信源編碼定理
離散無記憶信源產生的程式碼必須有效地表示,這是通訊中一個重要的問題。為此,存在表示這些信原始碼的碼字。
例如,在電報中,我們使用莫爾斯電碼,其中字母由點和劃表示。如果考慮使用頻率最高的字母E,則用“.”表示,而很少使用的字母Q則用“--.-”表示。
讓我們看一下框圖。
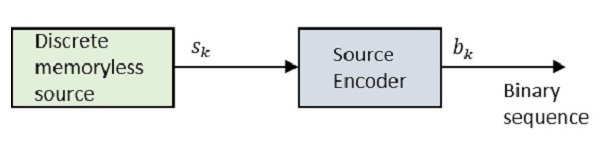
其中Sk是離散無記憶信源的輸出,bk是信源編碼器的輸出,用0和1表示。
編碼序列便於接收端解碼。
假設信源的字母表有k個不同的符號,第k個符號Sk出現的機率為Pk,其中k = 0, 1…k-1。
設編碼器為符號Sk分配的二進位制碼字長度為lk(以位元為單位)。
因此,我們將信源編碼器的平均碼字長度L定義為
$$\overline{L} = \displaystyle\sum\limits_{k=0}^{k-1} p_kl_k$$
L表示每個信源符號的平均位元數。
如果 $L_{min} = \: \overline{L}的最小可能值$
則編碼效率可以定義為
$$\eta = \frac{L_{min}}{\overline{L}}$$
由於$\overline{L}\geq L_{min}$,我們將有$\eta \leq 1$
然而,當$\eta = 1$時,信源編碼器被認為是有效的。
為此,必須確定$L_{min}$的值。
讓我們參考定義:“給定一個熵為$H(\delta)$的離散無記憶信源,任何信源編碼的平均碼字長度L都受限於$\overline{L} \geq H(\delta)$。”
簡單來說,碼字(例如,QUEUE的莫爾斯電碼是-.- ..- . ..- .)總是大於或等於信原始碼(例如QUEUE)。這意味著碼字中的符號大於或等於信原始碼中的字母。
因此,當$L_{min} = H(\delta)$時,根據熵$H(\delta)$,信源編碼器的效率可以寫成
$$\eta = \frac{H(\delta)}{\overline{L}}$$
此信源編碼定理稱為無噪聲編碼定理,因為它建立了無錯誤編碼。它也稱為夏農第一定理。