- Snowflake 教程
- Snowflake - 首頁
- Snowflake - 簡介
- Snowflake - 資料架構
- Snowflake - 功能架構
- Snowflake - 如何訪問
- Snowflake - 版本
- Snowflake - 定價模式
- Snowflake - 物件
- Snowflake - 表和檢視型別
- Snowflake - 登入
- Snowflake - 資料倉庫
- Snowflake - 資料庫
- Snowflake - 模式
- Snowflake - 表和列
- Snowflake - 從檔案載入資料
- Snowflake - 有用查詢示例
- Snowflake - 監控使用情況和儲存
- Snowflake - 快取
- 從 Snowflake 解除安裝資料到本地
- 外部資料載入(來自 AWS S3)
- 外部資料解除安裝(到 AWS S3)
- Snowflake 資源
- Snowflake - 快速指南
- Snowflake - 有用資源
- Snowflake - 討論
Snowflake - 快取
Snowflake 具有獨特的快取功能。它基於此快取提供快速的結果,並減少資料掃描量。它甚至可以幫助客戶降低賬單。
Snowflake 中基本上有三種類型的快取。
- 元資料快取
- 查詢結果快取
- 資料快取
預設情況下,所有 Snowflake 會話都啟用快取。但是使用者可以根據需要停用它。但是,使用者只能停用查詢結果快取,無法停用**元資料快取**和**資料快取**。
在本章中,我們將討論不同型別的快取以及 Snowflake 如何決定快取。
元資料快取
元資料儲存在雲服務層,因此快取也在同一層。這些元資料快取始終對所有人啟用。
它基本上包含以下詳細資訊:
表中的行數。
列的 MIN/MAX 值
列中 DISTINCT 值的數量
列中 NULL 值的數量
不同表版本的詳細資訊
物理檔案的引用
SQL 最佳化器主要使用這些資訊來更快地執行查詢。一些查詢可以直接透過元資料本身來回答。對於此類查詢,不需要虛擬倉庫,但可能適用雲服務費用。
此類查詢例如:
**所有 SHOW** 命令
**MIN,MAX**,但僅限於列的整數/數字/日期資料型別。
COUNT
讓我們執行一個查詢來了解元資料快取的工作原理,使用者可以進行驗證。
登入 Snowflake 並轉到工作表。透過執行以下查詢暫停資料倉庫:
ALTER WAREHOUSE COMPUTE_WH SUSPEND;
現在,按順序執行以下查詢:
USE SCHEMA SNOWFLAKE_SAMPLE_DATA.TPCH_SF100; SELECT MIN(L_orderkey), MAX(l_orderkey), COUNT(*) FROM lineitem;
使用者將能夠在不到 100 毫秒的時間內看到結果,如下面的螢幕截圖所示。單擊查詢 ID。它將顯示查詢 ID 的連結。然後單擊如下所示的連結:
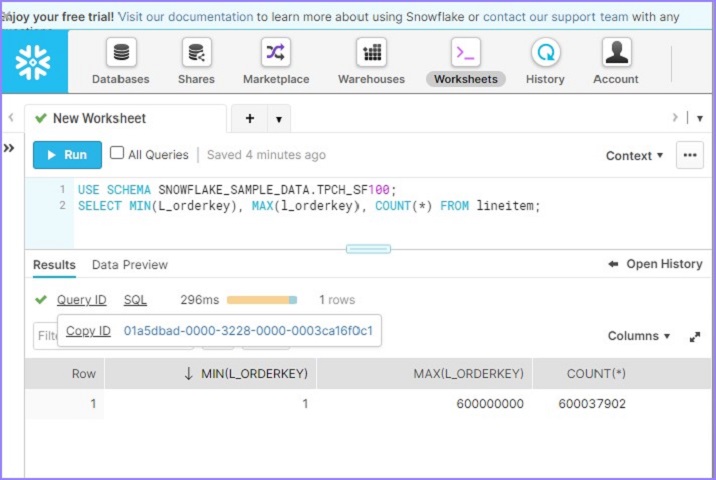
預設情況下,它會開啟顯示 SQL 的詳細資訊頁面。單擊“**概要檔案**”選項卡。它顯示 100% 基於元資料的的結果。這意味著它無需任何計算倉庫即可執行結果並根據元資料快取獲取詳細資訊。
以下螢幕截圖顯示了上述步驟:

查詢結果快取
查詢結果由雲服務層儲存和管理。如果多次執行相同的查詢,這將非常有用,但前提是在多次執行查詢的時間段內底層資料或基表沒有更改。此快取具有一個獨特的功能,即同一帳戶內的其他使用者也可以使用。
例如,如果使用者 1 第一次執行查詢,結果將儲存在快取中。當用戶 2 也嘗試執行相同的查詢(假設基表和資料沒有更改)時,它將從查詢結果快取中獲取結果。
快取的結果可用 24 小時。但是,每次重新執行相同的查詢時,24 小時的計數器都會重置。例如,如果一個查詢在上午 10 點執行,則其快取將可用到第二天上午 10 點。如果在同一天下午 2 點重新執行相同的查詢,則快取將可用到第二天的下午 2 點。
要使用查詢結果快取,需要滿足一些條件:
必須重新執行完全相同的**SQL** 查詢。
SQL 中不應有任何隨機函式。
使用者必須具有使用它的許可權。
執行查詢時應啟用查詢結果。預設情況下,除非另行設定,否則它是啟用的。
查詢結果快取的一些情況:
需要大量計算的查詢,例如聚合函式和半結構化資料分析。
非常頻繁執行的查詢。
複雜的查詢。
重構另一個查詢的輸出,例如“USE TABLE function RESULT_SCAN(<query_id>)”。
讓我們執行一個查詢來了解查詢結果快取的工作原理,使用者可以進行驗證。
登入 Snowflake 並轉到工作表。透過執行以下查詢恢復資料倉庫:
ALTER WAREHOUSE COMPUTE_WH Resume;
現在,按順序執行以下查詢:
USE SCHEMA SNOWFLAKE_SAMPLE_DATA.TPCH_SF100;
SELECT l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (l_discount)) AS sum_disc_price,
SUM(l_extendedprice * (l_discount) * (1+l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM lineitem
WHERE l_shipdate <= dateadd(day, 90, to_date('1998-12-01'))
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
單擊查詢 ID。它將顯示查詢 ID 的連結。然後單擊前面示例(元資料快取)中所示的連結。檢查查詢概要檔案,它將顯示如下:

它顯示掃描了 80.5% 的資料,因此沒有涉及快取。透過執行以下查詢暫停資料倉庫:
ALTER WAREHOUSE COMPUTE_WH Suspend;
再次執行與之前相同的查詢:
USE SCHEMA SNOWFLAKE_SAMPLE_DATA.TPCH_SF100;
SELECT l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (l_discount)) AS sum_disc_price,
SUM(l_extendedprice * (l_discount) * (1+l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM lineitem
WHERE l_shipdate <= dateadd(day, 90, to_date('1998-12-01'))
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
單擊**查詢** ID。它將顯示查詢 ID 的連結。然後單擊前面示例(元資料快取)中所示的連結。檢查查詢概要檔案,它將顯示如下:
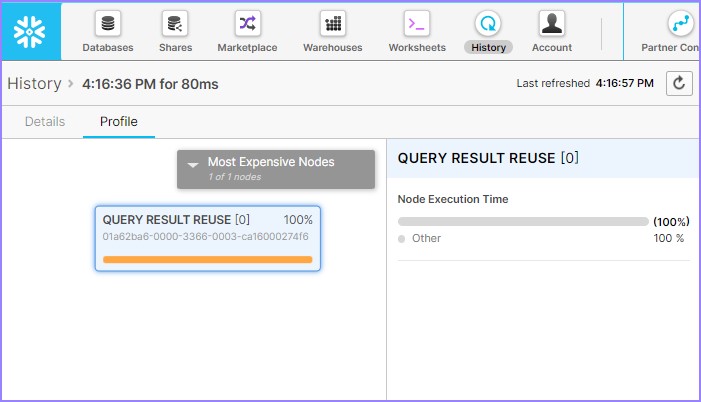
它顯示了查詢結果重用。這意味著它無需資料倉庫即可成功執行查詢,並且整個結果集均來自查詢結果快取。
資料快取
資料快取發生在儲存層。它快取來自查詢的儲存檔案頭和列資料。它儲存所有查詢的資料,但並非完全作為查詢結果。它將這些資料儲存到虛擬倉庫的 SSD 中。當執行類似的查詢時,Snowflake 會盡可能多地使用資料快取。使用者無法停用資料快取。資料快取適用於在同一虛擬倉庫上執行的所有查詢。這意味著與元資料和查詢結果快取不同,資料快取無法在沒有虛擬倉庫的情況下工作。
當查詢執行時,其頭和列資料將儲存在虛擬倉庫的 SSD 上。虛擬倉庫首先讀取本地可用資料(虛擬倉庫的 SSD),然後從遠端雲端儲存(實際的 Snowflake 儲存系統)讀取剩餘資料。當快取儲存空間已滿時,資料將根據最少使用方式刪除。
讓我們執行一個查詢來了解查詢結果快取的工作原理,使用者可以進行驗證。
登入 Snowflake 並轉到**工作表**。透過執行以下查詢恢復資料倉庫:
ALTER WAREHOUSE COMPUTE_WH Resume;
使用以下 SQL 停用 Query_Result 快取:
ALTER SESSION SET USE_CACHED_RESULT = FALSE;
執行以下查詢:
SELECT l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (l_discount)) AS sum_disc_price, SUM(l_extendedprice *
(l_discount) * (1+l_tax))
AS sum_charge, AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) as count_order
FROM lineitem
WHERE l_shipdate <= dateadd(day, 90, to_date('1998-12-01'))
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
單擊**查詢** ID。它將顯示查詢 ID 的連結。然後單擊前面示例(元資料快取)中所示的連結。檢查查詢概要檔案,它將顯示如下:

根據查詢概要檔案,掃描了 88.6% 的資料。如果您注意到右側,本地磁碟 I/O = 2%,而遠端磁碟 I/O = 80%。這意味著幾乎沒有或沒有使用資料快取。現在,執行以下查詢。WHERE 子句略有不同:
SELECT l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (l_discount)) AS sum_disc_price, SUM(l_extendedprice *
(l_discount) * (1+l_tax))
AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) as count_order
FROM lineitem
WHERE l_shipdate <= dateadd(day, 90, to_date('1998-12-01'))
and l_extendedprice <= 20000
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
單擊**查詢** ID。它將顯示查詢 ID 的連結。然後單擊前面示例(元資料快取)中所示的連結。檢查查詢概要檔案,它將顯示如下:
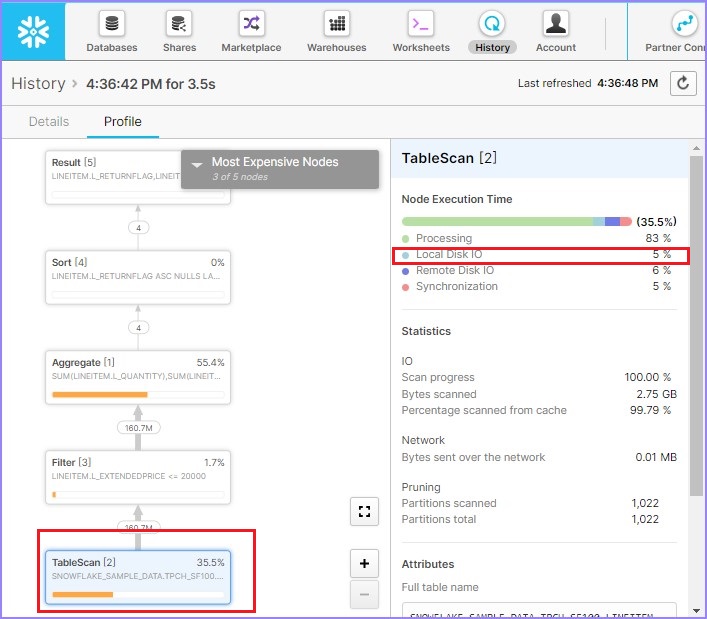
根據查詢概要檔案,掃描了 58.9% 的資料,這比第一次要低得多。如果您注意到右側,本地磁碟 I/O 增加到 4%,而遠端磁碟 I/O = 0%。這意味著幾乎沒有或沒有使用來自遠端的資料。