
- 編譯器設計教程
- 編譯器設計 - 首頁
- 編譯器設計 - 概述
- 編譯器設計 - 架構
- 編譯器設計 - 編譯器的階段
- 編譯器設計 - 詞法分析
- 編譯器 - 正則表示式
- 編譯器設計 - 有限自動機
- 編譯器設計 - 語法分析
- 編譯器設計 - 解析型別
- 編譯器設計 - 自頂向下解析器
- 編譯器設計 - 自底向上解析器
- 編譯器設計 - 錯誤恢復
- 編譯器設計 - 語義分析
- 編譯器 - 執行時環境
- 編譯器設計 - 符號表
- 編譯器 - 中間程式碼
- 編譯器設計 - 程式碼生成
- 編譯器設計 - 程式碼最佳化
- 編譯器設計有用資源
- 編譯器設計 - 快速指南
- 編譯器設計 - 有用資源
編譯器設計 - 語義分析
我們已經學習了在語法分析階段解析器如何構建語法樹。在該階段構建的普通語法樹通常對編譯器沒有用處,因為它不包含任何關於如何評估樹的資訊。上下文無關語法的產生式,它構成了語言的規則,並沒有包含如何解釋它們的規則。
例如
E → E + T
上述 CFG 產生式沒有與其關聯的語義規則,它無法幫助理解產生式。
語義
語言的語義為其結構(如標記和語法結構)提供含義。語義有助於解釋符號、它們的型別以及它們彼此之間的關係。語義分析判斷源程式中構建的語法結構是否有意義。
CFG + semantic rules = Syntax Directed Definitions
例如
int a = “value”;
不應該在詞法和語法分析階段發出錯誤,因為它在詞法和結構上是正確的,但它應該生成語義錯誤,因為賦值的型別不同。這些規則由語言的語法設定並在語義分析中進行評估。語義分析中應執行以下任務
- 作用域解析
- 型別檢查
- 陣列邊界檢查
語義錯誤
我們已經提到了一些語義分析器預期識別的語義錯誤
- 型別不匹配
- 未宣告的變數
- 保留識別符號誤用。
- 在一個作用域中多次宣告變數。
- 訪問超出作用域的變數。
- 實際引數和形式引數不匹配。
屬性文法
屬性文法是上下文無關文法的一種特殊形式,其中一些附加資訊(屬性)被附加到一個或多個非終結符上,以提供上下文相關資訊。每個屬性都有一個定義良好的值域,例如整數、浮點數、字元、字串和表示式。
屬性文法是為上下文無關文法提供語義的一種媒介,它可以幫助指定程式語言的語法和語義。屬性文法(當被視為語法樹時)可以在樹的節點之間傳遞值或資訊。
例子
E → E + T { E.value = E.value + T.value }
CFG 的右側包含指定如何解釋語法的語義規則。這裡,非終結符 E 和 T 的值相加,結果複製到非終結符 E。
語義屬性可以在解析時從其域中分配給它們的值,並在賦值或條件時進行評估。根據屬性獲取其值的方式,可以將其大致分為兩類:綜合屬性和繼承屬性。
綜合屬性
這些屬性從其子節點的屬性值獲取值。為了說明,假設以下產生式
S → ABC
如果 S 從其子節點 (A,B,C) 獲取值,則稱其為綜合屬性,因為 ABC 的值被綜合到 S 中。
在我們之前的示例 (E → E + T) 中,父節點 E 從其子節點獲取其值。綜合屬性永遠不會從其父節點或任何兄弟節點獲取值。
繼承屬性
與綜合屬性相反,繼承屬性可以從父節點和/或兄弟節點獲取值。如以下產生式所示,
S → ABC
A 可以從 S、B 和 C 獲取值。B 可以從 S、A 和 C 獲取值。同樣,C 可以從 S、A 和 B 獲取值。
擴充套件:當非終結符根據語法規則擴充套件為終結符時
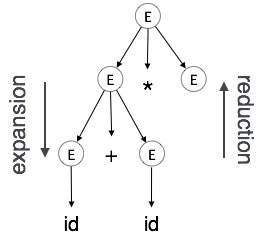
歸約:當終結符根據語法規則歸約為其相應的非終結符時。語法樹自頂向下、從左到右進行解析。每當發生歸約時,我們都應用其相應的語義規則(動作)。
語義分析使用語法制導翻譯來執行上述任務。
語義分析器從其前一階段(語法分析)接收 AST(抽象語法樹)。
語義分析器將屬性資訊附加到 AST,這些資訊稱為帶屬性的 AST。
屬性是二元組值,<屬性名稱,屬性值>
例如
int value = 5; <type, “integer”> <presentvalue, “5”>
對於每個產生式,我們都附加一個語義規則。
S 屬性 SDT
如果 SDT 僅使用綜合屬性,則稱為 S 屬性 SDT。這些屬性使用 S 屬性 SDT 進行評估,這些 SDT 的語義操作寫在產生式(右側)之後。
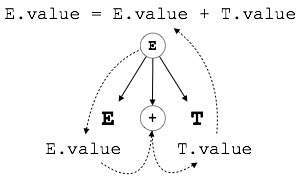
如上所示,S 屬性 SDT 中的屬性在自底向上解析中進行評估,因為父節點的值取決於子節點的值。
L 屬性 SDT
這種形式的 SDT 使用綜合屬性和繼承屬性,但限制不能從右側兄弟節點獲取值。
在 L 屬性 SDT 中,非終結符可以從其父節點、子節點和兄弟節點獲取值。如以下產生式所示
S → ABC
S 可以從 A、B 和 C 獲取值(綜合)。A 只能從 S 獲取值。B 可以從 S 和 A 獲取值。C 可以從 S、A 和 B 獲取值。任何非終結符都不能從其右側的兄弟節點獲取值。
L 屬性 SDT 中的屬性以深度優先和從左到右的解析方式進行評估。

我們可以得出結論,如果一個定義是 S 屬性的,那麼它也是 L 屬性的,因為 L 屬性定義包含 S 屬性定義。