- Elasticsearch 教程
- Elasticsearch - 首頁
- Elasticsearch - 基本概念
- Elasticsearch - 安裝
- Elasticsearch - 資料填充
- 版本遷移
- Elasticsearch - API 約定
- Elasticsearch - 文件 API
- Elasticsearch - 搜尋 API
- Elasticsearch - 聚合
- Elasticsearch - 索引 API
- Elasticsearch - CAT API
- Elasticsearch - 叢集 API
- Elasticsearch - 查詢 DSL
- Elasticsearch - 對映
- Elasticsearch - 分析
- Elasticsearch - 模組
- Elasticsearch - 索引模組
- Elasticsearch - Ingest 節點
- Elasticsearch - 管理索引生命週期
- Elasticsearch - SQL 訪問
- Elasticsearch - 監控
- Elasticsearch - 資料彙總
- Elasticsearch - 凍結索引
- Elasticsearch - 測試
- Elasticsearch - Kibana 儀表盤
- Elasticsearch - 按欄位過濾
- Elasticsearch - 資料表
- Elasticsearch - 區域地圖
- Elasticsearch - 餅圖
- Elasticsearch - 面積圖和條形圖
- Elasticsearch - 時間序列
- Elasticsearch - 標籤雲
- Elasticsearch - 熱力圖
- Elasticsearch - Canvas
- Elasticsearch - 日誌 UI
- Elasticsearch 有用資源
- Elasticsearch 快速指南
- Elasticsearch - 有用資源
- Elasticsearch - 討論
Elasticsearch 快速指南
Elasticsearch - 基本概念
Elasticsearch 是一個基於 Apache Lucene 的搜尋伺服器。它由 Shay Banon 開發,於 2010 年釋出。現在由 Elasticsearch BV 維護。其最新版本為 7.0.0。
Elasticsearch 是一個即時分散式、開源的全文搜尋和分析引擎。它可以透過 RESTful Web 服務介面訪問,並使用無模式 JSON(JavaScript 物件表示法)文件來儲存資料。它基於 Java 程式語言構建,因此 Elasticsearch 可以在不同的平臺上執行。它使使用者能夠以非常高的速度探索海量資料。
一般特性
Elasticsearch 的一般特性如下:
Elasticsearch 可擴充套件到 PB 級結構化和非結構化資料。
Elasticsearch 可用作 MongoDB 和 RavenDB 等文件儲存的替代品。
Elasticsearch 使用反規範化來提高搜尋效能。
Elasticsearch 是流行的企業搜尋引擎之一,目前被許多大型組織使用,例如維基百科、衛報、StackOverflow、GitHub 等。
Elasticsearch 是一個開源專案,根據 Apache 許可證 2.0 版釋出。
關鍵概念
Elasticsearch 的關鍵概念如下:
節點 (Node)
它指的是 Elasticsearch 的單個執行例項。單個物理和虛擬伺服器可以根據其物理資源(如 RAM、儲存和處理能力)容納多個節點。
叢集 (Cluster)
它是一個或多個節點的集合。叢集為所有節點提供整個資料的集體索引和搜尋功能。
索引 (Index)
它是一組不同型別的文件及其屬性的集合。索引還使用分片概念來提高效能。例如,一組文件包含社交網路應用程式的資料。
文件 (Document)
它是以 JSON 格式定義的特定方式排列的一組欄位的集合。每個文件屬於一個型別,並駐留在一個索引中。每個文件都與一個唯一的識別符號(稱為 UID)關聯。
分片 (Shard)
索引水平地細分為分片。這意味著每個分片包含文件的所有屬性,但包含的 JSON 物件數量少於索引。水平分離使分片成為一個獨立的節點,可以儲存在任何節點中。主分片是索引的原始水平部分,然後這些主分片被複制到副本分片中。
副本 (Replicas)
Elasticsearch 允許使用者建立其索引和分片的副本。複製不僅有助於在發生故障時提高資料的可用性,而且還透過在這些副本中執行並行搜尋操作來提高搜尋效能。
優點
Elasticsearch 基於 Java 開發,使其幾乎相容所有平臺。
Elasticsearch 是即時的,換句話說,新增的文件在一秒鐘後即可在此引擎中搜索到。
Elasticsearch 是分散式的,這使得它易於擴充套件並整合到任何大型組織中。
使用 Elasticsearch 中存在的閘道器概念可以輕鬆建立完整的備份。
與 Apache Solr 相比,Elasticsearch 中處理多租戶非常容易。
Elasticsearch 使用 JSON 物件作為響應,這使得可以使用大量不同的程式語言呼叫 Elasticsearch 伺服器。
Elasticsearch 支援幾乎所有型別的文件,除了不支援文字渲染的文件。
缺點
Elasticsearch 不支援處理請求和響應資料的多種語言(僅限於 JSON),這與 Apache Solr 不同,後者支援 CSV、XML 和 JSON 格式。
有時,Elasticsearch 會出現腦裂問題。
Elasticsearch 和 RDBMS 的比較
在 Elasticsearch 中,索引類似於 RDBMS(關係資料庫管理系統)中的表。每個表都是行的集合,就像每個索引都是 Elasticsearch 中文件的集合一樣。
下表給出了這些術語的直接比較:
| Elasticsearch | RDBMS |
|---|---|
| 叢集 (Cluster) | 資料庫 |
| 分片 (Shard) | 分片 (Shard) |
| 索引 (Index) | 表 |
| 欄位 | 列 |
| 文件 (Document) | 行 |
Elasticsearch - 安裝
在本章中,我們將詳細瞭解 Elasticsearch 的安裝過程。
要在本地計算機上安裝 Elasticsearch,您需要按照以下步驟操作:
步驟 1 - 檢查計算機上安裝的 Java 版本。它應該是 Java 7 或更高版本。您可以透過執行以下操作來檢查:
在 Windows 作業系統 (OS) 中(使用命令提示符):
> java -version
在 UNIX OS 中(使用終端):
$ echo $JAVA_HOME
步驟 2 - 根據您的作業系統,從 www.elastic.co 下載 Elasticsearch,如下所示:
對於 Windows OS,下載 ZIP 檔案。
對於 UNIX OS,下載 TAR 檔案。
對於 Debian OS,下載 DEB 檔案。
對於 Red Hat 和其他 Linux 發行版,下載 RPN 檔案。
APT 和 Yum 實用程式也可用於在許多 Linux 發行版中安裝 Elasticsearch。
步驟 3 - Elasticsearch 的安裝過程很簡單,以下是針對不同作業系統的說明:
Windows OS - 解壓縮 zip 包,Elasticsearch 就安裝好了。
UNIX OS - 將 tar 檔案解壓到任何位置,Elasticsearch 就安裝好了。
$wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch7.0.0-linux-x86_64.tar.gz $tar -xzf elasticsearch-7.0.0-linux-x86_64.tar.gz
使用 APT 實用程式安裝 Linux OS - 下載並安裝公共簽名金鑰
$ wget -qo - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
儲存如下所示的儲存庫定義:
$ echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
使用以下命令執行更新:
$ sudo apt-get update
現在,您可以使用以下命令進行安裝:
$ sudo apt-get install elasticsearch
使用此處提供的命令手動下載並安裝 Debian 包:
$wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch7.0.0-amd64.deb $sudo dpkg -i elasticsearch-7.0.0-amd64.deb0
對於 Debian Linux OS 使用 YUM 實用程式
下載並安裝公共簽名金鑰:
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
將以下文字新增到您“/etc/yum.repos.d/”目錄中帶有 .repo 字尾的檔案中。例如,elasticsearch.repo
elasticsearch-7.x] name=Elasticsearch repository for 7.x packages baseurl=https://artifacts.elastic.co/packages/7.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md
現在,您可以使用以下命令安裝 Elasticsearch
sudo yum install elasticsearch
步驟 4 - 轉到 Elasticsearch 主目錄和 bin 資料夾內。在 Windows 系統中執行 elasticsearch.bat 檔案,或者在 UNIX 系統中使用命令提示符和終端執行相同的操作來執行 Elasticsearch 檔案。
在 Windows 中
> cd elasticsearch-2.1.0/bin > elasticsearch
在 Linux 中
$ cd elasticsearch-2.1.0/bin $ ./elasticsearch
注意 - 在 Windows 系統中,您可能會收到一條錯誤訊息,指出未設定 JAVA_HOME,請在環境變數中將其設定為“C:\Program Files\Java\jre1.8.0_31”或您安裝 Java 的位置。
步驟 5 - Elasticsearch Web 介面的預設埠為 9200,或者您可以透過更改 bin 目錄中 elasticsearch.yml 檔案內的 http.port 來更改它。您可以透過瀏覽https://:9200來檢查伺服器是否已啟動並正在執行。它將返回一個 JSON 物件,其中包含以下方式安裝的 Elasticsearch 的資訊:
{
"name" : "Brain-Child",
"cluster_name" : "elasticsearch", "version" : {
"number" : "2.1.0",
"build_hash" : "72cd1f1a3eee09505e036106146dc1949dc5dc87",
"build_timestamp" : "2015-11-18T22:40:03Z",
"build_snapshot" : false,
"lucene_version" : "5.3.1"
},
"tagline" : "You Know, for Search"
}
步驟 6 - 在此步驟中,讓我們安裝 Kibana。請按照以下給出的相應程式碼在 Linux 和 Windows 上安裝:
在 Linux 上安裝:
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.0.0-linuxx86_64.tar.gz tar -xzf kibana-7.0.0-linux-x86_64.tar.gz cd kibana-7.0.0-linux-x86_64/ ./bin/kibana
在 Windows 上安裝:
從https://www.elastic.co/downloads/kibana下載 Windows 版 Kibana。單擊連結後,您將看到如下所示的主頁:
解壓縮並轉到 Kibana 主目錄,然後執行它。
CD c:\kibana-7.0.0-windows-x86_64 .\bin\kibana.bat
Elasticsearch - 資料填充
在本章中,讓我們學習如何向 Elasticsearch 新增一些索引、對映和資料。請注意,本教程中解釋的一些示例將使用這些資料。
建立索引
您可以使用以下命令建立索引:
PUT school
響應
如果建立了索引,您可以看到以下輸出:
{"acknowledged": true}
新增資料
Elasticsearch 將按照以下程式碼所示儲存我們新增到索引中的文件。文件被賦予一些 ID,這些 ID 用於標識文件。
請求正文
POST school/_doc/10
{
"name":"Saint Paul School", "description":"ICSE Afiliation",
"street":"Dawarka", "city":"Delhi", "state":"Delhi", "zip":"110075",
"location":[28.5733056, 77.0122136], "fees":5000,
"tags":["Good Faculty", "Great Sports"], "rating":"4.5"
}
響應
{
"_index" : "school",
"_type" : "_doc",
"_id" : "10",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
在這裡,我們正在新增另一個類似的文件。
POST school/_doc/16
{
"name":"Crescent School", "description":"State Board Affiliation",
"street":"Tonk Road",
"city":"Jaipur", "state":"RJ", "zip":"176114","location":[26.8535922,75.7923988],
"fees":2500, "tags":["Well equipped labs"], "rating":"4.5"
}
響應
{
"_index" : "school",
"_type" : "_doc",
"_id" : "16",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 9,
"_primary_term" : 7
}
這樣,我們將繼續新增我們在後續章節中工作所需的任何示例資料。
在 Kibana 中新增示例資料
Kibana 是一個用於訪問資料和建立視覺化的 GUI 驅動工具。在本節中,讓我們瞭解如何向其中新增示例資料。
在 Kibana 首頁,選擇以下選項以新增示例電子商務資料:

下一個螢幕將顯示一些視覺化和一個新增資料的按鈕:

單擊“新增資料”將顯示以下螢幕,確認資料已新增到名為 eCommerce 的索引中。
Elasticsearch - 版本遷移
在任何系統或軟體中,當我們升級到較新版本時,我們需要遵循一些步驟來維護應用程式設定、配置、資料和其他內容。這些步驟是必要的,以便使應用程式在新系統中保持穩定或維護資料的完整性(防止資料損壞)。
您需要遵循以下步驟來升級 Elasticsearch:
從https://www.elastic.co/閱讀升級文件
在非生產環境(例如 UAT、E2E、SIT 或 DEV 環境)中測試升級的版本。
請注意,如果沒有資料備份,則無法回滾到以前的 Elasticsearch 版本。因此,建議在升級到更高版本之前備份資料。
我們可以使用完全叢集重啟或滾動升級進行升級。滾動升級適用於新版本。請注意,當您使用滾動升級方法進行遷移時,不會發生服務中斷。
升級步驟
在升級生產叢集之前,請在開發環境中測試升級。
備份您的資料。除非您有資料的快照,否則您無法回滾到早期版本。
在開始升級過程之前,請考慮關閉機器學習作業。雖然機器學習作業可以在滾動升級期間繼續執行,但它會在升級過程中增加叢集的開銷。
按照以下順序升級 Elastic Stack 的元件:
- Elasticsearch
- Kibana
- Logstash
- Beats
- APM Server
從 6.6 或更早版本升級
要從 6.0-6.6 版本直接升級到 Elasticsearch 7.1.0,您必須手動重新索引需要繼續使用的任何 5.x 索引,並執行完全叢集重啟。
完全叢集重啟
完全叢集重啟的過程包括關閉叢集中的每個節點,將每個節點升級到 7x,然後重新啟動叢集。
以下是執行完整叢集重啟所需的高階步驟:
- 停用分片分配
- 停止索引並執行同步重新整理
- 關閉所有節點
- 升級所有節點
- 升級所有外掛
- 啟動每個已升級的節點
- 等待所有節點加入叢集並報告黃色狀態
- 重新啟用分配
重新啟用分配後,叢集開始將副本分片分配給資料節點。此時,可以安全地恢復索引和搜尋,但是如果您可以等到所有主分片和副本分片都已成功分配並且所有節點的狀態都變為綠色,則您的叢集恢復速度會更快。
Elasticsearch - API 約定
Web應用程式程式設計介面 (API) 是一組函式呼叫或其他程式設計指令,用於訪問特定 Web 應用程式中的軟體元件。例如,Facebook API 幫助開發者透過訪問 Facebook 的資料或其他功能(例如生日或狀態更新)來建立應用程式。
Elasticsearch 提供了一個 REST API,它透過 HTTP 上的 JSON 進行訪問。Elasticsearch 使用一些約定,我們現在將討論這些約定。
多個索引
API 中的大多數操作,主要是搜尋和其他操作,都是針對一個或多個索引的。這有助於使用者只需執行一次查詢即可在多個位置或所有可用資料中進行搜尋。許多不同的表示法用於在多個索引中執行操作。本章將討論其中的一些。
逗號分隔表示法
POST /index1,index2,index3/_search
請求正文
{
"query":{
"query_string":{
"query":"any_string"
}
}
}
響應
來自 index1、index2、index3 的 JSON 物件,其中包含 any_string。
_all 關鍵字用於所有索引
POST /_all/_search
請求正文
{
"query":{
"query_string":{
"query":"any_string"
}
}
}
響應
來自所有索引的 JSON 物件,其中包含 any_string。
萬用字元 (* , + , –)
POST /school*/_search
請求正文
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}
響應
所有以 school 開頭的索引中的 JSON 物件,其中包含 CBSE。
或者,您也可以使用以下程式碼:
POST /school*,-schools_gov /_search
請求正文
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}
響應
所有以“school”開頭但不是 schools_gov 的索引中的 JSON 物件,其中包含 CBSE。
還有一些 URL 查詢字串引數:
- ignore_unavailable - 如果 URL 中存在的一個或多個索引不存在,則不會發生錯誤或不會停止操作。例如,schools 索引存在,但 book_shops 不存在。
POST /school*,book_shops/_search
請求正文
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}
請求正文
{
"error":{
"root_cause":[{
"type":"index_not_found_exception", "reason":"no such index",
"resource.type":"index_or_alias", "resource.id":"book_shops",
"index":"book_shops"
}],
"type":"index_not_found_exception", "reason":"no such index",
"resource.type":"index_or_alias", "resource.id":"book_shops",
"index":"book_shops"
},"status":404
}
考慮以下程式碼:
POST /school*,book_shops/_search?ignore_unavailable = true
請求正文
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}
響應(無錯誤)
所有以 school 開頭的索引中的 JSON 物件,其中包含 CBSE。
allow_no_indices
此引數的true值將防止錯誤,如果帶有萬用字元的 URL 沒有產生任何索引。例如,沒有以 schools_pri 開頭的索引:
POST /schools_pri*/_search?allow_no_indices = true
請求正文
{
"query":{
"match_all":{}
}
}
響應(無錯誤)
{
"took":1,"timed_out": false, "_shards":{"total":0, "successful":0, "failed":0},
"hits":{"total":0, "max_score":0.0, "hits":[]}
}
expand_wildcards
此引數決定是否需要將萬用字元擴充套件到開啟的索引或關閉的索引,或同時執行兩者。此引數的值可以是 open 和 closed 或 none 和 all。
例如,關閉索引 schools:
POST /schools/_close
響應
{"acknowledged":true}
考慮以下程式碼:
POST /school*/_search?expand_wildcards = closed
請求正文
{
"query":{
"match_all":{}
}
}
響應
{
"error":{
"root_cause":[{
"type":"index_closed_exception", "reason":"closed", "index":"schools"
}],
"type":"index_closed_exception", "reason":"closed", "index":"schools"
}, "status":403
}
索引名稱中的日期數學支援
Elasticsearch 提供了一種根據日期和時間搜尋索引的功能。我們需要以特定的格式指定日期和時間。例如,accountdetail-2015.12.30 索引將儲存 2015 年 12 月 30 日的銀行賬戶詳細資訊。可以執行數學運算以獲取特定日期或日期和時間範圍的詳細資訊。
日期數學索引名稱的格式:
<static_name{date_math_expr{date_format|time_zone}}>
/<accountdetail-{now-2d{YYYY.MM.dd|utc}}>/_search
static_name 是表示式的一部分,在每個日期數學索引(如 account detail)中保持不變。date_math_expr 包含動態確定日期和時間的數學表示式,例如 now-2d。date_format 包含索引中日期的寫入格式,例如 YYYY.MM.dd。如果今天的日期是 2015 年 12 月 30 日,則
| 表示式 | 解析為 |
|---|---|
| <accountdetail-{now-d}> | accountdetail-2015.12.29 |
| <accountdetail-{now-M}> | accountdetail-2015.11.30 |
| <accountdetail-{now{YYYY.MM}}> | accountdetail-2015.12 |
現在,我們將瞭解 Elasticsearch 中可用的某些常用選項,這些選項可用於以指定格式獲取響應。
漂亮的結果
我們可以透過附加一個 URL 查詢引數 pretty = true 來獲取格式良好的 JSON 物件作為響應。
POST /schools/_search?pretty = true
請求正文
{
"query":{
"match_all":{}
}
}
響應
……………………..
{
"_index" : "schools", "_type" : "school", "_id" : "1", "_score" : 1.0,
"_source":{
"name":"Central School", "description":"CBSE Affiliation",
"street":"Nagan", "city":"paprola", "state":"HP", "zip":"176115",
"location": [31.8955385, 76.8380405], "fees":2000,
"tags":["Senior Secondary", "beautiful campus"], "rating":"3.5"
}
}
………………….
人類可讀的輸出
此選項可以將統計響應更改為人機可讀形式(如果 human = true)或計算機可讀形式(如果 human = false)。例如,如果 human = true,則 distance_kilometer = 20KM;如果 human = false,則 distance_meter = 20000,當響應需要由另一個計算機程式使用時。
響應過濾
我們可以透過在 field_path 引數中新增它們來過濾響應以減少欄位。例如,
POST /schools/_search?filter_path = hits.total
請求正文
{
"query":{
"match_all":{}
}
}
響應
{"hits":{"total":3}}
Elasticsearch - 文件 API
Elasticsearch 提供單文件 API 和多文件 API,其中 API 呼叫分別針對單個文件和多個文件。
索引 API
當向具有特定對映的相應索引發出請求時,它有助於在索引中新增或更新 JSON 文件。例如,以下請求會將 JSON 物件新增到 schools 索引和 school 對映下:
PUT schools/_doc/5
{
name":"City School", "description":"ICSE", "street":"West End",
"city":"Meerut",
"state":"UP", "zip":"250002", "location":[28.9926174, 77.692485],
"fees":3500,
"tags":["fully computerized"], "rating":"4.5"
}
執行上述程式碼後,我們將得到以下結果:
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
自動索引建立
當發出請求以將 JSON 物件新增到特定索引時,如果該索引不存在,則此 API 會自動建立該索引以及該特定 JSON 物件的基礎對映。可以透過將 elasticsearch.yml 檔案中以下引數的值更改為 false 來停用此功能。
action.auto_create_index:false index.mapper.dynamic:false
您還可以限制索引的自動建立,其中只允許具有特定模式的索引名稱,方法是更改以下引數的值:
action.auto_create_index:+acc*,-bank*
注意 - 這裡 + 表示允許,- 表示不允許。
版本控制
Elasticsearch 還提供版本控制功能。我們可以使用版本查詢引數來指定特定文件的版本。
PUT schools/_doc/5?version=7&version_type=external
{
"name":"Central School", "description":"CBSE Affiliation", "street":"Nagan",
"city":"paprola", "state":"HP", "zip":"176115", "location":[31.8955385, 76.8380405],
"fees":2200, "tags":["Senior Secondary", "beautiful campus"], "rating":"3.3"
}
執行上述程式碼後,我們將得到以下結果:
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}
版本控制是一個即時過程,不受即時搜尋操作的影響。
有兩種最重要的版本控制型別:
內部版本控制
內部版本控制是預設版本,從 1 開始,每次更新(包括刪除)都會遞增。
外部版本控制
當文件的版本控制儲存在外部系統(如第三方版本控制系統)中時使用。要啟用此功能,我們需要將 version_type 設定為 external。在這裡,Elasticsearch 將版本號儲存為外部系統指定的版本號,並且不會自動遞增它們。
操作型別
操作型別用於強制執行建立操作。這有助於避免覆蓋現有文件。
PUT chapter/_doc/1?op_type=create
{
"Text":"this is chapter one"
}
執行上述程式碼後,我們將得到以下結果:
{
"_index" : "chapter",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
自動 ID 生成
如果在索引操作中未指定 ID,則 Elasticsearch 會自動為該文件生成 ID。
POST chapter/_doc/
{
"user" : "tpoint",
"post_date" : "2018-12-25T14:12:12",
"message" : "Elasticsearch Tutorial"
}
執行上述程式碼後,我們將得到以下結果:
{
"_index" : "chapter",
"_type" : "_doc",
"_id" : "PVghWGoB7LiDTeV6LSGu",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
獲取 API
API 透過對特定文件發出獲取請求來幫助提取型別 JSON 物件。
pre class="prettyprint notranslate" > GET schools/_doc/5
執行上述程式碼後,我們將得到以下結果:
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
此操作是即時的,不受索引重新整理率的影響。
您也可以指定版本,然後 Elasticsearch 只會獲取該版本的文件。
您也可以在請求中指定 _all,以便 Elasticsearch 可以在每種型別中搜索該文件 ID,並且它將返回第一個匹配的文件。
您還可以指定您想要從該特定文件中獲取的結果中的欄位。
GET schools/_doc/5?_source_includes=name,fees
執行上述程式碼後,我們將得到以下結果:
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"fees" : 2200,
"name" : "Central School"
}
}
您也可以透過在獲取請求中新增 _source 部分來獲取結果中的源部分。
GET schools/_doc/5?_source
執行上述程式碼後,我們將得到以下結果:
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
您還可以透過將 refresh 引數設定為 true 來在執行獲取操作之前重新整理分片。
刪除 API
您可以透過向 Elasticsearch 傳送 HTTP DELETE 請求來刪除特定索引、對映或文件。
DELETE schools/_doc/4
執行上述程式碼後,我們將得到以下結果:
{
"found":true, "_index":"schools", "_type":"school", "_id":"4", "_version":2,
"_shards":{"total":2, "successful":1, "failed":0}
}
可以指定文件的版本以刪除該特定版本。可以指定路由引數以從特定使用者那裡刪除文件,如果文件不屬於該特定使用者,則操作將失敗。在此操作中,您可以指定與 GET API 相同的重新整理和超時選項。
更新 API
指令碼用於執行此操作,並且版本控制用於確保在獲取和重新索引期間沒有發生任何更新。例如,您可以使用指令碼更新學校的費用:
POST schools/_update/4
{
"script" : {
"source": "ctx._source.name = params.sname",
"lang": "painless",
"params" : {
"sname" : "City Wise School"
}
}
}
執行上述程式碼後,我們將得到以下結果:
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "4",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 2
}
您可以透過向更新後的文件傳送獲取請求來檢查更新。
Elasticsearch - 搜尋 API
此 API 用於搜尋 Elasticsearch 中的內容。使用者可以透過傳送帶有查詢字串作為引數的獲取請求來搜尋,或者他們可以在釋出請求的訊息正文中釋出查詢。主要所有搜尋 API 都是多索引、多型別的。
多索引
Elasticsearch 允許我們搜尋所有索引或某些特定索引中存在的文件。例如,如果我們需要搜尋名稱包含 central 的所有文件,我們可以按如下所示進行操作:
GET /_all/_search?q=city:paprola
執行上述程式碼後,我們將得到以下響應:
{
"took" : 33,
"timed_out" : false,
"_shards" : {
"total" : 7,
"successful" : 7,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808292,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
]
}
}
URI 搜尋
可以使用統一資源識別符號 (URI) 在搜尋操作中傳遞許多引數:
| 序號 | 引數和說明 |
|---|---|
| 1 | Q 此引數用於指定查詢字串。 |
| 2 | lenient 此引數用於指定查詢字串。透過將此引數設定為 true,可以忽略基於格式的錯誤。預設為 false。 |
| 3 | fields 此引數用於指定查詢字串。 |
| 4 | sort 我們可以使用此引數獲得排序結果,此引數的可能值為 fieldName、fieldName:asc/fieldname:desc |
| 5 | timeout 我們可以使用此引數來限制搜尋時間,並且響應僅包含在該指定時間內的命中結果。預設情況下,沒有超時。 |
| 6 | terminate_after 我們可以將響應限制為每個分片的指定數量的文件,達到該數量後,查詢將提前終止。預設情況下,沒有 terminate_after。 |
| 7 | from 要返回的命中的起始索引。預設為 0。 |
| 8 | size 它表示要返回的命中數量。預設為 10。 |
請求正文搜尋
我們也可以使用請求正文中的查詢 DSL 來指定查詢,並且前面章節中已經給出許多示例。這裡給出一個這樣的例子:
POST /schools/_search
{
"query":{
"query_string":{
"query":"up"
}
}
}
執行上述程式碼後,我們將得到以下響應:
{
"took" : 11,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.47000363,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 0.47000363,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}
Elasticsearch - 聚合
聚合框架收集搜尋查詢選擇的所有資料,幷包含許多構建塊,這些構建塊有助於構建資料的複雜摘要。聚合的基本結構如下所示:
"aggregations" : {
"" : {
"" : {
}
[,"meta" : { [] } ]?
[,"aggregations" : { []+ } ]?
}
[,"" : { ... } ]*
}
有不同型別的聚合,每種聚合都有其自身的用途。本章將詳細討論它們。
指標聚合
這些聚合有助於從聚合文件的欄位值計算矩陣,有時一些值可以從指令碼生成。
數值矩陣或者是單值的,如平均值聚合,或者是多值的,如統計聚合。
平均值聚合
此聚合用於獲取聚合文件中任何數值欄位的平均值。例如,
POST /schools/_search
{
"aggs":{
"avg_fees":{"avg":{"field":"fees"}}
}
}
執行上述程式碼後,我們將得到以下結果:
{
"took" : 41,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
},
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
},
"aggregations" : {
"avg_fees" : {
"value" : 2850.0
}
}
}
基數聚合
此聚合給出特定欄位的不同值的計數。
POST /schools/_search?size=0
{
"aggs":{
"distinct_name_count":{"cardinality":{"field":"fees"}}
}
}
執行上述程式碼後,我們將得到以下結果:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"distinct_name_count" : {
"value" : 2
}
}
}
注意 - 基數的值為 2,因為費用中有兩個不同的值。
擴充套件統計聚合
此聚合生成關於聚合文件中特定數值欄位的所有統計資訊。
POST /schools/_search?size=0
{
"aggs" : {
"fees_stats" : { "extended_stats" : { "field" : "fees" } }
}
}
執行上述程式碼後,我們將得到以下結果:
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"fees_stats" : {
"count" : 2,
"min" : 2200.0,
"max" : 3500.0,
"avg" : 2850.0,
"sum" : 5700.0,
"sum_of_squares" : 1.709E7,
"variance" : 422500.0,
"std_deviation" : 650.0,
"std_deviation_bounds" : {
"upper" : 4150.0,
"lower" : 1550.0
}
}
}
}
最大值聚合
此聚合查詢聚合文件中特定數值欄位的最大值。
POST /schools/_search?size=0
{
"aggs" : {
"max_fees" : { "max" : { "field" : "fees" } }
}
}
執行上述程式碼後,我們將得到以下結果:
{
"took" : 16,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"max_fees" : {
"value" : 3500.0
}
}
}
最小值聚合
此聚合查詢聚合文件中特定數值欄位的最小值。
POST /schools/_search?size=0
{
"aggs" : {
"min_fees" : { "min" : { "field" : "fees" } }
}
}
執行上述程式碼後,我們將得到以下結果:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"min_fees" : {
"value" : 2200.0
}
}
}
總和聚合
此聚合計算聚合文件中特定數值欄位的總和。
POST /schools/_search?size=0
{
"aggs" : {
"total_fees" : { "sum" : { "field" : "fees" } }
}
}
執行上述程式碼後,我們將得到以下結果:
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"total_fees" : {
"value" : 5700.0
}
}
}
還有一些其他指標聚合用於特殊情況,例如用於地理位置的地理邊界聚合和地理中心聚合。
統計聚合
一種多值指標聚合,它根據從聚合文件中提取的數值計算統計資料。
POST /schools/_search?size=0
{
"aggs" : {
"grades_stats" : { "stats" : { "field" : "fees" } }
}
}
執行上述程式碼後,我們將得到以下結果:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"grades_stats" : {
"count" : 2,
"min" : 2200.0,
"max" : 3500.0,
"avg" : 2850.0,
"sum" : 5700.0
}
}
}
聚合元資料
您可以使用 meta 標籤在請求時新增有關聚合的一些資料,並且可以在響應中獲取這些資料。
POST /schools/_search?size=0
{
"aggs" : {
"avg_fees" : { "avg" : { "field" : "fees" } ,
"meta" :{
"dsc" :"Lowest Fees This Year"
}
}
}
}
執行上述程式碼後,我們將得到以下結果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"avg_fees" : {
"meta" : {
"dsc" : "Lowest Fees This Year"
},
"value" : 2850.0
}
}
}
Elasticsearch - 索引 API
這些 API 負責管理索引的所有方面,例如設定、別名、對映、索引模板。
建立索引
此API幫助您建立索引。當用戶將JSON物件傳遞到任何索引時,可以自動建立索引,也可以提前建立索引。要建立索引,您只需傳送帶有設定、對映和別名(或僅包含簡單的請求體)的PUT請求。
PUT colleges
執行上述程式碼後,我們將得到如下所示的輸出:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "colleges"
}
我們還可以向上述命令新增一些設定:
PUT colleges
{
"settings" : {
"index" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
}
執行上述程式碼後,我們將得到如下所示的輸出:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "colleges"
}
刪除索引
此API幫助您刪除任何索引。您只需要使用要刪除的索引名稱傳送DELETE請求。
DELETE /colleges
您可以透過僅使用`_all`或`*`來刪除所有索引。
獲取索引
此API可以透過向一個或多個索引發送GET請求來呼叫。這將返回有關索引的資訊。
GET colleges
執行上述程式碼後,我們將得到如下所示的輸出:
{
"colleges" : {
"aliases" : {
"alias_1" : { },
"alias_2" : {
"filter" : {
"term" : {
"user" : "pkay"
}
},
"index_routing" : "pkay",
"search_routing" : "pkay"
}
},
"mappings" : { },
"settings" : {
"index" : {
"creation_date" : "1556245406616",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "3ExJbdl2R1qDLssIkwDAug",
"version" : {
"created" : "7000099"
},
"provided_name" : "colleges"
}
}
}
}
您可以使用`_all`或`*`獲取所有索引的資訊。
索引是否存在
可以透過向該索引發送GET請求來確定索引是否存在。如果HTTP響應為200,則表示存在;如果為404,則表示不存在。
HEAD colleges
執行上述程式碼後,我們將得到如下所示的輸出:
200-OK
索引設定
您可以透過在URL末尾附加`_settings`關鍵字來獲取索引設定。
GET /colleges/_settings
執行上述程式碼後,我們將得到如下所示的輸出:
{
"colleges" : {
"settings" : {
"index" : {
"creation_date" : "1556245406616",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "3ExJbdl2R1qDLssIkwDAug",
"version" : {
"created" : "7000099"
},
"provided_name" : "colleges"
}
}
}
}
索引統計資訊
此API幫助您提取有關特定索引的統計資訊。您只需傳送帶有索引URL和`_stats`關鍵字的GET請求。
GET /_stats
執行上述程式碼後,我們將得到如下所示的輸出:
………………………………………………
},
"request_cache" : {
"memory_size_in_bytes" : 849,
"evictions" : 0,
"hit_count" : 1171,
"miss_count" : 4
},
"recovery" : {
"current_as_source" : 0,
"current_as_target" : 0,
"throttle_time_in_millis" : 0
}
} ………………………………………………
重新整理
索引的重新整理過程確保當前僅持久儲存在事務日誌中的任何資料也永久持久儲存在Lucene中。這減少了恢復時間,因為在開啟Lucene索引後,不需要從事務日誌中重新索引該資料。
POST colleges/_flush
執行上述程式碼後,我們將得到如下所示的輸出:
{
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
}
}
Elasticsearch - Cat APIs
通常,各種Elasticsearch API的結果以JSON格式顯示。但JSON並不總是容易閱讀。因此,Elasticsearch 中提供了cat API功能,有助於提供更易於閱讀和理解的列印結果格式。cat API中使用了各種引數,它們具有不同的用途,例如 - `v` 引數使輸出更詳細。
讓我們在本章中更詳細地瞭解cat APIs。
詳細輸出
詳細輸出提供了cat命令結果的清晰顯示。在下面的示例中,我們獲取叢集中存在的各種索引的詳細資訊。
GET /_cat/indices?v
執行上述程式碼後,我們將得到如下所示的響應:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size yellow open schools RkMyEn2SQ4yUgzT6EQYuAA 1 1 2 1 21.6kb 21.6kb yellow open index_4_analysis zVmZdM1sTV61YJYrNXf1gg 1 1 0 0 283b 283b yellow open sensor-2018-01-01 KIrrHwABRB-ilGqTu3OaVQ 1 1 1 0 4.2kb 4.2kb yellow open colleges 3ExJbdl2R1qDLssIkwDAug 1 1 0 0 283b 283b
標題
`h`引數(也稱為header)用於僅顯示命令中提到的那些列。
GET /_cat/nodes?h=ip,port
執行上述程式碼後,我們將得到如下所示的響應:
127.0.0.1 9300
排序
sort命令接受查詢字串,該字串可以按查詢中指定的列對錶進行排序。預設排序為升序,但可以透過向列新增`:desc`來更改此設定。
下面的示例給出了按欄位索引模式降序排列的模板結果。
GET _cat/templates?v&s=order:desc,index_patterns
執行上述程式碼後,我們將得到如下所示的響應:
name index_patterns order version .triggered_watches [.triggered_watches*] 2147483647 .watch-history-9 [.watcher-history-9*] 2147483647 .watches [.watches*] 2147483647 .kibana_task_manager [.kibana_task_manager] 0 7000099
計數
count引數提供整個叢集中文件總數的計數。
GET /_cat/count?v
執行上述程式碼後,我們將得到如下所示的響應:
epoch timestamp count 1557633536 03:58:56 17809
Elasticsearch - 叢集 API
叢集API用於獲取有關叢集及其節點的資訊以及對其進行更改。要呼叫此API,我們需要指定節點名稱、地址或`_local`。
GET /_nodes/_local
執行上述程式碼後,我們將得到如下所示的響應:
………………………………………………
cluster_name" : "elasticsearch",
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"name" : "ubuntu",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1",
"version" : "7.0.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "b7e28a7",
"total_indexing_buffer" : 106502553,
"roles" : [
"master",
"data",
"ingest"
],
"attributes" : {
………………………………………………
叢集健康狀況
此API用於透過附加“health”關鍵字來獲取叢集健康狀況。
GET /_cluster/health
執行上述程式碼後,我們將得到如下所示的響應:
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 7,
"active_shards" : 7,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 4,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 63.63636363636363
}
叢集狀態
此API用於透過附加“state”關鍵字URL來獲取有關叢集的狀態資訊。狀態資訊包含版本、主節點、其他節點、路由表、元資料和塊。
GET /_cluster/state
執行上述程式碼後,我們將得到如下所示的響應:
………………………………………………
{
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IzKu0OoVTQ6LxqONJnN2eQ",
"version" : 89,
"state_uuid" : "y3BlwvspR1eUQBTo0aBjig",
"master_node" : "FKH-5blYTJmff2rJ_lQOCg",
"blocks" : { },
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"name" : "ubuntu",
"ephemeral_id" : "426kTGpITGixhEzaM-5Qyg",
"transport
}
………………………………………………
叢集統計資訊
此API透過使用“stats”關鍵字來幫助檢索有關叢集的統計資訊。此API返回分片數量、儲存大小、記憶體使用情況、節點數量、角色、作業系統和檔案系統。
GET /_cluster/stats
執行上述程式碼後,我們將得到如下所示的響應:
………………………………………….
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IzKu0OoVTQ6LxqONJnN2eQ",
"timestamp" : 1556435464704,
"status" : "yellow",
"indices" : {
"count" : 7,
"shards" : {
"total" : 7,
"primaries" : 7,
"replication" : 0.0,
"index" : {
"shards" : {
"min" : 1,
"max" : 1,
"avg" : 1.0
},
"primaries" : {
"min" : 1,
"max" : 1,
"avg" : 1.0
},
"replication" : {
"min" : 0.0,
"max" : 0.0,
"avg" : 0.0
}
………………………………………….
更新叢集設定
此API允許您使用“settings”關鍵字更新叢集的設定。有兩種型別的設定:永續性設定(在重啟後應用)和臨時設定(不會在叢集完全重啟後保留)。
節點統計資訊
此API用於檢索叢集的一個或多個節點的統計資訊。節點統計資訊幾乎與叢集統計資訊相同。
GET /_nodes/stats
執行上述程式碼後,我們將得到如下所示的響應:
{
"_nodes" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"cluster_name" : "elasticsearch",
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"timestamp" : 1556437348653,
"name" : "ubuntu",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1:9300",
"roles" : [
"master",
"data",
"ingest"
],
"attributes" : {
"ml.machine_memory" : "4112797696",
"xpack.installed" : "true",
"ml.max_open_jobs" : "20"
},
………………………………………………………….
節點熱執行緒
此API幫助您檢索叢集中每個節點上當前熱執行緒的資訊。
GET /_nodes/hot_threads
執行上述程式碼後,我們將得到如下所示的響應:
:::{ubuntu}{FKH-5blYTJmff2rJ_lQOCg}{426kTGpITGixhEzaM5Qyg}{127.0.0.1}{127.0.0.1:9300}{ml.machine_memory=4112797696,
xpack.installed=true, ml.max_open_jobs=20}
Hot threads at 2019-04-28T07:43:58.265Z, interval=500ms, busiestThreads=3,
ignoreIdleThreads=true:
Elasticsearch - 查詢 DSL
在Elasticsearch中,搜尋是使用基於JSON的查詢進行的。查詢由兩類子句組成:
葉子查詢子句 - 這些子句是匹配、術語或範圍,它們查詢特定欄位中的特定值。
複合查詢子句 - 這些查詢是葉子查詢子句和其他複合查詢的組合,用於提取所需資訊。
Elasticsearch支援大量的查詢。查詢以查詢關鍵字開頭,然後在JSON物件形式的內部包含條件和過濾器。下面描述了不同型別的查詢。
匹配所有查詢
這是最基本的查詢;它返回所有內容,每個物件的得分均為1.0。
POST /schools/_search
{
"query":{
"match_all":{}
}
}
執行上述程式碼後,我們將得到以下結果:
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
},
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}
全文查詢
這些查詢用於搜尋全文文字,例如章節或新聞文章。此查詢根據與特定索引或文件關聯的分析器工作。在本節中,我們將討論不同型別的全文查詢。
匹配查詢
此查詢將文字或短語與一個或多個欄位的值匹配。
POST /schools*/_search
{
"query":{
"match" : {
"rating":"4.5"
}
}
}
執行上述程式碼後,我們將得到如下所示的響應:
{
"took" : 44,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.47000363,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 0.47000363,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}
多欄位匹配查詢
此查詢將文字或短語與多個欄位匹配。
POST /schools*/_search
{
"query":{
"multi_match" : {
"query": "paprola",
"fields": [ "city", "state" ]
}
}
}
執行上述程式碼後,我們將得到如下所示的響應:
{
"took" : 12,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808292,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
]
}
}
查詢字串查詢
此查詢使用查詢解析器和`query_string`關鍵字。
POST /schools*/_search
{
"query":{
"query_string":{
"query":"beautiful"
}
}
}
執行上述程式碼後,我們將得到如下所示的響應:
{
"took" : 60,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
………………………………….
術語級查詢
這些查詢主要處理結構化資料,例如數字、日期和列舉。
POST /schools*/_search
{
"query":{
"term":{"zip":"176115"}
}
}
執行上述程式碼後,我們將得到如下所示的響應:
……………………………..
hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
}
}
]
…………………………………………..
範圍查詢
此查詢用於查詢具有給定值範圍內的值的objects。為此,我們需要使用以下運算子:
- gte - 大於等於
- gt - 大於
- lte - 小於等於
- lt - 小於
例如,觀察下面給出的程式碼:
POST /schools*/_search
{
"query":{
"range":{
"rating":{
"gte":3.5
}
}
}
}
執行上述程式碼後,我們將得到如下所示的響應:
{
"took" : 24,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}
還存在其他型別的術語級查詢,例如:
存在查詢 - 如果某個欄位具有非空值。
缺失查詢 - 這與存在查詢完全相反,此查詢搜尋缺少特定欄位或欄位值為null的objects。
萬用字元或正則表示式查詢 - 此查詢使用正則表示式查詢objects中的模式。
複合查詢
這些查詢是使用布林運算子(如and、or、not)或針對不同的索引或具有函式呼叫等將不同的查詢組合在一起的集合。
POST /schools/_search
{
"query": {
"bool" : {
"must" : {
"term" : { "state" : "UP" }
},
"filter": {
"term" : { "fees" : "2200" }
},
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}
執行上述程式碼後,我們將得到如下所示的響應:
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
地理查詢
這些查詢處理地理位置和地理點。這些查詢有助於查詢靠近任何位置的學校或任何其他地理物件。您需要使用地理點資料型別。
PUT /geo_example
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
}
}
}
}
執行上述程式碼後,我們將得到如下所示的響應:
{ "acknowledged" : true,
"shards_acknowledged" : true,
"index" : "geo_example"
}
現在,我們將資料釋出到上面建立的索引中。
POST /geo_example/_doc?refresh
{
"name": "Chapter One, London, UK",
"location": {
"type": "point",
"coordinates": [11.660544, 57.800286]
}
}
執行上述程式碼後,我們將得到如下所示的響應:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
"_index" : "geo_example",
"_type" : "_doc",
"_id" : "hASWZ2oBbkdGzVfiXHKD",
"_score" : 1.0,
"_source" : {
"name" : "Chapter One, London, UK",
"location" : {
"type" : "point",
"coordinates" : [
11.660544,
57.800286
]
}
}
}
}
Elasticsearch - 對映
對映是儲存在索引中的文件的輪廓。它定義了資料型別(如`geo_point`或`string`)以及文件中存在的欄位的格式,以及控制動態新增欄位的對映的規則。
PUT bankaccountdetails
{
"mappings":{
"properties":{
"name": { "type":"text"}, "date":{ "type":"date"},
"balance":{ "type":"double"}, "liability":{ "type":"double"}
}
}
}
執行上述程式碼後,我們將得到如下所示的響應:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "bankaccountdetails"
}
欄位資料型別
Elasticsearch支援多種不同的文件欄位資料型別。此處詳細討論了用於在Elasticsearch中儲存欄位的資料型別。
核心資料型別
這些是幾乎所有系統都支援的基本資料型別,例如文字、關鍵字、日期、長整型、雙精度浮點型、布林型或IP地址。
複雜資料型別
這些資料型別是核心資料型別的組合。這些包括陣列、JSON物件和巢狀資料型別。下面顯示了巢狀資料型別的示例:
POST /tabletennis/_doc/1
{
"group" : "players",
"user" : [
{
"first" : "dave", "last" : "jones"
},
{
"first" : "kevin", "last" : "morris"
}
]
}
執行上述程式碼後,我們將得到如下所示的響應:
{
"_index" : "tabletennis",
"_type" : "_doc",
"_id" : "1",
_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
下面顯示了另一個示例程式碼:
POST /accountdetails/_doc/1
{
"from_acc":"7056443341", "to_acc":"7032460534",
"date":"11/1/2016", "amount":10000
}
執行上述程式碼後,我們將得到如下所示的響應:
{ "_index" : "accountdetails",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
我們可以使用以下命令檢查上述文件:
GET /accountdetails/_mappings?include_type_name=false
移除對映型別
在Elasticsearch 7.0.0或更高版本中建立的索引不再接受`_default_`對映。在Elasticsearch 6.x中建立的6.x索引將繼續像以前一樣工作。7.0中的API已棄用型別。
Elasticsearch - 分析
在搜尋操作期間處理查詢時,任何索引中的內容都將由分析模組進行分析。此模組包含分析器、標記器、標記過濾器和字元過濾器。如果未定義分析器,則預設情況下,內建的分析器、標記、過濾器和標記器將與分析模組註冊。
在以下示例中,我們使用標準分析器,該分析器在未指定其他分析器時使用。它將根據語法分析句子並生成句子中使用的詞。
POST _analyze
{
"analyzer": "standard",
"text": "Today's weather is beautiful"
}
執行上述程式碼後,我們將得到如下所示的響應:
{
"tokens" : [
{
"token" : "today's",
"start_offset" : 0,
"end_offset" : 7,
"type" : "",
"position" : 0
},
{
"token" : "weather",
"start_offset" : 8,
"end_offset" : 15,
"type" : "",
"position" : 1
},
{
"token" : "is",
"start_offset" : 16,
"end_offset" : 18,
"type" : "",
"position" : 2
},
{
"token" : "beautiful",
"start_offset" : 19,
"end_offset" : 28,
"type" : "",
"position" : 3
}
]
}
配置標準分析器
我們可以使用各種引數配置標準分析器以滿足我們的自定義需求。
在以下示例中,我們將標準分析器的`max_token_length`配置為5。
為此,我們首先建立一個具有`max_length_token`引數的分析器的索引。
PUT index_4_analysis
{
"settings": {
"analysis": {
"analyzer": {
"my_english_analyzer": {
"type": "standard",
"max_token_length": 5,
"stopwords": "_english_"
}
}
}
}
}
接下來,我們將分析器應用於如下所示的文字。請注意,標記沒有出現,因為它開頭有兩個空格,結尾也有兩個空格。對於單詞“is”,它前面有一個空格,後面有一個空格。把它們加起來,它就變成了帶有空格的4個字母,這並不能算作一個單詞。至少開頭或結尾必須有一個非空格字元,才能將其計為一個單詞。
POST index_4_analysis/_analyze
{
"analyzer": "my_english_analyzer",
"text": "Today's weather is beautiful"
}
執行上述程式碼後,我們將得到如下所示的響應:
{
"tokens" : [
{
"token" : "today",
"start_offset" : 0,
"end_offset" : 5,
"type" : "",
"position" : 0
},
{
"token" : "s",
"start_offset" : 6,
"end_offset" : 7,
"type" : "",
"position" : 1
},
{
"token" : "weath",
"start_offset" : 8,
"end_offset" : 13,
"type" : "",
"position" : 2
},
{
"token" : "er",
"start_offset" : 13,
"end_offset" : 15,
"type" : "",
"position" : 3
},
{
"token" : "beaut",
"start_offset" : 19,
"end_offset" : 24,
"type" : "",
"position" : 5
},
{
"token" : "iful",
"start_offset" : 24,
"end_offset" : 28,
"type" : "",
"position" : 6
}
]
}
下表列出了各種分析器及其說明:
| 序號 | 分析器和說明 |
|---|---|
| 1 |
標準分析器 (standard) 可以為此分析器設定`stopwords`和`max_token_length`設定。預設情況下,`stopwords`列表為空,`max_token_length`為255。 |
| 2 |
簡單分析器 (simple) 此分析器由小寫標記器組成。 |
| 3 |
空格分析器 (whitespace) 此分析器由空格標記器組成。 |
| 4 |
停用詞分析器 (stop) 可以配置`stopwords`和`stopwords_path`。預設情況下,`stopwords`初始化為英語停用詞,`stopwords_path`包含停用詞文字檔案的路徑。 |
標記器
標記器用於在Elasticsearch中從文字生成標記。透過考慮空格或其他標點符號,可以將文字分解成標記。Elasticsearch有很多內建標記器,這些標記器可以用於自定義分析器。
下面顯示了一個標記器的示例,該標記器每當遇到非字母字元時就會將文字分解成術語,但它還會將所有術語小寫:
POST _analyze
{
"tokenizer": "lowercase",
"text": "It Was a Beautiful Weather 5 Days ago."
}
執行上述程式碼後,我們將得到如下所示的響應:
{
"tokens" : [
{
"token" : "it",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "was",
"start_offset" : 3,
"end_offset" : 6,
"type" : "word",
"position" : 1
},
{
"token" : "a",
"start_offset" : 7,
"end_offset" : 8,
"type" : "word",
"position" : 2
},
{
"token" : "beautiful",
"start_offset" : 9,
"end_offset" : 18,
"type" : "word",
"position" : 3
},
{
"token" : "weather",
"start_offset" : 19,
"end_offset" : 26,
"type" : "word",
"position" : 4
},
{
"token" : "days",
"start_offset" : 29,
"end_offset" : 33,
"type" : "word",
"position" : 5
},
{
"token" : "ago",
"start_offset" : 34,
"end_offset" : 37,
"type" : "word",
"position" : 6
}
]
}
下表列出了標記器及其說明:
| 序號 | 標記器和說明 |
|---|---|
| 1 |
標準標記器 (standard) 這是基於語法的標記器,可以為此標記器配置`max_token_length`。 |
| 2 |
邊際NGram標記器 (edgeNGram) 可以為此標記器設定`min_gram`、`max_gram`、`token_chars`等設定。 |
| 3 |
關鍵字標記器 (keyword) 這會將整個輸入作為輸出生成,並且可以為此設定`buffer_size`。 |
| 4 |
字母標記器 (letter) 這會捕獲整個單詞,直到遇到非字母字元。 |
Elasticsearch - 模組
Elasticsearch由許多模組組成,這些模組負責其功能。這些模組有兩種型別的設定:
靜態設定 - 這些設定需要在啟動Elasticsearch之前在配置檔案(elasticsearch.yml)中進行配置。您需要更新叢集中的所有相關節點以反映這些設定的更改。
動態設定 - 這些設定可以在活動的Elasticsearch上設定。
我們將在本章的後續部分討論Elasticsearch的不同模組。
叢集級路由和分片分配
叢集級設定決定了將分片分配給不同的節點以及重新分配分片以重新平衡叢集。以下是控制分片分配的設定。
叢集級分片分配
| 設定 | 可能的值 | 說明 |
|---|---|---|
| cluster.routing.allocation.enable | ||
| all | 此預設值允許對所有型別的分片進行分片分配。 | |
| primaries | 這僅允許對主分片進行分片分配。 | |
| new_primaries | 這僅允許為新索引分配主分片。 | |
| 無 | 這不允許任何分片分配。 | |
| cluster.routing.allocation.node_concurrent_recoveries | 數值(預設為 2) | 這限制了併發分片恢復的數量。 |
| cluster.routing.allocation.node_initial_primaries_recoveries | 數值(預設為 4) | 這限制了並行初始主分片恢復的數量。 |
| cluster.routing.allocation.same_shard.host | 布林值(預設為 false) | 這限制了在同一物理節點上分配多個相同分片的副本。 |
| indices.recovery.concurrent_streams | 數值(預設為 3) | 這控制了在從對等分片恢復分片時,每個節點開啟的網路流的數量。 |
| indices.recovery.concurrent_small_file_streams | 數值(預設為 2) | 這控制了在分片恢復期間,每個節點為大小小於 5MB 的小檔案開啟的流的數量。 |
| cluster.routing.rebalance.enable | ||
| all | 此預設值允許對所有型別的分片進行平衡。 | |
| primaries | 這僅允許對主分片進行分片平衡。 | |
| replicas | 這僅允許對副本分片進行分片平衡。 | |
| 無 | 這不允許任何型別的分片平衡。 | |
| cluster.routing.allocation.allow_rebalance | ||
| always | 此預設值始終允許重新平衡。 | |
| indices_primaries_active | 當叢集中所有主分片都已分配時,這允許重新平衡。 | |
| indices_all_active | 當所有主分片和副本分片都已分配時,這允許重新平衡。 | |
| cluster.routing.allocation.cluster_concurrent_rebalance | 數值(預設為 2) | 這限制了叢集中併發分片平衡的數量。 |
| cluster.routing.allocation.balance.shard | 浮點值(預設為 0.45f) | 這定義了分配在每個節點上的分片的權重因子。 |
| cluster.routing.allocation.balance.index | 浮點值(預設為 0.55f) | 這定義了分配在特定節點上的每個索引的分片數量的比率。 |
| cluster.routing.allocation.balance.threshold | 非負浮點值(預設為 1.0f) | 這是應執行的操作的最小最佳化值。 |
基於磁碟的分片分配
| 設定 | 可能的值 | 說明 |
|---|---|---|
| cluster.routing.allocation.disk.threshold_enabled | 布林值(預設為 true) | 這啟用和停用磁碟分配決策器。 |
| cluster.routing.allocation.disk.watermark.low | 字串值(預設為 85%) | 這表示磁碟的最大使用率;超過此點後,將不會再有其他分片分配到該磁碟。 |
| cluster.routing.allocation.disk.watermark.high | 字串值(預設為 90%) | 這表示分配時的最大使用率;如果在分配時達到此點,則 Elasticsearch 將會將該分片分配到另一個磁碟。 |
| cluster.info.update.interval | 字串值(預設為 30s) | 這是磁碟使用情況檢查之間的間隔。 |
| cluster.routing.allocation.disk.include_relocations | 布林值(預設為 true) | 這決定了在計算磁碟使用率時是否考慮當前正在分配的分片。 |
發現
此模組幫助叢集發現並維護其所有節點的狀態。當從叢集中新增或刪除節點時,叢集狀態會發生變化。叢集名稱設定用於建立不同叢集之間的邏輯差異。有一些模組可以幫助您使用雲供應商提供的 API,如下所示:
- Azure 發現
- EC2 發現
- Google Compute Engine 發現
- Zen 發現
閘道器
此模組維護叢集狀態和跨叢集完全重啟的分片資料。以下是此模組的靜態設定:
| 設定 | 可能的值 | 說明 |
|---|---|---|
| gateway.expected_nodes | 數值(預設為 0) | 預期在叢集中存在的節點數量,用於恢復本地分片。 |
| gateway.expected_master_nodes | 數值(預設為 0) | 在開始恢復之前,預期在叢集中存在的 master 節點數量。 |
| gateway.expected_data_nodes | 數值(預設為 0) | 在開始恢復之前,預期在叢集中存在的資料節點數量。 |
| gateway.recover_after_time | 字串值(預設為 5m) | 這是磁碟使用情況檢查之間的間隔。 |
| cluster.routing.allocation.disk.include_relocations | 布林值(預設為 true) | 這指定了恢復過程將等待開始的時間,而不管加入叢集的節點數量是多少。 gateway.recover_after_nodes |
HTTP
此模組管理 HTTP 客戶端和 Elasticsearch API 之間的通訊。可以透過將 http.enabled 的值更改為 false 來停用此模組。
以下是控制此模組的設定(在 elasticsearch.yml 中配置):
| 序號 | 設定和描述 |
|---|---|
| 1 | http.port 這是訪問 Elasticsearch 的埠,範圍為 9200-9300。 |
| 2 | http.publish_port 此埠用於 HTTP 客戶端,在防火牆情況下也很有用。 |
| 3 | http.bind_host 這是 HTTP 服務的主機地址。 |
| 4 | http.publish_host 這是 HTTP 客戶端的主機地址。 |
| 5 | http.max_content_length 這是 HTTP 請求中內容的最大大小。其預設值為 100MB。 |
| 6 | http.max_initial_line_length 這是 URL 的最大大小,其預設值為 4KB。 |
| 7 | http.max_header_size 這是最大的 HTTP 標頭大小,其預設值為 8KB。 |
| 8 | http.compression 這啟用或停用對壓縮的支援,其預設值為 false。 |
| 9 | http.pipelining 這啟用或停用 HTTP 管道。 |
| 10 | http.pipelining.max_events 這限制了在關閉 HTTP 請求之前要排隊的事件數。 |
索引
此模組維護為每個索引全域性設定的設定。以下設定主要與記憶體使用有關:
斷路器
這用於防止操作導致 OutOfMemoryError。該設定主要限制 JVM 堆大小。例如,indices.breaker.total.limit 設定,預設為 JVM 堆的 70%。
欄位資料快取
這主要在對欄位進行聚合時使用。建議有足夠的記憶體來分配它。可以使用 indices.fielddata.cache.size 設定來控制欄位資料快取使用的記憶體量。
節點查詢快取
此記憶體用於快取查詢結果。此快取使用最近最少使用 (LRU) 逐出策略。Indices.queries.cache.size 設定控制此快取的記憶體大小。
索引緩衝區
此緩衝區儲存索引中新建立的文件,並在緩衝區已滿時重新整理它們。諸如 indices.memory.index_buffer_size 之類的設定控制為此緩衝區分配的堆量。
分片請求快取
此快取用於儲存每個分片的本地搜尋資料。可以在建立索引期間啟用快取,也可以透過傳送 URL 引數來停用快取。
Disable cache - ?request_cache = true Enable cache "index.requests.cache.enable": true
索引恢復
它控制恢復過程中的資源。以下是設定:
| 設定 | 預設值 |
|---|---|
| indices.recovery.concurrent_streams | 3 |
| indices.recovery.concurrent_small_file_streams | 2 |
| indices.recovery.file_chunk_size | 512kb |
| indices.recovery.translog_ops | 1000 |
| indices.recovery.translog_size | 512kb |
| indices.recovery.compress | true |
| indices.recovery.max_bytes_per_sec | 40mb |
TTL 間隔
生存時間 (TTL) 間隔定義文件的時間,在此時間之後文件將被刪除。以下是控制此過程的動態設定:
| 設定 | 預設值 |
|---|---|
| indices.ttl.interval | 60s |
| indices.ttl.bulk_size | 1000 |
節點 (Node)
每個節點可以選擇是否為資料節點。您可以透過更改 **node.data** 設定來更改此屬性。將值設定為 **false** 表示該節點不是資料節點。
Elasticsearch - 索引模組
這些是為每個索引建立的模組,它們控制索引的設定和行為。例如,索引可以使用多少分片,或者主分片可以為此索引有多少個副本等。索引設定有兩種型別:
- **靜態** - 這些只能在索引建立時或在關閉的索引上設定。
- **動態** - 這些可以在活動索引上更改。
靜態索引設定
下表顯示靜態索引設定的列表:
| 設定 | 可能的值 | 說明 |
|---|---|---|
| index.number_of_shards | 預設為 5,最大 1024 | 索引應具有的主分片數量。 |
| index.shard.check_on_startup | 預設為 false。可以為 True | 是否應在開啟之前檢查分片是否存在損壞。 |
| index.codec | LZ4 壓縮。 | 用於儲存資料的壓縮型別。 |
| index.routing_partition_size | 1 | 自定義路由值可以到達的分片數量。 |
| index.load_fixed_bitset_filters_eagerly | false | 指示是否為巢狀查詢預載入快取的過濾器 |
動態索引設定
下表顯示動態索引設定的列表:
| 設定 | 可能的值 | 說明 |
|---|---|---|
| index.number_of_replicas | 預設為 1 | 每個主分片擁有的副本數量。 |
| index.auto_expand_replicas | 以短橫線分隔的下限和上限 (0-5) | 根據叢集中的資料節點數量自動擴充套件副本數量。 |
| index.search.idle.after | 30 秒 | 分片在被認為搜尋空閒之前不能接收搜尋或獲取請求的時間長度。 |
| index.refresh_interval | 1 秒 | 執行重新整理操作的頻率,這使得對索引的最新更改對搜尋可見。 |
Elasticsearch - Ingest 節點
| index.blocks.read_only | 1 true/false | 設定為 true 可使索引和索引元資料只讀,設定為 false 可允許寫入和元資料更改。 |
有時我們需要在索引文件之前對其進行轉換。例如,我們想從文件中刪除一個欄位或重新命名一個欄位,然後對其進行索引。這由 Ingest 節點處理。
叢集中的每個節點都具有攝取能力,但也可以自定義為僅由特定節點處理。
涉及的步驟
Ingest 節點的執行涉及兩個步驟:
- 建立管道
- 建立文件
建立管道
首先建立一個包含處理器的管道,然後執行該管道,如下所示:
PUT _ingest/pipeline/int-converter
{
"description": "converts the content of the seq field to an integer",
"processors" : [
{
"convert" : {
"field" : "seq",
"type": "integer"
}
}
]
}
執行上述程式碼後,我們將得到以下結果:
{
"acknowledged" : true
}
建立文件
接下來,我們使用管道轉換器建立一個文件。
PUT /logs/_doc/1?pipeline=int-converter
{
"seq":"21",
"name":"Tutorialspoint",
"Addrs":"Hyderabad"
}
執行上述程式碼後,我們將得到如下所示的響應:
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
接下來,我們使用GET命令搜尋上面建立的文件,如下所示:
GET /logs/_doc/1
執行上述程式碼後,我們將得到以下結果:
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"Addrs" : "Hyderabad",
"name" : "Tutorialspoint",
"seq" : 21
}
}
您可以看到上面21已經變成了整數。
無管道
現在我們建立一個不使用管道的文件。
PUT /logs/_doc/2
{
"seq":"11",
"name":"Tutorix",
"Addrs":"Secunderabad"
}
GET /logs/_doc/2
執行上述程式碼後,我們將得到以下結果:
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"seq" : "11",
"name" : "Tutorix",
"Addrs" : "Secunderabad"
}
}
您可以看到上面11在不使用管道的情況下是一個字串。
Elasticsearch - 管理索引生命週期
索引生命週期管理涉及根據分片大小和效能要求等因素執行管理操作。索引生命週期管理 (ILM) API 使您可以自動化您希望如何隨著時間的推移管理索引。
本章列出了 ILM API 及其用法。
策略管理 API
| API 名稱 | 用途 | 示例 |
|---|---|---|
| 建立生命週期策略。 | 建立一個生命週期策略。如果指定的策略存在,則替換該策略並遞增策略版本。 | PUT _ilm/policy/policy_id |
| 獲取生命週期策略。 | 返回指定的策略定義。包括策略版本和上次修改日期。如果未指定策略,則返回所有已定義的策略。 | GET _ilm/policy/policy_id |
| 刪除生命週期策略 | 刪除指定的生命週期策略定義。您不能刪除當前正在使用的策略。如果策略正在用於管理任何索引,則請求失敗並返回錯誤。 | DELETE _ilm/policy/policy_id |
索引管理 API
| API 名稱 | 用途 | 示例 |
|---|---|---|
| 移動到生命週期步驟 API。 | 手動將索引移動到指定的步驟並執行該步驟。 | POST _ilm/move/index |
| 重試策略。 | 將策略設定回發生錯誤的步驟並執行該步驟。 | POST index/_ilm/retry |
| 從索引 API 編輯中刪除策略。 | 刪除分配的生命週期策略並停止管理指定的索引。如果指定了索引模式,則從所有匹配的索引中刪除分配的策略。 | POST index/_ilm/remove |
操作管理 API
| API 名稱 | 用途 | 示例 |
|---|---|---|
| 獲取索引生命週期管理狀態 API。 | 返回 ILM 外掛的狀態。響應中的 operation_mode 欄位顯示三種狀態之一:STARTED、STOPPING 或 STOPPED。 | GET /_ilm/status |
| 啟動索引生命週期管理 API。 | 如果 ILM 外掛當前已停止,則啟動它。叢集形成時會自動啟動 ILM。 | POST /_ilm/start |
| 停止索引生命週期管理 API。 | 停止所有生命週期管理操作並停止 ILM 外掛。當您對叢集執行維護並需要阻止 ILM 對您的索引執行任何操作時,這很有用。 | POST /_ilm/stop |
| 解釋生命週期 API。 | 檢索有關索引當前生命週期狀態的資訊,例如當前正在執行的階段、操作和步驟。顯示索引何時進入每個階段,正在執行的階段的定義以及有關任何故障的資訊。 | GET index/_ilm/explain |
Elasticsearch - SQL 訪問
它是一個元件,允許對 Elasticsearch 執行類似 SQL 的即時查詢。您可以將 Elasticsearch SQL 視為一個轉換器,它既瞭解 SQL 也瞭解 Elasticsearch,並且可以輕鬆地透過利用 Elasticsearch 的功能來即時、大規模地讀取和處理資料。
Elasticsearch SQL 的優勢
它具有原生整合 - 每個查詢都根據底層儲存有效地針對相關節點執行。
無需外部元件 - 無需額外的硬體、程序、執行時或庫來查詢 Elasticsearch。
輕量級且高效 - 它採用並公開 SQL 以允許即時進行適當的全文搜尋。
示例
PUT /schoollist/_bulk?refresh
{"index":{"_id": "CBSE"}}
{"name": "GleanDale", "Address": "JR. Court Lane", "start_date": "2011-06-02",
"student_count": 561}
{"index":{"_id": "ICSE"}}
{"name": "Top-Notch", "Address": "Gachibowli Main Road", "start_date": "1989-
05-26", "student_count": 482}
{"index":{"_id": "State Board"}}
{"name": "Sunshine", "Address": "Main Street", "start_date": "1965-06-01",
"student_count": 604}
執行上述程式碼後,我們將得到如下所示的響應:
{
"took" : 277,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "CBSE",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "ICSE",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "State Board",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
}
]
}
SQL 查詢
以下示例顯示了我們如何構建 SQL 查詢:
POST /_sql?format=txt
{
"query": "SELECT * FROM schoollist WHERE start_date < '2000-01-01'"
}
執行上述程式碼後,我們將得到如下所示的響應:
Address | name | start_date | student_count --------------------+---------------+------------------------+--------------- Gachibowli Main Road|Top-Notch |1989-05-26T00:00:00.000Z|482 Main Street |Sunshine |1965-06-01T00:00:00.000Z|604
注意 - 透過更改上面的 SQL 查詢,您可以獲得不同的結果集。
Elasticsearch - 監控
為了監控叢集的健康狀況,監控功能會從每個節點收集指標並將其儲存在 Elasticsearch 索引中。與 Elasticsearch 中的監控相關的所有設定必須在每個節點的 elasticsearch.yml 檔案中設定,或者在可能的情況下,在動態叢集設定中設定。
為了啟動監控,我們需要檢查叢集設定,可以透過以下方式完成:
GET _cluster/settings
{
"persistent" : { },
"transient" : { }
}
堆疊中的每個元件負責監控自身,然後將這些文件轉發到 Elasticsearch 生產叢集以進行路由和索引(儲存)。Elasticsearch 中的路由和索引過程由稱為收集器和匯出器的元件處理。
收集器
收集器每隔一個收集間隔執行一次,以從它選擇監控的 Elasticsearch 中的公共 API 獲取資料。資料收集完成後,資料將批次交給匯出器傳送到監控叢集。
每種收集的資料型別只有一個收集器。每個收集器可以建立零個或多個監控文件。
匯出器
匯出器獲取從任何 Elastic Stack 源收集的資料並將其路由到監控叢集。可以配置多個匯出器,但常規和預設設定是使用單個匯出器。匯出器可以在節點和叢集級別進行配置。
Elasticsearch 中有兩種型別的匯出器:
本地 - 此匯出器將資料路由回同一叢集
HTTP - 首選的匯出器,您可以使用它將資料路由到任何透過 HTTP 可訪問的支援的 Elasticsearch 叢集。
在匯出器可以路由監控資料之前,它們必須設定某些 Elasticsearch 資源。這些資源包括模板和攝取管道
Elasticsearch - 資料彙總
彙總作業是一個定期任務,它會彙總索引模式指定的索引中的資料,並將其彙總到新的索引中。在下面的示例中,我們建立一個名為 sensor 的索引,其中包含不同的日期時間戳。然後,我們建立一個彙總作業,使用 cron 作業定期彙總這些索引中的資料。
PUT /sensor/_doc/1
{
"timestamp": 1516729294000,
"temperature": 200,
"voltage": 5.2,
"node": "a"
}
執行上述程式碼後,我們將得到以下結果:
{
"_index" : "sensor",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
現在,新增第二個文件,其他文件也如此。
PUT /sensor-2018-01-01/_doc/2
{
"timestamp": 1413729294000,
"temperature": 201,
"voltage": 5.9,
"node": "a"
}
建立彙總作業
PUT _rollup/job/sensor
{
"index_pattern": "sensor-*",
"rollup_index": "sensor_rollup",
"cron": "*/30 * * * * ?",
"page_size" :1000,
"groups" : {
"date_histogram": {
"field": "timestamp",
"interval": "60m"
},
"terms": {
"fields": ["node"]
}
},
"metrics": [
{
"field": "temperature",
"metrics": ["min", "max", "sum"]
},
{
"field": "voltage",
"metrics": ["avg"]
}
]
}
cron 引數控制作業何時以及多久啟用一次。當彙總作業的 cron 計劃觸發時,它將從上次啟用後停止的地方開始彙總。
作業執行並處理一些資料後,我們可以使用 DSL 查詢進行一些搜尋。
GET /sensor_rollup/_rollup_search
{
"size": 0,
"aggregations": {
"max_temperature": {
"max": {
"field": "temperature"
}
}
}
}
Elasticsearch - 凍結索引
頻繁搜尋的索引儲存在記憶體中,因為重建它們需要時間,並且有助於高效搜尋。另一方面,可能有一些我們很少訪問的索引。這些索引不需要佔用記憶體,可以在需要時重建。此類索引稱為凍結索引。
Elasticsearch 在每次搜尋凍結索引的每個分片時都會構建該分片的瞬態資料結構,並在搜尋完成後立即丟棄這些資料結構。因為 Elasticsearch 不在記憶體中維護這些瞬態資料結構,所以凍結索引消耗的堆記憶體比普通索引少得多。這允許比否則可能更高的磁碟與堆比率。
凍結和解凍示例
以下示例凍結和解凍索引:
POST /index_name/_freeze POST /index_name/_unfreeze
凍結索引上的搜尋預計執行速度較慢。凍結索引並非用於高搜尋負載。即使在索引未凍結時相同的搜尋在幾毫秒內完成,凍結索引的搜尋也可能需要幾秒鐘或幾分鐘才能完成。
搜尋凍結索引
每個節點併發載入的凍結索引數量受 search_throttled 執行緒池中的執行緒數限制,預設為 1。要包含凍結索引,必須使用查詢引數執行搜尋請求:_ignore_throttled=false。
GET /index_name/_search?q=user:tpoint&ignore_throttled=false
監控凍結索引
凍結索引是使用搜索限制和記憶體高效分片實現的普通索引。
GET /_cat/indices/index_name?v&h=i,sth
Elasticsearch - 測試
Elasticsearch 提供一個 jar 檔案,可以新增到任何 Java IDE 中,並可用於測試與 Elasticsearch 相關的程式碼。可以使用 Elasticsearch 提供的框架執行一系列測試。在本章中,我們將詳細討論這些測試:
- 單元測試
- 整合測試
- 隨機測試
前提條件
要開始測試,您需要將 Elasticsearch 測試依賴項新增到您的程式中。您可以為此目的使用 maven,並在 pom.xml 中新增以下內容。
<dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>2.1.0</version> </dependency>
EsSetup 已初始化以啟動和停止 Elasticsearch 節點以及建立索引。
EsSetup esSetup = new EsSetup();
帶有 createIndex 的 esSetup.execute() 函式將建立索引,您需要指定設定、型別和資料。
單元測試
單元測試是使用 JUnit 和 Elasticsearch 測試框架進行的。可以使用 Elasticsearch 類建立節點和索引,並且可以在測試方法中用於執行測試。ESTestCase 和 ESTokenStreamTestCase 類用於此測試。
整合測試
整合測試在叢集中使用多個節點。ESIntegTestCase 類用於此測試。有各種方法可以使準備測試用例的工作更容易。
| 序號 | 方法和說明 |
|---|---|
| 1 |
refresh() 重新整理叢集中的所有索引 |
| 2 |
ensureGreen() 確保綠色健康叢集狀態 |
| 3 |
ensureYellow() 確保黃色健康叢集狀態 |
| 4 |
createIndex(name) 建立具有傳遞給此方法的名稱的索引 |
| 5 |
flush() 重新整理叢集中的所有索引 |
| 6 |
flushAndRefresh() flush() 和 refresh() |
| 7 |
indexExists(name) 驗證指定索引的存在 |
| 8 |
clusterService() 返回叢集服務 Java 類 |
| 9 |
cluster() 返回測試叢集類 |
測試叢集方法
| 序號 | 方法和說明 |
|---|---|
| 1 |
ensureAtLeastNumNodes(n) 確保叢集中至少啟動的節點數大於或等於指定數量。 |
| 2 |
ensureAtMostNumNodes(n) 確保叢集中最多啟動的節點數小於或等於指定數量。 |
| 3 |
stopRandomNode() 停止叢集中的隨機節點 |
| 4 |
stopCurrentMasterNode() 停止主節點 |
| 5 |
stopRandomNonMaster() 停止叢集中的隨機節點(不是主節點)。 |
| 6 |
buildNode() 建立一個新節點 |
| 7 |
startNode(settings) 啟動一個新節點 |
| 8 |
nodeSettings() 重寫此方法以更改節點設定。 |
訪問客戶端
客戶端用於訪問叢集中的不同節點並執行某些操作。ESIntegTestCase.client() 方法用於獲取隨機客戶端。Elasticsearch 還提供其他訪問客戶端的方法,這些方法可以使用 ESIntegTestCase.internalCluster() 方法訪問。
| 序號 | 方法和說明 |
|---|---|
| 1 |
iterator() 這有助於您訪問所有可用的客戶端。 |
| 2 |
masterClient() 這返回一個與主節點通訊的客戶端。 |
| 3 |
nonMasterClient() 這返回一個不與主節點通訊的客戶端。 |
| 4 |
clientNodeClient() 這返回當前在客戶端節點上執行的客戶端。 |
隨機化測試
此測試用於使用所有可能的資料測試使用者程式碼,以便將來不會出現任何型別的資料故障。隨機資料是執行此測試的最佳選擇。
生成隨機資料
在此測試中,Random 類由 RandomizedTest 提供的例項例項化,並提供許多用於獲取不同型別資料的方法。
| 方法 | 返回值 |
|---|---|
| getRandom() | 隨機類的例項 |
| randomBoolean() | 隨機布林值 |
| randomByte() | 隨機位元組 |
| randomShort() | 隨機短整型 |
| randomInt() | 隨機整數 |
| randomLong() | 隨機長整型 |
| randomFloat() | 隨機浮點數 |
| randomDouble() | 隨機雙精度浮點數 |
| randomLocale() | 隨機區域設定 |
| randomTimeZone() | 隨機時區 |
| randomFrom() | 陣列中的隨機元素 |
斷言
ElasticsearchAssertions 和 ElasticsearchGeoAssertions 類包含斷言,這些斷言用於在測試時執行一些常見的檢查。例如,觀察此處給出的程式碼:
SearchResponse seearchResponse = client().prepareSearch();
assertHitCount(searchResponse, 6);
assertFirstHit(searchResponse, hasId("6"));
assertSearchHits(searchResponse, "1", "2", "3", "4",”5”,”6”);
Elasticsearch - Kibana 儀表盤
Kibana 儀表板是視覺化和搜尋的集合。您可以安排、調整大小和編輯儀表板內容,然後儲存儀表板以便共享。在本章中,我們將瞭解如何建立和編輯儀表板。
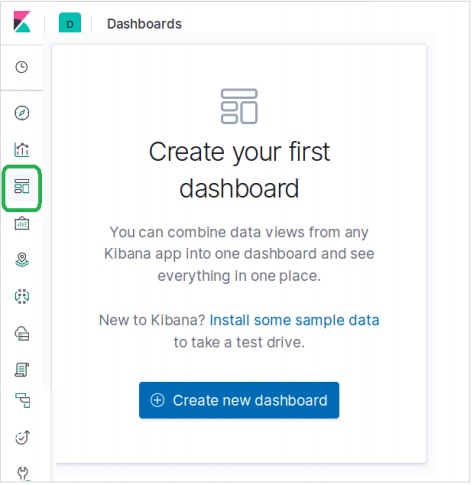
儀表板建立
在 Kibana 首頁,從左側控制欄中選擇儀表板選項,如下所示。這將提示您建立一個新的儀表板。
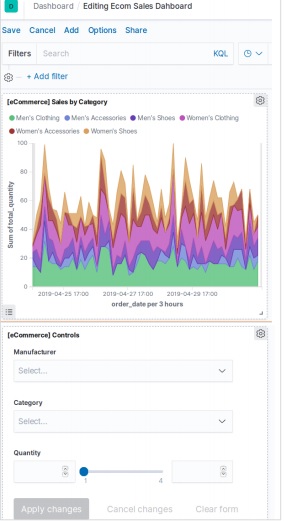
要將視覺化新增到儀表板,我們選擇“新增”選單,然後從可用的預構建視覺化中進行選擇。我們從列表中選擇了以下視覺化選項。

選擇上述視覺化後,我們將獲得如下所示的儀表板。我們以後可以新增和編輯儀表板以更改元素和新增新元素。
檢查元素
我們可以透過選擇視覺化面板選單並選擇“**檢查**”來檢查儀表板元素。這將顯示元素背後的資料,這些資料也可以下載。

共享儀表板
我們可以透過選擇“共享”選單並選擇獲取超連結的選項來共享儀表板,如下所示:
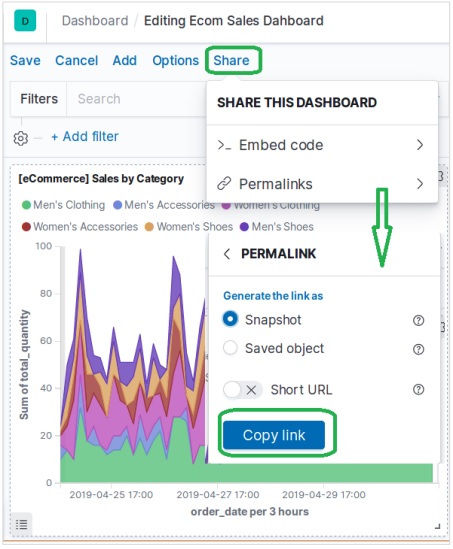
Elasticsearch - 按欄位過濾
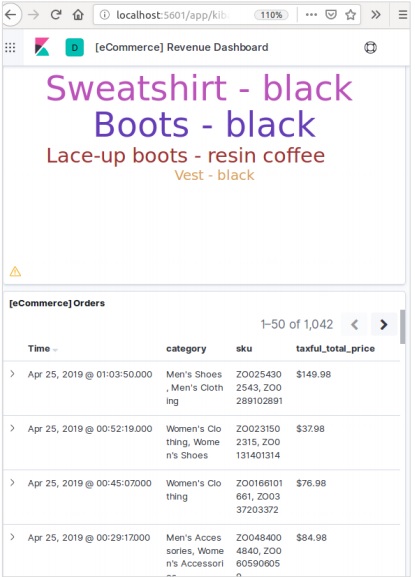
Kibana 首頁中提供的發現功能允許我們從各個角度探索資料集。您可以搜尋和過濾所選索引模式的資料。資料通常以一段時間內值的分佈形式提供。
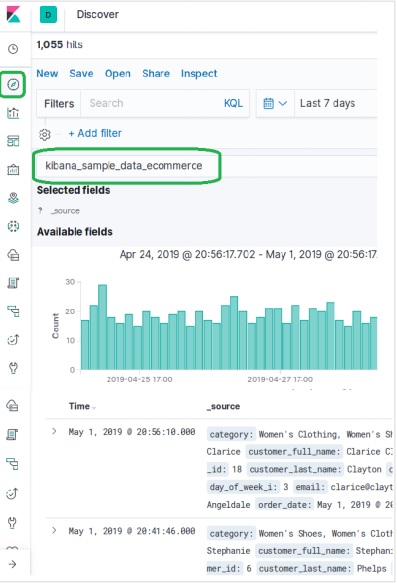
要探索電子商務資料樣本,我們點選下圖所示的“**發現**”圖示。這將顯示資料以及圖表。
按時間過濾
要按特定時間間隔過濾資料,我們使用如下所示的時間過濾器選項。預設情況下,過濾器設定為 15 分鐘。
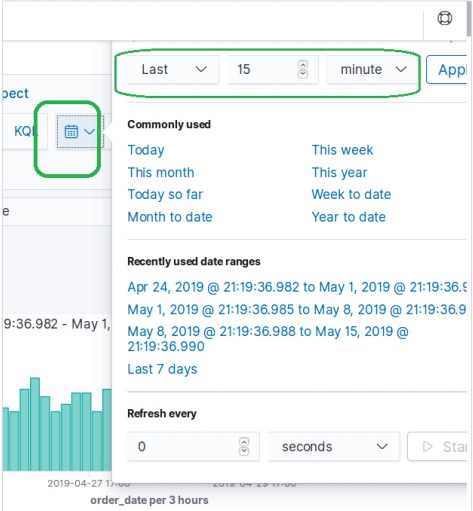
按欄位過濾
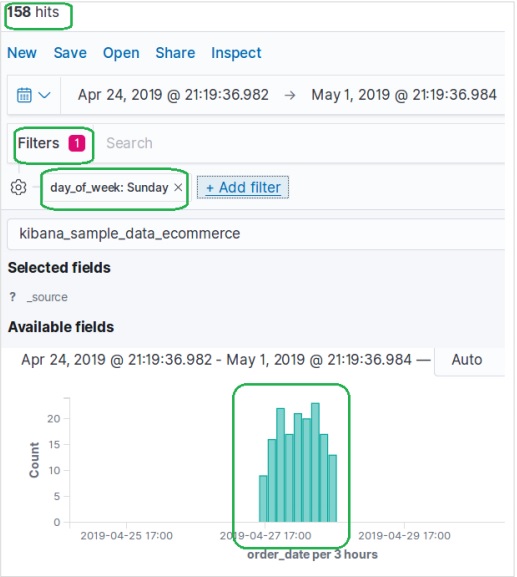
也可以使用如下所示的“**新增過濾器**”選項按欄位過濾資料集。在這裡,我們新增一個或多個欄位,並在應用過濾器後獲得相應的結果。在我們的示例中,我們選擇欄位“day_of_week”,然後選擇該欄位的運算子為“is”,值為“Sunday”。
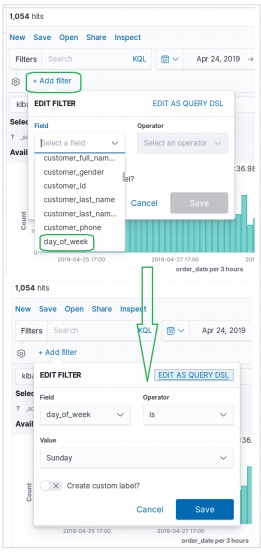
接下來,我們使用上述過濾器條件儲存。包含已應用過濾器條件的結果集如下所示。
Elasticsearch - 資料表
資料表是一種視覺化型別,用於顯示組合聚合的原始資料。使用資料表呈現各種型別的聚合。為了建立資料表,我們應該詳細瞭解此處討論的步驟。
視覺化
在 Kibana 主螢幕中,我們找到名為“視覺化”的選項,它允許我們根據儲存在 Elasticsearch 中的索引建立視覺化和聚合。下圖顯示了該選項。
選擇資料表
接下來,我們從各種可用的視覺化選項中選擇“資料表”選項。該選項顯示在下圖中:

選擇指標
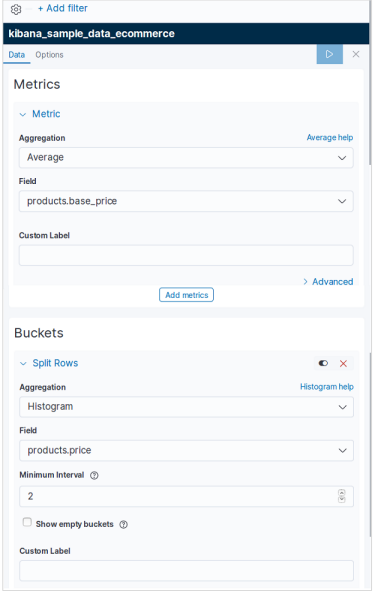
然後,我們選擇建立資料表視覺化所需的指標。此選擇決定我們將使用的聚合型別。我們為此從電子商務資料集中選擇以下特定欄位。
執行上述資料表配置後,我們將獲得如下所示的結果:

Elasticsearch - 區域地圖
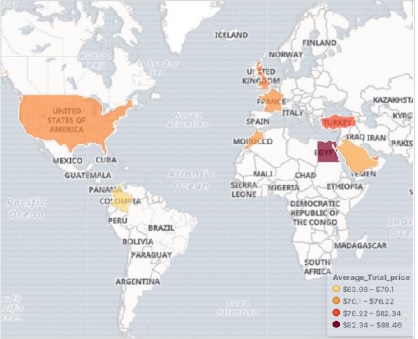
區域地圖在地理地圖上顯示指標。它有助於檢視錨定到不同地理區域的資料,強度各異。較深的陰影通常表示較高的值,較淺的陰影表示較低的值。
建立此視覺化的步驟如下所述:
視覺化
在此步驟中,我們轉到 Kibana 主螢幕左側欄中可用的“視覺化”按鈕,然後選擇新增新視覺化的選項。
以下螢幕顯示了我們如何選擇區域地圖選項。
選擇指標
下一個螢幕提示我們選擇將用於建立區域地圖的指標。在這裡,我們選擇平均價格作為指標,並將 country_iso_code 作為將用於建立視覺化的桶中的欄位。
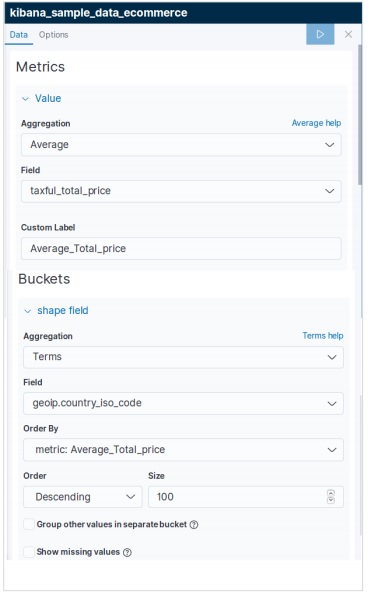
應用選擇後,最終結果(如下所示)顯示了區域地圖。請注意顏色的陰影及其在標籤中提到的值。
Elasticsearch - 餅圖
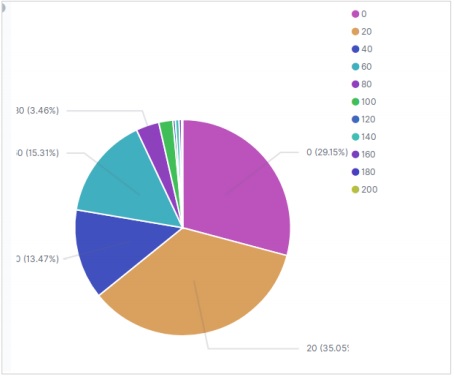
餅圖是最簡單和最著名的視覺化工具之一。它將資料表示為圓的切片,每個切片顏色不同。標籤以及百分比資料值可以與圓一起顯示。圓也可以採用甜甜圈的形狀。
視覺化
在 Kibana 主螢幕中,我們找到名為“視覺化”的選項,它允許我們根據儲存在 Elasticsearch 中的索引建立視覺化和聚合。我們選擇新增新的視覺化,並選擇餅圖作為如下所示的選項。

選擇指標
下一個螢幕提示我們選擇將用於建立餅圖的指標。在這裡,我們選擇基本單位價格的數量作為指標,並將桶聚合作為直方圖。此外,最小間隔選擇為 20。因此,價格將顯示為以 20 為範圍的值塊。
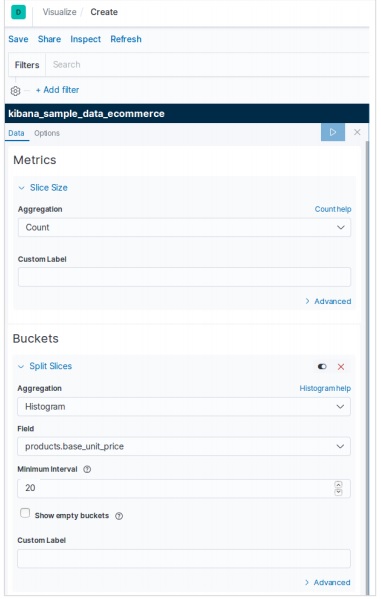
應用選擇後,結果(如下所示)顯示了餅圖。請注意顏色的陰影及其在標籤中提到的值。
餅圖選項
轉到餅圖下的選項選項卡後,我們可以看到各種配置選項,可以更改餅圖的外觀以及資料顯示的排列方式。在下面的示例中,餅圖顯示為甜甜圈,標籤顯示在頂部。

Elasticsearch - 面積圖和條形圖
面積圖是折線圖的擴充套件,其中折線圖與軸之間的區域用某些顏色突出顯示。條形圖表示組織成一定範圍的值的資料,然後相對於軸繪製。它可以包含水平條形或垂直條形。
在本章中,我們將看到所有這三種圖表型別,這些圖表型別是使用 Kibana 建立的。正如前面章節中所討論的,我們將繼續使用電子商務索引中的資料。
面積圖
在 Kibana 主螢幕中,我們找到名為“視覺化”的選項,它允許我們根據儲存在 Elasticsearch 中的索引建立視覺化和聚合。我們選擇新增新的視覺化,並選擇面積圖作為下圖所示的選項。
選擇指標
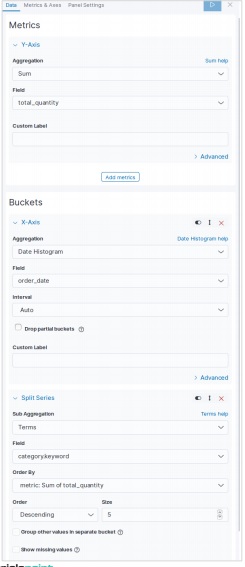
下一個螢幕提示我們選擇將用於建立面積圖的指標。在這裡,我們選擇 sum 作為聚合指標的型別。然後,我們選擇 total_quantity 欄位作為要用作指標的欄位。在 X 軸上,我們選擇 order_date 欄位,並以 5 的大小分割帶有給定指標的序列。
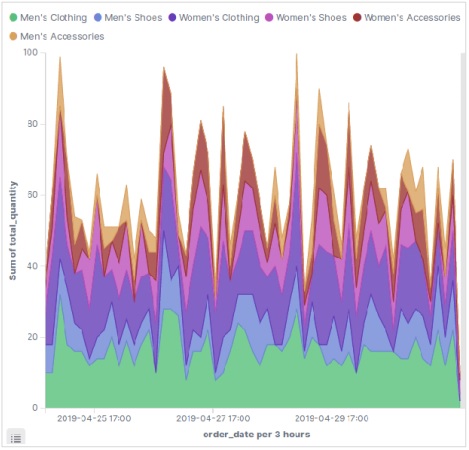
執行上述配置後,我們將獲得以下面積圖作為輸出:
水平條形圖
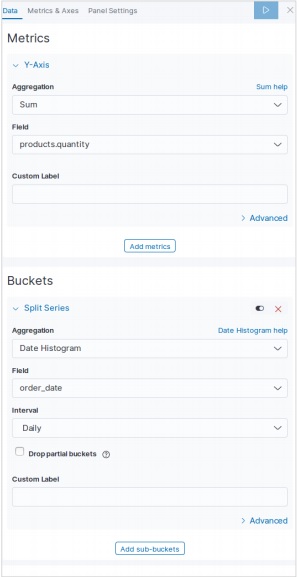
同樣,對於水平條形圖,我們從 Kibana 主螢幕選擇新的視覺化,然後選擇水平條形圖的選項。然後,我們選擇如下影像所示的指標。在這裡,我們選擇 Sum 作為名為 product quantity 的欄位的聚合。然後,我們為 order date 欄位選擇帶有日期直方圖的桶。
執行上述配置後,我們可以看到如下所示的水平條形圖:
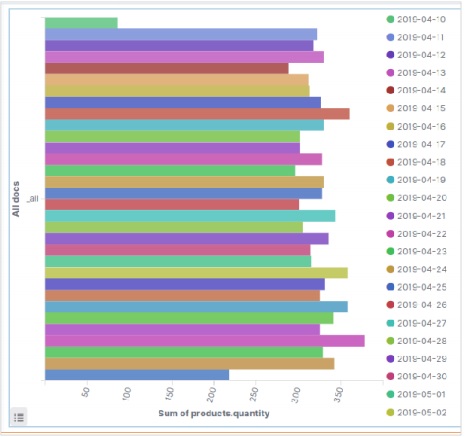
垂直條形圖
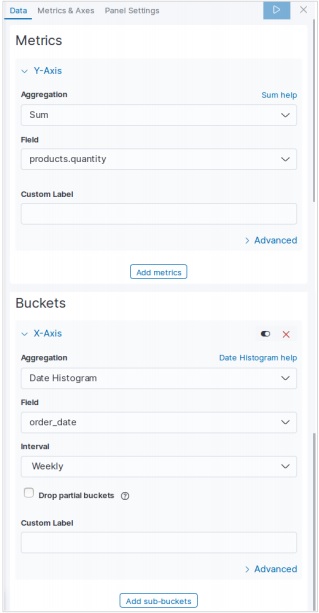
對於垂直條形圖,我們從 Kibana 主螢幕選擇新的視覺化,然後選擇垂直條形的選項。然後,我們選擇如下影像所示的指標。
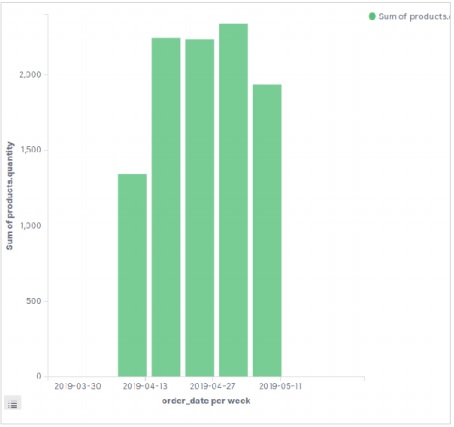
在這裡,我們選擇 Sum 作為名為 product quantity 的欄位的聚合。然後,我們為 order date 欄位選擇帶有日期直方圖的桶,間隔為每週。
執行上述配置後,將生成如下所示的圖表:
Elasticsearch - 時間序列
時間序列是在特定時間序列中表示資料序列的表示。例如,從月份的第一天到最後一天的每天資料。資料點之間的間隔保持不變。任何包含時間成分的資料集都可以表示為時間序列。
在本章中,我們將使用示例電子商務資料集並繪製每天訂單數量以建立時間序列。
選擇指標
首先,我們選擇將用於建立時間序列的索引模式、資料欄位和間隔。從示例電子商務資料集中,我們選擇 order_date 作為欄位,並將 1d 作為間隔。我們使用“面板選項”選項卡來做出這些選擇。此外,我們將此選項卡中的其他值保留為預設值,以便獲得時間序列的預設顏色和格式。

在“資料”選項卡中,我們選擇 count 作為聚合選項,將 group by 選項設定為 everything,併為時間序列圖表新增標籤。
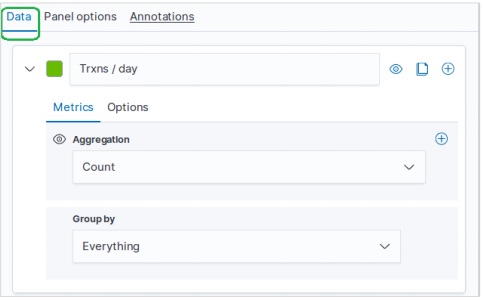
結果
此配置的最終結果如下所示。請注意,我們在此圖表中使用的是“本月至今”的時間段。不同的時間段將給出不同的結果。

Elasticsearch - 標籤雲
標籤雲以視覺上吸引人的形式表示文字,這些文字主要是關鍵字和元資料。它們以不同的角度排列,並以不同的顏色和字型大小表示。它有助於找出資料中最突出的術語。突出程度可以由一個或多個因素決定,例如術語的頻率、標籤的唯一性或附加到特定術語的權重等。下面我們將看到建立標籤雲的步驟。
視覺化
在 Kibana 主介面,我們找到名為“視覺化”的選項,它允許我們根據 Elasticsearch 中儲存的索引建立視覺化和聚合。我們選擇新增一個新的視覺化,並選擇“標籤雲”作為選項,如下所示:

選擇指標
下一個螢幕提示我們選擇用於建立標籤雲的指標。在這裡,我們選擇“計數”作為聚合指標的型別。然後,我們選擇“productname”欄位作為要用於標籤的關鍵字。
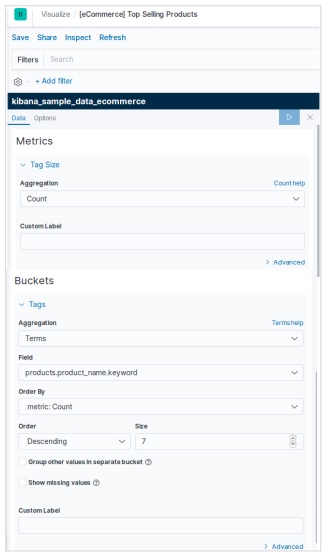
應用選擇後,此處顯示的結果為餅圖。請注意顏色陰影及其在標籤中提到的值。

標籤雲選項
在標籤雲下的“選項”選項卡中,我們可以看到各種配置選項,可以更改標籤雲中資料顯示的外觀和排列方式。在下面的示例中,標籤雲中的標籤橫向和縱向分佈。

Elasticsearch - 熱力圖
熱力圖是一種視覺化型別,其中不同的顏色陰影代表圖表中的不同區域。值可能連續變化,因此顏色的陰影會隨著值的變化而變化。它們非常有用,可以表示連續變化的資料和離散資料。
在本章中,我們將使用名為 sample_data_flights 的資料集來構建熱力圖。在其中,我們考慮航班的“出發國家”和“到達國家”變數並進行計數。
在 Kibana 主介面,我們找到名為“視覺化”的選項,它允許我們根據 Elasticsearch 中儲存的索引建立視覺化和聚合。我們選擇新增一個新的視覺化,並選擇“熱力圖”作為選項,如下所示:

選擇指標
下一個螢幕提示我們選擇用於建立熱力圖的指標。在這裡,我們選擇“計數”作為聚合指標的型別。然後對於 Y 軸的桶,我們為“OriginCountry”欄位選擇“Terms”作為聚合。對於 X 軸,我們選擇相同的聚合,但使用“DestCountry”作為欄位。在這兩種情況下,我們都將桶的大小選擇為 5。
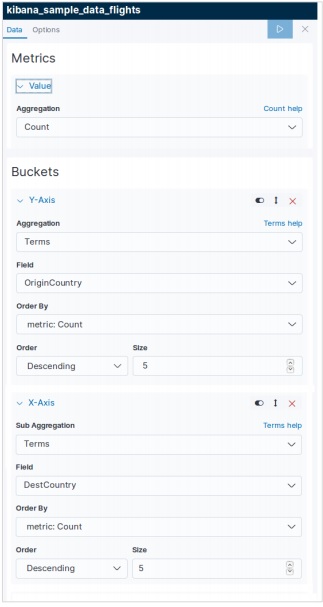
執行上述配置後,我們將生成如下所示的熱力圖。
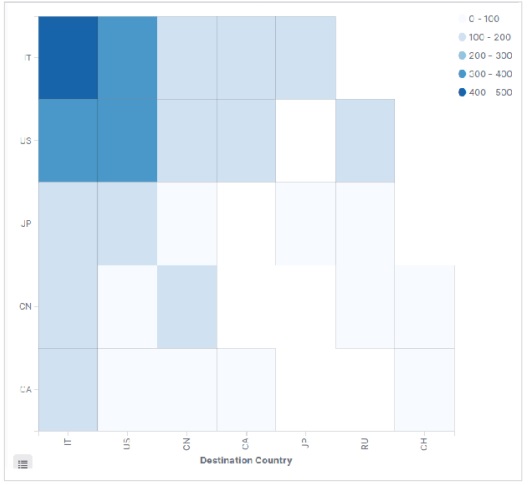
注意 - 您必須將日期範圍設定為“今年”,以便圖表收集一年的資料以生成有效的熱力圖。
Elasticsearch - Canvas
Canvas 應用程式是 Kibana 的一部分,它允許我們建立動態的、多頁面的、畫素完美的數 據顯示。它能夠建立資訊圖表,而不僅僅是圖表和指標,這使其獨一無二且引人注目。在本章中,我們將瞭解 Canvas 的各種功能以及如何使用 Canvas 工作區。
開啟 Canvas
轉到 Kibana 首頁,選擇如下所示的選項。它將開啟您擁有的 Canvas 工作區列表。我們選擇“電商收入追蹤”用於我們的研究。
克隆工作區
我們克隆“[電商]收入追蹤”工作區以用於我們的研究。要克隆它,我們突出顯示此工作區名稱的行,然後使用克隆按鈕,如下面的圖表所示:

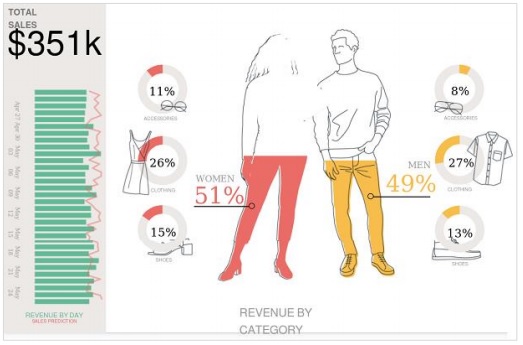
透過上述克隆操作,我們將獲得一個名為“[電商]收入追蹤 - 副本”的新工作區,開啟後將顯示下面的資訊圖表。
它描述了按類別劃分的總銷售額和收入,以及精美的圖片和圖表。
修改工作區
我們可以使用右側選項卡中提供的選項來更改工作區中的樣式和圖形。在這裡,我們旨在透過選擇不同的顏色來更改工作區的背景顏色,如下面的圖表所示。顏色選擇會立即生效,我們得到的結果如下所示:

Elasticsearch - 日誌 UI
Kibana 還可以幫助視覺化來自各種來源的日誌資料。日誌是分析基礎設施健康狀況、效能需求和安全漏洞分析等的重要來源。Kibana 可以連線到各種日誌,例如 Web 伺服器日誌、Elasticsearch 日誌和 CloudWatch 日誌等。
Logstash 日誌
在 Kibana 中,我們可以連線到 Logstash 日誌進行視覺化。首先,我們從 Kibana 主螢幕選擇“日誌”按鈕,如下所示:
然後,我們選擇“更改源配置”選項,這將使我們能夠選擇 Logstash 作為源。下面的螢幕還顯示了我們作為日誌源的其他型別的選項。
您可以流式傳輸資料以進行即時日誌尾隨,或暫停流式傳輸以關注歷史日誌資料。當您流式傳輸日誌時,最新的日誌將顯示在控制檯底部。
如需更多參考,您可以參考我們的 Logstash 教程。