- Python機器學習
- 首頁
- 基礎知識
- Python生態系統
- 機器學習方法
- 機器學習專案的資料載入
- 用統計學理解資料
- 用視覺化理解資料
- 資料準備
- 資料特徵選擇
- 機器學習演算法 - 分類
- 介紹
- 邏輯迴歸
- 支援向量機 (SVM)
- 決策樹
- 樸素貝葉斯
- 隨機森林
- 機器學習演算法 - 迴歸
- 隨機森林
- 線性迴歸
- 機器學習演算法 - 聚類
- 概述
- K均值演算法
- 均值漂移演算法
- 層次聚類
- 機器學習演算法 - KNN演算法
- 尋找最近鄰
- 效能指標
- 自動化流程
- 提高機器學習模型的效能
- 提高機器學習模型的效能(續…)
- Python機器學習 - 資源
- Python機器學習 - 快速指南
- Python機器學習 - 資源
- Python機器學習 - 討論
分類演算法 - 邏輯迴歸
邏輯迴歸介紹
邏輯迴歸是一種監督學習分類演算法,用於預測目標變數的機率。目標變數或因變數的性質是二分的,這意味著只有兩種可能的類別。
簡單來說,因變數本質上是二元的,資料編碼為1(代表成功/是)或0(代表失敗/否)。
在數學上,邏輯迴歸模型預測P(Y=1)作為X的函式。它是可用於各種分類問題的最簡單的機器學習演算法之一,例如垃圾郵件檢測、糖尿病預測、癌症檢測等。
邏輯迴歸的型別
通常,邏輯迴歸是指具有二元目標變數的二元邏輯迴歸,但它還可以預測目標變數的另外兩個類別。根據這些類別的數量,邏輯迴歸可以分為以下型別:
二元或二項
在這種型別的分類中,因變數只有兩種可能的型別,要麼是1,要麼是0。例如,這些變數可以代表成功或失敗、是或否、贏或輸等。
多項
在這種型別的分類中,因變數可以有3種或更多種可能的無序型別,或者這些型別沒有定量意義。例如,這些變數可以代表“A型”、“B型”或“C型”。
有序
在這種型別的分類中,因變數可以有3種或更多種可能的順序型別,或者這些型別具有定量意義。例如,這些變數可以代表“差”、“好”、“非常好”、“優秀”,每個類別可以有0,1,2,3這樣的分數。
邏輯迴歸假設
在深入研究邏輯迴歸的實現之前,我們必須瞭解以下關於它的假設:
在二元邏輯迴歸的情況下,目標變數必須始終是二元的,並且期望的結果由因子水平1表示。
模型中不應存在多重共線性,這意味著自變數必須彼此獨立。
我們必須在模型中包含有意義的變數。
我們應該為邏輯迴歸選擇一個大的樣本量。
二元邏輯迴歸模型
邏輯迴歸最簡單的形式是二元或二項邏輯迴歸,其中目標變數或因變數只有兩種可能的型別,要麼是1,要麼是0。它允許我們模擬多個預測變數和二元/二專案標變數之間的關係。在邏輯迴歸的情況下,線性函式基本上用作另一個函式(例如以下關係中的g)的輸入:
$$h_{\theta}{(x)}=g(\theta^{T}x)𝑤ℎ𝑒𝑟𝑒 0≤h_{\theta}≤1$$這裡,g是邏輯函式或S型函式,可以表示如下:
$$g(z)= \frac{1}{1+e^{-z}}𝑤ℎ𝑒𝑟𝑒 𝑧=\theta ^{T}𝑥$$S型曲線可以用下圖表示。我們可以看到y軸的值介於0和1之間,並在0.5處穿過軸。

類別可以分為正類或負類。如果輸出介於0和1之間,則輸出屬於正類的機率。在我們的實現中,如果假設函式的輸出≥0.5,則將其解釋為正類,否則為負類。
我們還需要定義一個損失函式來衡量演算法使用函式權重(用θ表示)的效能,如下所示:
ℎ=𝑔(𝑋𝜃)
$$J(\theta) = \frac{1}{m}.(-y^{T}log(h) - (1 -y)^Tlog(1-h))$$現在,在定義了損失函式之後,我們的主要目標是最小化損失函式。這可以透過擬合權重來完成,這意味著增加或減少權重。藉助損失函式相對於每個權重的導數,我們將能夠知道哪些引數應該具有較高的權重,哪些引數應該具有較低的權重。
下面的梯度下降方程告訴我們如果修改引數,損失將如何變化:
$$\frac{𝛿𝐽(𝜃)}{𝛿\theta_{j}}=\frac{1}{m}X^{T}(𝑔(𝑋𝜃)−𝑦)$$Python實現
現在,我們將用Python實現上述二元邏輯迴歸的概念。為此,我們使用一個名為“iris”的多元花卉資料集,它包含3個類別,每個類別有50個例項,但我們將使用前兩個特徵列。每個類別代表一種鳶尾花。
首先,我們需要匯入必要的庫,如下所示:
import numpy as np import matplotlib.pyplot as plt import seaborn as sns from sklearn import datasets
接下來,載入iris資料集,如下所示:
iris = datasets.load_iris() X = iris.data[:, :2] y = (iris.target != 0) * 1
我們可以繪製我們的訓練資料,如下所示:
plt.figure(figsize=(6, 6)) plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='g', label='0') plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='y', label='1') plt.legend();
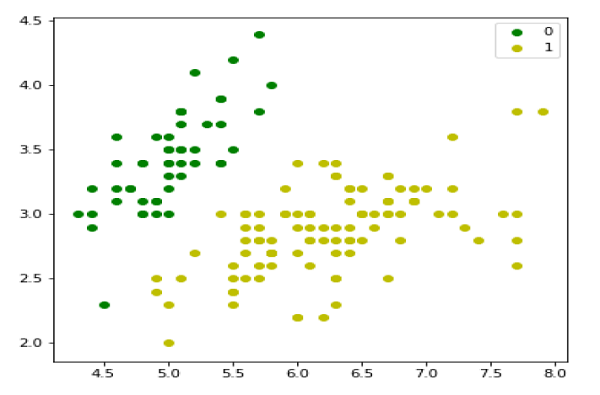
接下來,我們將定義sigmoid函式、損失函式和梯度下降,如下所示:
class LogisticRegression:
def __init__(self, lr=0.01, num_iter=100000, fit_intercept=True, verbose=False):
self.lr = lr
self.num_iter = num_iter
self.fit_intercept = fit_intercept
self.verbose = verbose
def __add_intercept(self, X):
intercept = np.ones((X.shape[0], 1))
return np.concatenate((intercept, X), axis=1)
def __sigmoid(self, z):
return 1 / (1 + np.exp(-z))
def __loss(self, h, y):
return (-y * np.log(h) - (1 - y) * np.log(1 - h)).mean()
def fit(self, X, y):
if self.fit_intercept:
X = self.__add_intercept(X)
現在,初始化權重,如下所示:
self.theta = np.zeros(X.shape[1])
for i in range(self.num_iter):
z = np.dot(X, self.theta)
h = self.__sigmoid(z)
gradient = np.dot(X.T, (h - y)) / y.size
self.theta -= self.lr * gradient
z = np.dot(X, self.theta)
h = self.__sigmoid(z)
loss = self.__loss(h, y)
if(self.verbose ==True and i % 10000 == 0):
print(f'loss: {loss} \t')
藉助以下指令碼,我們可以預測輸出機率:
def predict_prob(self, X):
if self.fit_intercept:
X = self.__add_intercept(X)
return self.__sigmoid(np.dot(X, self.theta))
def predict(self, X):
return self.predict_prob(X).round()
接下來,我們可以評估模型並繪製它,如下所示:
model = LogisticRegression(lr=0.1, num_iter=300000) preds = model.predict(X) (preds == y).mean() plt.figure(figsize=(10, 6)) plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='g', label='0') plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='y', label='1') plt.legend() x1_min, x1_max = X[:,0].min(), X[:,0].max(), x2_min, x2_max = X[:,1].min(), X[:,1].max(), xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max), np.linspace(x2_min, x2_max)) grid = np.c_[xx1.ravel(), xx2.ravel()] probs = model.predict_prob(grid).reshape(xx1.shape) plt.contour(xx1, xx2, probs, [0.5], linewidths=1, colors='red');
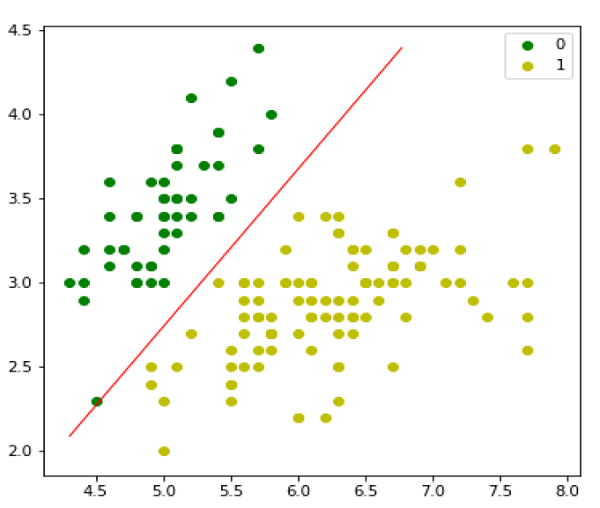
多項邏輯迴歸模型
邏輯迴歸的另一種有用的形式是多項邏輯迴歸,其中目標變數或因變數可以有3種或更多種可能的無序型別,即沒有定量意義的型別。
Python實現
現在,我們將用Python實現上述多項邏輯迴歸的概念。為此,我們使用sklearn中的一個名為digit的資料集。
首先,我們需要匯入必要的庫,如下所示:
Import sklearn from sklearn import datasets from sklearn import linear_model from sklearn import metrics from sklearn.model_selection import train_test_split
接下來,我們需要載入digit資料集:
digits = datasets.load_digits()
現在,定義特徵矩陣(X)和響應向量(y),如下所示:
X = digits.data y = digits.target
藉助下一行程式碼,我們可以將X和y拆分為訓練集和測試集:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1)
現在,建立一個邏輯迴歸物件,如下所示:
digreg = linear_model.LogisticRegression()
現在,我們需要使用訓練集來訓練模型,如下所示:
digreg.fit(X_train, y_train)
接下來,對測試集進行預測,如下所示:
y_pred = digreg.predict(X_test)
接下來,列印模型的準確率,如下所示:
print("Accuracy of Logistic Regression model is:",
metrics.accuracy_score(y_test, y_pred)*100)
輸出
Accuracy of Logistic Regression model is: 95.6884561891516
從上面的輸出中,我們可以看到我們的模型的準確率約為96%。