
- 編譯器設計教程
- 編譯器設計 - 首頁
- 編譯器設計 - 概述
- 編譯器設計 - 架構
- 編譯器設計 - 編譯器的階段
- 編譯器設計 - 詞法分析
- 編譯器 - 正則表示式
- 編譯器設計 - 有限自動機
- 編譯器設計 - 語法分析
- 編譯器設計 - 解析型別
- 編譯器設計 - 自頂向下解析器
- 編譯器設計 - 自底向上解析器
- 編譯器設計 - 錯誤恢復
- 編譯器設計 - 語義分析
- 編譯器 - 執行時環境
- 編譯器設計 - 符號表
- 編譯器 - 中間程式碼
- 編譯器設計 - 程式碼生成
- 編譯器設計 - 程式碼最佳化
- 編譯器設計有用資源
- 編譯器設計 - 快速指南
- 編譯器設計 - 有用資源
編譯器 - 中間程式碼生成
原始碼可以直接翻譯成目標機器碼,那麼為什麼還需要將原始碼翻譯成中間程式碼,然後再翻譯成目的碼呢?讓我們看看為什麼需要中間程式碼。
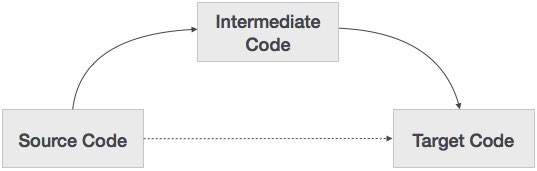
如果編譯器在沒有生成中間程式碼選項的情況下將源語言翻譯成目標機器語言,那麼對於每臺新機器都需要一個完整的原生編譯器。
中間程式碼透過保持所有編譯器的分析部分相同,消除了為每臺獨特的機器都需要一個新的完整編譯器的需求。
編譯器的第二部分,合成部分,會根據目標機器進行更改。
透過在中間程式碼上應用程式碼最佳化技術,更容易應用原始碼修改以提高程式碼效能。
中間表示
中間程式碼可以用多種方式表示,它們各有優勢。
高階IR - 高階中間程式碼表示非常接近源語言本身。它們可以很容易地從原始碼生成,並且我們可以很容易地應用程式碼修改以增強效能。但對於目標機器最佳化,它不太理想。
低階IR - 這個更接近目標機器,這使得它適合暫存器和記憶體分配、指令集選擇等。它有利於機器相關的最佳化。
中間程式碼可以是特定於語言的(例如,Java的位元組碼)或與語言無關的(三地址碼)。
三地址碼
中間程式碼生成器從其前階段語義分析器接收輸入,形式為帶註釋的語法樹。然後可以將該語法樹轉換為線性表示,例如字尾表示法。中間程式碼傾向於與機器無關的程式碼。因此,程式碼生成器假設有無限數量的記憶體儲存(暫存器)來生成程式碼。
例如
a = b + c * d;
中間程式碼生成器將嘗試將此表示式分解成子表示式,然後生成相應的程式碼。
r1 = c * d; r2 = b + r1; a = r2
r 用作目標程式中的暫存器。
三地址碼最多有三個地址位置來計算表示式。三地址碼可以用兩種形式表示:四元式和三元式。
四元式
四元式表示中的每個指令都分為四個欄位:運算子、arg1、arg2和結果。上面的例子在四元式格式中表示如下
| 運算子 | arg1 | arg2 | 結果 |
| * | c | d | r1 |
| + | b | r1 | r2 |
| + | r2 | r1 | r3 |
| = | r3 | a |
三元式
三元式表示中的每個指令都有三個欄位:運算子、arg1和arg2。各個子表示式的結果由表示式的位 置表示。三元式在表示表示式時與DAG和語法樹類似。它們在表示表示式時等同於DAG。
| 運算子 | arg1 | arg2 |
| * | c | d |
| + | b | (0) |
| + | (1) | (0) |
| = | (2) |
三元式在最佳化時面臨程式碼不可移動的問題,因為結果是位置性的,改變表示式的順序或位置可能會導致問題。
間接三元式
這種表示是對三元式表示的增強。它使用指標而不是位置來儲存結果。這使得最佳化器可以自由地重新定位子表示式以生成最佳化的程式碼。
宣告
變數或過程必須在使用前宣告。宣告包括在記憶體中分配空間以及在符號表中輸入型別和名稱。程式的編寫和設計可以考慮目標機器結構,但並不總是能夠準確地將原始碼轉換為目標語言。
將整個程式視為過程和子過程的集合,就可以宣告所有區域性於過程的名稱。記憶體分配以連續的方式進行,名稱按照程式中宣告的順序分配給記憶體。我們使用偏移量變數並將它的值設定為零{offset = 0},表示基地址。
源程式語言和目標機器架構在儲存名稱的方式上可能有所不同,因此使用相對定址。當第一個名稱從記憶體位置0 {offset=0}開始分配記憶體時,稍後宣告的下一個名稱應該分配給第一個名稱旁邊的記憶體。
示例
我們以C語言為例,其中一個整型變數分配2位元組記憶體,一個浮點型變數分配4位元組記憶體。
int a;
float b;
Allocation process:
{offset = 0}
int a;
id.type = int
id.width = 2
offset = offset + id.width
{offset = 2}
float b;
id.type = float
id.width = 4
offset = offset + id.width
{offset = 6}
為了將此細節輸入符號表,可以使用過程enter。此方法可能具有以下結構
enter(name, type, offset)
此過程應該在符號表中為變數name建立條目,其型別設定為type,資料區中的相對地址為offset。