
- 編譯器設計教程
- 編譯器設計 - 首頁
- 編譯器設計 - 概述
- 編譯器設計 - 架構
- 編譯器設計 - 編譯器的階段
- 編譯器設計 - 詞法分析
- 編譯器 - 正則表示式
- 編譯器設計 - 有限自動機
- 編譯器設計 - 語法分析
- 編譯器設計 - 解析型別
- 編譯器設計 - 自頂向下解析器
- 編譯器設計 - 自底向上解析器
- 編譯器設計 - 錯誤恢復
- 編譯器設計 - 語義分析
- 編譯器 - 執行時環境
- 編譯器設計 - 符號表
- 編譯器 - 中間程式碼
- 編譯器設計 - 程式碼生成
- 編譯器設計 - 程式碼最佳化
- 編譯器設計有用資源
- 編譯器設計 - 快速指南
- 編譯器設計 - 有用資源
編譯器設計 - 程式碼生成
程式碼生成可以被認為是編譯的最後階段。透過程式碼生成後的最佳化過程可以應用於程式碼,但這可以被視為程式碼生成階段本身的一部分。編譯器生成的程式碼是某種較低階程式語言的目的碼,例如組合語言。我們已經看到,用高階語言編寫的原始碼被轉換為低階語言,從而產生低階目的碼,該程式碼應具有以下最低限度的屬性
- 它應該承載原始碼的確切含義。
- 它應該在 CPU 使用率和記憶體管理方面高效。
我們現在將瞭解如何將中間程式碼轉換為目標物件程式碼(在本例中為彙編程式碼)。
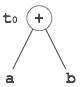
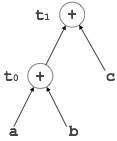
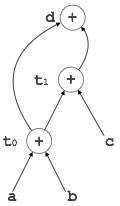
有向無環圖
有向無環圖 (DAG) 是一種工具,它描繪了基本塊的結構,有助於檢視值在基本塊之間流動的過程,並提供最佳化功能。DAG 提供了對基本塊的簡單轉換。這裡可以理解 DAG
葉節點表示識別符號、名稱或常量。
內部節點表示運算子。
內部節點還表示表示式的結果或將值儲存或賦值到的識別符號/名稱。
示例
t0 = a + b t1 = t0 + c d = t0 + t1
[t0 = a + b] |
[t1 = t0 + c] |
[d = t0 + t1] |
窺孔最佳化
此最佳化技術在原始碼上本地工作以將其轉換為最佳化後的程式碼。就本地而言,我們的意思是手頭程式碼塊的一小部分。這些方法可以應用於中間程式碼以及目的碼。分析一系列語句並檢查以下可能的最佳化
冗餘指令消除
在原始碼級別,使用者可以執行以下操作
int add_ten(int x)
{
int y, z;
y = 10;
z = x + y;
return z;
}
|
int add_ten(int x)
{
int y;
y = 10;
y = x + y;
return y;
}
|
int add_ten(int x)
{
int y = 10;
return x + y;
}
|
int add_ten(int x)
{
return x + 10;
}
|
在編譯級別,編譯器搜尋本質上冗餘的指令。即使刪除其中一些指令,多條載入和儲存指令也可能具有相同的含義。例如
- MOV x, R0
- MOV R0, R1
我們可以刪除第一條指令並將句子重寫為
MOV x, R1
不可達程式碼
不可達程式碼是程式程式碼的一部分,由於程式設計結構而永遠不會被訪問。程式設計師可能意外地編寫了一段永遠無法到達的程式碼。
示例
void add_ten(int x)
{
return x + 10;
printf(“value of x is %d”, x);
}
在此程式碼段中,printf 語句永遠不會執行,因為程式控制在執行之前返回,因此可以刪除printf。
控制流最佳化
在某些程式碼中,程式控制會在不執行任何重要任務的情況下來回跳轉。可以刪除這些跳轉。考慮以下程式碼塊
... MOV R1, R2 GOTO L1 ... L1 : GOTO L2 L2 : INC R1
在此程式碼中,可以刪除標籤 L1,因為它將控制權傳遞給 L2。因此,控制可以直接到達 L2,而不是跳轉到 L1 然後跳轉到 L2,如下所示
... MOV R1, R2 GOTO L2 ... L2 : INC R1
代數表示式簡化
在某些情況下,代數表示式可以變得簡單。例如,表示式a = a + 0 可以替換為a 本身,表示式 a = a + 1 可以簡單地替換為 INC a。
強度削弱
有些操作會消耗更多時間和空間。可以透過用其他消耗更少時間和空間但產生相同結果的操作替換它們來降低它們的“強度”。
例如,x * 2 可以替換為x << 1,它只涉及一次左移。雖然 a * a 和 a2 的輸出相同,但 a2 的實現效率更高。
訪問機器指令
目標機器可以部署更復雜的指令,這些指令能夠以更高效的方式執行特定操作。如果目的碼可以直接容納這些指令,這不僅會提高程式碼質量,還會產生更高效的結果。
程式碼生成器
程式碼生成器需要了解目標機器的執行時環境及其指令集。程式碼生成器應考慮以下事項以生成程式碼
目標語言:程式碼生成器必須瞭解要轉換程式碼的目標語言的性質。該語言可能提供一些特定於機器的指令來幫助編譯器以更方便的方式生成程式碼。目標機器可以具有 CISC 或 RISC 處理器架構。
IR 型別:中間表示形式有多種形式。它可以是抽象語法樹 (AST) 結構、逆波蘭表示法或 3 地址程式碼。
指令選擇:程式碼生成器將中間表示作為輸入並將其轉換為目標機器的指令集。一種表示形式可以有多種(指令)轉換方式,因此程式碼生成器有責任明智地選擇合適的指令。
暫存器分配:程式在執行期間需要維護許多值。目標機器的架構可能不允許所有值都儲存在 CPU 記憶體或暫存器中。程式碼生成器決定將哪些值儲存在暫存器中。此外,它決定使用哪些暫存器來儲存這些值。
指令排序:最後,程式碼生成器決定指令的執行順序。它建立指令排程以執行它們。
描述符
程式碼生成器在生成程式碼時必須跟蹤暫存器(以獲取可用性)和地址(值的儲存位置)。對於兩者,使用以下兩個描述符
暫存器描述符:暫存器描述符用於通知程式碼生成器暫存器的可用性。暫存器描述符跟蹤儲存在每個暫存器中的值。每當在程式碼生成期間需要新暫存器時,都會諮詢此描述符以獲取暫存器可用性。
地址描述符:程式中使用的名稱(識別符號)的值在執行期間可能儲存在不同的位置。地址描述符用於跟蹤儲存識別符號值的記憶體位置。這些位置可能包括 CPU 暫存器、堆、棧、記憶體或上述位置的組合。
程式碼生成器即時更新這兩個描述符。對於載入語句 LD R1, x,程式碼生成器
- 更新暫存器描述符 R1,其中包含 x 的值,並且
- 更新地址描述符 (x) 以顯示 x 的一個例項在 R1 中。
程式碼生成
基本塊包含一系列三地址指令。程式碼生成器將這些指令序列作為輸入。
注意:如果名稱的值存在於多個位置(暫存器、快取或記憶體),則暫存器的值將優先於快取和主記憶體。同樣,快取的值將優先於主記憶體。主記憶體幾乎沒有優先順序。
getReg:程式碼生成器使用getReg 函式來確定可用暫存器的狀態和名稱值的儲存位置。getReg 的工作原理如下
如果變數 Y 已經在暫存器 R 中,則使用該暫存器。
否則,如果某個暫存器 R 可用,則使用該暫存器。
否則,如果以上兩種選擇都不可能,則選擇需要最少載入和儲存指令的暫存器。
對於指令 x = y OP z,程式碼生成器可能會執行以下操作。假設 L 是要將 y OP z 的輸出儲存到的位置(最好是暫存器)
呼叫函式 getReg,以確定 L 的位置。
透過查閱y 的地址描述符來確定y 的當前位置(暫存器或記憶體)。如果y 當前不在暫存器L 中,則生成以下指令以將y 的值複製到L
MOV y’, L
其中y’表示y的複製值。
使用步驟 2 中用於y 的相同方法確定z 的當前位置,並生成以下指令
OP z’, L
其中z’表示z的複製值。
現在 L 包含 y OP z 的值,該值打算分配給x。因此,如果 L 是暫存器,則更新其描述符以指示它包含x的值。更新x的描述符以指示它儲存在位置L處。
如果 y 和 z 以後不再使用,則可以將其返還給系統。
其他程式碼結構(如迴圈和條件語句)通常以通用匯編方式轉換為組合語言。