- Python 資料科學教程
- Python 資料科學 - 主頁
- Python 資料科學 - 入門
- Python 資料科學 - 環境設定
- Python 資料科學 - Pandas
- Python 資料科學 - NumPy
- Python 資料科學 - SciPy
- Python 資料科學 - Matplotlib
- Python 資料處理
- Python 資料操作
- Python 資料清理
- Python 處理 CSV 資料
- Python 處理 JSON 資料
- Python 處理 XLS 資料
- Python 關係型資料庫
- Python 非關係型資料庫
- Python 日期和時間
- Python 資料整理
- Python 資料聚合
- Python 閱讀 HTML 頁面
- Python 處理非結構化資料
- Python 詞語標記化
- Python 詞幹提取和詞形還原
- Python 資料視覺化
- Python 圖表屬性
- Python 圖表樣式
- Python 箱式圖
- Python 熱力圖
- Python 散點圖
- Python 氣泡圖
- Python 三維圖
- Python 時間序列
- Python 地理資料
- Python 圖表資料
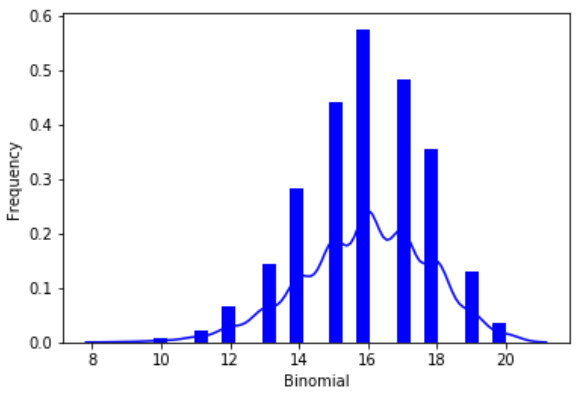
Python - 二項分佈
二項分佈模型用於找出在一個實驗系列中,僅有兩種可能結果的事件的成功機率。例如,拋擲一枚硬幣總是得到正面或反面。在二項分佈中,對一枚硬幣重複拋擲 10 次後恰好得到 3 次正面的機率會被估計出來。
我們使用內建了函式來建立此類機率分佈圖的海伯恩 Python 庫。此外,scipy 包有助於建立二項分佈。
from scipy.stats import binom
import seaborn as sb
binom.rvs(size=10,n=20,p=0.8)
data_binom = binom.rvs(n=20,p=0.8,loc=0,size=1000)
ax = sb.distplot(data_binom,
kde=True,
color='blue',
hist_kws={"linewidth": 25,'alpha':1})
ax.set(xlabel='Binomial', ylabel='Frequency')
其輸出如下 -
廣告