- 敏捷資料科學教程
- 敏捷資料科學 - 首頁
- 敏捷資料科學 - 簡介
- 方法論概念
- 敏捷資料科學 - 流程
- 敏捷工具與安裝
- 敏捷中的資料處理
- SQL 與 NoSQL
- NoSQL 與資料流程式設計
- 收集和顯示記錄
- 資料視覺化
- 資料豐富化
- 使用報表
- 預測的作用
- 使用 PySpark 提取特徵
- 構建迴歸模型
- 部署預測系統
- 敏捷資料科學 - SparkML
- 修復預測問題
- 提高預測效能
- 透過敏捷和資料科學創造更好的場景
- 敏捷的實施
- 敏捷資料科學有用資源
- 敏捷資料科學 - 快速指南
- 敏捷資料科學 - 資源
- 敏捷資料科學 - 討論
敏捷資料科學 - 簡介
敏捷資料科學是一種將資料科學與敏捷方法結合用於Web應用程式開發的方法。它關注資料科學過程的輸出,以便對組織產生影響。資料科學包括構建描述研究過程的應用程式,包括分析、互動式視覺化以及現在的應用機器學習。
敏捷資料科學的主要目標是:
記錄和指導解釋性資料分析,以發現並遵循通向引人注目的產品的關鍵路徑。
敏捷資料科學遵循以下原則:
持續迭代
此過程涉及持續迭代,建立表格、圖表、報表和預測。構建預測模型需要多次迭代特徵工程,包括提取和產生洞見。
中間輸出
這是生成的輸出清單。甚至可以說,失敗的實驗也有輸出。跟蹤每次迭代的輸出將有助於在下次迭代中建立更好的輸出。
原型實驗
原型實驗涉及分配任務並根據實驗生成輸出。在給定的任務中,我們必須迭代以獲得洞見,這些迭代可以最好地解釋為實驗。
資料整合
軟體開發生命週期包括不同的階段,其中資料對於以下方面至關重要:
客戶
開發人員,以及
企業
資料整合為更好的前景和輸出鋪平了道路。
金字塔資料價值
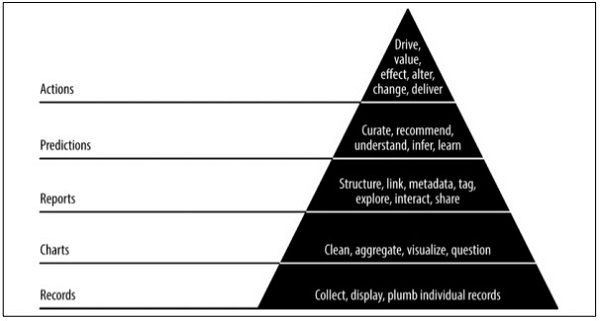
上述金字塔價值描述了“敏捷資料科學”開發所需的層級。它從基於需求的記錄收集和單個記錄的整理開始。在資料清洗和聚合之後建立圖表。聚合資料可用於資料視覺化。報表以適當的結構、元資料和資料標籤生成。從頂部開始的第二層包括預測分析。預測層是創造更多價值的地方,但它有助於建立良好的預測,重點關注特徵工程。
最頂層涉及行動,有效地驅動資料的價值。“人工智慧”是這一實施的最佳例證。
廣告