
- 編譯器設計教程
- 編譯器設計 - 首頁
- 編譯器設計 - 概述
- 編譯器設計 - 架構
- 編譯器設計 - 編譯器的階段
- 編譯器設計 - 詞法分析
- 編譯器 - 正則表示式
- 編譯器設計 - 有限自動機
- 編譯器設計 - 語法分析
- 編譯器設計 - 解析型別
- 編譯器設計 - 自頂向下解析器
- 編譯器設計 - 自底向上解析器
- 編譯器設計 - 錯誤恢復
- 編譯器設計 - 語義分析
- 編譯器 - 執行時環境
- 編譯器設計 - 符號表
- 編譯器 - 中間程式碼
- 編譯器設計 - 程式碼生成
- 編譯器設計 - 程式碼最佳化
- 編譯器設計有用資源
- 編譯器設計 - 快速指南
- 編譯器設計 - 有用資源
編譯器設計 - 錯誤恢復
解析器應該能夠檢測並報告程式中的任何錯誤。當遇到錯誤時,預期解析器能夠處理它並繼續解析其餘的輸入。大多數情況下,期望解析器檢查錯誤,但錯誤可能會在編譯過程的各個階段遇到。程式在各個階段可能出現以下幾種錯誤:
詞法錯誤:某些識別符號的名稱輸入錯誤
語法錯誤:缺少分號或括號不平衡
語義錯誤:不相容的值賦值
邏輯錯誤:程式碼不可達,無限迴圈
解析器中可以實現四種常見的錯誤恢復策略來處理程式碼中的錯誤。
恐慌模式
當解析器在語句中的任何位置遇到錯誤時,它會忽略語句的其餘部分,而不處理從錯誤輸入到分隔符(例如分號)的輸入。這是最簡單的錯誤恢復方法,並且它還可以防止解析器陷入無限迴圈。
語句模式
當解析器遇到錯誤時,它會嘗試採取糾正措施,以便語句的其餘輸入允許解析器繼續解析。例如,插入缺少的分號,用分號替換逗號等。解析器設計者在這裡必須小心,因為一個錯誤的更正可能會導致無限迴圈。
錯誤產生式
編譯器設計者知道程式碼中可能發生一些常見的錯誤。此外,設計者可以建立增強的語法以用作產生式,當遇到這些錯誤時,這些產生式會生成錯誤的結構。
全域性校正
解析器將程式作為一個整體來考慮,並試圖弄清楚程式的意圖,並試圖找到一個最接近的無錯誤匹配。當輸入錯誤的輸入(語句)X時,它會為某個最接近的無錯誤語句Y建立解析樹。這可以允許解析器對原始碼進行最小更改,但是由於此策略的複雜性(時間和空間),它尚未在實踐中實現。
抽象語法樹
解析樹表示不容易被編譯器解析,因為它們包含比實際需要的更多細節。以下面的解析樹為例
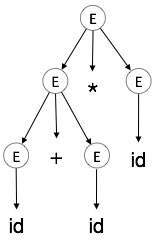
如果仔細觀察,我們會發現大多數葉子節點都是其父節點的單個子節點。此資訊可以在將其饋送到下一階段之前消除。透過隱藏額外資訊,我們可以獲得如下所示的樹
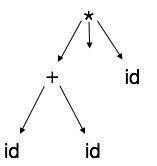
抽象樹可以表示為
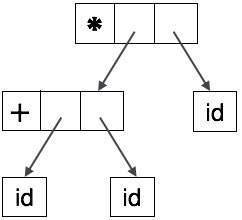
AST 是編譯器中重要的資料結構,其中包含最少的冗餘資訊。AST 比解析樹更緊湊,並且可以很容易地被編譯器使用。
廣告