- Python機器學習
- 首頁
- 基礎
- Python 生態系統
- 機器學習方法
- 機器學習專案的資料載入
- 用統計學理解資料
- 用視覺化理解資料
- 資料準備
- 資料特徵選擇
- 機器學習演算法 - 分類
- 介紹
- 邏輯迴歸
- 支援向量機 (SVM)
- 決策樹
- 樸素貝葉斯
- 隨機森林
- 機器學習演算法 - 迴歸
- 隨機森林
- 線性迴歸
- 機器學習演算法 - 聚類
- 概述
- K均值演算法
- 均值漂移演算法
- 層次聚類
- 機器學習演算法 - KNN演算法
- 尋找最近鄰
- 效能指標
- 自動化工作流
- 改進機器學習模型的效能
- 改進機器學習模型的效能(續…)
- Python機器學習 - 資源
- Python機器學習快速指南
- Python機器學習 - 資源
- Python機器學習 - 討論
Python機器學習快速指南
Python機器學習 - 基礎
我們正生活在“資料時代”,這個時代擁有更強大的計算能力和更多的儲存資源。這些資料或資訊日益增長,但真正的挑戰在於如何理解所有這些資料。企業和組織正試圖透過利用資料科學、資料探勘和機器學習的概念和方法構建智慧系統來應對這一挑戰。其中,機器學習是計算機科學中最令人興奮的領域之一。如果我們稱機器學習為提供資料意義的演算法的應用和科學,那也並不為過。
什麼是機器學習?
機器學習 (ML) 是計算機科學的一個領域,藉助它,計算機系統可以像人類一樣理解資料。
簡單來說,ML 是一種人工智慧,它透過使用演算法或方法從原始資料中提取模式。ML 的主要目標是讓計算機系統從經驗中學習,而無需明確的程式設計或人工干預。
機器學習的必要性
目前,人類是地球上最聰明、最先進的物種,因為他們能夠思考、評估和解決複雜問題。另一方面,人工智慧仍處於起步階段,在許多方面尚未超越人類智慧。那麼問題是,為什麼要讓機器學習呢?最合適的理由是,“基於資料,高效且大規模地做出決策”。
最近,組織正在大量投資於人工智慧、機器學習和深度學習等新技術,以獲取資料中的關鍵資訊,執行各種現實世界的任務和解決問題。我們可以稱之為機器做出的資料驅動決策,特別是自動化流程。這些資料驅動決策可以用於解決那些無法透過程式設計邏輯固有解決的問題,而不是使用程式設計邏輯。事實是我們離不開人類智慧,但另一方面,我們都需要高效且大規模地解決現實世界中的問題。這就是機器學習需求產生的原因。
為什麼以及何時讓機器學習?
我們已經討論了機器學習的必要性,但另一個問題隨之而來,在哪些情況下我們必須讓機器學習?在許多情況下,我們需要機器高效且大規模地做出資料驅動決策。以下是一些讓機器學習更有效的情況:
缺乏人類專業知識
我們希望機器學習並做出資料驅動決策的第一個場景可能是缺乏人類專業知識的領域。例如,在未知區域或太空行星中導航。
動態場景
有些場景本質上是動態的,即它們會隨著時間推移而不斷變化。對於這些場景和行為,我們希望機器學習並做出資料驅動決策。例如,組織中的網路連線和基礎設施可用性。
難以將專業知識轉化為計算任務
在許多領域,人類都擁有自己的專業知識,但他們無法將這些專業知識轉化為計算任務。在這種情況下,我們需要機器學習。例如,語音識別、認知任務等領域。
機器學習模型
在討論機器學習模型之前,我們需要理解米切爾教授給出的以下關於ML的正式定義:
“如果一個計算機程式在某些任務類別 T 中的效能,由效能度量 P 來衡量,隨著經驗 E 的積累而提高,則稱該計算機程式從經驗 E 中學習關於任務類別 T 的知識。”
上述定義主要關注三個引數,也是任何學習演算法的主要組成部分,即任務 (T)、效能 (P) 和經驗 (E)。在這種情況下,我們可以將此定義簡化為:
ML 是人工智慧的一個領域,它包含以下學習演算法:
提高它們的效能 (P)
在執行某些任務 (T) 方面
隨著時間的推移,積累經驗 (E)
基於以上內容,下圖表示機器學習模型:

現在讓我們更詳細地討論它們:
任務 (T)
從問題的角度來看,我們可以將任務 T 定義為要解決的現實世界問題。這個問題可以是任何事情,例如在特定位置找到最佳房屋價格或找到最佳營銷策略等。另一方面,如果我們談論機器學習,任務的定義是不同的,因為很難透過傳統的程式設計方法來解決基於ML的任務。
當任務 T 基於流程並且系統必須遵循的操作資料點時,則稱其為基於ML的任務。基於ML的任務示例包括分類、迴歸、結構化標註、聚類、轉錄等。
經驗 (E)
顧名思義,它是從提供給演算法或模型的資料點中獲得的知識。一旦提供了資料集,模型將迭代執行並學習一些內在模式。由此獲得的學習稱為經驗 (E)。以人類學習為例,我們可以將其視為人類從各種屬性(如情況、關係等)中學習或獲得經驗的情況。監督學習、無監督學習和強化學習是學習或獲得經驗的一些方法。我們的ML模型或演算法獲得的經驗將用於解決任務 T。
效能 (P)
ML演算法應該隨著時間的推移執行任務並積累經驗。衡量ML演算法是否按預期執行的指標是其效能 (P)。P 本質上是一個定量指標,它說明模型如何使用其經驗 E 來執行任務 T。有很多指標可以幫助理解ML效能,例如準確率得分、F1得分、混淆矩陣、精確率、召回率、靈敏度等。
機器學習的挑戰
雖然機器學習正在快速發展,並在網路安全和自動駕駛汽車方面取得重大進步,但作為整體的人工智慧領域仍有很長的路要走。其原因在於ML尚未克服許多挑戰。ML目前面臨的挑戰包括:
資料質量 - 為ML演算法提供高質量的資料是最大的挑戰之一。使用低質量資料會導致與資料預處理和特徵提取相關的問題。
耗時的任務 - ML模型面臨的另一個挑戰是耗費時間,尤其是在資料採集、特徵提取和檢索方面。
缺乏專業人員 - 由於ML技術仍處於起步階段,因此獲得專家資源是一項艱鉅的任務。
缺乏明確的業務問題制定目標 - 缺乏明確的目標和明確定義的業務問題目標是ML面臨的另一個關鍵挑戰,因為這項技術尚未成熟。
過擬合和欠擬合問題 - 如果模型過擬合或欠擬合,則無法很好地表示該問題。
維度災難 - ML模型面臨的另一個挑戰是資料點具有過多的特徵。這可能是一個真正的障礙。
部署困難 - ML模型的複雜性使其難以在現實生活中部署。
機器學習的應用
機器學習是發展最快的技術之一,根據研究人員的說法,我們正處於人工智慧和ML的黃金時代。它用於解決許多傳統方法無法解決的現實世界中的複雜問題。以下是ML的一些現實世界應用:
情感分析
情緒分析
錯誤檢測和預防
天氣預報和預測
股票市場分析和預測
語音合成
語音識別
客戶細分
物體識別
欺詐檢測
欺詐預防
在網上購物中向客戶推薦產品。
Python機器學習 - 生態系統
Python簡介
Python 是一種流行的面向物件程式語言,具有高階程式語言的功能。它易於學習的語法和可移植性使其在如今廣受歡迎。以下事實向我們介紹了 Python:
Python 由荷蘭 Stichting Mathematisch Centrum 的 Guido van Rossum 開發。
它被編寫為名為“ABC”的程式語言的後繼者。
它的第一個版本於 1991 年釋出。
Guido van Rossum 從名為 Monty Python's Flying Circus 的電視節目中選擇了 Python 這個名字。
它是一種開源程式語言,這意味著我們可以免費下載它並使用它來開發程式。它可以從 www.python.org下載。
Python 程式語言兼具 Java 和 C 的特性。它擁有優雅的“C”程式碼,另一方面,它像 Java 一樣擁有用於面向物件程式設計的類和物件。
它是一種解釋型語言,這意味著 Python 程式的原始碼將首先被轉換為位元組碼,然後由 Python 虛擬機器執行。
Python 的優缺點
每種程式語言都有其優點和缺點,Python 也不例外。
優點
根據研究和調查,Python 是第五重要的語言,也是機器學習和資料科學中最流行的語言。這是因為 Python 具有以下優點:
易於學習和理解 - Python 的語法更簡單,因此即使是初學者也很容易學習和理解這門語言。
多用途語言 - Python 是一種多用途程式語言,因為它支援結構化程式設計、面向物件程式設計以及函數語言程式設計。
大量的模組 - Python 擁有大量模組,涵蓋了程式設計的各個方面。這些模組易於使用,因此 Python 成為一種可擴充套件的語言。
開源社群的支援 - 作為開源程式語言,Python 受到了非常龐大的開發者社群的支援。因此,Python 社群可以輕鬆修復 bug。此特性使 Python 非常強大且適應性強。
可擴充套件性 - Python 是一種可擴充套件的程式語言,因為它提供了一種比 shell 指令碼更完善的結構來支援大型程式。
缺點
儘管 Python 是一種流行且強大的程式語言,但它也存在執行速度慢的缺點。
與編譯型語言相比,Python 的執行速度較慢,因為 Python 是一種解釋型語言。這可能是 Python 社群改進的主要方向。
安裝 Python
要使用 Python,我們首先必須安裝它。您可以透過以下兩種方式之一安裝 Python:
單獨安裝 Python
使用預打包的 Python 發行版 - Anaconda
讓我們詳細討論一下這些方法。
單獨安裝 Python
如果要在您的計算機上安裝 Python,則只需要下載適用於您平臺的二進位制程式碼即可。Python 發行版適用於 Windows、Linux 和 Mac 平臺。
以下是上述平臺上安裝 Python 的快速概述:
在 Unix 和 Linux 平臺上
藉助以下步驟,我們可以在 Unix 和 Linux 平臺上安裝 Python:
接下來,點選連結下載適用於 Unix/Linux 的壓縮原始碼。
現在,下載並解壓檔案。
接下來,如果要自定義某些選項,可以編輯 Modules/Setup 檔案。
接下來,執行命令 ./configure 指令碼
make
make install
在 Windows 平臺上
藉助以下步驟,我們可以在 Windows 平臺上安裝 Python:
接下來,點選 Windows 安裝程式 python-XYZ.msi 檔案的連結。這裡的 XYZ 是我們想要安裝的版本。
現在,我們必須執行下載的檔案。它將帶我們進入 Python 安裝嚮導,該向導易於使用。現在,接受預設設定並等待安裝完成。
在 Macintosh 平臺上
對於 Mac OS X,建議使用 Homebrew(一個很棒且易於使用的軟體包安裝程式)來安裝 Python 3。如果您沒有 Homebrew,可以使用以下命令安裝它:
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
可以使用以下命令更新它:
$ brew update
現在,要在系統上安裝 Python3,我們需要執行以下命令:
$ brew install python3
使用預打包的 Python 發行版:Anaconda
Anaconda 是 Python 的打包編譯版本,其中包含資料科學中廣泛使用的所有庫。我們可以按照以下步驟使用 Anaconda 設定 Python 環境:
步驟 1 - 首先,我們需要從 Anaconda 發行版下載所需的安裝包。連結為 https://www.anaconda.com/distribution/。您可以根據需要選擇 Windows、Mac 和 Linux 作業系統。
步驟 2 - 接下來,選擇要在機器上安裝的 Python 版本。最新的 Python 版本是 3.7。您將獲得 64 位和 32 點陣圖形安裝程式的選項。
步驟 3 - 選擇作業系統和 Python 版本後,它將下載 Anaconda 安裝程式到您的計算機上。現在,雙擊該檔案,安裝程式將安裝 Anaconda 包。
步驟 4 - 要檢查它是否已安裝,請開啟命令提示符並鍵入 Python,如下所示:

您還可以觀看以下詳細的影片講座:https://tutorialspoint.tw/python_essentials_online_training/getting_started_with_anaconda.asp。
為什麼選擇 Python 用於資料科學?
Python 是第五大最重要的語言,也是機器學習和資料科學中最流行的語言。以下是一些使 Python 成為資料科學首選語言的功能:
豐富的軟體包集
Python 擁有一個廣泛而強大的軟體包集,可用於各個領域。它還擁有 numpy、scipy、pandas、scikit-learn 等機器學習和資料科學所需的軟體包。
易於原型設計
Python 的另一個重要特性是易於快速原型設計,這使得它成為資料科學的首選語言。此功能有助於開發新演算法。
協作功能
資料科學領域基本上需要良好的協作,而 Python 提供了許多有用的工具,使協作變得極其簡單。
一門語言,多個領域
典型的資料科學專案包含資料提取、資料處理、資料分析、特徵提取、建模、評估、部署和更新解決方案等各個領域。由於 Python 是一種多用途語言,它允許資料科學家從一個通用平臺解決所有這些領域的問題。
Python ML 生態系統的元件
在本節中,讓我們討論一些構成 Python 機器學習生態系統元件的核心資料科學庫。這些有用的元件使 Python 成為一門重要的資料科學語言。儘管有許多這樣的元件,但讓我們在此處討論一些 Python 生態系統的重要元件:
Jupyter Notebook
Jupyter Notebook 主要為開發基於 Python 的資料科學應用程式提供了一個互動式計算環境。它們以前被稱為 ipython notebook。以下是一些使 Jupyter Notebook 成為 Python ML 生態系統最佳元件之一的功能:
Jupyter Notebook 可以透過以逐步的方式排列程式碼、影像、文字、輸出等內容,逐步說明分析過程。
它有助於資料科學家在開發分析過程時記錄思維過程。
還可以將結果作為筆記本的一部分捕獲。
藉助 Jupyter Notebook,我們還可以與同行共享我們的工作。
安裝和執行
如果您使用的是 Anaconda 發行版,則無需單獨安裝 Jupyter Notebook,因為它已隨發行版一起安裝。您只需要轉到 Anaconda Prompt 並鍵入以下命令:
C:\>jupyter notebook
按 Enter 鍵後,它將在計算機的 localhost:8888 上啟動一個筆記本伺服器。如下面的螢幕截圖所示:

現在,點選“新建”選項卡後,您將獲得一系列選項。選擇 Python 3,它將帶您進入新的筆記本,以便開始在其中工作。您將在以下螢幕截圖中看到它的概覽:
另一方面,如果您使用的是標準 Python 發行版,則可以使用流行的 Python 軟體包安裝程式 pip 安裝 Jupyter Notebook。
pip install jupyter
Jupyter Notebook 中的單元格型別
Jupyter Notebook 中有三種類型的單元格:
程式碼單元格 - 顧名思義,我們可以使用這些單元格編寫程式碼。編寫程式碼/內容後,它會將其傳送到與筆記本關聯的核心。
Markdown 單元格 - 我們可以使用這些單元格記錄計算過程。它們可以包含文字、影像、Latex 公式、HTML 標籤等內容。
原始單元格 - 其中編寫的文字按原樣顯示。這些單元格主要用於新增我們不希望 Jupyter Notebook 的自動轉換機制進行轉換的文字。
要更詳細地學習 Jupyter Notebook,您可以訪問以下連結:https://tutorialspoint.tw/jupyter/index.htm。
NumPy
它是另一個有用的元件,使 Python 成為資料科學中最受歡迎的語言之一。它基本上代表 Numerical Python,包含多維陣列物件。透過使用 NumPy,我們可以執行以下重要操作:
陣列上的數學和邏輯運算。
傅立葉變換
與線性代數相關的運算。
我們還可以將 NumPy 視為 MatLab 的替代品,因為 NumPy 通常與 Scipy(科學 Python)和 Mat-plotlib(繪相簿)一起使用。
安裝和執行
如果您使用的是 Anaconda 發行版,則無需單獨安裝 NumPy,因為它已隨發行版一起安裝。您只需要使用以下方法將軟體包匯入 Python 指令碼:
import numpy as np
另一方面,如果您使用的是標準 Python 發行版,則可以使用流行的 Python 軟體包安裝程式 pip 安裝 NumPy。
pip install NumPy
要更詳細地學習 NumPy,您可以訪問以下連結: https://tutorialspoint.tw/numpy/index.htm。
Pandas
它是另一個有用的 Python 庫,使 Python 成為資料科學中最受歡迎的語言之一。Pandas 主要用於資料處理、整理和分析。它由 Wes McKinney 於 2008 年開發。藉助 Pandas,在資料處理中,我們可以完成以下五個步驟:
載入
準備
操作
建模
分析
Pandas 中的資料表示
Pandas 中的資料表示完全藉助以下三種資料結構完成:
序列 - 它基本上是一個具有軸標籤的一維 ndarray,這意味著它就像一個具有同類資料的簡單陣列。例如,以下序列是整數 1、5、10、15、24、25…的集合。
| 1 | 5 | 10 | 15 | 24 | 25 | 28 | 36 | 40 | 89 |
資料框 - 它是最有用的資料結構,用於 Pandas 中幾乎所有型別的資料表示和操作。它基本上是一個二維資料結構,可以包含異類資料。通常,表格資料使用資料框表示。例如,下表顯示了學生的姓名、學號、年齡和性別資料:
姓名 |
學號 |
年齡 |
性別 |
|---|---|---|---|
Aarav |
1 |
15 |
男 |
Harshit |
2 |
14 |
男 |
Kanika |
3 |
16 |
女 |
Mayank |
4 |
15 |
男 |
面板 - 它是一個包含異類資料的 3 維資料結構。用圖形表示面板非常困難,但可以將其說明為 DataFrame 的容器。
下表提供了有關 Pandas 中使用的上述資料結構的維度和描述:
資料結構 |
維度 |
描述 |
|---|---|---|
序列 |
1-D |
大小不可變,1-D 同類資料 |
資料框 |
2-D |
大小可變,表格形式的異類資料 |
面板 |
3-D |
大小可變的陣列,DataFrame 的容器。 |
我們可以將這些資料結構理解為更高維的資料結構是較低維資料結構的容器。
安裝和執行
如果您使用的是 Anaconda 發行版,則無需單獨安裝 Pandas,因為它已隨發行版一起安裝。您只需要使用以下方法將軟體包匯入 Python 指令碼:
import pandas as pd
另一方面,如果您使用的是標準 Python 發行版,則可以使用流行的 Python 軟體包安裝程式 pip 安裝 Pandas。
pip install Pandas
安裝 Pandas 後,您可以將其匯入 Python 指令碼,如上所述。
示例
以下是使用 Pandas 從 ndarray 建立序列的示例:
In [1]: import pandas as pd In [2]: import numpy as np In [3]: data = np.array(['g','a','u','r','a','v']) In [4]: s = pd.Series(data) In [5]: print (s) 0 g 1 a 2 u 3 r 4 a 5 v dtype: object
要更詳細地學習 Pandas,您可以訪問以下連結:https://tutorialspoint.tw/python_pandas/index.htm。
Scikit-learn
另一個有用且最重要的 Python 資料科學和機器學習庫是 Scikit-learn。以下是一些使 Scikit-learn 如此有用的特性:
它建立在 NumPy、SciPy 和 Matplotlib 之上。
它是開源的,可以在 BSD 許可下重用。
每個人都可以訪問它,並且可以在各種環境中重用。
藉助它,可以實現涵蓋機器學習主要領域的多種機器學習演算法,例如分類、聚類、迴歸、降維、模型選擇等。
安裝和執行
如果您使用的是Anaconda發行版,則無需單獨安裝Scikit-learn,因為它已經隨Anaconda一起安裝。您只需要在Python指令碼中使用該包即可。例如,使用以下指令碼行,我們從Scikit-learn匯入乳腺癌患者的資料集:
from sklearn.datasets import load_breast_cancer
另一方面,如果您使用的是標準Python發行版並且擁有NumPy和SciPy,則可以使用流行的Python包安裝程式pip安裝Scikit-learn。
pip install -U scikit-learn
安裝Scikit-learn後,您可以像上面所做的那樣在Python指令碼中使用它。
Python機器學習 - 方法
有多種機器學習演算法、技術和方法可用於構建模型,透過使用資料解決現實生活中的問題。在本章中,我們將討論這些不同型別的方法。
不同型別的方法
以下是基於一些廣泛類別的各種機器學習方法:
基於人工監督
在學習過程中,一些基於人工監督的方法如下:
監督學習
監督學習演算法或方法是最常用的機器學習演算法。此方法或學習演算法在訓練過程中獲取資料樣本(即訓練資料)及其關聯的輸出(即標籤或響應),每個資料樣本都帶有相應的輸出。
監督學習演算法的主要目標是在執行多個訓練資料例項後,學習輸入資料樣本和相應輸出之間的關聯。
例如,我們有
x:輸入變數和
Y:輸出變數
現在,應用演算法學習從輸入到輸出的對映函式,如下所示:
Y=f(x)
現在,主要目標將是很好地逼近對映函式,以便即使當我們有新的輸入資料(x)時,我們也可以輕鬆地預測該新輸入資料的輸出變數(Y)。
之所以稱為監督學習,是因為整個學習過程可以被認為是在老師或監督者的監督下進行的。監督機器學習演算法的示例包括決策樹、隨機森林、KNN、邏輯迴歸等。
基於機器學習任務,監督學習演算法可以分為以下兩大類:
分類
迴歸
分類
基於分類的任務的關鍵目標是針對給定的輸入資料預測類別輸出標籤或響應。輸出將基於模型在訓練階段學到的內容。眾所周知,類別輸出響應意味著無序和離散值,因此每個輸出響應都屬於特定的類或類別。我們還將在後續章節中詳細討論分類和相關演算法。
迴歸
基於迴歸的任務的關鍵目標是針對給定的輸入資料預測輸出標籤或響應,這些標籤或響應是連續的數值。輸出將基於模型在訓練階段學到的內容。基本上,迴歸模型使用輸入資料特徵(自變數)及其相應的連續數值輸出值(因變數或結果變數)來學習輸入和相應輸出之間的特定關聯。我們還將在後續章節中詳細討論迴歸和相關演算法。
無監督學習
顧名思義,它與監督機器學習方法或演算法相反,這意味著在無監督機器學習演算法中,我們沒有任何監督者提供任何形式的指導。在沒有像監督學習演算法那樣擁有預先標記的訓練資料的自由,並且我們想要從輸入資料中提取有用模式的情況下,無監督學習演算法非常實用。
例如,可以理解為:
假設我們有:
x:輸入變數,那麼將沒有相應的輸出變數,演算法需要發現數據中的有趣模式以進行學習。
無監督機器學習演算法的示例包括K均值聚類、K最近鄰等。
基於機器學習任務,無監督學習演算法可以分為以下廣泛類別:
聚類
關聯
降維
聚類
聚類方法是最有用的無監督機器學習方法之一。這些演算法用於查詢資料樣本之間的相似性和關係模式,然後根據特徵將這些樣本聚類到具有相似性的組中。聚類的現實世界示例是根據客戶的購買行為對客戶進行分組。
關聯
另一種有用的無監督機器學習方法是關聯,它用於分析大型資料集以查詢模式,這些模式進一步表示各種專案之間有趣的關係。它也稱為關聯規則挖掘或市場籃分析,主要用於分析客戶的購物模式。
降維
此無監督機器學習方法用於透過選擇一組主要或代表性特徵來減少每個資料樣本的特徵變數數量。這裡出現了一個問題,那就是為什麼我們需要降低維度?其背後的原因是特徵空間複雜性問題,當我們開始從資料樣本中分析和提取數百萬個特徵時,就會出現這種問題。此問題通常稱為“維數災難”。PCA(主成分分析)、K最近鄰和判別分析是用於此目的的一些流行演算法。
異常檢測
此無監督機器學習方法用於找出通常不會發生的罕見事件或觀察結果的發生情況。透過使用學習到的知識,異常檢測方法能夠區分異常資料點或正常資料點。一些無監督演算法(如聚類、KNN)可以根據資料及其特徵檢測異常。
半監督學習
此類演算法或方法既不是完全監督的,也不是完全無監督的。它們基本上介於兩者之間,即監督學習方法和無監督學習方法。這些型別的演算法通常使用少量監督學習元件(即少量預先標記的註釋資料)和大量無監督學習元件(即大量未標記資料)進行訓練。我們可以遵循以下任何一種方法來實現半監督學習方法:
第一種簡單的方法是基於少量標記和註釋資料構建監督模型,然後透過將其應用於大量未標記資料來構建無監督模型以獲得更多標記樣本。現在,在它們上訓練模型並重復此過程。
- ,p>第二種方法需要一些額外的努力。在這種方法中,我們可以首先使用無監督方法對相似的資料樣本進行聚類,註釋這些組,然後使用此資訊的組合來訓練模型。
強化學習
這些方法不同於之前研究的方法,而且很少使用。在這種型別的學習演算法中,將有一個代理,我們希望對其進行一段時間訓練,以便它可以與特定環境互動。代理將遵循一組與環境互動的策略,然後在觀察環境後,它將根據環境的當前狀態採取行動。強化學習方法的主要步驟如下:
步驟1 - 首先,我們需要為代理準備一些初始策略集。
步驟2 - 然後觀察環境及其當前狀態。
步驟3 - 接下來,根據環境的當前狀態選擇最佳策略並執行重要操作。
步驟4 - 現在,代理可以根據其在上一步驟中採取的操作獲得相應的獎勵或懲罰。
步驟5 - 現在,如果需要,我們可以更新策略。
步驟6 - 最後,重複步驟 2-5,直到代理學會並採用最佳策略。
適合機器學習的任務
下圖顯示了哪種型別的任務適合各種機器學習問題:

基於學習能力
在學習過程中,以下是一些基於學習能力的方法:
批次學習
在許多情況下,我們有端到端的機器學習系統,我們需要使用所有可用的訓練資料一次性訓練模型。這種型別的學習方法或演算法稱為批次學習或離線學習。之所以稱為批次學習或離線學習,是因為它是一個一次性過程,模型將使用資料在一個批次中進行訓練。以下是批次學習方法的主要步驟:
步驟1 - 首先,我們需要收集所有訓練資料以開始訓練模型。
步驟2 - 現在,透過一次性提供所有訓練資料來開始模型的訓練。
步驟3 - 接下來,一旦獲得令人滿意的結果/效能,就停止學習/訓練過程。
步驟4 - 最後,將此訓練後的模型部署到生產環境中。在這裡,它將預測新資料樣本的輸出。
線上學習
它與批次學習或離線學習方法完全相反。在這些學習方法中,訓練資料以多個增量批次(稱為小批次)提供給演算法。以下是線上學習方法的主要步驟:
步驟1 - 首先,我們需要收集所有訓練資料以開始訓練模型。
步驟2 - 現在,透過向演算法提供訓練資料的小批次來開始模型的訓練。
步驟3 - 接下來,我們需要以多個增量向演算法提供訓練資料的小批次。
步驟4 - 因為它不會像批次學習那樣停止,因此在以小批次提供所有訓練資料後,還會向其提供新的資料樣本。
步驟5 - 最後,它將根據新的資料樣本持續學習一段時間。
基於泛化方法
在學習過程中,以下是一些基於泛化方法的方法:
基於例項的學習
基於例項的學習方法是一種有用的方法,它透過基於輸入資料進行泛化來構建機器學習模型。它與之前研究的學習方法相反,因為這種型別的學習涉及機器學習系統以及使用原始資料點本身來為較新的資料樣本繪製結果的方法,而無需在訓練資料上構建顯式模型。
簡單來說,基於例項的學習基本上從檢視輸入資料點開始,然後使用相似性度量,它將泛化並預測新的資料點。
基於模型的學習
在基於模型的學習方法中,一個迭代過程發生在基於各種模型引數(稱為超引數)構建的機器學習模型上,其中使用輸入資料來提取特徵。在這種學習中,超引數是根據各種模型驗證技術進行最佳化的。這就是為什麼我們可以說基於模型的學習方法對泛化使用了更傳統的機器學習方法。
機器學習專案的資料載入
假設您想啟動一個機器學習專案,那麼您首先需要什麼最重要的事情?它是我們啟動任何機器學習專案都需要載入的資料。關於資料,機器學習專案中最常見的格式是 CSV(逗號分隔值)。
基本上,CSV 是一種簡單的檔案格式,用於以純文字格式儲存表格資料(數字和文字),例如電子表格。在 Python 中,我們可以透過不同的方式將 CSV 資料載入到中,但在載入 CSV 資料之前,我們必須注意一些事項。
載入 CSV 資料時的注意事項
CSV 資料格式是機器學習資料中最常見的格式,但在將其載入到我們的機器學習專案中時,我們需要注意以下主要事項:
檔案頭
在 CSV 資料檔案中,檔案頭包含每個欄位的資訊。我們必須對檔案頭和資料檔案使用相同的定界符,因為檔案頭指定了如何解釋資料欄位。
以下是必須考慮的與 CSV 檔案頭相關的兩種情況:
情況一:當資料檔案具有檔案頭時 - 如果資料檔案具有檔案頭,它將自動為資料的每一列分配名稱。
情況二:當資料檔案沒有檔案頭時 - 如果資料檔案沒有檔案頭,我們需要手動為資料的每一列分配名稱。
在這兩種情況下,我們都需要明確指定我們的 CSV 檔案是否包含檔案頭。
註釋
任何資料檔案中的註釋都具有其重要性。在 CSV 資料檔案中,註釋由行首的雜湊符號 (#) 表示。在將 CSV 資料載入到機器學習專案中時,我們需要考慮註釋,因為如果我們在檔案中包含註釋,則可能需要指示(取決於我們選擇的載入方法)是否期望這些註釋。
分隔符
在 CSV 資料檔案中,逗號 (,) 字元是標準分隔符。分隔符的作用是分隔欄位中的值。在將 CSV 檔案上傳到機器學習專案時,考慮分隔符的作用非常重要,因為我們也可以使用其他分隔符,例如製表符或空格。但是,如果使用與標準分隔符不同的分隔符,則必須明確指定它。
引號
在 CSV 資料檔案中,雙引號 (“ ”) 標記是預設的引號字元。在將 CSV 檔案上傳到機器學習專案時,考慮引號的作用非常重要,因為我們也可以使用雙引號標記以外的其他引號字元。但是,如果使用與標準引號字元不同的引號字元,則必須明確指定它。
載入 CSV 資料檔案的方法
在使用機器學習專案時,最關鍵的任務是將資料正確地載入到其中。機器學習專案中最常見的資料格式是 CSV,它有多種形式,並且解析難度各不相同。在本節中,我們將討論在 Python 中載入 CSV 資料檔案的三種常見方法:
使用 Python 標準庫載入 CSV
載入 CSV 資料檔案的第一種也是最常用的方法是使用 Python 標準庫,它為我們提供了各種內建模組,即 csv 模組和 reader() 函式。以下是使用它載入 CSV 資料檔案的示例:
示例
在這個示例中,我們使用的是鳶尾花資料集,可以將其下載到我們的本地目錄中。載入資料檔案後,我們可以將其轉換為 NumPy 陣列,並在機器學習專案中使用它。以下是載入 CSV 資料檔案的 Python 指令碼:
首先,我們需要匯入 Python 標準庫提供的 csv 模組,如下所示:
import csv
接下來,我們需要匯入 Numpy 模組,以便將載入的資料轉換為 NumPy 陣列。
import numpy as np
現在,提供儲存在我們本地目錄中的包含 CSV 資料檔案的檔案的完整路徑:
path = r"c:\iris.csv"
接下來,使用 csv.reader() 函式從 CSV 檔案讀取資料:
with open(path,'r') as f: reader = csv.reader(f,delimiter = ',') headers = next(reader) data = list(reader) data = np.array(data).astype(float)
我們可以使用以下指令碼行列印標題的名稱:
print(headers)
以下指令碼行將列印資料的形狀,即檔案中的行數和列數:
print(data.shape)
下一個指令碼行將給出資料檔案的前三行:
print(data[:3])
輸出
['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] (150, 4) [ [5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2]]
使用 NumPy 載入 CSV
載入 CSV 資料檔案的另一種方法是 NumPy 和 numpy.loadtxt() 函式。以下是使用它載入 CSV 資料檔案的示例:
示例
在這個示例中,我們使用的是 Pima 印第安人資料集,其中包含糖尿病患者的資料。此資料集是一個沒有標題的數字資料集。它也可以下載到我們的本地目錄中。載入資料檔案後,我們可以將其轉換為 NumPy 陣列,並在機器學習專案中使用它。以下是載入 CSV 資料檔案的 Python 指令碼:
from numpy import loadtxt path = r"C:\pima-indians-diabetes.csv" datapath= open(path, 'r') data = loadtxt(datapath, delimiter=",") print(data.shape) print(data[:3])
輸出
(768, 9) [ [ 6. 148. 72. 35. 0. 33.6 0.627 50. 1.] [ 1. 85. 66. 29. 0. 26.6 0.351 31. 0.] [ 8. 183. 64. 0. 0. 23.3 0.672 32. 1.]]
使用 Pandas 載入 CSV
載入 CSV 資料檔案的另一種方法是使用 Pandas 和 pandas.read_csv() 函式。這是一個非常靈活的函式,它返回一個 pandas.DataFrame,可以立即用於繪圖。以下是使用它載入 CSV 資料檔案的示例:
示例
在這裡,我們將實現兩個 Python 指令碼,第一個是使用包含標題的鳶尾花資料集,另一個是使用 Pima 印第安人資料集,這是一個沒有標題的數字資料集。這兩個資料集都可以下載到本地目錄中。
指令碼 1
以下是使用 Pandas 在鳶尾花資料集上載入 CSV 資料檔案的 Python 指令碼:
from pandas import read_csv path = r"C:\iris.csv" data = read_csv(path) print(data.shape) print(data[:3]) Output: (150, 4) sepal_length sepal_width petal_length petal_width 0 5.1 3.5 1.4 0.2 1 4.9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2
指令碼 2
以下是使用 Pandas 在 Pima 印第安人糖尿病資料集上載入 CSV 資料檔案以及提供標題名稱的 Python 指令碼:
from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) print(data.shape) print(data[:3])
輸出
(768, 9) preg plas pres skin test mass pedi age class 0 6 148 72 35 0 33.6 0.627 50 1 1 1 85 66 29 0 26.6 0.351 31 0 2 8 183 64 0 0 23.3 0.672 32 1
透過給定的示例,可以很容易地理解上述三種載入 CSV 資料檔案的方法之間的區別。
機器學習 - 使用統計資料理解資料
介紹
在使用機器學習專案時,我們通常會忽略兩個最重要的部分,即數學和資料。這是因為,我們知道機器學習是一種資料驅動的方法,我們的機器學習模型產生的結果只會與我們提供給它的資料一樣好或一樣壞。
在上一章中,我們討論瞭如何將 CSV 資料上傳到我們的機器學習專案中,但在上傳之前瞭解資料會更好。我們可以透過兩種方式理解資料,即使用統計資料和使用視覺化。
在本章中,我們將藉助以下 Python 程式碼示例,使用統計資料來理解機器學習資料。
檢視原始資料
第一個程式碼示例用於檢視原始資料。檢視原始資料很重要,因為在檢視原始資料後獲得的見解將提高我們更好地預處理以及處理機器學習專案資料的機率。
以下是使用 Pandas DataFrame 的 head() 函式在 Pima 印第安人糖尿病資料集上實現的 Python 指令碼,用於檢視前 50 行以更好地理解它:
示例
from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) print(data.head(50))
輸出
preg plas pres skin test mass pedi age class 0 6 148 72 35 0 33.6 0.627 50 1 1 1 85 66 29 0 26.6 0.351 31 0 2 8 183 64 0 0 23.3 0.672 32 1 3 1 89 66 23 94 28.1 0.167 21 0 4 0 137 40 35 168 43.1 2.288 33 1 5 5 116 74 0 0 25.6 0.201 30 0 6 3 78 50 32 88 31.0 0.248 26 1 7 10 115 0 0 0 35.3 0.134 29 0 8 2 197 70 45 543 30.5 0.158 53 1 9 8 125 96 0 0 0.0 0.232 54 1 10 4 110 92 0 0 37.6 0.191 30 0 11 10 168 74 0 0 38.0 0.537 34 1 12 10 139 80 0 0 27.1 1.441 57 0 13 1 189 60 23 846 30.1 0.398 59 1 14 5 166 72 19 175 25.8 0.587 51 1 15 7 100 0 0 0 30.0 0.484 32 1 16 0 118 84 47 230 45.8 0.551 31 1 17 7 107 74 0 0 29.6 0.254 31 1 18 1 103 30 38 83 43.3 0.183 33 0 19 1 115 70 30 96 34.6 0.529 32 1 20 3 126 88 41 235 39.3 0.704 27 0 21 8 99 84 0 0 35.4 0.388 50 0 22 7 196 90 0 0 39.8 0.451 41 1 23 9 119 80 35 0 29.0 0.263 29 1 24 11 143 94 33 146 36.6 0.254 51 1 25 10 125 70 26 115 31.1 0.205 41 1 26 7 147 76 0 0 39.4 0.257 43 1 27 1 97 66 15 140 23.2 0.487 22 0 28 13 145 82 19 110 22.2 0.245 57 0 29 5 117 92 0 0 34.1 0.337 38 0 30 5 109 75 26 0 36.0 0.546 60 0 31 3 158 76 36 245 31.6 0.851 28 1 32 3 88 58 11 54 24.8 0.267 22 0 33 6 92 92 0 0 19.9 0.188 28 0 34 10 122 78 31 0 27.6 0.512 45 0 35 4 103 60 33 192 24.0 0.966 33 0 36 11 138 76 0 0 33.2 0.420 35 0 37 9 102 76 37 0 32.9 0.665 46 1 38 2 90 68 42 0 38.2 0.503 27 1 39 4 111 72 47 207 37.1 1.390 56 1 40 3 180 64 25 70 34.0 0.271 26 0 41 7 133 84 0 0 40.2 0.696 37 0 42 7 106 92 18 0 22.7 0.235 48 0 43 9 171 110 24 240 45.4 0.721 54 1 44 7 159 64 0 0 27.4 0.294 40 0 45 0 180 66 39 0 42.0 1.893 25 1 46 1 146 56 0 0 29.7 0.564 29 0 47 2 71 70 27 0 28.0 0.586 22 0 48 7 103 66 32 0 39.1 0.344 31 1 49 7 105 0 0 0 0.0 0.305 24 0
從上面的輸出中我們可以觀察到,第一列給出了行號,這對於引用特定觀察結果非常有用。
檢查資料的維度
瞭解機器學習專案有多少資料(以行和列表示)始終是一個好習慣。其背後的原因是:
假設如果我們有太多行和列,那麼執行演算法和訓練模型將需要很長時間。
假設如果我們有太少的行和列,那麼我們將沒有足夠的資料來很好地訓練模型。
以下是透過在 Pandas Data Frame 上列印 shape 屬性實現的 Python 指令碼。我們將對鳶尾花資料集實施它,以獲取其中的總行數和列數。
示例
from pandas import read_csv path = r"C:\iris.csv" data = read_csv(path) print(data.shape)
輸出
(150, 4)
我們可以很容易地從輸出中觀察到,我們將要使用的鳶尾花資料集有 150 行和 4 列。
獲取每個屬性的資料型別
瞭解每個屬性的資料型別是另一個好習慣。其背後的原因是,根據需要,有時我們需要將一種資料型別轉換為另一種資料型別。例如,我們可能需要將字串轉換為浮點數或整數,以表示類別或序數值。我們可以透過檢視原始資料來了解屬性的資料型別,但另一種方法是使用 Pandas DataFrame 的 dtypes 屬性。藉助 dtypes 屬性,我們可以對每個屬性的資料型別進行分類。這可以透過以下 Python 指令碼瞭解:
示例
from pandas import read_csv path = r"C:\iris.csv" data = read_csv(path) print(data.dtypes)
輸出
sepal_length float64 sepal_width float64 petal_length float64 petal_width float64 dtype: object
從上面的輸出中,我們可以很容易地獲取每個屬性的資料型別。
資料的統計摘要
我們已經討論了獲取資料形狀(即行數和列數)的 Python 程式碼示例,但很多時候我們需要檢視該資料形狀之外的摘要。這可以透過 Pandas DataFrame 的 describe() 函式來完成,該函式進一步提供每個資料屬性的以下 8 個統計屬性:
計數
平均值
標準差
最小值
最大值
25%
中位數,即 50%
75%
示例
from pandas import read_csv
from pandas import set_option
path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=names)
set_option('display.width', 100)
set_option('precision', 2)
print(data.shape)
print(data.describe())
輸出
(768, 9)
preg plas pres skin test mass pedi age class
count 768.00 768.00 768.00 768.00 768.00 768.00 768.00 768.00 768.00
mean 3.85 120.89 69.11 20.54 79.80 31.99 0.47 33.24 0.35
std 3.37 31.97 19.36 15.95 115.24 7.88 0.33 11.76 0.48
min 0.00 0.00 0.00 0.00 0.00 0.00 0.08 21.00 0.00
25% 1.00 99.00 62.00 0.00 0.00 27.30 0.24 24.00 0.00
50% 3.00 117.00 72.00 23.00 30.50 32.00 0.37 29.00 0.00
75% 6.00 140.25 80.00 32.00 127.25 36.60 0.63 41.00 1.00
max 17.00 199.00 122.00 99.00 846.00 67.10 2.42 81.00 1.00
從上面的輸出中,我們可以觀察到 Pima 印第安人糖尿病資料集的資料的統計摘要以及資料的形狀。
檢視類別分佈
類別分佈統計在分類問題中非常有用,在這些問題中我們需要了解類別值的平衡。瞭解類別值分佈非常重要,因為如果我們具有高度不平衡的類別分佈(即一個類別的觀察值比其他類別多得多),那麼在機器學習專案的預處理階段可能需要特殊處理。我們可以輕鬆地藉助 Pandas DataFrame 在 Python 中獲取類別分佈。
示例
from pandas import read_csv
path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=names)
count_class = data.groupby('class').size()
print(count_class)
輸出
Class 0 500 1 268 dtype: int64
從上面的輸出中可以清楚地看出,類別為 0 的觀察值數量幾乎是類別為 1 的觀察值數量的兩倍。
檢視屬性之間的相關性
兩個變數之間的關係稱為相關性。在統計學中,計算相關性的最常用方法是皮爾遜相關係數。它可以具有以下三個值:
係數值 = 1 - 它表示變數之間完全正相關。
係數值 = -1 - 它表示變數之間完全負相關。
係數值 = 0 - 它表示變數之間沒有相關性。
在將資料集用於機器學習專案之前,審查其屬性之間的兩兩相關性始終是一個好習慣,因為某些機器學習演算法(例如線性迴歸和邏輯迴歸)在存在高度相關的屬性時效能會很差。在 Python 中,我們可以藉助 Pandas DataFrame 上的 corr() 函式輕鬆計算資料集屬性的相關矩陣。
示例
from pandas import read_csv
from pandas import set_option
path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=names)
set_option('display.width', 100)
set_option('precision', 2)
correlations = data.corr(method='pearson')
print(correlations)
輸出
preg plas pres skin test mass pedi age class preg 1.00 0.13 0.14 -0.08 -0.07 0.02 -0.03 0.54 0.22 plas 0.13 1.00 0.15 0.06 0.33 0.22 0.14 0.26 0.47 pres 0.14 0.15 1.00 0.21 0.09 0.28 0.04 0.24 0.07 skin -0.08 0.06 0.21 1.00 0.44 0.39 0.18 -0.11 0.07 test -0.07 0.33 0.09 0.44 1.00 0.20 0.19 -0.04 0.13 mass 0.02 0.22 0.28 0.39 0.20 1.00 0.14 0.04 0.29 pedi -0.03 0.14 0.04 0.18 0.19 0.14 1.00 0.03 0.17 age 0.54 0.26 0.24 -0.11 -0.04 0.04 0.03 1.00 0.24 class 0.22 0.47 0.07 0.07 0.13 0.29 0.17 0.24 1.00
以上輸出中的矩陣給出了資料集中所有屬性對之間的相關性。
審查屬性分佈的偏度
偏度可以定義為假定為高斯分佈但出現扭曲或向一個方向或另一個方向偏移的分佈,或者向左或向右偏移。審查屬性的偏度是一項重要的任務,原因如下:
資料中存在偏度需要在資料準備階段進行校正,以便我們能夠從模型中獲得更高的準確性。
大多數機器學習演算法假設資料服從高斯分佈,即正態分佈或鐘形曲線資料。
在 Python 中,我們可以使用 Pandas DataFrame 上的 skew() 函式輕鬆計算每個屬性的偏度。
示例
from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=names) print(data.skew())
輸出
preg 0.90 plas 0.17 pres -1.84 skin 0.11 test 2.27 mass -0.43 pedi 1.92 age 1.13 class 0.64 dtype: float64
從以上輸出可以觀察到正偏度或負偏度。如果值接近於零,則表示偏度較小。
機器學習 - 使用視覺化理解資料
介紹
在上一章中,我們討論了資料對於機器學習演算法的重要性,以及一些用於使用統計方法理解資料的 Python 程式碼示例。還有一種方法稱為視覺化,可以用來理解資料。
藉助資料視覺化,我們可以看到資料的形態以及資料屬性之間存在何種相關性。這是檢視特徵是否對應於輸出的最快方法。藉助以下 Python 程式碼示例,我們可以使用統計方法理解機器學習資料。

單變數圖:獨立理解屬性
最簡單的視覺化型別是單變數或“單變數”視覺化。藉助單變數視覺化,我們可以獨立地理解資料集的每個屬性。以下是使用 Python 實現單變數視覺化的一些技術:
直方圖
直方圖將資料分組到若干區間中,是快速瞭解資料集中每個屬性分佈的最有效方法。以下是直方圖的一些特徵:
它為我們提供了每個用於視覺化的區間中觀測值的計數。
從區間的形狀,我們可以輕鬆地觀察分佈,例如它是高斯分佈、偏態分佈還是指數分佈。
直方圖還有助於我們發現可能的異常值。
示例
以下顯示的程式碼是建立皮馬印第安人糖尿病資料集屬性直方圖的 Python 指令碼示例。這裡,我們將使用 Pandas DataFrame 上的 hist() 函式生成直方圖,並使用matplotlib進行繪圖。
from matplotlib import pyplot from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=names) data.hist() pyplot.show()
輸出

以上輸出顯示它為資料集中每個屬性建立了直方圖。由此,我們可以觀察到,年齡、pedi 和 test 屬性可能服從指數分佈,而 mass 和 plas 屬性可能服從高斯分佈。
密度圖
獲取每個屬性分佈的另一種快速簡便的技術是密度圖。它也類似於直方圖,但在每個區間的頂部繪製一條平滑的曲線。我們可以將它們稱為抽象的直方圖。
示例
在以下示例中,Python 指令碼將生成皮馬印第安人糖尿病資料集屬性分佈的密度圖。
from matplotlib import pyplot from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=names) data.plot(kind='density', subplots=True, layout=(3,3), sharex=False) pyplot.show()
輸出

從以上輸出可以輕鬆理解密度圖和直方圖之間的區別。
箱線圖
箱線圖,簡稱箱圖,是另一種用於審查每個屬性分佈的有用技術。以下是此技術的一些特徵:
它本質上是單變數的,並總結了每個屬性的分佈。
它為中間值(即中位數)繪製一條線。
它圍繞 25% 和 75% 繪製一個框。
它還繪製了須線,這將使我們瞭解資料的擴充套件。
須線外部的點表示異常值。異常值將是中間資料擴充套件大小的 1.5 倍。
示例
在以下示例中,Python 指令碼將生成皮馬印第安人糖尿病資料集屬性分佈的密度圖。
from matplotlib import pyplot from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=names) data.plot(kind='box', subplots=True, layout=(3,3), sharex=False,sharey=False) pyplot.show()
輸出

從以上屬性分佈圖可以看出,年齡、test 和 skin 屬性向較小值方向傾斜。
多變數圖:多個變數之間的互動
另一種視覺化型別是多變數或“多變數”視覺化。藉助多變數視覺化,我們可以理解資料集多個屬性之間的互動。以下是使用 Python 實現多變數視覺化的一些技術:
相關矩陣圖
相關性是關於兩個變數之間變化的指示。在我們之前的章節中,我們已經討論了皮爾遜相關係數以及相關性的重要性。我們可以繪製相關矩陣來顯示哪個變數相對於另一個變數具有高相關性或低相關性。
示例
在以下示例中,Python 指令碼將生成並繪製皮馬印第安人糖尿病資料集的相關矩陣。它可以使用 Pandas DataFrame 上的 corr() 函式生成,並使用 pyplot 進行繪圖。
from matplotlib import pyplot from pandas import read_csv import numpy Path = r"C:\pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(Path, names=names) correlations = data.corr() fig = pyplot.figure() ax = fig.add_subplot(111) cax = ax.matshow(correlations, vmin=-1, vmax=1) fig.colorbar(cax) ticks = numpy.arange(0,9,1) ax.set_xticks(ticks) ax.set_yticks(ticks) ax.set_xticklabels(names) ax.set_yticklabels(names) pyplot.show()
輸出
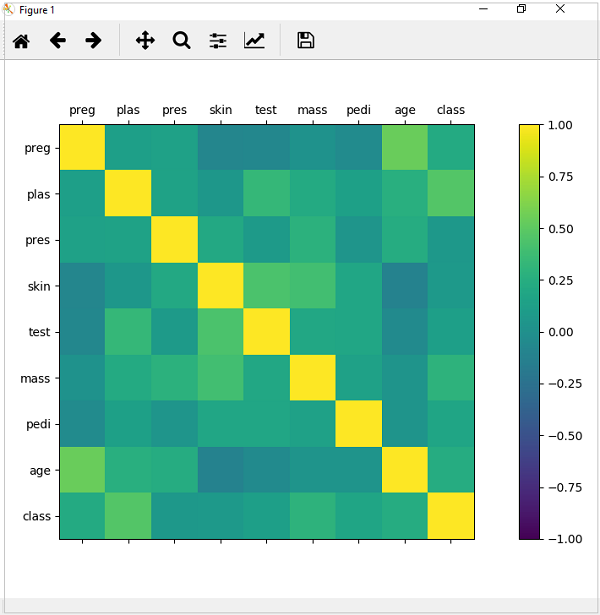
從以上相關矩陣輸出可以看出,它是對稱的,即左下角與右上角相同。還可以觀察到每個變數彼此之間都呈正相關。
散點矩陣圖
散點圖使用二維空間中的點來顯示一個變數受另一個變數影響的程度或它們之間的關係。從概念上講,散點圖非常類似於折線圖,它們使用水平和垂直軸來繪製資料點。
示例
在以下示例中,Python 指令碼將生成並繪製皮馬印第安人糖尿病資料集的散點矩陣。它可以使用 Pandas DataFrame 上的 scatter_matrix() 函式生成,並使用 pyplot 進行繪圖。
from matplotlib import pyplot from pandas import read_csv from pandas.tools.plotting import scatter_matrix path = r"C:\pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=names) scatter_matrix(data) pyplot.show()
輸出

使用 Python 進行機器學習 - 資料準備
介紹
機器學習演算法完全依賴於資料,因為它是使模型訓練成為可能的至關重要的方面。另一方面,如果我們在將資料饋送到機器學習演算法之前無法理解它,那麼機器將毫無用處。簡單來說,我們始終需要饋送正確的資料,即按正確比例、格式幷包含有意義特徵的資料,以解決我們希望機器解決的問題。
這使得資料準備成為機器學習過程中最重要的步驟。資料準備可以定義為使我們的資料集更適合機器學習過程的程式。
為什麼要進行資料預處理?
在選擇用於機器學習訓練的原始資料後,最重要的任務是資料預處理。從廣義上講,資料預處理將把選擇的資料轉換為我們可以處理或可以饋送到機器學習演算法的形式。我們始終需要預處理我們的資料,以便它能夠滿足機器學習演算法的期望。
資料預處理技術
我們有以下資料預處理技術,可以應用於資料集以生成用於機器學習演算法的資料:
縮放
我們的資料集很可能包含具有不同比例的屬性,但我們不能將此類資料提供給機器學習演算法,因此需要進行重新縮放。資料重新縮放確保屬性處於相同的比例。通常,屬性會重新縮放到 0 和 1 的範圍內。像梯度下降和 k 近鄰這樣的機器學習演算法需要縮放後的資料。我們可以使用 scikit-learn Python 庫的 MinMaxScaler 類重新縮放資料。
示例
在此示例中,我們將重新縮放之前使用過的皮馬印第安人糖尿病資料集的資料。首先,將載入 CSV 資料(如前幾章所述),然後藉助 MinMaxScaler 類將其重新縮放到 0 和 1 的範圍內。
以下指令碼的前幾行與我們在前幾章載入 CSV 資料時編寫的相同。
from pandas import read_csv from numpy import set_printoptions from sklearn import preprocessing path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(path, names=names) array = dataframe.values
現在,我們可以使用 MinMaxScaler 類將資料重新縮放到 0 和 1 的範圍內。
data_scaler = preprocessing.MinMaxScaler(feature_range=(0,1)) data_rescaled = data_scaler.fit_transform(array)
我們還可以根據我們的選擇彙總輸出資料。這裡,我們將精度設定為 1 並顯示輸出中的前 10 行。
set_printoptions(precision=1)
print ("\nScaled data:\n", data_rescaled[0:10])
輸出
Scaled data: [[0.4 0.7 0.6 0.4 0. 0.5 0.2 0.5 1. ] [0.1 0.4 0.5 0.3 0. 0.4 0.1 0.2 0. ] [0.5 0.9 0.5 0. 0. 0.3 0.3 0.2 1. ] [0.1 0.4 0.5 0.2 0.1 0.4 0. 0. 0. ] [0. 0.7 0.3 0.4 0.2 0.6 0.9 0.2 1. ] [0.3 0.6 0.6 0. 0. 0.4 0.1 0.2 0. ] [0.2 0.4 0.4 0.3 0.1 0.5 0.1 0.1 1. ] [0.6 0.6 0. 0. 0. 0.5 0. 0.1 0. ] [0.1 1. 0.6 0.5 0.6 0.5 0. 0.5 1. ] [0.5 0.6 0.8 0. 0. 0. 0.1 0.6 1. ]]
從以上輸出可以看出,所有資料都被重新縮放到 0 和 1 的範圍內。
標準化
另一種有用的資料預處理技術是標準化。這用於重新縮放資料的每一行,使其長度為 1。它主要用於稀疏資料集中,在稀疏資料集中我們有很多零。我們可以使用 scikit-learn Python 庫的 Normalizer 類重新縮放資料。
標準化的型別
在機器學習中,有兩種標準化預處理技術,如下所示:
L1 標準化
它可以定義為一種標準化技術,它以這樣一種方式修改資料集的值,即在每一行中,絕對值的總和始終為 1。它也稱為最小絕對偏差。
示例
在此示例中,我們使用 L1 標準化技術來標準化之前使用過的皮馬印第安人糖尿病資料集的資料。首先,將載入 CSV 資料,然後藉助 Normalizer 類對其進行標準化。
以下指令碼的前幾行與我們在前幾章載入 CSV 資料時編寫的相同。
from pandas import read_csv from numpy import set_printoptions from sklearn.preprocessing import Normalizer path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv (path, names=names) array = dataframe.values
現在,我們可以使用帶 L1 的 Normalizer 類來標準化資料。
Data_normalizer = Normalizer(norm='l1').fit(array) Data_normalized = Data_normalizer.transform(array)
我們還可以根據我們的選擇彙總輸出資料。這裡,我們將精度設定為 2 並顯示輸出中的前 3 行。
set_printoptions(precision=2)
print ("\nNormalized data:\n", Data_normalized [0:3])
輸出
Normalized data: [[0.02 0.43 0.21 0.1 0. 0.1 0. 0.14 0. ] [0. 0.36 0.28 0.12 0. 0.11 0. 0.13 0. ] [0.03 0.59 0.21 0. 0. 0.07 0. 0.1 0. ]]
L2 標準化
它可以定義為一種標準化技術,它以這樣一種方式修改資料集的值,即在每一行中,平方和始終為 1。它也稱為最小二乘法。
示例
在此示例中,我們使用 L2 標準化技術來標準化之前使用過的皮馬印第安人糖尿病資料集的資料。首先,將載入 CSV 資料(如前幾章所述),然後藉助 Normalizer 類對其進行標準化。
以下指令碼的前幾行與我們在前幾章載入 CSV 資料時編寫的相同。
from pandas import read_csv from numpy import set_printoptions from sklearn.preprocessing import Normalizer path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv (path, names=names) array = dataframe.values
現在,我們可以使用帶 L1 的 Normalizer 類來標準化資料。
Data_normalizer = Normalizer(norm='l2').fit(array) Data_normalized = Data_normalizer.transform(array)
我們還可以根據我們的選擇彙總輸出資料。這裡,我們將精度設定為 2 並顯示輸出中的前 3 行。
set_printoptions(precision=2)
print ("\nNormalized data:\n", Data_normalized [0:3])
輸出
Normalized data: [[0.03 0.83 0.4 0.2 0. 0.19 0. 0.28 0.01] [0.01 0.72 0.56 0.24 0. 0.22 0. 0.26 0. ] [0.04 0.92 0.32 0. 0. 0.12 0. 0.16 0.01]]
二值化
顧名思義,這是一種我們可以使資料二值化的技術。我們可以使用二值化閾值來使資料二值化。高於該閾值的值將轉換為 1,低於該閾值的值將轉換為 0。例如,如果我們選擇閾值為 0.5,則高於它的資料集值將變為 1,低於它將變為 0。這就是為什麼我們可以稱之為二值化資料或閾值化資料。當我們的資料集中有機率並希望將其轉換為清晰值時,此技術很有用。
我們可以使用 scikit-learn Python 庫的 Binarizer 類對資料進行二值化。
示例
在此示例中,我們將重新縮放之前使用過的皮馬印第安人糖尿病資料集的資料。首先,將載入 CSV 資料,然後藉助 Binarizer 類將其轉換為二值,即 0 和 1,具體取決於閾值。我們取 0.5 作為閾值。
以下指令碼的前幾行與我們在前幾章載入 CSV 資料時編寫的相同。
from pandas import read_csv from sklearn.preprocessing import Binarizer path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(path, names=names) array = dataframe.values
現在,我們可以使用 Binarize 類將資料轉換為二值。
binarizer = Binarizer(threshold=0.5).fit(array) Data_binarized = binarizer.transform(array)
這裡,我們顯示輸出中的前 5 行。
print ("\nBinary data:\n", Data_binarized [0:5])
輸出
Binary data: [[1. 1. 1. 1. 0. 1. 1. 1. 1.] [1. 1. 1. 1. 0. 1. 0. 1. 0.] [1. 1. 1. 0. 0. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1. 0. 1. 0.] [0. 1. 1. 1. 1. 1. 1. 1. 1.]]
標準化
另一種有用的資料預處理技術,主要用於將資料屬性轉換為高斯分佈。它將均值和標準差 (SD) 變換為標準高斯分佈,均值為 0,標準差為 1。這種技術在像線性迴歸、邏輯迴歸這樣的機器學習演算法中很有用,這些演算法假設輸入資料集中存在高斯分佈,並且在重新縮放的資料上產生更好的結果。我們可以藉助 scikit-learn Python 庫的 StandardScaler 類來標準化資料(均值 = 0,標準差 = 1)。
示例
在這個例子中,我們將重新縮放之前使用過的 Pima 印第安人糖尿病資料集的資料。首先,CSV 資料將被載入,然後藉助 StandardScaler 類將其轉換為均值為 0,標準差為 1 的高斯分佈。
以下指令碼的前幾行與我們在前幾章載入 CSV 資料時編寫的相同。
from sklearn.preprocessing import StandardScaler from pandas import read_csv from numpy import set_printoptions path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(path, names=names) array = dataframe.values
現在,我們可以使用 StandardScaler 類來重新縮放資料。
data_scaler = StandardScaler().fit(array) data_rescaled = data_scaler.transform(array)
我們還可以根據自己的選擇彙總輸出資料。這裡,我們將精度設定為 2,並在輸出中顯示前 5 行。
set_printoptions(precision=2)
print ("\nRescaled data:\n", data_rescaled [0:5])
輸出
Rescaled data: [[ 0.64 0.85 0.15 0.91 -0.69 0.2 0.47 1.43 1.37] [-0.84 -1.12 -0.16 0.53 -0.69 -0.68 -0.37 -0.19 -0.73] [ 1.23 1.94 -0.26 -1.29 -0.69 -1.1 0.6 -0.11 1.37] [-0.84 -1. -0.16 0.15 0.12 -0.49 -0.92 -1.04 -0.73] [-1.14 0.5 -1.5 0.91 0.77 1.41 5.48 -0.02 1.37]]
資料標註
我們討論了良好資料對於機器學習演算法的重要性,以及在將資料傳送到機器學習演算法之前預處理資料的一些技術。這方面還有一個方面是資料標註。將具有適當標註的資料傳送到機器學習演算法也非常重要。例如,在分類問題的情況下,資料上存在許多標籤形式的單詞、數字等。
什麼是標籤編碼?
大多數 sklearn 函式期望資料使用數字標籤而不是單詞標籤。因此,我們需要將此類標籤轉換為數字標籤。此過程稱為標籤編碼。我們可以藉助 scikit-learn Python 庫的 LabelEncoder() 函式執行資料的標籤編碼。
示例
在以下示例中,Python 指令碼將執行標籤編碼。
首先,匯入所需的 Python 庫,如下所示:
import numpy as np from sklearn import preprocessing
現在,我們需要提供輸入標籤,如下所示:
input_labels = ['red','black','red','green','black','yellow','white']
下一行程式碼將建立標籤編碼器並對其進行訓練。
encoder = preprocessing.LabelEncoder() encoder.fit(input_labels)
接下來的指令碼行將透過對隨機排序列表進行編碼來檢查效能:
test_labels = ['green','red','black']
encoded_values = encoder.transform(test_labels)
print("\nLabels =", test_labels)
print("Encoded values =", list(encoded_values))
encoded_values = [3,0,4,1]
decoded_list = encoder.inverse_transform(encoded_values)
我們可以藉助以下 Python 指令碼獲取編碼值的列表:
print("\nEncoded values =", encoded_values)
print("\nDecoded labels =", list(decoded_list))
輸出
Labels = ['green', 'red', 'black'] Encoded values = [1, 2, 0] Encoded values = [3, 0, 4, 1] Decoded labels = ['white', 'black', 'yellow', 'green']
Python 機器學習 - 資料特徵選擇
在上一章中,我們詳細瞭解瞭如何預處理和準備機器學習資料。在本章中,讓我們詳細瞭解資料特徵選擇及其涉及的各個方面。
資料特徵選擇的重要性
機器學習模型的效能與其用於訓練它的資料特徵成正比。如果提供給模型的資料特徵不相關,則機器學習模型的效能將受到負面影響。另一方面,使用相關的資料特徵可以提高機器學習模型的準確性,特別是線性迴歸和邏輯迴歸。
現在問題出現了,什麼是自動特徵選擇?它可以定義為一個過程,透過該過程,我們選擇資料中與我們感興趣的輸出或預測變數最相關的特徵。它也稱為屬性選擇。
以下是在資料建模之前自動特徵選擇的一些好處:
在資料建模之前執行特徵選擇將減少過擬合。
在資料建模之前執行特徵選擇將提高機器學習模型的準確性。
在資料建模之前執行特徵選擇將減少訓練時間。
特徵選擇技術
以下是我們可以用於在 Python 中對機器學習資料建模的自動特徵選擇技術:
單變數選擇
這種特徵選擇技術在選擇那些與預測變數具有最強關係的特徵(藉助統計檢驗)方面非常有用。我們可以藉助 scikit-learn Python 庫的 SelectKBest 類實現單變數特徵選擇技術。
示例
在這個例子中,我們將使用 Pima 印第安人糖尿病資料集,藉助卡方統計檢驗選擇 4 個具有最佳特徵的屬性。
from pandas import read_csv from numpy import set_printoptions from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(path, names=names) array = dataframe.values
接下來,我們將陣列分離成輸入和輸出元件:
X = array[:,0:8] Y = array[:,8]
以下程式碼行將從資料集中選擇最佳特徵:
test = SelectKBest(score_func=chi2, k=4) fit = test.fit(X,Y)
我們還可以根據自己的選擇彙總輸出資料。這裡,我們將精度設定為 2,並顯示 4 個具有最佳特徵的資料屬性以及每個屬性的最佳得分:
set_printoptions(precision=2)
print(fit.scores_)
featured_data = fit.transform(X)
print ("\nFeatured data:\n", featured_data[0:4])
輸出
[ 111.52 1411.89 17.61 53.11 2175.57 127.67 5.39 181.3 ] Featured data: [[148. 0. 33.6 50. ] [ 85. 0. 26.6 31. ] [183. 0. 23.3 32. ] [ 89. 94. 28.1 21. ]]
遞迴特徵消除
顧名思義,RFE(遞迴特徵消除)特徵選擇技術遞迴地移除屬性,並使用剩餘屬性構建模型。我們可以藉助 scikit-learn Python 庫的 RFE 類實現 RFE 特徵選擇技術。
示例
在這個例子中,我們將使用 RFE 和邏輯迴歸演算法從 Pima 印第安人糖尿病資料集中選擇具有最佳特徵的 3 個最佳屬性。
from pandas import read_csv from sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(path, names=names) array = dataframe.values
接下來,我們將陣列分離成其輸入和輸出元件:
X = array[:,0:8] Y = array[:,8]
以下程式碼行將從資料集中選擇最佳特徵:
model = LogisticRegression()
rfe = RFE(model, 3)
fit = rfe.fit(X, Y)
print("Number of Features: %d")
print("Selected Features: %s")
print("Feature Ranking: %s")
輸出
Number of Features: 3 Selected Features: [ True False False False False True True False] Feature Ranking: [1 2 3 5 6 1 1 4]
我們可以在上面的輸出中看到,RFE 選擇 preg、mass 和 pedi 作為前 3 個最佳特徵。它們在輸出中標記為 1。
主成分分析 (PCA)
PCA,通常稱為資料縮減技術,是一種非常有用的特徵選擇技術,因為它使用線性代數將資料集轉換為壓縮形式。我們可以藉助 scikit-learn Python 庫的 PCA 類實現 PCA 特徵選擇技術。我們可以選擇輸出中的主成分數量。
示例
在這個例子中,我們將使用 PCA 從 Pima 印第安人糖尿病資料集中選擇 3 個最佳主成分。
from pandas import read_csv from sklearn.decomposition import PCA path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(path, names=names) array = dataframe.values
接下來,我們將陣列分離成輸入和輸出元件:
X = array[:,0:8] Y = array[:,8]
以下程式碼行將從資料集中提取特徵:
pca = PCA(n_components=3)
fit = pca.fit(X)
print("Explained Variance: %s") % fit.explained_variance_ratio_
print(fit.components_)
輸出
Explained Variance: [ 0.88854663 0.06159078 0.02579012] [[ -2.02176587e-03 9.78115765e-02 1.60930503e-02 6.07566861e-02 9.93110844e-01 1.40108085e-02 5.37167919e-04 -3.56474430e-03] [ 2.26488861e-02 9.72210040e-01 1.41909330e-01 -5.78614699e-02 -9.46266913e-02 4.69729766e-02 8.16804621e-04 1.40168181e-01] [ -2.24649003e-02 1.43428710e-01 -9.22467192e-01 -3.07013055e-01 2.09773019e-02 -1.32444542e-01 -6.39983017e-04 -1.25454310e-01]]
我們可以從上面的輸出中觀察到,3 個主成分與源資料幾乎沒有相似之處。
特徵重要性
顧名思義,特徵重要性技術用於選擇重要特徵。它基本上使用經過訓練的監督分類器來選擇特徵。我們可以藉助 scikit-learn Python 庫的 ExtraTreeClassifier 類實現這種特徵選擇技術。
示例
在這個例子中,我們將使用 ExtraTreeClassifier 從 Pima 印第安人糖尿病資料集中選擇特徵。
from pandas import read_csv from sklearn.ensemble import ExtraTreesClassifier path = r'C:\Desktop\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(data, names=names) array = dataframe.values
接下來,我們將陣列分離成輸入和輸出元件:
X = array[:,0:8] Y = array[:,8]
以下程式碼行將從資料集中提取特徵:
model = ExtraTreesClassifier() model.fit(X, Y) print(model.feature_importances_)
輸出
[ 0.11070069 0.2213717 0.08824115 0.08068703 0.07281761 0.14548537 0.12654214 0.15415431]
從輸出中,我們可以觀察到每個屬性都有分數。分數越高,該屬性的重要性越高。
分類 - 簡介
分類簡介
分類可以定義為根據觀察值或給定資料點預測類別或類別的過程。分類輸出可以採用“黑色”或“白色”或“垃圾郵件”或“非垃圾郵件”等形式。
在數學上,分類是從輸入變數 (X) 到輸出變數 (Y) 的對映函式 (f) 的近似任務。它基本上屬於監督機器學習,其中目標也與輸入資料集一起提供。
分類問題的一個例子可能是電子郵件中的垃圾郵件檢測。輸出只有兩個類別,“垃圾郵件”和“非垃圾郵件”;因此,這是一種二元分類。
要實現此分類,我們首先需要訓練分類器。對於此示例,“垃圾郵件”和“非垃圾郵件”電子郵件將用作訓練資料。成功訓練分類器後,它可以用於檢測未知電子郵件。
分類中的學習器型別
在分類問題方面,我們有兩種型別的學習器:
懶惰學習器
顧名思義,這種學習器在儲存訓練資料後等待測試資料出現。只有在獲得測試資料後才會進行分類。它們在訓練上花費的時間較少,但在預測上花費的時間更多。懶惰學習器的例子包括 K 最近鄰和基於案例的推理。
積極學習器
與懶惰學習器相反,積極學習器在儲存訓練資料後構建分類模型,而無需等待測試資料出現。它們在訓練上花費的時間更多,但在預測上花費的時間更少。積極學習器的例子包括決策樹、樸素貝葉斯和人工神經網路 (ANN)。
在 Python 中構建分類器
Scikit-learn 是一個用於機器學習的 Python 庫,可用於在 Python 中構建分類器。在 Python 中構建分類器的步驟如下:
步驟 1:匯入必要的 Python 包
要使用 scikit-learn 構建分類器,我們需要匯入它。我們可以使用以下指令碼匯入它:
import sklearn
步驟 2:匯入資料集
匯入必要的包後,我們需要一個數據集來構建分類預測模型。我們可以從 sklearn 資料集中匯入它,也可以根據需要使用其他資料集。我們將使用 sklearn 的乳腺癌威斯康星診斷資料庫。我們可以藉助以下指令碼匯入它:
from sklearn.datasets import load_breast_cancer
以下指令碼將載入資料集;
data = load_breast_cancer()
我們還需要組織資料,這可以透過以下指令碼完成:
label_names = data['target_names'] labels = data['target'] feature_names = data['feature_names'] features = data['data']
以下命令將列印標籤的名稱,在我們的資料庫中為“惡性”和“良性”。
print(label_names)
上述命令的輸出是標籤的名稱:
['malignant' 'benign']
這些標籤對映到二進位制值 0 和 1。惡性癌症由 0 表示,良性癌症由 1 表示。
這些標籤的特徵名稱和特徵值可以透過以下命令檢視:
print(feature_names[0])
上述命令的輸出是標籤 0 即惡性癌症的特徵名稱:
mean radius
類似地,標籤的特徵名稱可以如下生成:
print(feature_names[1])
上述命令的輸出是標籤 1 即良性癌症的特徵名稱:
mean texture
我們可以藉助以下命令列印這些標籤的特徵:
print(features[0])
這將給出以下輸出:
[1.799e+01 1.038e+01 1.228e+02 1.001e+03 1.184e-01 2.776e-01 3.001e-01 1.471e-01 2.419e-01 7.871e-02 1.095e+00 9.053e-01 8.589e+00 1.534e+02 6.399e-03 4.904e-02 5.373e-02 1.587e-02 3.003e-02 6.193e-03 2.538e+01 1.733e+01 1.846e+02 2.019e+03 1.622e-01 6.656e-01 7.119e-01 2.654e-01 4.601e-01 1.189e-01]
我們可以藉助以下命令列印這些標籤的特徵:
print(features[1])
這將給出以下輸出:
[2.057e+01 1.777e+01 1.329e+02 1.326e+03 8.474e-02 7.864e-02 8.690e-02 7.017e-02 1.812e-01 5.667e-02 5.435e-01 7.339e-01 3.398e+00 7.408e+01 5.225e-03 1.308e-02 1.860e-02 1.340e-02 1.389e-02 3.532e-03 2.499e+01 2.341e+01 1.588e+02 1.956e+03 1.238e-01 1.866e-01 2.416e-01 1.860e-01 2.750e-01 8.902e-02]
步驟 3:將資料組織成訓練集和測試集
由於我們需要在未見資料上測試我們的模型,因此我們將資料集分成兩部分:訓練集和測試集。我們可以使用 sklearn python 包的 train_test_split() 函式將資料分成資料集。以下命令將匯入該函式:
from sklearn.model_selection import train_test_split
現在,下一個命令將資料分成訓練資料和測試資料。在這個例子中,我們使用 40% 的資料進行測試,60% 的資料進行訓練:
train, test, train_labels, test_labels = train_test_split(features,labels,test_size = 0.40, random_state = 42)
步驟 4 - 模型評估
將資料分成訓練集和測試集後,我們需要構建模型。我們將為此目的使用樸素貝葉斯演算法。以下命令將匯入 GaussianNB 模組 -
from sklearn.naive_bayes import GaussianNB
現在,如下所示初始化模型 -
gnb = GaussianNB()
接下來,藉助以下命令,我們可以訓練模型 -
model = gnb.fit(train, train_labels)
現在,為了評估目的,我們需要進行預測。可以使用 predict() 函式如下所示進行 -
preds = gnb.predict(test) print(preds)
這將給出以下輸出:
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0 0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0 1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0 1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0 1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]
輸出中上述一系列的 0 和 1 是惡性和良性腫瘤類別的預測值。
步驟 5 - 查詢準確率
我們可以透過比較兩個陣列(即 test_labels 和 preds)來找到上一步構建的模型的準確率。我們將使用 accuracy_score() 函式來確定準確率。
from sklearn.metrics import accuracy_score print(accuracy_score(test_labels,preds)) 0.951754385965
以上輸出顯示樸素貝葉斯分類器的準確率為 95.17%。
分類評估指標
即使您已完成機器學習應用程式或模型的實現,工作也尚未完成。我們必須找出我們的模型有多有效?可能存在不同的評估指標,但我們必須謹慎選擇,因為指標的選擇會影響如何衡量和比較機器學習演算法的效能。
以下是您可以根據您的資料集和問題型別從中選擇的幾個重要的分類評估指標 -
混淆矩陣
它是衡量分類問題效能的最簡單方法,其中輸出可以是兩種或多種型別的類別。混淆矩陣不過是一個二維表,即“實際”和“預測”,此外,這兩個維度都有“真陽性 (TP)”、“真陰性 (TN)”、“假陽性 (FP)”、“假陰性 (FN)”如下所示 -
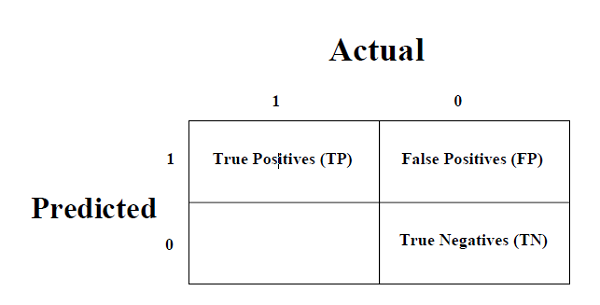
真陽性 (TP) - 當資料點的實際類別和預測類別均為 1 時。
真陰性 (TN) - 當資料點的實際類別和預測類別均為 0 時。
假陽性 (FP) - 當資料點的實際類別為 0 且預測類別為 1 時。
假陰性 (FN) - 當資料點的實際類別為 1 且預測類別為 0 時。
我們可以藉助 sklearn 的 confusion_matrix() 函式找到混淆矩陣。藉助以下指令碼,我們可以找到上面構建的二元分類器的混淆矩陣 -
from sklearn.metrics import confusion_matrix
輸出
[[ 73 7] [ 4 144]]
準確率
可以定義為我們的 ML 模型做出的正確預測的數量。我們可以很容易地透過混淆矩陣使用以下公式計算它 -
$$𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦=\frac{𝑇𝑃+𝑇𝑁}{𝑇𝑃+𝐹𝑃+𝐹𝑁+𝑇𝑁}$$對於上面構建的二元分類器,TP + TN = 73 + 144 = 217 且 TP + FP + FN + TN = 73 + 7 + 4 + 144 = 228。
因此,準確率 = 217/228 = 0.951754385965,與我們在建立二元分類器後計算的結果相同。
精確率
精確率,在文件檢索中使用,可以定義為我們的 ML 模型返回的正確文件的數量。我們可以很容易地透過混淆矩陣使用以下公式計算它 -
$$𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛=\frac{𝑇𝑃}{𝑇𝑃+FP}$$對於上面構建的二元分類器,TP = 73 且 TP + FP = 73 + 7 = 80。
因此,精確率 = 73/80 = 0.915
召回率或靈敏度
召回率可以定義為我們的 ML 模型返回的陽性數量。我們可以很容易地透過混淆矩陣使用以下公式計算它 -
$$𝑅𝑒𝑐𝑎𝑙𝑙=\frac{𝑇𝑃}{𝑇𝑃+FN}$$對於上面構建的二元分類器,TP = 73 且 TP + FN = 73 + 4 = 77。
因此,精確率 = 73/77 = 0.94805
特異性
特異性,與召回率相反,可以定義為我們的 ML 模型返回的陰性數量。我們可以很容易地透過混淆矩陣使用以下公式計算它 -
$$𝑆𝑝𝑒𝑐𝑖𝑓𝑖𝑐𝑖𝑡𝑦=\frac{𝑇N}{𝑇N+FP}$$對於上面構建的二元分類器,TN = 144 且 TN + FP = 144 + 7 = 151。
因此,精確率 = 144/151 = 0.95364
各種 ML 分類演算法
以下是幾個重要的 ML 分類演算法 -
邏輯迴歸
支援向量機 (SVM)
決策樹
樸素貝葉斯
隨機森林
我們將在後面的章節中詳細討論所有這些分類演算法。
應用
分類演算法的一些最重要的應用如下 -
語音識別
手寫識別
生物識別
文件分類
分類演算法 - 邏輯迴歸
邏輯迴歸簡介
邏輯迴歸是一種監督學習分類演算法,用於預測目標變數的機率。目標或因變數的性質是二分的,這意味著只有兩種可能的類別。
簡單來說,因變數本質上是二元的,資料編碼為 1(代表成功/是)或 0(代表失敗/否)。
在數學上,邏輯迴歸模型將 P(Y=1) 預測為 X 的函式。它是用於各種分類問題的最簡單的 ML 演算法之一,例如垃圾郵件檢測、糖尿病預測、癌症檢測等。
邏輯迴歸的型別
通常,邏輯迴歸指的是具有二元目標變數的二元邏輯迴歸,但它還可以預測目標變數的另外兩個類別。根據這些類別的數量,邏輯迴歸可以分為以下型別 -
二元或二項式
在這種型別的分類中,因變數將只有兩種可能的型別,要麼是 1 要麼是 0。例如,這些變數可能表示成功或失敗、是或否、贏或輸等。
多項式
在這種型別的分類中,因變數可以有 3 種或更多種可能的無序型別,或者沒有定量意義的型別。例如,這些變數可能表示“A 型”或“B 型”或“C 型”。
有序
在這種型別的分類中,因變數可以有 3 種或更多種可能的順序型別,或者具有定量意義的型別。例如,這些變數可能表示“差”或“好”、“非常好”、“優秀”,每個類別可以有 0、1、2、3 等分數。
邏輯迴歸假設
在深入研究邏輯迴歸的實現之前,我們必須瞭解以下關於它的假設 -
在二元邏輯迴歸的情況下,目標變數必須始終為二元,並且期望結果由因子水平 1 表示。
模型中不應存在多重共線性,這意味著自變數必須相互獨立。
我們必須在模型中包含有意義的變數。
我們應該為邏輯迴歸選擇一個大的樣本量。
二元邏輯迴歸模型
邏輯迴歸最簡單的形式是二元或二項式邏輯迴歸,其中目標或因變數只能有 2 種可能的型別,要麼是 1 要麼是 0。它允許我們對多個預測變數和二元/二項式目標變數之間的關係進行建模。在邏輯迴歸的情況下,線性函式基本上用作另一個函式(例如以下關係中的 𝑔)的輸入 -
$h_{\theta}{(x)}=g(\theta^{T}x)𝑤ℎ𝑒𝑟𝑒 0≤h_{\theta}≤1$這裡,𝑔 是邏輯或 sigmoid 函式,可以表示如下 -
$g(z)= \frac{1}{1+e^{-z}}𝑤ℎ𝑒𝑟𝑒 𝑧=\theta ^{T}𝑥$可以使用以下圖形表示 sigmoid 曲線。我們可以看到 y 軸的值介於 0 和 1 之間,並在 0.5 處穿過軸。

類別可以分為正類或負類。如果輸出介於 0 和 1 之間,則它屬於正類的機率。對於我們的實現,如果假設函式的輸出 ≥0.5,則將其解釋為正類,否則為負類。
我們還需要定義一個損失函式來衡量演算法使用函式上的權重(用 theta 表示)的執行情況,如下所示 -
ℎ=𝑔(𝑋𝜃)
$J(\theta) = \frac{1}{m}.(-y^{T}log(h) - (1 -y)^Tlog(1-h))$現在,在定義損失函式後,我們的主要目標是最小化損失函式。這可以透過擬合權重來完成,這意味著透過增加或減少權重。藉助損失函式對每個權重的導數,我們將能夠知道哪些引數應該具有較高的權重,哪些引數應該具有較小的權重。
以下梯度下降方程告訴我們如果修改引數,損失將如何變化 -
$\frac{𝛿𝐽(𝜃)}{𝛿\theta_{j}}=\frac{1}{m}X^{T}(𝑔(𝑋𝜃)−𝑦)$Python 中的實現
現在,我們將用 Python 實現上述二元邏輯迴歸的概念。為此,我們使用了一個名為“iris”的多元花卉資料集,它有 3 個類別,每個類別有 50 個例項,但我們將使用前兩個特徵列。每個類別代表一種鳶尾花。
首先,我們需要匯入必要的庫,如下所示 -
import numpy as np import matplotlib.pyplot as plt import seaborn as sns from sklearn import datasets
接下來,載入 iris 資料集,如下所示 -
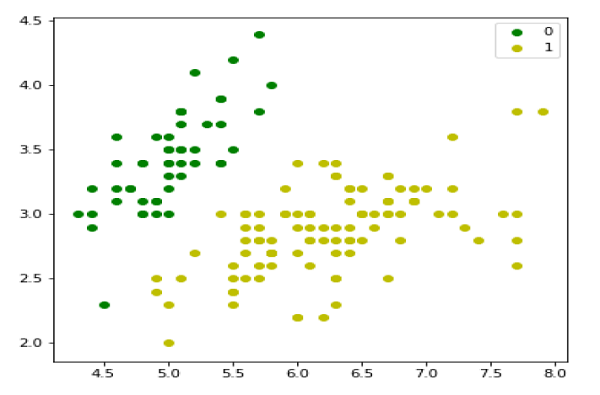
iris = datasets.load_iris() X = iris.data[:, :2] y = (iris.target != 0) * 1
我們可以繪製我們的訓練資料,如下所示 -
plt.figure(figsize=(6, 6)) plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='g', label='0') plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='y', label='1') plt.legend();
接下來,我們將定義 sigmoid 函式、損失函式和梯度下降,如下所示 -
class LogisticRegression:
def __init__(self, lr=0.01, num_iter=100000, fit_intercept=True, verbose=False):
self.lr = lr
self.num_iter = num_iter
self.fit_intercept = fit_intercept
self.verbose = verbose
def __add_intercept(self, X):
intercept = np.ones((X.shape[0], 1))
return np.concatenate((intercept, X), axis=1)
def __sigmoid(self, z):
return 1 / (1 + np.exp(-z))
def __loss(self, h, y):
return (-y * np.log(h) - (1 - y) * np.log(1 - h)).mean()
def fit(self, X, y):
if self.fit_intercept:
X = self.__add_intercept(X)
現在,初始化權重,如下所示 -
self.theta = np.zeros(X.shape[1])
for i in range(self.num_iter):
z = np.dot(X, self.theta)
h = self.__sigmoid(z)
gradient = np.dot(X.T, (h - y)) / y.size
self.theta -= self.lr * gradient
z = np.dot(X, self.theta)
h = self.__sigmoid(z)
loss = self.__loss(h, y)
if(self.verbose ==True and i % 10000 == 0):
print(f'loss: {loss} \t')
藉助以下指令碼,我們可以預測輸出機率 -
def predict_prob(self, X):
if self.fit_intercept:
X = self.__add_intercept(X)
return self.__sigmoid(np.dot(X, self.theta))
def predict(self, X):
return self.predict_prob(X).round()
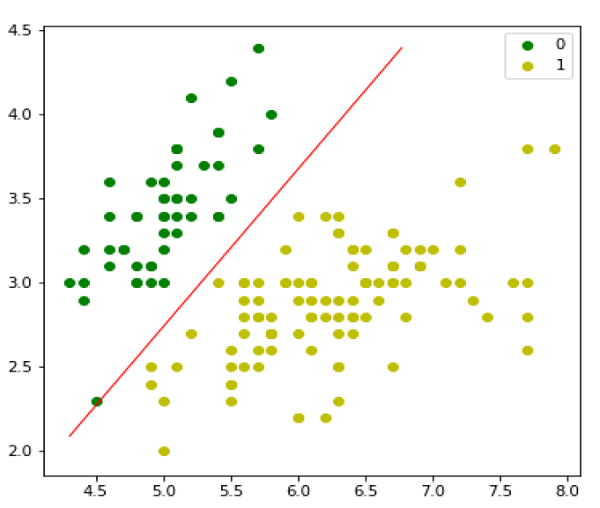
接下來,我們可以評估模型並繪製它,如下所示 -
model = LogisticRegression(lr=0.1, num_iter=300000) preds = model.predict(X) (preds == y).mean() plt.figure(figsize=(10, 6)) plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='g', label='0') plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='y', label='1') plt.legend() x1_min, x1_max = X[:,0].min(), X[:,0].max(), x2_min, x2_max = X[:,1].min(), X[:,1].max(), xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max), np.linspace(x2_min, x2_max)) grid = np.c_[xx1.ravel(), xx2.ravel()] probs = model.predict_prob(grid).reshape(xx1.shape) plt.contour(xx1, xx2, probs, [0.5], linewidths=1, colors='red');
多項式邏輯迴歸模型
邏輯迴歸的另一種有用形式是多項式邏輯迴歸,其中目標或因變數可以有 3 種或更多種可能的無序型別,即沒有定量意義的型別。
Python 中的實現
現在,我們將用 Python 實現上述多項式邏輯迴歸的概念。為此,我們使用 sklearn 中名為 digit 的資料集。
首先,我們需要匯入必要的庫,如下所示 -
Import sklearn from sklearn import datasets from sklearn import linear_model from sklearn import metrics from sklearn.model_selection import train_test_split
接下來,我們需要載入 digit 資料集 -
digits = datasets.load_digits()
現在,定義特徵矩陣 (X) 和響應向量 (y),如下所示 -
X = digits.data y = digits.target
藉助下一行程式碼,我們可以將 X 和 y 分割成訓練集和測試集 -
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1)
現在建立一個邏輯迴歸物件,如下所示 -
digreg = linear_model.LogisticRegression()
現在,我們需要使用訓練集訓練模型,如下所示 -
digreg.fit(X_train, y_train)
接下來,對測試集進行預測,如下所示 -
y_pred = digreg.predict(X_test)
接下來列印模型的準確率,如下所示 -
print("Accuracy of Logistic Regression model is:",
metrics.accuracy_score(y_test, y_pred)*100)
輸出
Accuracy of Logistic Regression model is: 95.6884561891516
從以上輸出中,我們可以看到模型的準確率約為 96%。
支援向量機 (SVM)
SVM 簡介
支援向量機 (SVM) 是一種強大且靈活的監督機器學習演算法,可用於分類和迴歸。但通常,它們用於分類問題。在 20 世紀 60 年代,SVM 首次被引入,但後來在 20 世紀 90 年代得到了改進。與其他機器學習演算法相比,SVM 具有獨特的實現方式。最近,由於它們能夠處理多個連續和分類變數,因此它們非常受歡迎。
SVM 的工作原理
SVM 模型基本上是在多維空間中超平面中不同類別的表示。超平面將以迭代方式由 SVM 生成,以便可以最小化誤差。SVM 的目標是將資料集劃分為類別以找到最大間隔超平面 (MMH)。

以下是 SVM 中的重要概念 -
支援向量 - 距離超平面最近的資料點稱為支援向量。分離線將藉助這些資料點來定義。
超平面 - 正如我們在上圖中看到的,它是一個決策平面或空間,它將一組具有不同類別的物件分隔開來。
間隔 - 它可以定義為不同類別最近資料點之間兩條線的間隙。它可以計算為從線到支援向量的垂直距離。大間隔被認為是好的間隔,小間隔被認為是壞的間隔。
SVM 的主要目標是將資料集劃分為不同的類別,以找到最大間隔超平面 (MMH),這可以透過以下兩個步驟完成:
首先,SVM 將迭代生成超平面,以最佳方式隔離類別。
然後,它將選擇正確分離類別的超平面。
在 Python 中實現 SVM
為了在 Python 中實現 SVM,我們將從匯入標準庫開始,如下所示:
import numpy as np import matplotlib.pyplot as plt from scipy import stats import seaborn as sns; sns.set()
接下來,我們正在建立用於使用 SVM 進行分類的線性可分離資料樣本資料集,來自 sklearn.dataset.sample_generator:
from sklearn.datasets.samples_generator import make_blobs
X, y = make_blobs(n_samples=100, centers=2,
random_state=0, cluster_std=0.50)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='summer');
生成包含 100 個樣本和 2 個簇的樣本資料集後的輸出如下:

我們知道 SVM 支援判別式分類。它透過簡單地在二維情況下找到一條線或在多維情況下找到一個流形來將類別彼此分開。它在上述資料集上實現如下:
xfit = np.linspace(-1, 3.5) plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='summer') plt.plot([0.6], [2.1], 'x', color='black', markeredgewidth=4, markersize=12) for m, b in [(1, 0.65), (0.5, 1.6), (-0.2, 2.9)]: plt.plot(xfit, m * xfit + b, '-k') plt.xlim(-1, 3.5);
輸出如下:

從上面的輸出中我們可以看到,有三個不同的分離器可以完美地區分上述樣本。
如前所述,SVM 的主要目標是將資料集劃分為不同的類別,以找到最大間隔超平面 (MMH),因此,與其在類別之間繪製零線,不如在每條線周圍繪製一定寬度的間隔,直到最近的點。它可以按如下方式完成:
xfit = np.linspace(-1, 3.5)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='summer')
for m, b, d in [(1, 0.65, 0.33), (0.5, 1.6, 0.55), (-0.2, 2.9, 0.2)]:
yfit = m * xfit + b
plt.plot(xfit, yfit, '-k')
plt.fill_between(xfit, yfit - d, yfit + d, edgecolor='none',
color='#AAAAAA', alpha=0.4)
plt.xlim(-1, 3.5);
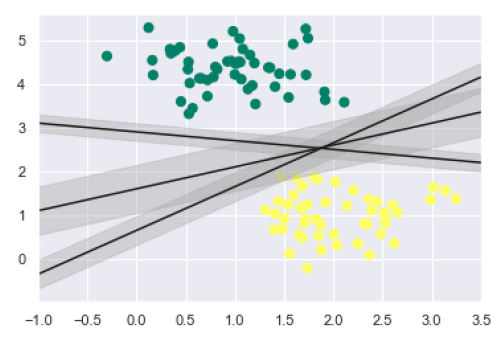
從輸出中的上圖中,我們可以很容易地觀察到判別分類器內的“間隔”。SVM 將選擇最大化間隔的線。
接下來,我們將使用 Scikit-Learn 的支援向量分類器來訓練此資料的 SVM 模型。在這裡,我們使用線性核來擬合 SVM,如下所示:
from sklearn.svm import SVC # "Support vector classifier" model = SVC(kernel='linear', C=1E10) model.fit(X, y)
輸出如下:
SVC(C=10000000000.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=3, gamma='auto_deprecated', kernel='linear', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False)
現在,為了更好地理解,以下將繪製二維 SVC 的決策函式:
def decision_function(model, ax=None, plot_support=True):
if ax is None:
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
為了評估模型,我們需要建立網格,如下所示:
x = np.linspace(xlim[0], xlim[1], 30) y = np.linspace(ylim[0], ylim[1], 30) Y, X = np.meshgrid(y, x) xy = np.vstack([X.ravel(), Y.ravel()]).T P = model.decision_function(xy).reshape(X.shape)
接下來,我們需要繪製決策邊界和間隔,如下所示:
ax.contour(X, Y, P, colors='k', levels=[-1, 0, 1], alpha=0.5, linestyles=['--', '-', '--'])
現在,類似地繪製支援向量,如下所示:
if plot_support:
ax.scatter(model.support_vectors_[:, 0],
model.support_vectors_[:, 1],
s=300, linewidth=1, facecolors='none');
ax.set_xlim(xlim)
ax.set_ylim(ylim)
現在,使用此函式擬合我們的模型,如下所示:
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='summer') decision_function(model);

從上面的輸出中我們可以觀察到,一個 SVM 分類器適合具有間隔(即虛線)和支援向量的資料,這些支援向量是此擬合的關鍵元素,並接觸到虛線。這些支援向量點儲存在分類器的 support_vectors_ 屬性中,如下所示:
model.support_vectors_
輸出如下:
array([[0.5323772 , 3.31338909], [2.11114739, 3.57660449], [1.46870582, 1.86947425]])
SVM 核函式
在實踐中,SVM 演算法是使用核函式來實現的,該核函式將輸入資料空間轉換為所需的形式。SVM 使用一種稱為核技巧的技術,其中核函式將低維輸入空間轉換為高維空間。簡單來說,核函式透過增加維度將不可分離問題轉換為可分離問題。它使 SVM 更加強大、靈活和準確。以下是 SVM 使用的一些核函式型別:
線性核函式
它可以用作任何兩個觀測值之間的點積。線性核函式的公式如下:
k(x,xi) = sum(x*xi)
從上面的公式中,我們可以看到兩個向量(例如 𝑥 和 𝑥𝑖)之間的乘積是每對輸入值的乘積之和。
多項式核函式
它是線性核函式的更通用形式,可以區分曲線或非線性輸入空間。以下是多項式核函式的公式:
K(x, xi) = 1 + sum(x * xi)^d
這裡 d 是多項式的次數,我們需要在學習演算法中手動指定它。
徑向基函式 (RBF) 核函式
RBF 核函式主要用於 SVM 分類,它將輸入空間對映到無限維空間。以下公式用數學方法解釋了它:
K(x,xi) = exp(-gamma * sum((x – xi^2))
這裡,gamma 的範圍為 0 到 1。我們需要在學習演算法中手動指定它。gamma 的一個好的預設值為 0.1。
由於我們已經實現了線性可分離資料的 SVM,因此我們可以使用核函式在 Python 中實現不可分離的資料。它可以透過使用核函式來完成。
示例
以下是如何使用核函式建立 SVM 分類器的示例。我們將使用 scikit-learn 中的 iris 資料集:
我們將從匯入以下包開始:
import pandas as pd import numpy as np from sklearn import svm, datasets import matplotlib.pyplot as plt
現在,我們需要載入輸入資料:
iris = datasets.load_iris()
從這個資料集中,我們取前兩個特徵,如下所示:
X = iris.data[:, :2] y = iris.target
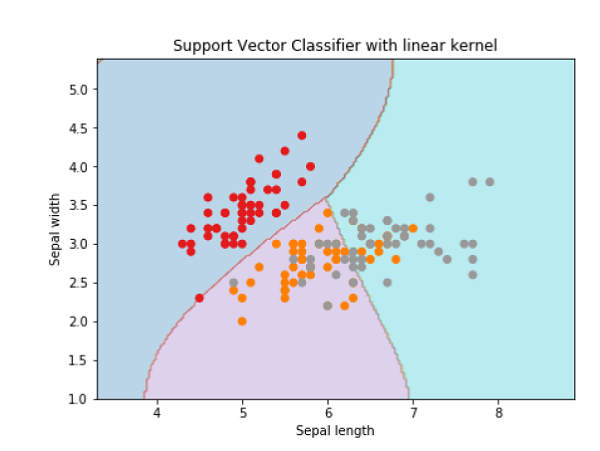
接下來,我們將使用原始資料繪製 SVM 邊界,如下所示:
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 h = (x_max / x_min)/100 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) X_plot = np.c_[xx.ravel(), yy.ravel()]
現在,我們需要提供正則化引數的值,如下所示:
C = 1.0
接下來,可以建立 SVM 分類器物件,如下所示:
Svc_classifier = svm.SVC(kernel='linear', C=C).fit(X, y)
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
plt.figure(figsize=(15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, cmap=plt.cm.tab10, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('Support Vector Classifier with linear kernel')
輸出
Text(0.5, 1.0, 'Support Vector Classifier with linear kernel')
為了使用rbf核函式建立 SVM 分類器,我們可以將核函式更改為rbf,如下所示:
Svc_classifier = svm.SVC(kernel='rbf', gamma =‘auto’,C=C).fit(X, y)
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
plt.figure(figsize=(15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, cmap=plt.cm.tab10, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('Support Vector Classifier with rbf kernel')
輸出
Text(0.5, 1.0, 'Support Vector Classifier with rbf kernel')

我們將 gamma 的值設定為“auto”,但您也可以提供其值(介於 0 到 1 之間)。
SVM 分類器的優缺點
SVM 分類器的優點
SVM 分類器提供很高的準確性,並且適用於高維空間。SVM 分類器基本上使用訓練點的子集,因此最終使用非常少的記憶體。
SVM 分類器的缺點
它們的訓練時間較長,因此在實踐中不適用於大型資料集。另一個缺點是 SVM 分類器不適用於重疊類別。
分類演算法 - 決策樹
決策樹簡介
通常,決策樹分析是一種預測建模工具,可以應用於許多領域。決策樹可以透過演算法方法構建,該方法可以根據不同的條件以不同的方式拆分資料集。決策樹是最強大的演算法,屬於監督演算法類別。
它們可用於分類和迴歸任務。樹的兩個主要實體是決策節點(資料在其中被拆分)和葉子節點(我們在其中獲得結果)。下面給出了一個用於預測一個人是否健康(提供各種資訊,如年齡、飲食習慣和鍛鍊習慣)的二叉樹示例:
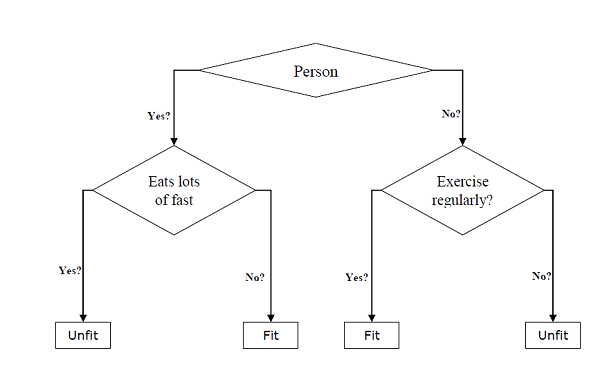
在上圖的決策樹中,問題是決策節點,最終結果是葉子節點。我們有以下兩種型別的決策樹:
分類決策樹 - 在這種決策樹中,決策變數是分類變數。上面的決策樹是分類決策樹的一個例子。
迴歸決策樹 - 在這種決策樹中,決策變數是連續變數。
實現決策樹演算法
基尼指數
它是用於評估資料集中二元拆分的成本函式的名稱,並且適用於分類目標變數“成功”或“失敗”。
基尼指數的值越高,同質性越高。完美的基尼指數值為 0,最差為 0.5(對於 2 類問題)。可以使用以下步驟計算拆分的基尼指數:
首先,使用公式 p^2+q^2 計算子節點的基尼指數,它是成功和失敗機率的平方和。
接下來,使用該拆分每個節點的加權基尼分數計算拆分的基尼指數。
分類和迴歸樹 (CART) 演算法使用基尼方法生成二元拆分。
拆分建立
拆分基本上包括資料集中的一個屬性和一個值。我們可以藉助以下三個部分在資料集中建立拆分:
部分 1 - 計算基尼分數:我們剛剛在上一節中討論了這部分內容。
部分 2 - 拆分資料集:它可以定義為將資料集分成兩個行列表,其中包含屬性的索引和該屬性的拆分值。從資料集中獲得兩個組(右組和左組)後,我們可以使用在第一部分中計算出的基尼分數來計算拆分值。拆分值將決定屬性將駐留在哪個組中。
部分 3 - 評估所有拆分:找到基尼分數和拆分資料集後的下一部分是對所有拆分進行評估。為此,我們首先必須檢查與每個屬性相關聯的每個值作為候選拆分。然後,我們需要透過評估拆分的成本找到最佳的拆分。最佳拆分將用作決策樹中的節點。
構建樹
眾所周知,樹具有根節點和終端節點。建立根節點後,我們可以透過以下兩個部分構建樹:
部分 1:終端節點建立
在建立決策樹的終端節點時,一個重要的點是決定何時停止樹的增長或建立進一步的終端節點。這可以透過使用以下兩個標準來完成:最大樹深度和最小節點記錄:
最大樹深度 - 顧名思義,這是根節點之後樹中節點的最大數量。一旦樹達到最大深度(即一旦樹獲得最大數量的終端節點),我們必須停止新增終端節點。
最小節點記錄 - 它可以定義為給定節點負責的訓練模式的最小數量。一旦樹達到這些最小節點記錄或低於此最小值,我們必須停止新增終端節點。
終端節點用於進行最終預測。
部分 2:遞迴拆分
在我們瞭解了何時建立終端節點後,現在我們可以開始構建我們的樹了。遞迴拆分是一種構建樹的方法。在這種方法中,一旦建立了一個節點,我們就可以在透過拆分資料集生成的每個資料組上遞迴地建立子節點(新增到現有節點的節點),方法是反覆呼叫相同的函式。
預測
構建決策樹後,我們需要對其進行預測。基本上,預測涉及使用特定提供的行資料遍歷決策樹。
我們可以藉助遞迴函式進行預測,就像上面所做的那樣。相同的預測例程將與左子節點或右子節點一起再次呼叫。
假設
在建立決策樹時,我們做出以下一些假設:
在準備決策樹時,訓練集作為根節點。
決策樹分類器更喜歡特徵值是分類的。如果您想使用連續值,則必須在構建模型之前對其進行離散化。
根據屬性的值,記錄被遞迴地分佈。
統計方法將用於將屬性放置在任何節點位置(即作為根節點或內部節點)。
Python 中的實現
示例
在以下示例中,我們將對 Pima 印第安人糖尿病資料集實現決策樹分類器:
首先,從匯入必要的 Python 包開始:
import pandas as pd from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split
接下來,從其網路連結下載 iris 資料集,如下所示:
col_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label'] pima = pd.read_csv(r"C:\pima-indians-diabetes.csv", header=None, names=col_names) pima.head()
pregnant glucose bp skin insulin bmi pedigree age label 0 6 148 72 35 0 33.6 0.627 50 1 1 1 85 66 29 0 26.6 0.351 31 0 2 8 183 64 0 0 23.3 0.672 32 1 3 1 89 66 23 94 28.1 0.167 21 0 4 0 137 40 35 168 43.1 2.288 33 1
現在,將資料集拆分為特徵和目標變數,如下所示:
feature_cols = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree'] X = pima[feature_cols] # Features y = pima.label # Target variable
接下來,我們將資料劃分為訓練集和測試集。以下程式碼將資料集拆分為 70% 的訓練資料和 30% 的測試資料:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
接下來,使用 sklearn 的 DecisionTreeClassifier 類訓練模型,如下所示:
clf = DecisionTreeClassifier() clf = clf.fit(X_train,y_train)
最後,我們需要進行預測。這可以透過以下指令碼完成:
y_pred = clf.predict(X_test)
接下來,我們可以獲取準確率得分、混淆矩陣和分類報告,如下所示:
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
result = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(result)
result1 = classification_report(y_test, y_pred)
print("Classification Report:",)
print (result1)
result2 = accuracy_score(y_test,y_pred)
print("Accuracy:",result2)
輸出
Confusion Matrix:
[[116 30]
[ 46 39]]
Classification Report:
precision recall f1-score support
0 0.72 0.79 0.75 146
1 0.57 0.46 0.51 85
micro avg 0.67 0.67 0.67 231
macro avg 0.64 0.63 0.63 231
weighted avg 0.66 0.67 0.66 231
Accuracy: 0.670995670995671
決策樹視覺化
可以使用以下程式碼視覺化上述決策樹:
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True, rounded=True,
special_characters=True,feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('Pima_diabetes_Tree.png')
Image(graph.create_png())
分類演算法 - 樸素貝葉斯
樸素貝葉斯演算法簡介
樸素貝葉斯演算法是一種分類技術,它基於貝葉斯定理,並假設所有預測變數之間相互獨立。簡單來說,這個假設就是指在一個類中某個特徵的存在與同一類中其他特徵的存在是相互獨立的。例如,一部手機如果具有觸控式螢幕、網際網路功能、良好的攝像頭等,就可以被認為是智慧手機。儘管所有這些特徵都是相互依賴的,但它們都獨立地對手機是否是智慧手機的機率做出貢獻。
在貝葉斯分類中,主要關注的是尋找後驗機率,即給定一些觀察到的特徵後標籤的機率,𝑃(𝐿 | 𝑓𝑒𝑎𝑡𝑢𝑟𝑒𝑠)。藉助貝葉斯定理,我們可以用以下定量形式表示:
$P(L |features)= \frac{P(L)P(features |L)}{𝑃(𝑓𝑒𝑎𝑡𝑢𝑟𝑒𝑠)}$其中,𝑃(𝐿 | 𝑓𝑒𝑎𝑡𝑢𝑟𝑒𝑠) 是類的後驗機率。
𝑃(𝐿) 是類的先驗機率。
𝑃(𝑓𝑒𝑎𝑡𝑢𝑟𝑒𝑠 | 𝐿) 是似然度,即給定類別的預測變數的機率。
𝑃(𝑓𝑒𝑎𝑡𝑢𝑟𝑒𝑠) 是預測變數的先驗機率。
使用 Python 中的樸素貝葉斯構建模型
Python 庫 Scikit-learn 是一個非常有用的庫,可以幫助我們在 Python 中構建樸素貝葉斯模型。在 Scikit-learn Python 庫下,我們有以下三種類型的樸素貝葉斯模型:
高斯樸素貝葉斯
這是最簡單的樸素貝葉斯分類器,它假設每個標籤的資料都來自一個簡單的高斯分佈。
多項式樸素貝葉斯
另一種有用的樸素貝葉斯分類器是多項式樸素貝葉斯,其中假設特徵是從一個簡單的多項式分佈中提取的。這種型別的樸素貝葉斯最適合表示離散計數的特徵。
伯努利樸素貝葉斯
另一個重要的模型是伯努利樸素貝葉斯,其中假設特徵是二元的(0 和 1)。使用“詞袋”模型的文字分類可以作為伯努利樸素貝葉斯的應用。
示例
根據我們的資料集,我們可以選擇上面解釋的任何一個樸素貝葉斯模型。在這裡,我們將在 Python 中實現高斯樸素貝葉斯模型:
我們將從所需的匯入開始,如下所示:
import numpy as np import matplotlib.pyplot as plt import seaborn as sns; sns.set()
現在,透過使用 Scikit-learn 的 make_blobs() 函式,我們可以生成具有高斯分佈的點集,如下所示:
from sklearn.datasets import make_blobs X, y = make_blobs(300, 2, centers=2, random_state=2, cluster_std=1.5) plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='summer');
接下來,為了使用 GaussianNB 模型,我們需要匯入並建立其物件,如下所示:
from sklearn.naive_bayes import GaussianNB model_GBN = GaussianNB() model_GNB.fit(X, y);
現在,我們必須進行預測。這可以在生成一些新資料後完成,如下所示:
rng = np.random.RandomState(0) Xnew = [-6, -14] + [14, 18] * rng.rand(2000, 2) ynew = model_GNB.predict(Xnew)
接下來,我們正在繪製新資料以找到其邊界:
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='summer') lim = plt.axis() plt.scatter(Xnew[:, 0], Xnew[:, 1], c=ynew, s=20, cmap='summer', alpha=0.1) plt.axis(lim);
現在,藉助以下幾行程式碼,我們可以找到第一個和第二個標籤的後驗機率:
yprob = model_GNB.predict_proba(Xnew) yprob[-10:].round(3)
輸出
array([[0.998, 0.002],
[1. , 0. ],
[0.987, 0.013],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[0. , 1. ],
[0.986, 0.014]])
優缺點
優點
以下是使用樸素貝葉斯分類器的一些優點:
樸素貝葉斯分類易於實現且速度快。
它比邏輯迴歸等判別模型收斂得更快。
它需要較少的訓練資料。
它本質上具有高度可擴充套件性,或者它們與預測變數和資料點的數量線性擴充套件。
它可以進行機率預測,並且可以處理連續資料和離散資料。
樸素貝葉斯分類演算法既可以用於二元分類問題,也可以用於多類分類問題。
缺點
以下是使用樸素貝葉斯分類器的一些缺點:
樸素貝葉斯分類的一個最重要的缺點是其強特徵獨立性,因為在現實生活中,幾乎不可能有一組完全相互獨立的特徵。
樸素貝葉斯分類的另一個問題是其“零頻率”,這意味著如果一個分類變數有一個類別但在訓練資料集中沒有觀察到,那麼樸素貝葉斯模型將為其分配零機率,並且將無法進行預測。
樸素貝葉斯分類的應用
以下是樸素貝葉斯分類的一些常見應用:
即時預測 - 由於其易於實現和快速計算,它可以用於進行即時預測。
多類預測 - 樸素貝葉斯分類演算法可以用於預測目標變數多個類的後驗機率。
文字分類 - 由於具有多類預測的功能,樸素貝葉斯分類演算法非常適合文字分類。因此,它也用於解決垃圾郵件過濾和情感分析等問題。
推薦系統 - 除了協同過濾等演算法外,樸素貝葉斯還可以構建推薦系統,用於過濾未見資訊並預測使用者是否喜歡給定資源。
分類演算法 - 隨機森林
介紹
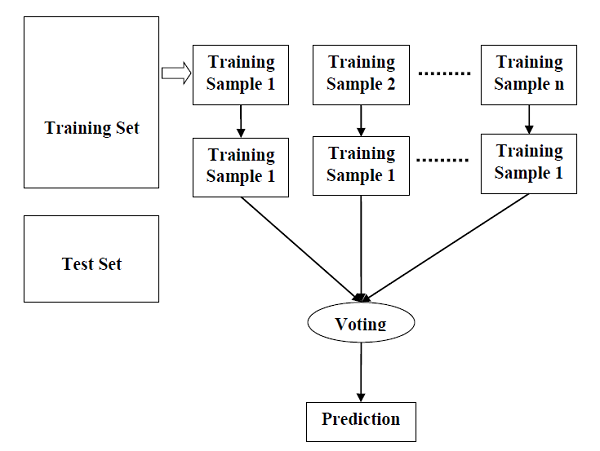
隨機森林是一種監督學習演算法,可用於分類和迴歸。但是,它主要用於分類問題。眾所周知,森林是由樹木組成的,樹木越多,森林就越茂盛。類似地,隨機森林演算法會在資料樣本上建立決策樹,然後從每個決策樹中獲取預測結果,最後透過投票選擇最佳解決方案。它是一種整合方法,優於單個決策樹,因為它透過平均結果來減少過擬合。
隨機森林演算法的工作原理
我們可以透過以下步驟瞭解隨機森林演算法的工作原理:
步驟1 - 首先,從給定的資料集中選擇隨機樣本。
步驟2 - 接下來,該演算法將為每個樣本構建一棵決策樹。然後,它將從每個決策樹中獲取預測結果。
步驟3 - 在此步驟中,將對每個預測結果進行投票。
步驟4 - 最後,選擇投票最多的預測結果作為最終預測結果。
下圖將說明其工作原理:
Python 中的實現
首先,從匯入必要的 Python 包開始:
import numpy as np import matplotlib.pyplot as plt import pandas as pd
接下來,從其網路連結下載 iris 資料集,如下所示:
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
接下來,我們需要為資料集分配列名,如下所示:
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
現在,我們需要將資料集讀取到 pandas 資料框中,如下所示:
dataset = pd.read_csv(path, names=headernames) dataset.head()
萼片長度 |
萼片寬度 |
花瓣長度 |
花瓣寬度 |
類別 |
|
|---|---|---|---|---|---|
0 |
5.1 |
3.5 |
1.4 |
0.2 |
Iris-setosa |
1 |
4.9 |
3.0 |
1.4 |
0.2 |
Iris-setosa |
2 |
4.7 |
3.2 |
1.3 |
0.2 |
Iris-setosa |
3 |
4.6 |
3.1 |
1.5 |
0.2 |
Iris-setosa |
4 |
5.0 |
3.6 |
1.4 |
0.2 |
Iris-setosa |
資料預處理將藉助以下指令碼行完成:
X = dataset.iloc[:, :-1].values y = dataset.iloc[:, 4].values
接下來,我們將資料劃分為訓練集和測試集。以下程式碼將資料集拆分為 70% 的訓練資料和 30% 的測試資料:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)
接下來,使用 sklearn 的 RandomForestClassifier 類訓練模型,如下所示:
from sklearn.ensemble import RandomForestClassifier classifier = RandomForestClassifier(n_estimators=50) classifier.fit(X_train, y_train)
最後,我們需要進行預測。這可以透過以下指令碼完成:
y_pred = classifier.predict(X_test)
接下來,列印結果,如下所示:
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
result = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(result)
result1 = classification_report(y_test, y_pred)
print("Classification Report:",)
print (result1)
result2 = accuracy_score(y_test,y_pred)
print("Accuracy:",result2)
輸出
Confusion Matrix:
[[14 0 0]
[ 0 18 1]
[ 0 0 12]]
Classification Report:
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 14
Iris-versicolor 1.00 0.95 0.97 19
Iris-virginica 0.92 1.00 0.96 12
micro avg 0.98 0.98 0.98 45
macro avg 0.97 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
Accuracy: 0.9777777777777777
隨機森林的優缺點
優點
以下是隨機森林演算法的優點:
它透過平均或組合不同決策樹的結果來克服過擬合問題。
與單個決策樹相比,隨機森林適用於更廣泛的資料項。
隨機森林的方差小於單個決策樹。
隨機森林非常靈活,並且具有很高的準確性。
隨機森林演算法不需要對資料進行縮放。即使在提供未縮放的資料後,它也能保持良好的準確性。
隨機森林演算法不需要對資料進行縮放。即使在提供未縮放的資料後,它也能保持良好的準確性。
缺點
以下是隨機森林演算法的缺點:
複雜性是隨機森林演算法的主要缺點。
構建隨機森林比決策樹更困難且耗時。
實現隨機森林演算法需要更多計算資源。
當我們有一大堆決策樹時,它不太直觀。
與其他演算法相比,使用隨機森林進行預測非常耗時。
迴歸演算法 - 概述
迴歸簡介
迴歸是另一個重要且廣泛使用的統計和機器學習工具。基於迴歸的任務的主要目標是預測輸出標籤或響應,這些標籤或響應是給定輸入資料的連續數值。輸出將基於模型在訓練階段學到的內容。基本上,迴歸模型使用輸入資料特徵(自變數)及其相應的連續數值輸出值(因變數或結果變數)來學習輸入和相應輸出之間的特定關聯。

迴歸模型的型別
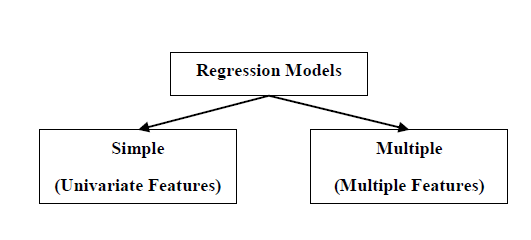
迴歸模型有以下兩種型別:
簡單迴歸模型 - 這是最基本的迴歸模型,其中預測是根據資料的單個單變數特徵形成的。
多元迴歸模型 - 顧名思義,在這種迴歸模型中,預測是根據資料的多個特徵形成的。
在 Python 中構建迴歸器
Python 中的迴歸器模型的構建方式與我們構建分類器的方式類似。Scikit-learn,一個用於機器學習的 Python 庫,也可以用於在 Python 中構建迴歸器。
在以下示例中,我們將構建一個基本回歸模型,該模型將一條線擬合到資料上,即線性迴歸器。在 Python 中構建迴歸器的必要步驟如下:
步驟 1:匯入必要的 Python 包
為了使用 scikit-learn 構建迴歸器,我們需要將其與其他必要的包一起匯入。我們可以使用以下指令碼匯入它:
import numpy as np from sklearn import linear_model import sklearn.metrics as sm import matplotlib.pyplot as plt
步驟 2:匯入資料集
匯入必要的包後,我們需要一個數據集來構建迴歸預測模型。我們可以從 sklearn 資料集中匯入它,也可以根據我們的需要使用其他資料集。我們將使用我們儲存的輸入資料。我們可以藉助以下指令碼匯入它:
input = r'C:\linear.txt'
接下來,我們需要載入此資料。我們使用 np.loadtxt 函式來載入它。
input_data = np.loadtxt(input, delimiter=',') X, y = input_data[:, :-1], input_data[:, -1]
步驟 3:將資料組織成訓練集和測試集
由於我們需要在未見過的資料上測試我們的模型,因此我們將資料集分成兩部分:訓練集和測試集。以下命令將執行此操作:
training_samples = int(0.6 * len(X)) testing_samples = len(X) - num_training X_train, y_train = X[:training_samples], y[:training_samples] X_test, y_test = X[training_samples:], y[training_samples:]
步驟4- 模型評估和預測
將資料劃分為訓練集和測試集後,我們需要構建模型。我們將為此目的使用 Scikit-learn 的 LineaRegression() 函式。以下命令將建立一個線性迴歸器物件。
reg_linear= linear_model.LinearRegression()
接下來,使用訓練樣本訓練此模型,如下所示:
reg_linear.fit(X_train, y_train)
現在,最後我們需要使用測試資料進行預測。
y_test_pred = reg_linear.predict(X_test)
步驟5- 繪製和視覺化
預測後,我們可以使用以下指令碼繪製和視覺化它:
plt.scatter(X_test, y_test, color='red') plt.plot(X_test, y_test_pred, color='black', linewidth=2) plt.xticks(()) plt.yticks(()) plt.show()
輸出

在上面的輸出中,我們可以看到資料點之間的迴歸線。
步驟6- 效能計算 - 我們還可以使用各種效能指標來計算迴歸模型的效能,如下所示:
print("Regressor model performance:")
print("Mean absolute error(MAE) =", round(sm.mean_absolute_error(y_test, y_test_pred), 2))
print("Mean squared error(MSE) =", round(sm.mean_squared_error(y_test, y_test_pred), 2))
print("Median absolute error =", round(sm.median_absolute_error(y_test, y_test_pred), 2))
print("Explain variance score =", round(sm.explained_variance_score(y_test, y_test_pred), 2))
print("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2))
輸出
Regressor model performance: Mean absolute error(MAE) = 1.78 Mean squared error(MSE) = 3.89 Median absolute error = 2.01 Explain variance score = -0.09 R2 score = -0.09
機器學習迴歸演算法的型別
最有用的和流行的機器學習迴歸演算法是線性迴歸演算法,它進一步分為兩種型別:
簡單線性迴歸演算法
多元線性迴歸演算法。
我們將在下一章討論它並在 Python 中實現它。
應用
機器學習迴歸演算法的應用如下:
預測或預測分析 - 迴歸的一個重要用途是預測或預測分析。例如,我們可以預測 GDP、油價或簡單來說是隨時間變化的定量資料。
最佳化 - 我們可以藉助迴歸來最佳化業務流程。例如,商店經理可以建立一個統計模型來了解客戶到來的高峰時間。
錯誤校正 - 在業務中,做出正確的決策與最佳化業務流程同等重要。迴歸也可以幫助我們做出正確的決策,以及糾正已實施的決策。
經濟學 - 它是經濟學中最常用的工具。我們可以使用迴歸來預測供應、需求、消費、庫存投資等。
金融 − 金融公司始終希望最小化投資組合風險,並想知道影響客戶的因素。所有這些都可以藉助迴歸模型進行預測。
迴歸演算法 - 線性迴歸
線性迴歸簡介
線性迴歸可以定義為一種統計模型,它分析因變數與給定的一組自變數之間的線性關係。變數之間的線性關係意味著,當一個或多個自變數的值發生變化(增加或減少)時,因變數的值也會相應地發生變化(增加或減少)。
從數學上講,這種關係可以用以下方程表示:
Y = mX + b
這裡,Y 是我們試圖預測的因變數
X 是我們用來進行預測的自變數。
m 是迴歸線的斜率,表示 X 對 Y 的影響
b 是一個常數,稱為 Y 截距。如果 X = 0,則 Y 等於 b。
此外,線性關係可以是正向的或負向的,如下所述:
正線性關係
如果自變數和因變數都增加,則線性關係稱為正線性關係。這可以透過以下圖形理解:

負線性關係
如果自變數增加而因變數減少,則線性關係稱為負線性關係。這可以透過以下圖形理解:

線性迴歸的型別
線性迴歸主要分為以下兩種型別:
簡單線性迴歸
多元線性迴歸
簡單線性迴歸 (SLR)
它是線性迴歸最基本的版本,使用單個特徵預測響應。SLR 的假設是這兩個變數之間存線上性關係。
Python 實現
我們可以透過兩種方式在 Python 中實現 SLR,一種是提供您自己的資料集,另一種是使用 scikit-learn Python 庫中的資料集。
示例 1 − 在以下 Python 實現示例中,我們使用自己的資料集。
首先,我們將從匯入必要的包開始,如下所示:
%matplotlib inline import numpy as np import matplotlib.pyplot as plt
接下來,定義一個函式,該函式將計算 SLR 的重要值:
def coef_estimation(x, y):
以下指令碼行將給出觀測值的數量 n:
n = np.size(x)
x 和 y 向量的平均值可以計算如下:
m_x, m_y = np.mean(x), np.mean(y)
我們可以找到交叉偏差和關於 x 的偏差,如下所示:
SS_xy = np.sum(y*x) - n*m_y*m_x SS_xx = np.sum(x*x) - n*m_x*m_x
接下來,迴歸係數,即 b 可以計算如下:
b_1 = SS_xy / SS_xx b_0 = m_y - b_1*m_x return(b_0, b_1)
接下來,我們需要定義一個函式,該函式將繪製迴歸線並預測響應向量:
def plot_regression_line(x, y, b):
以下指令碼行將實際點繪製為散點圖:
plt.scatter(x, y, color = "m", marker = "o", s = 30)
以下指令碼行將預測響應向量:
y_pred = b[0] + b[1]*x
以下指令碼行將繪製迴歸線並在其上新增標籤:
plt.plot(x, y_pred, color = "g")
plt.xlabel('x')
plt.ylabel('y')
plt.show()
最後,我們需要定義 main() 函式來提供資料集並呼叫我們上面定義的函式:
def main():
x = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
y = np.array([100, 300, 350, 500, 750, 800, 850, 900, 1050, 1250])
b = coef_estimation(x, y)
print("Estimated coefficients:\nb_0 = {} \nb_1 = {}".format(b[0], b[1]))
plot_regression_line(x, y, b)
if __name__ == "__main__":
main()
輸出
Estimated coefficients: b_0 = 154.5454545454545 b_1 = 117.87878787878788
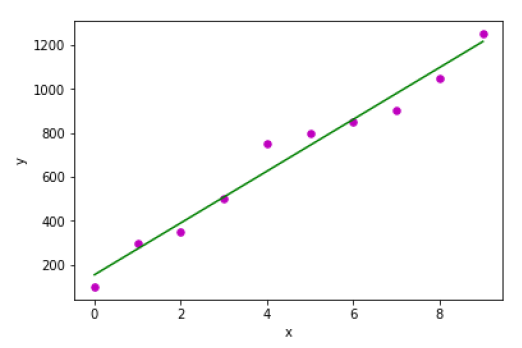
示例 2 − 在以下 Python 實現示例中,我們使用 scikit-learn 中的糖尿病資料集。
首先,我們將從匯入必要的包開始,如下所示:
%matplotlib inline import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model from sklearn.metrics import mean_squared_error, r2_score
接下來,我們將載入糖尿病資料集並建立其物件:
diabetes = datasets.load_diabetes()
由於我們正在實現 SLR,因此我們將只使用一個特徵,如下所示:
X = diabetes.data[:, np.newaxis, 2]
接下來,我們需要將資料拆分為訓練集和測試集,如下所示:
X_train = X[:-30] X_test = X[-30:]
接下來,我們需要將目標拆分為訓練集和測試集,如下所示:
y_train = diabetes.target[:-30] y_test = diabetes.target[-30:]
現在,要訓練模型,我們需要建立線性迴歸物件,如下所示:
regr = linear_model.LinearRegression()
接下來,使用訓練集訓練模型,如下所示:
regr.fit(X_train, y_train)
接下來,使用測試集進行預測,如下所示:
y_pred = regr.predict(X_test)
接下來,我們將列印一些係數,例如 MSE、方差分數等,如下所示:
print('Coefficients: \n', regr.coef_)
print("Mean squared error: %.2f"
% mean_squared_error(y_test, y_pred))
print('Variance score: %.2f' % r2_score(y_test, y_pred))
現在,繪製輸出,如下所示:
plt.scatter(X_test, y_test, color='blue') plt.plot(X_test, y_pred, color='red', linewidth=3) plt.xticks(()) plt.yticks(()) plt.show()
輸出
Coefficients: [941.43097333] Mean squared error: 3035.06 Variance score: 0.41

多元線性迴歸 (MLR)
它是簡單線性迴歸的擴充套件,使用兩個或多個特徵預測響應。從數學上講,我們可以解釋如下:
考慮一個具有 n 個觀測值、p 個特徵(即自變數)和 y 作為單個響應(即因變數)的資料集,則 p 個特徵的迴歸線可以計算如下:
$h(x_{i})=b_{0}+b_{1}x_{i1}+b_{2}x_{i2}+...+b_{p}x_{ip}$這裡,h(xi) 是預測的響應值,b0、b1、b2…、bp 是迴歸係數。
多元線性迴歸模型始終包括資料中的誤差,稱為殘差誤差,這會改變計算方式,如下所示:
$h(x_{i})=b_{0}+b_{1}x_{i1}+b_{2}x_{i2}+...+b_{p}x_{ip}+e_{i}$我們也可以將上述方程寫成如下形式:
$y_{i}=h(x_{i})+e_{i}$ 或 $e_{i}= y_{i} - h(x_{i})$Python 實現
在這個例子中,我們將使用 scikit learn 中的波士頓房價資料集:
首先,我們將從匯入必要的包開始,如下所示:
%matplotlib inline import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, metrics
接下來,載入資料集,如下所示:
boston = datasets.load_boston(return_X_y=False)
以下指令碼行將定義特徵矩陣 X 和響應向量 Y:
X = boston.data y = boston.target
接下來,將資料集拆分為訓練集和測試集,如下所示:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.7, random_state=1)
現在,建立線性迴歸物件並訓練模型,如下所示:
reg = linear_model.LinearRegression()
reg.fit(X_train, y_train)
print('Coefficients: \n', reg.coef_)
print('Variance score: {}'.format(reg.score(X_test, y_test)))
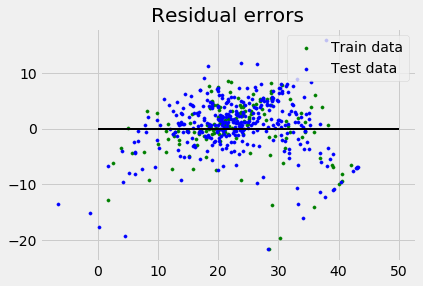
plt.style.use('fivethirtyeight')
plt.scatter(reg.predict(X_train), reg.predict(X_train) - y_train,
color = "green", s = 10, label = 'Train data')
plt.scatter(reg.predict(X_test), reg.predict(X_test) - y_test,
color = "blue", s = 10, label = 'Test data')
plt.hlines(y = 0, xmin = 0, xmax = 50, linewidth = 2)
plt.legend(loc = 'upper right')
plt.title("Residual errors")
plt.show()
輸出
Coefficients: [-1.16358797e-01 6.44549228e-02 1.65416147e-01 1.45101654e+00 -1.77862563e+01 2.80392779e+00 4.61905315e-02 -1.13518865e+00 3.31725870e-01 -1.01196059e-02 -9.94812678e-01 9.18522056e-03 -7.92395217e-01] Variance score: 0.709454060230326
假設
以下是線性迴歸模型對資料集做出的一些假設:
多重共線性 − 線性迴歸模型假設資料中幾乎沒有或沒有多重共線性。基本上,當自變數或特徵之間存在依賴關係時,就會發生多重共線性。
自相關 − 線性迴歸模型假設的另一個假設是資料中幾乎沒有或沒有自相關。基本上,當殘差誤差之間存在依賴關係時,就會發生自相關。
變數之間的關係 − 線性迴歸模型假設響應變數和特徵變數之間的關係必須是線性的。
聚類演算法 - 概述
聚類簡介
聚類方法是最有用的無監督機器學習方法之一。這些方法用於查詢資料樣本之間的相似性和關係模式,然後根據特徵將這些樣本聚類到具有相似性的組中。
聚類很重要,因為它確定了當前未標記資料中固有的分組。它們基本上對資料點做出一些假設來構成它們的相似性。每個假設將構建不同的但同樣有效的聚類。
例如,下圖顯示了聚類系統將相似型別的資料組合到不同聚類中的情況:

聚類形成方法
聚類不一定以球形形式形成。以下是其他一些聚類形成方法:
基於密度的
在這些方法中,聚類形成密集區域。這些方法的優點是它們具有良好的準確性和合並兩個聚類的能力。例如,基於密度的噪聲應用空間聚類 (DBSCAN)、用於識別聚類結構的排序點 (OPTICS) 等。
基於層次的
在這些方法中,聚類形成樹狀結構,基於層次結構。它們有兩個類別,即凝聚的(自下而上的方法)和分裂的(自上而下的方法)。例如,使用代表的聚類 (CURE)、基於層次結構的平衡迭代減少聚類 (BIRCH) 等。
劃分
在這些方法中,透過將物件劃分為 k 個聚類來形成聚類。聚類的數量將等於分割槽的數量。例如,K 均值、基於隨機搜尋的大型應用程式聚類 (CLARANS)。
網格
在這些方法中,聚類形成網格狀結構。這些方法的優點是所有在這些網格上進行的聚類操作都很快並且獨立於資料物件的數量。例如,統計資訊網格 (STING)、查詢聚類 (CLIQUE)。
衡量聚類效能
關於機器學習模型,最重要的考慮因素之一是評估其效能,或者您可以說模型的質量。在監督學習演算法的情況下,評估模型的質量很容易,因為我們已經為每個示例提供了標籤。
另一方面,在無監督學習演算法的情況下,我們沒有那麼幸運,因為我們處理的是未標記的資料。但我們仍然有一些指標可以使從業人員深入瞭解聚類變化如何根據演算法發生。
在我們深入研究這些指標之前,我們必須瞭解這些指標僅評估模型之間的比較效能,而不是衡量模型預測的有效性。以下是一些我們可以在聚類演算法上部署以衡量模型質量的指標:
輪廓分析
輪廓分析用於透過測量聚類之間的距離來檢查聚類模型的質量。它基本上為我們提供了一種透過輪廓分數來評估引數(如聚類數量)的方法。此分數衡量一個聚類中的每個點與相鄰聚類中的點的接近程度。
輪廓分數分析
輪廓分數的範圍是 [-1, 1]。其分析如下:
+1 分數 − 接近 +1 的輪廓分數表明樣本遠離其相鄰聚類。
0 分數 − 0 的輪廓分數表明樣本位於或非常靠近分隔兩個相鄰聚類的決策邊界。
-1 分數 &minusl -1 的輪廓分數表明樣本已被分配到錯誤的聚類。
輪廓分數的計算可以使用以下公式進行:
𝒔𝒊𝒍𝒉𝒐𝒖𝒆𝒕𝒕𝒆 𝒔𝒄𝒐𝒓𝒆=(𝒑−𝒒)/𝐦𝐚𝐱 (𝒑,𝒒)
這裡,𝑝 = 到最近聚類中點的平均距離
並且,𝑞 = 到所有點的平均聚類內距離。
戴維斯-鮑爾丁指數
DB 指數是另一個用於執行聚類演算法分析的良好指標。藉助 DB 指數,我們可以瞭解以下關於聚類模型的要點:
聚類是否彼此良好地間隔開?
聚類有多密集?
我們可以使用以下公式計算 DB 指數:
$DB=\frac{1}{n}\displaystyle\sum\limits_{i=1}^n max_{j\neq{i}}\left(\frac{\sigma_{i}+\sigma_{j}}{d(c_{i},c_{j})}\right)$這裡,𝑛 = 聚類數量
σi = 聚類 𝑖 中所有點到聚類質心 𝑐𝑖 的平均距離。
DB 指數越小,聚類模型越好。
鄧恩指數
它的工作原理與 DB 指數相同,但以下幾點是兩者不同之處:
Dunn 指數只考慮最壞情況,即距離較近的簇,而 DB 指數則考慮聚類模型中所有簇的離散度和分離度。
Dunn 指數隨著效能的提高而增加,而 DB 指數在簇分佈良好且密集時效果更好。
我們可以使用以下公式計算 Dunn 指數:
$D=\frac{min_{1\leq i <{j}\leq{n}}P(i,j)}{mix_{1\leq i < k \leq n}q(k)}$這裡,𝑖、𝑗、𝑘 = 每個簇的索引
𝑝 = 簇間距離
q = 簇內距離
機器學習聚類演算法型別
以下是最重要的和有用的機器學習聚類演算法:
K 均值聚類
此聚類演算法計算質心並迭代,直到找到最佳質心。它假設簇的數量已知。它也被稱為扁平聚類演算法。演算法從資料中識別出的簇的數量在 K 均值中用“K”表示。
均值漂移演算法
它是另一種用於無監督學習的強大聚類演算法。與 K 均值聚類不同,它不作任何假設,因此它是一種非引數演算法。
層次聚類
它是另一種無監督學習演算法,用於將具有相似特徵的未標記資料點分組。
我們將在後續章節中詳細討論所有這些演算法。
聚類的應用
我們可以在以下領域發現聚類很有用:
資料彙總和壓縮 - 聚類廣泛應用於需要資料彙總、壓縮和降維的領域。例如影像處理和向量量化。
協同系統和客戶細分 - 由於聚類可用於查詢類似產品或相同型別的使用者,因此可用於協同系統和客戶細分領域。
作為其他資料探勘任務的關鍵中間步驟 - 聚類分析可以生成資料的緊湊摘要,用於分類、測試、假設生成;因此,它也作為其他資料探勘任務的關鍵中間步驟。
動態資料中的趨勢檢測 - 聚類還可以透過對相似趨勢進行各種聚類來用於動態資料中的趨勢檢測。
社交網路分析 - 聚類可以用於社交網路分析。例如,在影像、影片或音訊中生成序列。
生物資料分析 - 聚類還可以用於對影像、影片進行聚類,因此可以成功地用於生物資料分析。
聚類演算法 - K 均值演算法
K 均值演算法簡介
K 均值聚類演算法計算質心並迭代,直到找到最佳質心。它假設簇的數量已知。它也被稱為扁平聚類演算法。演算法從資料中識別出的簇的數量在 K 均值中用“K”表示。
在此演算法中,資料點被分配到一個簇中,以使資料點和質心之間平方距離之和最小。需要理解的是,簇內差異越小,同一個簇內的資料點越相似。
K 均值演算法的工作原理
我們可以藉助以下步驟瞭解 K 均值聚類演算法的工作原理:
步驟 1 - 首先,我們需要指定此演算法需要生成的簇的數量 K。
步驟 2 - 接下來,隨機選擇 K 個數據點並將每個資料點分配到一個簇中。簡單來說,就是根據資料點的數量對資料進行分類。
步驟 3 - 現在它將計算簇質心。
步驟 4 - 接下來,繼續迭代以下操作,直到我們找到最佳質心,即資料點分配到不再更改的簇中:
4.1 - 首先,將計算資料點和質心之間平方距離之和。
4.2 - 現在,我們必須將每個資料點分配到比其他簇(質心)更近的簇。
4.3 - 最後,透過取該簇中所有資料點的平均值來計算簇的質心。
K 均值採用期望最大化方法來解決問題。期望步驟用於將資料點分配到最近的簇,最大化步驟用於計算每個簇的質心。
在使用 K 均值演算法時,我們需要注意以下事項:
在使用包括 K 均值在內的聚類演算法時,建議對資料進行標準化,因為此類演算法使用基於距離的度量來確定資料點之間的相似性。
由於 K 均值的迭代性質和質心的隨機初始化,K 均值可能會陷入區域性最優,可能不會收斂到全域性最優。因此,建議使用不同的質心初始化。
Python 中的實現
以下兩個實現 K 均值聚類演算法的示例將有助於我們更好地理解它:
示例 1
這是一個簡單的示例,用於瞭解 k 均值的工作原理。在此示例中,我們將首先生成包含 4 個不同斑點的 2D 資料集,然後應用 k 均值演算法檢視結果。
首先,我們將從匯入必要的包開始:
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans
以下程式碼將生成包含四個斑點的 2D 資料集:
from sklearn.datasets.samples_generator import make_blobs X, y_true = make_blobs(n_samples=400, centers=4, cluster_std=0.60, random_state=0)
接下來,以下程式碼將幫助我們視覺化資料集:
plt.scatter(X[:, 0], X[:, 1], s=20); plt.show()
接下來,建立一個 KMeans 物件並提供簇的數量,訓練模型並進行預測,如下所示:
kmeans = KMeans(n_clusters=4) kmeans.fit(X) y_kmeans = kmeans.predict(X)
現在,藉助以下程式碼,我們可以繪製和視覺化 k 均值 Python 估計器選擇的簇中心:
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=20, cmap='summer') centers = kmeans.cluster_centers_ plt.scatter(centers[:, 0], centers[:, 1], c='blue', s=100, alpha=0.9); plt.show()

示例 2
讓我們轉向另一個示例,在這個示例中,我們將對簡單的數字資料集應用 K 均值聚類。K 均值將嘗試識別相似的數字,而無需使用原始標籤資訊。
首先,我們將從匯入必要的包開始:
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans
接下來,從 sklearn 載入數字資料集並建立一個物件。我們還可以找到此資料集中行數和列數,如下所示:
from sklearn.datasets import load_digits digits = load_digits() digits.data.shape
輸出
(1797, 64)
以上輸出顯示此資料集有 1797 個樣本,64 個特徵。
我們可以像在上面的示例 1 中一樣執行聚類:
kmeans = KMeans(n_clusters=10, random_state=0) clusters = kmeans.fit_predict(digits.data) kmeans.cluster_centers_.shape
輸出
(10, 64)
以上輸出顯示 K 均值建立了 10 個簇,64 個特徵。
fig, ax = plt.subplots(2, 5, figsize=(8, 3)) centers = kmeans.cluster_centers_.reshape(10, 8, 8) for axi, center in zip(ax.flat, centers): axi.set(xticks=[], yticks=[]) axi.imshow(center, interpolation='nearest', cmap=plt.cm.binary)
輸出
作為輸出,我們將獲得以下影像,顯示 k 均值學習的簇中心。

以下程式碼行將學習到的簇標籤與其中找到的真實標籤匹配:
from scipy.stats import mode labels = np.zeros_like(clusters) for i in range(10): mask = (clusters == i) labels[mask] = mode(digits.target[mask])[0]
接下來,我們可以檢查準確率,如下所示:
from sklearn.metrics import accuracy_score accuracy_score(digits.target, labels)
輸出
0.7935447968836951
以上輸出顯示準確率約為 80%。
優點和缺點
優點
以下是 K 均值聚類演算法的一些優點:
它非常容易理解和實現。
如果我們有大量變數,那麼 K 均值將比層次聚類更快。
在重新計算質心時,例項可以更改簇。
與層次聚類相比,K 均值形成的簇更緊密。
缺點
以下是 K 均值聚類演算法的一些缺點:
很難預測簇的數量,即 k 的值。
輸出受初始輸入(如簇的數量(k 的值))的強烈影響。
資料的順序將對最終輸出產生強烈影響。
它對重新縮放非常敏感。如果我們透過歸一化或標準化重新縮放資料,則輸出將完全改變。最終輸出。
如果簇具有複雜的幾何形狀,則它不適合執行聚類任務。
K 均值聚類演算法的應用
聚類分析的主要目標是:
從我們正在處理的資料中獲得有意義的直覺。
先聚類後預測,其中將為不同的子組構建不同的模型。
為了實現上述目標,K 均值聚類表現得足夠好。它可用於以下應用:
市場細分
文件聚類
影像分割
影像壓縮
客戶細分
分析動態資料的趨勢
聚類演算法 - 均值漂移演算法
均值漂移演算法簡介
如前所述,它是另一種用於無監督學習的強大聚類演算法。與 K 均值聚類不同,它不作任何假設;因此它是一種非引數演算法。
均值漂移演算法基本上透過將點移向資料點密度最高的位置(即簇質心)來迭代地將資料點分配到簇中。
K 均值演算法和均值漂移演算法的區別在於,後者不需要預先指定簇的數量,因為簇的數量將由演算法根據資料確定。
均值漂移演算法的工作原理
我們可以藉助以下步驟瞭解均值漂移聚類演算法的工作原理:
步驟 1 - 首先,從將資料點分配到它們自己的簇開始。
步驟 2 - 接下來,此演算法將計算質心。
步驟 3 - 在此步驟中,將更新新質心位置。
步驟 4 - 現在,該過程將迭代並移動到更高密度的區域。
步驟 5 - 最後,一旦質心到達無法進一步移動的位置,它將停止。
Python 中的實現
這是一個簡單的示例,用於瞭解均值漂移演算法的工作原理。在此示例中,我們將首先生成包含 4 個不同斑點的 2D 資料集,然後應用均值漂移演算法檢視結果。
%matplotlib inline
import numpy as np
from sklearn.cluster import MeanShift
import matplotlib.pyplot as plt
from matplotlib import style
style.use("ggplot")
from sklearn.datasets.samples_generator import make_blobs
centers = [[3,3,3],[4,5,5],[3,10,10]]
X, _ = make_blobs(n_samples = 700, centers = centers, cluster_std = 0.5)
plt.scatter(X[:,0],X[:,1])
plt.show()
ms = MeanShift()
ms.fit(X)
labels = ms.labels_
cluster_centers = ms.cluster_centers_
print(cluster_centers)
n_clusters_ = len(np.unique(labels))
print("Estimated clusters:", n_clusters_)
colors = 10*['r.','g.','b.','c.','k.','y.','m.']
for i in range(len(X)):
plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize = 3)
plt.scatter(cluster_centers[:,0],cluster_centers[:,1],
marker=".",color='k', s=20, linewidths = 5, zorder=10)
plt.show()
輸出
[[ 2.98462798 9.9733794 10.02629344] [ 3.94758484 4.99122771 4.99349433] [ 3.00788996 3.03851268 2.99183033]] Estimated clusters: 3
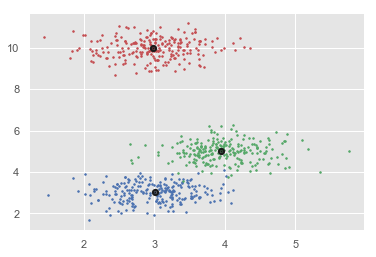
優點和缺點
優點
以下是均值漂移聚類演算法的一些優點:
它不需要像 K 均值或高斯混合那樣進行任何模型假設。
它還可以對具有非凸形狀的複雜簇進行建模。
它只需要一個名為頻寬的引數,該引數會自動確定簇的數量。
沒有像 K 均值那樣的區域性最小值問題。
沒有異常值生成的問題。
缺點
以下是均值漂移聚類演算法的一些缺點:
在高維情況下,均值漂移演算法效果不佳,其中簇的數量突然變化。
我們無法直接控制簇的數量,但在某些應用中,我們需要特定數量的簇。
它無法區分有意義和無意義的模式。
聚類演算法 - 層次聚類
層次聚類簡介
層次聚類是另一種無監督學習演算法,用於將具有相似特徵的未標記資料點分組在一起。層次聚類演算法分為以下兩類:
凝聚層次演算法 − 在凝聚層次演算法中,每個資料點都被視為一個單獨的簇,然後依次合併或凝聚(自下而上方法)成對的簇。簇的層次結構表示為樹狀圖或樹形結構。
分裂層次演算法 − 另一方面,在分裂層次演算法中,所有資料點都被視為一個大的簇,聚類過程包括將一個大的簇劃分為各種小的簇(自上而下方法)。
執行凝聚層次聚類的步驟
我們將解釋最常用和最重要的層次聚類,即凝聚層次聚類。執行該演算法的步驟如下:
步驟1 − 將每個資料點視為單個簇。因此,我們開始時將有,比如說K個簇。開始時資料點的數量也將是K。
步驟2 − 現在,在此步驟中,我們需要透過連線兩個最接近的資料點來形成一個大的簇。這將導致總共有K-1個簇。
步驟3 − 現在,為了形成更多簇,我們需要連線兩個最接近的簇。這將導致總共有K-2個簇。
步驟4 − 現在,為了形成一個大的簇,重複以上三個步驟,直到K變為0,即沒有更多的資料點可以連線。
步驟5 − 最後,在形成一個大的簇之後,將使用樹狀圖根據問題將其劃分為多個簇。
樹狀圖在凝聚層次聚類中的作用
正如我們在上一步中討論的那樣,樹狀圖的作用是在形成大的簇之後開始。樹狀圖將用於根據我們的問題將簇拆分為多個相關的簇。可以透過以下示例理解:
示例 1
為了理解,讓我們從匯入所需的庫開始,如下所示:
%matplotlib inline import matplotlib.pyplot as plt import numpy as np
接下來,我們將繪製我們在此示例中使用的點:
X = np.array([[7,8],[12,20],[17,19],[26,15],[32,37],[87,75],[73,85], [62,80],[73,60],[87,96],]) labels = range(1, 11) plt.figure(figsize=(10, 7)) plt.subplots_adjust(bottom=0.1) plt.scatter(X[:,0],X[:,1], label='True Position') for label, x, y in zip(labels, X[:, 0], X[:, 1]): plt.annotate(label,xy=(x, y), xytext=(-3, 3),textcoords='offset points', ha='right', va='bottom') plt.show()

從上圖可以很容易地看出,我們的資料點中有兩個簇,但在現實世界的資料中,可能會有數千個簇。接下來,我們將使用Scipy庫繪製資料點的樹狀圖:
from scipy.cluster.hierarchy import dendrogram, linkage from matplotlib import pyplot as plt linked = linkage(X, 'single') labelList = range(1, 11) plt.figure(figsize=(10, 7)) dendrogram(linked, orientation='top',labels=labelList, distance_sort='descending',show_leaf_counts=True) plt.show()

現在,一旦形成大的簇,就會選擇最長的垂直距離。然後透過它繪製一條垂直線,如下面的圖所示。由於水平線在兩點處與藍線相交,因此簇的數量將為兩個。
接下來,我們需要匯入用於聚類的類並呼叫其fit_predict方法來預測簇。我們正在匯入sklearn.cluster庫的AgglomerativeClustering類:
from sklearn.cluster import AgglomerativeClustering cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward') cluster.fit_predict(X)
接下來,使用以下程式碼繪製簇:
plt.scatter(X[:,0],X[:,1], c=cluster.labels_, cmap='rainbow')

上圖顯示了我們資料點中的兩個簇。
示例2
正如我們從上面討論的簡單示例中理解了樹狀圖的概念,讓我們繼續另一個示例,其中我們使用層次聚類建立Pima印第安人糖尿病資料集中的資料點的簇:
import matplotlib.pyplot as plt import pandas as pd %matplotlib inline import numpy as np from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values X = array[:,0:8] Y = array[:,8] data.shape (768, 9) data.head()
| 序號 | 懷孕次數 | 葡萄糖 | 血壓 | 皮膚厚度 | 胰島素 | BMI | 糖尿病譜系功能 | 年齡 | 類別 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
patient_data = data.iloc[:, 3:5].values
import scipy.cluster.hierarchy as shc
plt.figure(figsize=(10, 7))
plt.title("Patient Dendograms")
dend = shc.dendrogram(shc.linkage(data, method='ward'))
from sklearn.cluster import AgglomerativeClustering cluster = AgglomerativeClustering(n_clusters=4, affinity='euclidean', linkage='ward') cluster.fit_predict(patient_data) plt.figure(figsize=(10, 7)) plt.scatter(patient_data[:,0], patient_data[:,1], c=cluster.labels_, cmap='rainbow')
KNN演算法 - 尋找最近鄰
介紹
K近鄰(KNN)演算法是一種監督式機器學習演算法,可用於分類和迴歸預測問題。但是,它主要用於行業中的分類預測問題。以下兩個屬性可以很好地定義KNN:
懶惰學習演算法 − KNN是一種懶惰學習演算法,因為它沒有專門的訓練階段,並在分類時使用所有資料進行訓練。
非引數學習演算法 − KNN也是一種非引數學習演算法,因為它不假設任何關於底層資料的資訊。
KNN演算法的工作原理
K近鄰(KNN)演算法使用“特徵相似性”來預測新資料點的值,這進一步意味著新資料點將根據其與訓練集中點的匹配程度分配一個值。我們可以透過以下步驟瞭解其工作原理:
步驟1 − 要實現任何演算法,都需要資料集。因此,在KNN的第一步中,我們必須載入訓練資料和測試資料。
步驟2 − 接下來,我們需要選擇K的值,即最近的資料點。K可以是任何整數。
步驟3 − 對於測試資料中的每個點,執行以下操作:
3.1 − 使用任何方法(例如:歐幾里得距離、曼哈頓距離或漢明距離)計算測試資料與訓練資料每一行的距離。計算距離最常用的方法是歐幾里得距離。
3.2 − 現在,根據距離值,按升序對它們進行排序。
3.3 − 接下來,它將從排序陣列中選擇前K行。
3.4 − 現在,它將根據這些行的最頻繁類別為測試點分配一個類別。
步驟4 − 結束
示例
以下是一個示例,用於理解K的概念和KNN演算法的工作原理:
假設我們有一個數據集,可以繪製如下:
現在,我們需要將新的資料點(黑色點,在點60,60處)分類為藍色或紅色類別。我們假設K=3,即它將找到三個最近的資料點。這在下圖中顯示:
我們可以在上圖中看到黑色點資料點的三個最近鄰。在這三個中,有兩個屬於紅色類別,因此黑色點也將分配到紅色類別。
Python 中的實現
眾所周知,K近鄰(KNN)演算法可用於分類和迴歸。以下是使用KNN作為分類器和迴歸器的Python程式碼:
KNN作為分類器
首先,從匯入必要的 Python 包開始:
import numpy as np import matplotlib.pyplot as plt import pandas as pd
接下來,從其網路連結下載 iris 資料集,如下所示:
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
接下來,我們需要為資料集分配列名,如下所示:
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
現在,我們需要將資料集讀取到 pandas 資料框中,如下所示:
dataset = pd.read_csv(path, names=headernames) dataset.head()
| 序號 | 萼片長度 | 萼片寬度 | 花瓣長度 | 花瓣寬度 | 類別 |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
資料預處理將藉助以下指令碼行完成:
X = dataset.iloc[:, :-1].values y = dataset.iloc[:, 4].values
接下來,我們將資料劃分為訓練集和測試集。以下程式碼將資料集劃分為60%的訓練資料和40%的測試資料:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.40)
接下來,將執行資料縮放,如下所示:
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaler.fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test)
接下來,使用sklearn的KNeighborsClassifier類訓練模型,如下所示:
from sklearn.neighbors import KNeighborsClassifier classifier = KNeighborsClassifier(n_neighbors=8) classifier.fit(X_train, y_train)
最後,我們需要進行預測。這可以透過以下指令碼完成:
y_pred = classifier.predict(X_test)
接下來,列印結果,如下所示:
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
result = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(result)
result1 = classification_report(y_test, y_pred)
print("Classification Report:",)
print (result1)
result2 = accuracy_score(y_test,y_pred)
print("Accuracy:",result2)
輸出
Confusion Matrix:
[[21 0 0]
[ 0 16 0]
[ 0 7 16]]
Classification Report:
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 21
Iris-versicolor 0.70 1.00 0.82 16
Iris-virginica 1.00 0.70 0.82 23
micro avg 0.88 0.88 0.88 60
macro avg 0.90 0.90 0.88 60
weighted avg 0.92 0.88 0.88 60
Accuracy: 0.8833333333333333
KNN作為迴歸器
首先,從匯入必要的 Python 包開始:
import numpy as np import pandas as pd
接下來,從其網路連結下載 iris 資料集,如下所示:
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
接下來,我們需要為資料集分配列名,如下所示:
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
現在,我們需要將資料集讀取到 pandas 資料框中,如下所示:
data = pd.read_csv(url, names=headernames) array = data.values X = array[:,:2] Y = array[:,2] data.shape output:(150, 5)
接下來,從sklearn匯入KNeighborsRegressor以擬合模型:
from sklearn.neighbors import KNeighborsRegressor knnr = KNeighborsRegressor(n_neighbors=10) knnr.fit(X, y)
最後,我們可以找到MSE,如下所示:
print ("The MSE is:",format(np.power(y-knnr.predict(X),2).mean()))
輸出
The MSE is: 0.12226666666666669
KNN的優缺點
優點
這是一個非常容易理解和解釋的演算法。
它對非線性資料非常有用,因為此演算法不對資料做出任何假設。
它是一種通用的演算法,因為我們可以將其用於分類和迴歸。
它具有相對較高的準確性,但與KNN相比,還有更好的監督學習模型。
缺點
它在計算上是一個稍微昂貴的演算法,因為它儲存所有訓練資料。
與其他監督學習演算法相比,需要較高的記憶體儲存。
如果N很大,預測速度會很慢。
它對資料的尺度和無關特徵非常敏感。
KNN的應用
以下是一些KNN可以成功應用的領域:
銀行系統
KNN可用於銀行系統中預測個人是否適合貸款審批?該個人是否具有與違約者相似的特徵?
計算信用評級
KNN演算法可用於透過與具有相似特徵的人進行比較來查找個人的信用評級。
政治
藉助KNN演算法,我們可以將潛在選民分類為不同的類別,例如“將投票”、“將不投票”、“將投票給國大黨”、“將投票給人民黨”。
KNN演算法可用於的其他領域包括語音識別、手寫識別、影像識別和影片識別。
機器學習 - 效能指標
我們可以使用各種指標來評估機器學習演算法的效能,包括分類演算法和迴歸演算法。我們必須仔細選擇用於評估機器學習效能的指標,因為:
機器學習演算法的效能如何衡量和比較將完全取決於您選擇的指標。
您如何權衡結果中各種特徵的重要性將完全受您選擇的指標影響。
分類問題的效能指標
我們在前面的章節中討論了分類及其演算法。在這裡,我們將討論可用於評估分類問題預測的各種效能指標。
混淆矩陣
它是衡量分類問題效能的最簡單方法,其中輸出可以是兩種或多種型別的類別。混淆矩陣不過是一個二維表,即“實際”和“預測”,此外,這兩個維度都有“真陽性 (TP)”、“真陰性 (TN)”、“假陽性 (FP)”、“假陰性 (FN)”如下所示 -

與混淆矩陣相關的術語解釋如下:
真陽性 (TP) - 當資料點的實際類別和預測類別均為 1 時。
真陰性 (TN) - 當資料點的實際類別和預測類別均為 0 時。
假陽性 (FP) - 當資料點的實際類別為 0 且預測類別為 1 時。
假陰性 (FN) - 當資料點的實際類別為 1 且預測類別為 0 時。
我們可以使用sklearn.metrics的confusion_matrix函式來計算分類模型的混淆矩陣。
分類準確率
它是分類演算法最常見的效能指標。可以將其定義為正確預測的數量與所有預測數量的比率。我們可以使用以下公式透過混淆矩陣輕鬆計算它:
$Accuracy =\frac{TP+TN}{𝑇𝑃+𝐹𝑃+𝐹𝑁+𝑇𝑁}$我們可以使用sklearn.metrics的accuracy_score函式來計算分類模型的準確率。
分類報告
此報告包含精確率、召回率、F1分數和支援度的分數。解釋如下:
精確率
精確率,在文件檢索中使用,可以定義為我們的 ML 模型返回的正確文件的數量。我們可以很容易地透過混淆矩陣使用以下公式計算它 -
$Precision=\frac{TP}{TP+FP}$召回率或靈敏度
召回率可以定義為我們的 ML 模型返回的陽性數量。我們可以很容易地透過混淆矩陣使用以下公式計算它 -
$Recall =\frac{TP}{TP+FN}$特異性
特異性,與召回率相反,可以定義為我們的 ML 模型返回的陰性數量。我們可以很容易地透過混淆矩陣使用以下公式計算它 -
$Specificity =\frac{TN}{TN+FP}$支援度
支援度可以定義為位於目標值每個類別中的真實響應樣本的數量。
F1分數
此分數將提供精確率和召回率的調和平均值。在數學上,F1分數是精確率和召回率的加權平均值。F1的最佳值為1,最差值為0。我們可以使用以下公式計算F1分數:
𝑭𝟏 = 𝟐 ∗ (𝒑𝒓𝒆𝒄𝒊𝒔𝒊𝒐𝒏 ∗ 𝒓𝒆𝒄𝒂𝒍𝒍) / (𝒑𝒓𝒆𝒄𝒊𝒔𝒊𝒐𝒏 + 𝒓𝒆𝒄𝒂𝒍𝒍)
F1分數對精確率和召回率具有相等的相對貢獻。
我們可以使用sklearn.metrics的classification_report函式獲取分類模型的分類報告。
AUC(ROC曲線下面積)
AUC(曲線下面積)-ROC(受試者工作特徵)是一種用於分類問題的效能指標,它基於不同的閾值。顧名思義,ROC是一條機率曲線,而AUC衡量的是可分離性。簡單來說,AUC-ROC指標可以告訴我們模型區分不同類別的能力。AUC越高,模型越好。
在數學上,它可以透過繪製TPR(真正率),即靈敏度或召回率,與FPR(假正率),即1-特異度,在不同閾值下的曲線來建立。下圖顯示了ROC,AUC,其中y軸為TPR,x軸為FPR:
我們可以使用sklearn.metrics中的roc_auc_score函式來計算AUC-ROC。
LOGLOSS(對數損失)
它也稱為邏輯迴歸損失或交叉熵損失。它基本上定義在機率估計上,並衡量分類模型的效能,其中輸入是一個介於0和1之間的機率值。透過將其與準確率進行區分,可以更清楚地理解它。我們知道準確率是我們模型中預測值等於實際值的預測次數,而對數損失是我們預測的不確定性,基於它與實際標籤的差異程度。藉助對數損失值,我們可以更準確地瞭解模型的效能。我們可以使用sklearn.metrics中的log_loss函式來計算對數損失。
示例
下面是一個簡單的Python示例,它可以讓我們瞭解如何在二元分類模型上使用上述效能指標:
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from sklearn.metrics import roc_auc_score
from sklearn.metrics import log_loss
X_actual = [1, 1, 0, 1, 0, 0, 1, 0, 0, 0]
Y_predic = [1, 0, 1, 1, 1, 0, 1, 1, 0, 0]
results = confusion_matrix(X_actual, Y_predic)
print ('Confusion Matrix :')
print(results)
print ('Accuracy Score is',accuracy_score(X_actual, Y_predic))
print ('Classification Report : ')
print (classification_report(X_actual, Y_predic))
print('AUC-ROC:',roc_auc_score(X_actual, Y_predic))
print('LOGLOSS Value is',log_loss(X_actual, Y_predic))
輸出
Confusion Matrix :
[[3 3]
[1 3]]
Accuracy Score is 0.6
Classification Report :
precision recall f1-score support
0 0.75 0.50 0.60 6
1 0.50 0.75 0.60 4
micro avg 0.60 0.60 0.60 10
macro avg 0.62 0.62 0.60 10
weighted avg 0.65 0.60 0.60 10
AUC-ROC: 0.625
LOGLOSS Value is 13.815750437193334
迴歸問題的效能指標
我們在前面的章節中討論了迴歸及其演算法。在這裡,我們將討論可用於評估迴歸問題預測結果的各種效能指標。
平均絕對誤差(MAE)
這是迴歸問題中最簡單的誤差指標。它基本上是預測值和實際值之間絕對差值的平均和。簡單來說,透過MAE,我們可以瞭解預測的錯誤程度。MAE不指示模型的方向,即沒有關於模型的欠擬合或過擬合的指示。計算MAE的公式如下:
$MAE = \frac{1}{n}\sum|Y -\hat{Y}|$這裡,𝑌=實際輸出值
以及$\hat{Y}$=預測輸出值。
我們可以使用sklearn.metrics中的mean_absolute_error函式來計算MAE。
均方誤差(MSE)
MSE類似於MAE,但唯一的區別在於它在對所有差值求和之前,先對實際輸出值和預測輸出值之間的差值進行平方,而不是使用絕對值。在下面的等式中可以注意到差異:
$MSE = \frac{1}{n}\sum(Y -\hat{Y})^2$這裡,𝑌=實際輸出值
以及$\hat{Y}$ = 預測輸出值。
我們可以使用sklearn.metrics中的mean_squared_error函式來計算MSE。
R平方(R2)
R平方指標通常用於解釋目的,並提供一組預測輸出值與實際輸出值擬合優度的指示。下面的公式將幫助我們理解它:
$R^{2} = 1 -\frac{\frac{1}{n}\sum_{i{=1}}^n(Y_{i}-\hat{Y_{i}})^2}{\frac{1}{n}\sum_{i{=1}}^n(Y_{i}-\bar{Y_i})^2}$在上式中,分子是MSE,分母是𝑌值的方差。
我們可以使用sklearn.metrics中的r2_score函式來計算R平方值。
示例
下面是一個簡單的Python示例,它可以讓我們瞭解如何在迴歸模型上使用上述效能指標:
from sklearn.metrics import r2_score
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
X_actual = [5, -1, 2, 10]
Y_predic = [3.5, -0.9, 2, 9.9]
print ('R Squared =',r2_score(X_actual, Y_predic))
print ('MAE =',mean_absolute_error(X_actual, Y_predic))
print ('MSE =',mean_squared_error(X_actual, Y_predic))
輸出
R Squared = 0.9656060606060606 MAE = 0.42499999999999993 MSE = 0.5674999999999999
機器學習 - 自動工作流
介紹
為了成功地執行併產生結果,機器學習模型必須自動化一些標準的工作流。自動化這些標準工作流的過程可以透過Scikit-learn管道來完成。從資料科學家的角度來看,管道是一個通用但非常重要的概念。它基本上允許資料從其原始格式流向一些有用的資訊。可以透過下圖瞭解管道的運作方式:

ML管道的模組如下:
資料攝取 - 顧名思義,它是匯入資料以用於ML專案的過程。資料可以即時或批次地從單個或多個系統中提取。這是最具挑戰性的步驟之一,因為資料的質量會影響整個ML模型。
資料準備 - 匯入資料後,我們需要準備資料以用於我們的ML模型。資料預處理是資料準備中最重要的技術之一。
ML模型訓練 - 下一步是訓練我們的ML模型。我們有各種ML演算法,如監督學習、無監督學習、強化學習,可以從資料中提取特徵並進行預測。
模型評估 - 接下來,我們需要評估ML模型。在AutoML管道的情況下,ML模型可以透過各種統計方法和業務規則進行評估。
ML模型再訓練 - 在AutoML管道的情況下,第一個模型不一定是最好的模型。第一個模型被視為基線模型,我們可以重複訓練它以提高模型的準確性。
部署 - 最後,我們需要部署模型。此步驟涉及將模型應用並遷移到業務運營以供其使用。
ML管道伴隨的挑戰
為了建立ML管道,資料科學家面臨著許多挑戰。這些挑戰分為以下三類:
資料質量
任何ML模型的成功都嚴重依賴於資料的質量。如果我們提供給ML模型的資料不準確、不可靠和穩健,那麼我們將得到錯誤或誤導性的輸出。
資料可靠性
與ML管道相關的另一個挑戰是我們提供給ML模型的資料的可靠性。眾所周知,資料科學家可以從各種來源獲取資料,但為了獲得最佳結果,必須確保資料來源是可靠和可信的。
資料可訪問性
為了從ML管道中獲得最佳結果,資料本身必須是可訪問的,這需要對資料進行整合、清洗和整理。由於資料可訪問性屬性,元資料將使用新標籤進行更新。
ML管道和資料準備建模
資料洩漏,從訓練資料集到測試資料集,是資料科學家在準備ML模型資料時需要處理的一個重要問題。通常,在資料準備時,資料科學家會在學習之前對整個資料集使用標準化或歸一化等技術。但是,這些技術無法幫助我們防止資料洩漏,因為訓練資料集會受到測試資料集中資料規模的影響。
透過使用ML管道,我們可以防止這種資料洩漏,因為管道確保資料準備(如標準化)僅限於交叉驗證過程的每個摺疊。
示例
以下是一個Python示例,演示資料準備和模型評估工作流。為此,我們使用Sklearn中的Pima印第安人糖尿病資料集。首先,我們將建立一個標準化資料的管道。然後建立一個線性判別分析模型,最後使用10折交叉驗證評估管道。
首先,匯入所需的包,如下所示:
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.preprocessing import StandardScaler from sklearn.pipeline import Pipeline from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
現在,我們需要載入Pima糖尿病資料集,就像在前面的示例中所做的那樣:
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values
接下來,我們將使用以下程式碼建立一個管道:
estimators = []
estimators.append(('standardize', StandardScaler()))
estimators.append(('lda', LinearDiscriminantAnalysis()))
model = Pipeline(estimators)
最後,我們將評估此管道並輸出其準確率,如下所示:
kfold = KFold(n_splits=20, random_state=7) results = cross_val_score(model, X, Y, cv=kfold) print(results.mean())
輸出
0.7790148448043184
上述輸出是資料集上設定的準確率摘要。
ML管道和特徵提取建模
資料洩漏也可能發生在ML模型的特徵提取步驟中。因此,特徵提取過程也應受到限制,以停止訓練資料集中的資料洩漏。與資料準備一樣,透過使用ML管道,我們也可以防止這種資料洩漏。FeatureUnion是ML管道提供的一個工具,可用於此目的。
示例
以下是一個Python示例,演示特徵提取和模型評估工作流。為此,我們使用Sklearn中的Pima印第安人糖尿病資料集。
首先,將使用PCA(主成分分析)提取3個特徵。然後,將使用統計分析提取6個特徵。在特徵提取之後,將使用
FeatureUnion工具組合多個特徵選擇和提取過程的結果。最後,將建立一個邏輯迴歸模型,並使用10折交叉驗證評估管道。
首先,匯入所需的包,如下所示:
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.pipeline import Pipeline from sklearn.pipeline import FeatureUnion from sklearn.linear_model import LogisticRegression from sklearn.decomposition import PCA from sklearn.feature_selection import SelectKBest
現在,我們需要載入Pima糖尿病資料集,就像在前面的示例中所做的那樣:
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values
接下來,將建立特徵聯合,如下所示:
features = []
features.append(('pca', PCA(n_components=3)))
features.append(('select_best', SelectKBest(k=6)))
feature_union = FeatureUnion(features)
接下來,將使用以下指令碼行建立管道:
estimators = []
estimators.append(('feature_union', feature_union))
estimators.append(('logistic', LogisticRegression()))
model = Pipeline(estimators)
最後,我們將評估此管道並輸出其準確率,如下所示:
kfold = KFold(n_splits=20, random_state=7) results = cross_val_score(model, X, Y, cv=kfold) print(results.mean())
輸出
0.7789811066126855
上述輸出是資料集上設定的準確率摘要。
改進機器學習模型的效能
整合方法效能改進
整合方法可以透過組合多個模型來提高機器學習結果。基本上,整合模型由幾個單獨訓練的監督學習模型組成,並且它們的預測結果以各種方式合併,以實現比單個模型更好的預測效能。整合方法可以分為以下兩組:
順序整合方法
顧名思義,在這種整合方法中,基學習器是按順序生成的。此類方法的動機是利用基學習器之間的依賴關係。
並行整合方法
顧名思義,在這種整合方法中,基學習器是並行生成的。此類方法的動機是利用基學習器之間的獨立性。
整合學習方法
以下是最流行的整合學習方法,即組合不同模型預測的方法:
Bagging
術語Bagging也稱為Bootstrap聚合。在Bagging方法中,整合模型試圖透過組合在隨機生成的訓練樣本上訓練的各個模型的預測來提高預測準確性和降低模型方差。整合模型的最終預測將透過計算所有單個估計器的預測的平均值來給出。Bagging方法的一個最佳示例是隨機森林。
Boosting
在Boosting方法中,構建整合模型的主要原理是透過按順序訓練每個基模型估計器來增量構建它。顧名思義,它基本上將多個弱基學習器(在訓練資料的多個迭代中按順序訓練)組合起來以構建強大的整合。在訓練弱基學習器期間,會為之前被錯誤分類的學習器分配更高的權重。Boosting方法的示例是AdaBoost。
投票
在這個整合學習模型中,構建了多種不同型別的模型,並使用一些簡單的統計方法(如計算平均值或中位數等)來組合預測結果。該預測將作為訓練的額外輸入以進行最終預測。
Bagging整合演算法
以下是三種Bagging整合演算法:
Bagged決策樹
眾所周知,Bagging 整合方法對於方差較大的演算法效果很好,其中決策樹演算法是最佳選擇之一。在下面的 Python 示例中,我們將使用 sklearn 的 BaggingClassifier 函式和 DecisionTreeClasifier(一種分類和迴歸樹演算法)在 Pima 印第安人糖尿病資料集上構建 Bagging 決策樹整合模型。
首先,匯入所需的包,如下所示:
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.ensemble import BaggingClassifier from sklearn.tree import DecisionTreeClassifier
現在,我們需要像之前示例中那樣載入 Pima 糖尿病資料集 -
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values X = array[:,0:8] Y = array[:,8]
接下來,如下所示,為 10 折交叉驗證提供輸入 -
seed = 7 kfold = KFold(n_splits=10, random_state=seed) cart = DecisionTreeClassifier()
我們需要提供要構建的樹的數量。這裡我們將構建 150 棵樹 -
num_trees = 150
接下來,使用以下指令碼構建模型 -
model = BaggingClassifier(base_estimator=cart, n_estimators=num_trees, random_state=seed)
計算並列印結果,如下所示 -
results = cross_val_score(model, X, Y, cv=kfold) print(results.mean())
輸出
0.7733766233766234
上面的輸出表明,我們 Bagging 決策樹分類器模型的準確率約為 77%。
隨機森林
它是 Bagging 決策樹的擴充套件。對於單個分類器,訓練資料集的樣本是帶放回地取樣的,但樹的構建方式可以降低它們之間的相關性。此外,在構建每棵樹時,會考慮特徵的隨機子集來選擇每個分割點,而不是貪婪地選擇最佳分割點。
在下面的 Python 示例中,我們將使用 sklearn 的 RandomForestClassifier 類在 Pima 印第安人糖尿病資料集上構建 Bagging 隨機森林整合模型。
首先,匯入所需的包,如下所示:
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.ensemble import RandomForestClassifier
現在,我們需要載入Pima糖尿病資料集,就像在前面的示例中所做的那樣:
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values X = array[:,0:8] Y = array[:,8]
接下來,如下所示,為 10 折交叉驗證提供輸入 -
seed = 7 kfold = KFold(n_splits=10, random_state=seed)
我們需要提供要構建的樹的數量。這裡我們將構建 150 棵樹,並且分割點從 5 個特徵中選擇 -
num_trees = 150 max_features = 5
接下來,使用以下指令碼構建模型 -
model = RandomForestClassifier(n_estimators=num_trees, max_features=max_features)
計算並列印結果,如下所示 -
results = cross_val_score(model, X, Y, cv=kfold) print(results.mean())
輸出
0.7629357484620642
上面的輸出表明,我們 Bagging 隨機森林分類器模型的準確率約為 76%。
極端隨機樹 (Extra Trees)
它是 Bagging 決策樹整合方法的另一種擴充套件。在這種方法中,隨機樹是從訓練資料集的樣本中構建的。
在下面的 Python 示例中,我們將使用 sklearn 的 ExtraTreesClassifier 類在 Pima 印第安人糖尿病資料集上構建極端隨機樹整合模型。
首先,匯入所需的包,如下所示:
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.ensemble import ExtraTreesClassifier
現在,我們需要載入Pima糖尿病資料集,就像在前面的示例中所做的那樣:
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values X = array[:,0:8] Y = array[:,8]
接下來,如下所示,為 10 折交叉驗證提供輸入 -
seed = 7 kfold = KFold(n_splits=10, random_state=seed)
我們需要提供要構建的樹的數量。這裡我們將構建 150 棵樹,並且分割點從 5 個特徵中選擇 -
num_trees = 150 max_features = 5
接下來,使用以下指令碼構建模型 -
model = ExtraTreesClassifier(n_estimators=num_trees, max_features=max_features)
計算並列印結果,如下所示 -
results = cross_val_score(model, X, Y, cv=kfold) print(results.mean())
輸出
0.7551435406698566
上面的輸出表明,我們 Bagging 極端隨機樹分類器模型的準確率約為 75.5%。
Boosting 整合演算法
以下是兩種最常見的 Boosting 整合演算法 -
AdaBoost
它是最成功的 Boosting 整合演算法之一。該演算法的主要關鍵在於它們賦予資料集中例項權重的方式。因此,演算法在構建後續模型時需要減少對例項的關注。
在下面的 Python 示例中,我們將使用 sklearn 的 AdaBoostClassifier 類在 Pima 印第安人糖尿病資料集上構建用於分類的 AdaBoost 整合模型。
首先,匯入所需的包,如下所示:
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.ensemble import AdaBoostClassifier
現在,我們需要載入Pima糖尿病資料集,就像在前面的示例中所做的那樣:
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values X = array[:,0:8] Y = array[:,8]
接下來,如下所示,為 10 折交叉驗證提供輸入 -
seed = 5 kfold = KFold(n_splits=10, random_state=seed)
我們需要提供要構建的樹的數量。這裡我們將構建 150 棵樹,並且分割點從 5 個特徵中選擇 -
num_trees = 50
接下來,使用以下指令碼構建模型 -
model = AdaBoostClassifier(n_estimators=num_trees, random_state=seed)
計算並列印結果,如下所示 -
results = cross_val_score(model, X, Y, cv=kfold) print(results.mean())
輸出
0.7539473684210527
上面的輸出表明,我們的 AdaBoost 分類器整合模型的準確率約為 75%。
隨機梯度提升 (Stochastic Gradient Boosting)
它也被稱為梯度提升機 (Gradient Boosting Machines)。在下面的 Python 示例中,我們將使用 sklearn 的 GradientBoostingClassifier 類在 Pima 印第安人糖尿病資料集上構建用於分類的隨機梯度提升整合模型。
首先,匯入所需的包,如下所示:
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.ensemble import GradientBoostingClassifier
現在,我們需要載入Pima糖尿病資料集,就像在前面的示例中所做的那樣:
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values X = array[:,0:8] Y = array[:,8]
接下來,如下所示,為 10 折交叉驗證提供輸入 -
seed = 5 kfold = KFold(n_splits=10, random_state=seed)
我們需要提供要構建的樹的數量。這裡我們將構建 150 棵樹,並且分割點從 5 個特徵中選擇 -
num_trees = 50
接下來,使用以下指令碼構建模型 -
model = GradientBoostingClassifier(n_estimators=num_trees, random_state=seed)
計算並列印結果,如下所示 -
results = cross_val_score(model, X, Y, cv=kfold) print(results.mean())
輸出
0.7746582365003418
上面的輸出表明,我們的梯度提升分類器整合模型的準確率約為 77.5%。
投票整合演算法 (Voting Ensemble Algorithms)
如前所述,投票首先從訓練資料集中建立兩個或多個獨立模型,然後投票分類器將封裝模型,並在需要新資料時獲取子模型預測結果的平均值。
在下面的 Python 示例中,我們將使用 sklearn 的 VotingClassifier 類在 Pima 印第安人糖尿病資料集上構建投票整合模型用於分類。我們將邏輯迴歸、決策樹分類器和 SVM 的預測結果組合在一起,用於解決分類問題,如下所示 -
首先,匯入所需的包,如下所示:
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.ensemble import VotingClassifier
現在,我們需要載入Pima糖尿病資料集,就像在前面的示例中所做的那樣:
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values X = array[:,0:8] Y = array[:,8]
接下來,如下所示,為 10 折交叉驗證提供輸入 -
kfold = KFold(n_splits=10, random_state=7)
接下來,我們需要建立子模型,如下所示 -
estimators = []
model1 = LogisticRegression()
estimators.append(('logistic', model1))
model2 = DecisionTreeClassifier()
estimators.append(('cart', model2))
model3 = SVC()
estimators.append(('svm', model3))
現在,透過組合上面建立的子模型的預測結果,建立投票整合模型。
ensemble = VotingClassifier(estimators) results = cross_val_score(ensemble, X, Y, cv=kfold) print(results.mean())
輸出
0.7382262474367738
上面的輸出表明,我們的投票分類器整合模型的準確率約為 74%。
改進機器學習模型的效能(續…)
透過演算法調優提高效能
眾所周知,機器學習模型是以引數化的方式構建的,其行為可以針對特定問題進行調整。演算法調優意味著找到這些引數的最佳組合,以便提高機器學習模型的效能。此過程有時稱為超引數最佳化,演算法本身的引數稱為超引數,而機器學習演算法找到的係數稱為引數。
這裡,我們將討論 Python Scikit-learn 提供的一些演算法引數調優方法。
網格搜尋引數調優 (Grid Search Parameter Tuning)
這是一種引數調優方法。這種方法的工作關鍵在於,它對網格中指定的演算法引數的每個可能組合進行系統地構建和評估模型。因此,我們可以說這種演算法具有搜尋的特性。
示例
在下面的 Python 示例中,我們將使用 sklearn 的 GridSearchCV 類在 Pima 印第安人糖尿病資料集上執行網格搜尋,以評估嶺迴歸演算法的各種 alpha 值。
首先,匯入所需的包,如下所示:
import numpy from pandas import read_csv from sklearn.linear_model import Ridge from sklearn.model_selection import GridSearchCV
現在,我們需要載入Pima糖尿病資料集,就像在前面的示例中所做的那樣:
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values X = array[:,0:8] Y = array[:,8]
接下來,評估各種 alpha 值,如下所示 -
alphas = numpy.array([1,0.1,0.01,0.001,0.0001,0]) param_grid = dict(alpha=alphas)
現在,我們需要將網格搜尋應用於我們的模型 -
model = Ridge() grid = GridSearchCV(estimator=model, param_grid=param_grid) grid.fit(X, Y)
使用以下指令碼行列印結果 -
print(grid.best_score_) print(grid.best_estimator_.alpha)
輸出
0.2796175593129722 1.0
上面的輸出提供了最佳得分以及網格中獲得該得分的引數集。在這種情況下,alpha 值為 1.0。
隨機搜尋引數調優 (Random Search Parameter Tuning)
這是一種引數調優方法。這種方法的工作關鍵在於,它從隨機分佈中對演算法引數進行取樣,並進行固定次數的迭代。
示例
在下面的 Python 示例中,我們將使用 sklearn 的 RandomizedSearchCV 類在 Pima 印第安人糖尿病資料集上執行隨機搜尋,以評估嶺迴歸演算法在 0 到 1 之間的不同 alpha 值。
首先,匯入所需的包,如下所示:
import numpy from pandas import read_csv from scipy.stats import uniform from sklearn.linear_model import Ridge from sklearn.model_selection import RandomizedSearchCV
現在,我們需要載入Pima糖尿病資料集,就像在前面的示例中所做的那樣:
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values X = array[:,0:8] Y = array[:,8]
接下來,評估嶺迴歸演算法上的各種 alpha 值,如下所示 -
param_grid = {'alpha': uniform()}
model = Ridge()
random_search = RandomizedSearchCV(estimator=model, param_distributions=param_grid, n_iter=50,
random_state=7)
random_search.fit(X, Y)
使用以下指令碼行列印結果 -
print(random_search.best_score_) print(random_search.best_estimator_.alpha)
輸出
0.27961712703051084 0.9779895119966027 0.9779895119966027
上面的輸出提供了最佳得分,類似於網格搜尋。