- 敏捷資料科學教程
- 敏捷資料科學 - 主頁
- 敏捷資料科學 - 簡介
- 方法論概念
- 敏捷資料科學 - 流程
- 敏捷工具和安裝
- 敏捷資料處理
- SQL 與 NoSQL
- NoSQL 和 Dataflow 程式設計
- 收集和顯示記錄
- 資料視覺化
- 資料充實
- 使用報表
- 預測的作用
- 使用 PySpark 提取特徵
- 構建迴歸模型
- 部署預測系統
- 敏捷資料科學 - SparkML
- 修復預測問題
- 改善預測效能
- 透過敏捷和資料科學創造更好的場景
- 敏捷實施
- 敏捷資料科學有用資源
- 敏捷資料科學 - 快速指南
- 敏捷資料科學 - 資源
- 敏捷資料科學 - 討論
構建迴歸模型
邏輯迴歸是指用於預測分類因變數的機率的機器學習演算法。在邏輯迴歸中,因變數是二進位制變數,由編碼為 1 的資料組成(真和假的布林值)。
在本章中,我們將重點介紹使用連續變數在 Python 中開發迴歸模型。線性迴歸模型的示例將重點介紹 CSV 檔案的資料探索。
分類目標是預測客戶是否將訂閱定期存款(1/0)。
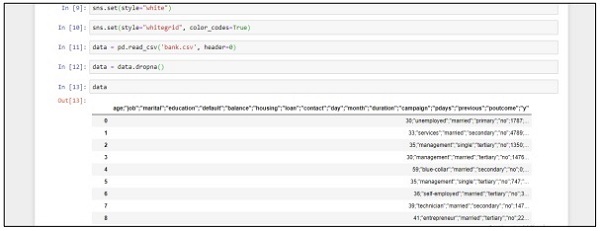
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
plt.rc("font", size=14)
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
import seaborn as sns
sns.set(style="white")
sns.set(style="whitegrid", color_codes=True)
data = pd.read_csv('bank.csv', header=0)
data = data.dropna()
print(data.shape)
print(list(data.columns))
按照以下步驟在具有“Jupyter Notebook”的 Anaconda Navigator 中實現上述程式碼−
步驟 1−使用 Anaconda Navigator 啟動 Jupyter Notebook。


步驟 2−上傳 csv 檔案以獲得迴歸模型的輸出,方式系統化。

步驟 3−建立一個新檔案並執行上述程式碼行以獲得預期輸出。

廣告