- Snowflake 教程
- Snowflake - 首頁
- Snowflake - 簡介
- Snowflake - 資料架構
- Snowflake - 功能架構
- Snowflake - 如何訪問
- Snowflake - 版本
- Snowflake - 定價模型
- Snowflake - 物件
- Snowflake - 表和檢視型別
- Snowflake - 登入
- Snowflake - 資料倉庫
- Snowflake - 資料庫
- Snowflake - 模式
- Snowflake - 表和列
- Snowflake - 從檔案載入資料
- Snowflake - 有用的示例查詢
- Snowflake - 監控使用情況和儲存
- Snowflake - 快取
- 將資料從 Snowflake 解除安裝到本地
- 外部資料載入(從 AWS S3)
- 外部資料解除安裝(到 AWS S3)
- Snowflake 資源
- Snowflake 快速指南
- Snowflake - 有用資源
- Snowflake - 討論
Snowflake 快速指南
Snowflake - 簡介
Snowflake 是一個基於雲的先進資料平臺系統,作為軟體即服務 (SaaS) 提供。Snowflake 提供了從 AWS S3、Azure、Google Cloud 儲存資料、處理複雜查詢和不同分析解決方案的功能。Snowflake 提供的分析解決方案比傳統的資料庫及其分析功能更快、更易於使用且更靈活。Snowflake 儲存和提供近即時資料,而不是實際即時資料。
Snowflake 是 OLAP(聯機分析處理)技術的先進解決方案。OLAP 也被稱為使用歷史資料的聯機資料檢索和資料分析系統。它處理具有少量事務的複雜和聚合查詢。例如:獲取公司上個月的訂單數量、銷售額、上季度公司的新使用者列表數量等。Snowflake 不用作 OLTP(聯機事務處理)資料庫。OLTP 資料庫通常包含具有大量小型資料事務的即時資料。例如:插入客戶的訂單詳情、註冊新客戶、跟蹤訂單交付狀態等。
為什麼要使用 Snowflake?
Snowflake 提供資料平臺作為雲服務。
客戶無需選擇、安裝、配置或管理任何硬體(虛擬或物理)。
無需安裝、配置或管理任何軟體即可訪問它。
所有持續的維護、管理、升級和修補都由 Snowflake 本身負責。
傳統的分析解決方案資料庫架構複雜、成本高且受限,而 Snowflake 則在資料工程、資料湖概念、資料倉庫、資料科學、資料應用和資料交換或共享方面非常豐富。它易於訪問和使用,不受資料大小和儲存容量的限制。使用者只需管理自己的資料;所有與資料平臺相關的管理都由 Snowflake 本身完成。
除此之外,Snowflake 還具有以下功能:
使用多種語言(如 Java、Python、PHP、Spark、Ruby 等)構建簡單可靠的資料管道。
安全訪問、非常好的效能和資料湖的安全性。
工具、資料儲存和資料大小的零管理。
使用任何框架進行建模的簡單資料準備。
構建資料密集型應用程式的零運營負擔。
在公司生態系統中共享和協作即時資料。
Snowflake - 資料架構
Snowflake 資料架構重新發明了一種新的 SQL 查詢引擎。它僅針對雲設計。Snowflake 不使用也不基於任何現有的資料庫技術。它甚至不使用 Hadoop 等大資料軟體平臺。Snowflake 提供了分析資料庫的所有功能,以及許多額外的獨特功能和能力。
Snowflake 擁有用於儲存結構化和半結構化資料的中央資料儲存庫。可以從 Snowflake 平臺中的所有可用計算節點訪問這些資料。它使用虛擬倉庫作為計算環境來處理查詢。在處理查詢時,它利用多叢集、微分割槽和高階快取概念。Snowflake 的雲服務負責為使用者提供端到端解決方案,例如使用者的登入驗證到 select 查詢的結果。
Snowflake 的資料架構**具有三個主要層**:
- 資料庫儲存
- 查詢處理
- 雲服務
以下是 Snowflake 的**資料架構**圖:
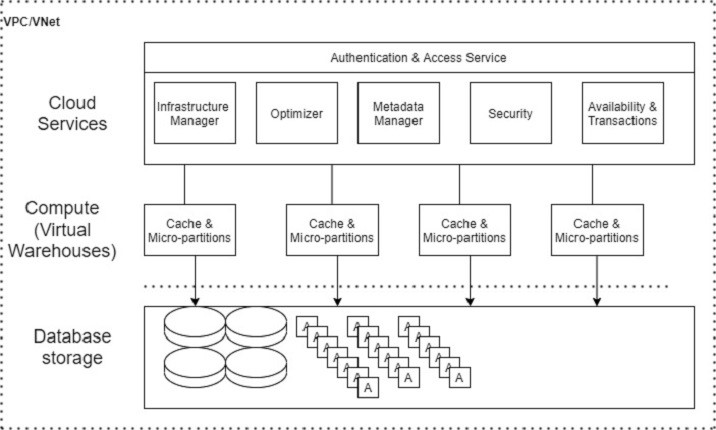
資料庫儲存
Snowflake 支援 Amazon S3、Azure 和 Google Cloud 使用檔案系統將資料載入到 Snowflake 中。使用者應將檔案(.csv、.txt、.xlsx 等)上傳到雲端,然後在 Snowflake 中建立連線以匯入資料。資料大小不限,但根據雲服務,檔案大小最多為 5GB。一旦資料載入到 Snowflake 中,它就會利用其內部最佳化和壓縮技術將資料以列格式儲存到中央儲存庫中。中央儲存庫基於資料儲存的雲。
Snowflake 負責資料管理的所有方面,例如如何使用自動資料叢集儲存資料、資料的組織和結構、透過將資料儲存在許多微分割槽中的壓縮技術、元資料、統計資料等等。Snowflake 將資料儲存為資料物件,使用者無法直接檢視或訪問它們。使用者可以透過 SQL 查詢(在 Snowflake 的 UI 中或使用 Java、Python、PHP、Ruby 等程式語言)訪問這些資料。
查詢處理
查詢執行是處理層或計算層的一部分。要處理查詢,Snowflake 需要計算環境,在 Snowflake 中稱為“虛擬倉庫”。虛擬倉庫是一個計算叢集。虛擬倉庫由 CPU、記憶體和臨時儲存系統組成,以便它可以執行 SQL 執行和 DML(資料操作語言)操作。
SQL SELECT 執行
使用 Update、Insert、Update 更新資料
使用 COPY INTO
將資料載入到表中 使用 COPY INTO
從表中解除安裝資料
但是,伺服器的數量取決於虛擬倉庫的大小。例如,XSmall 倉庫每個叢集有 1 臺伺服器,而 Small 倉庫每個叢集有 2 臺伺服器,並且隨著大小(例如 Large、XLarge 等)的增加而加倍。
在執行查詢時,Snowflake 會分析請求的查詢,並使用最新的微分割槽並在不同階段評估快取以提高效能並減少獲取資料的時間。減少時間意味著使用者使用的積分更少。
雲服務
雲服務是 Snowflake 的“大腦”。它協調和管理 Snowflake 的活動。它將 Snowflake 的所有元件整合在一起,以處理從登入驗證到交付查詢響應的使用者請求。
此層管理以下服務:
它是所有儲存的集中式管理。
它管理與儲存一起工作的計算環境。
它負責雲中 Snowflake 的升級、更新、修補和配置。
它對 SQL 查詢執行基於成本的最佳化。
它自動收集統計資訊,例如使用的積分、儲存容量利用率
安全性,例如基於角色和使用者的身份驗證、訪問控制
它執行加密以及金鑰管理服務。
它在資料載入到系統時儲存元資料。
還有更多……
Snowflake - 功能架構
Snowflake 支援結構化和半結構化資料。資料載入完成後,Snowflake 會自動組織和構造資料。在儲存資料時,Snowflake 會根據其智慧將其劃分並儲存到不同的微分割槽中。Snowflake 甚至將資料儲存在不同的叢集中。
在功能級別上,要從 Snowflake 訪問資料,需要以下元件:
登入後選擇合適的角色
Snowflake 中稱為資料倉庫的虛擬倉庫,用於執行任何活動
資料庫模式
資料庫
表和列
Snowflake 提供以下高階分析功能:
資料轉換
支援業務應用程式
商業分析/報告/BI
資料科學
與其他資料系統共享資料
資料克隆
下圖顯示了 Snowflake 的功能架構:
每個塊中的“設定”符號可以指資料倉庫,XS、XXL、XL、L、S 指的是執行不同操作所需的資料倉庫大小。根據需求和使用情況,可以增加或減少資料倉庫的大小;甚至可以將其從單叢集轉換為多叢集。
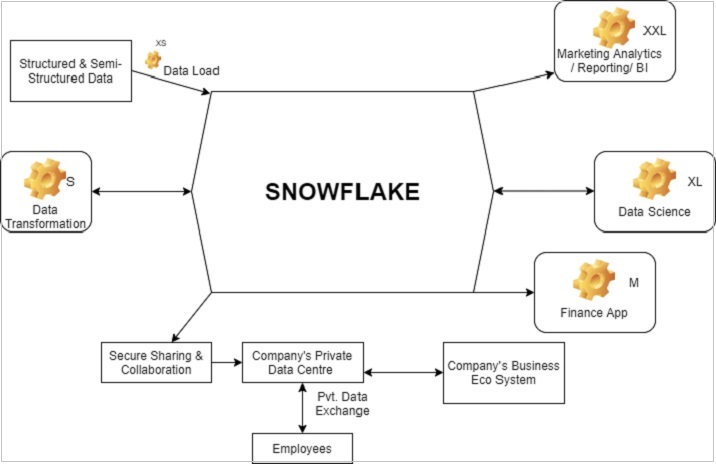
Snowflake - 如何訪問
Snowflake 是一個許可資料平臺。它使用積分的概念向客戶收費。但是,它提供 30 天免費試用,包含 400 美元的積分用於學習目的。
請按照以下步驟在 30 天內免費訪問 Snowflake:
開啟 URL "www.snowflake.com" 並單擊頁面右上角的“免費開始”。
它將導航到註冊頁面,使用者需要在其中提供姓名、電子郵件、公司和國家/地區等詳細資訊。填寫表格後,單擊“繼續”按鈕。
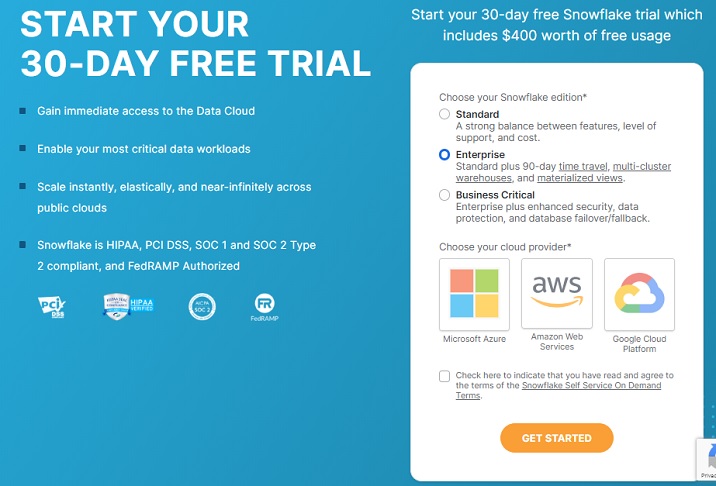
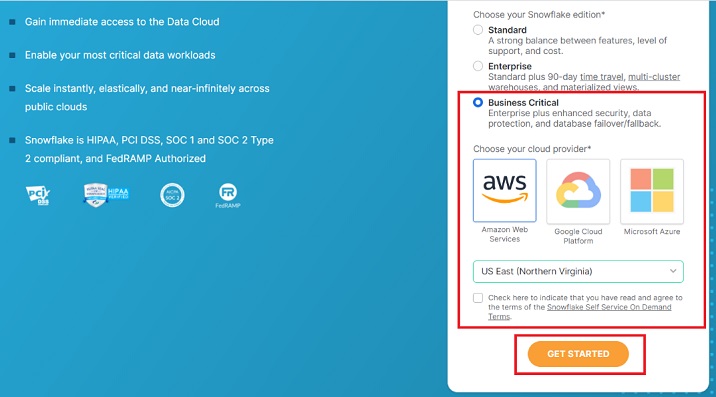
在下一個螢幕上,系統會要求您選擇 Snowflake 版本。根據您要執行的功能選擇版本。對於本教程,標準版就足夠了,但對於使用 AWS S3 載入資料,我們需要業務關鍵版。
選擇**業務關鍵版**,然後單擊**AWS**。選擇 AWS 所在的區域。
選中“條款和條件”框,然後單擊“開始”按鈕。
以下螢幕截圖演示了上述步驟:
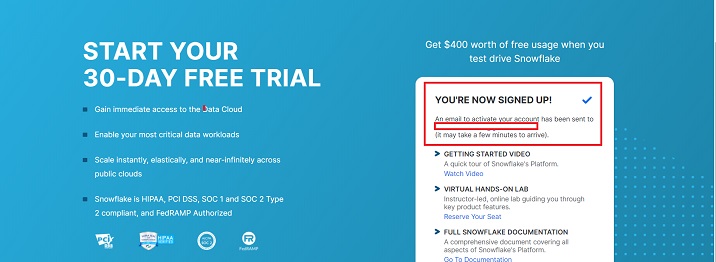
您將收到一條訊息,提示帳戶建立正在進行中,並且已向您的地址傳送電子郵件,如下所示。
檢查您的電子郵件收件箱。收到來自 Snowflake 的電子郵件後(通常在 2-3 分鐘內),單擊“點選啟用”按鈕。
它將導航到 Snowflake 的頁面,使用者需要在其中設定使用者名稱和密碼。此憑據將用於登入 Snowflake。
您的電子郵件中將提供一個 URL,例如:**“https://ABC12345.us-east-1.snowflakecomputing.com/console/login”**。這是一個使用者特定的 URL,用於訪問雲中的 Snowflake。無論何時要在 Snowflake 中工作,請使用個人 URL 並登入。
Snowflake - 版本
Snowflake 根據使用者/公司的需求提供四個不同的版本。
- 標準版
- 企業版
- 業務關鍵版
- 虛擬私有 Snowflake (VPS) 版
標準版
這是 Snowflake 的基本版本。此版本提供以下功能:
- 支援完整的 SQL 資料倉庫
- 安全資料共享
- 全天候優質支援
- 1 天的資料時光機
- 資料加密
- 專用虛擬倉庫
- 聯合身份驗證
- 資料庫複製
- 支援外部函式
- Snowsight
- 支援使用者建立自己的資料交換
- 資料市場訪問
企業版
它是標準版+,即標準版的所有功能以及以下附加功能:
- 多叢集倉庫
- 長達 90 天的資料時光機
- 每年更改加密金鑰
- 物化檢視
- 搜尋最佳化服務
- 動態資料遮蔽
- 外部資料令牌化
業務關鍵版
它是企業版+,即企業版和標準版的所有功能以及以下附加功能:
- HIPAA 支援
- PCI 合規性
- 無處不在的資料加密
- AWS 私有鏈路支援
- Azure 私有鏈路支援
- 資料庫故障轉移和回退
虛擬私有 Snowflake (VPS) 版
它是業務關鍵版+,也是最先進的版本。它支援 Snowflake 的所有產品。
客戶專用的虛擬伺服器,其中加密金鑰位於記憶體中。
客戶專用的元資料儲存。
Snowflake - 定價模型
Snowflake 使用**三個不同的階段**或**層級**為終端使用者提供服務:
- 儲存 (Storage)
- 虛擬倉庫 (計算) (Virtual Warehouse (Compute))
- 雲服務
Snowflake 沒有許可證費用。但是,定價基於這三層的使用情況以及無伺服器功能。Snowflake 收取固定金額,加上基於 Snowflake 積分使用情況的任何額外費用。
什麼是 Snowflake 積分?(What is Snowflake Credit?)
它是用於消費 Snowflake 資源(通常是虛擬倉庫、雲服務和無伺服器功能)的支付方式。Snowflake 積分是一個計量單位。它是根據使用的資源計算的,如果客戶沒有使用任何資源或資源處於休眠狀態,則不收取任何費用。例如,當虛擬倉庫正在執行並且雲服務層正在執行某些使用者定義的任務時,就會使用 Snowflake 積分。
儲存成本 (Storage Cost)
Snowflake 對資料儲存收取月費。儲存成本以每月在 Snowflake 中儲存的資料平均量來衡量。此資料大小是在 Snowflake 執行壓縮後計算的。此成本非常低,每月 1TB 資料約 23 美元。
虛擬倉庫 (計算) (Virtual Warehouse (Compute))
它是一個或多個用於將資料載入到 Snowflake 並執行查詢的叢集。Snowflake 使用 Snowflake 積分作為客戶的付款方式。
Snowflake 積分的計算基於倉庫大小、叢集數量和執行查詢所花費的時間。倉庫的大小決定了查詢執行的速度。當虛擬倉庫未執行並處於暫停模式時,它不會消耗任何 Snowflake 積分。不同大小的倉庫消耗 Snowflake 積分的速度也不同。
| 倉庫大小 (Warehouse Size) | 伺服器 (Servers) | 每小時積分 (Credit/Hour) | 每秒積分 (Credits/Second) |
|---|---|---|---|
| 超小 (X-Small) | 1 | 1 | 0.0003 |
| 小 (Small) | 2 | 2 | 0.0006 |
| 中 (Medium) | 4 | 4 | 0.0011 |
| 大 (Large) | 8 | 8 | 0.0022 |
| 超大 (X-Large) | 16 | 16 | 0.0044 |
| 2 倍超大 (2X-Large) | 32 | 32 | 0.0089 |
| 3 倍超大 (3X-Large) | 64 | 64 | 0.0178 |
| 4 倍超大 (4X-Large) | 128 | 128 | 0.0356 |
雲服務
雲服務管理使用者任務的端到端解決方案。它會根據任務的要求自動分配資源。Snowflake 提供高達每日計算積分 10% 的免費雲服務使用量。
例如,如果使用者每天在計算方面花費 100 積分,則用於雲服務的 10 積分免費。
無伺服器功能 (Serverless Features)
Snowflake 提供許多額外的無伺服器功能。這些是託管的計算資源,Snowflake 在使用時會消耗積分。
Snowpipe、資料庫複製、物化檢視維護、自動叢集和搜尋最佳化服務都是 Snowflake 提供的無伺服器功能。
Snowflake - 物件
Snowflake 在邏輯上將資料組織到三個階段:帳戶、資料庫和模式。
資料庫和模式在邏輯上組織 Snowflake 帳戶中的資料。一個帳戶可以有多個數據庫和模式,但一個數據庫必須只與一個模式繫結,反之亦然。
Snowflake 物件 (Snowflake Objects)
以下是 Snowflake 物件的列表:
- 帳戶 (Account)
- 使用者 (User)
- 角色 (Role)
- 虛擬倉庫 (Virtual Warehouse)
- 資源監控器 (Resource Monitor)
- 整合 (Integration)
- 資料庫
- 模式 (Schema)
- 表 (Table)
- 檢視 (View)
- 儲存過程 (Stored Procedure)
- 使用者自定義函式 (UDF) (User Defined Functions (UDF))
- 階段 (Stage)
- 檔案格式 (File Format)
- 管道 (Pipe)
- 序列 (Sequence)
模式之後的物件與模式繫結,模式與資料庫繫結。其他實體(如使用者和角色)用於身份驗證和訪問管理。
與 Snowflake 物件相關的要點 (Important Points Related to Snowflake Objects)
以下是一些關於 Snowflake 物件的重要事項,您應該瞭解:
所有 Snowflake 物件都屬於邏輯容器,頂級容器是帳戶,即所有內容都在 Snowflake 的帳戶下。
Snowflake 單獨保護所有物件。
使用者可以根據授予角色的許可權對物件執行操作和任務。
許可權示例 (Privileges Example):
- 建立虛擬倉庫 (Create a virtual warehouse)
- 列出模式中的表 (List Tables in a schema)
- 將資料插入表中 (Insert data into a table)
- 從表中選擇資料 (Select data from a table)
- 不允許刪除/截斷表 (Not delete/truncate a table)
Snowflake - 表和檢視型別 (Snowflake - Table & View Types)
表型別 (Table Types)
Snowflake 根據表的用途和性質將其分為不同型別。共有四種類型的表:
永久表 (Permanent Table)
永久表是在**資料庫**中建立的。
這些表會一直存在,直到從資料庫中**刪除**或**刪除**。
這些表旨在儲存需要最高級別資料保護和恢復的資料。
這些是預設的表型別。
這些表可以進行時間旅行,最長可達 90 天,即某人可以獲取最多 90 天前的數。
它是故障安全的,如果由於故障而丟失資料,可以恢復資料。
臨時表 (Temporary Table)
顧名思義,臨時表的存在時間較短。
這些表在一個會話中存在。
如果使用者需要為後續查詢和分析使用臨時表,則會話完成後,它會自動刪除臨時表。
它主要用於短暫的資料,例如 ETL/ELT。
臨時表可以進行時間旅行,但只有 0 到 1 天。
它不是故障安全的,這意味著無法自動恢復資料。
瞬態表 (Transient Table)
這些表會一直存在,直到使用者刪除或刪除它們。
多個使用者可以訪問瞬態表。
它用於需要“資料永續性”但不需求長期“資料保留”的情況。例如,網站訪客的詳細資訊、訪問和註冊網站的使用者詳細資訊,因此註冊後,可能不需要將詳細資訊儲存在兩個不同的表中。
瞬態表可以進行時間旅行,但只有 0 到 1 天。
它也不是故障安全的。
外部表 (External Table)
這些表會一直存在,直到被移除。
這裡使用“移除”一詞,因為外部表就像 Snowflake 的外部,它們不能被刪除或刪除。它應該被移除。
可以將其視為 Snowflake 位於外部資料湖之上,即資料湖的主要來源指向 Snowflake 以根據使用者的需求利用資料。
無法直接訪問資料。可以透過外部階段在 Snowflake 中訪問它。
外部表僅用於讀取。
外部表無法進行時間旅行。
在 Snowflake 環境中它不是故障安全的。
檢視型別 (View Types)
Snowflake 中主要有三類檢視:
標準檢視 (Standard View)
這是預設的檢視型別。
選擇表中的查詢以檢視資料。
使用者可以根據角色和許可權執行查詢。
底層 DDL 可供任何有權訪問這些檢視的角色使用。
安全檢視 (Secure View)
安全檢視意味著只有授權使用者才能訪問。
授權使用者可以檢視定義和詳細資訊。
擁有適當角色的授權使用者可以訪問這些表並執行查詢。
在安全檢視中,Snowflake 查詢最佳化器會繞過用於常規檢視的最佳化。
物化檢視 (Materialized View)
物化檢視更像一張表。
這些檢視使用過濾器條件儲存來自主資料來源的結果。例如,一家公司擁有自公司成立以來所有在職、離職或已故員工的記錄。現在,如果使用者只需要在職員工的詳細資訊,則可以查詢主表並將結果儲存為物化檢視以進行進一步的分析。
物化檢視會自動重新整理,即每當主表獲得額外/新的員工記錄時,它也會重新整理物化檢視。
Snowflake 也支援安全物化檢視。
物化檢視會自動維護,它可能會消耗大量的計算資源。
物化檢視的總成本基於“資料儲存 + 計算 + 無伺服器服務”。
每個物化檢視的計算費用是根據資料變化量計算的。
Snowflake - 登入
登入 Snowflake 非常容易,因為它是一個基於雲的平臺。登入 Snowflake 帳戶需要執行以下步驟:
轉到您在註冊時收到的來自 Snowflake 的電子郵件,並複製唯一的 URL(每個使用者唯一)。
轉到瀏覽器並導航到該 URL。它將導航到**登入**頁面。
提供您在註冊過程中設定的使用者名稱和密碼。最後,單擊登入按鈕。
以下螢幕截圖顯示了登入螢幕:
成功登入會將使用者導航到 Snowflake 資料平臺。使用者可以在右上角看到他們的姓名,如下圖所示。除了姓名外,他們還可以看到分配給他們的角色。
在左上角,有一些圖示,例如**資料庫、共享、資料市場、倉庫、工作表**和**歷史記錄**。使用者可以單擊它們並檢視這些專案的詳細資訊。
在左側面板中,Snowflake 提供了一些資料庫和模式用於實踐,例如“DEMO_DB、SNOWFLAKE_SAMPLE_DATA、UTILDB”。
資料庫詳細資訊旁邊的空白螢幕稱為**工作表**,使用者可以在其中編寫查詢並使用**執行**按鈕執行它們。
底部是**結果**面板。查詢的結果將顯示在此處。
以下螢幕截圖顯示了登入後螢幕的不同部分:

Snowflake - 資料倉庫
由於倉庫對於計算很重要。讓我們討論如何建立倉庫、更改它以及檢視倉庫的詳細資訊。
Snowflake 提供兩種建立/修改/檢視倉庫的方法:第一種方法是 UI,另一種方法是**SQL**語句。
使用 Snowflake 的 UI 操作倉庫 (Working on Warehouses using Snowflake's UI)
讓我們從建立倉庫開始:
建立倉庫 (Create Warehouse)
使用唯一的 URL 登入 Snowflake。單擊頂部功能區中顯示的**倉庫**,如下圖所示:
它會導航到下一個螢幕。單擊倉庫列表上方的**建立**,如下所示。
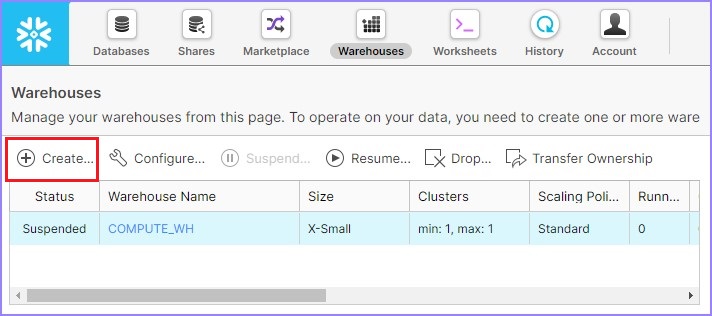
它將開啟**建立**倉庫對話方塊。應輸入以下欄位以建立倉庫。
- **名稱** - test_WH
- **大小** - 小 (Small)
- 將**自動暫停**設定為**5 分鐘**
然後單擊**完成**按鈕。
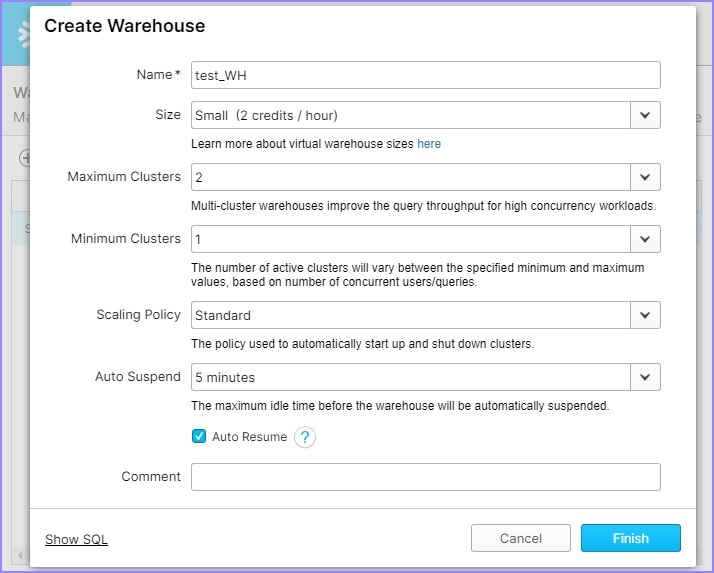
建立倉庫後,使用者可以在列表中檢視它,如下圖所示:
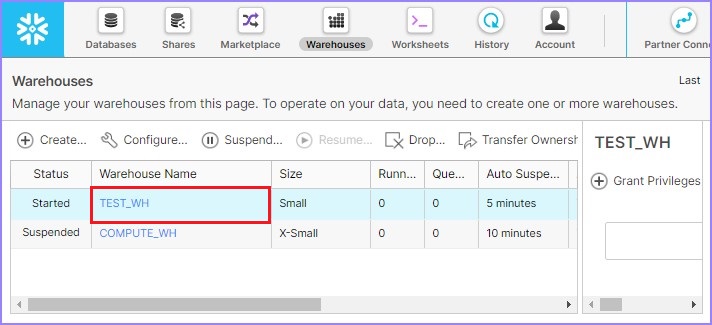
編輯/修改/更改倉庫 (Edit/Modify/Alter Warehouse)
Snowflake 提供了根據需求修改或更改**倉庫**的功能。例如,建立和使用後,使用者可以更新倉庫大小、叢集和暫停時間。
點選頂部功能區中顯示的倉庫按鈕。它將顯示倉庫頁面詳細資訊。從倉庫列表中選擇需要修改的倉庫。單擊配置,如下面的螢幕截圖所示:
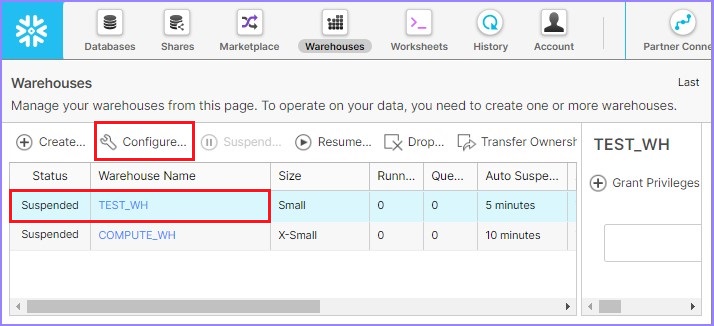
將彈出配置倉庫對話方塊。使用者可以修改除名稱之外的所有詳細資訊。將自動暫停時間從5分鐘更改為10分鐘。單擊完成按鈕,如下面的螢幕截圖所示。
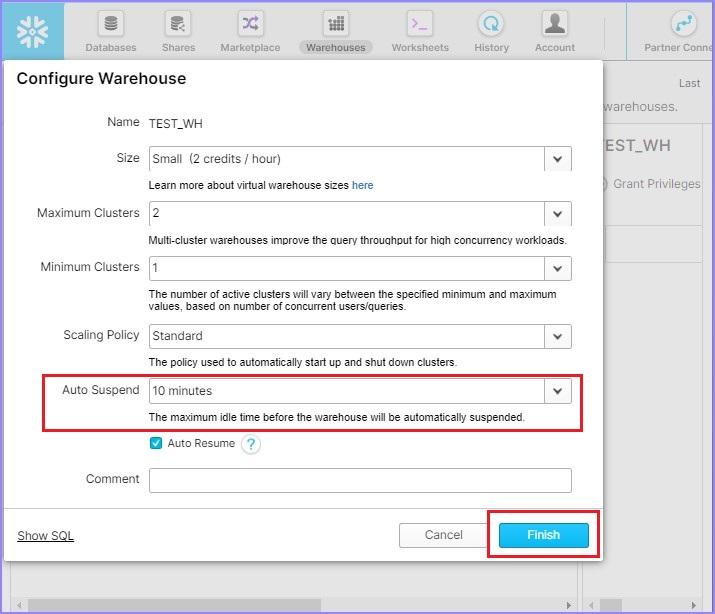
使用者單擊完成按鈕後,將能夠在視圖面板中看到更新的詳細資訊。
檢視倉庫
點選頂部功能區中顯示的倉庫按鈕。它將顯示倉庫的視圖面板,其中包含所有已建立的倉庫。
使用建立按鈕建立新的倉庫。
使用配置按鈕更改/修改現有倉庫。
如果所選倉庫處於暫停模式,則使用恢復按鈕啟用它。
下面的螢幕截圖演示瞭如何恢復處於暫停模式的倉庫:
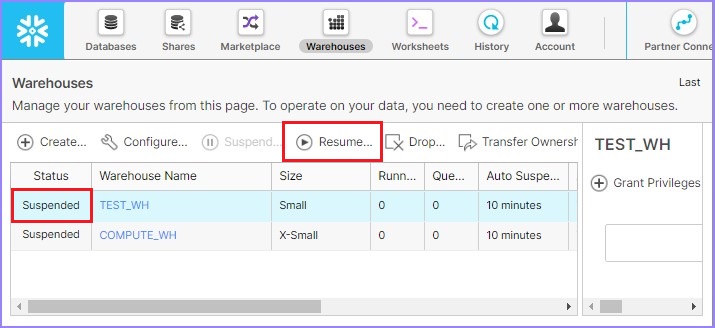
單擊恢復按鈕後,將彈出一個對話方塊。單擊那裡的完成按鈕,如下面的螢幕截圖所示:
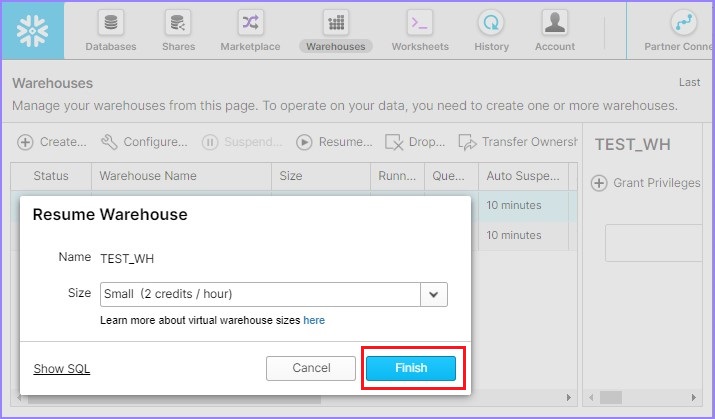
現在,使用者可以看到倉庫已啟動,如下面的螢幕截圖所示:
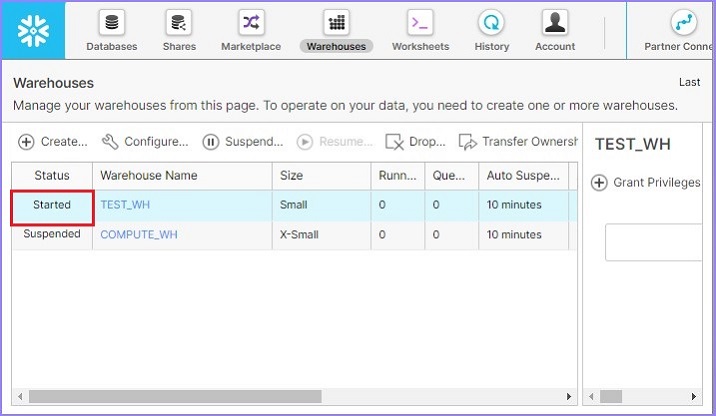
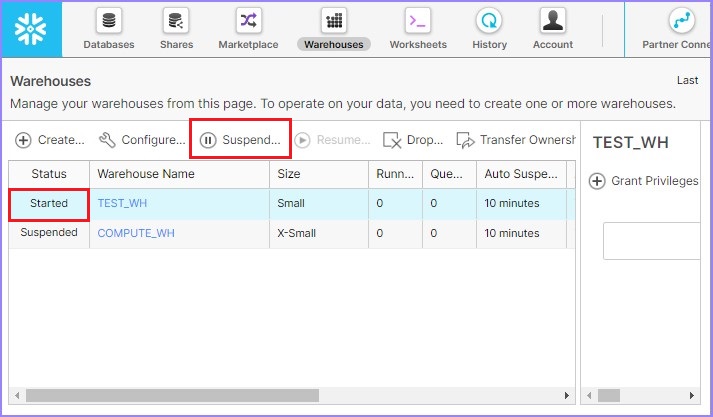
同樣,使用者可以使用暫停按鈕立即暫停倉庫。如果任何倉庫處於已啟動模式,則此按鈕可用。選擇要暫停的倉庫並單擊暫停按鈕。將彈出一個對話方塊,單擊是以暫停,否則單擊否。
下面的螢幕截圖顯示了暫停功能:
使用者還可以透過選擇倉庫並單擊刪除按鈕來刪除倉庫,如下面的螢幕截圖所示:
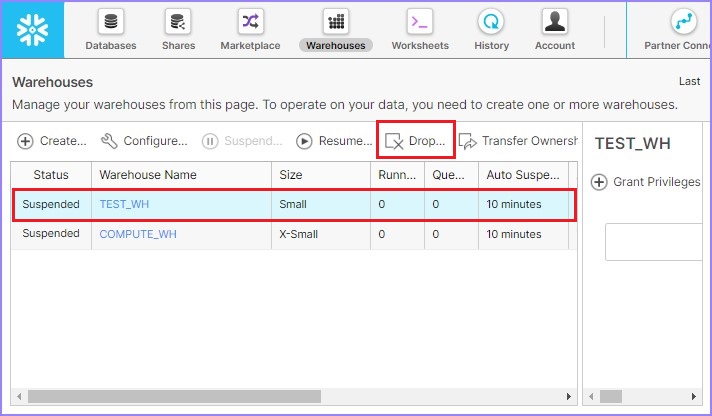
將彈出一個對話方塊以確認。單擊“是”以刪除,否則單擊“否”。
使用Snowflake的SQL介面操作倉庫
現在讓我們檢查如何使用Snowflake的SQL介面操作倉庫。
建立倉庫 (Create Warehouse)
登入Snowflake並導航到工作表。使用者登入後,預設情況下會開啟工作表,否則單擊頂部功能區中顯示的工作表,如下面的螢幕截圖所示。
使用以下查詢建立倉庫TEST_WH:
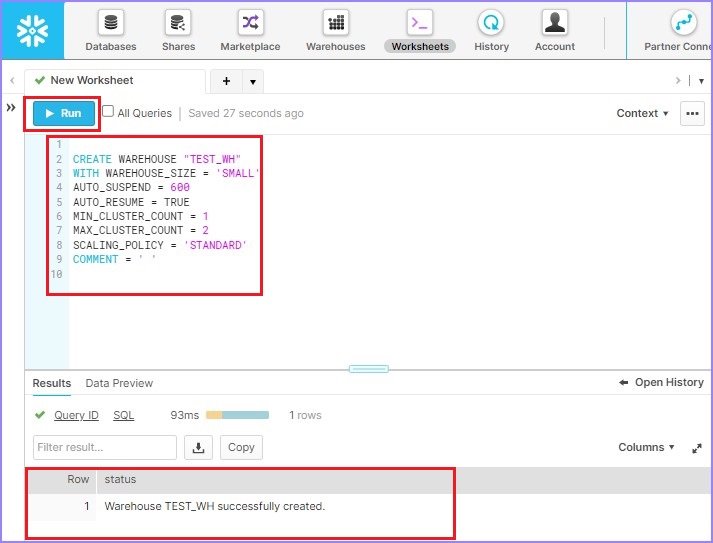
CREATE WAREHOUSE "TEST_WH" WITH WAREHOUSE_SIZE = 'SMALL' AUTO_SUSPEND = 600 AUTO_RESUME = TRUE MIN_CLUSTER_COUNT = 1 MAX_CLUSTER_COUNT = 2 SCALING_POLICY = 'STANDARD' COMMENT = ' '
單擊執行以執行查詢。結果將顯示在結果面板中,因為倉庫“TEST_WH”已成功建立。
下面的螢幕截圖顯示了使用SQL處理的輸出:
編輯/修改/更改倉庫 (Edit/Modify/Alter Warehouse)
要更改/修改倉庫,請使用以下查詢並執行它:
ALTER WAREHOUSE "TEST_WH" SET WAREHOUSE_SIZE = 'SMALL' AUTO_SUSPEND = 1200 AUTO_RESUME = TRUE MIN_CLUSTER_COUNT = 1 MAX_CLUSTER_COUNT = 1 SCALING_POLICY = 'STANDARD' COMMENT = ' '
使用者可以轉到檢視面板並驗證更新的詳細資訊,如下所示:
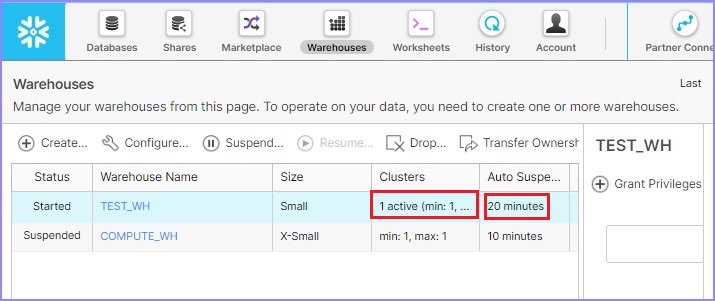
檢視倉庫
要檢視所有列出的倉庫,使用者可以使用以下SQL。它會顯示所有列出倉庫的詳細資訊。
SHOW WAREHOUSES
要暫停倉庫,請使用以下SQL:
ALTER WAREHOUSE TEST_WH SUSPEND
要恢復倉庫,請使用以下SQL:
ALTER WAREHOUSE "TEST_WH" RESUME If SUSPENDED
要刪除倉庫,請使用以下SQL:
DROP WAREHOUSE "TEST_WH"
Snowflake - 資料庫
資料庫是模式的邏輯分組,其中包含表和列。在本章中,我們將討論如何建立資料庫以及檢視詳細資訊。
Snowflake為使用者提供了兩種建立資料庫的方法,第一種是使用使用者介面,第二種是應用SQL查詢。
使用Snowflake的UI操作資料庫
Snowflake中的所有資料都儲存在資料庫中。每個資料庫都包含一個或多個模式,這些模式是資料庫物件的邏輯分組,例如表和檢視。Snowflake不對資料庫的數量設定限制,您可以建立模式(在資料庫內)或物件(在模式內)。
建立資料庫
使用唯一的URL登入Snowflake帳戶。單擊頂部功能區中顯示的資料庫,如下面的螢幕截圖所示:

它將導航到下一個螢幕。單擊資料庫列表上方的建立按鈕,如下所示。
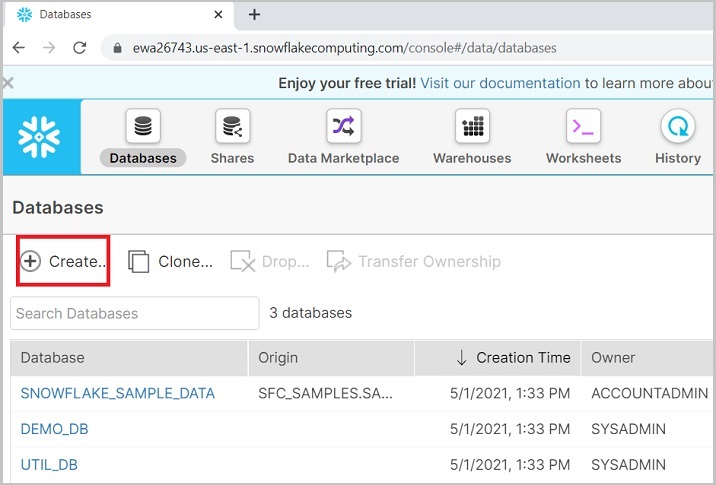
它將帶您進入建立資料庫對話方塊。輸入資料庫名稱和註釋,然後單擊完成按鈕。

建立資料庫後,使用者可以在列表中檢視它,如下面的螢幕截圖所示:

檢視倉庫
現在,要檢視所有已建立的資料庫,請單擊頂部功能區中顯示的資料庫。它將顯示資料庫的視圖面板,其中包含所有已建立的資料庫。
使用建立按鈕建立新的倉庫。使用者還可以透過選擇資料庫並單擊克隆來克隆資料庫,如下面的螢幕截圖所示:

將彈出一個克隆資料庫對話方塊,用於輸入一些資訊,例如名稱、源和註釋。輸入這些詳細資訊後,單擊完成按鈕,如下面的螢幕截圖所示:

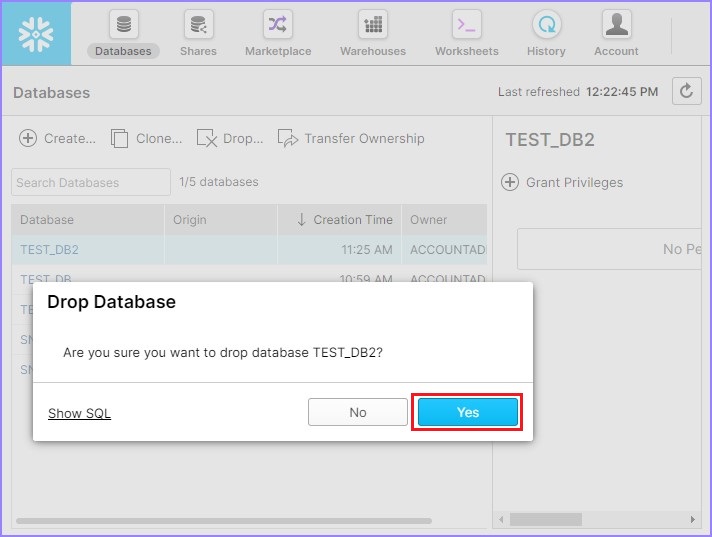
使用者可以看到建立了另一個數據庫,它將顯示在視圖面板中。使用者還可以透過選擇資料庫並單擊刪除按鈕來刪除資料庫,如下面的螢幕截圖所示:
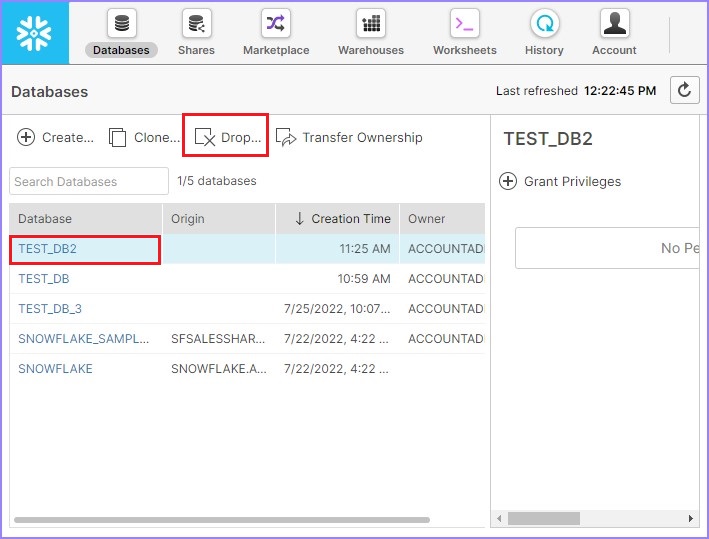
將彈出一個對話方塊以確認。單擊是以刪除,否則單擊否。
使用Snowflake的SQL介面操作資料庫
在這裡,我們將學習如何使用Snowflake的SQL介面建立和檢視資料庫。
建立資料庫
要建立資料庫,首先需要登入Snowflake並導航到工作表。使用者登入後,預設情況下會開啟工作表,否則單擊頂部功能區中顯示的工作表圖示。
編寫以下查詢以建立資料庫“TEST_DB_2”
CREATE DATABASE "TEST_DB_2"
現在單擊執行按鈕以執行查詢。結果將顯示在結果面板中,表明TEST_DB_2資料庫已成功建立。下面的螢幕截圖顯示了使用SQL處理的輸出:

檢視資料庫
要檢視所有列出的倉庫,使用者可以使用以下SQL。它會顯示所有列出倉庫的詳細資訊。
SHOW DATABASES
要克隆資料庫,使用者可以使用以下SQL,這裡“TEST_DB_3”是新資料庫的名稱,而DEMO_DB用於克隆它:
CREATE DATABASE TEST_DB_3 CLONE "DEMO_DB"
要刪除資料庫,請使用以下SQL:
DROP DATABASE "TEST_DB_3"
使用者可以在每次操作後執行SHOW DATABASE查詢以驗證操作是否已完成。
Snowflake - 模式
模式是資料庫物件的集合,例如表、檢視等。每個模式都屬於單個數據庫。“Database.Schema”是Snowflake中的名稱空間。執行任何操作時,都需要直接在查詢中提供名稱空間或在Snowflake的UI中進行設定。
在本章中,我們將討論如何建立資料庫以及檢視詳細資訊。Snowflake為使用者提供了兩種建立資料庫的方法,第一種是使用使用者介面,第二種是使用SQL查詢。
使用Snowflake的UI操作模式
讓我們看看如何使用GUI功能建立模式。
建立模式
使用唯一的URL登入Snowflake帳戶。現在單擊頂部功能區中顯示的資料庫圖示。它將導航到資料庫檢視螢幕。然後單擊要建立新模式的資料庫名稱,如下面的螢幕截圖所示:
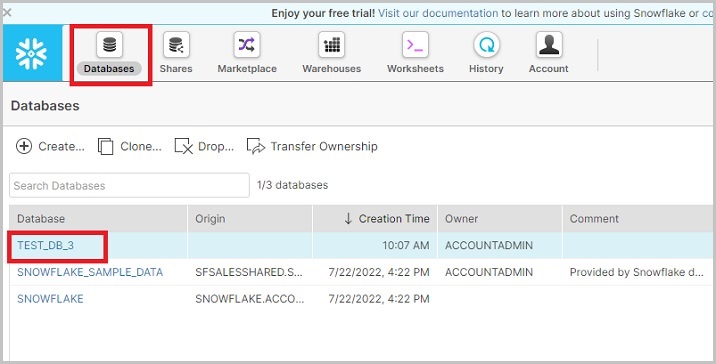
單擊資料庫名稱後,它將導航您到資料庫屬性頁面,您可以在其中檢視在資料庫內建立的表/檢視/模式等。現在單擊模式圖示,預設情況下,選擇“表”,如下面的螢幕截圖所示:
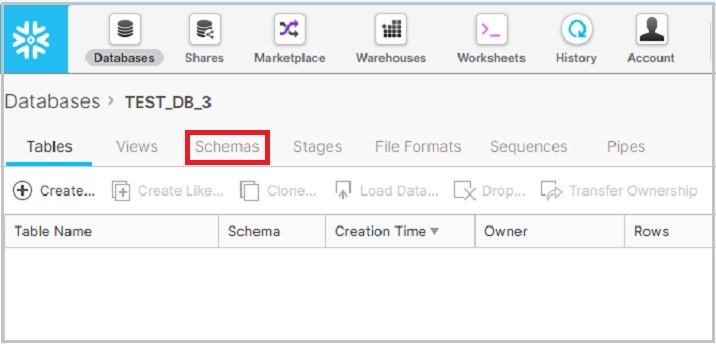
它顯示已為所選資料庫建立的模式列表。現在單擊模式列表上方的建立圖示以建立新模式,如下面的螢幕截圖所示:
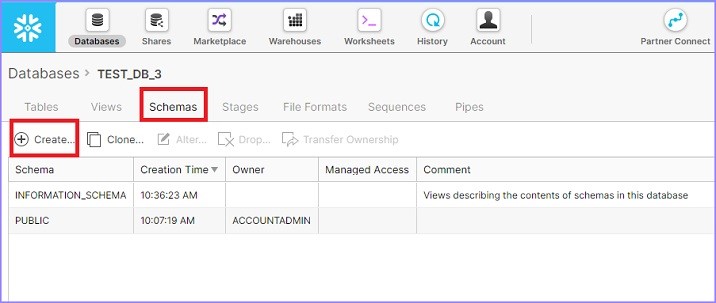
單擊建立圖示後,您將看到建立模式對話方塊。輸入模式名稱並單擊完成按鈕,如下面的螢幕截圖所示:
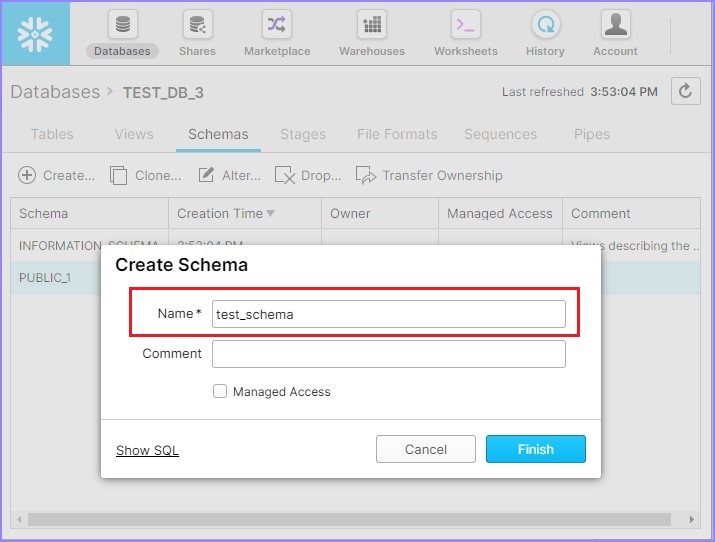
將建立一個新的模式,並與其他模式一起列出。
編輯/修改/更改模式
Snowflake提供了修改或更改模式名稱的功能。讓我們看看如何修改模式名稱。
單擊頂部功能區中顯示的資料庫圖示。它將顯示資料庫頁面詳細資訊。現在單擊資料庫的名稱。它將導航您到資料庫屬性檢視頁面。單擊模式以檢視可用模式的列表。選擇一個模式以更改其名稱,然後單擊更改圖示,如下所示。
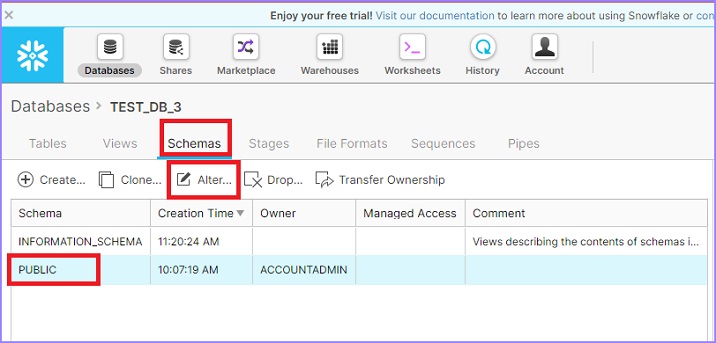
將彈出更改模式對話方塊。使用者可以修改名稱。單擊完成按鈕,如下所示。
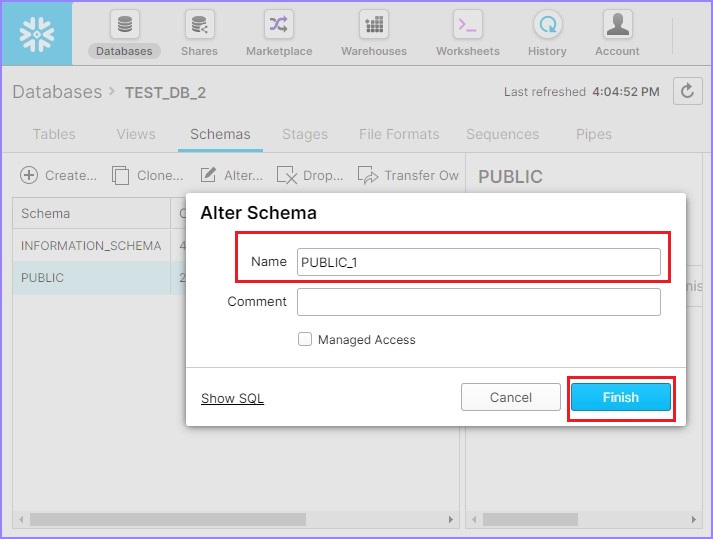
現在,它顯示更新的模式名稱。
檢視模式
模式位於資料庫內。要檢視模式,我們必須導航到資料庫。讓我們看看如何使用UI檢視模式。
單擊頂部功能區中顯示的資料庫圖示。它將顯示資料庫的檢視面板,其中包含所有已建立的資料庫。選擇一個數據庫並單擊其名稱以檢視其下的模式。
單擊模式列表上方的模式。它將顯示所有可用的模式。建立資料庫後,它將預設生成兩個模式 – 資訊模式和公共模式。資訊模式包含資料庫的所有元資料。
使用建立按鈕在同一資料庫下建立新的模式。使用者可以建立N個模式。
使用克隆按鈕建立現有模式的另一個副本。要執行此操作,請選擇一個模式並單擊克隆圖示。
下面的螢幕截圖演示了此功能:
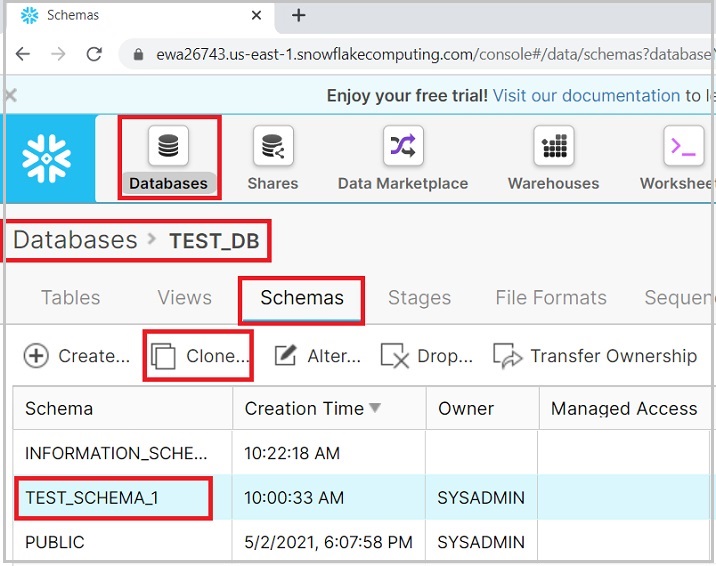
將彈出克隆模式對話方塊,輸入新模式的名稱並單擊完成按鈕。
下面的螢幕截圖顯示了克隆功能:
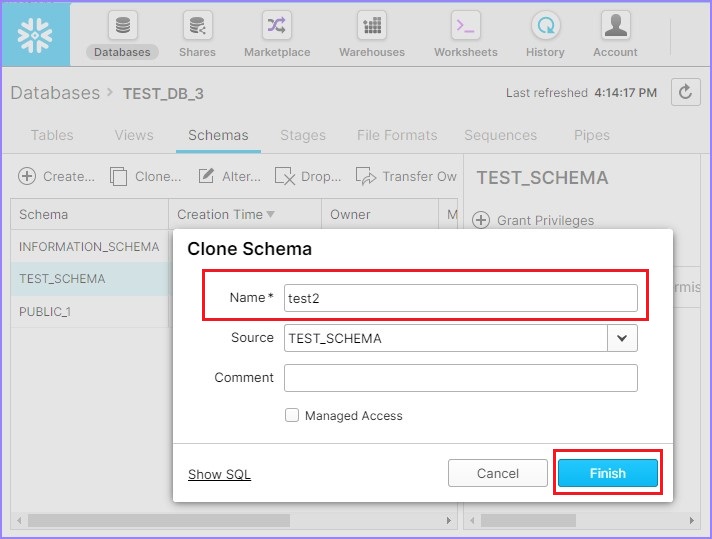
在視圖面板中,您可以看到克隆的模式。使用者還可以透過選擇模式並單擊刪除圖示來刪除模式,如下面的螢幕截圖所示:
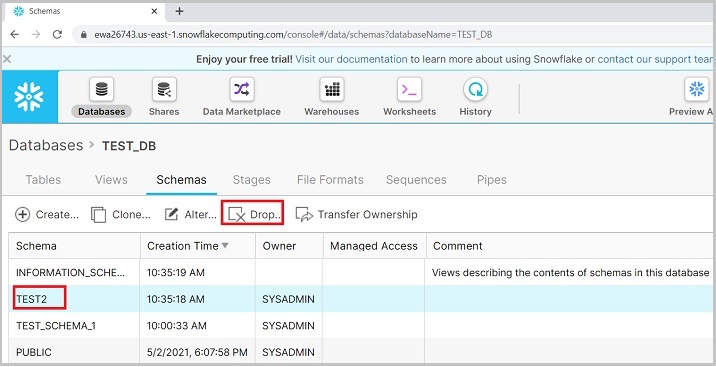
將彈出一個對話方塊以確認。單擊“是”以刪除,否則單擊“否”。
使用Snowflake的SQL介面操作模式
讓我們看看如何使用SQL介面功能建立模式。
建立模式
首先登入Snowflake並導航到工作表。使用者登入後,預設情況下會開啟工作表,否則單擊頂部功能區中顯示的工作表圖示。
編寫以下查詢以在資料庫TSET_DB下建立模式TEST_SCHEMA:
CREATE SCHEMA "TEST_DB"."TEST_SCHEMA"
單擊執行按鈕以執行查詢。結果將顯示在結果面板中,表明“模式TEST_SCHEMA”已成功建立。
編輯/修改/更改模式
要更改/修改模式名稱,請使用以下查詢並執行它:
ALTER SCHEMA "TEST_DB"."TEST_SCHEMA" RENAME TO "TEST_DB"."TEST_SCHEMA_RENAME"
使用者可以轉到視圖面板並驗證更新的名稱。
檢視模式
要檢視所有列出的模式,使用者可以使用以下SQL。它會顯示所有列出模式的詳細資訊。
SHOW SCHEMAS
要克隆模式,請使用以下SQL:
CREATE SCHEMA "TEST_DB"."TEST2" CLONE "TEST_DB"."TEST_SCHEMA_RENAME"
要刪除模式,請使用以下SQL:
DROP SCHEMA "TEST_DB"."TEST2"
使用者可以在每次操作後執行SHOW SCHEMAS查詢以驗證操作是否已完成。
Snowflake - 表和列
在資料庫中,建立模式,它們是表的邏輯分組。表包含列。表和列是資料庫中低級別且最重要的物件。在本章中,我們將討論如何在Snowflake中建立表和列。
Snowflake為使用者提供了兩種方法來建立表和相應的列,分別使用使用者介面和SQL查詢。不提供列的詳細資訊,使用者無法建立表。
使用Snowflake的UI操作表和列
讓我們看看如何使用Snowflake的UI操作表和列。
建立表和列
使用唯一的URL登入Snowflake帳戶。單擊頂部功能區中顯示的資料庫按鈕。它將導航到資料庫檢視螢幕。
單擊要在其中建立新表的資料庫名稱。它將導航到資料庫屬性頁面,您可以在其中檢視在資料庫內建立的表/檢視/模式等。
如果未選中,請單擊表,預設情況下,選擇“表”。您可以看到在同一資料庫中建立的表列表,否則為空白。

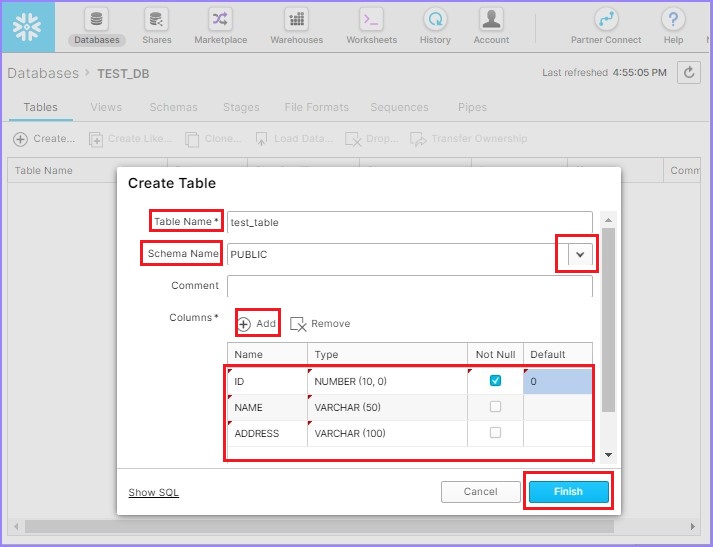
點選建立按鈕新增表格。將彈出建立表格對話方塊。輸入以下欄位:
表名 - test_table
模式名 - 從可用列表中選擇 – PUBLIC
列 - 點選新增按鈕,然後輸入名稱、型別、非空或任何預設值。
要新增多列,請繼續點選新增按鈕,然後輸入詳細資訊。現在,點選完成按鈕。
以下螢幕截圖顯示瞭如何新增表和列:
您可以在視圖面板中看到已建立的表。
查看錶和列
在本節中,我們將討論如何檢視表和列的詳細資訊,如何建立類似的表,如何克隆它以及如何刪除表。
點選頂部功能區上的資料庫。它將顯示資料庫的視圖面板,其中列出了所有資料庫。點選存在表的資料庫的名稱。例如,以下螢幕截圖中顯示的TEST_DB:
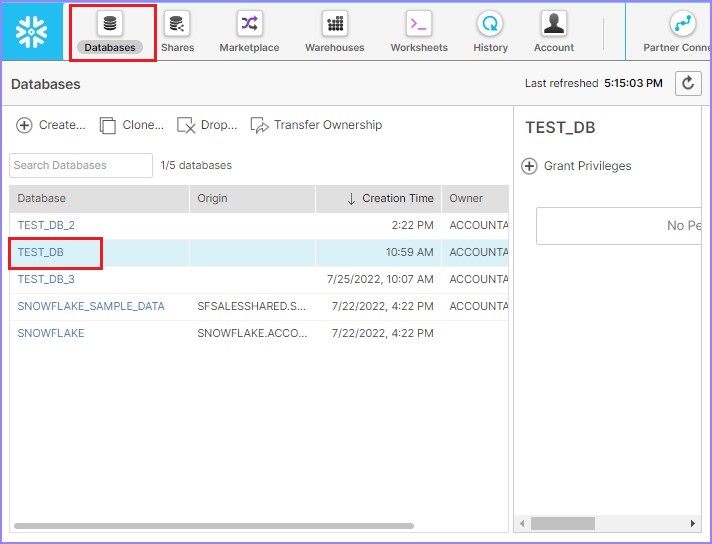
它將顯示資料庫中列出的所有表。使用建立按鈕建立新表。使用建立類似按鈕建立具有與現有表相同的元資料的表。
點選建立類似按鈕,將彈出建立類似表對話方塊。輸入新表名稱並點選完成按鈕。
以下螢幕截圖解釋了此功能:
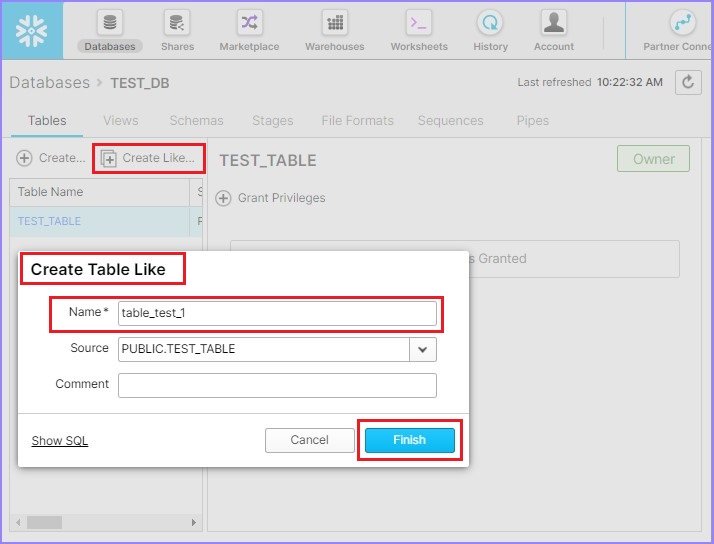
在視圖面板中,您可以看到新表。在本例中為 TABLE_TEST_1。
使用克隆按鈕建立現有表的另一個副本。要執行此操作,請選擇一個表並點選克隆按鈕。
克隆表對話方塊將彈出到螢幕上。輸入新表名稱並點選完成按鈕。
以下螢幕截圖顯示了克隆功能。
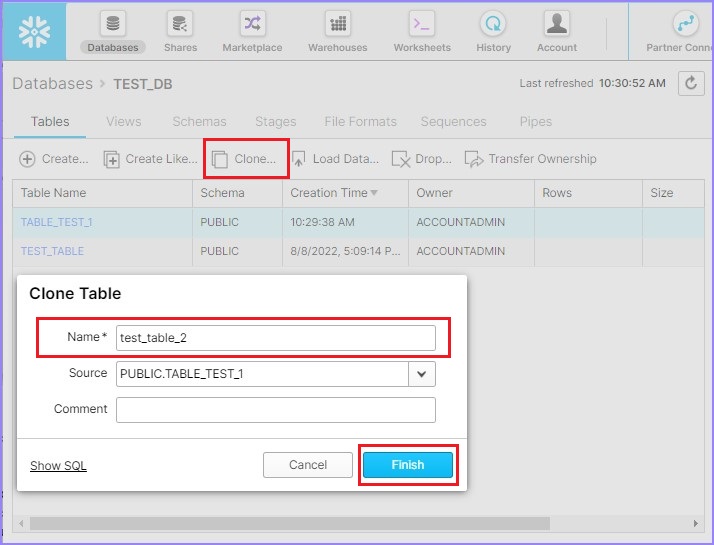
您可以在視圖面板中看到新表。
克隆和建立類似的區別在於“列資料”。克隆會從現有表中提取實際資料,而建立類似只會複製表的元資料。它不會複製表中存在的現有資料。
使用者也可以透過選擇一個表並點選刪除按鈕來刪除表。將彈出刪除表對話方塊以確認。點選“是”進行刪除,否則點選“否”。

使用 Snowflake 的 SQL 介面操作表和列
一旦使用者開始操作表和列,相應的資料庫和模式就成為重要因素。如果未提供資料庫和模式的詳細資訊,則查詢將無法成功執行。
有兩種方法可以設定資料庫和模式詳細資訊:一種使用 Snowflake 的 UI,另一種是在查詢中表名前提供資料庫名稱和模式名稱,如下例所示:
SELECT * FROM DATABSE_NAME.SCHEMA_NAME.TABLE_NAME.
在 UI 中,需要執行以下步驟:
點選“選擇模式”旁邊的右上角的下拉箭頭。將彈出一個對話方塊,使用者可以在其中提供以下詳細資訊:
- 角色 (ROLE)
- 倉庫 (Warehouse)
- 資料庫
- 模式 (Schema)
以下螢幕截圖描述了上述步驟:

現在,當用戶執行查詢時,無需在查詢中提供資料庫名稱和模式名稱,它將針對如上設定的資料庫和模式執行。如果需要切換到另一個數據庫/模式,可以頻繁更改它。
在 SQL 中設定資料庫、倉庫和模式
使用以下查詢為會話設定倉庫:
USE WAREHOUSE <WAREHOUSE_NAME>
使用以下查詢為會話設定資料庫:
USE DATABASE <DATABASE_NAME>
使用以下查詢為會話設定模式:
USE SCHEMA <SCHEMA_NAME>
建立表和列
登入 Snowflake 並導航到工作表。預設情況下,登入後會開啟工作表,否則點選頂部功能區上的工作表圖示。
使用以下查詢在資料庫 TEST_DB 和模式 TEST_SCHEMA_1 下建立表和列:
CREATE TABLE "TEST_DB"."TEST_SCHEMA_1"."TEST_TABLE"
("ID" NUMBER (10,0) NOT NULL DEFAULT 0, "NAME" VARCHAR (50), "ADDRESS" VARCHAR (100))
點選執行按鈕執行查詢。結果將顯示在結果面板中,顯示 TEST_TABLE 已成功建立。
查看錶和列
要檢視所有列出的表,可以使用以下 SQL。它顯示所有列出的模式的詳細資訊。
SHOW TABLES
要檢視列定義,請使用以下 SQL:
DESCRIBE TABLE TEST_DB.TEST_SCHEMA_1.TEST_TABLE
要克隆表,請使用以下 SQL:
CREATE TABLE "TEST_DB"."TEST_SCHEMA_1".TEST_TABLE_2 CLONE "TEST_DB"."TEST_SCHEMA_1"."TEST_TABL_1"
要建立類似的表,請使用以下查詢:
CREATE TABLE "TEST_DB"."TEST_SCHEMA_1".TEST_TABL_1 LIKE "TEST_DB"."TEST_SCHEMA_1"."TEST_TABLE"
要刪除表,請使用以下 SQL:
DROP TABLE "TEST_DB"."TEST_SCHEMA_1"."TEST_TABLE_2"
使用者可以在每次操作後執行 SHOW TABLES 查詢以驗證操作是否完成。
Snowflake - 從檔案載入資料
在資料庫中,建立模式,它們是表的邏輯分組。表包含列。表和列是資料庫中低級別且最重要的物件。現在,表和列最重要的功能是儲存資料。
在本章中,我們將討論如何在 Snowflake 中將資料儲存到表和列中。
Snowflake 為使用者提供了兩種方法,可以使用使用者介面和 SQL 查詢將資料儲存到表和相應的列中。
使用 Snowflake 的 UI 將資料載入到表和列中
在本節中,我們將討論使用 CSV、JSON、XML、Avro、ORC、Parquet 等檔案將資料載入到表及其相應列中應遵循的步驟。
此方法僅限於載入少量資料,最多 50 MB。
建立任何格式的示例檔案。建立檔案時,請確保檔案中的列數與表中的列數匹配,否則載入資料時操作將失敗。
在 TEST_DB.TEST_SCHEMA.TEST_TABLE 中,有三列:ID、NAME 和 ADDRESS。
以下示例資料在“data.csv”中建立:
| ID | NAME | ADDRESS |
|---|---|---|
| 1 | aa | abcd |
| 2 | ab | abcd |
| 3 | aa | abcd |
| 4 | ab | abcd |
| 5 | aa | abcd |
| 6 | ab | abcd |
| 7 | aa | abcd |
| 8 | ab | abcd |
| 9 | aa | abcd |
現在,點選頂部功能區上的資料庫圖示。點選要上傳資料的表名。它顯示列數和定義。
以下螢幕截圖顯示了載入資料的功能:

重新驗證與列相關的示例檔案。點選列名頂部的載入表按鈕。它將彈出載入資料對話方塊。在第一個螢幕上,選擇倉庫名稱並點選下一步按鈕。

在下一個螢幕上,透過點選選擇檔案從本地計算機選擇檔案。上傳檔案後,您可以看到檔名,如下面的螢幕截圖所示。點選下一步按鈕。

現在透過點選+ 號建立檔案格式,如下面的螢幕截圖所示:

它將彈出建立檔案格式對話方塊。輸入以下詳細資訊:
名稱 - 檔案格式的名稱。
模式名稱 - 建立的檔案格式只能在給定的模式中使用。
格式型別 - 檔案格式的名稱。
列分隔符 - 如果 CSV 檔案已分隔,請提供檔案分隔符。
行分隔符 - 如何識別新行。
要跳過的標題行 - 如果提供了標題,則為 1,否則為 0。
其他內容可以保持不變。輸入詳細資訊後,點選完成按鈕。
以下螢幕截圖顯示了上述詳細資訊:

從下拉列表中選擇檔案格式並點選載入,如下面的螢幕截圖所示:

載入結果後,您將獲得摘要,如下所示。點選確定按鈕。

要檢視資料,請執行查詢“SELECT * from TEST_TABLE”。在左側面板中,使用者還可以看到資料庫、模式和表詳細資訊。

使用 SQL 將資料載入到表和列中
要從本地檔案載入資料,您可以執行以下步驟:
使用 Snowflake 提供的外掛 SnowSQL 將檔案上傳到 Snowflake 的暫存區。要執行此操作,請轉到幫助並點選下載,如下所示:

點選 CLI 客戶端 (snowsql) 並點選Snowflake 資源庫,如下面的螢幕截圖所示:

使用者可以移動到 bootstrap → 1.2 → windows_x86_64 → 點選下載最新版本。
以下螢幕截圖顯示了上述步驟:
現在,安裝下載的外掛。安裝後,在您的系統中開啟 CMD。執行以下命令以檢查連線:
snowsql -a <account_name> -u <username>
它將詢問密碼。輸入您的 Snowflake 密碼並按 ENTER。您將看到連線成功。現在使用命令列:
<username>#<warehouse_name>@<db_name>.<schema_name>
現在使用以下命令將檔案上傳到 Snowflake 的暫存區:
PUT file://C:/Users/*******/Documents/data.csv @csvstage;
不要忘記在末尾加上“分號”,否則它將永遠執行。
檔案上傳後,使用者可以在工作表中執行以下命令:
COPY INTO "TEST_DB"."TEST_SCHEMA_1"."TEST_TABLE" FROM @/csvstage ON_ERROR = 'ABORT_STATEMENT' PURGE = TRUE
資料將載入到表中。
Snowflake - 有用的示例查詢
在本章中,我們將介紹 Snowflake 中一些有用的示例查詢及其輸出。
使用以下查詢在 Select 語句中提取有限的資料:
"SELECT * from <table_name>" Limit 10
此查詢將僅顯示前 10 行。
使用以下查詢顯示過去 10 天的使用情況。
SELECT * FROM TABLE (INFORMATION_SCHEMA.DATABASE_STORAGE_USAGE_HISTORY
(DATEADD('days', -10, CURRENT_DATE()), CURRENT_DATE()))
使用以下查詢檢查 Snowflake 中建立的暫存區和檔案格式:
SHOW STAGES SHOW FILE FORMATS
要檢查變數,請按順序執行以下查詢:
SELECT * FROM snowflake_sample_data.tpch_sf1.region JOIN snowflake_sample_data.tpch_sf1.nation ON r_regionkey = n_regionkey;
select * from table(result_scan(last_query_id()));
SELECT * FROM snowflake_sample_data.tpch_sf1.region JOIN snowflake_sample_data.tpch_sf1.nation ON r_regionkey = n_regionkey;
SET q1 = LAST_QUERY_ID();
select $q1;
SELECT * FROM TABLE(result_scan($q1)) ;
SHOW VARIABLES;
使用以下查詢查詢資料庫的登入歷史記錄:
select * from table(test_db.information_schema.login_history());
結果提供時間戳、使用者名稱、登入方式(使用密碼或 SSO)、登入期間的錯誤等。
使用以下命令檢視所有列:
SHOW COLUMNS SHOW COLUMNS in table <table_name>
使用以下命令顯示 Snowflake 提供的所有引數:
SHOW PARAMETERS;
以下是一些僅執行查詢“SHOW PARAMETERS;”即可檢視的詳細資訊:
| 序號 | 鍵和說明 |
|---|---|
| 1 | ABORT_DETACHED_QUERY 如果為 true,則 Snowflake 將在檢測到客戶端消失時自動中止查詢。 |
| 2 | AUTOCOMMIT auto-commit 屬性決定語句是否應該隱式地包含在事務中。如果 auto-commit 設定為 true,則需要事務的語句將隱式地包含在事務中執行。如果 auto-commit 為 false,則需要顯式提交或回滾才能關閉事務。預設的 auto-commit 值為 true。 |
| 3 | AUTOCOMMIT_API_SUPPORTED 此客戶端是否啟用了 auto-commit 功能。此引數僅供 Snowflake 使用。 |
| 4 | BINARY_INPUT_FORMAT 二進位制的輸入格式 |
| 5 | BINARY_OUTPUT_FORMAT 二進位制的顯示格式 |
| 6 | CLIENT_ENABLE_CONSERVATIVE_MEMORY_USAGE 啟用 JDBC 的保守記憶體使用。 |
| 7 | CLIENT_ENABLE_DEFAULT_OVERWRITE_IN_PUT 如果在 sql 命令中未指定 overwrite 選項,則將 overwrite 選項的預設值設定為 true。 |
| 8 | CLIENT_ENABLE_LOG_INFO_STATEMENT_PARAMETERS 啟用準備好的語句繫結引數的資訊級別日誌記錄。 |
| 9 | CLIENT_MEMORY_LIMIT 以 MB 為單位限制客戶端使用的記憶體量。 |
| 10 | CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX 對於客戶端元資料請求 (getTables()),如果設定為 true,則使用會話目錄和模式。 |
| 11 | CLIENT_METADATA_USE_SESSION_DATABASE 對於客戶端元資料請求 (getTables()),如果設定為 true(與 CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX 結合使用),則使用會話目錄,但使用多個模式。 |
| 12 | CLIENT_PREFETCH_THREADS 控制執行緒的客戶引數,0=自動。 |
| 13 | CLIENT_RESULT_CHUNK_SIZE 設定客戶端側最大結果塊大小(以 MB 為單位)。 |
| 14 | CLIENT_RESULT_COLUMN_CASE_INSENSITIVE 客戶端中的列名搜尋不區分大小寫。 |
| 15 | CLIENT_SESSION_CLONE 如果為 true,客戶端將從帳戶和使用者的先前使用令牌克隆一個新會話。 |
| 16 | CLIENT_SESSION_KEEP_ALIVE 如果為 true,客戶端會話將不會自動過期。 |
| 17 | CLIENT_SESSION_KEEP_ALIVE_HEARTBEAT_FREQUENCY CLIENT_SESSION_KEEP_ALIVE 的心跳頻率(以秒為單位)。 |
| 18 | CLIENT_TIMESTAMP_TYPE_MAPPING 如果使用繫結 API 將變數繫結到 TIMESTAMP 資料型別,則確定它應對映到的 TIMESTAMP* 型別。 |
| 19 | C_API_QUERY_RESULT_FORMAT 用於將查詢結果序列化後傳送回 C API 的格式 |
| 20 | DATE_INPUT_FORMAT 日期輸入格式 |
| 21 | DATE_OUTPUT_FORMAT 日期顯示格式 |
| 22 | ENABLE_UNLOAD_PHYSICAL_TYPE_OPTIMIZATION 啟用Snowflake中使用的物理型別最佳化以影響Parquet輸出 |
| 23 | ERROR_ON_NONDETERMINISTIC_MERGE 嘗試合併更新連線多行的行時引發錯誤 |
| 24 | ERROR_ON_NONDETERMINISTIC_UPDATE 嘗試更新連線多行的行時引發錯誤 |
| 25 | GEOGRAPHY_OUTPUT_FORMAT 地理位置顯示格式:GeoJSON、WKT 或 WKB(不區分大小寫) |
| 26 | GO_QUERY_RESULT_FORMAT 用於將查詢結果序列化後傳送回 Golang 驅動程式的格式 |
| 27 | JDBC_FORMAT_DATE_WITH_TIMEZONE 如果為 true,則 ResultSet#getDate(int columnIndex, Calendar cal) 和 getDate(String columnName, Calendar cal) 將使用 Calendar 的輸出顯示日期。 |
| 28 | JDBC_QUERY_RESULT_FORMAT 用於將查詢結果序列化後傳送回 JDBC 的格式 |
| 29 | JDBC_TREAT_DECIMAL_AS_INT 當 scale 為 0 時,是否在 JDBC 中將 Decimal 視為 Int |
| 30 | JDBC_TREAT_TIMESTAMP_NTZ_AS_UTC 如果為 true,則 Timestamp_NTZ 值始終以 UTC 時區儲存 |
| 31 | JDBC_USE_SESSION_TIMEZONE 如果為 true,JDBC 驅動程式將不顯示 JVM 和會話之間的時區偏移量。 |
| 32 | JSON_INDENT JSON 輸出的縮排寬度(0 表示緊湊) |
| 33 | JS_TREAT_INTEGER_AS_BIGINT 如果為 true,則 nodejs 客戶端會將所有整數列轉換為 bigint 型別 |
| 34 | LANGUAGE UI、GS、查詢協調和 XP 將使用的所選語言。輸入語言應採用 BCP-47 格式,即短劃線格式。有關詳細資訊,請參閱 LocaleUtil.java。 |
| 35 | LOCK_TIMEOUT 嘗試鎖定資源時等待的秒數,在此之後超時並中止語句。值為 0 將關閉鎖定等待,即 |
| 36 | MULTI_STATEMENT_COUNT 提交的查詢文字中包含的語句數。此引數由使用者提交以避免 SQL 注入。值為 1 表示一個語句,值 > 1 表示可以執行 N 個語句,如果不等於該值,則會引發異常。值為 0 表示可以執行任意數量的語句。 |
| 37 | ODBC_QUERY_RESULT_FORMAT 用於將查詢結果序列化後傳送回 ODBC 的格式 |
| 38 | ODBC_SCHEMA_CACHING 如果為 true,則啟用 ODBC 中的模式快取。這可以加快 SQL Columns API 呼叫的速度。 |
| 39 | ODBC_USE_CUSTOM_SQL_DATA_TYPES ODBC 在結果集元資料中返回 Snowflake 特定的 SQL 資料型別 |
| 40 | PYTHON_CONNECTOR_QUERY_RESULT_FORMAT 用於將查詢結果序列化後傳送回 Python 聯結器的格式 |
| 41 | QA_TEST_NAME 如果在 QA 模式下執行,則為測試名稱。用作共享池的區分符 |
| 42 | QUERY_RESULT_FORMAT 用於將查詢結果序列化後傳送回客戶端的格式 |
| 43 | QUERY_TAG 用於標記會話執行的語句的字串(最多 2000 個字元) |
| 44 | QUOTED_IDENTIFIERS_IGNORE_CASE 如果為 true,則忽略帶引號的識別符號的大小寫 |
| 45 | ROWS_PER_RESULTSET 結果集中的最大行數 |
| 46 | SEARCH_PATH 未限定物件引用的搜尋路徑。 |
| 47 | SHOW_EXTERNAL_TABLE_KIND_AS_TABLE 更改 SHOW TABLES 和 SHOW OBJECTS 顯示外部表 KIND 資訊的方式。如果為 true,則外部表的 KIND 列顯示為 TABLE,否則顯示為 EXTERNAL_TABLE。 |
| 48 | SIMULATED_DATA_SHARING_CONSUMER 資料共享檢視將返回在指定的使用者帳戶中執行時相同的行。 |
| 49 | SNOWPARK_LAZY_ANALYSIS 為 Snowpark 啟用延遲結果模式分析 |
| 50 | STATEMENT_QUEUED_TIMEOUT_IN_SECONDS 排隊語句的超時時間(秒):如果語句在倉庫中排隊的時間超過此時間,則會自動取消語句;如果設定為零,則停用。 |
| 51 | STATEMENT_TIMEOUT_IN_SECONDS 語句的超時時間(秒):如果語句執行時間過長,則會自動取消語句;如果設定為零,則強制使用最大值 (604800)。 |
| 52 | STRICT_JSON_OUTPUT JSON 輸出嚴格符合規範 |
| 53 | TIMESTAMP_DAY_IS_ALWAYS_24H 如果設定,則對日期的算術運算始終使用每天 24 小時,可能不會保留時間(由於夏令時變化) |
| 54 | TIMESTAMP_INPUT_FORMAT 時間戳輸入格式 |
| 55 | TIMESTAMP_LTZ_OUTPUT_FORMAT TIMESTAMP_LTZ 值的顯示格式。如果為空,則使用 TIMESTAMP_OUTPUT_FORMAT。 |
| 56 | TIMESTAMP_NTZ_OUTPUT_FORMAT TIMESTAMP_NTZ 值的顯示格式。如果為空,則使用 TIMESTAMP_OUTPUT_FORMAT。 |
| 57 | TIMESTAMP_OUTPUT_FORMAT 所有時間戳型別的預設顯示格式。 |
| 58 | TIMESTAMP_TYPE_MAPPING 如果使用 TIMESTAMP 型別,則應將其對映到的特定 TIMESTAMP* 型別 |
| 59 | TIMESTAMP_TZ_OUTPUT_FORMAT TIMESTAMP_TZ 值的顯示格式。如果為空,則使用 TIMESTAMP_OUTPUT_FORMAT。 |
| 60 | TIMEZONE 時區 |
| 61 | TIME_INPUT_FORMAT 時間輸入格式 |
| 62 | TIME_OUTPUT_FORMAT 時間顯示格式 |
| 63 | TRANSACTION_ABORT_ON_ERROR 如果此引數為 true,並且在非自動提交事務中發出的語句返回錯誤,則非自動提交事務將被中止。在此事務內發出的所有語句都將失敗,直到執行 commit 或 rollback 語句以關閉該事務為止。 |
| 64 | TRANSACTION_DEFAULT_ISOLATION_LEVEL 啟動事務時的預設隔離級別,在未指定隔離級別時 |
| 65 | TWO_DIGIT_CENTURY_START 對於兩位數日期,定義一個世紀起始年份。 |
| 66 | UI_QUERY_RESULT_FORMAT 用於將查詢結果序列化後傳送回 Python 聯結器的格式 |
| 67 | UNSUPPORTED_DDL_ACTION 遇到不受支援的 DDL 語句時要採取的操作 |
| 68 | USE_CACHED_RESULT 如果啟用,則只要原始結果未過期,就可以在相同查詢的連續呼叫之間重用查詢結果 |
| 69 | WEEK_OF_YEAR_POLICY 定義將周分配給年份的策略 |
| 70 | WEEK_START 定義一週的第一天 |
Snowflake - 監控使用情況和儲存
Snowflake 根據**儲存**、**使用情況**和**雲服務**向客戶收費。監控儲存資料和使用情況變得非常重要。
單個使用者可以檢視長時間執行的查詢的歷史記錄,而帳戶管理員可以檢視每個使用者的賬單、每個使用者或按日期的服務消耗和使用情況等。
檢查儲存
使用者可以檢查各個表有多少行以及資料大小。如果使用者有權訪問表,則只需選擇一個表即可檢視這些詳細資訊。在左下側面板中,使用者可以看到**表名**,然後是行數和資料儲存大小。之後,它顯示錶的列定義。
以下螢幕截圖顯示瞭如何檢查儲存詳細資訊:

歷史記錄
在本節中,使用者可以檢查他們在 Snowflake 中的活動,例如他們使用哪些查詢、查詢的當前狀態、執行查詢花費了多少時間等。
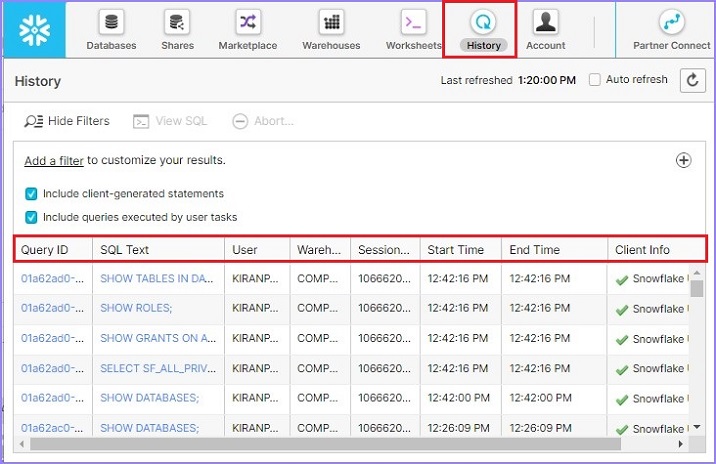
要檢視歷史記錄,請單擊頂部功能區中的**歷史記錄**選項卡。它將顯示使用者歷史記錄。如果使用者已以帳戶管理員身份訪問或登入,他們可以根據單個使用者過濾歷史記錄。它顯示以下資訊:
查詢狀態為執行中/失敗/成功
**查詢 ID** - 查詢 ID 對所有執行的查詢都是唯一的
**SQL 文字** - 它顯示使用者執行的查詢。
**使用者** - 執行該操作的使用者。
**倉庫** - 用於執行查詢的倉庫。
**叢集** - 如果是多叢集,則為使用的叢集數量
**大小** - 倉庫大小
**會話 ID** - 每個工作表都有唯一的會話 ID。
**開始時間** - 查詢開始執行的時間
**結束時間** - 查詢完成執行的時間
**總持續時間** - 查詢執行的總持續時間。
**掃描的位元組數** - 它顯示掃描了多少資料才能獲得結果
**行數** - 掃描的行數
以下螢幕截圖顯示歷史記錄檢視:
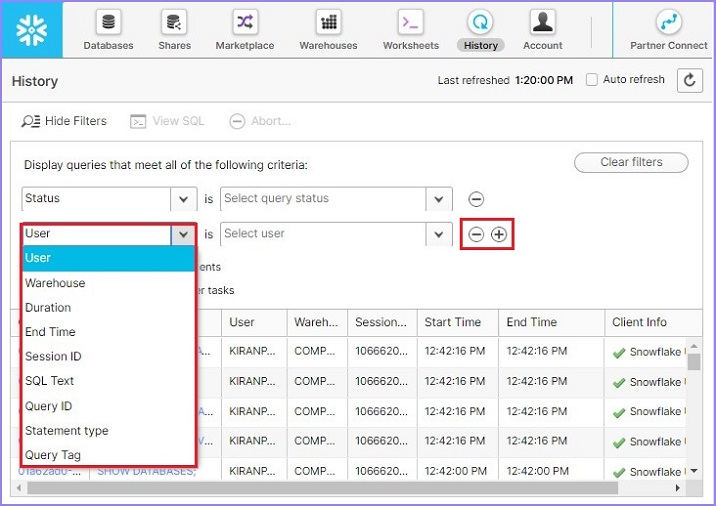
在過濾器中,使用者可以透過單擊**“+”**號來放置一個或多個過濾器,並使用**“-”**號來刪除過濾器。以下螢幕截圖顯示可用過濾器的列表:
監控
要執行帳戶級別監控,使用者必須以 ACCOUNTADMIN 角色登入。
出於監控目的,請以**帳戶管理員**身份登入。單擊頂部功能區中的**帳戶連結**。預設情況下,它將顯示帳戶使用情況。使用者可以看到建立的倉庫數量、使用了多少信用額度、平均儲存使用量(這意味著在執行查詢期間我們掃描了多少資料與總體儲存量相比),以及傳輸了多少資料。
它還顯示每個倉庫使用的信用額度,並顯示一個餅圖。在右側,使用者可以看到表格形式的**日期**與**使用的信用額度**。使用者甚至可以透過單擊“下載資料”來下載資料。可以透過更改右上角的月份來檢視月度使用情況。
以下螢幕截圖顯示“使用情況”選項卡資訊:

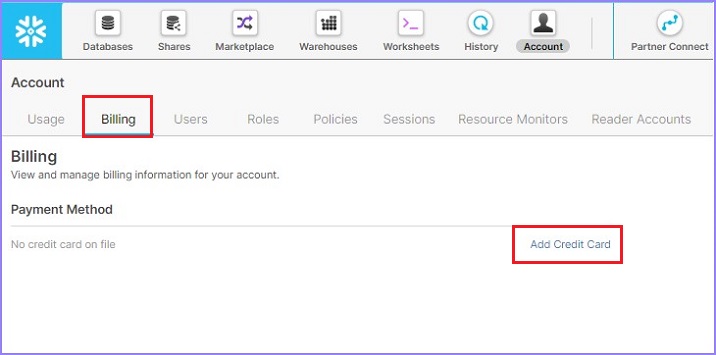
單擊下一個選項卡**賬單**。在這裡,使用者可以看到之前新增的任何付款方式。使用者還可以透過單擊“新增信用卡”連結,然後提供信用卡號、CVV、有效期、姓名等常規詳細資訊來新增新的付款方式。
以下螢幕截圖顯示賬單部分:
單擊下一個選項卡**使用者**。它顯示帳戶中所有使用者的名稱。
透過選擇**使用者**,帳戶管理員可以使用**重置密碼**、**停用使用者**和**刪除**按鈕分別重置使用者密碼、停用使用者或刪除使用者。透過單擊使用者列表頂部的“建立”按鈕,帳戶管理員可以建立新使用者。
以下螢幕截圖顯示“使用者”選項卡的功能:

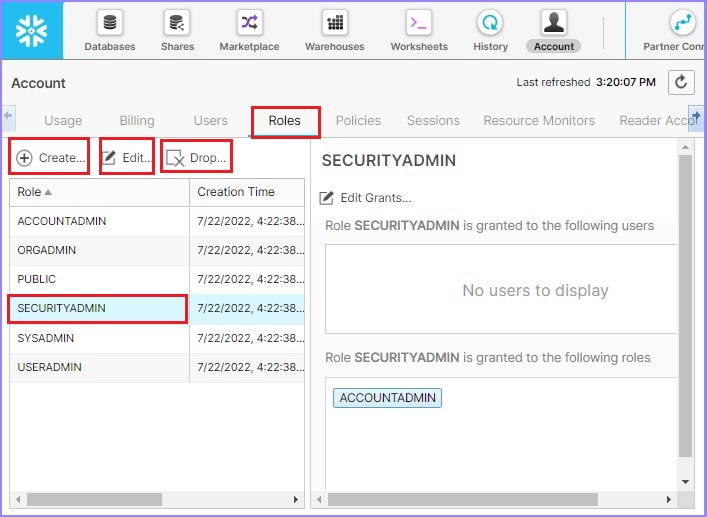
現在單擊下一個選項卡**角色**。可以透過單擊角色列表頂部的**建立**按鈕在此處建立新角色。透過選擇角色,它還提供啟用或刪除角色的選項,分別透過單擊**編輯**按鈕和**刪除**按鈕。
以下螢幕截圖顯示**角色**選項卡的功能:
除此之外,還有策略、會話、資源監視器和閱讀器帳戶選項卡。帳戶管理員可以建立/編輯/刪除策略,建立/編輯/刪除會話,建立/編輯/刪除資源監視器,以及類似於閱讀器帳戶的操作。
Snowflake - 快取
Snowflake 具有獨特的快取功能。它基於此快取提供快速的結果和較少的資料掃描。它甚至可以幫助客戶降低賬單。
Snowflake中主要有三種快取型別。
- 元資料快取
- 查詢結果快取
- 資料快取
預設情況下,所有Snowflake會話都啟用快取。但使用者可以根據需要停用它。但是,使用者只能停用**查詢結果快取**,無法停用**元資料快取**和**資料快取**。
本章將討論不同型別的快取以及Snowflake如何決定快取策略。
元資料快取
元資料儲存在雲服務層,因此快取也在同一層。這些元資料快取對所有人始終啟用。
它主要包含以下詳細資訊:
表中的行數。
列的最小/最大值
列中不同值的個數
列中NULL值的個數
不同表版本的詳細資訊
物理檔案的引用
SQL最佳化器主要利用這些資訊來更快地執行查詢。一些查詢可以直接透過元資料本身回答。對於此類查詢,不需要虛擬倉庫,但可能需要支付雲服務費用。
此類查詢例如:
**所有SHOW**命令
**MIN,MAX**,但僅限於列的整數/數字/日期資料型別。
COUNT
讓我們執行一個查詢來了解元資料快取的工作原理,使用者可以進行驗證。
登入Snowflake並轉到工作表。透過執行以下查詢來掛起倉庫:
ALTER WAREHOUSE COMPUTE_WH SUSPEND;
現在,按順序執行以下查詢:
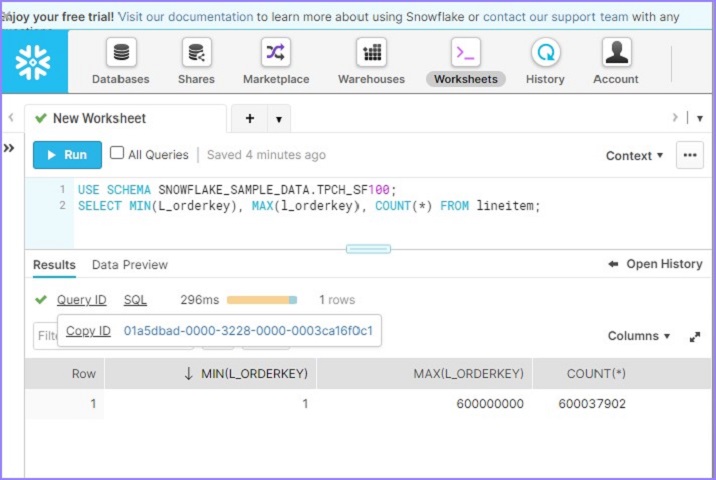
USE SCHEMA SNOWFLAKE_SAMPLE_DATA.TPCH_SF100; SELECT MIN(L_orderkey), MAX(l_orderkey), COUNT(*) FROM lineitem;
使用者將能夠在不到100毫秒內看到結果,如下面的螢幕截圖所示。單擊查詢ID,將顯示查詢ID的連結。然後單擊如下所示的連結:
預設情況下,它會開啟顯示SQL的詳細資訊頁面。單擊“**概要(Profile)**”選項卡。它顯示100%基於元資料的結果。這意味著它無需任何計算倉庫即可執行結果並基於元資料快取獲取詳細資訊。
下面的螢幕截圖顯示了上述步驟:

查詢結果快取
查詢結果由雲服務層儲存和管理。如果多次執行相同的查詢,這非常有用,但前提是在多次執行查詢的時間段內,底層資料或基表沒有更改。此快取具有一個獨特的功能,即同一帳戶中的其他使用者也可以使用。
例如,如果使用者1第一次執行查詢,結果將儲存在快取中。當用戶2也嘗試執行相同的查詢(假設基表和資料沒有更改)時,它將從查詢結果快取中獲取結果。
快取的結果可用24小時。但是,每次重新執行相同的查詢時,24小時的計數器都會重置。例如,如果一個查詢在上午10點執行,它的快取將保留到第二天上午10點。如果在同一天下午2點重新執行相同的查詢,那麼快取將保留到第二天下午2點。
要使用查詢結果快取,需要滿足一些條件:
必須重新執行完全相同的**SQL**查詢。
SQL中不應包含任何隨機函式。
使用者必須擁有使用它的許可權。
執行查詢時應啟用查詢結果快取。預設情況下啟用,除非另行設定。
查詢結果快取的一些適用場景:
需要大量計算的查詢,例如聚合函式和半結構化資料分析。
非常頻繁執行的查詢。
複雜的查詢。
重構其他查詢的輸出,例如“USE TABLE function RESULT_SCAN(<query_id>)”。
讓我們執行一個查詢來了解查詢結果快取的工作原理,使用者可以進行驗證。
登入Snowflake並轉到工作表。透過執行以下查詢來恢復倉庫:
ALTER WAREHOUSE COMPUTE_WH Resume;
現在,按順序執行以下查詢:
USE SCHEMA SNOWFLAKE_SAMPLE_DATA.TPCH_SF100;
SELECT l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (l_discount)) AS sum_disc_price,
SUM(l_extendedprice * (l_discount) * (1+l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM lineitem
WHERE l_shipdate <= dateadd(day, 90, to_date('1998-12-01'))
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
單擊查詢ID,將顯示查詢ID的連結。然後單擊與前面示例(元資料快取)中相同的連結。檢視查詢概要,它將顯示如下:

它顯示掃描了80.5%的資料,因此沒有涉及快取。透過執行以下查詢來掛起倉庫:
ALTER WAREHOUSE COMPUTE_WH Suspend;
再次執行我們之前執行的相同查詢:
USE SCHEMA SNOWFLAKE_SAMPLE_DATA.TPCH_SF100;
SELECT l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (l_discount)) AS sum_disc_price,
SUM(l_extendedprice * (l_discount) * (1+l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM lineitem
WHERE l_shipdate <= dateadd(day, 90, to_date('1998-12-01'))
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
單擊**查詢**ID,將顯示查詢ID的連結。然後單擊與前面示例(元資料快取)中相同的連結。檢視查詢概要,它將顯示如下:
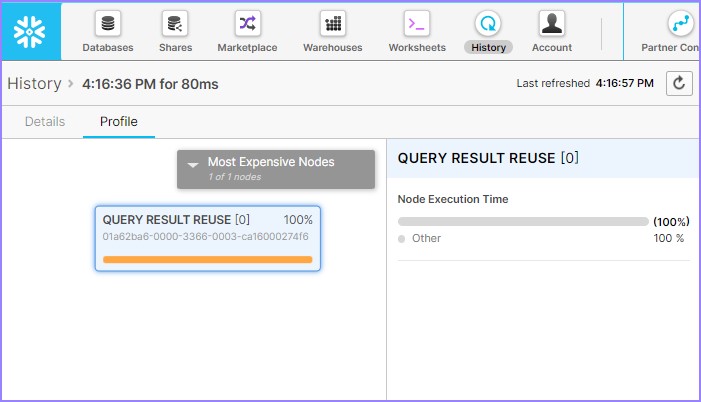
它顯示了查詢結果重用。這意味著它無需倉庫即可成功執行查詢,並且整個結果集都來自查詢結果快取。
資料快取
資料快取發生在儲存層。它快取來自查詢的儲存檔案頭和列資料。它儲存所有查詢的資料,但並非完全作為查詢結果。它將這些資料儲存到虛擬倉庫的SSD中。當執行類似的查詢時,Snowflake會盡可能多地使用資料快取。使用者無法停用資料快取。資料快取適用於在同一虛擬倉庫上執行的所有查詢。這意味著資料快取不像元資料和查詢結果快取那樣,無需虛擬倉庫即可工作。
當查詢執行時,它的頭和列資料將儲存在虛擬倉庫的SSD上。虛擬倉庫首先讀取本地可用資料(虛擬倉庫的SSD),然後從遠端雲端儲存(實際的Snowflake儲存系統)讀取剩餘資料。當快取儲存空間已滿時,資料將根據最少使用原則被丟棄。
讓我們執行一個查詢來了解查詢結果快取的工作原理,使用者可以進行驗證。
登入Snowflake並轉到**工作表**。透過執行以下查詢來恢復倉庫:
ALTER WAREHOUSE COMPUTE_WH Resume;
使用以下SQL停用Query_Result快取:
ALTER SESSION SET USE_CACHED_RESULT = FALSE;
執行以下查詢:
SELECT l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (l_discount)) AS sum_disc_price, SUM(l_extendedprice *
(l_discount) * (1+l_tax))
AS sum_charge, AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) as count_order
FROM lineitem
WHERE l_shipdate <= dateadd(day, 90, to_date('1998-12-01'))
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
單擊**查詢**ID,將顯示查詢ID的連結。然後單擊與前面示例(元資料快取)中相同的連結。檢視查詢概要,它將顯示如下:

根據查詢概要,掃描了88.6%的資料。如果您注意到右側,本地磁碟IO = 2%,而遠端磁碟IO = 80%。這意味著幾乎沒有或根本沒有使用資料快取。現在,執行以下查詢。WHERE子句略有不同:
SELECT l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (l_discount)) AS sum_disc_price, SUM(l_extendedprice *
(l_discount) * (1+l_tax))
AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) as count_order
FROM lineitem
WHERE l_shipdate <= dateadd(day, 90, to_date('1998-12-01'))
and l_extendedprice <= 20000
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
單擊**查詢**ID,將顯示查詢ID的連結。然後單擊與前面示例(元資料快取)中相同的連結。檢視查詢概要,它將顯示如下:
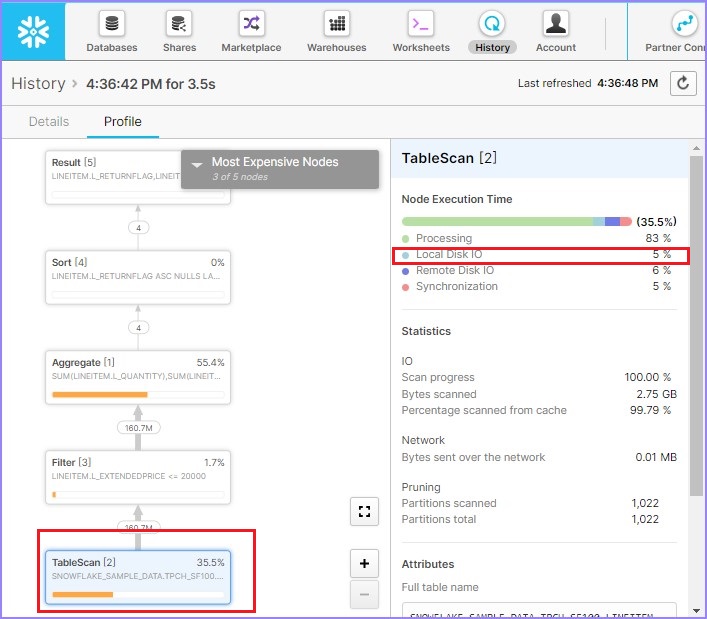
根據查詢概要,掃描了58.9%的資料,這比第一次要低得多。如果您注意到右側,本地磁碟IO增加到4%,而遠端磁碟IO = 0%。這意味著幾乎沒有或根本沒有使用遠端資料。
將資料從 Snowflake 解除安裝到本地
在資料庫中,建立模式,它是表的邏輯分組。表包含列。表和列是資料庫中低級別但最重要的物件。現在,表和列最重要的功能是儲存資料。
本章將討論如何將Snowflake表和列中的資料解除安裝到本地檔案。Snowflake為使用者提供了兩種將資料解除安裝到本地檔案的方法:使用使用者介面和使用SQL查詢。
使用Snowflake的UI將資料解除安裝到本地檔案
在本節中,我們將討論將資料作為csv或tsv解除安裝到本地檔案應遵循的步驟。UI有一個限制,使用者不能直接將所有資料儲存到本地目錄。
要從UI儲存資料,使用者需要先執行查詢,然後才能將結果儲存為“.csv”或“.tsv”檔案。但是,使用SQL和SNOWSQL,可以將資料直接儲存到本地驅動器,而無需執行查詢。稍後的過程將在下一節中討論。
讓我們討論使用者介面方法。
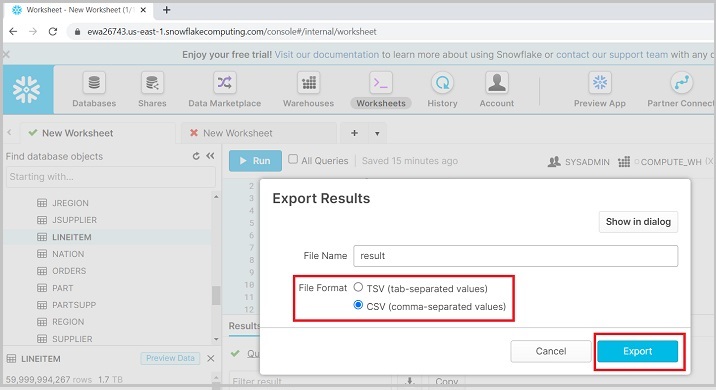
登入Snowflake。執行基於需要儲存到本地目錄的資料的查詢。查詢成功執行後,單擊如下螢幕截圖所示的下載圖示:
它會彈出一個對話方塊,如下面的螢幕截圖所示,並要求選擇**檔案格式**為CSV或TSV。選擇後,單擊**匯出**。它將下載結果檔案。
下面的螢幕截圖顯示了資料解除安裝功能:
使用SQL解除安裝表和列中的資料
要將資料解除安裝到本地檔案,首先選擇需要解除安裝資料的列。接下來,執行以下查詢:
USE SCHEMA "TEST_DB"."TEST_SCHEMA_1";
COPY INTO @%TEST_TABLE FROM (SELECT * FROM TEST_TABLE) FILE_FORMAT=(FORMAT_NAME=TEST_DB.TEST_SCHEMA_1.CSV);
注意,@%用於Snowflake建立的預設階段。如果您需要使用您自己的內部階段,只需傳入@<stage_name>。
查詢成功執行後,表示資料已複製到內部階段。Snowflake預設情況下為所有表建立一個表階段,例如@%<table_name>。
現在執行以下查詢以確認檔案是否儲存在內部階段:
LIST @%TEST_TABLE;
它顯示儲存在內部階段的所有檔案,即使是載入資料時不成功的檔案。
現在,要將檔案匯入本地目錄,我們需要使用**snowsql**。確保已將其下載到系統中。如果尚未下載,請按照以下螢幕截圖中的步驟下載:
單擊**CLI客戶端(snowsql)**,然後單擊Snowflake儲存庫,如下面的螢幕截圖所示:
使用者可以轉到bootstrap→1.2→windows_x86_64→單擊下載最新版本。下面的螢幕截圖顯示了上述步驟:
現在,安裝下載的外掛。安裝後,在您的系統中開啟 CMD。執行以下命令以檢查連線:
"snowsql -a <account_name> -u <username>"
它將詢問密碼。輸入您的Snowflake密碼。輸入密碼並按ENTER鍵。使用者將看到成功連線的訊息。現在命令列顯示為:
"<username>#<warehouse_name>@<db_name>.<schema_name>"
現在使用以下命令將檔案上傳到 Snowflake 的暫存區:
"GET @%TEST_TABLE file://C:/Users/*******/Documents/"
注意,@%用於Snowflake建立的預設階段,如果使用者想使用他們自己的內部階段,只需傳入@<stage_name>。資料將解除安裝到本地目錄。
Snowflake - 外部資料載入
Snowflake也支援客戶端的雲端儲存。這意味著客戶端可以在其雲中擁有資料,並且可以透過引用位置將其載入到Snowflake中。目前,Snowflake支援3個雲:AWS S3、Microsoft Azure和Google Cloud Platform位置。這些被稱為外部階段。但是,Snowflake提供Snowflake管理的階段,這些階段被稱為**內部階段**。
**外部階段**是客戶端位置,而內部階段用於使用者在其本地系統目錄中工作時。
要從外部雲上傳資料,需要進行以下設定:
Snowflake中現有的資料庫和模式,資料必須載入到其中。
指向AWS S3儲存桶的外部階段設定。
檔案格式,它定義載入到AWS S3中的檔案結構。
本章將討論如何設定這些要求並將資料載入到表中。
我們已經建立了一個名為TEST_DB的資料庫、名為TEST_SCHEMA_1的模式和名為TEST_TABLE的表。如果這些不存在,請按照前面章節中的說明建立它們。
外部階段可以透過Snowflake的使用者介面以及使用SQL進行設定。
使用UI
要建立外部階段,請按照以下說明操作:
登入Snowflake。單擊頂部功能區上的**資料庫**。在資料庫檢視中,單擊名為TEST_DB的資料庫名稱。現在,單擊**階段**選項卡。現在,單擊頂部顯示的**建立**按鈕,如下面的螢幕截圖所示:
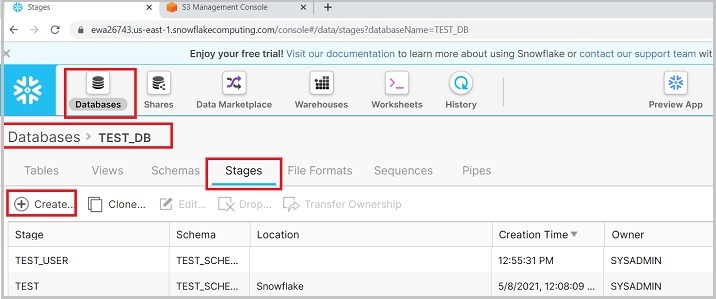
會彈出建立階段(Create Stage)對話方塊,在列表中選擇amazon|s3,然後點選“下一步”按鈕,如下所示:

接下來進入下一個螢幕,使用者需要在此輸入以下詳細資訊:
名稱(Name)- 使用者定義的外部階段名稱。此名稱將用於將資料從階段複製到表。
模式名稱(Schema Name)- 選擇表所在的模式名稱以載入資料。
URL- 提供來自 Amazon 的 S3 URL。它基於儲存桶名稱和金鑰是唯一的。
AWS 金鑰 ID(AWS Key ID)- 請輸入您的 AWS 金鑰 ID。
AWS 金鑰(AWS Secret Key)- 輸入您的金鑰以連線到您的 AWS。
加密主金鑰(Encryption Master Key)- 如有,請提供加密金鑰。
提供這些詳細資訊後,單擊完成(Finish)按鈕。以下螢幕截圖描述了上述步驟:
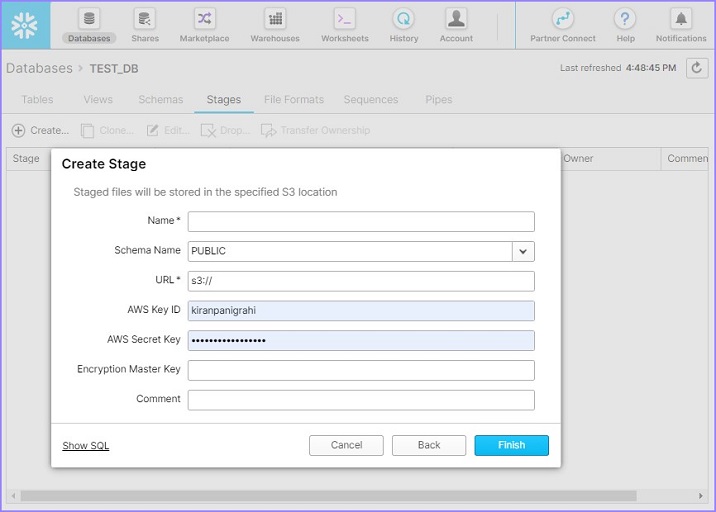
使用者可以在“檢視”面板中看到新建立的外部階段。
使用 SQL
使用 SQL 建立外部階段非常簡單。只需執行以下查詢並提供所有詳細資訊(例如名稱、AWS 金鑰、密碼、主金鑰),它將建立階段。
CREATE STAGE "TEST_DB"."TEST_SCHEMA_1".Ext_S3_stage URL = 's3://***/***** CREDENTIALS = (AWS_KEY_ID = '*********' AWS_SECRET_KEY = '********') ENCRYPTION = (MASTER_KEY = '******');
檔案格式定義上傳到 S3 的檔案的結構。如果檔案結構與表結構不匹配,則載入將失敗。
使用UI
要建立檔案格式,請按照以下說明操作。
登入 Snowflake。單擊頂部功能區中的資料庫(Databases)。在資料庫檢視中,單擊資料庫名稱 TEST_DB。現在,單擊檔案格式(File Format)選項卡。然後,單擊頂部的建立(Create)按鈕。這將彈出建立檔案格式(Create File Format)對話方塊。輸入以下詳細資訊:
名稱(Name)- 檔案格式的名稱
模式名稱 - 建立的檔案格式只能在給定的模式中使用。
格式型別(Format Type)- 檔案格式的名稱
列分隔符(Column separator)- 如果 csv 檔案已分隔,請提供檔案分隔符
行分隔符(Row separator)- 如何識別新行
要跳過的標題行(Header lines to skip)- 如果提供標題,則為 1,否則為 0
其他內容可以保持不變。輸入詳細資訊後,單擊完成(Finish)按鈕。以下螢幕截圖顯示了上述詳細資訊:
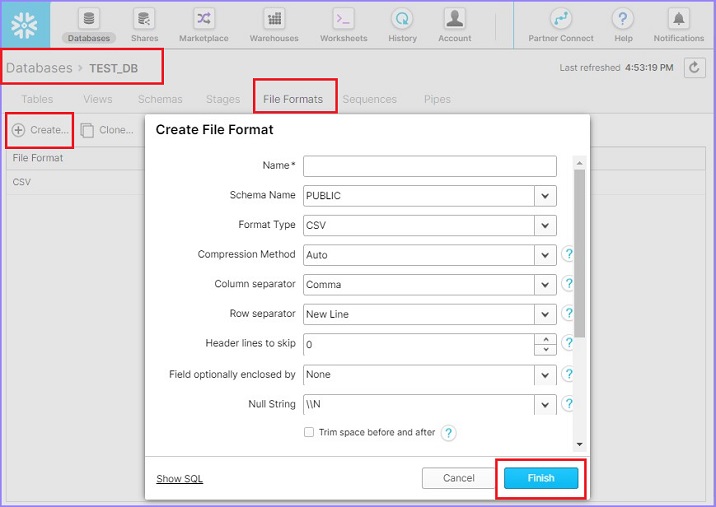
使用者將能夠在視圖面板中看到已建立的檔案格式。
使用 SQL
使用 SQL 建立檔案格式非常簡單。只需執行以下查詢並提供所有詳細資訊,如下所示。
CREATE FILE FORMAT "TEST_DB"."TEST_SCHEMA_1".ext_csv TYPE = 'CSV' COMPRESSION = 'AUTO'
FIELD_DELIMITER = ',' RECORD_DELIMITER = '\n' SKIP_HEADER = 0 FIELD_OPTIONALLY_ENCLOSED_BY =
'NONE' TRIM_SPACE = FALSE ERROR_ON_COLUMN_COUNT_MISMATCH = TRUE ESCAPE = 'NONE'
ESCAPE_UNENCLOSED_FIELD = '\134' DATE_FORMAT = 'AUTO' TIMESTAMP_FORMAT = 'AUTO' NULL_IF = ('\\N');
從 S3 載入資料
本章將討論如何設定所有必需的引數(如階段、檔案格式、資料庫)以從 S3 載入資料。
使用者可以執行以下查詢以檢視給定階段中存在的所有檔案:
LS @<external_stage_name>
現在,要載入資料,請執行以下查詢:
語法
COPY INTO @<database_name>.<schema_name>.<table_name>
FROM @<database_name>.<schema_name>.<ext_stage_name>
FILES=('<file_name>')
FILE_FORMAT=(FORMAT_NAME=<database_name>.<schema_name>.<file_format_name>);
示例
COPY INTO @test_db.test_schema_1.TEST_USER
FROM @test_db.test_schema_1.EXT_STAGE
FILES=('data.csv')
FILE_FORMAT=(FORMAT_NAME=test_db.test_schema_1.CSV);
執行上述查詢後,使用者可以透過執行以下簡單查詢來驗證表中的資料:
Select count(*) from Test_Table
如果使用者想要上傳外部階段中存在的所有檔案,則無需傳遞“FILES=(<file_name>)”。
Snowflake - 外部資料解除安裝
Snowflake 也支援客戶端的雲端儲存。這意味著客戶端可以從 Snowflake 將資料匯出到其雲中。目前,Snowflake 支援 3 個雲 - AWS S3、Microsoft Azure 和 Google Cloud Platform 位置。這些被稱為外部階段。但是,Snowflake 提供 Snowflake 託管階段,這些階段被稱為內部階段。
外部階段是客戶端位置,而內部階段在使用者使用本地系統目錄時使用。
要將資料解除安裝到外部雲,需要進行以下設定:
Snowflake 中現有的資料庫和模式,資料必須解除安裝到 AWS S3。
指向AWS S3儲存桶的外部階段設定。
檔案格式定義載入到 AWS S3 的檔案的結構。
本章將討論如何設定這些要求並將資料從表解除安裝到 S3。
我們已經建立了一個名為 TEST_DB 的資料庫、名為 TEST_SCHEMA_1 的模式和名為 TEST_TABLE 的表。如果這些不存在,請按照前面章節中的說明建立它們。
外部階段可以透過Snowflake的使用者介面以及使用SQL進行設定。
使用UI
要建立外部階段,請按照以下說明操作:
登入 Snowflake。單擊頂部功能區中的資料庫(Databases)。在資料庫檢視中,單擊資料庫名稱 TEST_DB。接下來,單擊階段(Stages)選項卡,然後單擊頂部的建立(Create)按鈕,如下面的螢幕截圖所示:

會彈出建立階段(Create Stage)對話方塊,在列表中選擇 amazon|s3,然後單擊“下一步”,如下所示:

接下來進入下一個螢幕,使用者需要在此輸入以下詳細資訊:
名稱(Name)- 使用者定義的外部階段名稱。此名稱將用於將資料從階段複製到表。
模式名稱(Schema Name)- 選擇表所在的模式名稱以載入資料。
URL- 提供來自 Amazon 的 S3 URL。它基於儲存桶名稱和金鑰是唯一的。
AWS 金鑰 ID(AWS Key ID)- 請輸入您的 AWS 金鑰 ID。
AWS 金鑰(AWS Secret Key)- 輸入您的金鑰以連線到您的 AWS。
加密主金鑰(Encryption Master Key)- 如有,請提供加密金鑰。
提供詳細資訊後,單擊完成(Finish)按鈕。以下螢幕截圖描述了上述步驟:

使用者可以在“檢視”面板中看到新建立的外部階段。
使用 SQL
使用 SQL 建立外部階段非常簡單。只需執行以下查詢並提供所有詳細資訊(例如名稱、AWS 金鑰、密碼、主金鑰),它將建立階段。
CREATE STAGE "TEST_DB"."TEST_SCHEMA_1".Ext_S3_stage URL = 's3://***/***** CREDENTIALS = (AWS_KEY_ID = '*********' AWS_SECRET_KEY = '********') ENCRYPTION = (MASTER_KEY = '******');
檔案格式定義上傳到 S3 的檔案的結構。如果檔案結構與表結構不匹配,則載入將失敗。
使用UI
要建立檔案格式,請按照以下說明操作。
登入 Snowflake 並單擊頂部功能區中的資料庫(Databases)。在資料庫檢視中,單擊資料庫名稱 TEST_DB。
接下來,單擊檔案格式(File Format)選項卡,然後單擊頂部的“建立”按鈕。將彈出建立檔案格式(Create File Format)對話方塊。輸入以下詳細資訊:
名稱 - 檔案格式的名稱。
模式名稱 - 建立的檔案格式只能在給定的模式中使用。
格式型別 - 檔案格式的名稱。
列分隔符(Column separator)- 如果 csv 檔案已分隔,請提供檔案分隔符。
行分隔符 - 如何識別新行。
要跳過的標題行(Header lines to skip)- 如果提供標題,則為 1,否則為 0。
其他內容可以保持不變。輸入這些詳細資訊後,單擊“完成”按鈕。
以下螢幕截圖顯示了上述詳細資訊:

使用者將能夠在視圖面板中看到已建立的檔案格式。
使用 SQL
使用 SQL 建立檔案格式非常簡單。只需執行以下查詢並提供所有必要的詳細資訊,如下所示。
CREATE FILE FORMAT "TEST_DB"."TEST_SCHEMA_1".ext_csv TYPE = 'CSV' COMPRESSION = 'AUTO'
FIELD_DELIMITER = ',' RECORD_DELIMITER = '\n' SKIP_HEADER = 0 FIELD_OPTIONALLY_ENCLOSED_BY =
'NONE' TRIM_SPACE = FALSE ERROR_ON_COLUMN_COUNT_MISMATCH = TRUE ESCAPE = 'NONE'
ESCAPE_UNENCLOSED_FIELD = '\134' DATE_FORMAT = 'AUTO' TIMESTAMP_FORMAT = 'AUTO' NULL_IF = ('\\N');
將資料解除安裝到 S3
本章討論瞭如何設定所有必需的引數(如階段、檔案格式、資料庫)以將資料解除安裝到 S3。
現在,要解除安裝資料,請執行以下查詢:
語法
COPY INTO @<database_name>.<schema_name>.<external_stage_name> FROM (SELECT * FROM <table_name>) FILE_FORMAT=(FORMAT_NAME=<database_name>.<schema_name>.<file_format_name>);
示例
COPY INTO @test_db.test_schema_1.EXT_Stage FROM (SELECT * FROM TEST_TABLE) FILE_FORMAT=(FORMAT_NAME=test_db.test_schema_1.CSV);