- Python Pandas 教程
- Python Pandas - 首頁
- Python Pandas - 簡介
- Python Pandas - 環境搭建
- Python Pandas - 基礎
- Python Pandas - 資料結構介紹
- Python Pandas - 索引物件
- Python Pandas - Panel (面板)
- Python Pandas - 基本功能
- Python Pandas - 索引和資料選擇
- Python Pandas - Series (序列)
- Python Pandas - Series (序列)
- Python Pandas - Series 物件切片
- Python Pandas - Series 物件屬性
- Python Pandas - Series 物件的算術運算
- Python Pandas - 將 Series 轉換為其他物件
- Python Pandas - DataFrame
- Python Pandas - DataFrame
- Python Pandas - 訪問 DataFrame
- Python Pandas - DataFrame 物件切片
- Python Pandas - 修改 DataFrame
- Python Pandas - 從 DataFrame 中刪除行
- Python Pandas - DataFrame 的算術運算
- Python Pandas - I/O 工具
- Python Pandas - I/O 工具
- Python Pandas - 使用 CSV 格式
- Python Pandas - 讀取和寫入 JSON 檔案
- Python Pandas - 從 Excel 檔案讀取資料
- Python Pandas - 將資料寫入 Excel 檔案
- Python Pandas - 使用 HTML 資料
- Python Pandas - 剪貼簿
- Python Pandas - 使用 HDF5 格式
- Python Pandas - 與 SQL 的比較
- Python Pandas - 資料處理
- Python Pandas - 排序
- Python Pandas - 重新索引
- Python Pandas - 迭代
- Python Pandas - 連線
- Python Pandas - 統計函式
- Python Pandas - 描述性統計
- Python Pandas - 處理文字資料
- Python Pandas - 函式應用
- Python Pandas - 選項和自定義
- Python Pandas - 視窗函式
- Python Pandas - 聚合
- Python Pandas - 合併/連線
- Python Pandas - 多級索引
- Python Pandas - 多級索引基礎
- Python Pandas - 使用多級索引進行索引
- Python Pandas - 使用多級索引進行高階重新索引
- Python Pandas - 重新命名多級索引標籤
- Python Pandas - 對多級索引排序
- Python Pandas - 二元運算
- Python Pandas - 二元比較運算
- Python Pandas - 布林索引
- Python Pandas - 布林掩碼
- Python Pandas - 資料重塑和透視
- Python Pandas - 透視表
- Python Pandas - 堆疊和取消堆疊
- Python Pandas - 熔化
- Python Pandas - 計算虛擬變數
- Python Pandas - 分類資料
- Python Pandas - 分類資料
- Python Pandas - 分類資料的排序和排列
- Python Pandas - 分類資料的比較
- Python Pandas - 處理缺失資料
- Python Pandas - 缺失資料
- Python Pandas - 填充缺失資料
- Python Pandas - 缺失值的插值
- Python Pandas - 刪除缺失資料
- Python Pandas - 對缺失資料進行計算
- Python Pandas - 處理重複資料
- Python Pandas - 重複資料
- Python Pandas - 計數和檢索唯一元素
- Python Pandas - 重複標籤
- Python Pandas - 分組和聚合
- Python Pandas - GroupBy
- Python Pandas - 時間序列資料
- Python Pandas - 日期函式
- Python Pandas - Timedelta (時間差)
- Python Pandas - 稀疏資料結構
- Python Pandas - 稀疏資料
- Python Pandas - 視覺化
- Python Pandas - 視覺化
- Python Pandas - 其他概念
- Python Pandas - 警告和陷阱
- Python Pandas 有用資源
- Python Pandas - 快速指南
- Python Pandas - 有用資源
- Python Pandas - 討論
Python Pandas - DataFrame
在 Python 的 pandas 庫中,DataFrame 是一個二維帶標籤的資料結構,用於資料操作和分析。它可以處理不同型別的資料,例如整數、浮點數和字串。每一列都有一個唯一的標籤,每一行都有一個唯一的索引值,這有助於訪問特定的行。
DataFrame 用於機器學習任務,允許使用者操作和分析大型資料集。它支援諸如過濾、排序、合併、分組和資料轉換等操作。
DataFrame 的特性
以下是 Pandas DataFrame 的特性:
- 列可以是不同型別。
- 大小是可變的。
- 帶標籤的軸(行和列)。
- 可以對行和列執行算術運算。
Python Pandas DataFrame 結構
您可以將 DataFrame 視為類似於 SQL 表格或電子表格資料表示。假設我們正在建立一個包含學生資料的資料框。
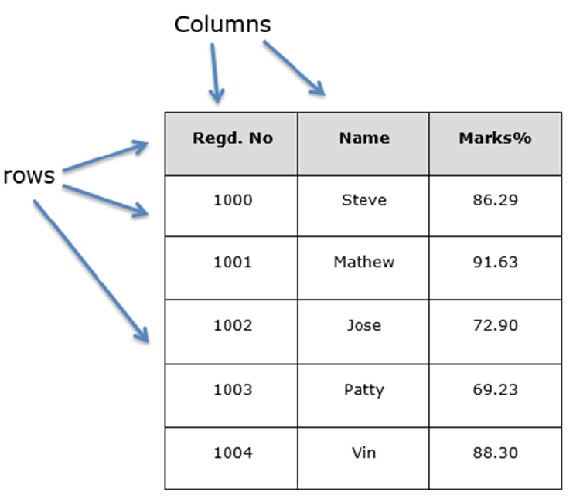
建立 pandas DataFrame
可以使用以下建構函式建立一個 pandas DataFrame:
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)
建構函式的引數如下:
| 序號 | 引數和描述 |
|---|---|
| 1 |
data data 可以採用多種形式,例如 ndarray、series、map、列表、字典、常量以及另一個 DataFrame。 |
| 2 |
index 用於結果框架的行標籤,是可選的。如果未傳遞索引,則預設為 np.arange(n)。 |
| 3 |
columns 此引數指定列標籤,可選的預設語法為 - np.arange(n)。只有在未傳遞索引時才為真。 |
| 4 |
dtype 每列的資料型別。 |
| 5 |
copy 此命令(或任何它是什麼)用於複製資料,如果預設為 False。 |
從不同的輸入建立 DataFrame
可以使用各種輸入(例如)建立 pandas DataFrame:
- 列表
- 字典
- Series
- NumPy ndarrays
- 另一個 DataFrame
- 外部輸入檔案,例如 CSV、JSON、HTML、Excel 表格等等。
在本章的後續部分,我們將瞭解如何使用這些輸入建立 DataFrame。
建立空 DataFrame
可以使用 DataFrame 建構函式在沒有任何輸入的情況下建立一個空 DataFrame。
示例
以下是建立空 DataFrame 的示例。
#import the pandas library and aliasing as pd import pandas as pd df = pd.DataFrame() print(df)
其輸出如下:
Empty DataFrame Columns: [] Index: []
從列表建立 DataFrame
可以使用單個列表或列表的列表建立 DataFrame。
示例
以下示例演示如何從 Python 列表物件建立 pandas DataFrame。
import pandas as pd data = [1,2,3,4,5] df = pd.DataFrame(data) print(df)
其輸出如下:
0 0 1 1 2 2 3 3 4 4 5
示例
這是另一個從 Python 列表的列表建立 Pandas DataFrame 的示例。
import pandas as pd data = [['Alex',10],['Bob',12],['Clarke',13]] df = pd.DataFrame(data,columns=['Name','Age']) print(df)
其輸出如下:
Name Age 0 Alex 10 1 Bob 12 2 Clarke 13
從 ndarray/列表的字典建立 DataFrame
所有ndarrays都必須具有相同的長度。如果傳遞索引,則索引的長度應等於陣列的長度。
如果沒有傳遞索引,則預設情況下,索引將是 range(n),其中n是陣列的長度。
示例
以下是根據 Python 字典建立 DataFrame 的示例。
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data)
print(df)
其輸出如下:
Age Name 0 28 Tom 1 34 Jack 2 29 Steve 3 42 Ricky
注意 - 請觀察值 0,1,2,3。它們是使用函式 range(n) 為每個值分配的預設索引。
示例
現在讓我們使用陣列建立一個帶索引的 DataFrame。
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data, index=['rank1','rank2','rank3','rank4'])
print(df)
其輸出如下:
Age Name rank1 28 Tom rank2 34 Jack rank3 29 Steve rank4 42 Ricky
注意 - 請注意,index引數為每一行分配一個索引。
從字典列表建立 DataFrame
字典列表可以作為輸入資料傳遞以建立 DataFrame。字典鍵預設情況下被視為列名。
示例
以下示例顯示如何透過傳遞字典列表來建立 DataFrame。
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print(df)
其輸出如下:
a b c 0 1 2 NaN 1 5 10 20.0
注意 - 請注意,NaN(非數字)附加在缺失區域。
示例
以下示例顯示如何使用字典列表、行索引和列索引建立 DataFrame。
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
#With two column indices, values same as dictionary keys
df1 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b'])
#With two column indices with one index with other name
df2 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b1'])
print(df1)
print(df2)
其輸出如下:
#df1 output
a b
first 1 2
second 5 10
#df2 output
a b1
first 1 NaN
second 5 NaN
注意 - 請注意,df2 DataFrame 是使用與字典鍵不同的列索引建立的;因此,在適當位置添加了 NaN。而 df1 是使用與字典鍵相同的列索引建立的,因此添加了 NaN。
從 Series 字典建立 DataFrame
Series 的字典可以傳遞來形成 DataFrame。結果索引是傳遞的所有 Series 索引的並集。
示例
這是一個例子:
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print(df)
其輸出如下:
one two a 1.0 1 b 2.0 2 c 3.0 3 d NaN 4
注意 - 請注意,對於 series one,沒有傳遞標籤‘d’,但在結果中,對於標籤d,附加了 NaN。
示例
另一個從 Series 建立 Pandas DataFrame 的示例:
import pandas as pd data = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']) df = pd.DataFrame(data) print(df)
其輸出如下:
0 a 1 b 2 c 3 d 4