- Kibana 教程
- Kibana - 首頁
- Kibana - 概述
- Kibana - 環境設定
- Kibana - ELK Stack 簡介
- Kibana - 載入示例資料
- Kibana - 管理
- Kibana - 發現
- Kibana - 聚合和指標
- Kibana - 建立視覺化
- Kibana - 使用圖表
- Kibana - 使用圖形
- Kibana - 使用熱力圖
- 使用座標地圖
- Kibana - 使用區域地圖
- 使用儀表和目標
- Kibana - 使用畫布
- Kibana - 建立儀表板
- Kibana - Timelion
- Kibana - 開發工具
- Kibana - 監控
- 使用 Kibana 建立報表
- Kibana 有用資源
- Kibana - 快速指南
- Kibana - 有用資源
- Kibana - 討論
Kibana - 聚合和指標
在學習 Kibana 的過程中,您經常會遇到“桶”和“指標聚合”這兩個術語。本章討論它們在 Kibana 中扮演的角色以及更多詳細資訊。
什麼是 Kibana 聚合?
聚合是指從特定搜尋查詢或篩選器中獲得的文件或一組文件的集合。聚合構成了在 Kibana 中構建所需視覺化的主要概念。
每當您執行任何視覺化操作時,您都需要確定標準,這意味著您希望以何種方式對資料進行分組以對其執行指標計算。
在本節中,我們將討論兩種型別的聚合:
- 桶聚合
- 指標聚合
桶聚合
一個桶主要由一個鍵和一個文件組成。執行聚合時,文件將被放置在相應的桶中。因此,最終您應該得到一個桶列表,每個桶都包含一個文件列表。在 Kibana 中建立視覺化時將看到的桶聚合列表如下:

桶聚合具有以下列表:
- 日期直方圖
- 日期範圍
- 過濾器
- 直方圖
- IPv4 範圍
- 範圍
- 重要術語
- 術語
在建立時,您需要為桶聚合決定其中之一,即在桶內對文件進行分組。
例如,為了進行分析,請考慮我們在本教程開始時上傳的國家/地區資料。國家/地區索引中可用的欄位是國家/地區名稱、面積、人口和地區。在國家/地區資料中,我們有國家/地區的名稱以及它的人口、地區和麵積。
假設我們想要按地區檢視資料。那麼,每個地區中可用的國家/地區就成為我們的搜尋查詢,因此在這種情況下,地區將構成我們的桶。下圖顯示 R1、R2、R3、R4、R5 和 R6 是我們獲得的桶,c1、c2…c25 是屬於桶 R1 到 R6 的文件列表。

我們可以看到每個桶中都有一些圓圈。它們是基於搜尋條件的一組文件,並被認為屬於每個桶。在桶 R1 中,我們有文件 c1、c8 和 c15。這些文件是屬於該地區的國家/地區,其他地區也是如此。因此,如果我們計算桶 R1 中的國家/地區數量,則為 3,R2 為 6,R3 為 6,R4 為 2,R5 為 5,R6 為 4。
因此,透過桶聚合,我們可以將文件聚合到桶中,並獲得這些桶中文件的列表,如上所示。
到目前為止,我們擁有的桶聚合列表為:
- 日期直方圖
- 日期範圍
- 過濾器
- 直方圖
- IPv4 範圍
- 範圍
- 重要術語
- 術語
現在讓我們詳細討論如何逐一形成這些桶。
日期直方圖
日期直方圖聚合用於日期欄位。因此,如果您使用的索引具有日期欄位,則只能使用此聚合型別。這是一個多桶聚合,這意味著您可以將某些文件作為多個桶的一部分。此聚合將使用一個間隔,詳細資訊如下:

當您選擇“桶聚合”為“日期直方圖”時,它將顯示“欄位”選項,該選項將僅提供與日期相關的欄位。選擇欄位後,您需要選擇間隔,其中包含以下詳細資訊:

因此,來自所選索引的文件以及基於所選欄位和間隔將文件分類到桶中。例如,如果您選擇間隔為每月,則基於日期的文件將轉換為桶,並基於月份(即 1 月至 12 月)將文件放入桶中。此處,1 月、2 月…12 月將是桶。
日期範圍
您需要一個日期欄位才能使用此聚合型別。在這裡,我們將有一個日期範圍,即需要給出起始日期和結束日期。桶將根據給定的起始日期和結束日期包含其文件。

過濾器
使用過濾器型別聚合,桶將根據過濾器形成。在這裡,您將獲得一個多桶,因為根據過濾器條件,一個文件可以存在於一個或多個桶中。
使用過濾器,使用者可以在過濾器選項中編寫他們的查詢,如下所示:
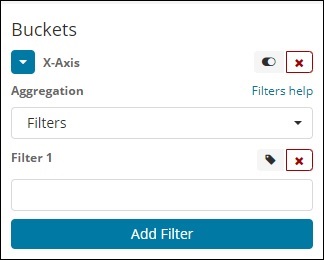
您可以使用“新增過濾器”按鈕新增多個您選擇的過濾器。
直方圖
此型別的聚合應用於數字欄位,它將根據應用的間隔將文件分組到桶中。例如,0-50、50-100、100-150 等。

IPv4 範圍
此型別的聚合用於 IP 地址。

我們擁有的索引(即 contriesdata-28.12.2018)沒有 IP 型別的欄位,因此它會顯示如下所示的訊息。如果您碰巧擁有 IP 欄位,則可以像上面顯示的那樣指定其“起始”值和“結束”值。
範圍
此型別的聚合需要欄位為數字型別。您需要指定範圍,文件將列在落在該範圍內的桶中。
如果需要,您可以透過單擊“新增範圍”按鈕新增更多範圍。
重要術語
此型別的聚合主要用於字串欄位。

術語
此型別的聚合用於所有可用欄位,即數字、字串、日期、布林值、IP 地址、時間戳等。請注意,這是我們將在本教程中進行的所有視覺化操作中將使用的聚合。
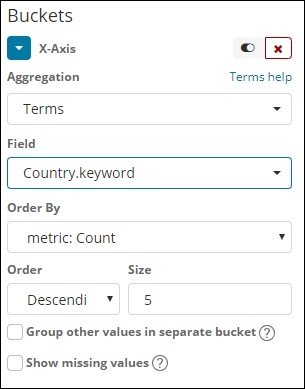
我們有一個“按”排序選項,我們將根據選擇的指標對資料進行分組。“大小”指的是您要在視覺化中顯示的桶數。
接下來,讓我們討論指標聚合。
指標聚合
指標聚合主要指對桶中存在的文件進行的數學計算。例如,如果您選擇一個數字欄位,則可以對其執行的指標計算包括 COUNT、SUM、MIN、MAX、AVERAGE 等。
我們將討論的指標聚合列表如下:

在本節中,讓我們討論一些我們將經常使用的重要內容:
- 平均值
- 計數
- 最大值
- 最小值
- 總和
該指標將應用於我們上面已經討論過的各個桶聚合。
接下來,讓我們在此處討論指標聚合列表:
平均值
這將給出桶中存在的文件值的平均值。例如:
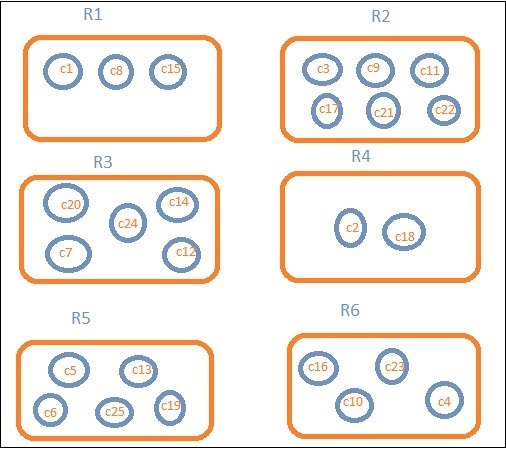
R1 到 R6 是桶。在 R1 中,我們有 c1、c8 和 c15。假設 c1 的值為 300,c8 為 500,c15 為 700。現在要獲得 R1 桶的平均值
R1 = c1 的值 + c8 的值 + c15 的值 / 3 = 300 + 500 + 700 / 3 = 500。
R1 桶的平均值為 500。此處文件的值可以是任何值,例如,如果您考慮國家/地區資料,它可以是該地區國家/地區的面積。
計數
這將給出桶中存在的文件數量。例如,如果您想要知道該地區存在的國家/地區數量,它將是桶中存在的總文件數。例如,R1 為 3,R2 = 6,R3 = 5,R4 = 2,R5 = 5,R6 = 4。
最大值
這將給出桶中存在的文件的最大值。考慮到上面的例子,如果我們在地區桶中按面積劃分國家/地區資料。每個地區的最大值將是面積最大的國家/地區。因此,它將從每個地區(即 R1 到 R6)中包含一個國家/地區。
在
這將給出桶中存在的文件的最小值。考慮到上面的例子,如果我們在地區桶中按面積劃分國家/地區資料。每個地區的最小值將是面積最小的國家/地區。因此,它將從每個地區(即 R1 到 R6)中包含一個國家/地區。
總和
這將給出桶中存在的文件值的總和。例如,如果您考慮上面的例子,如果我們想要知道該地區的總面積或國家/地區數量,它將是該地區中存在的文件的總和。
例如,要了解地區 R1 中的國家/地區總數,它將是 3,R2 = 6,R3 = 5,R4 = 2,R5 = 5,R6 = 4。
如果我們在該地區有包含面積的文件,那麼 R1 到 R6 將對該地區的國家/地區面積進行求和。