
- 編譯器設計教程
- 編譯器設計 - 首頁
- 編譯器設計 - 概述
- 編譯器設計 - 架構
- 編譯器設計 - 編譯器的階段
- 編譯器設計 - 詞法分析
- 編譯器 - 正則表示式
- 編譯器設計 - 有限自動機
- 編譯器設計 - 語法分析
- 編譯器設計 - 解析型別
- 編譯器設計 - 自頂向下分析器
- 編譯器設計 - 自底向上分析器
- 編譯器設計 - 錯誤恢復
- 編譯器設計 - 語義分析
- 編譯器 - 執行時環境
- 編譯器設計 - 符號表
- 編譯器 - 中間程式碼
- 編譯器設計 - 程式碼生成
- 編譯器設計 - 程式碼最佳化
- 編譯器設計有用資源
- 編譯器設計 - 快速指南
- 編譯器設計 - 有用資源
編譯器設計 - 符號表
符號表是由編譯器建立和維護的重要資料結構,用於儲存各種實體(例如變數名、函式名、物件、類、介面等)的出現資訊。符號表被編譯器的分析和綜合部分使用。
根據手頭的語言,符號表可以服務於以下目的
在一個地方以結構化的形式儲存所有實體的名稱。
驗證變數是否已宣告。
實現型別檢查,透過驗證原始碼中的賦值和表示式在語義上是否正確。
確定名稱的作用域(作用域解析)。
符號表只是一個表格,可以是線性表或雜湊表。它為每個名稱維護一個條目,格式如下:
<symbol name, type, attribute>
例如,如果符號表需要儲存以下變數宣告的資訊:
static int interest;
那麼它應該儲存如下條目:
<interest, int, static>
屬性子句包含與名稱相關的條目。
實現
如果編譯器要處理少量資料,那麼符號表可以實現為無序列表,這很容易編碼,但它只適用於小型表格。符號表可以透過以下幾種方式實現:
- 線性(排序或未排序)列表
- 二叉搜尋樹
- 雜湊表
在所有方法中,符號表大多實現為雜湊表,其中原始碼符號本身被視為雜湊函式的鍵,返回值是關於該符號的資訊。
操作
符號表(無論是線性表還是雜湊表)都應提供以下操作。
插入(insert())
此操作更常用於分析階段,即編譯器的前半部分,其中標識令牌並將名稱儲存在表中。此操作用於在符號表中新增有關原始碼中出現的唯一名稱的資訊。儲存名稱的格式或結構取決於手頭的編譯器。
原始碼中符號的屬性是與該符號關聯的資訊。此資訊包含有關符號的值、狀態、作用域和型別。insert() 函式以符號及其屬性作為引數,並將資訊儲存在符號表中。
例如:
int a;
應由編譯器處理為:
insert(a, int);
查詢(lookup())
lookup() 操作用於在符號表中搜索名稱以確定:
- 符號是否存在於表中。
- 在使用之前是否已宣告。
- 名稱是否在作用域中使用。
- 符號是否已初始化。
- 符號是否宣告多次。
lookup() 函式的格式根據程式語言而有所不同。基本格式應與以下格式匹配:
lookup(symbol)
如果符號不存在於符號表中,則此方法返回 0(零)。如果符號存在於符號表中,則它返回儲存在表中的其屬性。
作用域管理
編譯器維護兩種型別的符號表:一個全域性符號表,所有過程都可以訪問它;以及為程式中的每個作用域建立的作用域符號表。
為了確定名稱的作用域,符號表以分層結構排列,如下例所示:
. . .
int value=10;
void pro_one()
{
int one_1;
int one_2;
{ \
int one_3; |_ inner scope 1
int one_4; |
} /
int one_5;
{ \
int one_6; |_ inner scope 2
int one_7; |
} /
}
void pro_two()
{
int two_1;
int two_2;
{ \
int two_3; |_ inner scope 3
int two_4; |
} /
int two_5;
}
. . .
上述程式可以用符號表的層次結構表示:
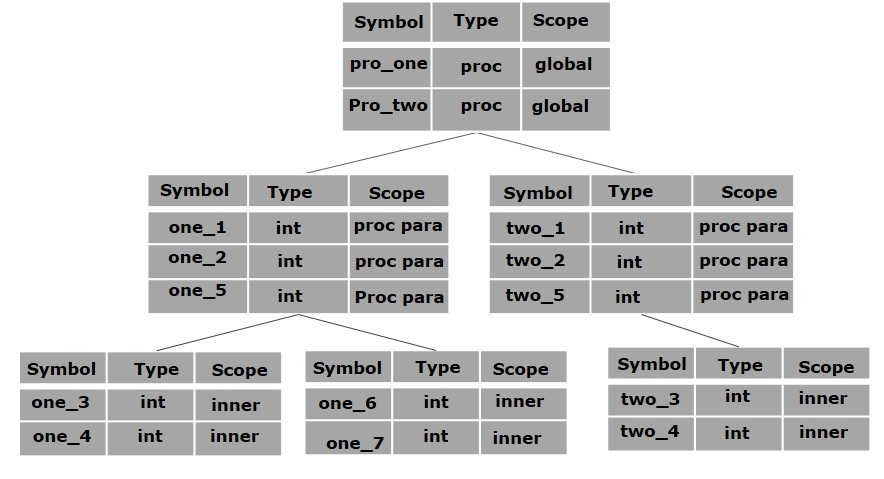
全域性符號表包含一個全域性變數(int value)和兩個過程名稱的名稱,這些名稱應可供上面顯示的所有子節點使用。pro_one 符號表(及其所有子表)中提到的名稱不適用於 pro_two 符號及其子表。
此符號表資料結構層次結構儲存在語義分析器中,並且每當需要在符號表中搜索名稱時,它都會使用以下演算法進行搜尋:
首先將在當前作用域(即當前符號表)中搜索符號。
如果找到名稱,則搜尋完成,否則將在父符號表中搜索,直到:
找到名稱或已在全域性符號表中搜索過該名稱。