL 資料庫可以根據選擇它們的供應商分類為開源或閉源。 | NoSQL 資料庫根據儲存型別進行分類。NoSQL 資料庫預設是開源的。 |
為什麼敏捷選擇 NoSQL?
上述比較表明,NoSQL 文件資料庫完全支援敏捷開發。它沒有模式,並且不完全專注於資料建模。相反,NoSQL 推遲應用程式和服務,因此開發人員可以更好地瞭解如何建模資料。NoSQL 將資料模型定義為應用程式模型。

MongoDB 安裝
在本教程中,我們將更多地關注 MongoDB 的示例,因為它被認為是最好的“NoSQL 模式”。



NoSQL 和資料流程式設計
有時資料以非關係格式不可用,我們需要藉助 NoSQL 資料庫使其保持事務性。
本章我們將重點介紹 NoSQL 的資料流。我們還將學習它如何與敏捷和資料科學相結合進行操作。
使用 NoSQL 與敏捷的主要原因之一是提高與市場競爭的速度。以下原因說明了為什麼 NoSQL 最適合敏捷軟體方法:
更少的障礙
更改當前正在進行中的模型即使在敏捷開發中也有一些實際成本。使用 NoSQL,使用者使用聚合資料,而不是浪費時間規範化資料。要點是完成某些工作並朝著使模型資料完善的目標努力。
可擴充套件性增強
每當一個組織建立產品時,它都會更加關注其可擴充套件性。NoSQL 始終以其可擴充套件性而聞名,但在水平可擴充套件性設計時效果更好。
利用資料的能力
NoSQL 是一種無模式資料模型,允許使用者輕鬆使用大量資料,其中包括多個可變性和速度引數。在考慮技術選擇時,您應該始終考慮能夠更大規模地利用資料的技術。
NoSQL 的資料流
讓我們考慮以下示例,其中我們展示瞭如何將資料模型集中於建立 RDBMS 模式。
以下是模式的不同需求:
應列出使用者標識。
每個使用者至少必須具備一項技能。
應妥善維護每個使用者的經驗詳情。
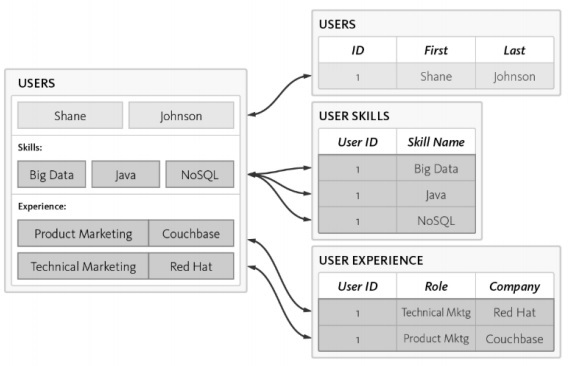
使用者表已使用 3 個單獨的表進行規範化:
使用者
使用者技能
使用者體驗
查詢資料庫時複雜性會增加,並且隨著規範化的增加,時間消耗也會增加,這不利於敏捷方法。可以使用 NoSQL 資料庫設計相同的模式,如下所示:
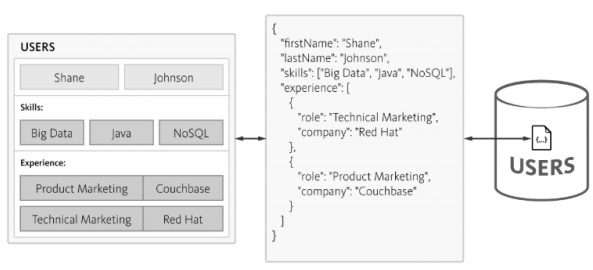
NoSQL 以 JSON 格式維護結構,結構輕量級。使用 JSON,應用程式可以將具有巢狀資料的物件儲存為單個文件。
收集和顯示記錄
本章我們將重點介紹構成“敏捷方法”一部分的 JSON 結構。MongoDB 是一種廣泛使用的 NoSQL 資料結構,易於收集和顯示記錄。
步驟 1
此步驟涉及與 MongoDB 建立連線以建立集合和指定資料模型。您需要執行的是“mongod”命令以啟動連線,以及“mongo”命令以連線到指定的終端。
步驟 2
建立一個新資料庫以建立 JSON 格式的記錄。現在,我們建立一個名為“mydb”的虛擬資料庫。
>use mydb
switched to db mydb
>db
mydb
>show dbs
local 0.78125GB
test 0.23012GB
>db.user.insert({"name":"Agile Data Science"})
>show dbs
local 0.78125GB
mydb 0.23012GB
test 0.23012GB
步驟 3
建立集合是獲取記錄列表的必要步驟。此功能有利於資料科學研究和輸出。
>use test
switched to db test
>db.createCollection("mycollection")
{ "ok" : 1 }
>show collections
mycollection
system.indexes
>db.createCollection("mycol", { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
{ "ok" : 1 }
>db.agiledatascience.insert({"name" : "demoname"})
>show collections
mycol
mycollection
system.indexes
demoname
敏捷資料科學 - 資料視覺化
資料視覺化在資料科學中扮演著非常重要的角色。我們可以將資料視覺化視為資料科學的一個模組。資料科學不僅僅是構建預測模型。它包括模型的解釋以及使用模型來理解資料並做出決策。資料視覺化是將資料以最令人信服的方式呈現出的一個組成部分。
從資料科學的角度來看,資料視覺化是一個突出顯示特徵,它顯示了變化和趨勢。
請考慮以下有效資料視覺化的指導原則:
將資料置於共同的比例尺上。
與圓形和方形相比,使用條形圖更有效。
散點圖應使用合適的顏色。
使用餅圖顯示比例。
旭日圖更適用於層次圖。
敏捷方法需要一種簡單的資料視覺化指令碼語言,並且與資料科學結合,“Python”是建議用於資料視覺化的語言。
示例 1
以下示例演示了特定年份計算的 GDP 的資料視覺化。“Matplotlib”是 Python 中最好的資料視覺化庫。該庫的安裝如下所示:

請考慮以下程式碼以瞭解這一點:
import matplotlib.pyplot as plt
years = [1950, 1960, 1970, 1980, 1990, 2000, 2010]
gdp = [300.2, 543.3, 1075.9, 2862.5, 5979.6, 10289.7, 14958.3]
# create a line chart, years on x-axis, gdp on y-axis
plt.plot(years, gdp, color='green', marker='o', linestyle='solid')
# add a title plt.title("Nominal GDP")
# add a label to the y-axis
plt.ylabel("Billions of $")
plt.show()
輸出
上述程式碼生成以下輸出:
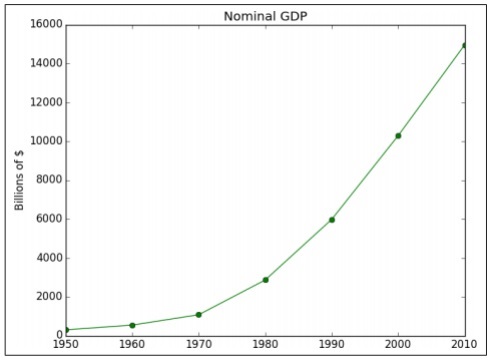
有很多方法可以使用軸標籤、線型和點標記來自定義圖表。讓我們關注下一個示例,它演示了更好的資料視覺化效果。這些結果可用於獲得更好的輸出。
示例 2
import datetime import random import matplotlib.pyplot as plt # make up some data x = [datetime.datetime.now() + datetime.timedelta(hours=i) for i in range(12)] y = [i+random.gauss(0,1) for i,_ in enumerate(x)] # plot plt.plot(x,y) # beautify the x-labels plt.gcf().autofmt_xdate() plt.show()
輸出
上述程式碼生成以下輸出:

敏捷資料科學 - 資料增強
資料增強是指用於增強、細化和改進原始資料的一系列流程。它指的是有用的資料轉換(原始資料到有用資訊)。資料增強的過程側重於使資料成為現代企業或組織寶貴的資料資產。
最常見的資料增強過程包括透過使用特定的決策演算法來糾正資料庫中的拼寫錯誤或排版錯誤。資料增強工具會向簡單的資料表中新增有用的資訊。
請考慮以下用於單詞拼寫糾正的程式碼:
import re
from collections import Counter
def words(text): return re.findall(r'\w+', text.lower())
WORDS = Counter(words(open('big.txt').read()))
def P(word, N=sum(WORDS.values())):
"Probabilities of words"
return WORDS[word] / N
def correction(word):
"Spelling correction of word"
return max(candidates(word), key=P)
def candidates(word):
"Generate possible spelling corrections for word."
return (known([word]) or known(edits1(word)) or known(edits2(word)) or [word])
def known(words):
"The subset of `words` that appear in the dictionary of WORDS."
return set(w for w in words if w in WORDS)
def edits1(word):
"All edits that are one edit away from `word`."
letters = 'abcdefghijklmnopqrstuvwxyz'
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
deletes = [L + R[1:] for L, R in splits if R]
transposes = [L + R[1] + R[0] + R[2:] for L, R in splits if len(R)>1]
replaces = [L + c + R[1:] for L, R in splits if R for c in letters]
inserts = [L + c + R for L, R in splits for c in letters]
return set(deletes + transposes + replaces + inserts)
def edits2(word):
"All edits that are two edits away from `word`."
return (e2 for e1 in edits1(word) for e2 in edits1(e1))
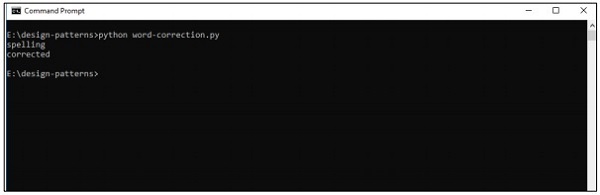
print(correction('speling'))
print(correction('korrectud'))
在這個程式中,我們將與包含已更正單詞的“big.txt”進行匹配。單詞與文字檔案中包含的單詞匹配,並相應地列印適當的結果。
輸出
上述程式碼將生成以下輸出:
敏捷資料科學 - 使用報表
在本章中,我們將學習報表建立,這是敏捷方法的一個重要模組。敏捷衝刺圖表將視覺化建立的頁面轉換成完整的報表。藉助報表,圖表變得互動式,靜態頁面變得動態,並且與網路相關的資料。報表階段的資料價值金字塔特徵如下所示:

我們將更加重視建立 csv 檔案,該檔案可用作資料科學分析的報表,並得出結論。儘管敏捷方法側重於減少文件,但生成報表以說明產品開發進度始終被認為是重要的。
import csv
#----------------------------------------------------------------------
def csv_writer(data, path):
"""
Write data to a CSV file path
"""
with open(path, "wb") as csv_file:
writer = csv.writer(csv_file, delimiter=',')
for line in data:
writer.writerow(line)
#----------------------------------------------------------------------
if __name__ == "__main__":
data = ["first_name,last_name,city".split(","),
"Tyrese,Hirthe,Strackeport".split(","),
"Jules,Dicki,Lake Nickolasville".split(","),
"Dedric,Medhurst,Stiedemannberg".split(",")
]
path = "output.csv"
csv_writer(data, path)
上述程式碼將幫助您生成如下所示的“csv 檔案”:
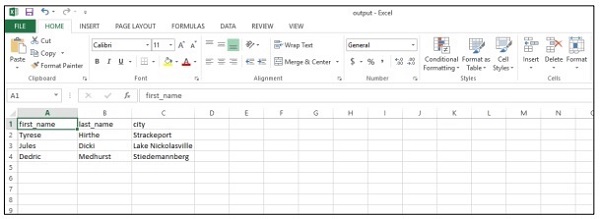
讓我們考慮一下 csv(逗號分隔值)報表的以下好處:
- 它對使用者友好,易於手動編輯。
- 它易於實現和解析。
- CSV 可在所有應用程式中處理。
- 它更小,處理速度更快。
- CSV 遵循標準格式。
- 它為資料科學家提供了直觀的模式。
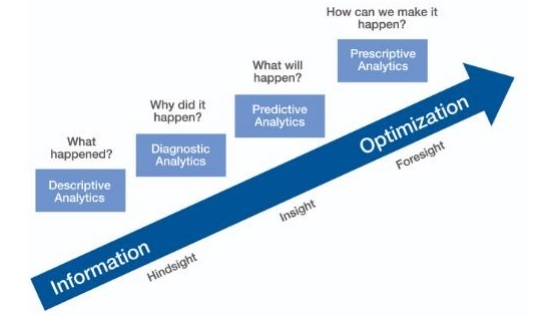
敏捷資料科學 - 預測的作用
在本章中,我們將學習預測在敏捷資料科學中的作用。互動式報表揭示了資料的不同方面。預測構成敏捷衝刺的第四層。

在進行預測時,我們總是參考過去的資料,並將它們用作未來迭代的推論。在這個完整的過程中,我們將資料從歷史資料的批次處理轉換為關於未來的即時資料。
預測的作用包括以下方面:
預測有助於預測。一些預測基於統計推斷。一些預測基於專家的意見。
統計推斷涉及各種預測。
有時預測是準確的,而有時預測是不準確的。
預測分析
預測分析包括來自預測建模、機器學習和資料探勘的各種統計技術,這些技術分析當前和歷史事實以預測未來和未知事件。
預測分析需要訓練資料。訓練資料包括獨立特徵和依賴特徵。依賴特徵是使用者試圖預測的值。獨立特徵是描述我們想要根據依賴特徵進行預測的事物的特徵。
對特徵的研究稱為特徵工程;這對於進行預測至關重要。資料視覺化和探索性資料分析是特徵工程的一部分;它們構成了**敏捷資料科學**的核心。
進行預測
在敏捷資料科學中進行預測有兩種方法:
迴歸
分類
構建迴歸模型或分類模型完全取決於業務需求及其分析。連續變數的預測導致迴歸模型,而分類變數的預測導致分類模型。
迴歸
迴歸考慮包含特徵的示例,從而產生數值輸出。
分類
分類獲取輸入併產生分類結果。
**注意** - 定義統計預測輸入並使機器能夠學習的示例資料集稱為“訓練資料”。
使用 PySpark 提取特徵
在本章中,我們將學習如何在敏捷資料科學中使用 PySpark 提取特徵的應用。
Spark 概述
Apache Spark 可定義為一個快速即時處理框架。它進行計算以即時分析資料。Apache Spark 被引入作為即時流處理系統,也可以處理批次處理。Apache Spark 支援互動式查詢和迭代演算法。
Spark是用“Scala程式語言”編寫的。
PySpark 可以被認為是 Python 與 Spark 的組合。PySpark 提供 PySpark shell,它將 Python API 連結到 Spark 核心並初始化 Spark 上下文。大多數資料科學家使用 PySpark 來跟蹤特徵,如前一章所述。
在這個例子中,我們將重點關注構建名為 counts 的資料集並將其儲存到特定檔案的轉換。
text_file = sc.textFile("hdfs://...")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")
使用 PySpark,使用者可以使用 Python 程式語言處理 RDD。內建庫涵蓋了資料驅動文件和元件的基礎知識,這有助於實現這一點。
構建迴歸模型
邏輯迴歸是指用於預測分類因變數機率的機器學習演算法。在邏輯迴歸中,因變數是二元變數,其資料編碼為 1(真和假的布林值)。
在本章中,我們將重點關注使用連續變數在 Python 中開發迴歸模型。線性迴歸模型的示例將側重於從 CSV 檔案中探索資料。
分類目標是預測客戶是否會訂閱(1/0)定期存款。
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
plt.rc("font", size=14)
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
import seaborn as sns
sns.set(style="white")
sns.set(style="whitegrid", color_codes=True)
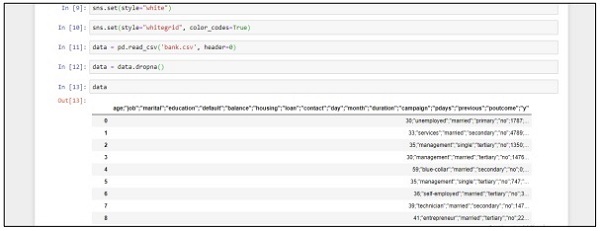
data = pd.read_csv('bank.csv', header=0)
data = data.dropna()
print(data.shape)
print(list(data.columns))
按照以下步驟使用 Anaconda Navigator 和“Jupyter Notebook”來實現上述程式碼:
**步驟 1** - 使用 Anaconda Navigator 啟動 Jupyter Notebook。


**步驟 2** - 上傳 csv 檔案以系統地獲取迴歸模型的輸出。

**步驟 3** - 建立一個新檔案並執行上述程式碼行以獲得所需的輸出。

部署預測系統
在這個示例中,我們將學習如何建立和部署預測模型,該模型有助於使用 python 指令碼預測房價。用於部署預測系統的重要的框架包括 Anaconda 和“Jupyter Notebook”。
按照以下步驟部署預測系統:
**步驟 1** - 實現以下程式碼以將 csv 檔案中的值轉換為關聯值。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import mpl_toolkits
%matplotlib inline
data = pd.read_csv("kc_house_data.csv")
data.head()
上述程式碼生成以下輸出:

**步驟 2** - 執行 describe 函式以獲取 csv 檔案屬性中包含的資料型別。
data.describe()

**步驟 3** - 我們可以根據我們建立的預測模型的部署來刪除關聯值。
train1 = data.drop(['id', 'price'],axis=1) train1.head()

**步驟 4** - 您可以根據記錄視覺化資料。這些資料可用於資料科學分析和白皮書的輸出。
data.floors.value_counts().plot(kind='bar')

敏捷資料科學 - SparkML
機器學習庫也稱為“SparkML”或“MLLib”,它包含常見的學習演算法,包括分類、迴歸、聚類和協同過濾。
為什麼要學習用於敏捷方法的 SparkML?
Spark 正在成為構建機器學習演算法和應用程式的事實上的平臺。開發人員在 Spark 上工作,以便在 Spark 框架中以可擴充套件且簡潔的方式實現機器演算法。我們將學習機器學習的概念、實用程式和演算法以及此框架。敏捷方法始終選擇能夠提供快速結果的框架。
ML 演算法
ML 演算法包括常見的學習演算法,例如分類、迴歸、聚類和協同過濾。
特徵
它包括特徵提取、轉換、降維和選擇。
管道
管道提供用於構建、評估和調整機器學習管道的工具。
流行演算法
以下是一些流行的演算法:
基本統計
迴歸
分類
推薦系統
聚類
降維
特徵提取
最佳化
推薦系統
推薦系統是資訊過濾系統的一個子類,它試圖預測使用者對給定專案的“評分”和“偏好”。
推薦系統包括各種過濾系統,使用方法如下:
協同過濾
它包括基於過去的行為以及其他使用者做出的類似決策來構建模型。此特定過濾模型用於預測使用者感興趣的專案。
基於內容的過濾
它包括過濾專案的離散特徵,以便推薦和新增具有類似屬性的新專案。
在後續章節中,我們將重點關注使用推薦系統來解決特定問題並從敏捷方法的角度提高預測效能。
修復預測問題
在本章中,我們將重點關注在特定場景的幫助下解決預測問題。
假設一家公司希望根據透過線上申請表提供的客戶詳細資訊自動執行貸款資格詳細資訊。詳細資訊包括客戶姓名、性別、婚姻狀況、貸款金額和其他必填詳細資訊。
詳細資訊記錄在如下所示的 CSV 檔案中:

執行以下程式碼來評估預測問題:
import pandas as pd
from sklearn import ensemble
import numpy as np
from scipy.stats import mode
from sklearn import preprocessing,model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
#loading the dataset
data=pd.read_csv('train.csv',index_col='Loan_ID')
def num_missing(x):
return sum(x.isnull())
#imputing the the missing values from the data
data['Gender'].fillna(mode(list(data['Gender'])).mode[0], inplace=True)
data['Married'].fillna(mode(list(data['Married'])).mode[0], inplace=True)
data['Self_Employed'].fillna(mode(list(data['Self_Employed'])).mode[0], inplace=True)
# print (data.apply(num_missing, axis=0))
# #imputing mean for the missing value
data['LoanAmount'].fillna(data['LoanAmount'].mean(), inplace=True)
mapping={'0':0,'1':1,'2':2,'3+':3}
data = data.replace({'Dependents':mapping})
data['Dependents'].fillna(data['Dependents'].mean(), inplace=True)
data['Loan_Amount_Term'].fillna(method='ffill',inplace=True)
data['Credit_History'].fillna(method='ffill',inplace=True)
print (data.apply(num_missing,axis=0))
#converting the cateogorical data to numbers using the label encoder
var_mod = ['Gender','Married','Education','Self_Employed','Property_Area','Loan_Status']
le = LabelEncoder()
for i in var_mod:
le.fit(list(data[i].values))
data[i] = le.transform(list(data[i]))
#Train test split
x=['Gender','Married','Education','Self_Employed','Property_Area','LoanAmount', 'Loan_Amount_Term','Credit_History','Dependents']
y=['Loan_Status']
print(data[x])
X_train,X_test,y_train,y_test=model_selection.train_test_split(data[x],data[y], test_size=0.2)
#
# #Random forest classifier
# clf=ensemble.RandomForestClassifier(n_estimators=100,
criterion='gini',max_depth=3,max_features='auto',n_jobs=-1)
clf=ensemble.RandomForestClassifier(n_estimators=200,max_features=3,min_samples
_split=5,oob_score=True,n_jobs=-1,criterion='entropy')
clf.fit(X_train,y_train)
accuracy=clf.score(X_test,y_test)
print(accuracy)
輸出
以上程式碼生成以下輸出。

改進預測效能
本章,我們將重點構建一個模型,幫助預測學生的學習成績,其中包含多個屬性。重點在於展示學生考試不及格的結果。
流程
評估的目標值是 G3。此值可以被分箱並進一步分類為不及格和及格。如果 G3 值大於或等於 10,則學生透過考試。
示例
考慮以下示例,其中執行程式碼來預測學生的學習成績:
import pandas as pd
""" Read data file as DataFrame """
df = pd.read_csv("student-mat.csv", sep=";")
""" Import ML helpers """
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import GridSearchCV, cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.svm import LinearSVC # Support Vector Machine Classifier model
""" Split Data into Training and Testing Sets """
def split_data(X, Y):
return train_test_split(X, Y, test_size=0.2, random_state=17)
""" Confusion Matrix """
def confuse(y_true, y_pred):
cm = confusion_matrix(y_true=y_true, y_pred=y_pred)
# print("\nConfusion Matrix: \n", cm)
fpr(cm)
ffr(cm)
""" False Pass Rate """
def fpr(confusion_matrix):
fp = confusion_matrix[0][1]
tf = confusion_matrix[0][0]
rate = float(fp) / (fp + tf)
print("False Pass Rate: ", rate)
""" False Fail Rate """
def ffr(confusion_matrix):
ff = confusion_matrix[1][0]
tp = confusion_matrix[1][1]
rate = float(ff) / (ff + tp)
print("False Fail Rate: ", rate)
return rate
""" Train Model and Print Score """
def train_and_score(X, y):
X_train, X_test, y_train, y_test = split_data(X, y)
clf = Pipeline([
('reduce_dim', SelectKBest(chi2, k=2)),
('train', LinearSVC(C=100))
])
scores = cross_val_score(clf, X_train, y_train, cv=5, n_jobs=2)
print("Mean Model Accuracy:", np.array(scores).mean())
clf.fit(X_train, y_train)
confuse(y_test, clf.predict(X_test))
print()
""" Main Program """
def main():
print("\nStudent Performance Prediction")
# For each feature, encode to categorical values
class_le = LabelEncoder()
for column in df[["school", "sex", "address", "famsize", "Pstatus", "Mjob",
"Fjob", "reason", "guardian", "schoolsup", "famsup", "paid", "activities",
"nursery", "higher", "internet", "romantic"]].columns:
df[column] = class_le.fit_transform(df[column].values)
# Encode G1, G2, G3 as pass or fail binary values
for i, row in df.iterrows():
if row["G1"] >= 10:
df["G1"][i] = 1
else:
df["G1"][i] = 0
if row["G2"] >= 10:
df["G2"][i] = 1
else:
df["G2"][i] = 0
if row["G3"] >= 10:
df["G3"][i] = 1
else:
df["G3"][i] = 0
# Target values are G3
y = df.pop("G3")
# Feature set is remaining features
X = df
print("\n\nModel Accuracy Knowing G1 & G2 Scores")
print("=====================================")
train_and_score(X, y)
# Remove grade report 2
X.drop(["G2"], axis = 1, inplace=True)
print("\n\nModel Accuracy Knowing Only G1 Score")
print("=====================================")
train_and_score(X, y)
# Remove grade report 1
X.drop(["G1"], axis=1, inplace=True)
print("\n\nModel Accuracy Without Knowing Scores")
print("=====================================")
train_and_score(X, y)
main()
輸出
以上程式碼生成的輸出如下所示
預測僅參考一個變數。參考一個變數,學生學習成績預測如下所示:
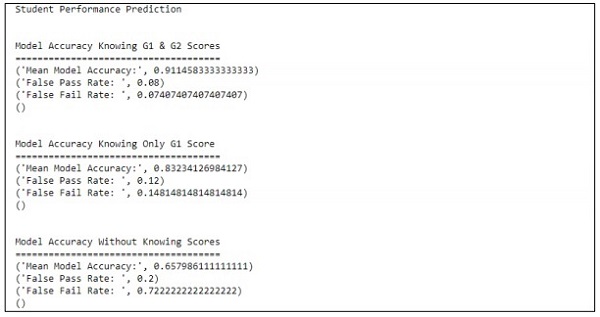
利用敏捷方法和資料科學創造更好的場景
敏捷方法幫助組織適應變化,在市場中競爭並構建高質量的產品。據觀察,隨著客戶需求變化的增加,組織在敏捷方法中日趨成熟。將資料與組織的敏捷團隊進行編譯和同步,對於根據所需組合彙總資料至關重要。
制定更好的計劃
標準化的敏捷績效完全取決於計劃。有序的資料模式增強了組織進度效率、質量和響應能力。通過歷史和即時場景保持資料一致性水平。
請參考下圖瞭解資料科學實驗週期:
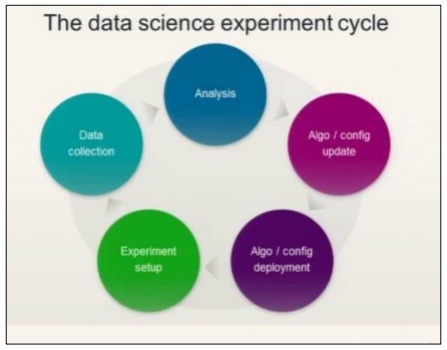
資料科學涉及對需求的分析,然後根據需求建立演算法。一旦設計好演算法並設定好環境,使用者就可以建立實驗並收集資料以進行更好的分析。
這種思想計算敏捷的最後一個衝刺,稱為“行動”。
行動包括敏捷方法最後一個衝刺或階段的所有強制性任務。可以透過故事卡片作為行動項來維護資料科學階段(關於生命週期)的跟蹤。
預測分析和大資料
未來規劃完全取決於使用從分析中收集的資料定製資料報告。它還將包括對大資料分析的操作。藉助大資料,可以有效地對離散的資訊片段進行分析,對組織的指標進行切片和切塊。分析總是被認為是更好的解決方案。
敏捷資料科學 - 敏捷的實施
敏捷開發過程中使用了各種方法。這些方法也可以用於資料科學研究過程。
下圖顯示了不同的方法:

Scrum( scrum )
在軟體開發方面,Scrum 意味著用小型團隊管理工作和管理特定專案,以揭示專案的優缺點。
水晶方法(Crystal methodologies)
水晶方法包括用於產品管理和執行的創新技術。使用此方法,團隊可以以不同的方式進行類似的任務。水晶系列是最容易應用的方法之一。
動態軟體開發方法 (Dynamic Software Development Method)
此交付框架主要用於在軟體方法中實施當前的知識系統。
未來驅動開發 (Future driven development)
此開發生命週期的重點是專案中涉及的功能。它最適合領域物件建模、程式碼和功能開發的所有權。
精益軟體開發 (Lean Software development)
此方法旨在以低成本提高軟體開發速度,並將團隊的注意力集中在為客戶提供特定價值上。極限程式設計 (Extreme Programming)
極限程式設計是一種獨特的軟體開發方法,它專注於提高軟體質量。當客戶不確定任何專案的功能時,這將非常有效。
敏捷方法正在資料科學領域紮根,它被認為是重要的軟體方法。透過敏捷自組織,跨職能團隊可以有效地一起工作。如前所述,敏捷開發有六個主要類別,每個類別都可以根據需求與資料科學結合。資料科學涉及用於統計洞察的迭代過程。敏捷有助於分解資料科學模組,並有助於有效地處理迭代和衝刺。
敏捷資料科學的過程是一種瞭解如何以及為什麼實施資料科學模組的絕佳方法。它以創造性的方式解決問題。