- Python機器學習
- 首頁
- 基礎
- Python 生態系統
- 機器學習方法
- ML 專案的資料載入
- 用統計學理解資料
- 用視覺化理解資料
- 準備資料
- 資料特徵選擇
- ML 演算法 - 分類
- 介紹
- 邏輯迴歸
- 支援向量機 (SVM)
- 決策樹
- 樸素貝葉斯
- 隨機森林
- ML 演算法 - 迴歸
- 隨機森林
- 線性迴歸
- ML 演算法 - 聚類
- 概述
- K均值演算法
- 均值漂移演算法
- 層次聚類
- ML 演算法 - KNN 演算法
- 尋找最近鄰
- 效能指標
- 自動工作流
- 提高 ML 模型的效能
- 提高 ML 模型的效能(續…)
- Python機器學習 - 資源
- Python機器學習 - 快速指南
- Python機器學習 - 資源
- Python機器學習 - 討論
聚類演算法 - 層次聚類
層次聚類的介紹
層次聚類是另一種無監督學習演算法,用於將具有相似特徵的未標記資料點分組在一起。層次聚類演算法分為以下兩類:
凝聚層次演算法 - 在凝聚層次演算法中,每個資料點都被視為一個單獨的簇,然後依次合併或聚集(自下而上的方法)成對的簇。簇的層次結構表示為樹狀圖或樹結構。
分裂層次演算法 - 另一方面,在分裂層次演算法中,所有資料點都被視為一個大的簇,並且聚類的過程涉及將一個大的簇劃分為多個小的簇(自上而下的方法)。
執行凝聚層次聚類的步驟
我們將解釋最常用和最重要的層次聚類,即凝聚層次聚類。執行此操作的步驟如下:
步驟 1 - 將每個資料點視為單個簇。因此,我們開始時將有 K 個簇。資料點的數量開始時也將為 K。
步驟 2 - 現在,在此步驟中,我們需要透過連線兩個最接近的資料點來形成一個大的簇。這將導致總共 K-1 個簇。
步驟 3 - 現在,要形成更多簇,我們需要連線兩個最接近的簇。這將導致總共 K-2 個簇。
步驟 4 - 現在,要形成一個大的簇,重複上述三個步驟,直到 K 變為 0,即沒有更多資料點可以連線。
步驟 5 - 最後,在形成一個大的簇後,將使用樹狀圖根據問題將其劃分為多個簇。
樹狀圖在凝聚層次聚類中的作用
正如我們在上一步中所討論的,一旦形成大的簇,樹狀圖的作用就開始了。樹狀圖將用於根據我們的問題將簇拆分為多個相關資料點的簇。可以透過以下示例來理解:
示例 1
為了理解,讓我們從匯入所需的庫開始,如下所示:
%matplotlib inline import matplotlib.pyplot as plt import numpy as np
接下來,我們將繪製在此示例中使用的所有資料點:
X = np.array([[7,8],[12,20],[17,19],[26,15],[32,37],[87,75],[73,85], [62,80],[73,60],[87,96],]) labels = range(1, 11) plt.figure(figsize=(10, 7)) plt.subplots_adjust(bottom=0.1) plt.scatter(X[:,0],X[:,1], label='True Position') for label, x, y in zip(labels, X[:, 0], X[:, 1]): plt.annotate(label,xy=(x, y), xytext=(-3, 3),textcoords='offset points', ha='right', va='bottom') plt.show()

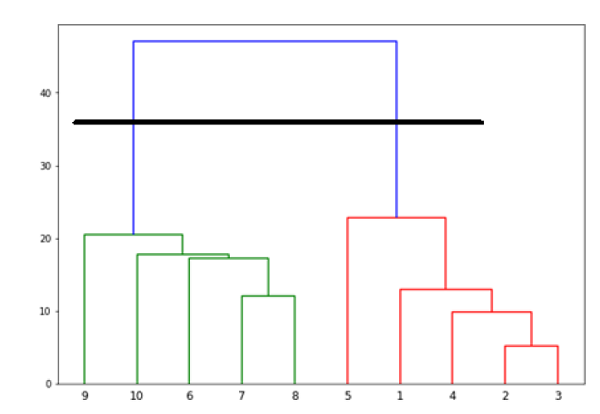
從上圖中,很容易看出我們的資料點中有兩個簇,但在現實世界的資料中,可能會有數千個簇。接下來,我們將使用 Scipy 庫繪製資料點的樹狀圖:
from scipy.cluster.hierarchy import dendrogram, linkage from matplotlib import pyplot as plt linked = linkage(X, 'single') labelList = range(1, 11) plt.figure(figsize=(10, 7)) dendrogram(linked, orientation='top',labels=labelList, distance_sort='descending',show_leaf_counts=True) plt.show()

現在,一旦形成大的簇,就會選擇最長的垂直距離。然後,如以下圖表所示,透過它繪製一條垂直線。由於水平線在兩點與藍線相交,因此簇的數量將為兩個。
接下來,我們需要匯入用於聚類的類並呼叫其 fit_predict 方法來預測簇。我們正在匯入 sklearn.cluster 庫的 AgglomerativeClustering 類:
from sklearn.cluster import AgglomerativeClustering cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward') cluster.fit_predict(X)
接下來,使用以下程式碼繪製簇:
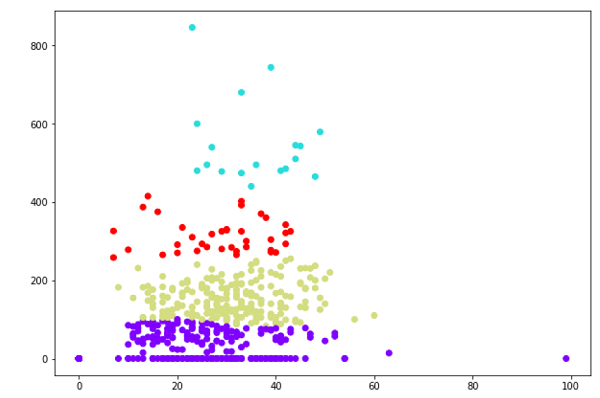
plt.scatter(X[:,0],X[:,1], c=cluster.labels_, cmap='rainbow')

上圖顯示了我們資料點中的兩個簇。
示例 2
正如我們從上面討論的簡單示例中理解了樹狀圖的概念,讓我們繼續另一個示例,其中我們使用層次聚類建立皮馬印第安人糖尿病資料集中的資料點的簇:
import matplotlib.pyplot as plt import pandas as pd %matplotlib inline import numpy as np from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values X = array[:,0:8] Y = array[:,8] data.shape (768, 9) data.head()
| 序號。 | 孕期 | 葡萄糖 | 血壓 | 皮膚厚度 | 胰島素 | 體重指數 | 糖尿病譜系 | 年齡 | 類別 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
patient_data = data.iloc[:, 3:5].values
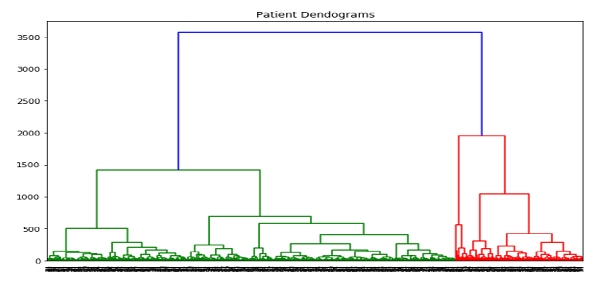
import scipy.cluster.hierarchy as shc
plt.figure(figsize=(10, 7))
plt.title("Patient Dendograms")
dend = shc.dendrogram(shc.linkage(data, method='ward'))
from sklearn.cluster import AgglomerativeClustering cluster = AgglomerativeClustering(n_clusters=4, affinity='euclidean', linkage='ward') cluster.fit_predict(patient_data) plt.figure(figsize=(10, 7)) plt.scatter(patient_data[:,0], patient_data[:,1], c=cluster.labels_, cmap='rainbow')