- 演算法設計與分析
- 首頁
- 演算法基礎
- DAA - 演算法導論
- DAA - 演算法分析
- DAA - 分析方法
- DAA - 漸進符號與先驗分析
- DAA - 時間複雜度
- DAA - 主定理
- DAA - 空間複雜度
- 分治法
- DAA - 分治演算法
- DAA - 最大最小問題
- DAA - 歸併排序演算法
- DAA - Strassen 矩陣乘法
- DAA - Karatsuba 演算法
- DAA - 漢諾塔問題
- 貪心演算法
- DAA - 貪心演算法
- DAA - 旅行商問題
- DAA - Prim 最小生成樹
- DAA - Kruskal 最小生成樹
- DAA - Dijkstra 最短路徑演算法
- DAA - 地圖著色演算法
- DAA - 分數揹包問題
- DAA - 帶截止日期的作業排序
- DAA - 最優合併模式
- 動態規劃
- DAA - 動態規劃
- DAA - 矩陣鏈乘法
- DAA - Floyd-Warshall 演算法
- DAA - 0-1 揹包問題
- DAA - 最長公共子序列演算法
- DAA - 使用動態規劃的旅行商問題
- 隨機化演算法
- DAA - 隨機化演算法
- DAA - 隨機快速排序演算法
- DAA - Karger 最小割演算法
- DAA - Fisher-Yates 洗牌演算法
- 近似演算法
- DAA - 近似演算法
- DAA - 頂點覆蓋問題
- DAA - 集合覆蓋問題
- DAA - 旅行商問題近似演算法
- 排序技術
- DAA - 氣泡排序演算法
- DAA - 插入排序演算法
- DAA - 選擇排序演算法
- DAA - 希爾排序演算法
- DAA - 堆排序演算法
- DAA - 桶排序演算法
- DAA - 計數排序演算法
- DAA - 基數排序演算法
- DAA - 快速排序演算法
- 搜尋技術
- DAA - 搜尋技術簡介
- DAA - 線性搜尋
- DAA - 二分搜尋
- DAA - 插值搜尋
- DAA - 跳躍搜尋
- DAA - 指數搜尋
- DAA - 斐波那契搜尋
- DAA - 子列表搜尋
- DAA - 雜湊表
- 圖論
- DAA - 最短路徑
- DAA - 多階段圖
- DAA - 最優代價二叉搜尋樹
- 堆演算法
- DAA - 二叉堆
- DAA - 插入方法
- DAA - 堆化方法
- DAA - 提取方法
- 複雜度理論
- DAA - 確定性計算與非確定性計算
- DAA - 最大團
- DAA - 頂點覆蓋
- DAA - P 類和 NP 類
- DAA - 庫克定理
- DAA - NP-Hard 和 NP-Complete 類
- DAA - 爬山演算法
- DAA 有用資源
- DAA - 快速指南
- DAA - 有用資源
- DAA - 討論
二叉堆的設計與分析

堆有很多種型別,但在本章中,我們將討論二叉堆。二叉堆是一種資料結構,它看起來類似於一棵完全二叉樹。堆資料結構遵循下面討論的排序屬性。通常,堆用陣列表示。在本章中,我們用H表示堆。
由於堆的元素儲存在陣列中,假設起始索引為1,則第i個元素的父節點的位置可以在⌊ i/2 ⌋找到。第i個節點的左孩子和右孩子分別位於2i和2i + 1的位置。
根據排序屬性,二叉堆可以進一步分類為最大堆或最小堆。
最大堆
在這種堆中,節點的鍵值大於或等於其最高子節點的鍵值。
因此,H[Parent(i)] ≥ H[i]
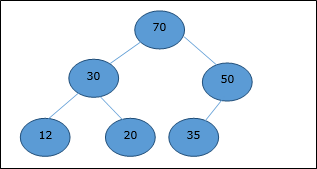
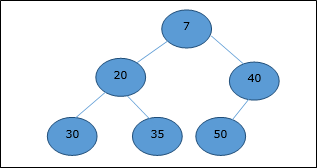
最小堆
在最小堆中,節點的鍵值小於或等於其最低子節點的鍵值。
因此,H[Parent(i)] ≤ H[i]
在本例中,基本操作如下所示,針對最大堆。在堆中插入和刪除元素需要重新排列元素。因此,需要呼叫堆化函式。
陣列表示
完全二叉樹可以用陣列表示,使用層序遍歷儲存其元素。
讓我們考慮一個堆(如下所示),它將由陣列H表示。
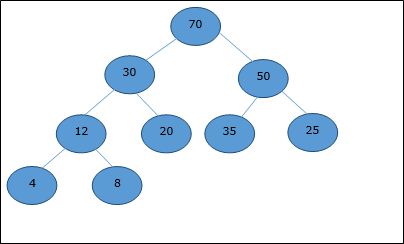
假設起始索引為0,使用層序遍歷,元素按如下方式儲存在陣列中。
| 索引 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ... |
| 元素 | 70 | 30 | 50 | 12 | 20 | 35 | 25 | 4 | 8 | ... |
在本例中,堆上的操作針對最大堆進行表示。
要查詢索引為i的元素的父節點的索引,使用以下演算法Parent (numbers[], i)。
Algorithm: Parent (numbers[], i) if i == 1 return NULL else [i / 2]
可以使用以下演算法Left-Child (numbers[], i)查詢索引為i的元素的左孩子的索引。
Algorithm: Left-Child (numbers[], i) If 2 * i ≤ heapsize return [2 * i] else return NULL
可以使用以下演算法Right-Child(numbers[], i)查詢索引為i的元素的右孩子的索引。
Algorithm: Right-Child (numbers[], i) if 2 * i < heapsize return [2 * i + 1] else return NULL
廣告