- Seaborn 教程
- Seaborn - 首頁
- Seaborn - 簡介
- Seaborn - 環境設定
- 匯入資料集和庫
- Seaborn - 圖形美觀
- Seaborn - 調色盤
- Seaborn - 直方圖
- Seaborn - 核密度估計
- 視覺化成對關係
- Seaborn - 繪製分類資料
- 觀測值的分佈
- Seaborn - 統計估計
- Seaborn - 繪製寬格式資料
- 多面板分類圖
- Seaborn - 線性關係
- Seaborn - Facet Grid
- Seaborn - Pair Grid
- 函式參考
- Seaborn - 函式參考
- Seaborn 有用資源
- Seaborn - 快速指南
- Seaborn - 有用資源
- Seaborn - 討論
Seaborn - 快速指南
Seaborn - 簡介
在分析的世界中,獲得洞察力的最佳方法是將資料視覺化。資料可以透過將其表示為易於理解、探索和掌握的圖表來視覺化。此類資料有助於吸引關鍵要素的注意力。
為了使用 Python 分析一組資料,我們使用了 Matplotlib,這是一個廣泛實施的二維繪相簿。同樣,Seaborn 是 Python 中的一個視覺化庫。它構建在 Matplotlib 之上。
Seaborn 與 Matplotlib
總結一下,如果 Matplotlib“試圖使簡單的事情變得簡單,而使困難的事情變得可能”,那麼 Seaborn 則試圖使一組明確定義的困難的事情也變得簡單。”
Seaborn 有助於解決 Matplotlib 面臨的兩個主要問題;問題是 -
- 預設 Matplotlib 引數
- 使用資料幀
由於 Seaborn 補充並擴充套件了 Matplotlib,因此學習曲線非常平緩。如果您瞭解 Matplotlib,那麼您已經掌握了 Seaborn 的一半。
Seaborn 的重要特性
Seaborn 構建在 Python 的核心視覺化庫 Matplotlib 之上。它旨在作為補充,而不是替代。但是,Seaborn 具有許多非常重要的特性。讓我們在這裡看看其中的一些。這些特性有助於 -
- 內建主題,用於設定 Matplotlib 圖形的樣式
- 視覺化單變數和雙變數資料
- 擬合和視覺化線性迴歸模型
- 繪製統計時間序列資料
- Seaborn 與 NumPy 和 Pandas 資料結構配合使用良好
- 它帶有內建主題,用於設定 Matplotlib 圖形的樣式
在大多數情況下,您仍然會將 Matplotlib 用於簡單的繪圖。建議瞭解 Matplotlib 以調整 Seaborn 的預設繪圖。
Seaborn - 環境設定
在本章中,我們將討論 Seaborn 的環境設定。讓我們從安裝開始,並瞭解如何在前進的過程中開始使用。
安裝 Seaborn 並開始使用
在本節中,我們將瞭解 Seaborn 安裝涉及的步驟。
使用 Pip 安裝程式
要安裝 Seaborn 的最新版本,您可以使用 pip -
pip install seaborn
對於 Windows、Linux 和 Mac 使用 Anaconda
Anaconda(來自 https://www.anaconda.com/)是 SciPy 棧的免費 Python 發行版。它也適用於 Linux 和 Mac。
也可以使用 conda 安裝已釋出的版本 -
conda install seaborn
要直接從 github 安裝 Seaborn 的開發版本
https://github.com/mwaskom/seaborn"
依賴項
考慮以下 Seaborn 的依賴項 -
- Python 2.7 或 3.4+
- numpy
- scipy
- pandas
- matplotlib
Seaborn - 匯入資料集和庫
在本章中,我們將討論如何匯入資料集和庫。讓我們從瞭解如何匯入庫開始。
匯入庫
讓我們從匯入 Pandas 開始,這是一個用於管理關係(表格格式)資料集的優秀庫。在處理 DataFrame 時,Seaborn 非常方便,DataFrame 是資料分析中最廣泛使用的資料結構。
以下命令將幫助您匯入 Pandas -
# Pandas for managing datasets import pandas as pd
現在,讓我們匯入 Matplotlib 庫,它可以幫助我們自定義我們的繪圖。
# Matplotlib for additional customization from matplotlib import pyplot as plt
我們將使用以下命令匯入 Seaborn 庫 -
# Seaborn for plotting and styling import seaborn as sb
匯入資料集
我們已經匯入了所需的庫。在本節中,我們將瞭解如何匯入所需的資料集。
Seaborn 在庫中帶有一些重要的資料集。安裝 Seaborn 後,資料集會自動下載。
您可以使用這些資料集中的任何一個進行學習。您可以使用以下函式載入所需的資料集
load_dataset()
將資料匯入為 Pandas DataFrame
在本節中,我們將匯入一個數據集。此資料集預設情況下載入為 Pandas DataFrame。如果 Pandas DataFrame 中有任何函式,它都會在此 DataFrame 上執行。
以下程式碼行將幫助您匯入資料集 -
# Seaborn for plotting and styling
import seaborn as sb
df = sb.load_dataset('tips')
print df.head()
以上程式碼行將生成以下輸出 -
total_bill tip sex smoker day time size 0 16.99 1.01 Female No Sun Dinner 2 1 10.34 1.66 Male No Sun Dinner 3 2 21.01 3.50 Male No Sun Dinner 3 3 23.68 3.31 Male No Sun Dinner 2 4 24.59 3.61 Female No Sun Dinner 4
要檢視 Seaborn 庫中所有可用的資料集,您可以使用以下命令以及如下所示的 get_dataset_names() 函式 -
import seaborn as sb print sb.get_dataset_names()
以上程式碼行將返回可用資料集的列表,作為以下輸出
[u'anscombe', u'attention', u'brain_networks', u'car_crashes', u'dots', u'exercise', u'flights', u'fmri', u'gammas', u'iris', u'planets', u'tips', u'titanic']
DataFrame 透過可以輕鬆檢視資料的方式以矩形網格的形式儲存資料。矩形網格的每一行包含一個例項的值,網格的每一列都是一個向量,它儲存特定變數的資料。這意味著 DataFrame 的行不需要包含相同資料型別的值,它們可以是數字、字元、邏輯等。Python 的 DataFrame 隨 Pandas 庫提供,它們被定義為具有潛在不同型別列的二維標記資料結構。
有關 DataFrame 的更多詳細資訊,請訪問我們的 教程 關於 pandas。
Seaborn - 圖形美觀
視覺化資料是一個步驟,進一步使視覺化資料更美觀是另一個步驟。視覺化在向受眾傳達定量見解以吸引他們的注意力方面起著至關重要的作用。
美學是指一組與美的本質和欣賞相關的原則,尤其是在藝術中。視覺化是將資料以有效且最簡單的方式表示的藝術。
Matplotlib 庫高度支援自定義,但瞭解需要調整哪些設定才能實現有吸引力和預期的繪圖,是人們應該瞭解的才能使用它。與 Matplotlib 不同,Seaborn 附帶自定義主題和用於自定義和控制 Matplotlib 圖形外觀的高階介面。
示例
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
sinplot()
plt.show()
以下是使用預設 Matplotlib 的繪圖外觀 -
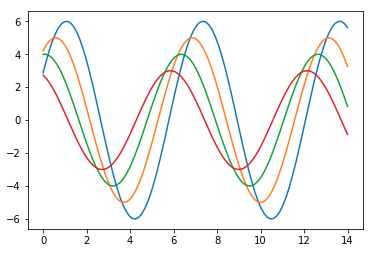
要將相同的繪圖更改為 Seaborn 預設值,請使用 set() 函式 -
示例
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set()
sinplot()
plt.show()
輸出
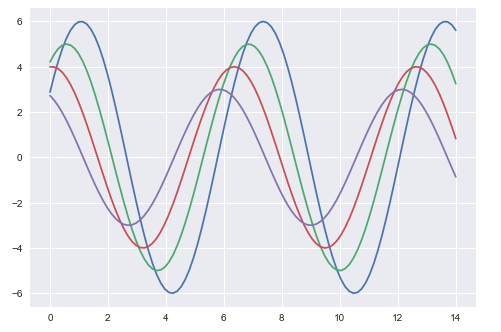
以上兩幅圖顯示了預設 Matplotlib 和 Seaborn 繪圖之間的差異。資料的表示相同,但兩種表示樣式有所不同。
基本上,Seaborn 將 Matplotlib 引數分為兩組 -
- 繪圖樣式
- 繪圖比例
Seaborn 圖形樣式
操縱樣式的介面是 set_style()。使用此函式,您可以設定繪圖的主題。根據最新更新的版本,以下是可用的五個主題。
- Darkgrid
- Whitegrid
- Dark
- White
- Ticks
讓我們嘗試從上述列表中應用一個主題。繪圖的預設主題將是 darkgrid,我們在前面的示例中已經看到過。
示例
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("whitegrid")
sinplot()
plt.show()
輸出
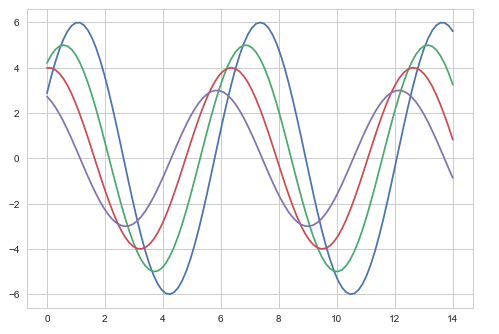
以上兩個繪圖之間的區別是背景顏色
刪除座標軸脊柱
在白色和刻度主題中,我們可以使用 despine() 函式刪除頂部和右側座標軸脊柱。
示例
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("white")
sinplot()
sb.despine()
plt.show()
輸出
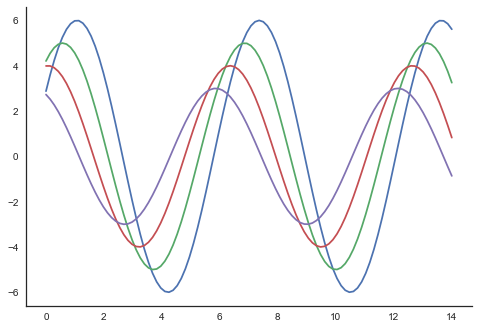
在常規繪圖中,我們僅使用左側和底部座標軸。使用 despine() 函式,我們可以避免不必要的右側和頂部座標軸脊柱,這在 Matplotlib 中不受支援。
覆蓋元素
如果要自定義 Seaborn 樣式,可以將引數字典傳遞給 set_style() 函式。可以使用 axes_style() 函式檢視可用的引數。
示例
import seaborn as sb print sb.axes_style
輸出
{'axes.axisbelow' : False,
'axes.edgecolor' : 'white',
'axes.facecolor' : '#EAEAF2',
'axes.grid' : True,
'axes.labelcolor' : '.15',
'axes.linewidth' : 0.0,
'figure.facecolor' : 'white',
'font.family' : [u'sans-serif'],
'font.sans-serif' : [u'Arial', u'Liberation
Sans', u'Bitstream Vera Sans', u'sans-serif'],
'grid.color' : 'white',
'grid.linestyle' : u'-',
'image.cmap' : u'Greys',
'legend.frameon' : False,
'legend.numpoints' : 1,
'legend.scatterpoints': 1,
'lines.solid_capstyle': u'round',
'text.color' : '.15',
'xtick.color' : '.15',
'xtick.direction' : u'out',
'xtick.major.size' : 0.0,
'xtick.minor.size' : 0.0,
'ytick.color' : '.15',
'ytick.direction' : u'out',
'ytick.major.size' : 0.0,
'ytick.minor.size' : 0.0}
更改任何引數的值將更改繪圖樣式。
示例
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("darkgrid", {'axes.axisbelow': False})
sinplot()
sb.despine()
plt.show()
輸出
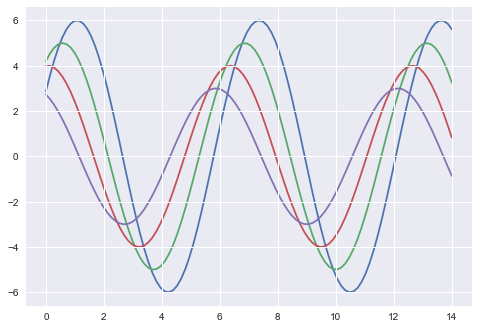
縮放繪圖元素
我們還可以控制繪圖元素,並可以使用 set_context() 函式控制繪圖的比例。我們有四個預設上下文模板,基於相對大小,上下文命名如下
- Paper
- Notebook
- Talk
- Poster
預設情況下,上下文設定為筆記本;並在上面的繪圖中使用。
示例
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("darkgrid", {'axes.axisbelow': False})
sinplot()
sb.despine()
plt.show()
輸出
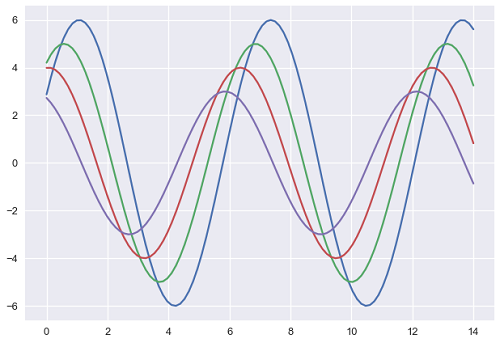
與上面的繪圖相比,實際繪圖的輸出尺寸更大。
注意 - 由於我們網頁上影像的縮放,您可能會錯過我們示例繪圖中的實際差異。
Seaborn - 調色盤
顏色在視覺化中比任何其他方面都起著重要的作用。如果使用得當,顏色會為繪圖增加更多價值。調色盤是指畫家整理和混合顏料的平面。
構建調色盤
Seaborn 提供了一個名為 color_palette() 的函式,可用於為繪圖著色併為其新增更多美學價值。
用法
seaborn.color_palette(palette = None, n_colors = None, desat = None)
引數
下表列出了構建調色盤的引數 -
| 序號 | 調色盤和描述 |
|---|---|
| 1 | n_colors 調色盤中的顏色數量。如果為 None,則預設值將取決於調色盤的指定方式。預設情況下,n_colors 的值為 6 種顏色。 |
| 2 | desat 使每種顏色去飽和的比例。 |
返回值
返回值是指 RGB 元組列表。以下是現成的 Seaborn 調色盤 -
- Deep
- Muted
- Bright
- Pastel
- Dark
- Colorblind
除此之外,還可以生成新的調色盤
在不知道資料特徵的情況下,很難確定應該為給定資料集使用哪種調色盤。意識到這一點,我們將對使用 color_palette() 型別的不同方法進行分類 -
- 定性
- 順序
- 發散
我們還有另一個函式 seaborn.palplot() 用於處理調色盤。此函式將調色盤繪製為水平陣列。我們將在接下來的示例中瞭解更多關於 seaborn.palplot() 的資訊。
定性調色盤
定性或分類調色盤最適合繪製分類資料。
示例
from matplotlib import pyplot as plt import seaborn as sb current_palette = sb.color_palette() sb.palplot(current_palette) plt.show()
輸出
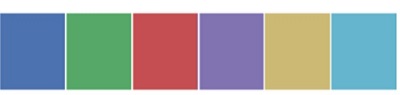
我們沒有在color_palette();中傳遞任何引數,預設情況下,我們看到了6種顏色。可以透過向n_colors引數傳遞一個值來檢視所需的顏色數量。這裡,palplot()用於水平繪製顏色陣列。
順序顏色調色盤
順序圖適合表達資料在一定範圍內從相對較低值到較高值的分佈。
將額外的字元“s”附加到傳遞給顏色引數的顏色上,將繪製順序圖。
示例
from matplotlib import pyplot as plt
import seaborn as sb
current_palette = sb.color_palette()
sb.palplot(sb.color_palette("Greens"))
plt.show()

注意 -我們需要像上面示例中的“Greens”一樣將“s”附加到引數上。
發散顏色調色盤
發散調色盤使用兩種不同的顏色。每種顏色代表從一個共同點向任一方向變化的值的變化。
假設繪製從 -1 到 1 的資料。從 -1 到 0 的值採用一種顏色,從 0 到 +1 的值採用另一種顏色。
預設情況下,值以零為中心。可以透過傳遞一個值來使用引數center控制它。
示例
from matplotlib import pyplot as plt
import seaborn as sb
current_palette = sb.color_palette()
sb.palplot(sb.color_palette("BrBG", 7))
plt.show()
輸出

設定預設顏色調色盤
函式color_palette()有一個名為set_palette()的伴侶函式。它們之間的關係類似於美學章節中介紹的配對。set_palette()和color_palette()的引數相同,但預設的Matplotlib引數已更改,以便將調色盤用於所有繪圖。
示例
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("white")
sb.set_palette("husl")
sinplot()
plt.show()
輸出

繪製單變數分佈
在分析資料時,首先需要了解資料的分佈。在這裡,我們將瞭解seaborn如何幫助我們理解資料的單變數分佈。
函式distplot()提供了快速檢視單變數分佈的最便捷方法。此函式將繪製一個直方圖,該直方圖擬合數據的核密度估計。
用法
seaborn.distplot()
引數
下表列出了引數及其描述 -
| 序號 | 引數 & 描述 |
|---|---|
| 1 | data Series、一維陣列或列表 |
| 2 | bins 直方圖bin的規範 |
| 3 | hist 布林值 |
| 4 | kde 布林值 |
這些是需要了解的基本且重要的引數。
Seaborn - 直方圖
直方圖透過沿資料範圍形成bin,然後繪製條形圖來顯示落入每個bin中的觀測值的數量,從而表示資料分佈。
Seaborn帶有一些資料集,我們在之前的章節中使用了一些資料集。我們已經學習瞭如何載入資料集以及如何查詢可用資料集的列表。
Seaborn帶有一些資料集,我們在之前的章節中使用了一些資料集。我們已經學習瞭如何載入資料集以及如何查詢可用資料集的列表。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
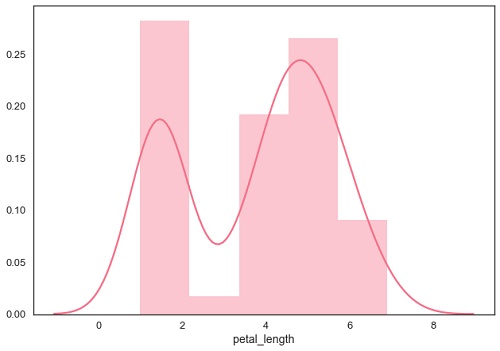
sb.distplot(df['petal_length'],kde = False)
plt.show()
輸出
這裡,kde標誌設定為False。結果,核估計圖的表示將被移除,並且僅繪製直方圖。
Seaborn - 核密度估計
核密度估計 (KDE) 是一種估計連續隨機變數的機率密度函式的方法。它用於非引數分析。
在distplot中將hist標誌設定為False將生成核密度估計圖。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'],hist=False)
plt.show()
輸出
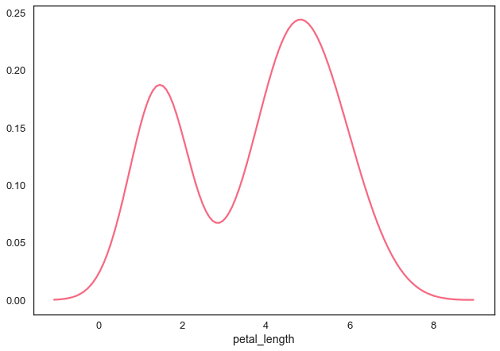
擬合引數分佈
distplot()用於視覺化資料集的引數分佈。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'])
plt.show()
輸出
繪製雙變數分佈
雙變數分佈用於確定兩個變數之間的關係。這主要處理兩個變數之間的關係以及一個變數相對於另一個變數的行為方式。
在seaborn中分析雙變數分佈的最佳方法是使用jointplot()函式。
Jointplot建立一個多面板圖形,該圖形投影了兩個變數之間的雙變數關係,以及每個變數在單獨軸上的單變數分佈。
散點圖
散點圖是視覺化分佈的最便捷方法,其中每個觀測值都透過x軸和y軸在二維圖中表示。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df)
plt.show()
輸出
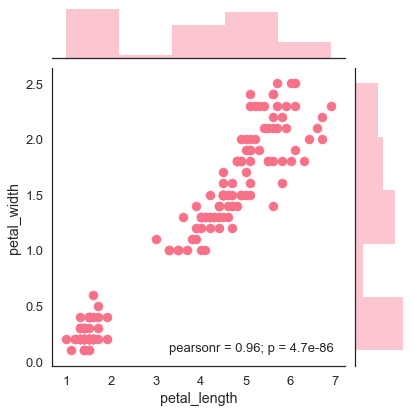
上圖顯示了Iris資料中petal_length和petal_width之間的關係。圖中的趨勢表明研究變數之間存在正相關關係。
六邊形圖
當資料密度稀疏時,即當資料非常分散且難以透過散點圖進行分析時,六邊形分箱用於雙變數資料分析。
一個名為“kind”且值為“hex”的附加引數繪製六邊形圖。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df,kind = 'hex')
plt.show()
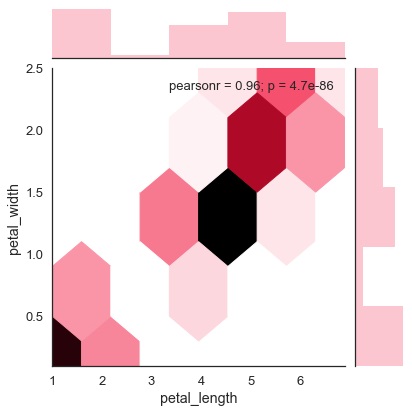
核密度估計
核密度估計是一種非引數方法來估計變數的分佈。在seaborn中,我們可以使用jointplot()繪製kde。
將值“kde”傳遞給kind引數以繪製核圖。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df,kind = 'hex')
plt.show()
輸出
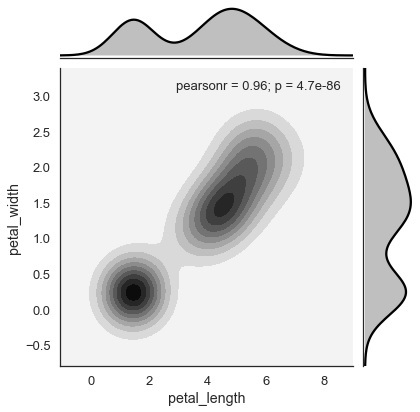
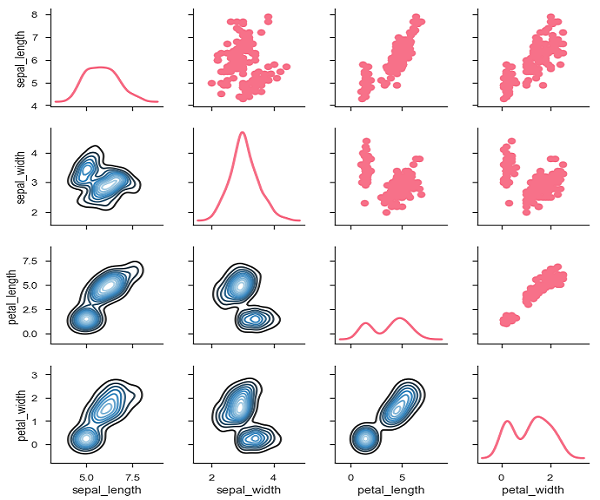
Seaborn - 視覺化成對關係
即時研究中的資料集包含許多變數。在這種情況下,應分析每個變數之間的關係。繪製(n,2)組合的雙變數分佈將是一個非常複雜且耗時的過程。
要繪製資料集中多個成對的雙變數分佈,可以使用pairplot()函式。這將DataFrame中變數的(n,2)組合的關係顯示為矩陣圖,對角線圖是單變數圖。
軸
在本節中,我們將學習什麼是軸、它們的用法、引數等。
用法
seaborn.pairplot(data,…)
引數
下表列出了軸的引數 -
| 序號 | 引數 & 描述 |
|---|---|
| 1 | data 資料框 |
| 2 | hue 資料中用於將繪圖方面對映到不同顏色的變數。 |
| 3 | palette 用於對映hue變數的顏色集 |
| 4 | kind 非恆等關係的繪圖型別。{‘scatter’, ‘reg’} |
| 5 | diag_kind 對角線子圖的繪圖型別。{‘hist’, ‘kde’} |
除了data之外,所有其他引數都是可選的。pairplot可以接受其他一些引數。上面提到的引數經常使用。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.set_style("ticks")
sb.pairplot(df,hue = 'species',diag_kind = "kde",kind = "scatter",palette = "husl")
plt.show()
輸出
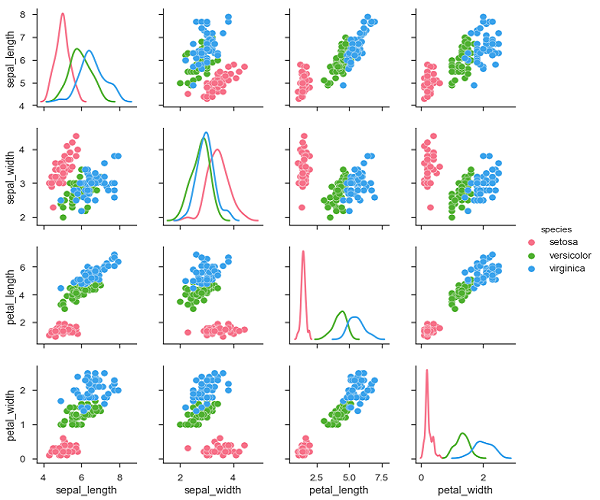
我們可以觀察到每個圖的變化。這些圖採用矩陣格式,其中行名稱表示x軸,列名稱表示y軸。
對角線圖是核密度圖,其他圖如所述是散點圖。
Seaborn - 繪製分類資料
在我們之前的章節中,我們學習了散點圖、六邊形圖和kde圖,這些圖用於分析正在研究的連續變數。當正在研究的變數是分類變數時,這些圖不適用。
當正在研究的一個或兩個變數是分類變數時,我們使用stripplot()、swarmplot()等圖。Seaborn提供了這樣的介面。
分類散點圖
在本節中,我們將學習有關分類散點圖的知識。
stripplot()
當正在研究的變數之一是分類變數時,使用stripplot()。它按排序順序沿任意一個軸表示資料。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.stripplot(x = "species", y = "petal_length", data = df)
plt.show()
輸出
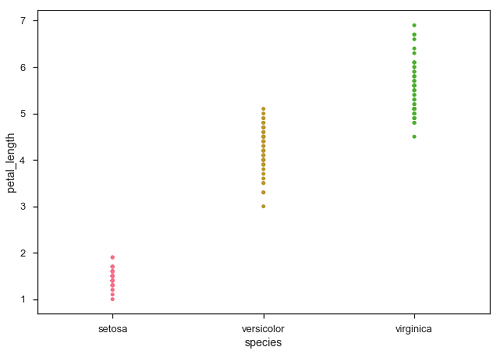
在上圖中,我們可以清楚地看到每個物種中petal_length的差異。但是,上述散點圖的主要問題是散點圖上的點重疊了。我們使用“Jitter”引數來處理這種情況。
Jitter向資料新增一些隨機噪聲。此引數將調整沿分類軸的位置。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.stripplot(x = "species", y = "petal_length", data = df, jitter = Ture)
plt.show()
輸出
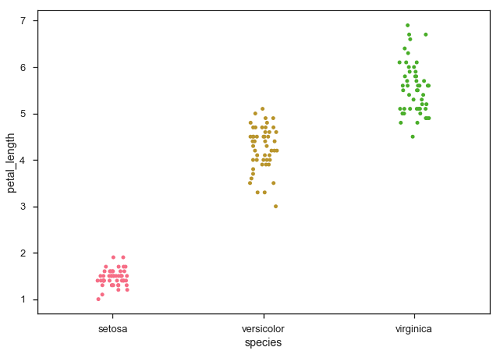
現在,可以輕鬆地看到點的分佈。
Swarmplot()
另一種可以作為“Jitter”替代方案的選項是函式swarmplot()。此函式將散點圖的每個點定位在分類軸上,從而避免點重疊 -
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.swarmplot(x = "species", y = "petal_length", data = df)
plt.show()
輸出
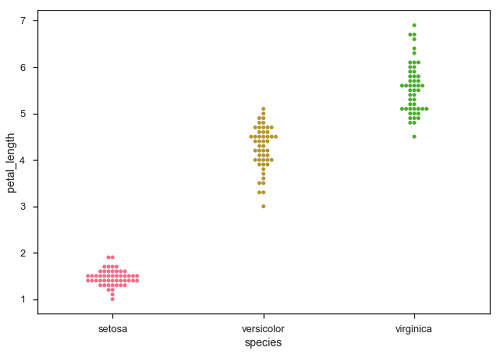
Seaborn - 觀測值的分佈
在上一章中處理的分類散點圖中,它所能提供關於每個類別內值分佈的資訊變得有限。現在,讓我們進一步瞭解一下什麼可以幫助我們在類別中進行比較。
箱線圖
箱線圖是透過四分位數視覺化資料分佈的便捷方法。
箱線圖通常在箱體上延伸有垂直線,稱為須線。這些須線表示上四分位數和下四分位數之外的變化,因此箱線圖也稱為箱須圖和箱須圖。資料中的任何異常值都將作為單個點繪製。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.swarmplot(x = "species", y = "petal_length", data = df)
plt.show()
輸出
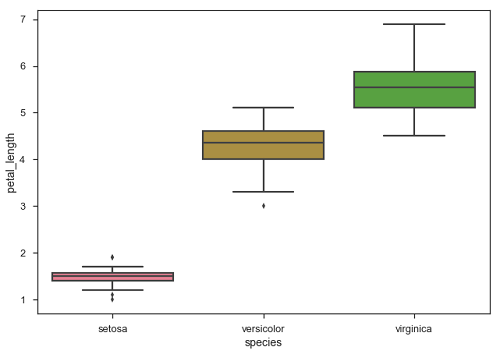
圖上的點表示異常值。
小提琴圖
小提琴圖是箱線圖與核密度估計的組合。因此,這些圖更容易分析和理解資料的分佈。
讓我們使用名為tips的資料集來進一步瞭解小提琴圖。此資料集包含餐廳顧客給的小費的相關資訊。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
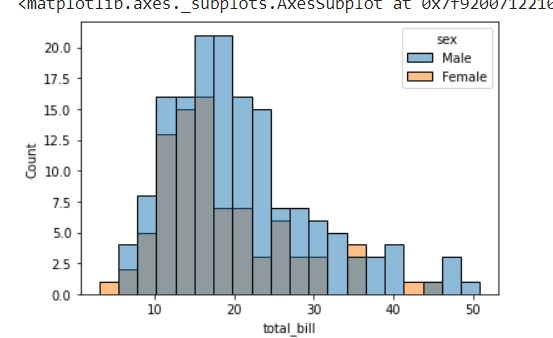
sb.violinplot(x = "day", y = "total_bill", data=df)
plt.show()
輸出
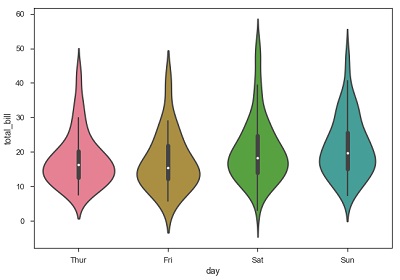
箱線圖中的四分位數和須線值顯示在小提琴內部。由於小提琴圖使用KDE,因此小提琴的較寬部分表示較高的密度,而窄區域表示相對較低的密度。箱線圖中的四分位距和kde中的較高密度部分落在小提琴圖每個類別的相同區域。
上圖顯示了每週四天total_bill的分佈。但是,除此之外,如果我們想看看分佈相對於性別的行為方式,讓我們在下面的示例中探索它。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.violinplot(x = "day", y = "total_bill",hue = 'sex', data = df)
plt.show()
輸出
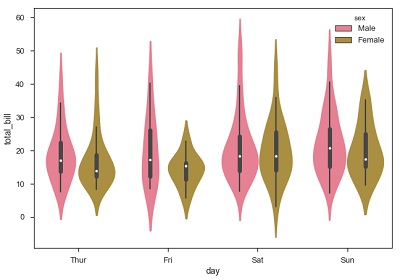
現在我們可以清楚地看到男性和女性之間的消費行為。透過檢視圖表,我們可以很容易地說,男性比女性消費更多。
並且,如果hue變數只有兩個類別,我們可以透過將每個小提琴分成兩個而不是在特定日期有兩個小提琴來美化圖表。小提琴的任一部分都指hue變數中的每個類別。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.violinplot(x = "day", y="total_bill",hue = 'sex', data = df)
plt.show()
輸出
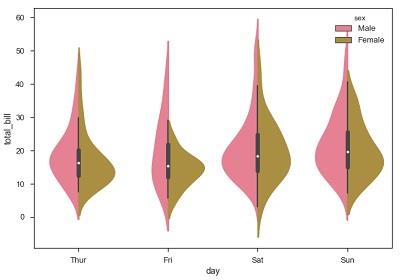
Seaborn - 統計估計
在大多數情況下,我們處理的是整個資料分佈的估計。但是當涉及到中心趨勢估計時,我們需要一種特定的方法來總結分佈。均值和中位數是估計分佈中心趨勢的常用技術。
在我們上面一節中學習的所有圖表中,我們都對整個分佈進行了視覺化。現在,讓我們討論一下我們可以用哪些圖表來估計分佈的中心趨勢。
條形圖
barplot()顯示了分類變數和連續變數之間的關係。資料以矩形條表示,其中條的長度表示該類別中資料的比例。
條形圖表示中心趨勢的估計。讓我們使用“titanic”資料集來學習條形圖。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.barplot(x = "sex", y = "survived", hue = "class", data = df)
plt.show()
輸出

在上面的例子中,我們可以看到每個等級男性和女性的平均存活人數。從圖中我們可以看出,女性的存活人數多於男性。在男性和女性中,頭等艙的存活人數都較多。
條形圖的一個特殊情況是顯示每個類別的觀察值數量,而不是計算第二個變數的統計量。為此,我們使用countplot()。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.countplot(x = " class ", data = df, palette = "Blues");
plt.show()
輸出
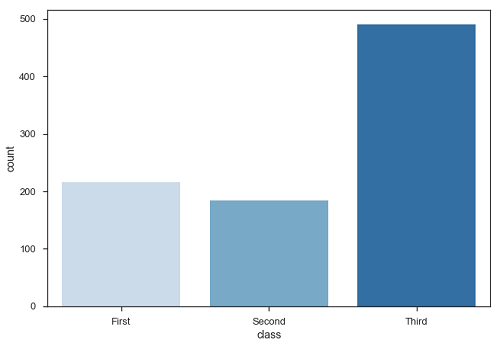
圖顯示,三等艙的乘客數量高於一、二等艙。
點圖
點圖與條形圖的作用相同,但樣式不同。它不是使用完整的條形,而是用某個高度上的點來表示估計值在另一條軸上的值。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.pointplot(x = "sex", y = "survived", hue = "class", data = df)
plt.show()
輸出
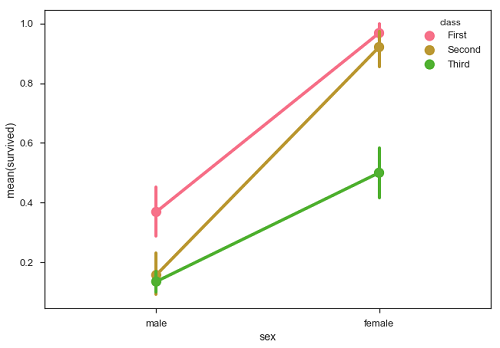
Seaborn - 繪製寬格式資料
始終建議使用“長格式”或“整潔”資料集。但在某些情況下,我們別無選擇,只能使用“寬格式”資料集,同樣的函式也可以應用於各種格式的“寬格式”資料,包括 Pandas DataFrame 或二維 NumPy 陣列。這些物件應該直接傳遞給 data 引數,x 和 y 變數必須指定為字串。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.boxplot(data = df, orient = "h")
plt.show()
輸出
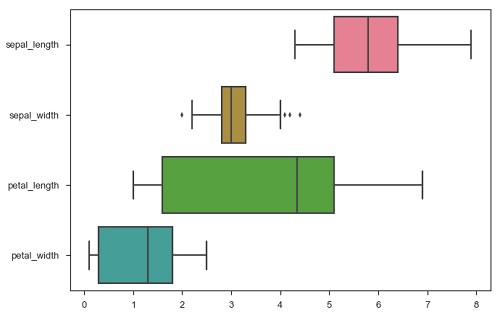
此外,這些函式接受 Pandas 或 NumPy 物件的向量,而不是 DataFrame 中的變數。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.boxplot(data = df, orient = "h")
plt.show()
輸出
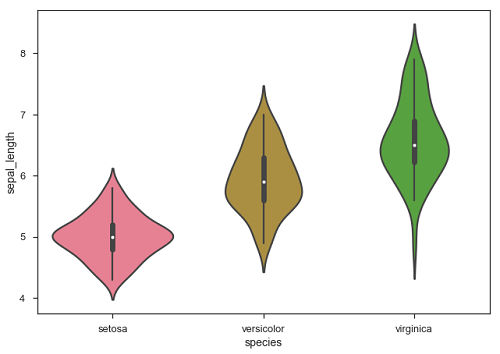
Seaborn 對許多 Python 開發人員的主要優勢在於它可以將 pandas DataFrame 物件作為引數。
Seaborn - 多面板分類圖
分類資料可以使用兩種圖進行視覺化,可以使用pointplot()函式,或使用更高階的factorplot()函式。
Factorplot
Factorplot 在 FacetGrid 上繪製分類圖。使用“kind”引數,我們可以選擇箱線圖、小提琴圖、條形圖和散點圖等圖。FacetGrid 預設使用 pointplot。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('exercise')
sb.factorplot(x = "time", y = pulse", hue = "kind",data = df);
plt.show()
輸出
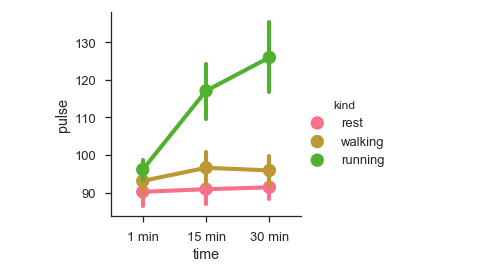
我們可以使用不同的圖來視覺化相同的資料,方法是使用kind引數。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('exercise')
sb.factorplot(x = "time", y = "pulse", hue = "kind", kind = 'violin',data = df);
plt.show()
輸出
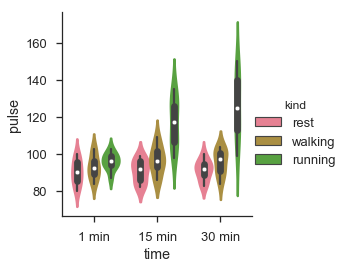
在 factorplot 中,資料繪製在 facet 網格上。
什麼是 Facet 網格?
Facet 網格透過劃分變數形成由行和列定義的面板矩陣。由於面板的存在,單個圖看起來像多個圖。它對於分析兩個離散變數的所有組合非常有用。
讓我們用一個例子來視覺化上述定義。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('exercise')
sb.factorplot(x = "time", y = "pulse", hue = "kind", kind = 'violin', col = "diet", data = df);
plt.show()
輸出
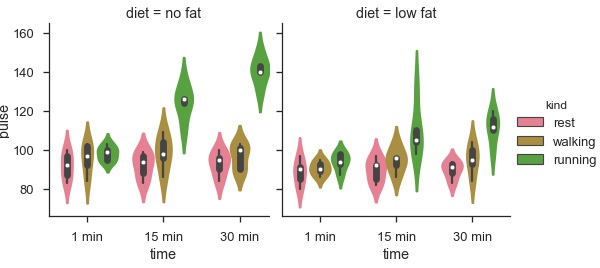
使用 Facet 的優勢在於,我們可以將另一個變數輸入到圖中。上面的圖根據名為“diet”的第三個變數(使用“col”引數)將其劃分為兩個圖。
我們可以建立許多列面並將其與網格的行對齊 -
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.factorplot("alive", col = "deck", col_wrap = 3,data = df[df.deck.notnull()],kind = "count")
plt.show()
輸出
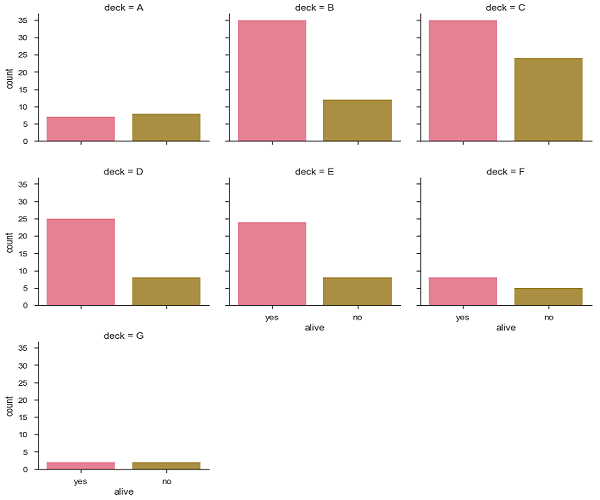
Seaborn - 線性關係
大多數情況下,我們使用包含多個定量變數的資料集,分析的目標通常是將這些變數相互關聯。這可以透過迴歸線來實現。
在構建迴歸模型時,我們通常會檢查多重共線性,我們需要檢視所有連續變數組合之間的相關性,如果存在多重共線性,則需要採取必要的措施將其去除。在這種情況下,以下技術會有所幫助。
繪製線性迴歸模型的函式
Seaborn 中有兩個主要函式可以視覺化透過迴歸確定的線性關係。這些函式是regplot()和lmplot()。
regplot 與 lmplot
| regplot | lmplot |
|---|---|
| 接受各種格式的 x 和 y 變數,包括簡單的 numpy 陣列、pandas Series 物件,或作為 pandas DataFrame 中變數的引用。 | 將資料作為必需引數,並且必須將 x 和 y 變數指定為字串。這種資料格式稱為“長格式”資料。 |
現在讓我們繪製這些圖。
示例
在本例中,使用相同的資料繪製 regplot 和 lmplot 圖。
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.regplot(x = "total_bill", y = "tip", data = df)
sb.lmplot(x = "total_bill", y = "tip", data = df)
plt.show()
輸出
您可以看到兩個圖的大小差異。
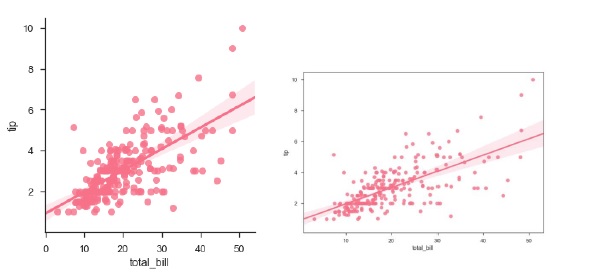
當其中一個變數取離散值時,我們也可以擬合線性迴歸。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.lmplot(x = "size", y = "tip", data = df)
plt.show()
輸出
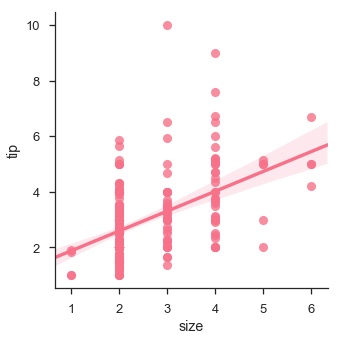
擬合不同型別的模型
上面使用的簡單線性迴歸模型非常容易擬合,但在大多數情況下,資料是非線性的,上述方法無法推廣迴歸線。
讓我們使用 Anscombe 資料集和迴歸圖 -
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x="x", y="y", data=df.query("dataset == 'I'"))
plt.show()
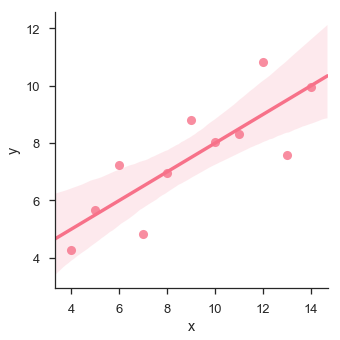
在這種情況下,資料非常適合線性迴歸模型,方差較小。
讓我們看看另一個例子,其中資料具有較大的偏差,這表明最佳擬合線不太好。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x = "x", y = "y", data = df.query("dataset == 'II'"))
plt.show()
輸出
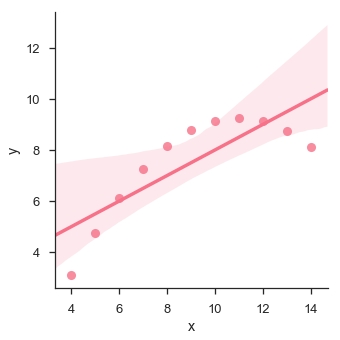
該圖顯示了資料點與迴歸線的偏差較大。可以使用lmplot()和regplot()視覺化此類非線性、高階資料。這些可以擬合多項式迴歸模型來探索資料集中簡單的非線性趨勢 -
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x = "x", y = "y", data = df.query("dataset == 'II'"),order = 2)
plt.show()
輸出
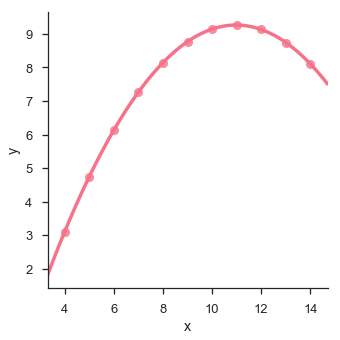
Seaborn - Facet Grid
探索中等維資料的一種有效方法是,在資料集的不同子集上繪製同一圖的多個例項。
這種技術通常稱為“格子”或“網格”繪圖,它與“小倍數”的概念有關。
要使用這些功能,您的資料必須位於 Pandas DataFrame 中。
繪製資料子集的小倍數
在上一章中,我們已經看到了 FacetGrid 示例,其中 FacetGrid 類有助於視覺化一個變數的分佈以及使用多個面板分別在資料集的子集中多個變數之間的關係。
FacetGrid 可以繪製最多三個維度 - 行、列和色調。前兩個與生成的軸陣列有明顯的對應關係;將色調變數視為沿深度軸的第三個維度,其中不同級別以不同的顏色繪製。
FacetGrid物件將 DataFrame 作為輸入,以及將構成網格的行、列或色調維度的變數名稱。
變數應該是分類變數,並且變數每個級別的的資料將用於該軸上的一個面。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
g = sb.FacetGrid(df, col = "time")
plt.show()
輸出
在上面的例子中,我們只是初始化了facetgrid物件,它不會在上面繪製任何內容。
在此網格上視覺化資料的的主要方法是使用FacetGrid.map()方法。讓我們看看每個子集中小費的分佈情況,使用直方圖。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
g = sb.FacetGrid(df, col = "time")
g.map(plt.hist, "tip")
plt.show()
輸出
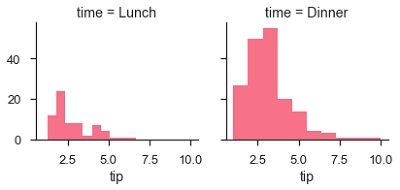
由於 col 引數,圖的數量多於一個。我們在之前的章節中討論過 col 引數。
要建立關係圖,請傳遞多個變數名稱。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
g = sb.FacetGrid(df, col = "sex", hue = "smoker")
g.map(plt.scatter, "total_bill", "tip")
plt.show()
輸出
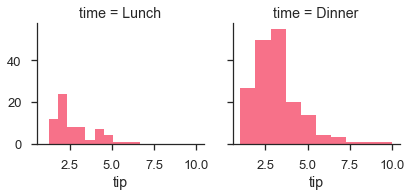
Seaborn - Pair Grid
PairGrid 允許我們使用相同的繪圖型別繪製子圖網格以視覺化資料。
與 FacetGrid 不同,它對每個子圖使用不同的變數對。它形成子圖矩陣。它有時也稱為“散點圖矩陣”。
pairgrid 的用法類似於 facetgrid。首先初始化網格,然後傳遞繪圖函式。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map(plt.scatter);
plt.show()
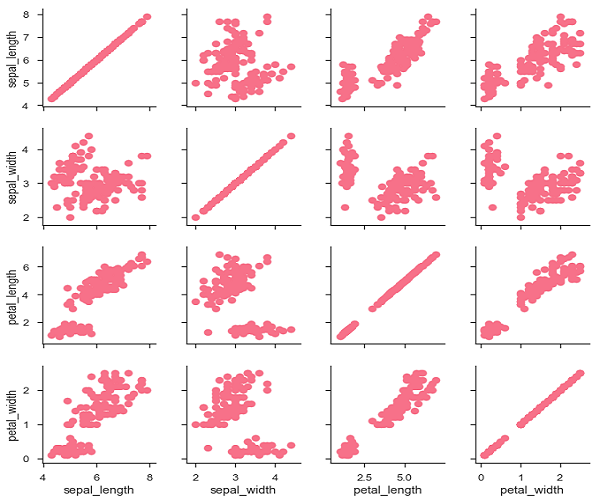
也可以在對角線上繪製不同的函式,以顯示每列中變數的單變數分佈。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map_diag(plt.hist)
g.map_offdiag(plt.scatter);
plt.show()
輸出
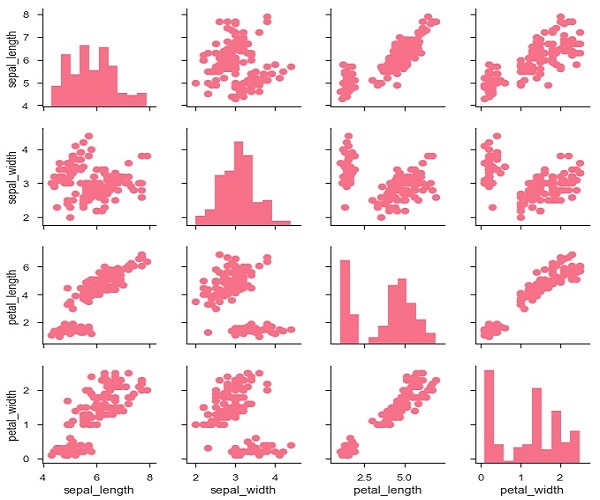
我們可以使用另一個分類變數自定義這些圖的顏色。例如,iris 資料集對三種不同的鳶尾花物種的每一種都進行了四次測量,因此您可以看到它們之間的差異。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map_diag(plt.hist)
g.map_offdiag(plt.scatter);
plt.show()
輸出
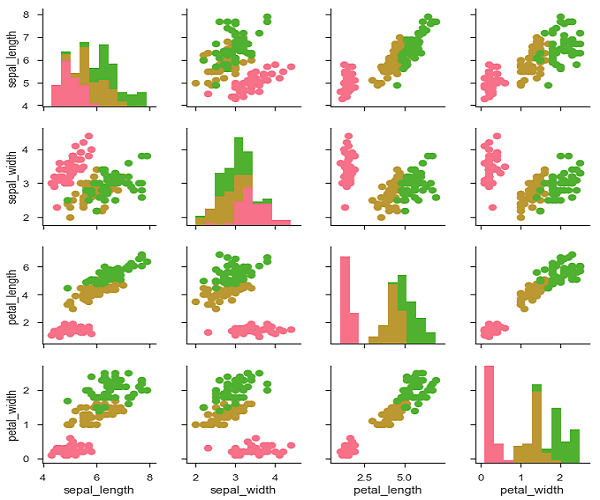
我們可以在上三角和下三角中使用不同的函式來檢視關係的不同方面。
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map_upper(plt.scatter)
g.map_lower(sb.kdeplot, cmap = "Blues_d")
g.map_diag(sb.kdeplot, lw = 3, legend = False);
plt.show()
輸出