- Seaborn 教程
- Seaborn - 首頁
- Seaborn - 簡介
- Seaborn - 環境設定
- 匯入資料集和庫
- Seaborn - 圖形美觀
- Seaborn - 調色盤
- Seaborn - 直方圖
- Seaborn - 核密度估計
- 視覺化成對關係
- Seaborn - 繪製分類資料
- 觀測值的分佈
- Seaborn - 統計估計
- Seaborn - 繪製寬格式資料
- 多面板分類圖
- Seaborn - 線性關係
- Seaborn - Facet Grid
- Seaborn - Pair Grid
- 函式參考
- Seaborn - 函式參考
- Seaborn 有用資源
- Seaborn - 快速指南
- Seaborn - 有用資源
- Seaborn - 討論
Seaborn.clustermap() 方法
Seaborn.clustermap() 方法用於將資料集繪製為分層聚類的熱圖。
聚類圖是一種互動式地圖,當繪製的太多資料點過於靠近彼此,導致難以確定變化並從給定資料中得出結論時,它非常有用。它也被稱為氣泡圖,用於衡量不同位置的叢集的效能、大小和存在。
語法
以下是 seaborn.clustermap() 方法的語法:
引數
下面討論了 seaborn.clustermap() 方法的一些引數。
| 序號 | 名稱和描述 |
|---|---|
| 1 | 資料 它接受矩形資料集作為輸入。一個可以強制轉換為二維資料集的 ndarray。如果提供 Pandas DataFrame,則將使用索引和列資訊為列和行新增標籤。 |
| 2 | Vmin,vmax 此可選引數接受浮點值作為輸入,這些值用作顏色對映錨點;否則,將使用資料和其他關鍵字引數來推斷它們。 |
| 3 | Cmap 此可選引數接受 matplotlib 顏色或顏色列表作為輸入。它執行將資料值轉換為顏色空間的轉換。如果未指定,預設值將取決於是否設定了中心。 |
| 4 | 度量 接受字串值,並確定用於計算叢集的連結方法。 |
| 5 | 掩碼 接受布林陣列或 DataFrame,是一個可選引數。如果傳遞,則在 mask 為 True 的單元格中不會顯示資料。 |
| 6 | Standard_scale 此可選引數接受整數值,一行或一列。傳遞的值確定是否標準化該維度,這需要將每一行或每一列的最大值除以其最小值。 |
| 7 | {row,col}_cluster 接受布林值,如果傳遞 True,則對 {row,column} 進行聚類。 |
| 8 | {row,col}_linkage 接受 numpy.ndarray 作為輸入,並使用此獲取行或列的預計算連結矩陣。 |
| 9 | cbar 接受布林值,並確定是否繪製顏色條。 |
返回值
此方法返回一個 ClusterGrid 例項。
載入 seaborn 庫
在繼續開發繪圖之前,讓我們載入 seaborn 庫和資料集。要載入或匯入 seaborn 庫,可以使用以下程式碼行。
Import seaborn as sns
載入資料集
在本文中,我們將使用 seaborn 庫中內建的 flights 資料集。以下命令用於載入資料集。
flights=sns.load_dataset("flights")
以下命令用於檢視資料集中前 5 行。這使我們能夠了解可以使用哪些變數來繪製圖形。
flights.head()
以下是上述程式碼段的輸出。
index,year,passengers 0,1949,112 1,1949,118 2,1949,132 3,1949,129 4,1949,121
現在我們已經載入了資料集,我們將探索一些示例。
示例 1
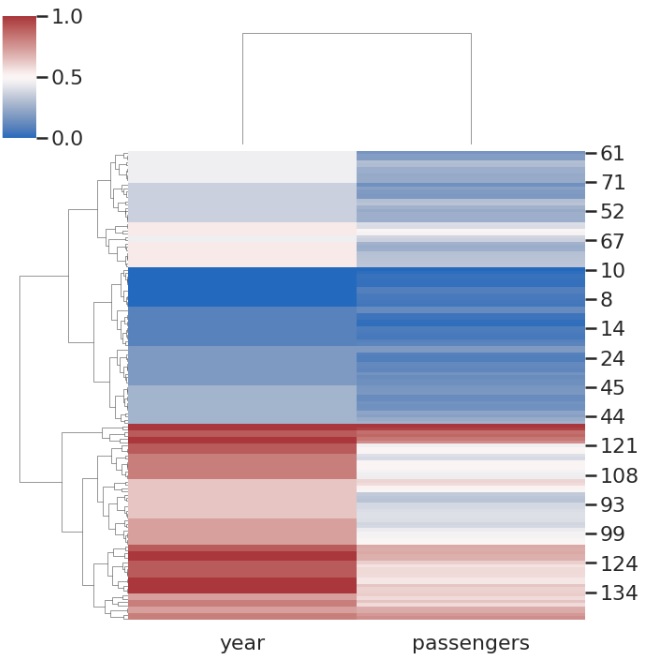
我們使用上面提到的 flights 資料集,並且由於我們要繪製聚類圖,因此必須從資料集中彈出分類變數。因此,在這種情況下,month 列被彈出/刪除,然後生成聚類圖。然後我們將 flights 資料幀以及 figsize 和 cmap 引數傳遞給 clustermap 函式。figsize 引數確定圖的大小引數,cmap 確定圖的顏色。
import seaborn as sns
import matplotlib.pyplot as plt
flights=sns.load_dataset("flights")
flights.head()
data=flights.pop('month')
sns.clustermap(flights, cmap='vlag', figsize=(7, 7))
plt.show()
輸出
示例 2
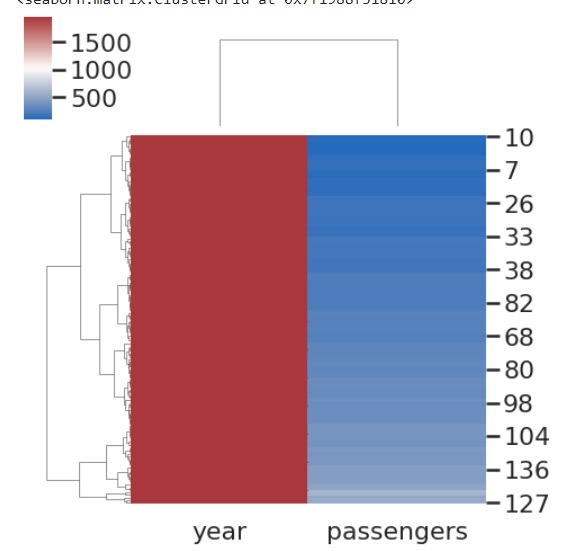
在此示例中,我們將 vmin 和 vmax 引數與 cmap 和資料幀一起傳遞。Vmax 和 vmin 是可選引數,接受浮點值作為輸入,這些值用作顏色對映錨點;否則,將使用資料和其他關鍵字引數來推斷它們。當傳遞這些引數時,我們將注意到圖的變化。
import seaborn as sns
import matplotlib.pyplot as plt
flights=sns.load_dataset("flights")
flights.head()
sns.clustermap(flights, cmap="mako", vmin=0, vmax=1000)
plt.show()
輸出
示例 3
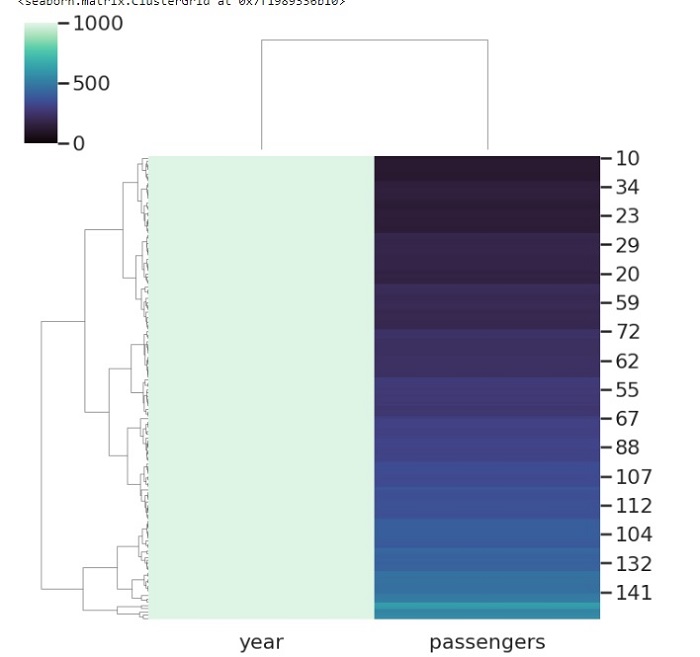
Metric 是 seaborn 庫中 clustermap() 方法的一個非常有用的引數。它接受字串值,並確定用於計算叢集的連結方法。
在下面的程式碼中,我們將 flights 資料幀以及 metric 引數傳遞給 clustermap 函式。metric 引數採用不同的值,在此示例中,我們傳遞了相關性。
import seaborn as sns
import matplotlib.pyplot as plt
flights=sns.load_dataset("flights")
flights.head()
sns.clustermap(flights, metric="correlation")
plt.show()
輸出
示例 4
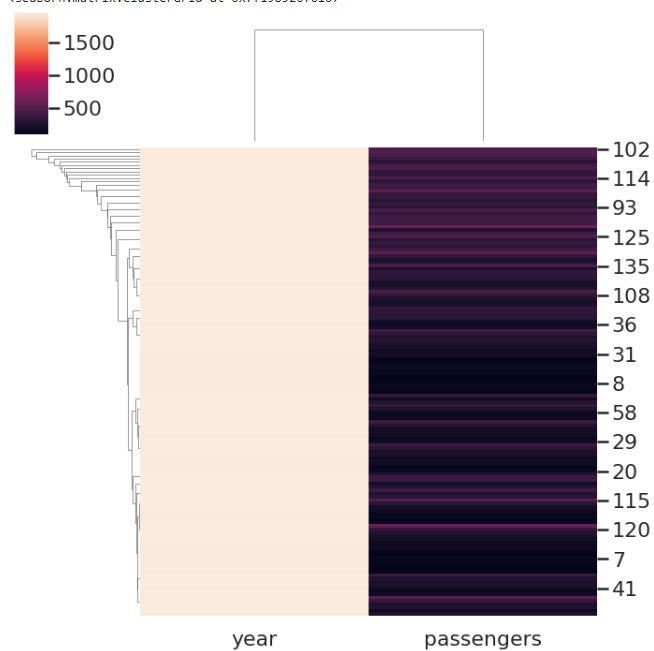
Standard_scale 是另一個常用的引數,在下面的示例中,我們使用此引數並在 flights 資料集上獲得聚類圖。
standard_scale 是一個可選引數,接受整數值,一行或一列。傳遞的值確定是否標準化該維度,這需要將每一行或每一列的最大值除以其最小值。
import seaborn as sns
import matplotlib.pyplot as plt
flights=sns.load_dataset("flights")
flights.head()
sns.clustermap(flights, standard_scale=1,cmap="vlag")
plt.show()
輸出
執行上述程式碼行後獲得的圖如下所示: