- Kibana 教程
- Kibana - 首頁
- Kibana - 概述
- Kibana - 環境設定
- Kibana - ELK Stack 簡介
- Kibana - 載入示例資料
- Kibana - 管理
- Kibana - 探索 (Discover)
- Kibana - 聚合和指標
- Kibana - 建立視覺化
- Kibana - 使用圖表
- Kibana - 使用圖形
- Kibana - 使用熱力圖
- 使用座標地圖
- Kibana - 使用區域地圖
- 使用儀表和目標
- Kibana - 使用畫布 (Canvas)
- Kibana - 建立儀表盤
- Kibana - Timelion
- Kibana - 開發工具 (Dev Tools)
- Kibana - 監控
- 使用 Kibana 建立報表
- Kibana 有用資源
- Kibana 快速指南
- Kibana - 有用資源
- Kibana - 討論
Kibana 快速指南
Kibana - 概述
Kibana是一個開源的基於瀏覽器的視覺化工具,主要用於分析海量日誌,以折線圖、條形圖、餅圖、熱力圖、區域地圖、座標地圖、儀表盤、目標、Timelion等形式呈現。視覺化功能使預測或檢視錯誤趨勢或輸入源其他重要事件的變化變得容易。Kibana 與 Elasticsearch 和 Logstash 協同工作,共同構成所謂的ELK堆疊。
什麼是 ELK 堆疊?
ELK代表 Elasticsearch、Logstash 和 Kibana。ELK是全球廣泛使用的流行日誌管理平臺之一,用於日誌分析。在 ELK 堆疊中,Logstash 從不同的輸入源提取日誌資料或其他事件。它處理這些事件,然後將它們儲存在 Elasticsearch 中。
Kibana是一個視覺化工具,它訪問 Elasticsearch 中的日誌,並能夠以折線圖、條形圖、餅圖等形式向用戶顯示。
ELK 堆疊的基本流程如下圖所示:
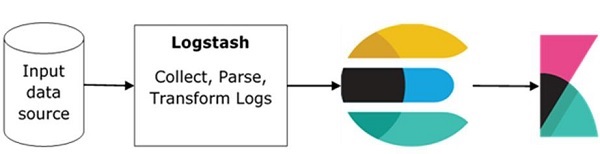
Logstash 負責收集所有遠端日誌檔案所在的資料,並將這些資料推送到 Elasticsearch。
Elasticsearch 充當資料庫,用於收集資料,而 Kibana 使用 Elasticsearch 中的資料以條形圖、餅圖、熱力圖等形式向用戶呈現資料,如下所示:
它即時地向用戶顯示資料,例如按天或按小時顯示。Kibana 的使用者介面友好,即使是初學者也很容易理解。
Kibana 的功能
Kibana 為使用者提供以下功能:
視覺化
Kibana 提供了許多簡便易用的資料視覺化方式。一些常用的方式包括垂直條形圖、水平條形圖、餅圖、折線圖、熱力圖等。
儀表盤
準備好視覺化之後,所有視覺化都可以放置在一個面板上——儀表盤。同時觀察不同的部分,可以更清晰地瞭解正在發生的事情。
開發工具
您可以使用開發工具處理索引。初學者可以使用開發工具新增虛擬索引,還可以新增、更新、刪除資料並使用索引建立視覺化。
報表
所有以視覺化和儀表盤形式存在的資料都可以轉換為報表(CSV 格式),嵌入到程式碼中,或以 URL 的形式與他人共享。
過濾器和搜尋查詢
您可以使用過濾器和搜尋查詢從儀表盤或視覺化工具中獲取特定輸入的所需詳細資訊。
外掛
您可以新增第三方外掛來新增一些新的視覺化效果或其他 UI 功能到 Kibana 中。
座標地圖和區域地圖
Kibana 中的座標地圖和區域地圖有助於在地理地圖上顯示視覺化效果,從而更真實地展現資料。
Timelion
Timelion,也稱為時間線,是另一個主要用於基於時間的分析的視覺化工具。要使用時間線,我們需要使用簡單的表示式語言,這有助於我們連線到索引,並對資料進行計算以獲得所需的結果。它更有助於將資料與上一週期(按周、月等)的資料進行比較。
畫布 (Canvas)
畫布是 Kibana 中另一個強大的功能。使用畫布視覺化,您可以使用不同的顏色組合、形狀、文字和多個頁面(基本上稱為工作區)來表示資料。
Kibana 的優點
Kibana 為使用者提供以下優點:
包含主要用於分析海量日誌的開源基於瀏覽器的視覺化工具,以折線圖、條形圖、餅圖、熱力圖等形式呈現。
對初學者來說簡單易懂。
視覺化和儀表盤易於轉換為報表。
畫布視覺化有助於輕鬆分析複雜資料。
Kibana 中的 Timelion 視覺化有助於向後比較資料,以便更好地瞭解效能。
Kibana 的缺點
如果版本不匹配,向 Kibana 新增外掛可能會非常繁瑣。
當您想從舊版本升級到新版本時,您可能會遇到問題。
Kibana - 環境設定
要開始使用 Kibana,我們需要安裝 Logstash、Elasticsearch 和 Kibana。在本節中,我們將嘗試瞭解此處 ELK 堆疊的安裝。
我們將在此處討論以下安裝:
- Elasticsearch 安裝
- Logstash 安裝
- Kibana 安裝
Elasticsearch 安裝
我們的庫中提供了有關 Elasticsearch 的詳細文件。您可以在這裡檢視 elasticsearch 安裝。您必須按照教程中提到的步驟安裝 Elasticsearch。
安裝完成後,按如下方式啟動 elasticsearch 伺服器:
步驟 1
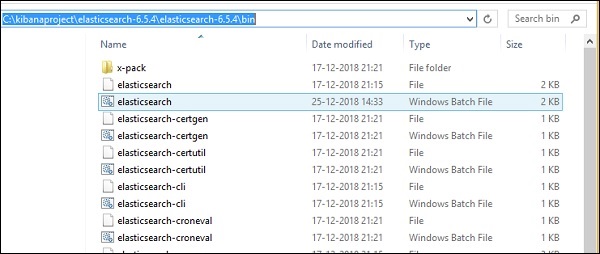
對於 Windows
> cd kibanaproject/elasticsearch-6.5.4/elasticsearch-6.5.4/bin > elasticsearch
請注意,對於 Windows 使用者,必須將 JAVA_HOME 變數設定為 java jdk 路徑。
對於 Linux
$ cd kibanaproject/elasticsearch-6.5.4/elasticsearch-6.5.4/bin $ elasticsearch
Elasticsearch 的預設埠是 9200。完成後,您可以在 localhost 的 9200 埠上檢查 elasticsearch,https://:9200/ 如下所示:
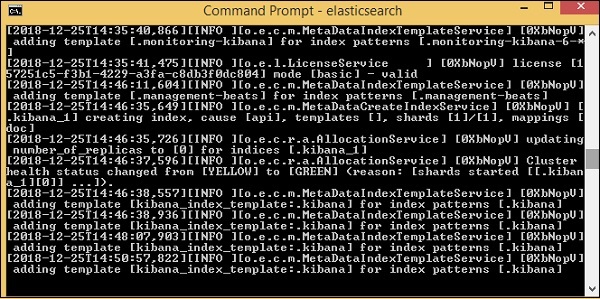
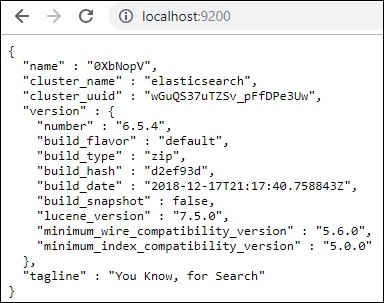
Logstash 安裝
有關 Logstash 安裝,請參閱我們庫中已有的 elasticsearch 安裝。
Kibana 安裝
訪問 Kibana 官方網站:https://www.elastic.co/products/kibana
點選右上角的下載連結,將顯示如下螢幕:
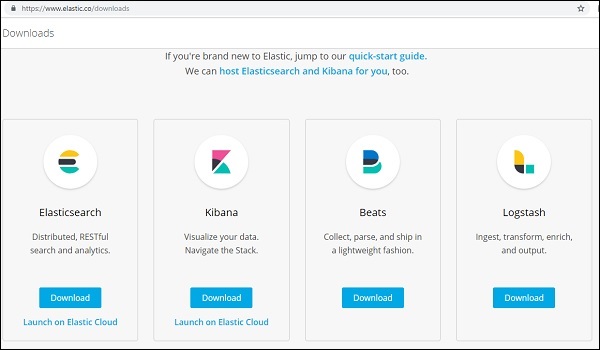
點選 Kibana 的下載按鈕。請注意,要使用 Kibana,我們需要 64 位機器,它不適用於 32 位機器。
在本教程中,我們將使用 Kibana 6 版。Windows、Mac 和 Linux 系統均可下載。您可以根據自己的選擇下載。
建立一個資料夾並解壓 Kibana 的 tar/zip 下載檔案。我們將使用上傳到 elasticsearch 的示例資料。因此,現在讓我們看看如何啟動 elasticsearch 和 kibana。為此,請轉到 Kibana 解壓到的資料夾。
對於 Windows
> cd kibanaproject/kibana-6.5.4/kibana-6.5.4/bin > kibana
對於 Linux
$ cd kibanaproject/kibana-6.5.4/kibana-6.5.4/bin $ kibana
Kibana 啟動後,使用者將看到如下螢幕:

在控制檯中看到就緒訊號後,您可以使用https://:5601/在瀏覽器中開啟 Kibana。Kibana 可用的預設埠是 5601。
Kibana 的使用者介面如下所示:
在下一節中,我們將學習如何使用 Kibana 的 UI。要在 Kibana UI 上了解 Kibana 版本,請轉到左側的“管理”選項卡,它將顯示我們當前使用的 Kibana 版本。
Kibana - ELK Stack 簡介
Kibana 是一款開源的視覺化工具,主要用於分析海量日誌,以折線圖、條形圖、餅圖、熱力圖等形式呈現。Kibana 與 Elasticsearch 和 Logstash 協同工作,共同構成所謂的ELK堆疊。
ELK代表 Elasticsearch、Logstash 和 Kibana。ELK是全球廣泛使用的流行日誌管理平臺之一,用於日誌分析。
在 ELK 堆疊中:
Logstash從不同的輸入源提取日誌資料或其他事件。它處理這些事件,然後將它們儲存在 Elasticsearch 中。
Kibana是一個視覺化工具,它訪問 Elasticsearch 中的日誌,並能夠以折線圖、條形圖、餅圖等形式向用戶顯示。
在本教程中,我們將密切關注 Kibana 和 Elasticsearch,並以不同的形式視覺化資料。
在本節中,讓我們瞭解如何一起使用 ELK 堆疊。此外,您還將看到如何:
- 將 CSV 資料從 Logstash 載入到 Elasticsearch。
- 在 Kibana 中使用 Elasticsearch 中的索引。
將 CSV 資料從 Logstash 載入到 Elasticsearch
我們將使用 CSV 資料透過 Logstash 將資料上傳到 Elasticsearch。為了進行資料分析,我們可以從 kaggle.com 網站獲取資料。Kaggle.com 網站上傳了各種型別的資料,使用者可以使用它來進行資料分析。
我們從這裡獲取了 countries.csv 資料:https://www.kaggle.com/fernandol/countries-of-the-world。您可以下載 csv 檔案並使用它。
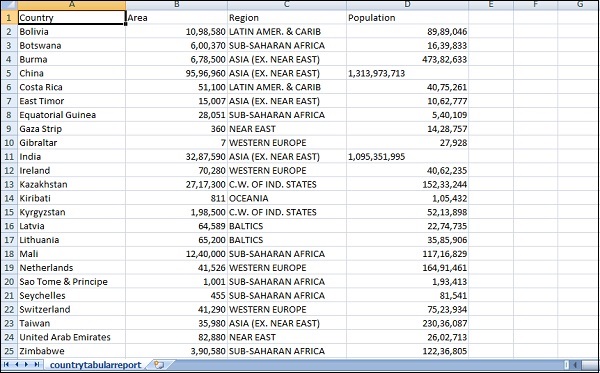
我們將使用的 csv 檔案包含以下詳細資訊。
檔名 - countriesdata.csv
列 - "國家",“地區”,“人口”,“面積”
您也可以建立一個虛擬 csv 檔案並使用它。我們將使用 logstash 將此資料從countriesdata.csv轉儲到 elasticsearch。
在您的終端中啟動 elasticsearch 和 Kibana 並保持執行。我們必須為 logstash 建立配置檔案,其中將包含 CSV 檔案列的詳細資訊以及其他詳細資訊,如下所示的 logstash-config 檔案:
input {
file {
path => "C:/kibanaproject/countriesdata.csv"
start_position => "beginning"
sincedb_path => "NUL"
}
}
filter {
csv {
separator => ","
columns => ["Country","Region","Population","Area"]
}
mutate {convert => ["Population", "integer"]}
mutate {convert => ["Area", "integer"]}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
=> "countriesdata-%{+dd.MM.YYYY}"
}
stdout {codec => json_lines }
}
在配置檔案中,我們建立了 3 個元件:
輸入
我們需要指定輸入檔案的路徑,在本例中為 csv 檔案。將 csv 檔案儲存的路徑提供給 path 欄位。
過濾器
將包含 csv 元件以及使用的分隔符(在本例中為逗號),以及 csv 檔案中可用的列。由於 logstash 將所有傳入資料視為字串,如果我們希望任何列用作整數或浮點數,則必須使用 mutate 指定,如上所示。
輸出
對於輸出,我們需要指定需要放置資料的位置。在本例中,我們使用的是 elasticsearch。需要提供給 elasticsearch 的資料是其執行的主機,我們將其指定為 localhost。下一個欄位是索引,我們將其命名為countries-currentdate。一旦資料更新到 Elasticsearch 中,我們就必須在 Kibana 中使用相同的索引。
將上述配置檔案儲存為logstash_countries.config。請注意,在下一步中,我們需要將此配置檔案的路徑提供給 logstash 命令。
要將資料從 csv 檔案載入到 elasticsearch,我們需要啟動 elasticsearch 伺服器:
現在,在瀏覽器中執行https://:9200以確認 elasticsearch 是否已成功執行。
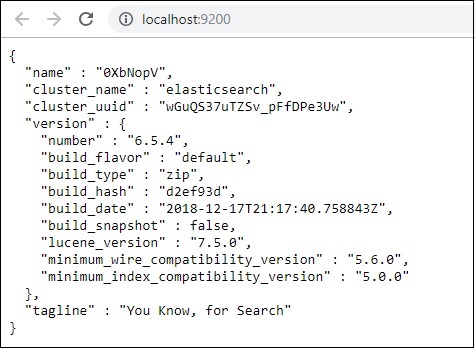
我們的 elasticsearch 正在執行。現在,轉到安裝 logstash 的路徑,並執行以下命令以將資料上傳到 elasticsearch。
> logstash -f logstash_countries.conf
上面的螢幕顯示從 CSV 檔案到 Elasticsearch 的資料載入。要了解我們是否已在 Elasticsearch 中建立了索引,我們可以按如下方式檢查:
我們可以看到如上所示建立了 countriesdata-28.12.2018 索引。

索引 countries-28.12.2018 的詳細資訊如下:
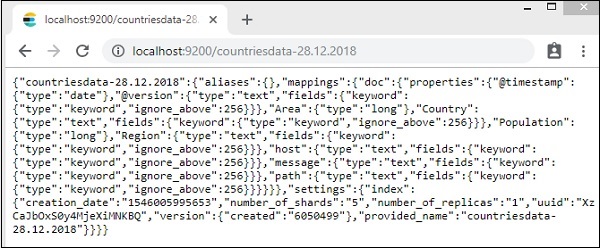
請注意,當從 Logstash 上傳資料到 Elasticsearch 時,會建立包含屬性的對映詳細資訊。
在 Kibana 中使用 Elasticsearch 資料
目前,我們已經在本地主機 5601 埠執行 Kibana − https://:5601。Kibana 的 UI 如圖所示 −
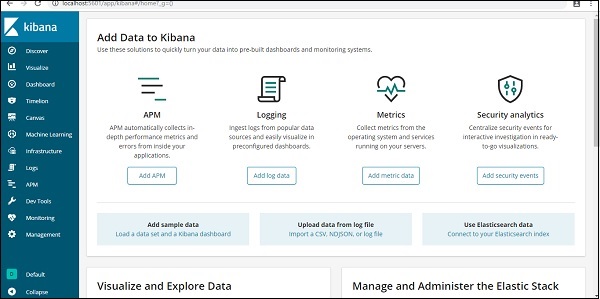
請注意,我們已經將 Kibana 連線到 Elasticsearch,並且應該能夠在 Kibana 中看到索引:countries-28.12.2018。
在 Kibana UI 中,單擊左側的管理選單選項 −
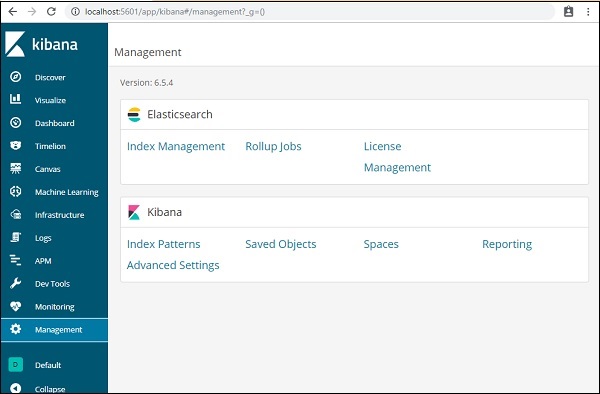
現在,單擊索引管理 −
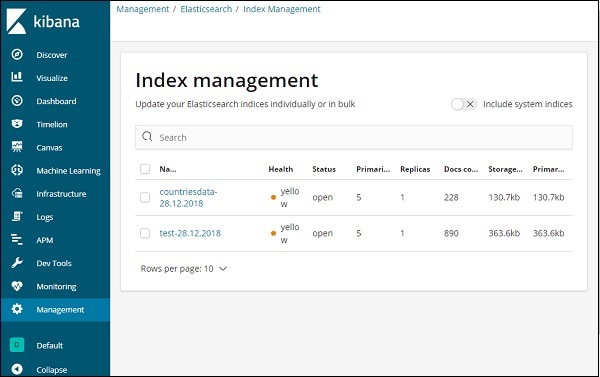
Elasticsearch 中存在的索引顯示在索引管理中。我們將在 Kibana 中使用的索引是 countriesdata-28.12.2018。
因此,由於我們已經在 Kibana 中擁有 Elasticsearch 索引,接下來我們將瞭解如何在 Kibana 中使用該索引以餅圖、條形圖、折線圖等形式視覺化資料。
Kibana - 載入示例資料
我們已經瞭解瞭如何將資料從 Logstash 上傳到 Elasticsearch。我們將在這裡使用 Logstash 和 Elasticsearch 上傳資料。但關於我們需要使用的包含日期、經度和緯度欄位的資料,我們將在接下來的章節中學習。如果我們沒有 CSV 檔案,我們還將學習如何直接在 Kibana 中上傳資料。
本章將涵蓋以下主題 −
- 使用 Logstash 上傳包含日期、經度和緯度欄位的資料到 Elasticsearch
- 使用 Dev Tools 上傳批次資料
使用 Logstash 上傳包含欄位的資料到 Elasticsearch
我們將使用 CSV 格式的資料,這些資料來自 Kaggle.com,其中包含可用於分析的資料。
此處將使用的家庭醫療訪問資料取自 Kaggle.com。
CSV 檔案中包含以下欄位 −
["Visit_Status","Time_Delay","City","City_id","Patient_Age","Zipcode","Latitude","Longitude", "Pathology","Visiting_Date","Id_type","Id_personal","Number_Home_Visits","Is_Patient_Minor","Geo_point"]
Home_visits.csv 檔案如下所示 −
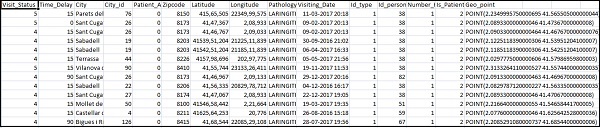
以下是與 Logstash 一起使用的配置檔案 −
input {
file {
path => "C:/kibanaproject/home_visits.csv"
start_position => "beginning"
sincedb_path => "NUL"
}
}
filter {
csv {
separator => ","
columns =>
["Visit_Status","Time_Delay","City","City_id","Patient_Age",
"Zipcode","Latitude","Longitude","Pathology","Visiting_Date",
"Id_type","Id_personal","Number_Home_Visits","Is_Patient_Minor","Geo_point"]
}
date {
match => ["Visiting_Date","dd-MM-YYYY HH:mm"]
target => "Visiting_Date"
}
mutate {convert => ["Number_Home_Visits", "integer"]}
mutate {convert => ["City_id", "integer"]}
mutate {convert => ["Id_personal", "integer"]}
mutate {convert => ["Id_type", "integer"]}
mutate {convert => ["Zipcode", "integer"]}
mutate {convert => ["Patient_Age", "integer"]}
mutate {
convert => { "Longitude" => "float" }
convert => { "Latitude" => "float" }
}
mutate {
rename => {
"Longitude" => "[location][lon]"
"Latitude" => "[location][lat]"
}
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "medicalvisits-%{+dd.MM.YYYY}"
}
stdout {codec => json_lines }
}
預設情況下,Logstash 將上傳到 Elasticsearch 的所有內容都視為字串。如果您的 CSV 檔案包含日期欄位,則需要執行以下操作才能獲得正確的日期格式。
對於日期欄位 −
date {
match => ["Visiting_Date","dd-MM-YYYY HH:mm"]
target => "Visiting_Date"
}
對於地理位置,Elasticsearch 的理解方式如下 −
"location": {
"lat":41.565505000000044,
"lon": 2.2349995750000695
}
因此,我們需要確保經度和緯度採用 Elasticsearch 所需的格式。因此,我們首先需要將經度和緯度轉換為浮點數,然後重新命名它們,以便它們作為包含lat 和 lon 的location json 物件的一部分提供。程式碼如下所示 −
mutate {
convert => { "Longitude" => "float" }
convert => { "Latitude" => "float" }
}
mutate {
rename => {
"Longitude" => "[location][lon]"
"Latitude" => "[location][lat]"
}
}
要將欄位轉換為整數,請使用以下程式碼 −
mutate {convert => ["Number_Home_Visits", "integer"]}
mutate {convert => ["City_id", "integer"]}
mutate {convert => ["Id_personal", "integer"]}
mutate {convert => ["Id_type", "integer"]}
mutate {convert => ["Zipcode", "integer"]}
mutate {convert => ["Patient_Age", "integer"]}
處理完欄位後,執行以下命令將資料上傳到 Elasticsearch −
- 進入 Logstash bin 目錄並執行以下命令。
logstash -f logstash_homevisists.conf
- 完成後,您應該在 Elasticsearch 中看到 Logstash 配置檔案中提到的索引,如下所示 −
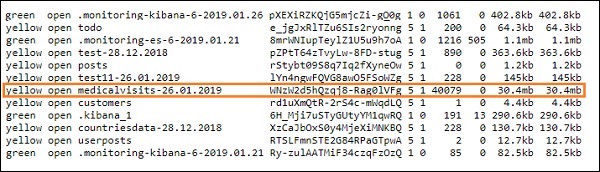
我們現在可以根據上面上傳的索引建立索引模式,並進一步將其用於建立視覺化。
使用 Dev Tools 上傳批次資料
我們將使用 Kibana UI 中的 Dev Tools。Dev Tools 有助於在不使用 Logstash 的情況下將資料上傳到 Elasticsearch。我們可以使用 Dev Tools 在 Kibana 中釋出、放置、刪除和搜尋所需的資料。
在本節中,我們將嘗試在 Kibana 本身載入示例資料。我們可以使用它來練習示例資料,並試用 Kibana 功能,以更好地瞭解 Kibana。
讓我們從以下網址獲取 JSON 資料,並在 Kibana 中上傳。同樣,您可以嘗試將任何示例 JSON 資料載入到 Kibana 中。
在開始上傳示例資料之前,我們需要擁有在 Elasticsearch 中使用的索引的 JSON 資料。當我們使用 Logstash 上傳資料時,Logstash 會負責新增索引,使用者不必擔心 Elasticsearch 需要哪些索引。
普通 JSON 資料
[
{"type":"act","line_id":1,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"ACT I"},
{"type":"scene","line_id":2,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"SCENE I.London. The palace."},
{"type":"line","line_id":3,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":
"Enter KING HENRY, LORD JOHN OF LANCASTER, the
EARL of WESTMORELAND, SIR WALTER BLUNT, and others"}
]
與 Kibana 一起使用的 JSON 程式碼必須按如下方式建立索引 −
{"index":{"_index":"shakespeare","_id":0}}
{"type":"act","line_id":1,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"ACT I"}
{"index":{"_index":"shakespeare","_id":1}}
{"type":"scene","line_id":2,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"",
"text_entry":"SCENE I. London. The palace."}
{"index":{"_index":"shakespeare","_id":2}}
{"type":"line","line_id":3,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":
"Enter KING HENRY, LORD JOHN OF LANCASTER, the EARL
of WESTMORELAND, SIR WALTER BLUNT, and others"}
請注意,JSON 檔案中還有一些附加資料 −{"index":{"_index":"nameofindex","_id":key}}。
要將任何與 Elasticsearch 相容的示例 JSON 檔案進行轉換,這裡我們有一個小的 PHP 程式碼,它將輸出的 JSON 檔案轉換為 Elasticsearch 所需的格式 −
PHP 程式碼
<?php
$myfile = fopen("todo.json", "r") or die("Unable to open file!"); // your json
file here
$alldata = fread($myfile,filesize("todo.json"));
fclose($myfile);
$farray = json_decode($alldata);
$afinalarray = [];
$index_name = "todo";
$i=0;
$myfile1 = fopen("todonewfile.json", "w") or die("Unable to open file!"); //
writes a new file to be used in kibana dev tool
foreach ($farray as $a => $value) {
$_index = json_decode('{"index": {"_index": "'.$index_name.'", "_id": "'.$i.'"}}');
fwrite($myfile1, json_encode($_index));
fwrite($myfile1, "\n");
fwrite($myfile1, json_encode($value));
fwrite($myfile1, "\n");
$i++;
}
?>
我們從 https://jsonplaceholder.typicode.com/todos 獲取了 todo JSON 檔案,並使用 PHP 程式碼將其轉換為我們需要在 Kibana 中上傳的格式。
要載入示例資料,請開啟 Dev Tools 選項卡,如下所示 −
我們現在將使用上面顯示的控制檯。我們將使用執行 PHP 程式碼後獲得的 JSON 資料。
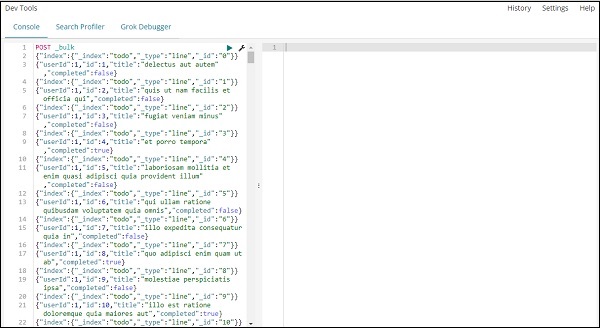
在 Dev Tools 中用於上傳 JSON 資料的命令是 −
POST _bulk
請注意,我們正在建立的索引的名稱是 todo。
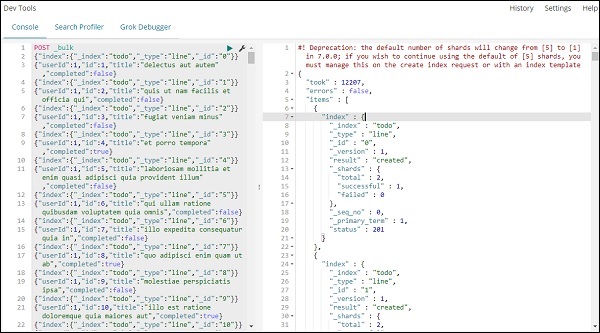
單擊綠色按鈕上傳資料後,您可以檢查索引是否已在 Elasticsearch 中建立,方法如下 −
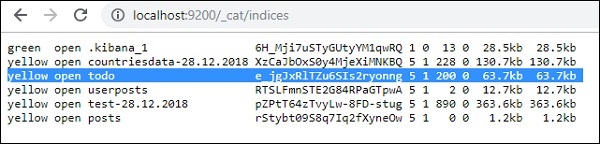
您可以在 Dev Tools 本身中檢查相同的內容,方法如下 −
命令 −
GET /_cat/indices

如果您想在您的索引:todo 中搜索某些內容,您可以按照如下所示進行操作 −
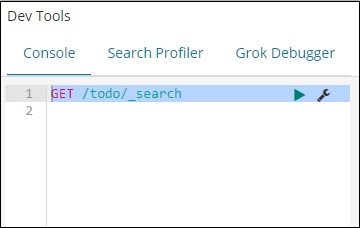
Dev Tools 中的命令
GET /todo/_search
上述搜尋的結果如下所示 −
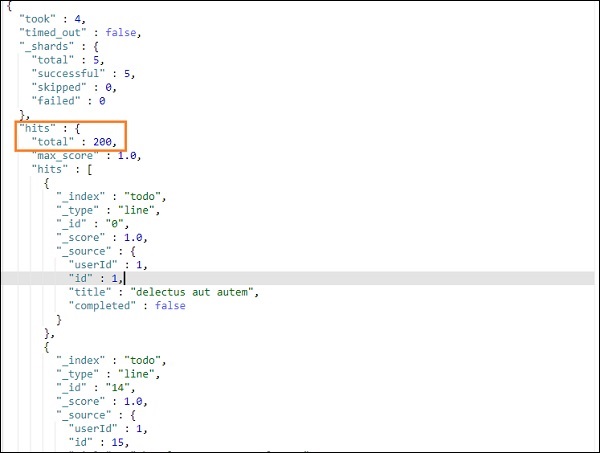
它提供了 todo 索引中存在的所有記錄。我們獲得的總記錄數為 200。
在 todo 索引中搜索記錄
我們可以使用以下命令執行此操作 −
GET /todo/_search
{
"query":{
"match":{
"title":"delectusautautem"
}
}
}
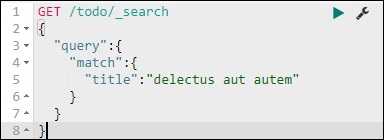
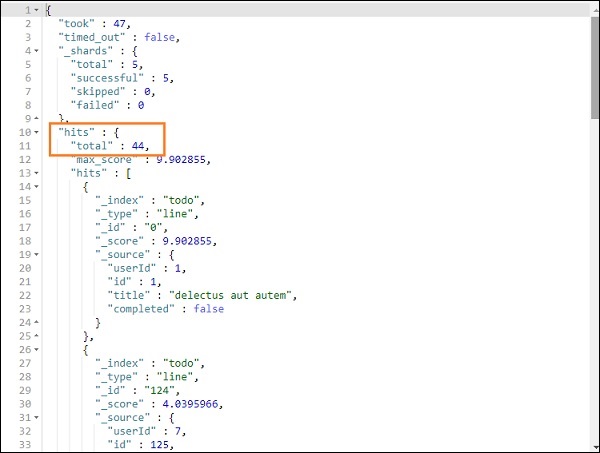
我們能夠獲取與我們提供的標題匹配的記錄。
Kibana - 管理
Kibana 中的管理部分用於管理索引模式。本章將討論以下內容 −
- 建立無時間篩選欄位的索引模式
- 建立有時間篩選欄位的索引模式
建立無時間篩選欄位的索引模式
要執行此操作,請轉到 Kibana UI 並單擊管理 −
要使用 Kibana,我們首先必須建立從 Elasticsearch 填充的索引。您可以從 Elasticsearch → 索引管理中獲取所有可用的索引,如下所示 −
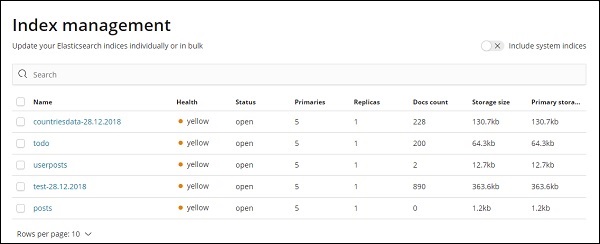
目前 Elasticsearch 擁有上述索引。文件計數告訴我們每個索引中可用的記錄數量。如果任何索引已更新,文件計數將不斷變化。主要儲存空間指示每個上傳索引的大小。
要在 Kibana 中建立新的索引,我們需要單擊索引模式,如下所示 −

單擊索引模式後,我們將看到以下螢幕 −
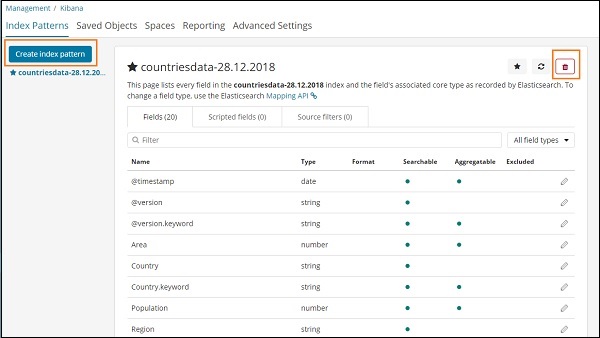
請注意,建立索引模式按鈕用於建立新的索引。回想一下,我們在教程的開始就建立了 countriesdata-28.12.2018。
建立有時間篩選欄位的索引模式
單擊建立索引模式以建立新的索引。
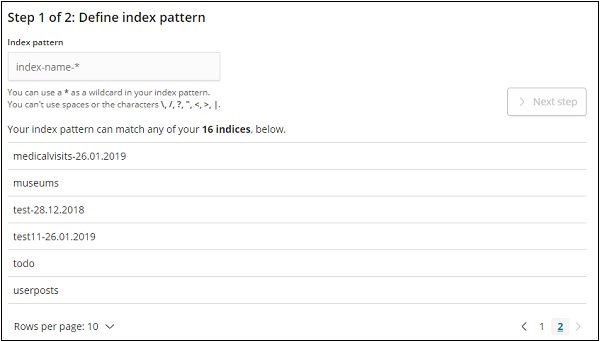
將顯示來自 Elasticsearch 的索引,選擇一個以建立新的索引。
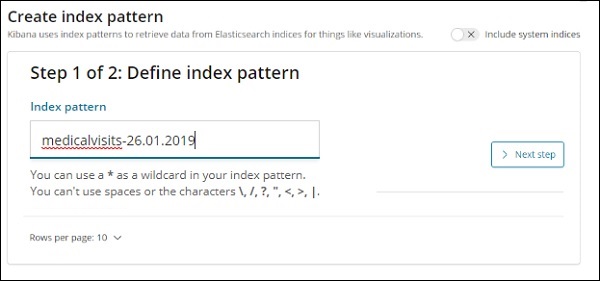
現在,單擊下一步。
下一步是配置設定,您需要輸入以下內容 −
時間篩選欄位名稱用於基於時間篩選資料。下拉選單將顯示索引中所有與時間和日期相關的欄位。
在下圖中,我們有Visiting_Date 作為日期欄位。選擇Visiting_Date 作為時間篩選欄位名稱。
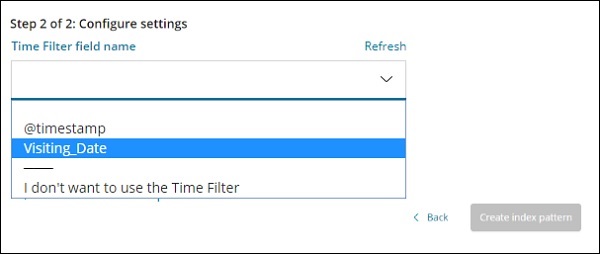
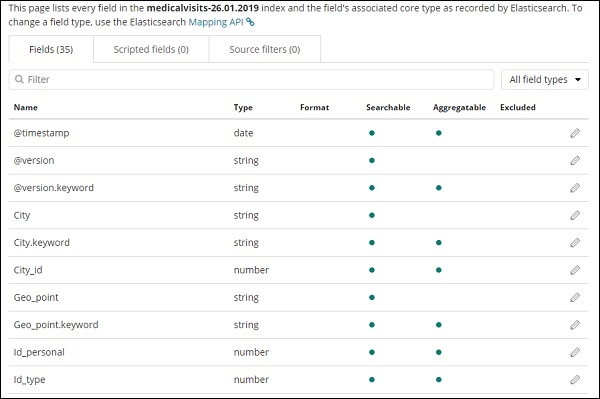
單擊建立索引模式按鈕以建立索引。完成後,它將顯示索引 medicalvisits-26.01.2019 中存在的所有欄位,如下所示 −
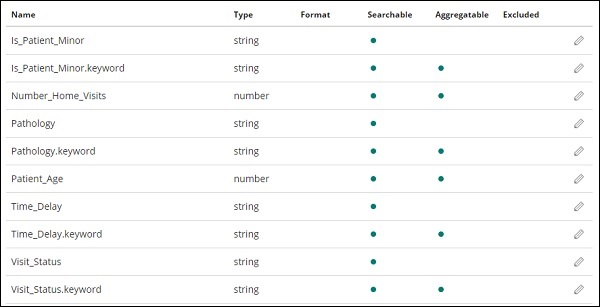
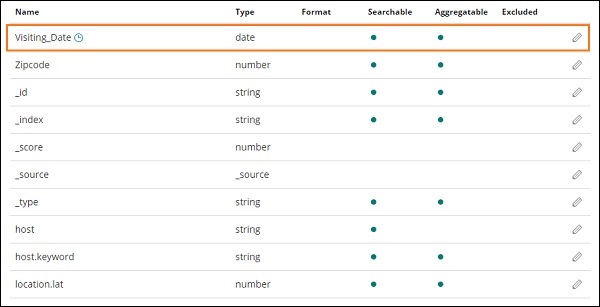
我們在索引 medicalvisits-26.01.2019 中具有以下欄位 −
["Visit_Status","Time_Delay","City","City_id","Patient_Age","Zipcode","Latitude ","Longitude","Pathology","Visiting_Date","Id_type","Id_personal","Number_Home_ Visits","Is_Patient_Minor","Geo_point"].
該索引包含家庭醫療訪問的所有資料。從 Logstash 插入時,Elasticsearch 還添加了一些附加欄位。
Kibana - 探索 (Discover)
本章討論 Kibana UI 中的“發現”選項卡。我們將詳細瞭解以下概念 −
- 無日期欄位的索引
- 有日期欄位的索引
無日期欄位的索引
在左側選單中選擇“發現”,如下所示 −

在右側,它顯示我們在上一章中建立的countriesdata- 28.12.2018 索引中可用資料的詳細資訊。
在左上角,它顯示了可用的總記錄數 −

我們可以在此選項卡中獲取索引(countriesdata-28.12.2018)內資料的詳細資訊。在上圖左上角,我們可以看到“新建”、“儲存”、“開啟”、“共享”、“檢查”和“自動重新整理”等按鈕。
如果單擊“自動重新整理”,它將顯示如下所示的螢幕 −

您可以透過單擊上面的秒、分鐘或小時來設定自動重新整理間隔。Kibana 將自動重新整理螢幕,並在您設定的每個間隔計時器後獲取新資料。
索引:countriesdata-28.12.2018中的資料顯示如下 −
所有欄位及其資料都按行顯示。單擊箭頭展開行,它將以表格格式或 JSON 格式提供詳細資訊


JSON 格式
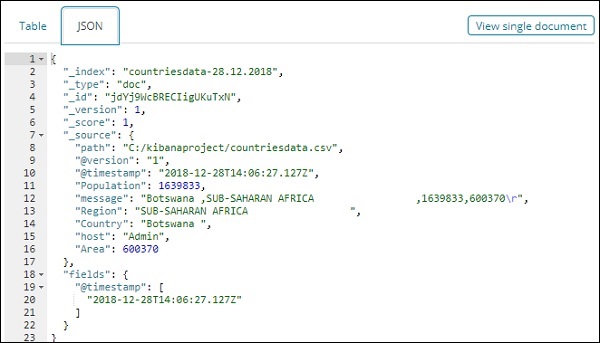
左側有一個名為“檢視單個文件”的按鈕。

如果單擊它,它將顯示頁面內行或行中存在的資料,如下所示 −

儘管我們在這裡獲得了所有資料詳細資訊,但很難逐一檢視它們。
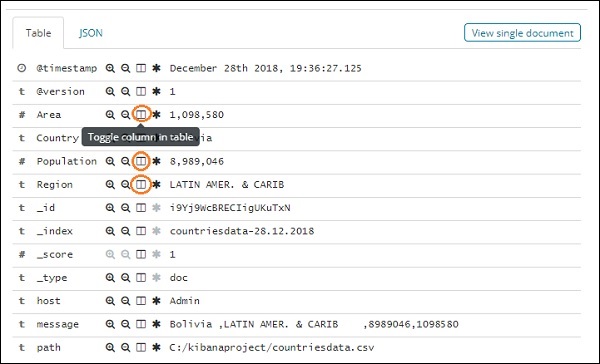
現在讓我們嘗試以表格格式獲取資料。一種方法是展開其中一行,然後單擊每個欄位中提供的切換列選項,如下所示 −
單擊每個欄位中提供的表格中的切換列選項,您將注意到資料以表格格式顯示 −

在這裡,我們選擇了國家/地區、面積、區域和人口欄位。摺疊展開的行,您應該現在會看到所有資料都以表格格式顯示。

我們選擇的欄位顯示在螢幕的左側,如下所示 −

請注意,有兩個選項 − 已選擇欄位和可用欄位。我們選擇以表格格式顯示的欄位是已選擇欄位的一部分。如果您想刪除任何欄位,您可以透過單擊將在已選擇欄位選項中欄位名稱旁顯示的刪除按鈕來執行此操作。
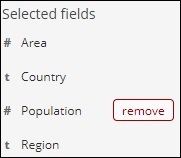
刪除後,該欄位將在可用欄位中可用,您可以透過單擊將在您想要的欄位旁顯示的新增按鈕將其添加回來。您還可以使用此方法透過從可用欄位中選擇所需欄位來以表格格式獲取資料。
我們在“發現”中有一個搜尋選項,我們可以使用它來搜尋索引中的資料。讓我們在此處嘗試與搜尋選項相關的示例 −
假設您想搜尋國家/地區印度,您可以執行以下操作 −

您可以鍵入搜尋詳細資訊並單擊“更新”按鈕。如果您想搜尋以 Aus 開頭的國家/地區,您可以執行以下操作 −

單擊“更新”以檢視結果
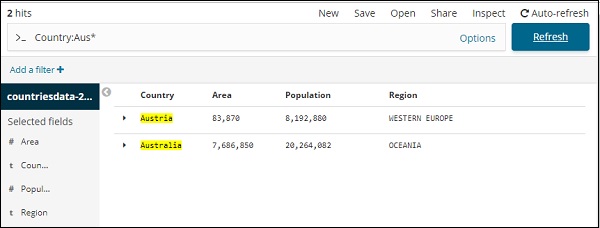
在這裡,我們有兩個以 Aus* 開頭的國家/地區。搜尋欄位有一個選項按鈕,如上所示。當用戶單擊它時,它會顯示一個切換按鈕,當開啟時,它有助於編寫搜尋查詢。

開啟查詢功能並在搜尋中鍵入欄位名稱,它將顯示該欄位可用的選項。
例如,Country 欄位是一個字串,它為字串欄位顯示以下選項 −
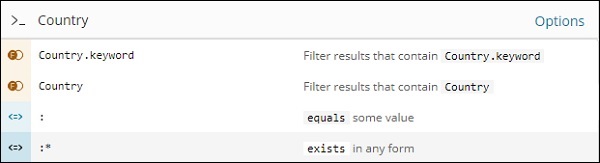
同樣,Area 是一個數字欄位,它為數字欄位顯示以下選項 −
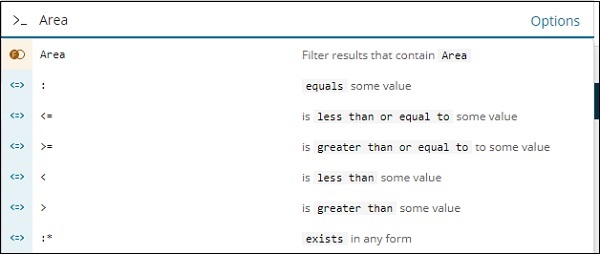
您可以嘗試不同的組合,並根據您在“發現”欄位中的選擇過濾資料。“發現”選項卡中的資料可以使用“儲存”按鈕儲存,以便您可以將其用於將來的用途。
要儲存“發現”中的資料,請單擊右上角的“儲存”按鈕,如下所示 −
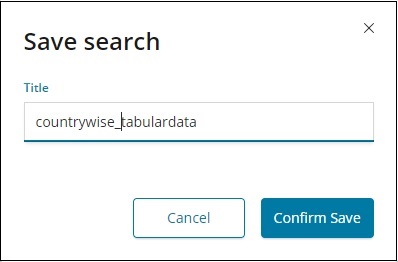
為搜尋指定標題,然後單擊“確認儲存”以儲存它。儲存後,下次訪問“發現”選項卡時,您可以單擊右上角的“開啟”按鈕以獲取儲存的標題,如下所示 −
您還可以使用右上角的“共享”按鈕與他人共享資料。如果單擊它,您可以找到共享選項,如下所示 −

您可以使用 CSV 報告或永久連結的形式共享它。
單擊 CSV 報告後可用的選項是 −

單擊“生成 CSV”以獲取要與他人共享的報告。
點選永久連結後可用的選項如下:
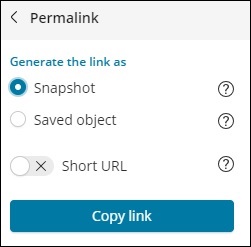
“快照”選項將提供一個 Kibana 連結,該連結將顯示當前搜尋中可用的資料。
“已儲存物件”選項將提供一個 Kibana 連結,該連結將顯示搜尋中最近可用的資料。
快照 − https://:5601/goto/309a983483fccd423950cfb708fabfa5 已儲存物件:https://:5601/app/kibana#/discover/40bd89d0-10b1-11e9-9876-4f3d759b471e?_g=()
您可以使用“發現”選項卡和可用的搜尋選項,並將獲得的結果儲存並與他人共享。
包含日期欄位的索引
轉到“發現”選項卡並選擇索引:medicalvisits-26.01.2019
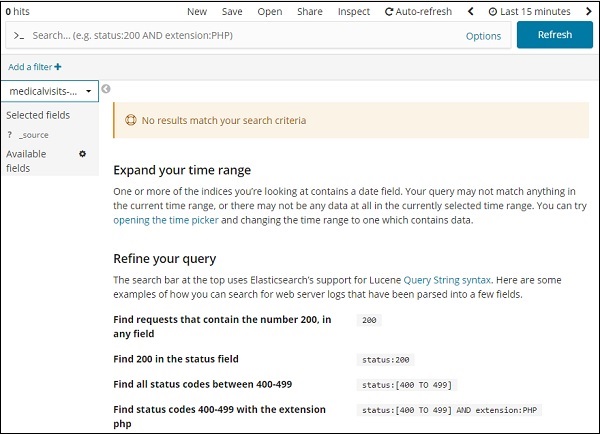
在所選索引上,過去 15 分鐘顯示了訊息 - “沒有結果與您的搜尋條件匹配”。該索引包含 2015 年、2016 年、2017 年和 2018 年的資料。
更改時間範圍,如下所示:

點選“絕對”選項卡。

選擇日期:從 - 2017 年 1 月 1 日到 - 2017 年 12 月 31 日,我們將分析 2017 年的資料。

點選“Go”按鈕新增時間範圍。它將顯示資料和條形圖,如下所示:

這是 2017 年的月度資料:

由於我們還儲存了與日期一起的時間,因此我們也可以按小時和分鐘過濾資料。

上圖顯示了 2017 年的小時資料。
此處顯示的欄位來自索引:medicalvisits-26.01.2019

我們左側有可用的欄位,如下所示:
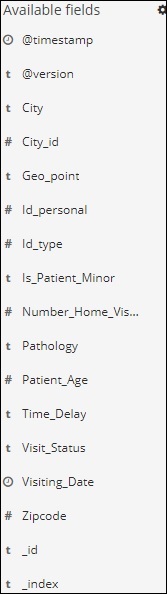
您可以從可用欄位中選擇欄位,並將資料轉換為表格格式,如下所示。在這裡,我們選擇了以下欄位:

以上欄位的表格資料如下所示:

Kibana - 聚合和指標
在學習 Kibana 的過程中,您經常會遇到“桶”和“指標聚合”這兩個術語。本章將討論它們在 Kibana 中的作用以及更多詳細資訊。
什麼是 Kibana 聚合?
聚合是指從特定搜尋查詢或過濾器獲得的文件集合或文件集。聚合構成了在 Kibana 中構建所需視覺化的主要概念。
每當您執行任何視覺化操作時,都需要確定標準,這意味著您希望以何種方式對資料進行分組以對其執行指標。
在本節中,我們將討論兩種型別的聚合:
- 桶聚合
- 指標聚合
桶聚合
桶主要由鍵和文件組成。執行聚合時,文件將放置在相應的桶中。因此,最終您應該獲得一個桶列表,每個桶包含一個文件列表。在 Kibana 中建立視覺化時將看到的桶聚合列表如下所示:

桶聚合具有以下列表:
- 日期直方圖
- 日期範圍
- 過濾器
- 直方圖
- IPv4 範圍
- 範圍
- 重要術語
- 術語
在建立時,您需要為桶聚合決定其中一個,即對桶內的文件進行分組。
例如,為了進行分析,請考慮我們在本教程開始時上傳的國家/地區資料。國家/地區索引中可用的欄位是國家/地區名稱、面積、人口、區域。在國家/地區資料中,我們有國家/地區的名稱以及它們的人口、區域和麵積。
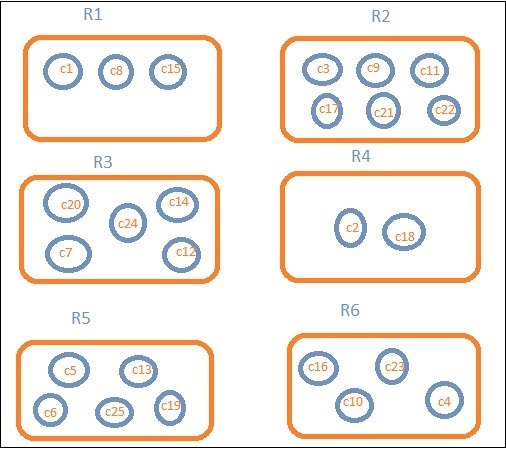
讓我們假設我們想要按區域的資料。然後,每個區域中可用的國家/地區成為我們的搜尋查詢,因此在這種情況下,區域將構成我們的桶。下圖顯示 R1、R2、R3、R4、R5 和 R6 是我們獲得的桶,c1、c2…c25 是屬於桶 R1 到 R6 的文件列表。

我們可以看到每個桶中都有一些圓圈。它們是基於搜尋條件的文件集,並被認為屬於每個桶。在桶 R1 中,我們有文件 c1、c8 和 c15。這些文件是屬於該區域的國家/地區,其他國家/地區也是如此。因此,如果我們計算桶 R1 中的國家/地區數量,則為 3,R2 為 6,R3 為 6,R4 為 2,R5 為 5,R6 為 4。
因此,透過桶聚合,我們可以將文件聚合到桶中,並獲得這些桶中的文件列表,如上所示。
到目前為止,我們擁有的桶聚合列表是:
- 日期直方圖
- 日期範圍
- 過濾器
- 直方圖
- IPv4 範圍
- 範圍
- 重要術語
- 術語
現在讓我們詳細討論如何逐一形成這些桶。
日期直方圖
日期直方圖聚合用於日期欄位。因此,如果您使用的索引中包含日期欄位,則只能使用此聚合型別。這是一個多桶聚合,這意味著您可以將某些文件作為多個桶的一部分。此聚合將使用一個間隔,詳細資訊如下所示:

當您選擇“桶聚合”為“日期直方圖”時,它將顯示“欄位”選項,該選項將僅提供與日期相關的欄位。選擇欄位後,需要選擇間隔,其中包含以下詳細資訊:

因此,根據所選的索引、欄位和間隔,文件將對文件進行分類到桶中。例如,如果您選擇間隔為每月,則基於日期的文件將轉換為桶,並根據月份(即 1 月至 12 月)將文件放入桶中。此處 1 月、2 月…12 月將是桶。
日期範圍
您需要一個日期欄位才能使用此聚合型別。這裡我們將有一個日期範圍,即需要提供開始日期和結束日期。桶將根據提供的開始日期和結束日期包含其文件。

過濾器
使用過濾器型別聚合,桶將根據過濾器形成。在這裡,您將獲得一個多桶,因為基於過濾器標準,一個文件可以存在於一個或多個桶中。
使用過濾器,使用者可以在過濾器選項中編寫他們的查詢,如下所示:
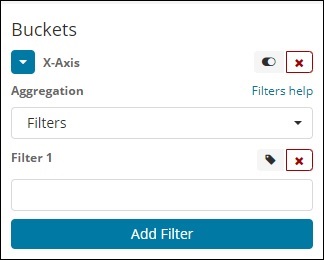
您可以使用“新增過濾器”按鈕新增多個您選擇的過濾器。
直方圖
這種型別的聚合應用於數字欄位,它將根據應用的間隔將文件分組到桶中。例如,0-50、50-100、100-150 等。

IPv4 範圍
這種型別的聚合被使用,主要用於 IP 地址。

我們擁有的索引(即 contriesdata-28.12.2018)沒有型別為 IP 的欄位,因此它會顯示如上所示的訊息。如果您碰巧有 IP 欄位,則可以像上面那樣在其中指定“從”和“到”值。
範圍
這種型別的聚合需要欄位的型別為數字。您需要指定範圍,並且文件將列在落入該範圍的桶中。
如果需要,您可以透過點選“新增範圍”按鈕新增更多範圍。
重要術語
這種型別的聚合主要用於字串欄位。

術語
這種型別的聚合用於所有可用欄位,即數字、字串、日期、布林值、IP 地址、時間戳等。請注意,這是我們將在本教程中進行的所有視覺化操作中將使用的聚合。
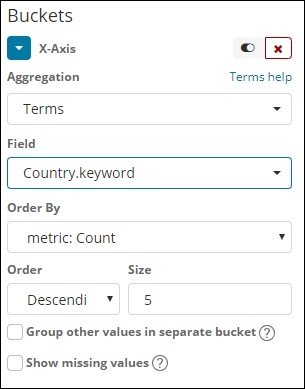
我們有一個按順序排序的選項,我們將根據我們選擇的指標對資料進行分組。大小是指您希望在視覺化中顯示的桶的數量。
接下來,讓我們討論指標聚合。
指標聚合
指標聚合主要指對桶中存在的文件進行的數學計算。例如,如果您選擇一個數字欄位,則可以對其進行的指標計算為 COUNT、SUM、MIN、MAX、AVERAGE 等。
我們將討論的指標聚合列表如下所示:

在本節中,讓我們討論我們將經常使用的一些重要內容:
- 平均值
- 計數
- 最大值
- 最小值
- 總和
指標將應用於我們上面已經討論過的各個桶聚合。
接下來,讓我們在此處討論指標聚合的列表:
平均值
這將給出桶中存在的文件值的平均值。例如:
R1 到 R6 是桶。在 R1 中,我們有 c1、c8 和 c15。考慮 c1 的值為 300,c8 為 500,c15 為 700。現在要獲得 R1 桶的平均值
R1 = c1 的值 + c8 的值 + c15 的值 / 3 = 300 + 500 + 700 / 3 = 500。
R1 桶的平均值為 500。這裡文件的值可以是任何東西,例如,如果您考慮國家/地區資料,它可以是該區域中國家/地區的面積。
計數
這將給出桶中存在的文件數量。例如,如果您想要該區域中存在的國家/地區數量,則將是桶中存在的總文件數量。例如,R1 為 3,R2 = 6,R3 = 5,R4 = 2,R5 = 5,R6 = 4。
最大值
這將給出桶中存在的文件的最大值。考慮到上面的例子,如果我們在區域桶中按區域劃分國家/地區資料。每個區域的最大值將是面積最大的國家/地區。因此,它將從每個區域(即 R1 到 R6)中包含一個國家/地區。
在
這將給出桶中存在的文件的最小值。考慮到上面的例子,如果我們在區域桶中按區域劃分國家/地區資料。每個區域的最小值將是面積最小的國家/地區。因此,它將從每個區域(即 R1 到 R6)中包含一個國家/地區。
總和
這將給出桶中存在的文件值的總和。例如,如果您考慮上面的例子,如果我們想要該區域中國家/地區的總面積或數量,則將是該區域中存在的文件的總和。
例如,要知道區域 R1 中的國家/地區總數,它將是 3,R2 = 6,R3 = 5,R4 = 2,R5 = 5,R6 = 4。
如果我們在該區域中有包含面積的文件,則 R1 到 R6 將對該區域的國家/地區面積進行彙總。
Kibana - 建立視覺化
我們可以以條形圖、折線圖、餅圖等形式視覺化我們擁有的資料。在本節中,我們將瞭解如何建立視覺化。
建立視覺化
轉到 Kibana 視覺化,如下所示:
我們沒有建立任何視覺化,因此它顯示為空白,並且有一個建立視覺化的按鈕。
點選螢幕上方顯示的按鈕建立視覺化,它將帶您進入如下所示的螢幕:
在這裡,您可以選擇您需要視覺化資料的選項。我們將在接下來的章節中詳細瞭解每一個選項。現在,我們將從選擇餅圖開始。
選擇視覺化型別後,接下來需要選擇要處理的索引,然後您將看到如下所示的螢幕:
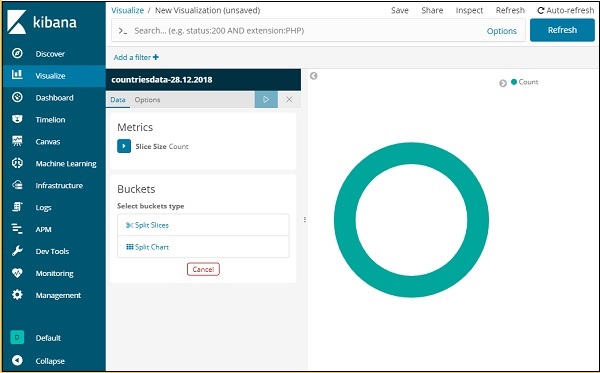
現在我們有一個預設的餅圖。我們將使用countriesdata-28.12.2018資料,以餅圖的形式獲取國家資料中可用區域的數量。
桶和指標聚合
左側是指標,我們將選擇計數。在“桶”中,有兩個選項:“拆分切片”和“拆分圖表”。我們將使用“拆分切片”選項。
現在,選擇“拆分切片”,將顯示以下選項:
現在,選擇“聚合”為“術語”,將顯示更多需要輸入的選項,如下所示:
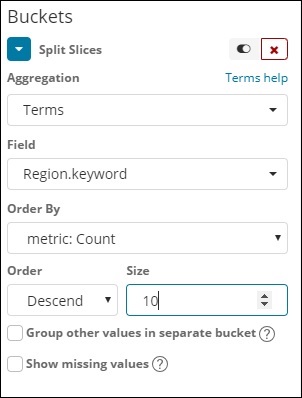
“欄位”下拉選單將包含所選索引:countriesdata中的所有欄位。我們選擇了“區域”欄位和“排序依據”。請注意,我們選擇了“計數”指標作為“排序依據”。我們將按降序排列,大小設定為10。這意味著我們將從國家索引中獲得前10個區域的計數。
現在,單擊如下所示的高亮顯示的“分析”按鈕,您應該會看到右側的餅圖已更新。
餅圖顯示
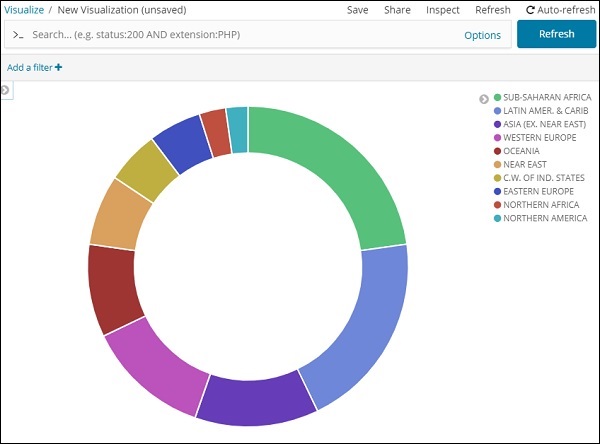
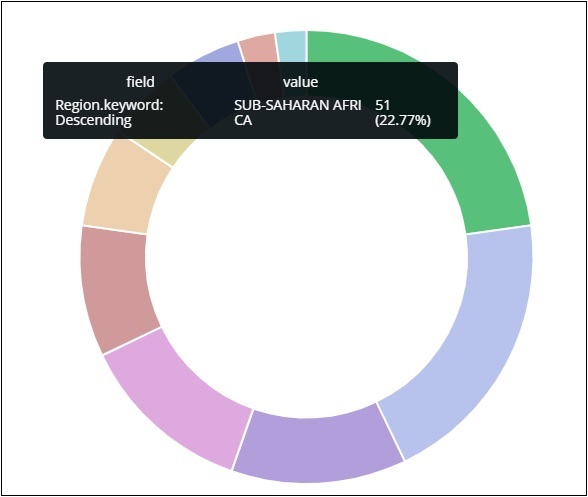
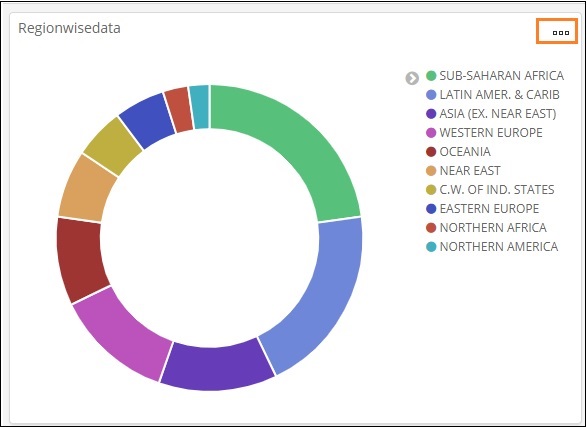
所有區域都列在右上角,帶有顏色,餅圖中顯示相同的顏色。如果將滑鼠懸停在餅圖上,它將顯示區域的計數以及區域的名稱,如下所示:
因此,它告訴我們,在已上傳的國家資料中,撒哈拉以南非洲地區佔據了22.77%的區域。
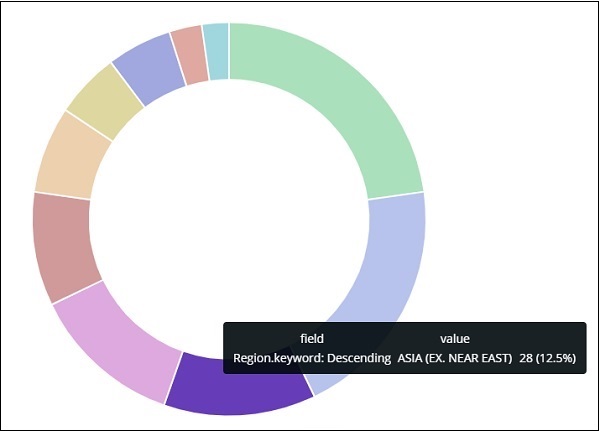
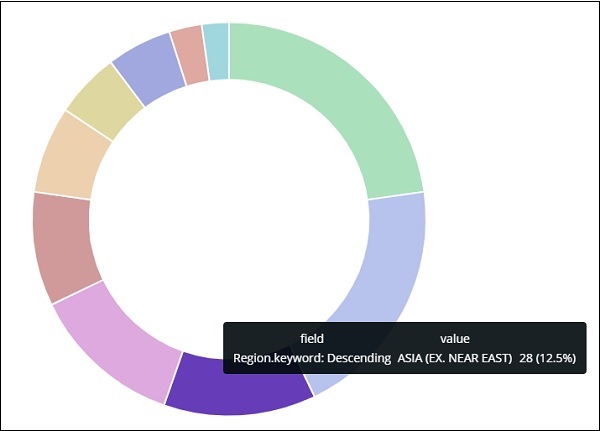
亞洲地區佔12.5%,數量為28。
現在,我們可以單擊右上角的儲存按鈕儲存視覺化,如下所示:

現在,儲存視覺化,以便以後可以使用。
我們還可以使用搜索選項獲取所需的資料,如下所示:
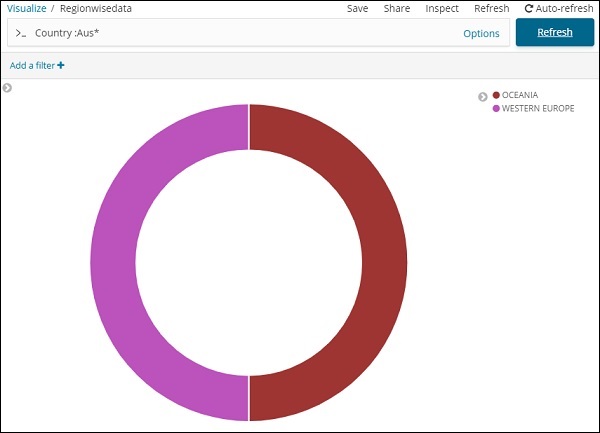
我們過濾了以Aus*開頭的國家的資料。我們將在接下來的章節中更深入地瞭解餅圖和其他視覺化。
Kibana - 使用圖表
讓我們探索並瞭解視覺化中最常用的圖表。
- 水平條形圖
- 垂直條形圖
- 餅圖
以下是建立上述視覺化需要遵循的步驟。讓我們從水平條形圖開始。
水平條形圖
開啟Kibana,單擊左側的“視覺化”選項卡,如下所示:
單擊“+”按鈕建立新的視覺化:
單擊上面列出的“水平條形圖”。您需要選擇要視覺化的索引。
選擇**countriesdata-28.12.2018**索引,如上所示。選擇索引後,將顯示如下所示的螢幕:
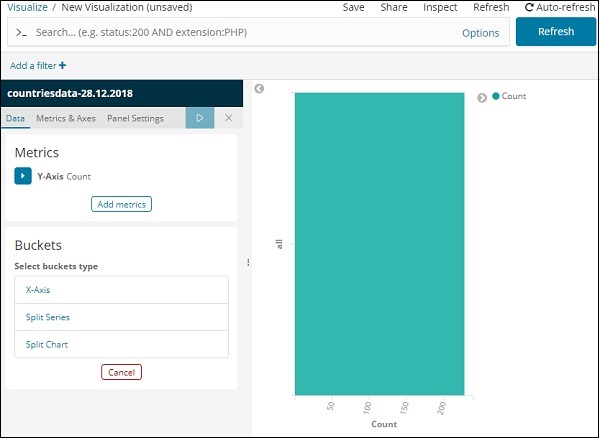
它顯示預設計數。現在,讓我們繪製一個水平圖表,在其中可以看到前10個國家的人口資料。
為此,我們需要選擇要在Y軸和X軸上顯示的內容。因此,選擇“桶”和“指標聚合”:

現在,如果您單擊Y軸,將顯示如下所示的螢幕:
現在,從此處顯示的選項中選擇所需的聚合:
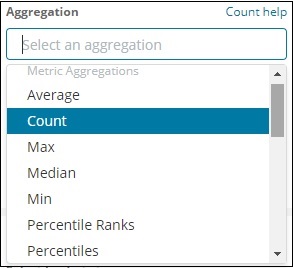
請注意,這裡我們將選擇“最大值”聚合,因為我們希望根據可用的最大人口顯示資料。
接下來,我們必須選擇需要其最大值的欄位。在索引countriesdata-28.12.2018中,我們只有2個數字欄位——面積和人口。
由於我們需要最大人口,因此我們選擇“人口”欄位,如下所示:
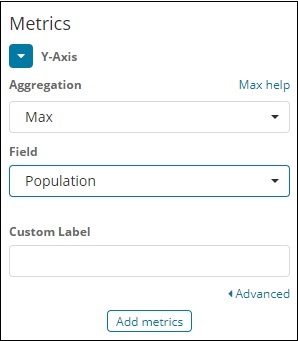
透過此操作,我們就完成了Y軸的操作。我們為Y軸獲得的輸出如下所示:
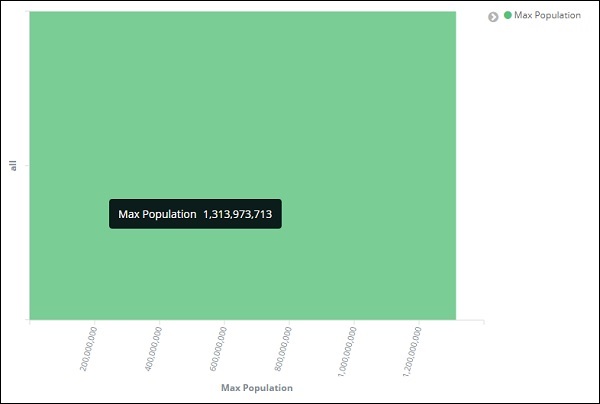
現在讓我們選擇X軸,如下所示:
如果選擇X軸,您將獲得以下輸出:
選擇“聚合”為“術語”。
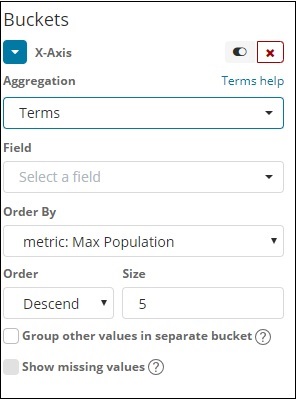
從下拉選單中選擇欄位。我們想要按國家人口繪製圖表,因此選擇“國家”欄位。對於“排序依據”,我們有以下選項:
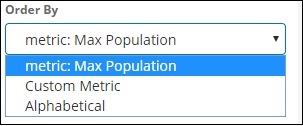
我們將選擇“排序依據”為“最大人口”,因為我們希望首先顯示人口最多的國家,依此類推。新增所需資料後,單擊“指標”資料頂部的“應用更改”按鈕,如下所示:
單擊“應用更改”後,我們將獲得水平圖表,在該圖表中我們可以看到中國是人口最多的國家,其次是印度、美國等。
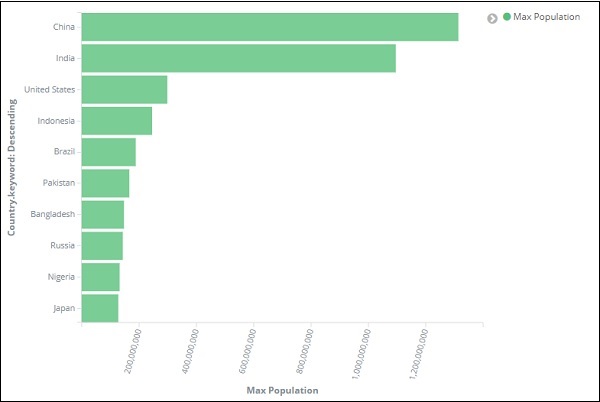
同樣,您可以透過選擇所需的欄位來繪製不同的圖表。接下來,我們將儲存此視覺化為max_population,以便以後用於儀表板建立。
在下一節中,我們將建立垂直條形圖。
垂直條形圖
單擊“視覺化”選項卡,並使用垂直條形圖和索引**countriesdata-28.12.2018**建立新的視覺化。
在此垂直條形圖視覺化中,我們將建立一個按國家面積繪製的條形圖,即顯示面積最大的國家。
因此,讓我們選擇Y軸和X軸,如下所示:
Y軸
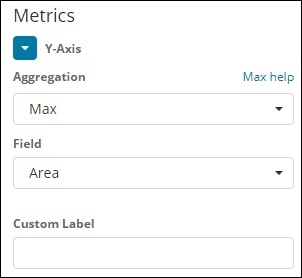
X軸
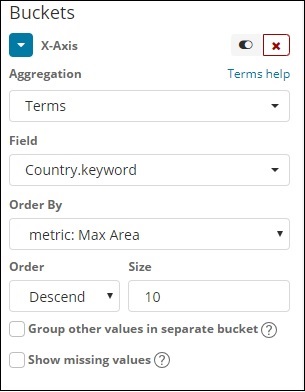
在此處應用更改後,我們可以看到如下所示的輸出:
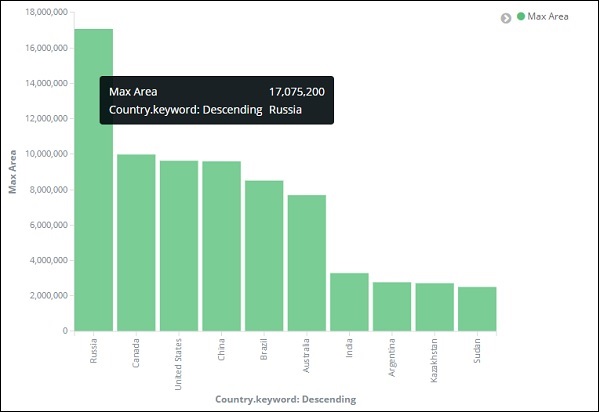
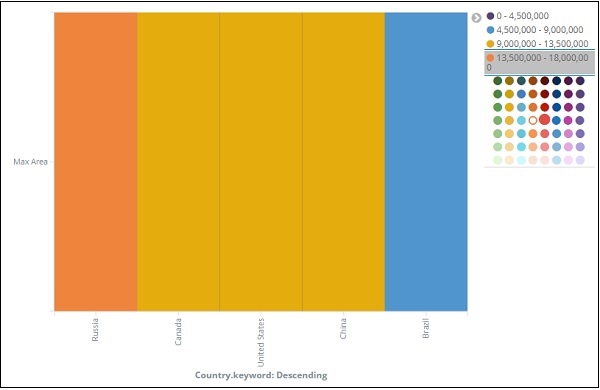
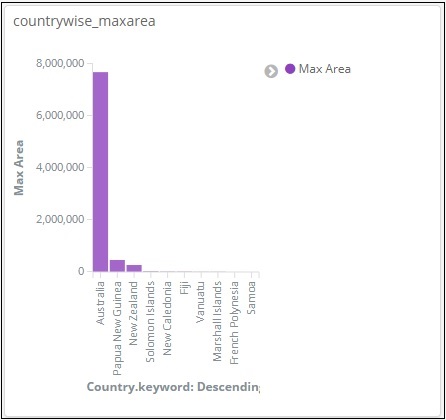
從圖表中,我們可以看到俄羅斯面積最大,其次是加拿大和美國。請注意,此資料是從countriesdata索引中提取的,它是虛擬資料,因此數字可能與即時資料不符。
讓我們將此視覺化儲存為countrywise_maxarea,以便以後與儀表板一起使用。
接下來,讓我們處理餅圖。
餅圖
因此,首先建立一個視覺化,並選擇餅圖,索引為countriesdata。我們將以餅圖的形式顯示countriesdata中可用區域的數量。
左側是指標,將提供計數。在“桶”中,有兩個選項:“拆分切片”和“拆分圖表”。現在,我們將使用“拆分切片”選項。
現在,如果您選擇“拆分切片”,將顯示以下選項:
選擇“聚合”為“術語”,將顯示更多需要輸入的選項,如下所示:
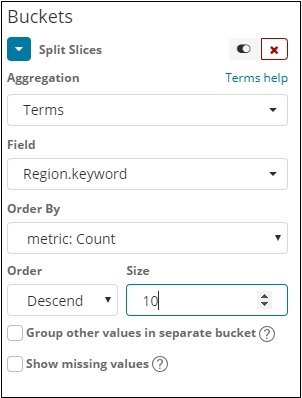
“欄位”下拉選單將包含所選索引中的所有欄位。我們選擇了“區域”欄位和“排序依據”,我們將其選擇為“計數”。我們將按降序排列,大小將設定為10。因此,我們將獲得國家索引中10個區域的計數。
現在,單擊如下所示的高亮顯示的播放按鈕,您應該會看到右側的餅圖已更新。
餅圖顯示
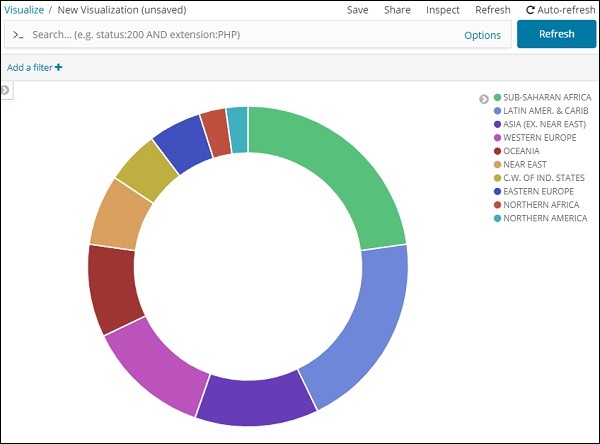
所有區域都列在右上角,帶有顏色,餅圖中顯示相同的顏色。如果將滑鼠懸停在餅圖上,它將顯示區域的計數以及區域的名稱,如下所示:
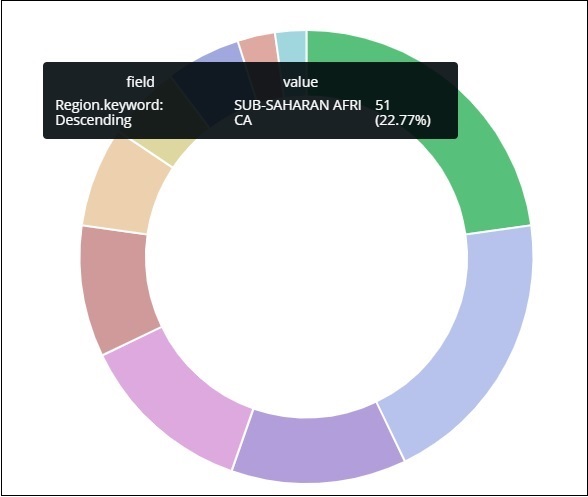
因此,它告訴我們,在已上傳的國家資料中,撒哈拉以南非洲地區佔據了22.77%的區域。
從餅圖中可以看出,亞洲地區佔12.5%,數量為28。
現在,我們可以單擊右上角的儲存按鈕儲存視覺化,如下所示:

現在,儲存視覺化,以便以後在儀表板中使用。
Kibana - 使用圖形
在本節中,我們將討論視覺化中使用的兩種型別的圖表:
- 折線圖
- 面積圖
折線圖
首先,讓我們建立一個視覺化,選擇折線圖來顯示資料,並使用countriesdata作為索引。我們需要建立Y軸和X軸,以及相同的詳細資訊,如下所示:
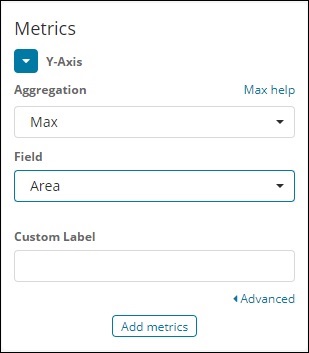
對於Y軸

請注意,我們已將“最大值”作為聚合。因此,我們將在此處顯示折線圖中的資料表示。現在,我們將繪製一個圖表,該圖表將顯示按國家劃分的最大人口。我們選擇的欄位是“人口”,因為我們需要按國家劃分的最大人口。
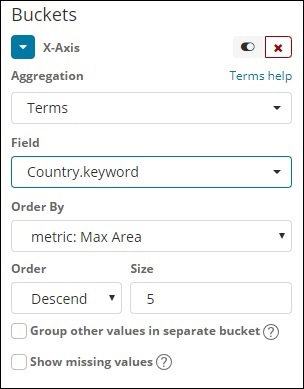
對於X軸

在x軸上,我們選擇了“術語”作為聚合,“Country.keyword”作為欄位,並選擇了“指標:最大人口”作為“排序依據”,順序大小為5。因此,它將繪製前5個最大人口的國家。應用更改後,您可以看到如下所示的折線圖:

因此,中國的人口最多,其次是印度、美國、印度尼西亞和巴西,它們是人口最多的前5個國家。
現在,讓我們儲存此折線圖,以便以後可以在儀表板中使用。
單擊“確認儲存”,即可儲存視覺化。
面積圖
轉到視覺化,選擇面積圖,索引為countriesdata。我們需要選擇Y軸和X軸。我們將繪製按國家劃分的最大面積的面積圖。
因此,此處X軸和Y軸將如下所示:
單擊“應用更改”按鈕後,我們可以看到的輸出如下所示:

從圖表中,我們可以看出俄羅斯面積最大,其次是加拿大、美國、中國和巴西。儲存視覺化以便以後使用。
Kibana - 使用熱力圖
在本節中,我們將瞭解如何使用熱力圖。熱力圖將以不同的顏色顯示資料表示,用於在資料指標中選擇的範圍。
開始使用熱力圖
首先,我們需要透過單擊左側的“視覺化”選項卡來建立視覺化,如下所示:

選擇熱力圖作為視覺化型別,如上所示。它將要求您選擇索引,如下所示:

選擇索引**countriesdata-28.12.2018**,如上所示。選擇索引後,我們將選擇要顯示的資料,如下所示:

選擇指標,如下所示:

從下拉選單中選擇“最大值”聚合,如下所示:

我們選擇“最大值”,因為我們想要繪製按國家劃分的最大面積。
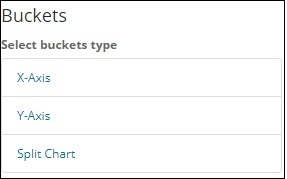
現在,我們將為“桶”選擇值,如下所示:
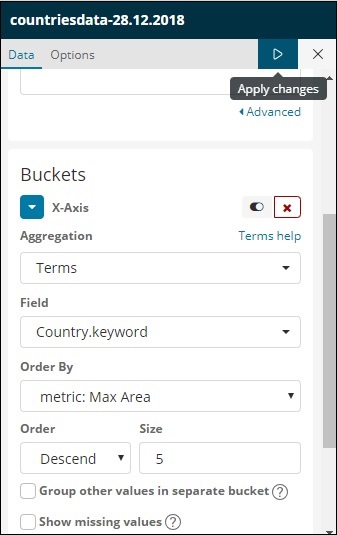
現在,讓我們選擇X軸,如下所示:

我們使用“術語”作為聚合,“國家”作為欄位,“最大面積”作為“排序依據”。單擊“應用更改”,如下所示:
如果單擊“應用更改”,熱力圖將如下所示:

熱力圖以不同的顏色顯示,面積範圍顯示在右側。您可以透過單擊面積範圍旁邊的圓圈來更改顏色,如下所示:
Kibana - 使用座標地圖
Kibana中的座標地圖將顯示地理區域,並根據您指定的聚合標記區域。
為座標地圖建立索引
用於座標地圖的桶聚合是geohash聚合。對於這種型別的聚合,您將使用的索引應該具有地理點型別的欄位。地理點是緯度和經度的組合。
我們將使用Kibana開發工具建立一個索引,並向其中新增批次資料。我們將新增對映並新增所需的geo_point型別。
我們將使用的資料如下所示:
{"index":{"_id":1}}
{"location": "2.089330000000046,41.47367000000008", "city": "SantCugat"}
{"index":{"_id":2}}
{"location": "2.2947825000000677,41.601800991000076", "city": "Granollers"}
{"index":{"_id":3}}
{"location": "2.1105957495300474,41.5496295760424", "city": "Sabadell"}
{"index":{"_id":4}}
{"location": "2.132605678083895,41.5370461908878", "city": "Barbera"}
{"index":{"_id":5}}
{"location": "2.151270020052683,41.497779918345415", "city": "Cerdanyola"}
{"index":{"_id":6}}
{"location": "2.1364609496220606,41.371303520399344", "city": "Barcelona"}
{"index":{"_id":7}}
{"location": "2.0819450306711165,41.385491966414705", "city": "Sant Just Desvern"}
{"index":{"_id":8}}
{"location": "2.00532082278266,41.542294286427385", "city": "Rubi"}
{"index":{"_id":9}}
{"location": "1.9560805366930398,41.56142635214226", "city": "Viladecavalls"}
{"index":{"_id":10}}
{"location": "2.09205348251486,41.39327140161001", "city": "Esplugas de Llobregat"}
現在,在Kibana開發工具中執行以下命令,如下所示:
PUT /cities
{
"mappings": {
"_doc": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
}
POST /cities/_city/_bulk?refresh
{"index":{"_id":1}}
{"location": "2.089330000000046,41.47367000000008", "city": "SantCugat"}
{"index":{"_id":2}}
{"location": "2.2947825000000677,41.601800991000076", "city": "Granollers"}
{"index":{"_id":3}}
{"location": "2.1105957495300474,41.5496295760424", "city": "Sabadell"}
{"index":{"_id":4}}
{"location": "2.132605678083895,41.5370461908878", "city": "Barbera"}
{"index":{"_id":5}}
{"location": "2.151270020052683,41.497779918345415", "city": "Cerdanyola"}
{"index":{"_id":6}}
{"location": "2.1364609496220606,41.371303520399344", "city": "Barcelona"}
{"index":{"_id":7}}
{"location": "2.0819450306711165,41.385491966414705", "city": "Sant Just Desvern"}
{"index":{"_id":8}}
{"location": "2.00532082278266,41.542294286427385", "city": "Rubi"}
{"index":{"_id":9}}
{"location": "1.9560805366930398,41.56142635214226", "city": "Viladecavalls"}
{"index":{"_id":10}}
{"location": "2.09205348251486,41.3s9327140161001", "city": "Esplugas de Llobregat"}
現在,在Kibana開發工具中執行上述命令:
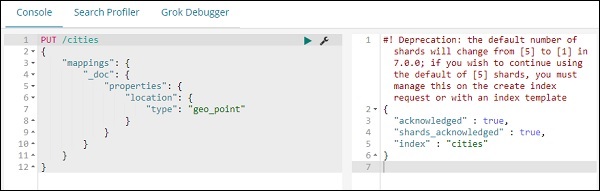
以上操作將建立一個名為 cities 的索引,型別為 _doc,欄位 location 的型別為 geo_point。
現在讓我們向 cities 索引新增資料:
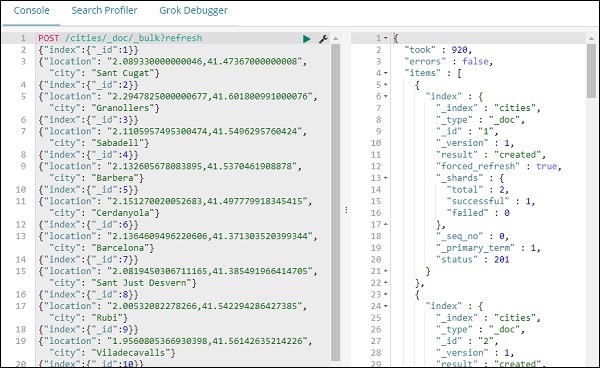
我們已經建立了名為 cites 的索引並添加了資料。現在讓我們使用管理選項卡為 cities 建立索引模式。
cities 索引中欄位的詳細資訊如下:
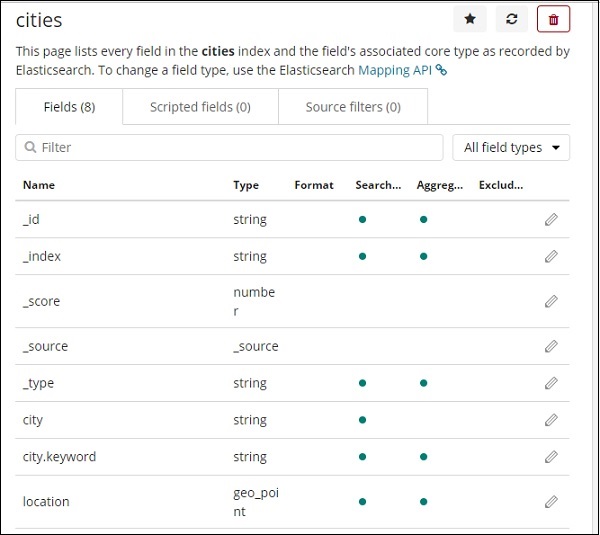
我們可以看到 location 的型別為 geo_point。現在我們可以使用它來建立視覺化。
座標地圖入門
轉到“視覺化”並選擇“座標地圖”。
選擇索引模式 cities 並配置聚合指標和桶,如下所示:
如果單擊“分析”按鈕,您將看到以下螢幕:
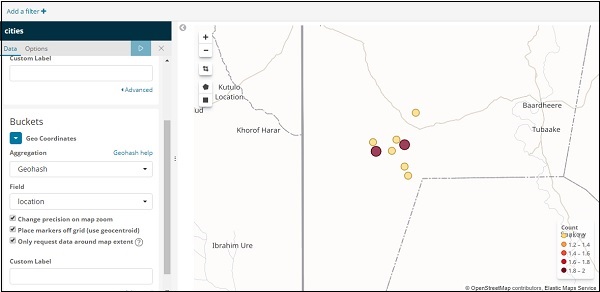
根據經度和緯度,圓圈將繪製在地圖上,如上所示。
Kibana - 使用區域地圖
透過此視覺化,您可以看到在地理世界地圖上表示的資料。在本節中,讓我們詳細瞭解一下。
為區域地圖建立索引
我們將建立一個新的索引來使用區域地圖視覺化。我們將上傳的資料如下所示:
{"index":{"_id":1}}
{"country": "China", "population": "1313973713"}
{"index":{"_id":2}}
{"country": "India", "population": "1095351995"}
{"index":{"_id":3}}
{"country": "United States", "population": "298444215"}
{"index":{"_id":4}}
{"country": "Indonesia", "population": "245452739"}
{"index":{"_id":5}}
{"country": "Brazil", "population": "188078227"}
{"index":{"_id":6}}
{"country": "Pakistan", "population": "165803560"}
{"index":{"_id":7}}
{"country": "Bangladesh", "population": "147365352"}
{"index":{"_id":8}}
{"country": "Russia", "population": "142893540"}
{"index":{"_id":9}}
{"country": "Nigeria", "population": "131859731"}
{"index":{"_id":10}}
{"country": "Japan", "population": "127463611"}
請注意,我們將使用 dev tools 中的 _bulk 上傳來上傳資料。
現在,轉到 Kibana Dev Tools 並執行以下查詢:
PUT /allcountries
{
"mappings": {
"_doc": {
"properties": {
"country": {"type": "keyword"},
"population": {"type": "integer"}
}
}
}
}
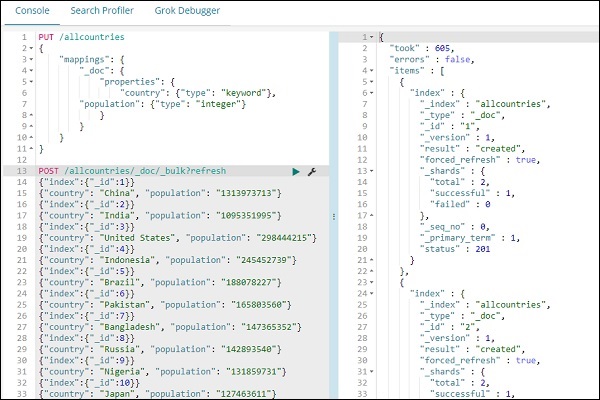
POST /allcountries/_doc/_bulk?refresh
{"index":{"_id":1}}
{"country": "China", "population": "1313973713"}
{"index":{"_id":2}}
{"country": "India", "population": "1095351995"}
{"index":{"_id":3}}
{"country": "United States", "population": "298444215"}
{"index":{"_id":4}}
{"country": "Indonesia", "population": "245452739"}
{"index":{"_id":5}}
{"country": "Brazil", "population": "188078227"}
{"index":{"_id":6}}
{"country": "Pakistan", "population": "165803560"}
{"index":{"_id":7}}
{"country": "Bangladesh", "population": "147365352"}
{"index":{"_id":8}}
{"country": "Russia", "population": "142893540"}
{"index":{"_id":9}}
{"country": "Nigeria", "population": "131859731"}
{"index":{"_id":10}}
{"country": "Japan", "population": "127463611"}
接下來,讓我們建立 allcountries 索引。我們已將國家欄位型別指定為 **keyword**:
PUT /allcountries
{
"mappings": {
"_doc": {
"properties": {
"country": {"type": "keyword"},
"population": {"type": "integer"}
}
}
}
}
**注意** - 要使用區域地圖,我們需要將用作聚合的欄位型別指定為 keyword。
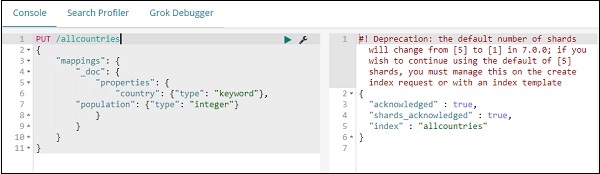
完成後,使用 _bulk 命令上傳資料。
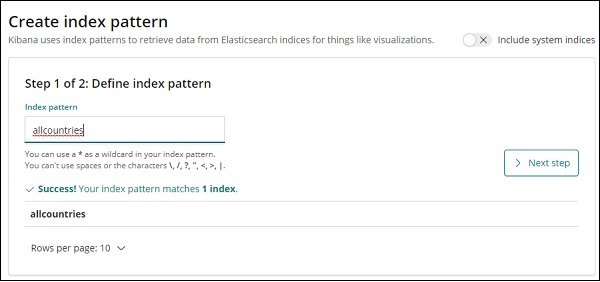
現在我們將建立索引模式。轉到 Kibana 管理選項卡並選擇建立索引模式。
以下是 allcountries 索引中顯示的欄位。

區域地圖入門
現在,我們將使用區域地圖建立視覺化。轉到“視覺化”並選擇“區域地圖”。
完成後,選擇索引為 *allcountries* 並繼續。
選擇聚合指標和桶指標,如下所示:

在這裡,我們選擇欄位為 country,因為我想在世界地圖上顯示它。
區域地圖的向量地圖和連線欄位
對於區域地圖,我們還需要選擇選項卡,如下所示:

選項卡具有在世界地圖上繪製資料所需的圖層設定配置。
向量地圖具有以下選項:
在這裡,我們將選擇 world countries,因為我擁有國家資料。
連線欄位具有以下詳細資訊:
在我們的索引中,我們有國家名稱,因此我們將選擇國家名稱。
在樣式設定中,您可以選擇要為國家/地區顯示的顏色:
我們將選擇 Reds。我們不會觸及其餘的詳細資訊。
現在,單擊“分析”按鈕以檢視繪製在世界地圖上的國家/地區的詳細資訊,如下所示:
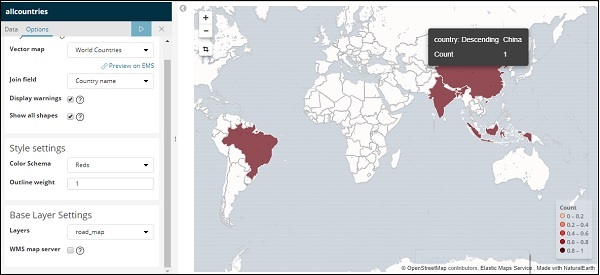
在 Kibana 中自託管向量地圖和連線欄位
您還可以為向量地圖和連線欄位新增您自己的 Kibana 設定。為此,請從 kibana 配置資料夾轉到 kibana.yml 並新增以下詳細資訊:
regionmap:
includeElasticMapsService: false
layers:
- name: "Countries Data"
url: "https:///kibana/worldcountries.geojson"
attribution: "INRAP"
fields:
- name: "Country"
description: "country names"
選項卡中的向量地圖將填充上述資料,而不是預設資料。請注意,給定的 URL 必須啟用 CORS,以便 Kibana 可以下載它。使用的 json 檔案應使座標連續。例如:
https://vector.maps.elastic.co/blob/5659313586569216?elastic_tile_service_tos=agree當區域地圖向量地圖詳細資訊為自託管時,選項卡如下所示:

Kibana - 使用儀表和目標
儀表視覺化顯示您根據資料考慮的指標如何落在預定義範圍內。
目標視覺化顯示您的目標以及您資料的指標如何朝著目標發展。
使用儀表
要開始使用儀表,請轉到視覺化並從 Kibana UI 選擇視覺化選項卡。
單擊儀表並選擇要使用的索引。

我們將使用 *medicalvisits-26.01.2019* 索引。
選擇 2017 年 2 月的時間範圍

現在您可以選擇指標和桶聚合。

我們已將指標聚合選擇為計數。

我們選擇的桶聚合是 Terms,選擇的欄位是 Number_Home_Visits。
從資料選項卡中,選擇的選項如下所示:
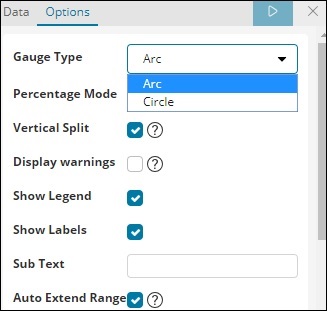
儀表型別可以是圓形或弧形。我們已將其選擇為弧形,其餘所有內容均為預設值。
我們新增的預定義範圍如下所示:

選擇的顏色為綠色到紅色。
現在,單擊“分析”按鈕以檢視儀表形式的視覺化,如下所示:

使用目標
轉到視覺化選項卡並選擇目標,如下所示:
選擇目標並選擇索引。
使用 *medicalvisits-26.01.2019* 作為索引。
選擇指標聚合和桶聚合。
指標聚合

我們已選擇計數作為指標聚合。
桶聚合
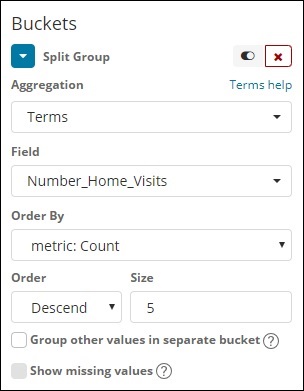
我們已選擇 Terms 作為桶聚合,欄位為 Number_Home_Visits。
選擇的選項如下:
選擇的範圍如下:

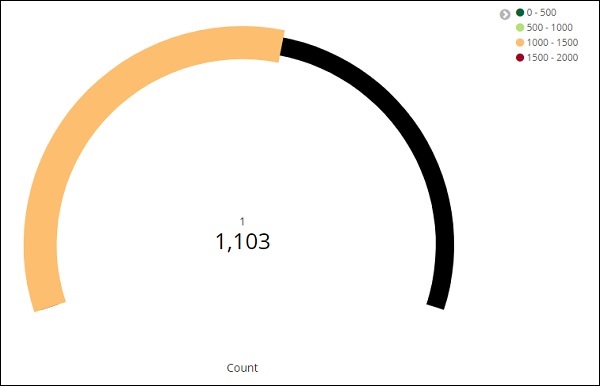
單擊分析,您將看到目標顯示如下:
Kibana - 使用畫布 (Canvas)
畫布是 Kibana 中另一個強大的功能。使用畫布視覺化,您可以以不同的顏色組合、形狀、文字、多頁設定等來表示您的資料。
我們需要在畫布中顯示資料。現在,讓我們載入 Kibana 中已有的某些樣本資料。
載入畫布建立的樣本資料
要獲取樣本資料,請轉到 Kibana 首頁並單擊新增樣本資料,如下所示:

單擊載入資料集和 Kibana 儀表板。它將帶您進入如下所示的螢幕:
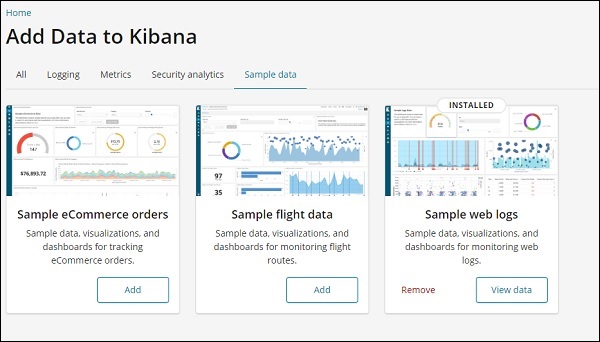
單擊樣本電子商務訂單的新增按鈕。載入樣本資料需要一些時間。完成後,您將收到一條警報訊息,顯示“已載入樣本電子商務資料”。
畫布視覺化入門
現在轉到畫布視覺化,如下所示:
單擊畫布,它將顯示如下所示的螢幕:
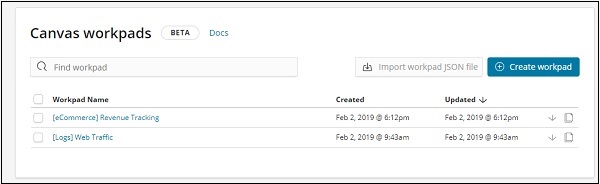
我們添加了電子商務和網路流量樣本資料。我們可以建立新的工作區或使用現有的工作區。
在這裡,我們將選擇現有的工作區。選擇電子商務收入跟蹤工作區名稱,它將顯示如下所示的螢幕:
在畫布中克隆現有工作區
我們將克隆工作區,以便我們可以對其進行更改。要克隆現有工作區,請單擊左下方顯示的工作區名稱:
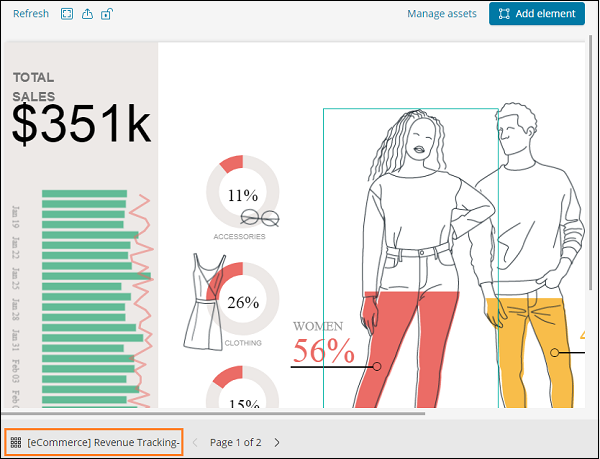
單擊名稱並選擇克隆選項,如下所示:
單擊克隆按鈕,它將建立電子商務收入跟蹤工作區的副本。您可以找到它,如下所示:
在本節中,讓我們瞭解如何使用工作區。如果您看到上面的工作區,它有 2 頁。因此,在畫布中,我們可以表示多頁資料。
第 2 頁顯示如下:

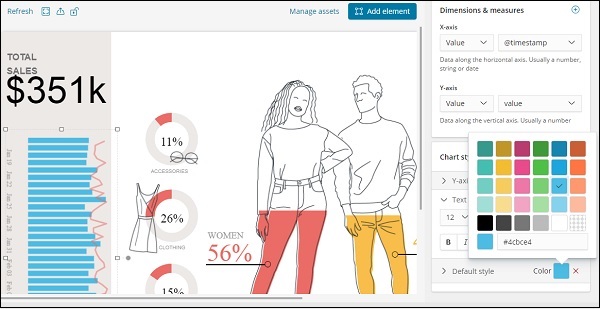
選擇第 1 頁並單擊左側顯示的總銷售額,如下所示:
在右側,您將獲得與其相關的資料:
現在使用的預設樣式為綠色。我們可以在此處更改顏色並檢查相同的顯示。
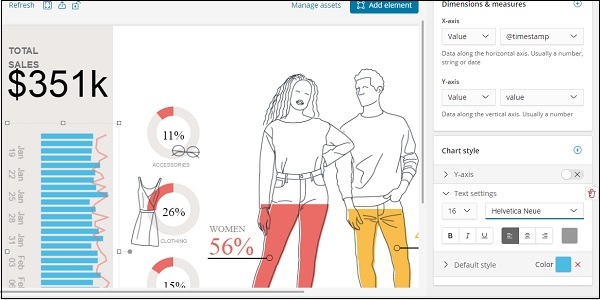
我們還更改了文字設定的字型和大小,如下所示:
向畫布內的工作區新增新頁面
要向工作區新增新頁面,請按照以下步驟操作:
建立頁面後,如下所示:
單擊新增元素,它將顯示所有可能的視覺化,如下所示:
我們添加了兩個元素資料表和區域圖,如下所示
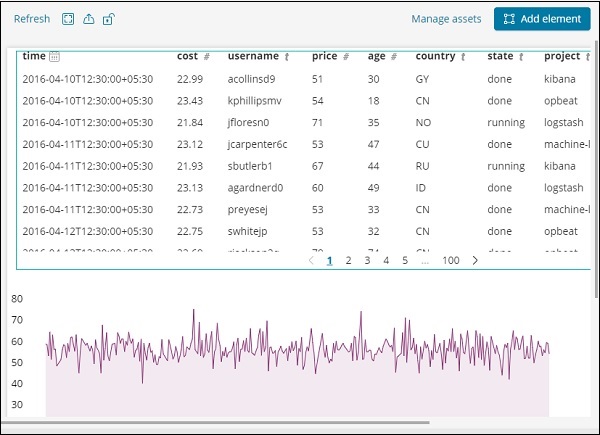
您可以向同一頁面新增更多資料元素,也可以新增更多頁面。
Kibana - 建立儀表盤
在我們之前的章節中,我們已經瞭解瞭如何建立垂直條形圖、水平條形圖、餅圖等形式的視覺化。在本節中,讓我們學習如何將它們組合在一起形成儀表板。儀表板是您建立的視覺化的集合,以便您可以一次檢視所有視覺化。
儀表板入門
要在 Kibana 中建立儀表板,請單擊如下所示的儀表板選項:
現在,單擊如上所示的建立新儀表板按鈕。它將帶我們進入如下所示的螢幕:
觀察到我們到目前為止還沒有建立任何儀表板。頂部有一些選項,我們可以儲存、取消、新增、選項、共享、自動重新整理,還可以更改時間以獲取儀表板上的資料。我們將透過單擊上面顯示的新增按鈕來建立一個新的儀表板。
將視覺化新增到儀表板
當我們單擊新增按鈕(左上角)時,它會顯示我們建立的視覺化,如下所示:
選擇要新增到儀表板的視覺化。我們將選擇前三個視覺化,如下所示:
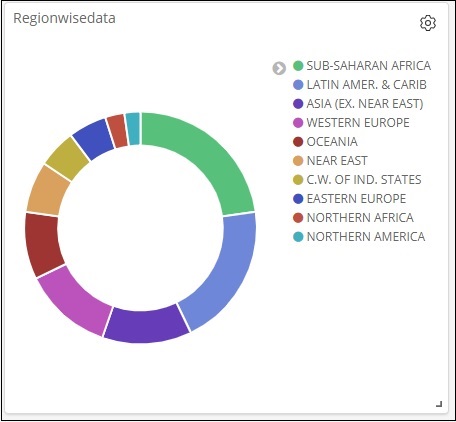
這就是它一起在螢幕上的顯示方式:
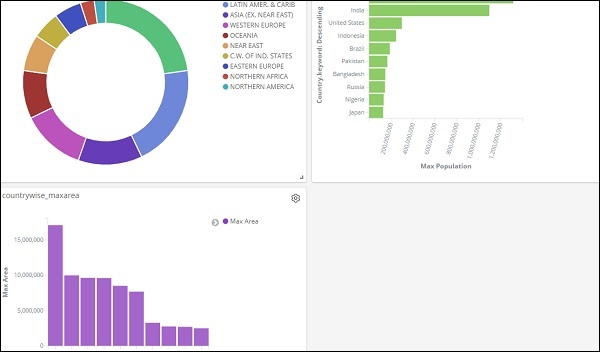
因此,作為使用者,您可以獲得有關我們上傳的資料的總體詳細資訊 - 按國家/地區劃分,欄位包括國家/地區名稱、區域名稱、面積和人口。
因此,現在我們知道所有可用的區域、按人口數量降序排列的每個國家的最大人口、最大面積等。
這只是我們上傳的樣本資料視覺化,但在現實世界中,跟蹤業務詳細資訊變得非常容易,例如,您有一個網站,每月或每天獲得數百萬次點選,您想跟蹤每天、每小時、每分鐘、每秒完成的銷售情況,如果您擁有 ELK 堆疊,Kibana 可以每小時、每分鐘、每秒向您展示銷售視覺化,您可以根據需要檢視。它會顯示正在現實世界中發生的事情的即時資料。
總的來說,Kibana 在提取有關您每日、每小時或每分鐘業務交易的準確詳細資訊方面發揮著非常重要的作用,因此公司知道進展如何。
儲存儀表板
您可以使用頂部的儲存按鈕儲存儀表板。
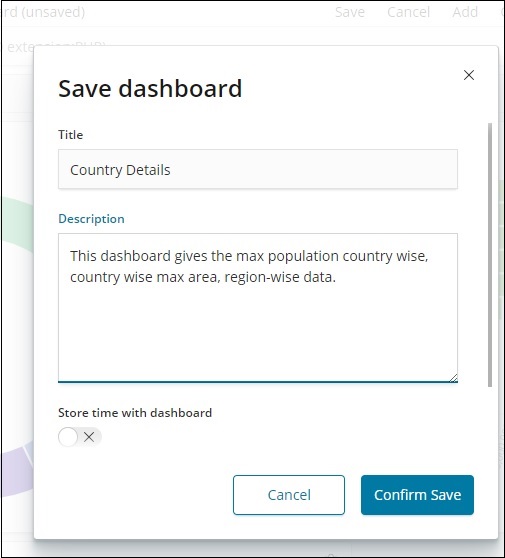
有一個標題和描述,您可以在其中輸入儀表板的名稱和簡短描述,說明儀表板的功能。現在,單擊確認儲存以儲存儀表板。
更改儀表板的時間範圍
目前,您可以看到顯示的資料是過去 15 分鐘的資料。請注意,這是一個沒有時間欄位的靜態資料,因此顯示的資料不會更改。當您將資料連線到即時系統時,更改時間也將顯示反映的資料。
預設情況下,您將看到過去 15 分鐘,如下所示:
單擊過去 15 分鐘,它將顯示您可以根據自己的選擇選擇的時間範圍。
觀察到有快速、相對、絕對和最近選項。以下螢幕截圖顯示了快速選項的詳細資訊:

現在,單擊相對以檢視可用的選項:
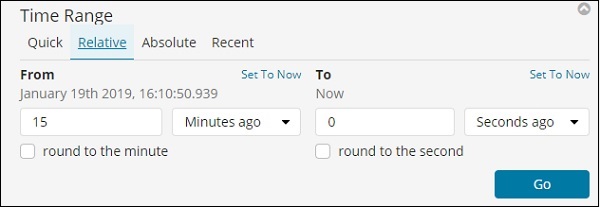
在此,您可以指定距現在多少分鐘、小時、秒、月、年前的起始日期和結束日期。
“絕對”選項包含以下詳細資訊:
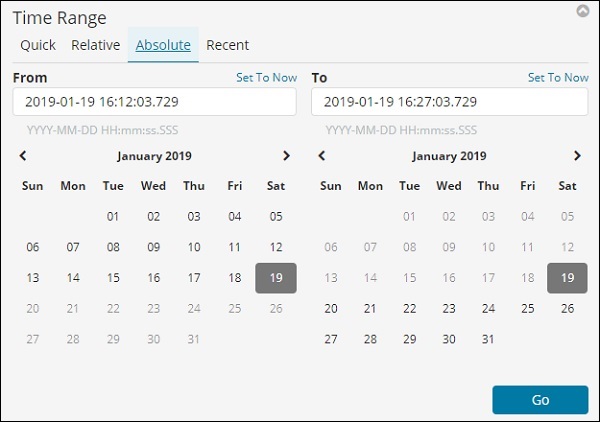
您可以看到日曆選項,並可以選擇一個日期範圍。
“最近”選項將提供“最近 15 分鐘”選項,以及您最近選擇的其他選項。選擇時間範圍將更新該時間範圍內的傳入資料。
在儀表盤中使用搜索和篩選
我們還可以在儀表盤上使用搜索和篩選。例如,如果在搜尋中想要獲取特定區域的詳細資訊,可以新增如下所示的搜尋:

在上述搜尋中,我們使用了“區域”欄位,並希望顯示“大洋洲”區域的詳細資訊。
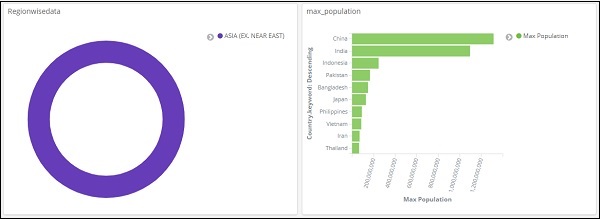
我們將得到以下結果:

從上述資料可以看出,在大洋洲地區,澳大利亞的人口和麵積最大。
同樣,我們可以新增如下所示的篩選器:
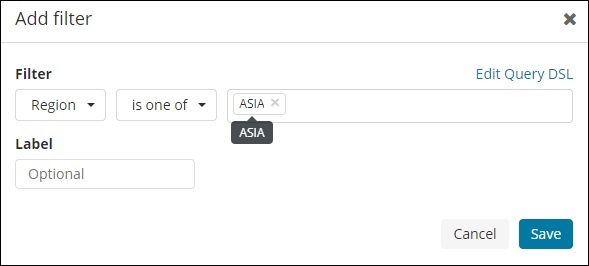
接下來,單擊“新增篩選器”按鈕,它將顯示索引中可用欄位的詳細資訊,如下所示:
選擇要對其進行篩選的欄位。我將使用“區域”欄位來獲取亞洲地區的詳細資訊,如下所示:
儲存篩選器,您應該會看到如下所示的篩選器:
現在將根據新增的篩選器顯示資料:
您還可以新增更多篩選器,如下所示:
您可以單擊停用複選框來停用篩選器,如下所示。

您可以單擊同一個複選框來啟用篩選器。請注意,有一個刪除按鈕用於刪除篩選器,還有一個編輯按鈕用於編輯篩選器或更改篩選器選項。
對於顯示的視覺化,您會注意到如下所示的三個點:
單擊它,將顯示如下所示的選項:
檢查和全屏
單擊“檢查”,它將以表格格式提供區域的詳細資訊,如下所示:
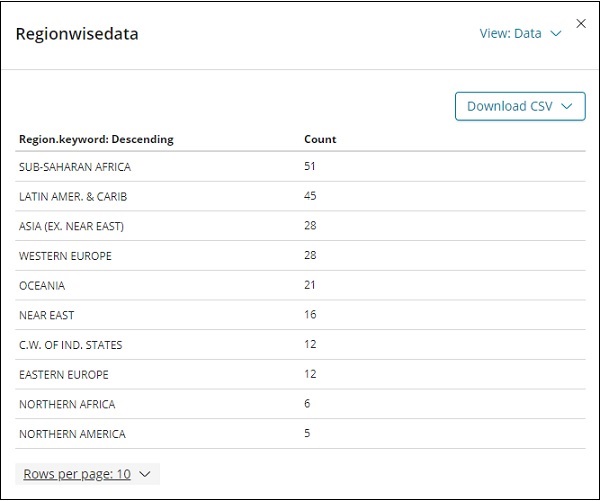
如果要檢視 Excel 表格中的視覺化,可以選擇將其下載為 CSV 格式。
下一個選項“全屏”將以全屏模式顯示視覺化,如下所示:
您可以使用同一個按鈕退出全屏模式。
共享儀表盤
我們可以使用共享按鈕共享儀表盤。單擊共享按鈕後,您將看到如下顯示:
您還可以使用嵌入程式碼在您的網站上顯示儀表盤,或者使用永久連結與他人共享。
網址如下:
https://:5601/goto/519c1a088d5d0f8703937d754923b84b
Kibana - Timelion
Timelion(也稱為時間線)是另一個視覺化工具,主要用於基於時間的資料分析。要使用時間線,我們需要使用簡單的表示式語言,這將幫助我們連線到索引,並對資料執行計算以獲得所需的結果。
我們可以在哪裡使用 Timelion?
當您想要比較時間相關資料時,可以使用 Timelion。例如,您有一個網站,每天都會獲得瀏覽量。您想分析資料,其中您想將當前周的資料與上一週的資料進行比較,即週一與週一,週二與週二,依此類推,比較瀏覽量的差異以及流量。
Timelion 入門
要開始使用 Timelion,請單擊如下所示的 Timelion:

Timelion 預設情況下顯示所有索引的時間線,如下所示:
Timelion 使用表示式語法。
注意 - es(*) => 表示所有索引。
要獲取可與 Timelion 一起使用的可用函式的詳細資訊,只需單擊如下所示的文字區域:

它將為您提供可與表示式語法一起使用的函式列表。
啟動 Timelion 後,它會顯示一條歡迎訊息,如下所示。突出顯示的部分(即跳轉到函式參考)提供了可與 Timelion 一起使用的所有函式的詳細資訊。
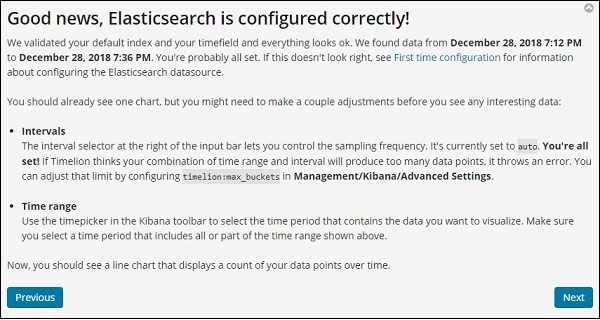
Timelion 歡迎訊息
Timelion 歡迎訊息如下所示:
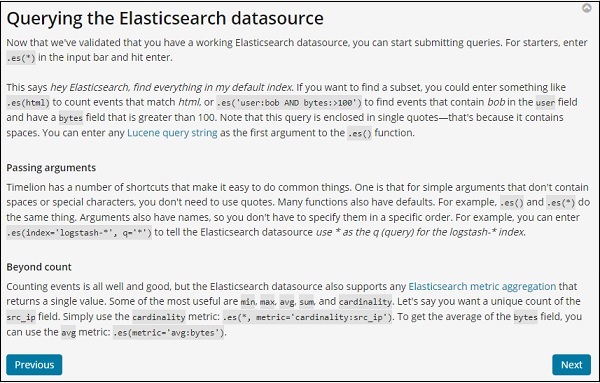
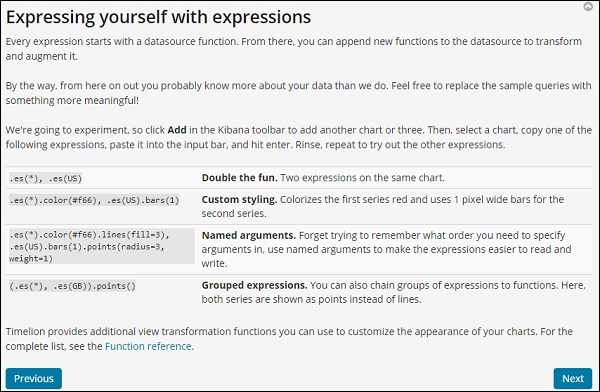
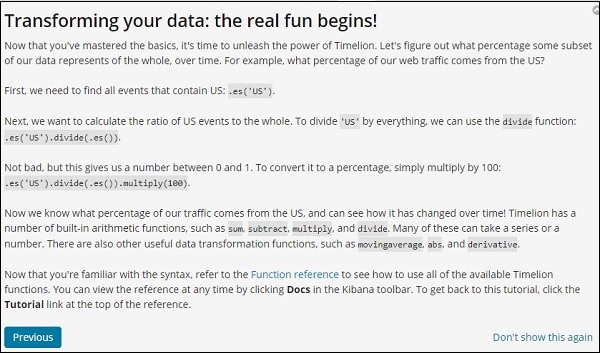
單擊“下一步”按鈕,它將引導您完成其基本功能和用法。現在,當您單擊“下一步”時,您可以看到以下詳細資訊:
Timelion 函式參考
單擊“幫助”按鈕,獲取 Timelion 可用函式參考的詳細資訊:
Timelion 配置
Timelion 的設定在 Kibana 管理 > 高階設定中完成。
單擊“高階設定”,然後從“類別”中選擇 Timelion
選擇 Timelion 後,它將顯示 Timelion 配置所需的所有必要欄位。
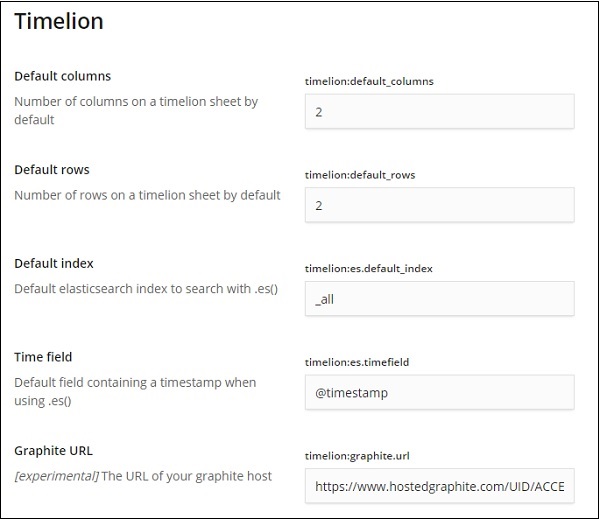
在以下欄位中,您可以更改要用於索引的預設索引和時間欄位:
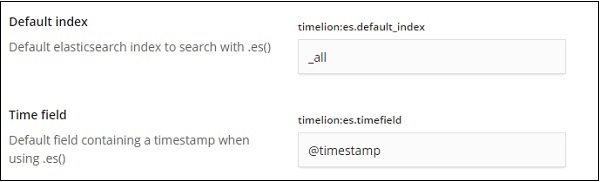
預設值為 _all,時間欄位為 @timestamp。我們將保留原樣,並在 Timelion 本身中更改索引和時間欄位。
使用 Timelion 視覺化資料
我們將使用索引:`medicalvisits-26.01.2019`。以下是 2017 年 1 月 1 日至 2017 年 12 月 31 日 Timelion 顯示的資料:
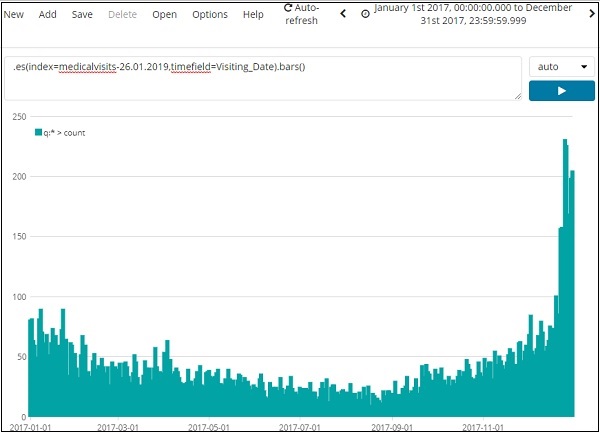
用於上述視覺化的表示式如下:
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date).bars()
我們使用了索引`medicalvisits-26.01.2019`,該索引上的時間欄位為 Visiting_Date,並使用了 bars 函式。
在下文中,我們分析了 2017 年 1 月份的每日資料,分析了兩個城市。
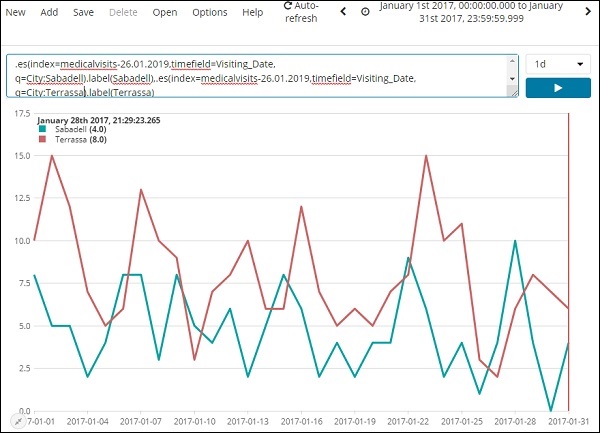
使用的表示式為:
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date, q=City:Sabadell).label(Sabadell),.es(index=medicalvisits-26.01.2019, timefield=Visiting_Date, q=City:Terrassa).label(Terrassa)
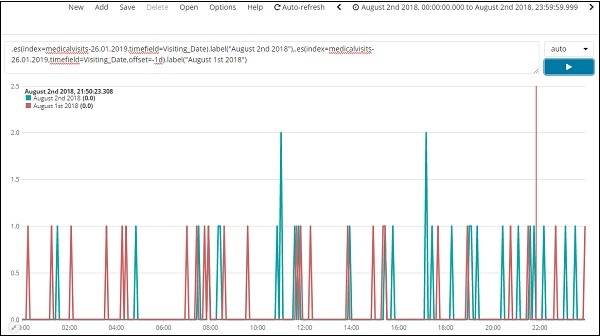
此處顯示了 2 天的時間線比較:
表示式
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date).label("August 2nd 2018"),
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date,offset=-1d).label("August 1st 2018")
在這裡,我們使用了 offset 並給出了 1 天的差值。我們選擇了 2018 年 8 月 2 日作為當前日期。因此,它提供了 2018 年 8 月 2 日和 2018 年 8 月 1 日的資料差異。
以下是 2017 年 1 月份排名前 5 個城市的列表資料。此處使用的表示式如下:
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date,split=City.keyword:5)
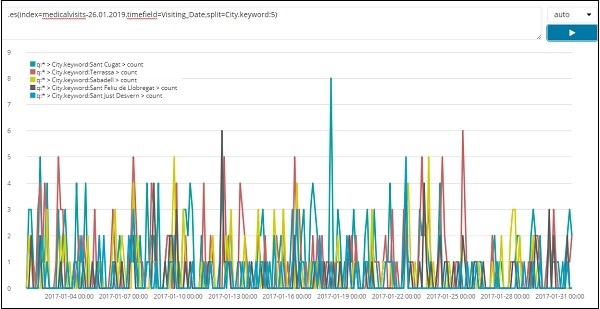
我們使用了 split 並給出了欄位名稱 City,由於我們需要來自索引的前五個城市,因此我們將其指定為`split=City.keyword:5`
它提供了每個城市的計數並列出了其名稱,如繪製的圖形中所示。
Kibana - 開發工具 (Dev Tools)
我們可以使用 Dev Tools 將資料上傳到 Elasticsearch,而無需使用 Logstash。我們可以使用 Dev Tools 在 Kibana 中釋出、放置、刪除和搜尋所需的資料。
要在 Kibana 中建立新的索引,可以在 dev tools 中使用以下命令:
使用 PUT 建立索引
建立索引的命令如下所示:
PUT /usersdata?pretty
執行此操作後,將建立一個空的索引 userdata。
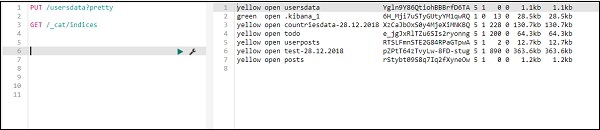
我們完成了索引建立。現在將資料新增到索引中:
使用 PUT 將資料新增到索引
您可以按如下方式將資料新增到索引:


我們將在 usersdata 索引中再新增一條記錄:
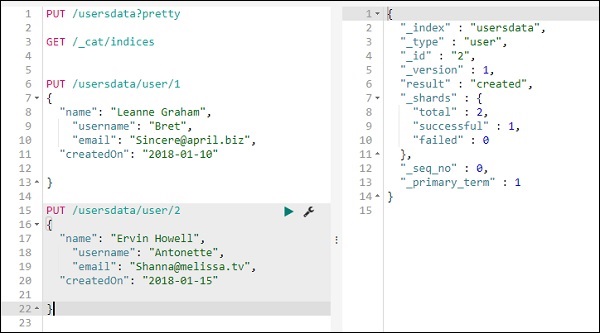
因此,usersdata 索引中有 2 條記錄。
使用 GET 從索引中獲取資料
我們可以按如下方式獲取記錄 1 的詳細資訊:
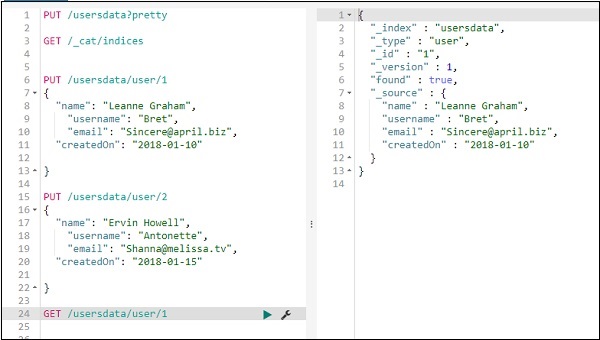
您可以按如下方式獲取所有記錄:
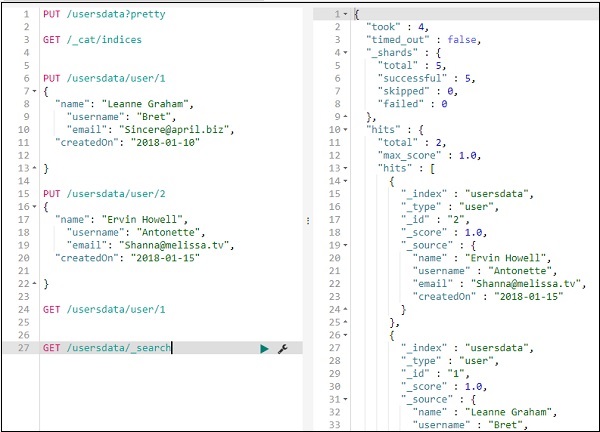
因此,我們可以從 usersdata 獲取所有記錄,如上所示。
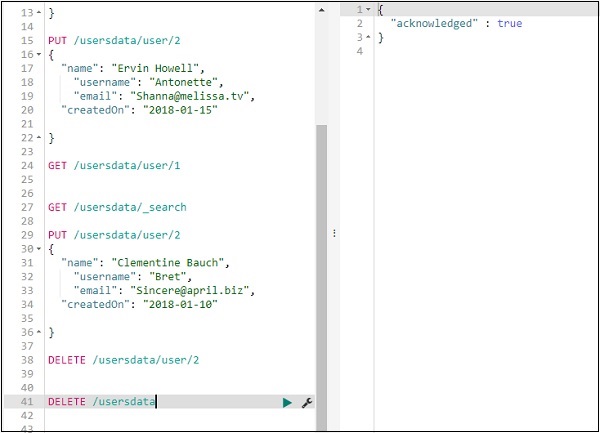
使用 PUT 更新索引中的資料
要更新記錄,您可以執行以下操作:
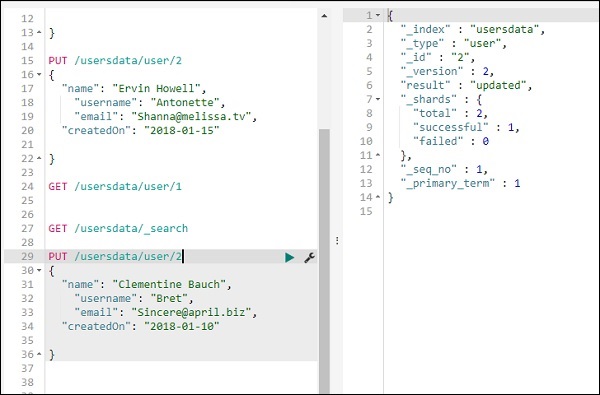
我們將名稱從“Ervin Howell”更改為“Clementine Bauch”。現在,我們可以從索引中獲取所有記錄,並檢視更新後的記錄,如下所示:
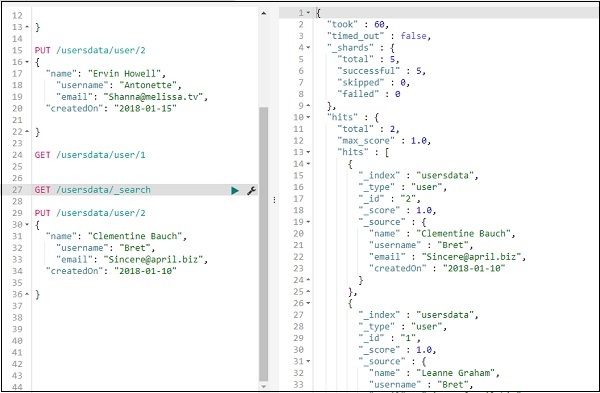
使用 DELETE 從索引中刪除資料
您可以按如下所示刪除記錄:
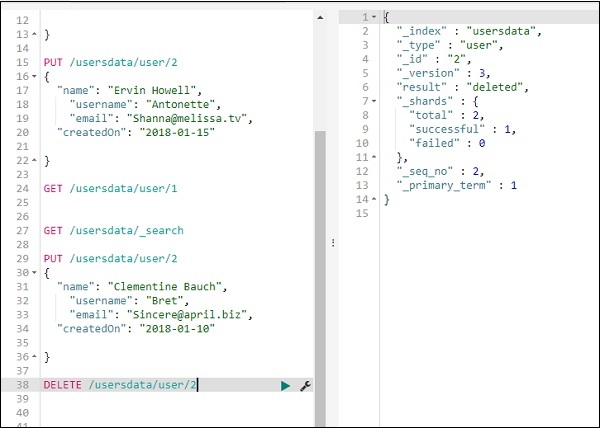
現在,如果您檢視總記錄數,我們將只有一條記錄:
我們可以按如下方式刪除已建立的索引:
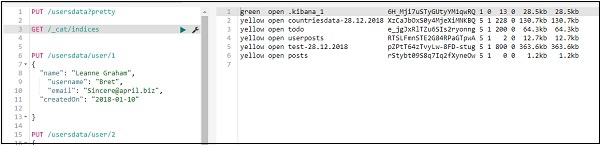
現在,如果您檢查可用的索引,我們將不會在其中看到 usersdata 索引,因為它已被刪除。
Kibana - 監控
Kibana 監控提供有關 ELK 堆疊效能的詳細資訊。我們可以獲取記憶體使用情況、響應時間等詳細資訊。
監控詳細資訊
要在 Kibana 中獲取監控詳細資訊,請單擊如下所示的監控選項卡:
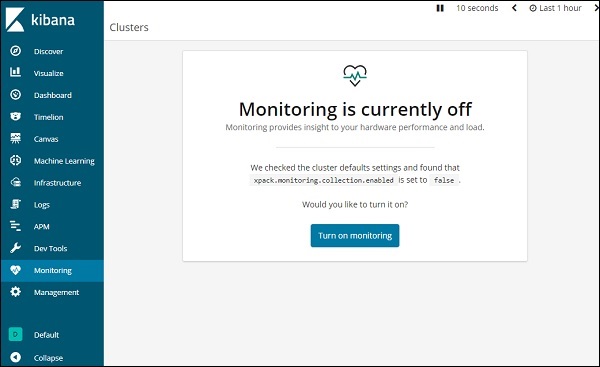
由於我們第一次使用監控,我們需要將其開啟。為此,請單擊上面顯示的“開啟監控”按鈕。以下是 Elasticsearch 顯示的詳細資訊:
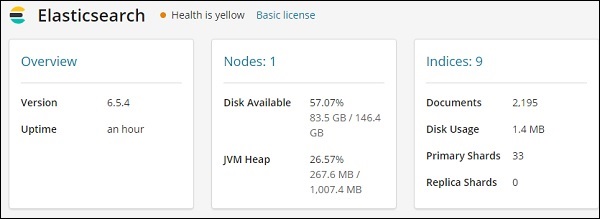
它提供了 Elasticsearch 的版本、可用磁碟、新增到 Elasticsearch 的索引、磁碟使用情況等。
以下是 Kibana 的監控詳細資訊:
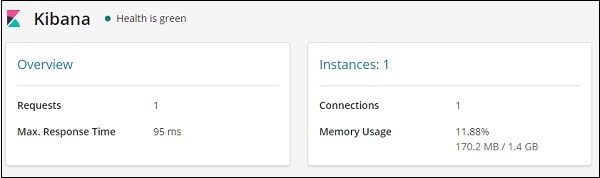
它提供了請求和請求的最大響應時間,以及正在執行的例項和記憶體使用情況。
Kibana - 使用 Kibana 建立報表
可以使用 Kibana UI 中提供的“共享”按鈕輕鬆建立報表。
Kibana 中的報表有以下兩種形式:
- 永久連結
- CSV 報表
作為永久連結的報表
執行視覺化時,您可以按如下方式共享:
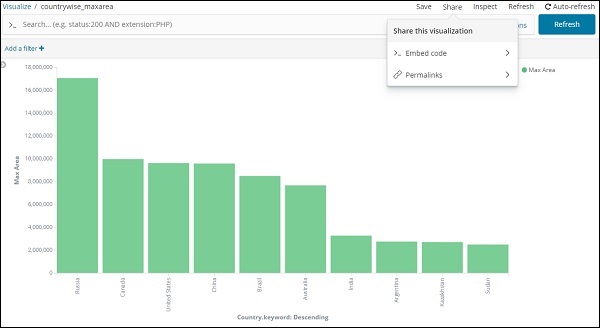
使用共享按鈕與他人共享視覺化,方法是使用嵌入程式碼或永久連結。
對於嵌入程式碼,您將獲得以下選項:
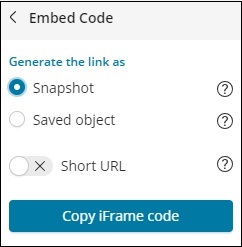
您可以生成快照或已儲存物件的 iframe 程式碼作為短網址或長網址。快照不會提供最新資料,使用者將能夠看到共享連結時儲存的資料。稍後進行的任何更改都不會反映出來。
對於已儲存的物件,您將獲得對該視覺化進行的最新更改。
長網址的快照 IFrame 程式碼:
<iframe src="https://:5601/app/kibana#/visualize/edit/87af cb60-165f-11e9-aaf1-3524d1f04792?embed=true&_g=()&_a=(filters:!(),linked:!f,query:(language:lucene,query:''), uiState:(),vis:(aggs:!((enabled:!t,id:'1',params:(field:Area),schema:metric,type:max),(enabled:!t,id:'2',p arams:(field:Country.keyword,missingBucket:!f,missingBucketLabel:Missing,order:desc,orderBy:'1',otherBucket:! f,otherBucketLabel:Other,size:10),schema:segment,type:terms)),params:(addLegend:!t,addTimeMarker:!f,addToo ltip:!t,categoryAxes:!((id:CategoryAxis-1,labels:(show:!t,truncate:100),position:bottom,scale:(type:linear), show:!t,style:(),title:(),type:category)),grid:(categoryLines:!f,style:(color:%23eee)),legendPosition:right, seriesParams:!((data:(id:'1',label:'Max+Area'),drawLi nesBetweenPoints:!t,mode:stacked,show:true,showCircles:!t,type:histogram,valueAxis:ValueAxis-1)),times:!(), type:histogram,valueAxes:!((id:ValueAxis-1,labels:(filter:!f,rotate:0,show:!t,truncate:100),name:LeftAxis-1, position:left,scale:(mode:normal,type:linear),show:!t,style:(),title:(text:'Max+Area'),type:value))),title: 'countrywise_maxarea+',type:histogram))" height="600" width="800"></iframe>
短網址的快照 IFrame 程式碼:
<iframe src="https://:5601/goto/f0a6c852daedcb6b4fa74cce8c2ff6c4?embed=true" height="600" width="800"><iframe>
作為快照和短網址。
使用短網址:
https://:5601/goto/f0a6c852daedcb6b4fa74cce8c2ff6c4
關閉短網址後,連結如下所示:
https://:5601/app/kibana#/visualize/edit/87afcb60-165f-11e9-aaf1-3524d1f04792?_g=()&_a=(filters:!( ),linked:!f,query:(language:lucene,query:''),uiState:(),vis:(aggs:!((enabled:!t,id:'1',params:(field:Area), schema:metric,type:max),(enabled:!t,id:'2',params:(field:Country.keyword,missingBucket:!f,missingBucketLabel: Missing,order:desc,orderBy:'1',otherBucket:!f,otherBucketLabel:Other,size:10),schema:segment,type:terms)), params:(addLegend:!t,addTimeMarker:!f,addTooltip:!t,categoryAxes:!((id:CategoryAxis-1,labels:(show:!t,trun cate:100),position:bottom,scale:(type:linear),show:!t,style:(),title:(),type:category)),grid:(categoryLine s:!f,style:(color:%23eee)),legendPosition:right,seriesParams:!((data:(id:'1',label:'Max%20Area'),drawLines BetweenPoints:!t,mode:stacked,show:true,showCircles:!t,type:histogram,valueAxis:ValueAxis-1)),times:!(), type:histogram,valueAxes:!((id:ValueAxis-1,labels:(filter:!f,rotate:0,show:!t,truncate:100),name:LeftAxis-1, position:left,scale:(mode:normal,type:linear),show:!t,style:(),title:(text:'Max%20Area'),type:value))),title:'countrywise_maxarea%20',type:histogram))
當您在瀏覽器中訪問上述連結時,您將獲得與上面顯示的相同的視覺化效果。上述連結是在本地託管的,因此在本地環境之外使用時將無法工作。
CSV 報表
您可以在 Kibana 中獲取 CSV 報表,其中包含資料,這些資料主要位於“發現”選項卡中。
轉到“發現”選項卡,並選擇您想要其資料的任何索引。在這裡,我們使用了索引:`countriesdata-26.12.2018`。以下是索引中顯示的資料:

您可以根據上述資料建立表格資料,如下所示:
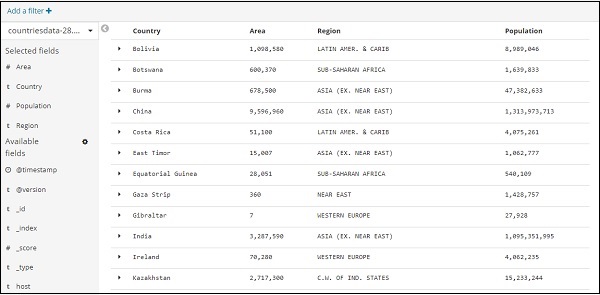
我們從“可用欄位”中選擇了欄位,並將前面看到的資料轉換為表格格式。
您可以按如下所示獲取上述資料的 CSV 報表:
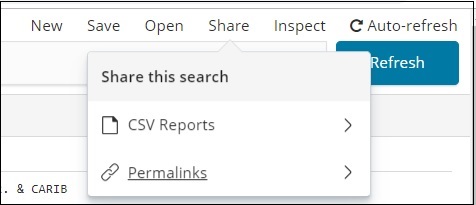
共享按鈕具有 CSV 報表和永久連結的選項。您可以單擊“CSV 報表”並下載。
請注意,要獲取 CSV 報表,您需要儲存資料。
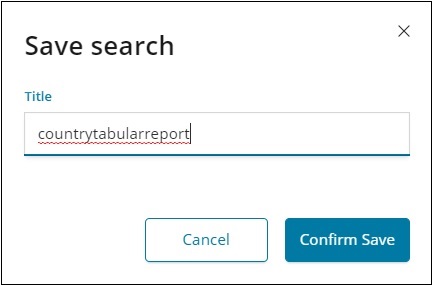
確認儲存並單擊“共享”按鈕和“CSV 報表”。您將看到以下顯示:
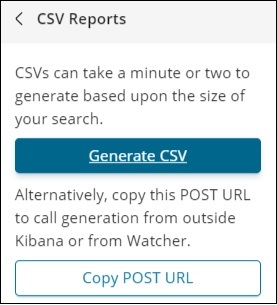
單擊“生成 CSV”以獲取報表。完成後,它將指示您轉到管理選項卡。
轉到管理選項卡 > 報表
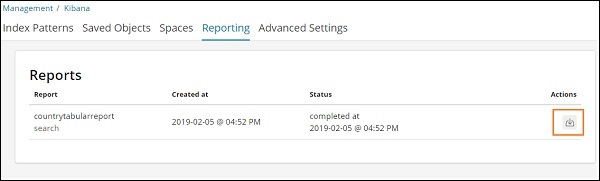
它顯示報表名稱、建立時間、狀態和操作。您可以單擊上面突出顯示的下載按鈕並獲取您的 csv 報表。
我們剛剛下載的 CSV 檔案如下所示: