
- 編譯器設計教程
- 編譯器設計 - 首頁
- 編譯器設計 - 概述
- 編譯器設計 - 架構
- 編譯器設計 - 編譯器的階段
- 編譯器設計 - 詞法分析
- 編譯器 - 正則表示式
- 編譯器設計 - 有限自動機
- 編譯器設計 - 語法分析
- 編譯器設計 - 解析型別
- 編譯器設計 - 自頂向下解析器
- 編譯器設計 - 自底向上解析器
- 編譯器設計 - 錯誤恢復
- 編譯器設計 - 語義分析
- 編譯器 - 執行時環境
- 編譯器設計 - 符號表
- 編譯器 - 中間程式碼
- 編譯器設計 - 程式碼生成
- 編譯器設計 - 程式碼最佳化
- 編譯器設計有用資源
- 編譯器設計 - 快速指南
- 編譯器設計 - 有用資源
編譯器設計 - 執行時環境
程式作為原始碼僅僅是文字(程式碼、語句等)的集合,要使其執行,需要在目標機器上執行操作。程式需要記憶體資源來執行指令。程式包含過程的名稱、識別符號等,這些需要在執行時與實際記憶體位置進行對映。
執行時是指正在執行的程式。執行時環境是目標機器的狀態,可能包括軟體庫、環境變數等,以向系統中執行的程序提供服務。
執行時支援系統是一個包,大部分與可執行程式本身一起生成,並促進程序與執行時環境之間的程序通訊。它在程式執行期間負責記憶體分配和釋放。
啟用樹
程式是由組合成多個過程的指令序列組成的。過程中的指令按順序執行。過程有開始和結束分隔符,其內部的所有內容都稱為過程的主體。過程識別符號和其中的有限指令序列構成了過程的主體。
過程的執行稱為其啟用。啟用記錄包含呼叫過程所需的所有必要資訊。啟用記錄可能包含以下單元(取決於使用的源語言)。
| 臨時變數 | 儲存表示式的臨時值和中間值。 |
| 區域性資料 | 儲存被呼叫過程的區域性資料。 |
| 機器狀態 | 在呼叫過程之前儲存機器狀態,例如暫存器、程式計數器等。 |
| 控制連結 | 儲存呼叫過程的啟用記錄的地址。 |
| 訪問連結 | 儲存超出區域性範圍的資料資訊。 |
| 實際引數 | 儲存實際引數,即用於向被呼叫過程傳送輸入的引數。 |
| 返回值 | 儲存返回值。 |
每當執行一個過程時,它的啟用記錄都儲存在堆疊上,也稱為控制堆疊。當一個過程呼叫另一個過程時,呼叫者的執行將暫停,直到被呼叫過程完成執行。此時,被呼叫過程的啟用記錄儲存在堆疊上。
我們假設程式控制以順序方式流動,當呼叫一個過程時,其控制將轉移到被呼叫過程。當被呼叫過程執行完畢後,它將控制返回給呼叫者。這種型別的控制流使更容易以樹的形式表示一系列啟用,稱為**啟用樹**。
為了理解這個概念,我們以一段程式碼為例
. . .
printf(“Enter Your Name: “);
scanf(“%s”, username);
show_data(username);
printf(“Press any key to continue…”);
. . .
int show_data(char *user)
{
printf(“Your name is %s”, username);
return 0;
}
. . .
以下是給定程式碼的啟用樹。

現在我們瞭解到過程是以深度優先的方式執行的,因此堆疊分配是最適合過程啟用的儲存形式。
儲存分配
執行時環境管理以下實體的執行時記憶體需求
程式碼:它被稱為程式的文字部分,在執行時不會改變。它的記憶體需求在編譯時已知。
過程:它們的文字部分是靜態的,但它們以隨機方式被呼叫。這就是為什麼使用堆疊儲存來管理過程呼叫和啟用。
變數:變數只有在執行時才知道,除非它們是全域性變數或常量。堆記憶體分配方案用於管理執行時變數的記憶體分配和釋放。
靜態分配
在這種分配方案中,編譯資料繫結到記憶體中的固定位置,並且在程式執行時不會更改。由於記憶體需求和儲存位置是預先知道的,因此不需要用於記憶體分配和釋放的執行時支援包。
堆疊分配
過程呼叫及其啟用透過堆疊記憶體分配來管理。它採用後進先出 (LIFO) 方法,這種分配策略對於遞迴過程呼叫非常有用。
堆分配
過程的區域性變數僅在執行時分配和釋放。堆分配用於動態地為變數分配記憶體,並在不再需要變數時將其回收。
除了靜態分配的記憶體區域外,堆疊和堆記憶體都可以動態且意外地增長和縮小。因此,系統不能為它們提供固定數量的記憶體。
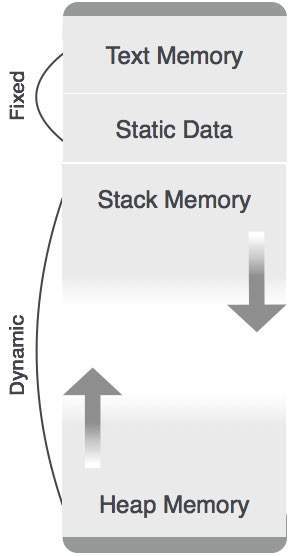
如上圖所示,程式碼的文字部分分配了固定數量的記憶體。堆疊和堆記憶體排列在分配給程式的總記憶體的兩端。兩者都彼此相對地收縮和增長。
引數傳遞
過程之間的通訊媒介稱為引數傳遞。呼叫過程的變數值透過某種機制傳遞給被呼叫過程。在繼續之前,首先了解一些與程式中值相關的基本術語。
右值 (r-value)
表示式的值稱為其右值。如果單個變量出現在賦值運算子的右側,則其包含的值也成為右值。右值總是可以賦值給其他變數。
左值 (l-value)
儲存表示式的記憶體位置(地址)稱為該表示式的左值。它總是出現在賦值運算子的左側。
例如
day = 1; week = day * 7; month = 1; year = month * 12;
從這個例子中,我們瞭解到像 1、7、12 這樣的常量值,以及像 day、week、month 和 year 這樣的變數,都具有右值。只有變數具有左值,因為它們也表示分配給它們的記憶體位置。
例如
7 = x + y;
是一個左值錯誤,因為常量 7 不代表任何記憶體位置。
形式引數
接收呼叫過程傳遞的資訊的變數稱為形式引數。這些變數在被呼叫函式的定義中宣告。
實際引數
其值或地址被傳遞給被呼叫過程的變數稱為實際引數。這些變數在函式呼叫中作為引數指定。
示例
fun_one()
{
int actual_parameter = 10;
call fun_two(int actual_parameter);
}
fun_two(int formal_parameter)
{
print formal_parameter;
}
形式引數根據使用的引數傳遞技術持有實際引數的資訊。它可以是值或地址。
按值傳遞
在按值傳遞機制中,呼叫過程傳遞實際引數的右值,編譯器將其放入被呼叫過程的啟用記錄中。然後,形式引數持有呼叫過程傳遞的值。如果形式引數持有的值發生更改,則它不應影響實際引數。
按引用傳遞
在按引用傳遞機制中,實際引數的左值被複制到被呼叫過程的啟用記錄中。這樣,被呼叫過程現在擁有實際引數的地址(記憶體位置),而形式引數指向相同的記憶體位置。因此,如果形式引數指向的值發生更改,則應該在實際引數上看到影響,因為它們也應該指向相同的值。
按複製-恢復傳遞
這種引數傳遞機制與“按引用傳遞”類似,只是實際引數的更改是在被呼叫過程結束時進行的。在函式呼叫時,實際引數的值被複制到被呼叫過程的啟用記錄中。如果操作形式引數,則不會對實際引數產生即時影響(因為傳遞了左值),但是當被呼叫過程結束時,形式引數的左值將被複制到實際引數的左值。
示例
int y;
calling_procedure()
{
y = 10;
copy_restore(y); //l-value of y is passed
printf y; //prints 99
}
copy_restore(int x)
{
x = 99; // y still has value 10 (unaffected)
y = 0; // y is now 0
}
當此函式結束時,形式引數 x 的左值將被複制到實際引數 y。即使在過程結束之前 y 的值發生更改,x 的左值也會被複制到 y 的左值,使其行為類似於按引用呼叫。
按名稱傳遞
像 Algol 這樣的語言提供了一種新的引數傳遞機制,它類似於 C 語言中的預處理器。在按名稱傳遞機制中,被呼叫的過程的名稱將被其實際主體替換。按名稱傳遞在文字上將過程呼叫中的引數表示式替換為過程主體中的相應引數,以便它現在可以處理實際引數,就像按引用傳遞一樣。