- SAS 教程
- SAS - 首頁
- SAS - 概述
- SAS - 環境
- SAS - 使用者介面
- SAS - 程式結構
- SAS - 基本語法
- SAS - 資料集
- SAS - 變數
- SAS - 字串
- SAS - 陣列
- SAS - 數字格式
- SAS - 運算子
- SAS - 迴圈
- SAS - 決策
- SAS - 函式
- SAS - 輸入方法
- SAS - 宏
- SAS - 日期和時間
- SAS 資料集操作
- SAS - 讀取原始資料
- SAS - 寫入資料集
- SAS - 合併資料集
- SAS - 合併資料集
- SAS - 子集資料集
- SAS - 排序資料集
- SAS - 格式化資料集
- SAS - SQL
- SAS - 輸出交付系統
- SAS - 模擬
- SAS 基本統計過程
- SAS - 算術平均數
- SAS - 標準差
- SAS - 頻率分佈
- SAS - 交叉表
- SAS - T檢驗
- SAS - 相關分析
- SAS - 線性迴歸
- SAS - Bland-Altman 分析
- SAS - 卡方檢驗
- SAS - Fisher 精確檢驗
- SAS - 重複測量分析
- SAS - 單因素方差分析
- SAS - 假設檢驗
- SAS 有用資源
- SAS - 快速指南
- SAS - 有用資源
- SAS - 常見問題解答
- SAS - 討論
SAS - 快速指南
SAS - 概述
SAS 代表 Statistical Analysis Software(統計分析軟體)。它由 SAS Institute 於 1960 年建立。從 1960 年 1 月 1 日起,SAS 用於資料管理、商業智慧、預測分析、描述性和規範性分析等。從那時起,軟體中引入了許多新的統計程式和元件。
隨著 JMP(Jump)統計軟體的引入,SAS 利用了 Macintosh 引入的圖形使用者介面。Jump 主要用於六西格瑪、設計、質量控制以及工程和科學分析等應用。
SAS 是平臺無關的,這意味著您可以在任何作業系統上執行 SAS,無論是 Linux 還是 Windows。SAS 由 SAS 程式設計師驅動,他們在 SAS 資料集上使用一系列操作來建立用於資料分析的正確報告。
多年來,SAS 已在其產品組合中增加了眾多解決方案。它提供了資料治理、資料質量、大資料分析、文字挖掘、欺詐管理、健康科學等方面的解決方案。我們可以安全地假設 SAS 針對每個業務領域都提供解決方案。
要了解可用的產品列表,您可以訪問 SAS 元件
我們為什麼要使用 SAS
SAS 主要用於處理大型資料集。藉助 SAS 軟體,您可以在資料上執行各種操作,例如:
- 資料管理
- 統計分析
- 生成具有完美圖形的報表
- 業務規劃
- 運籌學和專案管理
- 質量改進
- 應用程式開發
- 資料提取
- 資料轉換
- 資料更新和修改
如果我們談論 SAS 的元件,那麼 SAS 中提供了 200 多個元件。
| 序號 | SAS 元件及其用途 |
|---|---|
| 1 | Base SAS 它是核心元件,包含資料管理功能和用於資料分析的程式語言。它也是使用最廣泛的。 |
| 2 | SAS/GRAPH 建立圖形、簡報,以便更好地理解和以正確的格式展示結果。 |
| 3 | SAS/STAT 執行統計分析,包括方差分析、迴歸、多元分析、生存分析、心理測量分析和混合模型分析。 |
| 4 | SAS/OR 運籌學。 |
| 5 | SAS/ETS 計量經濟學和時間序列分析。 |
| 6 | SAS/IML 互動式矩陣語言。 |
| 7 | SAS/AF 應用程式功能。 |
| 8 | SAS/QC 質量控制。 |
| 9 | SAS/INSIGHT 資料探勘。 |
| 10 | SAS/PH 臨床試驗分析。 |
| 11 | SAS/Enterprise Miner 資料探勘。 |
SAS 軟體型別
- Windows 或 PC SAS
- SAS EG(企業指南)
- SAS EM(企業挖掘,即用於預測分析)
- SAS Means
- SAS Stats
在組織和培訓機構中,我們大多使用 Windows SAS。一些組織使用 Linux,但它沒有圖形使用者介面,因此您必須為每個查詢編寫程式碼。但在 Windows SAS 中,提供了許多實用程式,這極大地幫助了程式設計師,並且還減少了編寫程式碼的時間。
SAS 視窗有 5 個部分。
| 序號 | SAS 視窗及其用途 |
|---|---|
| 1 | 日誌視窗 日誌視窗就像一個執行視窗,我們可以在其中檢查 SAS 程式的執行情況。在此視窗中,我們還可以檢查錯誤。在執行程式後每次檢查日誌視窗非常重要。這樣,我們就可以對程式的執行有一個正確的理解。 |
| 2 | 編輯器視窗
編輯器視窗是 SAS 中編寫所有程式碼的部分。它就像一個記事本。 |
| 3 | 輸出視窗 輸出視窗是結果視窗,我們可以在其中檢視程式的輸出。 |
| 4 | 結果視窗 它就像所有輸出的索引。我們在 SAS 的一個會話中執行的所有程式都列在其中,您可以透過單擊輸出結果來開啟輸出。但這些僅在 SAS 的一個會話中提及。如果我們關閉軟體然後再次開啟它,則結果視窗將為空。 |
| 5 | 瀏覽視窗 這裡列出了所有庫。您還可以從此處瀏覽系統中 SAS 支援的檔案。 |
SAS 中的庫
庫就像 SAS 中的儲存。您可以建立一個庫並將所有類似的程式儲存在該庫中。SAS 為您提供了建立多個庫的功能。SAS 庫的長度僅為 8 個字元。
SAS 中提供了兩種型別的庫:
| 序號 | SAS 視窗及其用途 |
|---|---|
| 1 | 臨時或工作庫 這是 SAS 的預設庫。如果我們沒有為程式分配任何其他庫,則我們建立的所有程式都將儲存在此工作庫中。您可以在瀏覽視窗中檢查此工作庫。如果您建立了一個 SAS 程式並且沒有為其分配任何永久庫,那麼如果您結束會話並在之後再次啟動軟體,則此程式將不在工作庫中。因為它只會在會話持續期間存在於工作庫中。 |
| 2 | 永久庫 這些是 SAS 的永久庫。我們可以使用 SAS 實用程式或在編輯器視窗中編寫程式碼來建立一個新的 SAS 庫。這些庫被稱為永久庫,因為如果我們在 SAS 中建立一個程式並將其儲存在這些永久庫中,那麼這些程式將根據需要一直可用。 |
SAS - 環境
SAS Institute Inc. 釋出了一個免費的SAS University Edition,它非常適合學習 SAS 程式設計。它提供了學習 BASE SAS 程式設計所需的所有功能,進而使您能夠學習任何其他 SAS 元件。
下載和安裝 SAS University Edition 的過程非常簡單。它作為虛擬機器提供,需要在虛擬環境中執行。在執行 SAS 軟體之前,您需要在 PC 中安裝虛擬化軟體。在本教程中,我們將使用VMware。以下是下載、設定 SAS 環境和驗證安裝的步驟的詳細資訊。
下載 SAS University Edition
SAS University Edition 可在以下網址下載 SAS University Edition。請向下滾動以閱讀系統要求,然後再開始下載。訪問此 URL 時將顯示以下螢幕。
設定虛擬化軟體
在同一頁面上向下滾動以找到安裝步驟 1。此步驟提供了獲取適合您的虛擬化軟體的連結。如果您已經在系統中安裝了其中任何一個軟體,則可以跳過此步驟。

快速啟動虛擬化軟體
如果您完全不熟悉虛擬化環境,則可以透過閱讀以下指南和影片(作為步驟 2 提供)來熟悉它。如果您已經熟悉,則可以再次跳過此步驟。

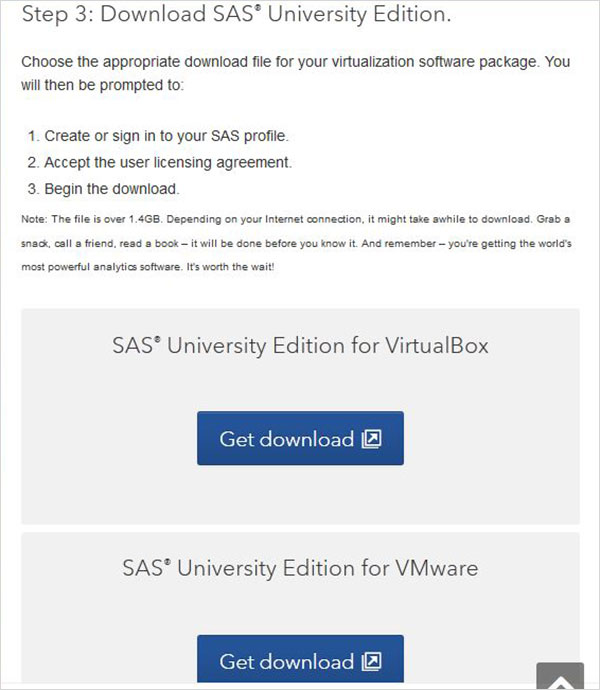
下載 Zip 檔案
在步驟 3 中,您可以選擇與您擁有的虛擬化環境相容的 SAS University Edition 的適當版本。它將下載為一個 zip 檔案,名稱類似於 unvbasicvapp__9411005__vmx__en__sp0__1.zip
解壓縮 zip 檔案
上面提到的 zip 檔案需要解壓縮並存儲到適當的目錄中。在我們的例子中,我們選擇了 VMware zip 檔案,解壓縮後顯示以下檔案。

載入虛擬機器
啟動 VMware 播放器(或工作站)並開啟副檔名為 .vmx 的檔案。將顯示以下螢幕。請注意分配給虛擬機器的基本設定,例如記憶體和硬碟空間。

啟動虛擬機器
單擊綠色箭頭標記旁邊的啟動此虛擬機器以啟動虛擬機器。將顯示以下螢幕。

當 SAS 虛擬機器處於載入狀態時,將顯示以下螢幕,之後正在執行的虛擬機器將提示您轉到一個 URL 位置,該位置將開啟 SAS 環境。
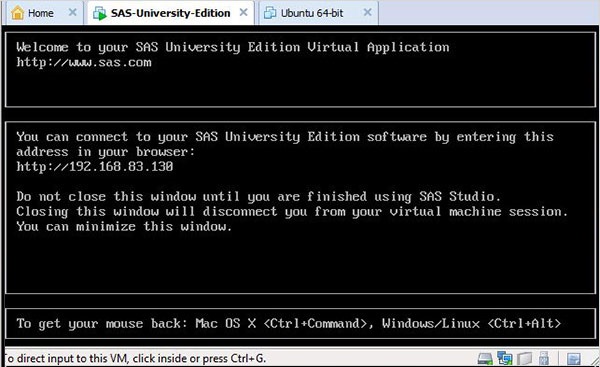
啟動 SAS Studio
開啟一個新的瀏覽器標籤頁並載入上述URL(每個電腦的URL可能不同)。以下螢幕顯示SAS環境已準備就緒。

SAS環境
點選啟動SAS Studio,我們將進入SAS環境,預設情況下以視覺化程式設計模式開啟,如下所示。
我們也可以透過點選下拉選單將其更改為SAS程式設計模式。

現在我們準備編寫SAS程式了。
SAS - 使用者介面
SAS程式是使用一個稱為SAS Studio的使用者介面建立的。
以下是各個視窗及其用法的描述。
SAS主視窗
這是您進入SAS環境時看到的視窗。左側是導航窗格,用於導航各種程式設計功能。右側是工作區,用於編寫程式碼並執行它。
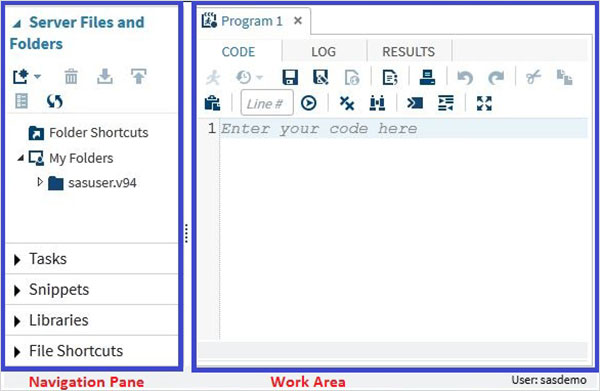
程式碼自動完成
這是一個非常強大的功能,它有助於獲取SAS關鍵字的正確語法,並提供指向該關鍵字文件的連結。

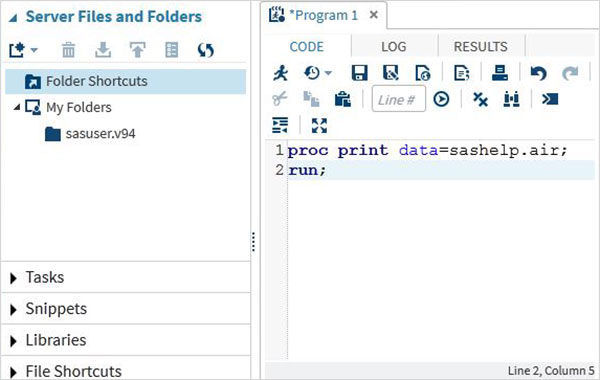
程式執行
程式碼的執行是透過按下執行圖示(最左側的第一個圖示)或F3鍵來完成的。
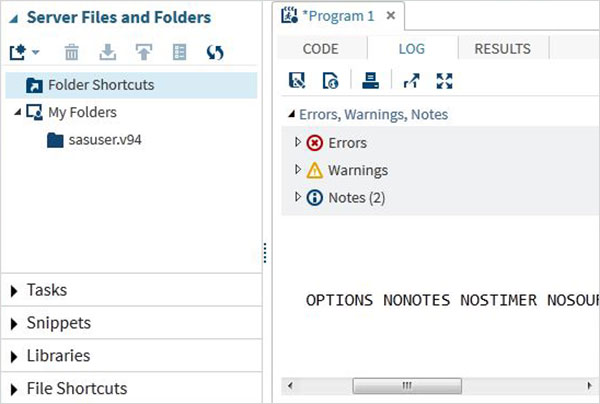
程式日誌
已執行程式碼的日誌可在日誌選項卡下找到。它描述了程式執行過程中的錯誤、警告或提示。這是您獲取所有除錯程式碼線索的視窗。
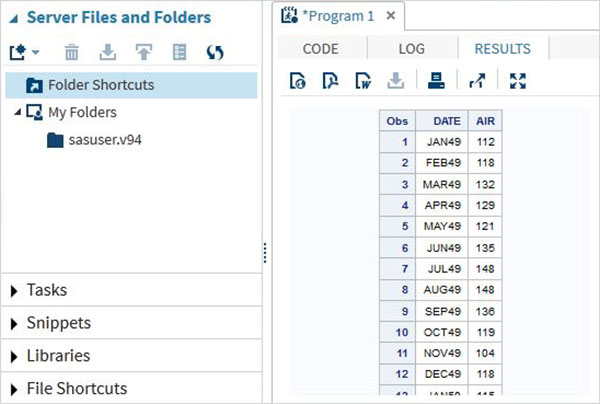
程式結果
程式碼執行的結果顯示在結果選項卡中。預設情況下,它們以html表格格式顯示。
程式選項卡
導航區域包含建立和管理程式的功能。它還提供可與您的程式一起使用的預構建功能。
伺服器檔案和資料夾
在此選項卡下,我們可以建立其他程式、匯入要分析的資料以及查詢現有資料。它還可用於建立資料夾快捷方式。
任務
任務選項卡提供功能,可以透過僅提供輸入變數來使用內建SAS程式。例如,在統計資料夾下,您可以找到一個SAS程式,只需提供SAS資料集名稱和變數名稱即可進行線性迴歸。
程式碼片段
程式碼片段選項卡提供功能來編寫SAS宏並從現有資料集中生成檔案。

程式庫
SAS將資料集儲存在SAS庫中。臨時庫僅在單個會話中可用,並命名為WORK。但永久庫始終可用。
檔案快捷方式
此選項卡用於訪問儲存在SAS環境外部的檔案。此類檔案的快捷方式儲存在此選項卡下。
SAS - 程式結構
SAS程式設計首先涉及將資料集建立/讀取到記憶體中,然後對這些資料進行分析。我們需要了解編寫程式以實現此目標的流程。
SAS程式結構
下圖顯示了以給定順序編寫的建立SAS程式的步驟。
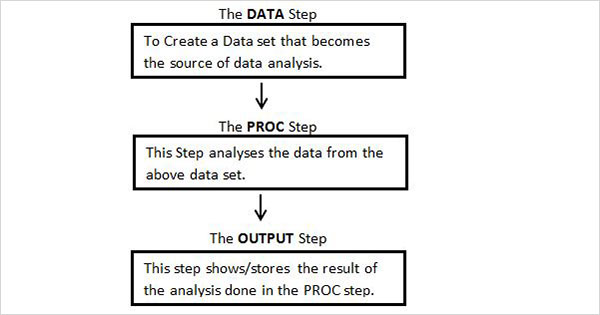
每個SAS程式都必須包含所有這些步驟才能完成讀取輸入資料、分析資料和給出分析輸出。此外,每個步驟末尾的RUN語句都是完成該步驟執行所必需的。
DATA步
此步驟涉及將所需資料集載入到SAS記憶體中並識別資料集的變數(也稱為列)。它還捕獲記錄(也稱為觀測值或主體)。DATA語句的語法如下。
語法
DATA data_set_name; #Name the data set. INPUT var1,var2,var3; #Define the variables in this data set. NEW_VAR; #Create new variables. LABEL; #Assign labels to variables. DATALINES; #Enter the data. RUN;
示例
以下示例顯示了一個簡單的命名資料集、定義變數、建立新變數和輸入資料的案例。這裡字串變數末尾帶有$,數值變數則沒有。
DATA TEMP; INPUT ID $ NAME $ SALARY DEPARTMENT $; comm = SALARY*0.25; LABEL ID = 'Employee ID' comm = 'COMMISION'; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 Operations 3 Michelle 611 IT 4 Ryan 729 HR 5 Gary 843.25 Finance 6 Nina 578 IT 7 Simon 632.8 Operations 8 Guru 722.5 Finance ; RUN;
PROC步
此步驟涉及呼叫SAS內建過程來分析資料。
語法
PROC procedure_name options; #The name of the proc. RUN;
示例
以下示例顯示了使用MEANS過程列印資料集中數值變數的平均值。
PROC MEANS; RUN;
輸出步
資料集中的資料可以使用條件輸出語句顯示。
語法
PROC PRINT DATA = data_set; OPTIONS; RUN;
示例
以下示例顯示了在輸出中使用where子句從資料集中僅生成少量記錄。
PROC PRINT DATA = TEMP; WHERE SALARY > 700; RUN;
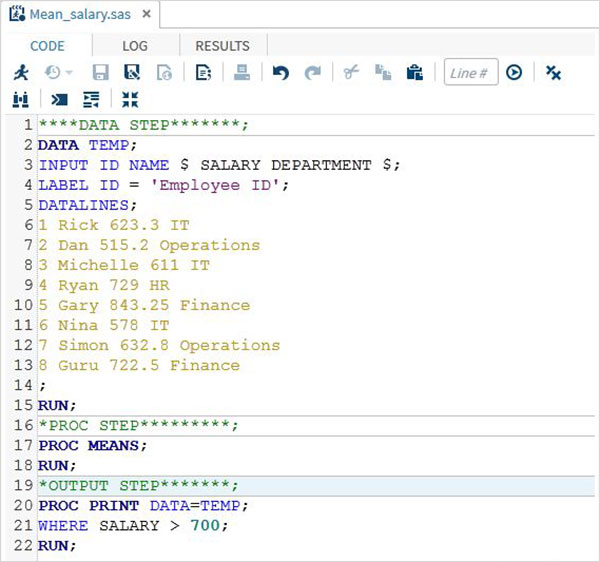
完整的SAS程式
以下是每個上述步驟的完整程式碼。
程式輸出
上述程式碼的輸出顯示在結果選項卡中。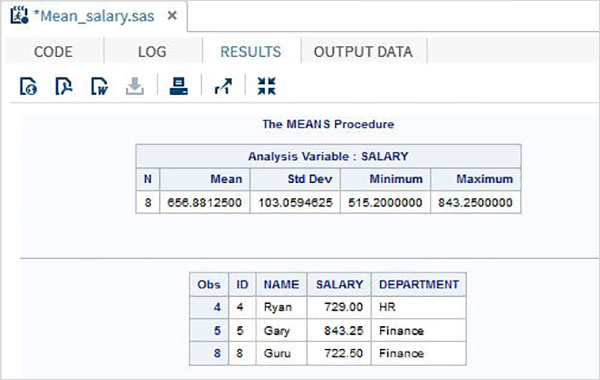
SAS - 基本語法
與任何其他程式語言一樣,SAS語言也有自己的語法規則來建立SAS程式。
任何SAS程式的三個組成部分——語句、變數和資料集遵循以下語法規則。
SAS語句
語句可以從任何位置開始,到任何位置結束。最後一行末尾的分號標誌著語句的結束。
同一行可以有多個SAS語句,每個語句以分號結尾。
可以使用空格分隔SAS程式語句中的元件。
SAS關鍵字不區分大小寫。
每個SAS程式都必須以RUN語句結束。
SAS變數名稱
SAS中的變量表示SAS資料集中的一列。變數名稱遵循以下規則。
最多可以有32個字元。
不能包含空格。
必須以字母A到Z(不區分大小寫)或下劃線(_)開頭。
可以包含數字,但不能作為第一個字元。
變數名稱不區分大小寫。
示例
# Valid Variable Names REVENUE_YEAR MaxVal _Length # Invalid variable Names Miles Per Liter #contains Space. RainfFall% # contains apecial character other than underscore. 90_high # Starts with a number.
SAS資料集
DATA語句標誌著新SAS資料集的建立。資料集建立規則如下。
DATA語句後跟一個單詞表示臨時資料集名稱。這意味著資料集在會話結束時會被刪除。
資料集名稱可以以庫名稱為字首,這使其成為永久資料集。這意味著資料集在會話結束後仍然存在。
如果省略了SAS資料集名稱,則SAS會建立一個由SAS生成的臨時資料集名稱,例如- DATA1、DATA2等。
示例
# Temporary data sets. DATA TempData; DATA abc; DATA newdat; # Permanent data sets. DATA LIBRARY1.DATA1 DATA MYLIB.newdat;
SAS副檔名
SAS程式、資料檔案和程式結果在Windows中以各種副檔名儲存。
*.sas − 它表示SAS程式碼檔案,可以使用SAS編輯器或任何文字編輯器進行編輯。
*.log − 它表示SAS日誌檔案,其中包含提交的SAS程式的錯誤、警告和資料集詳細資訊等資訊。
*.mht / *.html −它表示SAS結果檔案。
*.sas7bdat −它表示SAS資料檔案,其中包含SAS資料集,包括變數名稱、標籤和計算結果。
SAS中的註釋
SAS程式碼中的註釋以兩種方式指定。以下是這兩種格式。
*message; 型別註釋
形式為*message;的註釋不能包含分號或不匹配的引號。此外,此類註釋中不應引用任何宏語句。它可以跨越多行,並且可以是任意長度。以下是一個單行註釋示例−
* This is comment ;
以下是一個多行註釋示例−
* This is first line of the comment * This is second line of the comment;
/*message*/ 型別註釋
形式為/*message*/的註釋使用頻率更高,並且不能巢狀。但它可以跨越多行,並且可以是任意長度。以下是一個單行註釋示例−
/* This is comment */
以下是一個多行註釋示例−
/* This is first line of the comment * This is second line of the comment */
SAS - 資料集
可用於SAS程式分析的資料稱為SAS資料集。它使用DATA步建立。SAS可以讀取各種檔案作為其資料來源,例如CSV、Excel、Access、SPSS以及原始資料。它還提供了許多可供使用的內建資料來源。
如果資料集由SAS程式使用,然後在會話執行後被丟棄,則稱為臨時資料集。
但如果它被永久儲存以供將來使用,則稱為永久資料集。所有永久資料集都儲存在特定的庫中。
SAS資料集以行和列的形式儲存,也稱為SAS資料表。下面我們將看到內建以及從外部來源讀取的永久資料集的示例。
SAS內建資料集
這些資料集已存在於已安裝的SAS軟體中。它們可以被探索並用於制定資料分析的示例表示式。要探索這些資料集,請轉到庫 -> 我的庫 -> SASHELP。展開後,我們將看到所有可用內建資料集名稱的列表。
讓我們向下滾動以找到一個名為CARS的資料集。雙擊此資料集將在右側視窗窗格中開啟它,我們可以在其中進一步探索它。我們還可以使用右側窗格下方的最大化檢視按鈕最小化左側窗格。
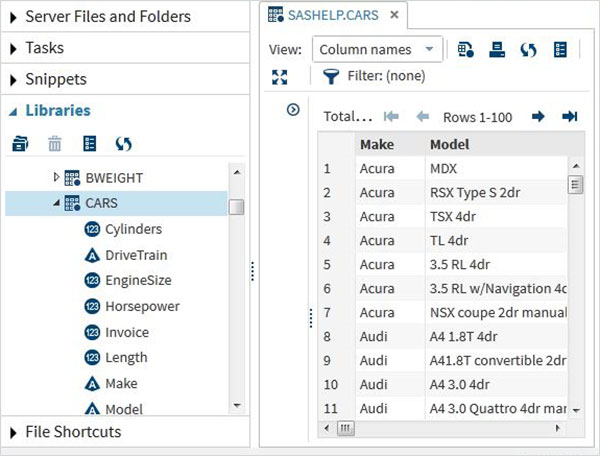
我們可以使用底部的捲軸向右滾動以瀏覽表中的所有列及其值。

匯入外部資料集
我們可以使用SAS Studio中提供的匯入功能將自己的檔案匯出為資料集。但這些檔案必須存在於SAS伺服器資料夾中。因此,我們必須使用伺服器檔案和資料夾下的上傳選項將源資料檔案上傳到SAS資料夾。

接下來,我們透過匯入在SAS程式中使用上述檔案。為此,我們使用選項任務 -> 實用程式 -> 匯入資料,如下所示。雙擊匯入資料按鈕,將在右側開啟一個視窗,用於選擇資料集的檔案。
接下來,點選右側窗格中匯入資料程式下的選擇檔案按鈕。以下是可匯入的檔案型別列表。

我們選擇儲存在本地系統中的“employee.txt”檔案,並將檔案匯入,如下所示。

檢視匯入的資料
我們可以使用執行選項執行使用生成的預設匯入程式碼來檢視匯入的資料。
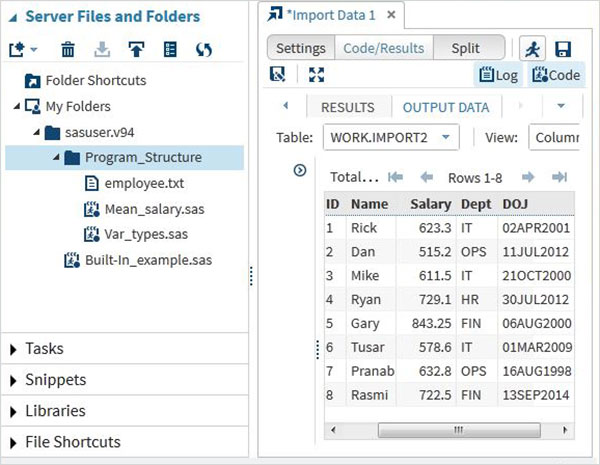
我們可以使用與上述相同的方法匯入任何其他檔案型別,並在各種SAS程式中使用它。
SAS - 變數
通常,SAS中的變量表示其正在分析的資料表的列名。但它也可以用於其他目的,例如在程式設計迴圈中用作計數器。在本章中,我們將看到SAS變數用作SAS資料集列名的用法。
SAS變數型別
SAS有三種類型的變數,如下所示−
數值變數
這是預設變數型別。這些變數用於數學表示式。
語法
INPUT VAR1 VAR2 VAR3; #Define numeric variables in the data set.
在上述語法中,INPUT語句顯示了數值變數的宣告。
示例
INPUT ID SALARY COMM_PERCENT;
字元變數
字元變數用於不用於數學表示式的值。它們被視為文字或字串。透過在變數名稱末尾新增$符號和空格,變數將變為字元變數。
語法
INPUT VAR1 $ VAR2 $ VAR3 $; #Define character variables in the data set.
在上述語法中,INPUT語句顯示了字元變數的宣告。
示例
INPUT FNAME $ LNAME $ ADDRESS $;
日期變數
這些變數僅被視為日期,並且需要採用有效的日期格式。透過在變數名稱末尾新增日期格式和空格,變數將變為日期變數。
語法
INPUT VAR1 DATE11. VAR2 MMDDYY10. ; #Define date variables in the data set.
在上述語法中,INPUT語句顯示了日期變數的宣告。
示例
INPUT DOB DATE11. START_DATE MMDDYY10. ;
變數在SAS程式中的用法
上述變數在SAS程式中使用,如下例所示。
示例
以下程式碼顯示了三種變數如何在SAS程式中宣告和使用。
DATA TEMP; INPUT ID NAME $ SALARY DEPT $ DOJ DATE9. ; FORMAT DOJ DATE9. ; DATALINES; 1 Rick 623.3 IT 02APR2001 2 Dan 515.2 OPS 11JUL2012 3 Michelle 611 IT 21OCT2000 4 Ryan 729 HR 30JUL2012 5 Gary 843.25 FIN 06AUG2000 6 Tusar 578 IT 01MAR2009 7 Pranab 632.8 OPS 16AUG1998 8 Rasmi 722.5 FIN 13SEP2014 ; PROC PRINT DATA = TEMP; RUN;
在上面的示例中,所有字元變數的聲明後面都跟著一個$符號,日期變數的聲明後面跟著日期格式。上面程式的輸出如下所示。
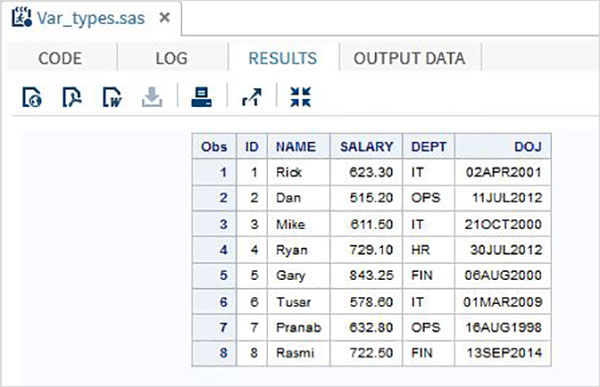
使用變數
變數在分析資料中非常有用。它們用於應用統計分析的表示式中。讓我們看一個分析名為CARS的內建資料集的示例,該資料集位於Libraries → My Libraries → SASHELP下。雙擊它以瀏覽變數及其資料型別。
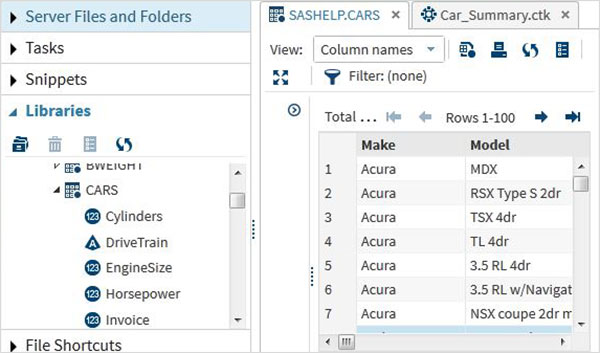
接下來,我們可以使用SAS Studio中的任務選項生成一些這些變數的彙總統計資訊。轉到Tasks -> Statistics -> Summary Statistics並雙擊它以開啟如下所示的視窗。選擇資料集SASHELP.CARS,並在“分析變數”下選擇三個變數 - MPG_CITY、MPG_Highway和Weight。在選擇變數時按住Ctrl鍵單擊。點選執行。
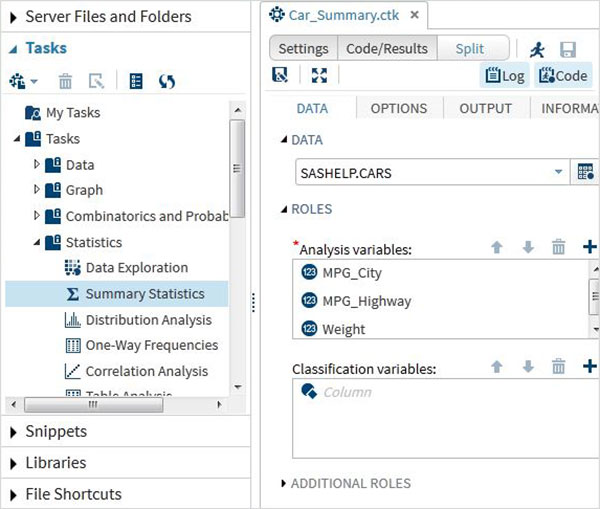
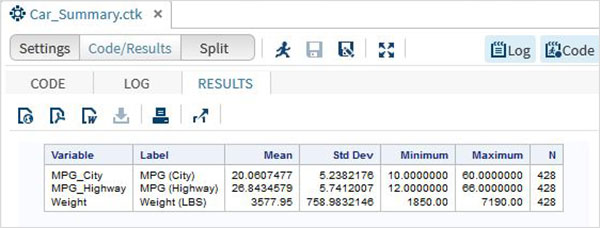
完成上述步驟後,點選結果選項卡。它顯示了所選三個變數的統計摘要。最後一列表示分析中使用的觀察值(記錄)的數量。
SAS - 字串
SAS中的字串是包含在一對單引號中的值。此外,字串變數透過在變數宣告末尾新增空格和$符號來宣告。SAS有很多強大的函式來分析和操作字串。
宣告字串變數
我們可以宣告字串變數及其值,如下所示。在下面的程式碼中,我們聲明瞭兩個長度分別為6和5的字元變數。LENGTH關鍵字用於宣告變數,而無需建立多個觀察值。
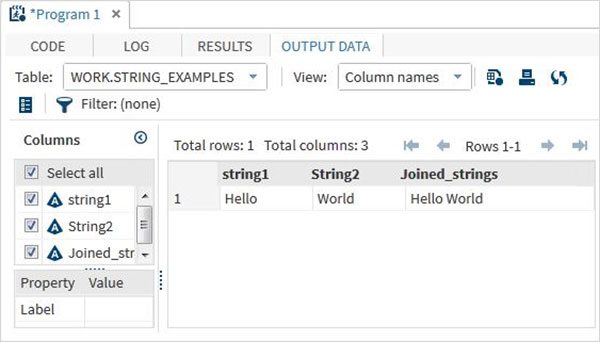
data string_examples; LENGTH string1 $ 6 String2 $ 5; /*String variables of length 6 and 5 */ String1 = 'Hello'; String2 = 'World'; Joined_strings = String1 ||String2 ; run; proc print data = string_examples noobs; run;
執行上述程式碼後,我們得到輸出,其中顯示了變數名及其值。
字串函式
以下是經常使用的一些SAS函式的示例。
SUBSTRN
此函式使用起始位置和結束位置提取子字串。如果沒有提及結束位置,它將提取到字串末尾的所有字元。
語法
SUBSTRN('stringval',p1,p2)
以下是所用引數的說明:
- stringval是字串變數的值。
- p1是提取的起始位置。
- p2是提取的最終位置。
示例
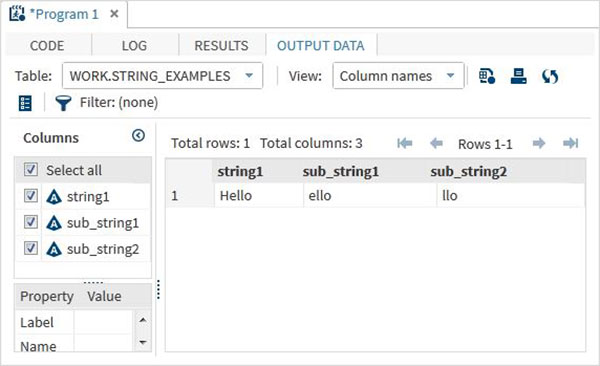
data string_examples; LENGTH string1 $ 6 ; String1 = 'Hello'; sub_string1 = substrn(String1,2,4) ; /*Extract from position 2 to 4 */ sub_string2 = substrn(String1,3) ; /*Extract from position 3 onwards */ run; proc print data = string_examples noobs; run;
執行上述程式碼後,我們得到輸出,其中顯示了substrn函式的結果。
TRIMN
此函式刪除字串後面的空格。
語法
TRIMN('stringval')
以下是所用引數的說明:
- stringval是字串變數的值。
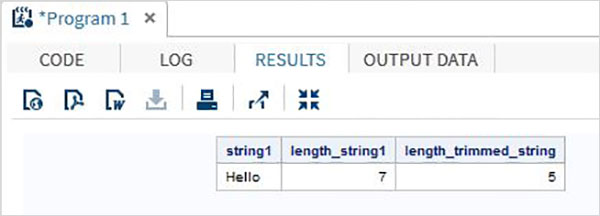
data string_examples; LENGTH string1 $ 7 ; String1='Hello '; length_string1 = lengthc(String1); length_trimmed_string = lengthc(TRIMN(String1)); run; proc print data = string_examples noobs; run;
執行上述程式碼後,我們得到輸出,其中顯示了TRIMN函式的結果。
SAS - 陣列
SAS中的陣列用於使用索引值儲存和檢索一系列值。索引表示保留記憶體區域中的位置。
語法
在SAS中,陣列的宣告使用以下語法:
ARRAY ARRAY-NAME(SUBSCRIPT) ($) VARIABLE-LIST ARRAY-VALUES
在上述語法中:
ARRAY是宣告陣列的SAS關鍵字。
ARRAY-NAME是陣列的名稱,遵循與變數名稱相同的規則。
SUBSCRIPT是陣列將儲存的值的數量。
($)是一個可選引數,僅當陣列將儲存字元值時才使用。
VARIABLE-LIST是變數的可選列表,它們是陣列值的佔位符。
ARRAY-VALUES是儲存在陣列中的實際值。它們可以在這裡宣告,也可以從檔案或資料行讀取。
陣列宣告示例
可以使用上述語法以多種方式宣告陣列。以下是示例。
# Declare an array of length 5 named AGE with values. ARRAY AGE[5] (12 18 5 62 44); # Declare an array of length 5 named COUNTRIES with values starting at index 0. ARRAY COUNTRIES(0:8) A B C D E F G H I; # Declare an array of length 5 named QUESTS which contain character values. ARRAY QUESTS(1:5) $ Q1-Q5; # Declare an array of required length as per the number of values supplied. ARRAY ANSWER(*) A1-A100;
訪問陣列值
可以使用print過程訪問儲存在陣列中的值,如下所示。在使用上述方法之一聲明後,使用DATALINES語句提供資料。
DATA array_example; INPUT a1 $ a2 $ a3 $ a4 $ a5 $; ARRAY colours(5) $ a1-a5; mix = a1||'+'||a2; DATALINES; yello pink orange green blue ; RUN; PROC PRINT DATA = array_example; RUN;
當我們執行上述程式碼時,它會產生以下結果:

使用OF運算子
OF運算子用於分析陣列中的資料,以對陣列的整行執行計算。在下面的示例中,我們應用了每行值的和與平均值。
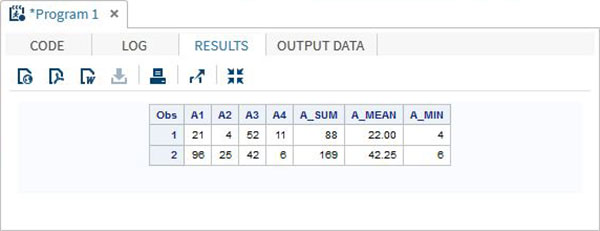
DATA array_example_OF; INPUT A1 A2 A3 A4; ARRAY A(4) A1-A4; A_SUM = SUM(OF A(*)); A_MEAN = MEAN(OF A(*)); A_MIN = MIN(OF A(*)); DATALINES; 21 4 52 11 96 25 42 6 ; RUN; PROC PRINT DATA = array_example_OF; RUN;
當我們執行上述程式碼時,它會產生以下結果:
使用IN運算子
還可以使用IN運算子訪問陣列中的值,該運算子檢查陣列行中是否存在某個值。在下面的示例中,我們檢查資料中是否存在顏色“Yellow”。此值區分大小寫。
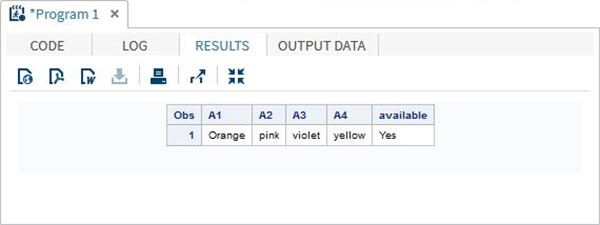
DATA array_in_example; INPUT A1 $ A2 $ A3 $ A4 $; ARRAY COLOURS(4) A1-A4; IF 'yellow' IN COLOURS THEN available = 'Yes';ELSE available = 'No'; DATALINES; Orange pink violet yellow ; RUN; PROC PRINT DATA = array_in_example; RUN;
當我們執行上述程式碼時,它會產生以下結果:
SAS - 數字格式
SAS可以處理各種各樣的數值資料格式。它在變數名的末尾使用這些格式,以將特定的數值格式應用於資料。SAS使用兩種數值格式。一種用於讀取數值資料的特定格式,稱為informat,另一種用於以特定格式顯示數值資料,稱為output format。
語法
數值informat的語法為:
Varname Formatnamew.d
以下是所用引數的說明:
Varname是變數的名稱。
Formatname是應用於變數的數值格式的名稱。
w是允許為變數儲存的最大資料列數(包括小數點後的數字和小數點本身)。
d是小數點右邊的數字位數。
讀取數值格式
以下是用於將資料讀入SAS的格式列表。
輸入數值格式
| 格式 | 用途 |
|---|---|
| n. | 最多“n”列,無小數點。 |
| n.p | 最多“n”列,有“p”位小數。 |
| COMMAn.p | 最多“n”列,有“p”位小數,刪除任何逗號或美元符號。 |
| COMMAn.p | 最多“n”列,有“p”位小數,刪除任何逗號或美元符號。 |
顯示數值格式
類似於在讀取資料時應用格式,以下是用於在SAS程式輸出中顯示資料的格式列表。
輸出數值格式
| 格式 | 用途 |
|---|---|
| n. | 寫入最多“n”位數字,無小數點。 |
| n.p | 寫入最多“n.p”列,有“p”位小數。 |
| DOLLARn.p | 寫入最多“n”列,有“p”位小數,前導美元符號和千分位逗號。 |
請注意:
如果小數點後的數字位數小於格式說明符,則在末尾追加零。
如果小數點後的數字位數大於格式說明符,則最後一個數字將四捨五入。
示例
以下示例說明了上述場景。
DATA MYDATA1; input x 6.; /*maxiiuum width of the data*/ format x 6.3; datalines; 8722 93.2 .1122 15.116 PROC PRINT DATA = MYDATA1; RUN; DATA MYDATA2; input x 6.; /*maximum width of the data*/ format x 5.2; datalines; 8722 93.2 .1122 15.116 PROC PRINT DATA = MYDATA2; RUN; DATA MYDATA3; input x 6.; /*maximum width of the data*/ format x DOLLAR10.2; datalines; 8722 93.2 .1122 15.116 PROC PRINT DATA = MYDATA3; RUN;
當我們執行上述程式碼時,它會產生以下結果:
# MYDATA1. Obs x 1 8722.0 # Display 6 columns with zero appended after decimal. 2 93.200 # Display 6 columns with zero appended after decimal. 3 0.112 # No integers before decimal, so display 3 available digits after decimal. 4 15.116 # Display 6 columns with 3 available digits after decimal. # MYDATA2 Obs x 1 8722 # Display 5 columns. Only 4 are available. 2 93.20 # Display 5 columns with zero appended after decimal. 3 0.11 # Display 5 columns with 2 places after decimal. 4 15.12 # Display 5 columns with 2 places after decimal. # MYDATA3 Obs x 1 $8,722.00 # Display 10 columns with leading $ sign, comma at thousandth place and zeros appended after decimal. 2 $93.20 # Only 2 integers available before decimal and one available after the decimal. 3 $0.11 # No integers available before decimal and two available after the decimal. 4 $15.12 # Only 2 integers available before decimal and two available after the decimal.
SAS - 運算子
SAS中的運算子是用於數學、邏輯或比較表示式中的符號。這些符號內置於SAS語言中,並且可以在單個表示式中組合多個運算子以提供最終輸出。
以下是SAS運算子類別列表。
- 算術運算子
- 邏輯運算子
- 比較運算子
- 最小/最大運算子
- 連線運算子
我們將逐一檢視每個運算子。運算子始終與作為SAS程式分析的資料一部分的變數一起使用。
算術運算子
下表描述了算術運算子的詳細資訊。假設有兩個資料變數V1和V2,其值分別為8和4。
| 運算子 | 描述 | 示例 |
|---|---|---|
| + | 加法 | V1+V2=12 |
| - | 減法 | V1-V2=4 |
| * | 乘法 | V1*V2=32 |
| / | 除法 | V1/V2=2 |
| ** | 冪運算 | V1**V2=4096 |
示例
DATA MYDATA1; input @1 COL1 4.2 @7 COL2 3.1; Add_result = COL1+COL2; Sub_result = COL1-COL2; Mult_result = COL1*COL2; Div_result = COL1/COL2; Expo_result = COL1**COL2; datalines; 11.21 5.3 3.11 11 ; PROC PRINT DATA = MYDATA1; RUN;
執行上述程式碼後,我們得到以下輸出。

邏輯運算子
下表描述了邏輯運算子的詳細資訊。這些運算子評估表示式的真值。因此,邏輯運算子的結果始終為1或0。假設有兩個資料變數V1和V2,其值分別為8和4。
| 運算子 | 描述 | 示例 |
|---|---|---|
| & | AND運算子。如果兩個資料值都計算為真,則結果為1,否則為0。 | (V1>2 & V2 > 3)給出0。 |
| | | OR運算子。如果任何一個數據值計算為真,則結果為1,否則為0。 | (V1>9 & V2 > 3)為1。 |
| ~ | NOT運算子。NOT運算子的結果以表示式的形式表示,其值為FALSE或缺失值,則為1,否則為0。 | NOT(V1 > 3)為1。 |
示例
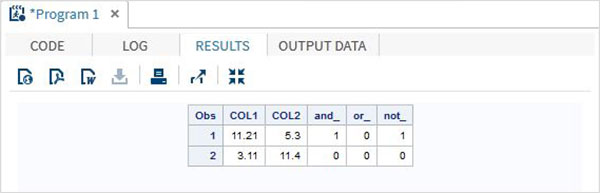
DATA MYDATA1; input @1 COL1 5.2 @7 COL2 4.1; and_=(COL1 > 10 & COL2 > 5 ); or_ = (COL1 > 12 | COL2 > 15 ); not_ = ~( COL2 > 7 ); datalines; 11.21 5.3 3.11 11.4 ; PROC PRINT DATA = MYDATA1; RUN;
執行上述程式碼後,我們得到以下輸出。
比較運算子
下表描述了比較運算子的詳細資訊。這些運算子比較變數的值,結果是真值,用1表示TRUE,用0表示False。假設有兩個資料變數V1和V2,其值分別為8和4。
| 運算子 | 描述 | 示例 |
|---|---|---|
| = | EQUAL運算子。如果兩個資料值相等,則結果為1,否則為0。 | (V1 = 8)給出1。 |
| ^= | NOT EQUAL運算子。如果兩個資料值不相等,則結果為1,否則為0。 | (V1 ^= V2)給出1。 |
| < | LESS THAN運算子。 | (V2 < V2)給出1。 |
| <= | LESS THAN or EQUAL TO運算子。 | (V2 <= 4)給出1。 |
| > | GREATER THAN運算子。 | (V2 > V1)給出1。 |
| >= | GREATER THAN or EQUAL TO運算子。 | (V2 >= V1)給出0。 |
| IN | IN運算子。如果變數的值等於給定值列表中的任何一個值,則返回1,否則返回0。 | V1 in (5,7,9,8)給出1。 |
示例
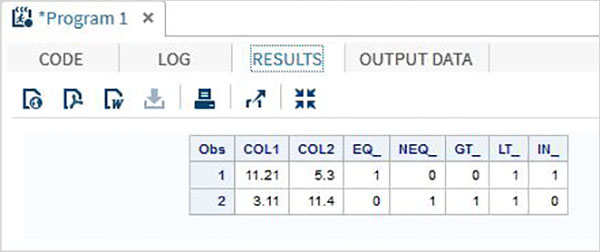
DATA MYDATA1; input @1 COL1 5.2 @7 COL2 4.1; EQ_ = (COL1 = 11.21); NEQ_= (COL1 ^= 11.21); GT_ = (COL2 => 8); LT_ = (COL2 <= 12); IN_ = COL2 in( 6.2,5.3,12 ); datalines; 11.21 5.3 3.11 11.4 ; PROC PRINT DATA = MYDATA1; RUN;
執行上述程式碼後,我們得到以下輸出。
最小/最大運算子
下表描述了最小/最大運算子的詳細資訊。這些運算子比較跨行的變數的值,並返回行中值列表中的最小值或最大值。
| 運算子 | 描述 | 示例 |
|---|---|---|
| MIN | MIN運算子。它返回行中值列表中的最小值。 | MIN(45.2,11.6,15.41)給出11.6 |
| MAX | MAX運算子。它返回行中值列表中的最大值。 | MAX(45.2,11.6,15.41)給出45.2 |
示例
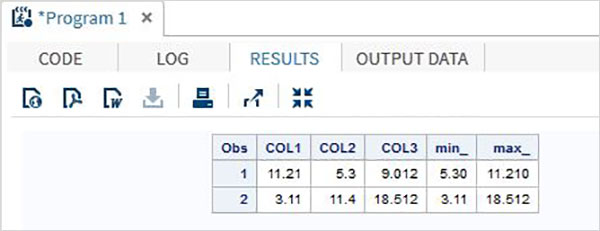
DATA MYDATA1; input @1 COL1 5.2 @7 COL2 4.1 @12 COL3 6.3; min_ = MIN(COL1 , COL2 , COL3); max_ = MAX( COL1, COl2 , COL3); datalines; 11.21 5.3 29.012 3.11 11.4 18.512 ; PROC PRINT DATA = MYDATA1; RUN;
執行上述程式碼後,我們得到以下輸出。
連線運算子
下表描述了連線運算子的詳細資訊。此運算子連線兩個或多個字串值。返回單個字元值。
| 運算子 | 描述 | 示例 |
|---|---|---|
| || | 連線運算子。它返回兩個或多個值的連線。 | 'Hello'||' World'給出Hello World |
示例
DATA MYDATA1; input COL1 $ COL2 $ COL3 $; concat_ = (COL1 || COL2 || COL3); datalines; Tutorial s point simple easy learning ; PROC PRINT DATA = MYDATA1; RUN;
執行上述程式碼後,我們得到以下輸出。

運算子優先順序
運算子優先順序指示覆雜表示式中多個運算子的評估順序。下表描述了運算子組內的優先順序順序。
| 組 | 順序 | 符號 |
|---|---|---|
| 組I | 從右到左 | ** + - NOT MIN MAX |
| 組II | 從左到右 | * / |
| 組III | 從左到右 | + - |
| 組IV | 從左到右 | || |
| 組V | 從左到右 | < <= = >= > |
SAS - 迴圈
您可能會遇到需要多次執行程式碼塊的情況。通常,語句按順序執行:函式中的第一個語句首先執行,然後是第二個語句,依此類推。但是,當您希望同一組語句被反覆執行時,我們需要迴圈的幫助。
在 SAS 中,迴圈是透過使用 DO 語句來完成的。它也稱為 **DO 迴圈**。下面是 SAS 中 DO 迴圈語句的一般形式。
流程圖

以下是 SAS 中 DO 迴圈的型別。
| 序號 | 迴圈型別和描述 |
|---|---|
| 1 | DO Index。
迴圈從索引變數的起始值持續到結束值。 |
| 2 | DO WHILE。
迴圈持續到 while 條件變為假。 |
| 3 | DO UNTIL。
迴圈持續到 UNTIL 條件變為真。 |
SAS - 決策
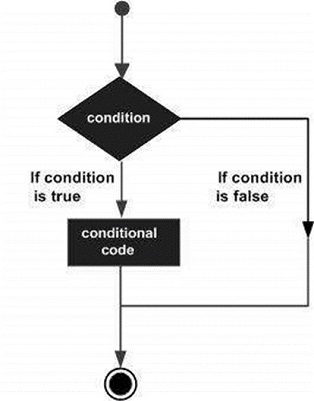
決策結構要求程式設計師指定一個或多個條件,由程式進行評估或測試,以及如果條件確定為 **真** 則要執行的語句,以及可選地,如果條件確定為 **假** 則要執行的其他語句。
以下是大多數程式語言中典型的決策結構的一般形式:
SAS 提供以下型別的決策語句。點選以下連結檢視它們的詳細資訊。
| 序號 | 語句型別和描述 |
|---|---|
| 1 | IF 語句。
一個 **if 語句** 包含一個條件。如果條件為真,則獲取特定的資料。 |
| 2 | IF-THEN-ELSE 語句。
一個 **if 語句** 後跟 else 語句,當布林條件為假時執行。 |
| 3 | IF-THEN-ELSE-IF 語句。
一個 **if 語句** 後跟 else 語句,該語句又被另一個 IF-THEN 語句對跟隨。 |
| 4 | IF-THEN-DELETE 語句。
一個 **if 語句** 包含一個條件,當條件為真時,從觀測值中刪除特定資料。 |
SAS - 函式
SAS 具有各種內建函式,有助於分析和處理資料。這些函式用作 DATA 語句的一部分。它們將資料變數作為引數,並返回儲存到另一個變數中的結果。根據函式的型別,它接受的引數數量可能會有所不同。某些函式接受零個引數,而其他函式則接受固定數量的變數。下面是 SAS 提供的函式型別的列表。
語法
在 SAS 中使用函式的一般語法如下。
FUNCTIONNAME(argument1, argument2...argumentn)
這裡引數可以是常量、變數、表示式或另一個函式。
函式類別
根據其用途,SAS 中的函式分類如下。
- 數學函式
- 日期和時間函式
- 字元函式
- 截斷函式
- 雜項函式
數學函式
這些函式用於對變數值應用一些數學計算。
示例
下面的 SAS 程式顯示了一些重要的數學函式的使用。
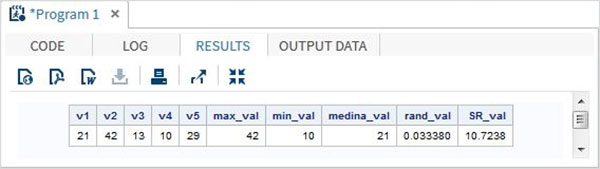
data Math_functions;
v1=21; v2=42; v3=13; v4=10; v5=29; /* Get Maximum value */ max_val = MAX(v1,v2,v3,v4,v5); /* Get Minimum value */ min_val = MIN (v1,v2,v3,v4,v5); /* Get Median value */ med_val = MEDIAN (v1,v2,v3,v4,v5); /* Get a random number */ rand_val = RANUNI(0); /* Get Square root of sum of the values */ SR_val= SQRT(sum(v1,v2,v3,v4,v5)); proc print data = Math_functions noobs; run;
執行以上程式碼後,我們將獲得以下輸出:
日期和時間函式
這些函式用於處理日期和時間值。
示例
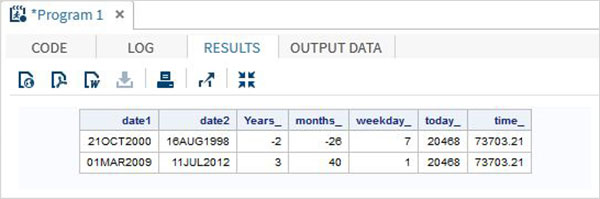
下面的 SAS 程式顯示了日期和時間函式的使用。
data date_functions;
INPUT @1 date1 date9. @11 date2 date9.;
format date1 date9. date2 date9.;
/* Get the interval between the dates in years*/
Years_ = INTCK('YEAR',date1,date2);
/* Get the interval between the dates in months*/
months_ = INTCK('MONTH',date1,date2);
/* Get the week day from the date*/
weekday_ = WEEKDAY(date1);
/* Get Today's date in SAS date format */
today_ = TODAY();
/* Get current time in SAS time format */
time_ = time();
DATALINES;
21OCT2000 16AUG1998
01MAR2009 11JUL2012
;
proc print data = date_functions noobs;
run;
執行以上程式碼後,我們將獲得以下輸出:
字元函式
這些函式用於處理字元或文字值。
示例
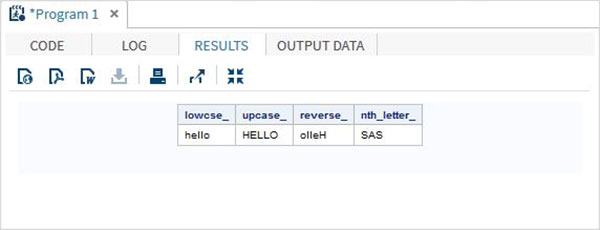
下面的 SAS 程式顯示了字元函式的使用。
data character_functions;
/* Convert the string into lower case */
lowcse_ = LOWCASE('HELLO');
/* Convert the string into upper case */
upcase_ = UPCASE('hello');
/* Reverse the string */
reverse_ = REVERSE('Hello');
/* Return the nth word */
nth_letter_ = SCAN('Learn SAS Now',2);
run;
proc print data = character_functions noobs;
run;
執行以上程式碼後,我們將獲得以下輸出:
截斷函式
這些函式用於截斷數值。
示例
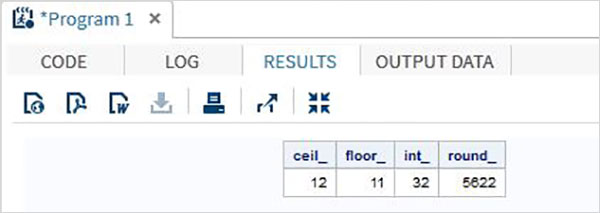
下面的 SAS 程式顯示了截斷函式的使用。
data trunc_functions; /* Nearest greatest integer */ ceil_ = CEIL(11.85); /* Nearest greatest integer */ floor_ = FLOOR(11.85); /* Integer portion of a number */ int_ = INT(32.41); /* Round off to nearest value */ round_ = ROUND(5621.78); run; proc print data = trunc_functions noobs; run;
執行以上程式碼後,我們將獲得以下輸出:
雜項函式
現在讓我們透過一些示例瞭解 SAS 的雜項函式。
示例
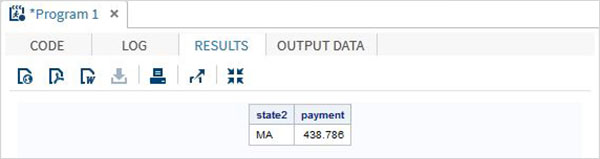
下面的 SAS 程式顯示了雜項函式的使用。
data misc_functions;
/* Nearest greatest integer */
state2=zipstate('01040');
/* Amortization calculation */
payment = mort(50000, . , .10/12,30*12);
proc print data = misc_functions noobs;
run;
執行以上程式碼後,我們將獲得以下輸出:
SAS - 輸入方法
輸入方法用於讀取原始資料。原始資料可能來自外部來源或來自流式資料行。input 語句建立一個變數,其名稱分配給每個欄位。因此,您必須在 Input 語句中建立一個變數。相同的變數將顯示在 SAS 資料集的輸出中。以下是 SAS 中可用的不同輸入方法。
- 列表輸入方法
- 命名輸入方法
- 列輸入方法
- 格式化輸入方法
每種輸入方法的詳細資訊如下所述。
列表輸入方法
在這種方法中,變數與資料型別一起列出。仔細分析原始資料,以便宣告的變數順序與資料匹配。分隔符(通常是空格)應在任何一對相鄰列之間保持一致。任何缺失資料都會導致輸出出現問題,因為結果將不正確。
示例
以下程式碼和輸出顯示了列表輸入方法的使用。
DATA TEMP; INPUT EMPID ENAME $ DEPT $ ; DATALINES; 1 Rick IT 2 Dan OPS 3 Tusar IT 4 Pranab OPS 5 Rasmi FIN ; PROC PRINT DATA = TEMP; RUN;
執行上述程式碼後,我們將獲得以下輸出。
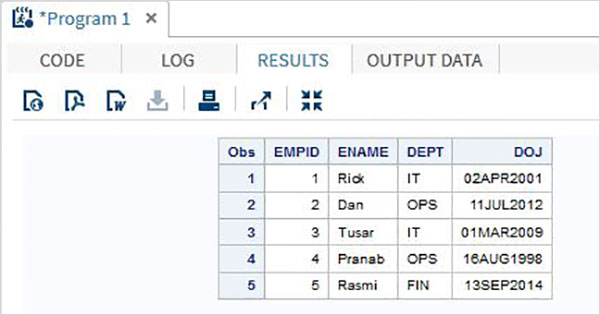
命名輸入方法
在這種方法中,變數與資料型別一起列出。原始資料被修改為在匹配資料前面具有宣告的變數名。分隔符(通常是空格)應在任何一對相鄰列之間保持一致。
示例
以下程式碼和輸出顯示了命名輸入方法的使用。
DATA TEMP; INPUT EMPID= ENAME= $ DEPT= $ ; DATALINES; EMPID = 1 ENAME = Rick DEPT = IT EMPID = 2 ENAME = Dan DEPT = OPS EMPID = 3 ENAME = Tusar DEPT = IT EMPID = 4 ENAME = Pranab DEPT = OPS EMPID = 5 ENAME = Rasmi DEPT = FIN ; PROC PRINT DATA = TEMP; RUN;
執行上述程式碼後,我們將獲得以下輸出。
列輸入方法
在這種方法中,變數與資料型別和列的寬度一起列出,這些列指定單個數據列的值。例如,如果員工姓名最多包含 9 個字元,並且每個員工姓名從第 10 列開始,則員工姓名變數的列寬將為 10-19。
示例
以下程式碼顯示了列輸入方法的使用。
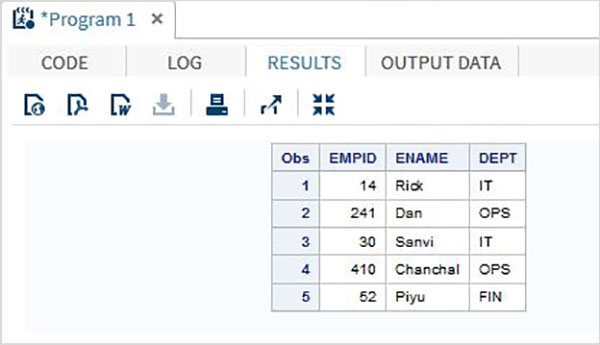
DATA TEMP; INPUT EMPID 1-3 ENAME $ 4-12 DEPT $ 13-16; DATALINES; 14 Rick IT 241Dan OPS 30 Sanvi IT 410Chanchal OPS 52 Piyu FIN ; PROC PRINT DATA = TEMP; RUN;
當我們執行上述程式碼時,它會產生以下結果:
格式化輸入方法
在這種方法中,變數從固定的起始點讀取,直到遇到空格。由於每個變數都有一個固定的起始點,因此任何一對變數之間的列數成為第一個變數的寬度。字元 '@n' 用於將變數的起始列位置指定為第 n 列。
示例
以下程式碼顯示了格式化輸入方法的使用
DATA TEMP; INPUT @1 EMPID $ @4 ENAME $ @13 DEPT $ ; DATALINES; 14 Rick IT 241 Dan OPS 30 Sanvi IT 410 Chanchal OPS 52 Piyu FIN ; PROC PRINT DATA = TEMP; RUN;
當我們執行上述程式碼時,它會產生以下結果:
SAS - 宏
SAS 具有一個強大的程式設計功能,稱為 **宏**,它允許我們避免重複的程式碼部分,並在需要時反覆使用它們。它還有助於在程式碼中建立動態變數,這些變數可以在相同程式碼的不同執行例項中採用不同的值。宏也可以為程式碼塊宣告,這些程式碼塊將以類似於宏變數的方式多次重複使用。我們將在下面的示例中看到這兩者。
宏變數
這些變數儲存一個值,供 SAS 程式反覆使用。它們在 SAS 程式的開頭宣告,並在程式主體中稍後呼叫。它們可以是全域性範圍或區域性範圍。
全域性宏變數
它們被稱為全域性宏變數,因為 SAS 環境中可用的任何 SAS 程式都可以訪問它們。通常,它們是系統分配的變數,多個程式都可以訪問它們。一個常見的例子是系統日期。
示例
下面是一個名為 SYSDATE 的 SAS 變數的示例,它表示系統日期。考慮一個場景,在每天生成報表時,在 SAS 報表的標題中列印系統日期。標題將顯示當前日期和日期,而無需我們為它們編碼任何值。我們使用名為 CARS 的內建 SAS 資料集,該資料集位於 SASHELP 庫中。
proc print data = sashelp.cars; where make = 'Audi' and type = 'Sports' ; TITLE "Sales as of &SYSDAY &SYSDATE"; run;
執行以上程式碼後,我們將獲得以下輸出。

區域性宏變數
這些變數可以被宣告為程式一部分的 SAS 程式訪問。它們通常用於向相同的 SAS 語句提供不同的變數,以便它們可以處理資料集的不同觀測值。
語法
區域性變數使用以下語法宣告。
% LET (Macro Variable Name) = Value;
這裡 Value 欄位可以根據程式需要採用任何數值、文字或日期值。宏變數名是任何有效的 SAS 變數。
示例
變數由 SAS 語句使用,方法是在變數名的開頭附加 **&** 字元。以下程式獲取製造商為“奧迪”且型別為“跑車”的所有觀測值。如果我們想要 **不同製造商** 的結果,我們需要更改變數 **make_name** 的值,而無需更改程式的任何其他部分。在大型程式中,此變數可以在任何 SAS 語句中反覆引用。
%LET make_name = 'Audi'; %LET type_name = 'Sports'; proc print data = sashelp.cars; where make = &make_name and type = &type_name ; TITLE "Sales as of &SYSDAY &SYSDATE"; run;
執行以上程式碼後,我們將獲得與上一個程式相同的輸出。但讓我們將 **型別名稱** 更改為 **'旅行車'** 並執行相同的程式。我們將獲得以下結果。

宏程式
宏是一組 SAS 語句,由一個名稱引用,並在程式中的任何位置使用該名稱。它以 %MACRO 語句開頭,以 %MEND 語句結尾。
語法
區域性變數使用以下語法宣告。
# Creating a Macro program. %MACRO <macro name>(Param1, Param2,….Paramn); Macro Statements; %MEND; # Calling a Macro program. %MacroName (Value1, Value2,…..Valuen);
示例
以下程式在名為 **'show_result'** 的宏下宣告一組 SAT 語句;此宏由其他 SAS 語句呼叫。
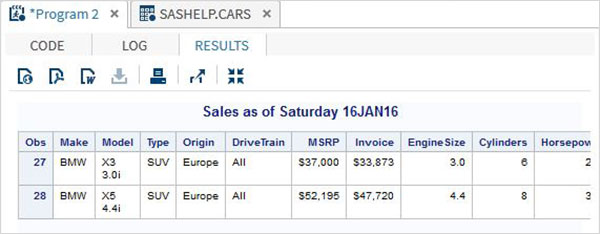
%MACRO show_result(make_ , type_); proc print data = sashelp.cars; where make = "&make_" and type = "&type_" ; TITLE "Sales as of &SYSDAY &SYSDATE"; run; %MEND; %show_result(BMW,SUV);
執行以上程式碼後,我們將獲得以下輸出。
常用宏
SAS 具有許多宏語句,這些語句是 SAS 程式語言中內建的。它們由其他 SAS 程式使用,無需顯式宣告它們。常見示例包括 - 在滿足某些條件時終止程式或在程式日誌中捕獲變數的執行時值。以下是一些示例。
宏 %PUT
此宏語句將文字或宏變數資訊寫入 SAS 日誌。在以下示例中,變數 'today' 的值被寫入程式日誌。
data _null_;
CALL SYMPUT ('today',
TRIM(PUT("&sysdate"d,worddate22.)));
run;
%put &today;
執行以上程式碼後,我們將獲得以下輸出。

宏 %RETURN
執行此宏會導致當前正在執行的宏在某些條件評估為真時正常終止。在以下示例中,當變數 **"val"** 的值變為 10 時,宏終止,否則繼續。
%macro check_condition(val);
%if &val = 10 %then %return;
data p;
x = 34.2;
run;
%mend check_condition;
%check_condition(11) ;
執行以上程式碼後,我們將獲得以下輸出。

宏 %END
此宏定義包含一個 **%DO %WHILE** 迴圈,該迴圈在需要時以 %END 語句結束。在以下示例中,名為 test 的宏獲取使用者輸入並使用此輸入值執行 DO 迴圈。DO 迴圈的結束透過 %end 語句實現,而宏的結束透過 %mend 語句實現。
%macro test(finish);
%let i = 1;
%do %while (&i <&finish);
%put the value of i is &i;
%let i=%eval(&i+1);
%end;
%mend test;
%test(5)
執行以上程式碼後,我們將獲得以下輸出。

SAS - 日期和時間
在 SAS 中,日期是數值的一種特殊情況。從 1960 年 1 月 1 日開始,每一天都被分配一個特定的數值。此日期被分配日期值 0,下一個日期的日期值為 1,依此類推。此日期之前的日期由 -1、-2 等表示。透過這種方法,SAS 可以表示將來的任何日期和過去的任何日期。
當 SAS 從源讀取資料時,它會將讀取的資料轉換為指定的日期格式。儲存日期值的變數用所需的正確 informat 宣告。輸出日期透過使用輸出資料格式顯示。
SAS 日期 Informat
源資料可以透過使用特定的日期 informat 正確讀取,如下所示。informat 末尾的數字表示要使用 informat 完全讀取的日期字串的最小寬度。較小的寬度將導致錯誤的結果。在 SAS V9 中,有一個通用的日期格式 **anydtdte15。** 可以處理任何日期輸入。
| 輸入日期 | 日期寬度 | Informat |
|---|---|---|
| 03/11/2014 | 10 | mmddyy10。 |
| 03/11/14 | 8 | mmddyy8。 |
| 2012 年 12 月 11 日 | 20 | worddate20。 |
| 2011 年 3 月 14 日 | 9 | date9。 |
| 2011 年 3 月 14 日 | 11 | date11。 |
| 2011 年 3 月 14 日 | 15 | anydtdte15。 |
示例
以下程式碼展示了讀取不同日期格式的方法。請注意,所有輸出值都只是數字,因為我們沒有對輸出值應用任何格式語句。
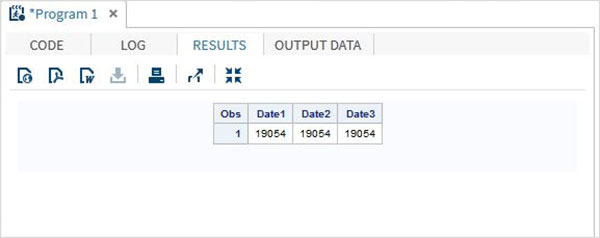
DATA TEMP; INPUT @1 Date1 date11. @12 Date2 anydtdte15. @23 Date3 mmddyy10. ; DATALINES; 02-mar-2012 3/02/2012 3/02/2012 ; PROC PRINT DATA = TEMP; RUN;
當執行上述程式碼時,我們將得到以下輸出。
SAS日期輸出格式
讀取日期後,可以根據顯示需要將其轉換為其他格式。這是透過使用日期型別的格式語句實現的。它們採用與informat相同的格式。
示例
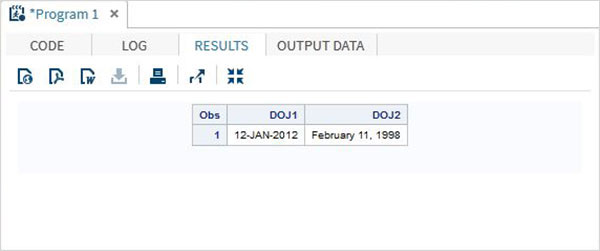
在下面的示例中,日期以一種格式讀取,但以另一種格式顯示。
DATA TEMP; INPUT @1 DOJ1 mmddyy10. @12 DOJ2 mmddyy10.; format DOJ1 date11. DOJ2 worddate20. ; DATALINES; 01/12/2012 02/11/1998 ; PROC PRINT DATA = TEMP; RUN;
當執行上述程式碼時,我們將得到以下輸出。
SAS - 讀取原始資料
SAS可以從各種來源讀取資料,包括許多檔案格式。下面將討論SAS環境中使用的檔案格式。
- ASCII(文字)資料集
- 分隔資料
- Excel資料
- 層次資料
讀取ASCII(文字)資料集
這些檔案包含以文字格式儲存的資料。資料通常以空格分隔,但也可以使用SAS可以處理的不同型別的分隔符。讓我們考慮一個包含員工資料的ASCII檔案。我們使用SAS中提供的Infile語句讀取此檔案。
示例
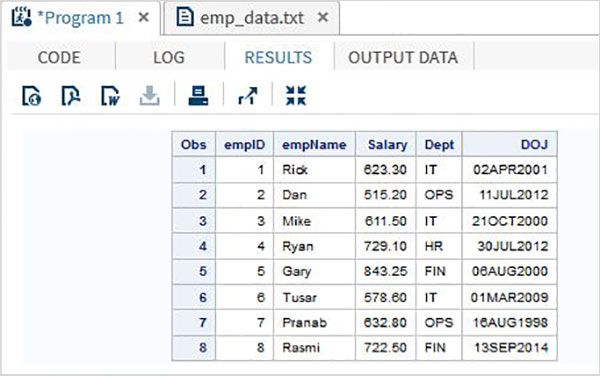
在下面的示例中,我們從本地環境讀取名為emp_data.txt的資料檔案。
data TEMP; infile '/folders/myfolders/sasuser.v94/TutorialsPoint/emp_data.txt'; input empID empName $ Salary Dept $ DOJ date9. ; format DOJ date9.; run; PROC PRINT DATA = TEMP; RUN;
當執行上述程式碼時,我們將得到以下輸出。
讀取分隔資料
這些資料檔案中的列值以分隔符(如逗號或管道等)分隔。在這種情況下,我們在infile語句中使用dlm選項。
示例
在下面的示例中,我們從本地環境讀取名為emp.csv的資料檔案。
data TEMP; infile '/folders/myfolders/sasuser.v94/TutorialsPoint/emp.csv' dlm=","; input empID empName $ Salary Dept $ DOJ date9. ; format DOJ date9.; run; PROC PRINT DATA = TEMP; RUN;
當執行上述程式碼時,我們將得到以下輸出。
讀取Excel資料
SAS可以使用匯入功能直接讀取Excel檔案。如SAS資料集章節所示,它可以處理各種檔案型別,包括MS Excel。假設檔案emp.xls在SAS環境中本地可用。
示例
FILENAME REFFILE "/folders/myfolders/TutorialsPoint/emp.xls" TERMSTR = CR; PROC IMPORT DATAFILE = REFFILE DBMS = XLS OUT = WORK.IMPORT; GETNAMES = YES; RUN; PROC PRINT DATA = WORK.IMPORT RUN;
上述程式碼從Excel檔案讀取資料,並給出與上述兩種檔案型別相同的輸出。
讀取分層檔案
在這些檔案中,資料以分層格式存在。對於給定的觀測值,下面有一個標題記錄,其中提到了許多詳細記錄。詳細記錄的數量可能因觀測值而異。下面是分層檔案的示例。
在下面的檔案中,列出了每個部門下每個員工的詳細資訊。第一條記錄是標題記錄,其中提到了部門,接下來的幾條記錄以DTLS開頭是詳細資訊記錄。
DEPT:IT DTLS:1:Rick:623 DTLS:3:Mike:611 DTLS:6:Tusar:578 DEPT:OPS DTLS:7:Pranab:632 DTLS:2:Dan:452 DEPT:HR DTLS:4:Ryan:487 DTLS:2:Siyona:452
示例
要讀取分層檔案,我們使用以下程式碼,其中我們使用IF子句識別標題記錄,並使用do迴圈處理詳細資訊記錄。
data employees(drop = Type);
length Type $ 3 Department
empID $ 3 empName $ 10 Empsal 3 ;
retain Department;
infile
'/folders/myfolders/TutorialsPoint/empdtls.txt' dlm = ':';
input Type $ @;
if Type = 'DEP' then
input Department $;
else do;
input empID empName $ Empsal ;
output;
end;
run;
PROC PRINT DATA = employees;
RUN;
當執行上述程式碼時,我們將得到以下輸出。

SAS - 寫入資料集
與讀取資料集類似,SAS可以以不同的格式寫入資料集。它可以將資料從SAS檔案寫入普通文字檔案。這些檔案可以被其他軟體程式讀取。SAS使用PROC EXPORT來寫入資料集。
PROC EXPORT
這是一個SAS內建過程,用於匯出SAS資料集以將資料寫入不同格式的檔案。
語法
在SAS中編寫此過程的基本語法為:
PROC EXPORT DATA = libref.SAS data-set (SAS data-set-options) OUTFILE = "filename" DBMS = identifier LABEL(REPLACE);
以下是所用引數的說明:
SAS資料集是要匯出的資料集名稱。SAS可以透過建立不同作業系統可以讀取的檔案,將其環境中的資料集與其他應用程式共享。它使用內建的EXPORT函式以各種格式輸出資料集檔案。在本章中,我們將看到使用proc export以及dlm和dbms選項寫入SAS資料集的方法。
SAS資料集選項用於指定要匯出的列的子集。
檔名是要將資料寫入的檔案的名稱。
識別符號用於提及將寫入檔案的分隔符。
LABEL選項用於提及寫入檔案的變數的名稱。
示例
我們將使用SASHELP庫中名為cars的SAS資料集。我們將其匯出為一個空格分隔的文字檔案,程式碼如下面的程式所示。
proc export data = sashelp.cars outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.txt' dbms = dlm; delimiter = ' '; run;
執行上述程式碼後,我們可以看到輸出為一個文字檔案,並右鍵單擊它以檢視其內容,如下所示。

寫入CSV檔案
為了寫入逗號分隔的檔案,我們可以將dlm選項的值設定為“csv”。以下程式碼寫入檔案car_data.csv。
proc export data = sashelp.cars outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.csv' dbms = csv; run;
執行上述程式碼後,我們將得到以下輸出。

寫入製表符分隔的檔案
為了寫入製表符分隔的檔案,我們可以將dlm選項的值設定為“tab”。以下程式碼寫入檔案car_tab.txt。
proc export data = sashelp.cars outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_tab.txt' dbms = csv; run;
資料也可以作為HTML檔案寫入,我們將在輸出交付系統章節中看到。
SAS - 合併資料集
可以使用SET語句將多個SAS資料集連線起來以生成單個數據集。連線資料集中的觀測值總數是原始資料集中觀測值總數的和。觀測值的順序是連續的。第一個資料集中的所有觀測值後面跟著第二個資料集中的所有觀測值,依此類推。
理想情況下,所有組合資料集都具有相同的變數,但如果它們具有不同數量的變數,則在結果中將顯示所有變數,較小的資料集中的變數將顯示缺失值。
語法
SAS中SET語句的基本語法為:
SET data-set 1 data-set 2 data-set 3.....;
以下是所用引數的說明:
資料集1、資料集2是依次寫入的資料集名稱。
示例
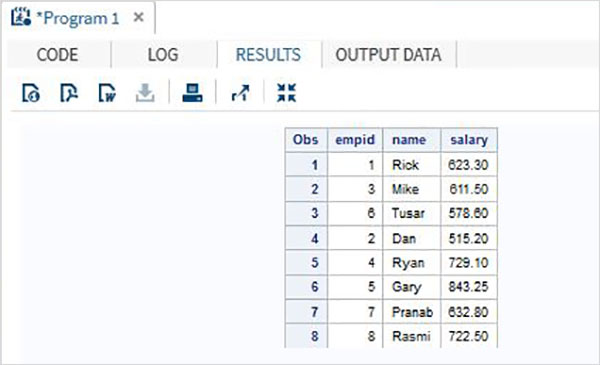
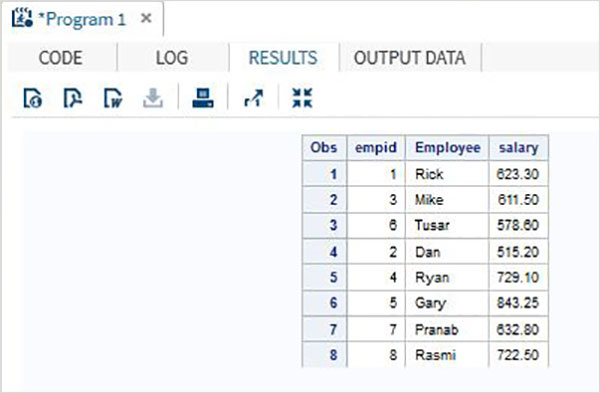
考慮一個組織的員工資料,這些資料儲存在兩個不同的資料集中,一個用於IT部門,另一個用於非IT部門。要獲取所有員工的完整詳細資訊,我們可以使用SET語句連線這兩個資料集,如下所示。
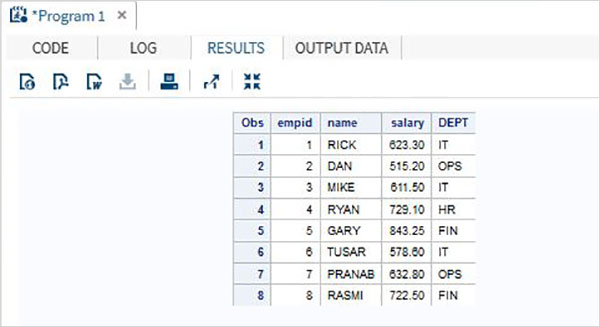
DATA ITDEPT; INPUT empid name $ salary ; DATALINES; 1 Rick 623.3 3 Mike 611.5 6 Tusar 578.6 ; RUN; DATA NON_ITDEPT; INPUT empid name $ salary ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; SET ITDEPT NON_ITDEPT; RUN; PROC PRINT DATA = All_Dept; RUN;
當執行上述程式碼時,我們將得到以下輸出。
場景
當我們在連線資料集時存在許多差異時,變數的結果可能會有所不同,但連線資料集中觀測值的總數始終是每個資料集中觀測值的總數。我們將在下面考慮關於此差異的許多場景。
不同數量的變數
如果其中一個原始資料集的變數數量多於另一個,則資料集仍然會合並,但在較小的資料集中,這些變數將顯示為缺失。
示例
在下面的示例中,第一個資料集有一個額外的名為DOJ的變數。在結果中,第二個資料集的DOJ值將顯示為缺失。
DATA ITDEPT; INPUT empid name $ salary DOJ date9. ; DATALINES; 1 Rick 623.3 02APR2001 3 Mike 611.5 21OCT2000 6 Tusar 578.6 01MAR2009 ; RUN; DATA NON_ITDEPT; INPUT empid name $ salary ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; SET ITDEPT NON_ITDEPT; RUN; PROC PRINT DATA = All_Dept; RUN;
當執行上述程式碼時,我們將得到以下輸出。
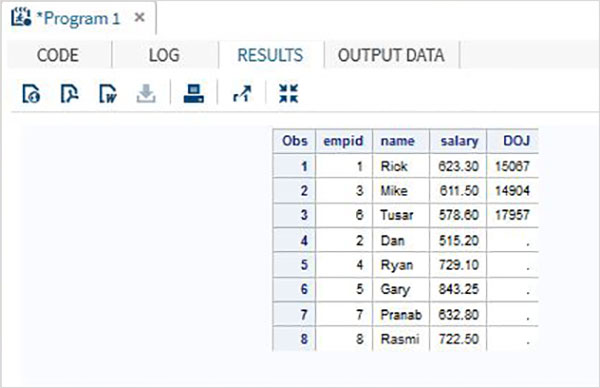
不同的變數名
在這種情況下,資料集具有相同數量的變數,但它們之間的一個變數名稱不同。在這種情況下,正常的連線將在結果集中生成所有變數,併為兩個不同的變數提供缺失結果。雖然我們可能不會更改原始資料集中的變數名稱,但我們可以在建立的連線資料集中應用RENAME函式。這將產生與正常連線相同的結果,當然,在一個新變數名稱代替原始資料集中存在的兩個不同變數名稱。
示例
在下面的示例中,資料集ITDEPT的變數名為ename,而資料集NON_ITDEPT的變數名為empname。但這兩個變數都表示相同的型別(字元)。我們像下面所示在SET語句中應用RENAME函式。
DATA ITDEPT; INPUT empid ename $ salary ; DATALINES; 1 Rick 623.3 3 Mike 611.5 6 Tusar 578.6 ; RUN; DATA NON_ITDEPT; INPUT empid empname $ salary ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) ); RUN; PROC PRINT DATA = All_Dept; RUN;
當執行上述程式碼時,我們將得到以下輸出。
不同的變數長度
如果兩個資料集中變數的長度不同,則連線資料集將包含一些資料被截斷的值,這些值的變數長度較小。如果第一個資料集的長度較小,就會發生這種情況。要解決此問題,我們可以將較高的長度應用於兩個資料集,如下所示。
示例
在下面的示例中,變數ename在第一個資料集中長度為5,在第二個資料集中長度為7。在連線時,我們在連線的資料集中應用LENGTH語句將ename長度設定為7。
DATA ITDEPT; INPUT empid 1-2 ename $ 3-7 salary 8-14 ; DATALINES; 1 Rick 623.3 3 Mike 611.5 6 Tusar 578.6 ; RUN; DATA NON_ITDEPT; INPUT empid 1-2 ename $ 3-9 salary 10-16 ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; LENGTH ename $ 7 ; SET ITDEPT NON_ITDEPT ; RUN; PROC PRINT DATA = All_Dept; RUN;
當執行上述程式碼時,我們將得到以下輸出。
SAS - 合併資料集
多個SAS資料集可以基於特定的公共變數合併以生成單個數據集。這是使用MERGE語句和BY語句完成的。合併資料集中觀測值的總數通常小於原始資料集中觀測值總數的和。這是因為當公共變數的值匹配時,來自兩個資料集的變數將合併為一條記錄。
下面給出了合併資料集的兩個先決條件:
- 輸入資料集必須至少有一個公共變數才能進行合併。
- 輸入資料集必須按將用於合併的公共變數排序。
語法
SAS中MERGE和BY語句的基本語法為:
MERGE Data-Set 1 Data-Set 2 BY Common Variable
以下是所用引數的說明:
資料集1、資料集2是依次寫入的資料集名稱。
公共變數是根據其匹配值合併資料集的變數。
資料合併
讓我們透過一個示例瞭解資料合併。
示例
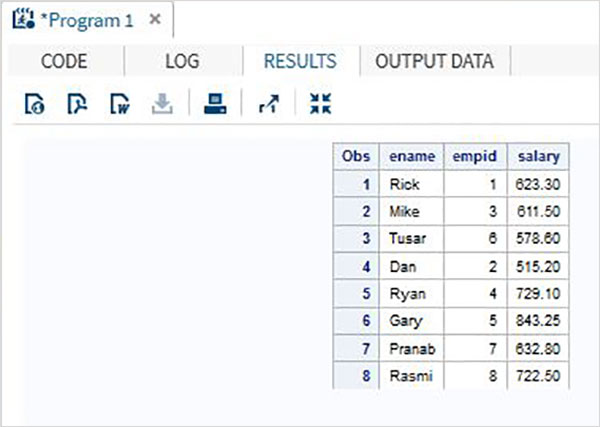
考慮兩個SAS資料集,一個包含員工ID、姓名和工資,另一個包含員工ID和部門。在這種情況下,要獲取每個員工的完整資訊,我們可以合併這兩個資料集。最終資料集仍然每個員工一個觀測值,但它將包含工資和部門變數。
# Data set 1 ID NAME SALARY 1 Rick 623.3 2 Dan 515.2 3 Mike 611.5 4 Ryan 729.1 5 Gary 843.25 6 Tusar 578.6 7 Pranab 632.8 8 Rasmi 722.5 # Data set 2 ID DEPT 1 IT 2 OPS 3 IT 4 HR 5 FIN 6 IT 7 OPS 8 FIN # Merged data set ID NAME SALARY DEPT 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN
上述結果是透過在BY語句中使用公共變數(ID)來實現的。請注意,兩個資料集中的觀測值已按ID列排序。
DATA SALARY; INPUT empid name $ salary ; DATALINES; 1 Rick 623.3 2 Dan 515.2 3 Mike 611.5 4 Ryan 729.1 5 Gary 843.25 6 Tusar 578.6 7 Pranab 632.8 8 Rasmi 722.5 ; RUN; DATA DEPT; INPUT empid dEPT $ ; DATALINES; 1 IT 2 OPS 3 IT 4 HR 5 FIN 6 IT 7 OPS 8 FIN ; RUN; DATA All_details; MERGE SALARY DEPT; BY (empid); RUN; PROC PRINT DATA = All_details; RUN;
匹配列中的缺失值
在某些情況下,公共變數的一些值在資料集之間可能不匹配。在這種情況下,資料集仍然會合並,但在結果中會顯示缺失值。
示例
考慮資料集salary中缺少員工ID 3,資料集DEPT中缺少員工ID 6的情況。當應用上述程式碼時,我們將得到以下結果。ID NAME SALARY DEPT 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 . . IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 . 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN
僅合併匹配項
為了避免結果中的缺失值,我們可以考慮只保留公共變數匹配值的觀測值。這是透過使用IN語句實現的。SAS程式的merge語句需要更改。
示例
在下面的示例中,IN=值僅保留來自兩個資料集SALARY和DEPT的值匹配的觀測值。
DATA All_details; MERGE SALARY(IN = a) DEPT(IN = b); BY (empid); IF a = 1 and b = 1; RUN; PROC PRINT DATA = All_details; RUN;
執行上述更改部分的SAS程式後,我們將得到以下輸出。
1 Rick 623.3 IT 2 Dan 515.2 OPS 4 Ryan 729.1 HR 5 Gary 843.25 FIN 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN
SAS - 子集資料集
子集化SAS資料集意味著透過選擇較少的變數或較少的觀測值(或兩者)來提取資料集的一部分。雖然變數的子集化是透過使用KEEP和DROP語句完成的,但觀測值的子集化是使用DELETE語句完成的。
此外,子集化操作產生的結果資料儲存在一個新資料集中,該資料集可用於進一步分析。子集化主要用於分析資料集的一部分,而不使用與分析無關的變數或觀測值。
子集化變數
在這種方法中,我們僅從整個資料集中提取一些變數。
語法
SAS中子集化變數的基本語法為:
KEEP var1 var2 ... ; DROP var1 var2 ... ;
以下是所用引數的說明:
var1和var2是要保留或刪除的資料集中的變數名稱。
示例
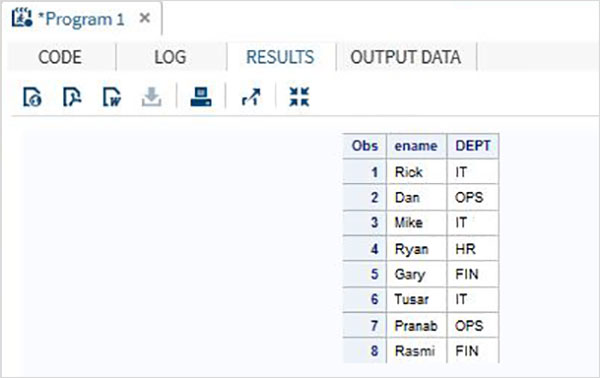
考慮以下包含組織員工詳細資訊的SAS資料集。如果我們只對獲取資料集中的姓名和部門值感興趣,則可以使用以下程式碼。
DATA Employee; INPUT empid ename $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; RUN; DATA OnlyDept; SET Employee; KEEP ename DEPT; RUN; PROC PRINT DATA = OnlyDept; RUN;
當執行上述程式碼時,我們將得到以下輸出。
可以透過刪除不需要的變數來獲得相同的結果。以下程式碼說明了這一點。
DATA Employee; INPUT empid ename $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; RUN; DATA OnlyDept; SET Employee; DROP empid salary; RUN; PROC PRINT DATA = OnlyDept; RUN;
子集化觀測值
在這種方法中,我們僅從整個資料集中提取一些觀測值。
語法
我們使用PROC FREQ,它跟蹤為新資料集選擇的觀測值。
子集觀測的語法如下:
IF Var Condition THEN DELETE ;
以下是所用引數的說明:
Var 是變數的名稱,根據其值將使用指定的條件刪除觀測值。
示例
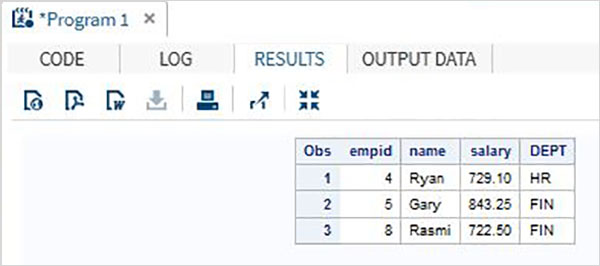
考慮以下包含組織員工詳細資訊的 SAS 資料集。如果我們只對獲取薪資大於 700 的員工資料感興趣,則使用以下程式碼。
DATA Employee; INPUT empid name $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; RUN; DATA OnlyDept; SET Employee; IF salary < 700 THEN DELETE; RUN; PROC PRINT DATA = OnlyDept; RUN;
當執行上述程式碼時,我們將得到以下輸出。
SAS - 格式化資料集
有時我們希望以與資料集中已存在格式不同的格式顯示分析資料。例如,我們希望為包含價格資訊的變數新增美元符號和小數點後兩位。或者我們可能希望將文字變數全部顯示為大寫。我們可以使用FORMAT 應用內建的 SAS 格式,並使用PROC FORMAT 應用使用者定義的格式。此外,單個格式可以應用於多個變數。
語法
應用內建 SAS 格式的基本語法如下:
format variable name format name
以下是所用引數的說明:
變數名 是資料集中使用的變數名。
格式名稱 是要應用於變數的資料格式。
示例
讓我們考慮以下包含組織員工詳細資訊的 SAS 資料集。我們希望將所有名稱顯示為大寫。格式語句 用於實現此目的。
DATA Employee; INPUT empid name $ salary DEPT $ ; format name $upcase9. ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; RUN; PROC PRINT DATA = Employee; RUN;
當執行上述程式碼時,我們將得到以下輸出。
使用 PROC FORMAT
我們還可以使用PROC FORMAT 格式化資料。在下面的示例中,我們為變數 DEPT 分配新值,擴充套件部門的名稱。
DATA Employee;
INPUT empid name $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
proc format;
value $DEP 'IT' = 'Information Technology'
'OPS'= 'Operations' ;
RUN;
PROC PRINT DATA = Employee;
format name $upcase9. DEPT $DEP.;
RUN;
當執行上述程式碼時,我們將得到以下輸出。

SAS - SQL
SAS 透過在 SAS 程式中使用 SQL 查詢,對大多數流行的關係資料庫提供了廣泛的支援。大多數ANSI SQL 語法都受支援。PROC SQL 過程用於處理 SQL 語句。此過程不僅可以返回 SQL 查詢的結果,還可以建立 SAS 表和變數。下面描述了所有這些場景的示例。
語法
在 SAS 中使用 PROC SQL 的基本語法如下:
PROC SQL; SELECT Columns FROM TABLE WHERE Columns GROUP BY Columns ; QUIT;
以下是所用引數的說明:
SQL 查詢寫在 PROC SQL 語句之後,後跟 QUIT 語句。
下面我們將看到如何在 SQL 中使用此 SAS 過程進行CRUD(建立、讀取、更新和刪除)操作。
SQL 建立操作
使用 SQL,我們可以從原始資料建立新的資料集。在下面的示例中,我們首先宣告一個名為 TEMP 的資料集,其中包含原始資料。然後,我們編寫一個 SQL 查詢以從此資料集的變數建立表。
DATA TEMP; INPUT ID $ NAME $ SALARY DEPARTMENT $; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 Operations 3 Michelle 611 IT 4 Ryan 729 HR 5 Gary 843.25 Finance 6 Nina 578 IT 7 Simon 632.8 Operations 8 Guru 722.5 Finance ; RUN; PROC SQL; CREATE TABLE EMPLOYEES AS SELECT * FROM TEMP; QUIT; PROC PRINT data = EMPLOYEES; RUN;
執行上述程式碼後,我們將獲得以下結果:

SQL 讀取操作
SQL 中的讀取操作涉及編寫 SQL SELECT 查詢以讀取表中的資料。在下面的程式中,查詢了庫 SASHELP 中名為 CARS 的 SAS 資料集。查詢獲取資料集的一些列。
PROC SQL; SELECT make,model,type,invoice,horsepower FROM SASHELP.CARS ; QUIT;
執行上述程式碼後,我們將獲得以下結果:

帶 WHERE 子句的 SQL SELECT
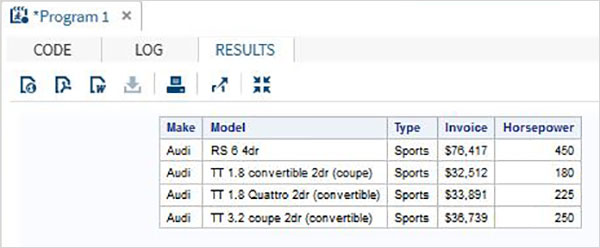
下面的程式使用where 子句查詢 CARS 資料集。在結果中,我們僅獲取製造商為“Audi”且型別為“Sports”的觀測值。
PROC SQL; SELECT make,model,type,invoice,horsepower FROM SASHELP.CARS Where make = 'Audi' and Type = 'Sports' ; QUIT;
執行上述程式碼後,我們將獲得以下結果:
SQL 更新操作
我們可以使用 SQL Update 語句更新 SAS 表。下面我們首先建立一個名為 EMPLOYEES2 的新表,然後使用 SQL UPDATE 語句更新它。
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;
PROC SQL;
CREATE TABLE EMPLOYEES2 AS
SELECT ID as EMPID,
Name as EMPNAME ,
SALARY as SALARY,
DEPARTMENT as DEPT,
SALARY*0.23 as COMMISION
FROM TEMP;
QUIT;
PROC SQL;
UPDATE EMPLOYEES2
SET SALARY = SALARY*1.25;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;
執行上述程式碼後,我們將獲得以下結果:

SQL 刪除操作
SQL 中的刪除操作涉及使用 SQL DELETE 語句從表中刪除某些值。我們繼續使用上述示例中的資料,並刪除表中員工薪資大於 900 的行。
PROC SQL;
DELETE FROM EMPLOYEES2
WHERE SALARY > 900;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;
執行上述程式碼後,我們將獲得以下結果:

SAS - ODS
SAS 程式的輸出可以轉換為更使用者友好的形式,例如.html 或PDF。 這是透過使用 SAS 中可用的ODS 語句完成的。ODS 代表輸出交付系統。 它主要用於將 SAS 程式的輸出資料格式化為漂亮的報表,這些報表易於檢視和理解。這也有助於與其他平臺和軟體共享輸出。它還可以將來自多個 PROC 語句的結果組合到一個檔案中。
語法
在 SAS 中使用 ODS 語句的基本語法如下:
ODS outputtype PATH path name FILE = Filename and Path STYLE = StyleName ; PROC some proc ; ODS outputtype CLOSE;
以下是所用引數的說明:
PATH 表示在 HTML 輸出的情況下使用的語句。在其他型別的輸出中,我們在檔名中包含路徑。
Style 表示 SAS 環境中可用的內建樣式之一。
建立 HTML 輸出
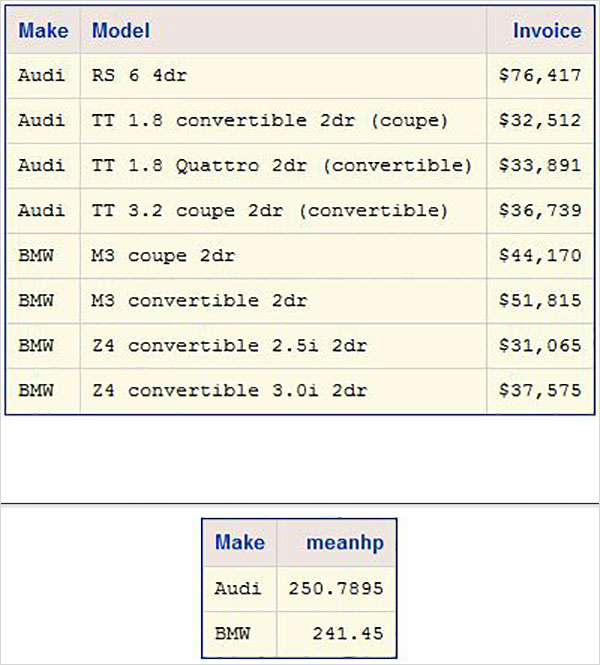
我們使用 ODS HTML 語句建立 HTML 輸出。在下面的示例中,我們在所需的路徑中建立了一個 html 檔案。我們應用樣式庫中可用的樣式。我們可以在提到的路徑中檢視輸出檔案,並且可以將其下載以儲存在與 SAS 環境不同的環境中。請注意,我們有兩個 proc SQL 語句,並且它們的輸出都捕獲到一個檔案中。
ODS HTML
PATH = '/folders/myfolders/sasuser.v94/TutorialsPoint/'
FILE = 'CARS2.html'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS HTML CLOSE;
執行上述程式碼後,我們將獲得以下結果:
建立 PDF 輸出
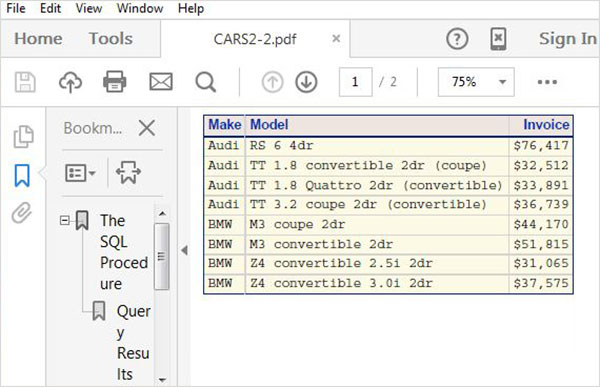
在下面的示例中,我們在所需的路徑中建立了一個 PDF 檔案。我們應用樣式庫中可用的樣式。我們可以在提到的路徑中檢視輸出檔案,並且可以將其下載以儲存在與 SAS 環境不同的環境中。請注意,我們有兩個 proc SQL 語句,並且它們的輸出都捕獲到一個檔案中。
ODS PDF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS2.pdf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS PDF CLOSE;
執行上述程式碼後,我們將獲得以下結果:
建立 TRF(Word)輸出
在下面的示例中,我們在所需的路徑中建立了一個 RTF 檔案。我們應用樣式庫中可用的樣式。我們可以在提到的路徑中檢視輸出檔案,並且可以將其下載以儲存在與 SAS 環境不同的環境中。請注意,我們有兩個 proc SQL 語句,並且它們的輸出都捕獲到一個檔案中。
ODS RTF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS.rtf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS rtf CLOSE;
執行上述程式碼後,我們將獲得以下結果:

SAS - 模擬
模擬是一種計算技術,它對許多不同的隨機樣本進行重複計算以估計統計量。使用 SAS,我們可以模擬具有現實世界系統中指定統計屬性的複雜資料。我們使用軟體構建系統的模型,並以數字方式生成可用於更好地理解現實世界系統行為的資料。設計計算機模擬模型的部分技巧是確定哪些方面的現實生活系統需要包含在模型中,以便模型生成的資料可用於做出有效決策。由於這種複雜性,SAS 擁有一個專用於模擬的軟體元件。
用於建立 SAS 模擬的 SAS 軟體元件稱為SAS Simulation Studio。其圖形使用者介面提供了一套完整的工具,用於構建、執行和分析離散事件模擬模型的結果。
下面列出了 SAS 模擬可以應用的不同型別的統計分佈。
- 從連續分佈模擬資料
- 從離散分佈模擬資料
- 從混合分佈模擬資料
- 從複雜分佈模擬資料
- 從多變數分佈模擬資料
- 逼近抽樣分佈
- 評估迴歸估計
SAS - 直方圖
直方圖是使用不同高度的條形顯示資料的圖形顯示。它將資料集中各種數字分組到許多範圍內。它還表示連續變數的機率分佈估計。在 SAS 中,PROC UNIVARIATE 用於使用以下選項建立直方圖。
語法
在 SAS 中建立直方圖的基本語法如下:
PROC UNIVARAITE DATA = DATASET; HISTOGRAM variables; RUN;以下是使用引數的描述:
資料集 是使用的資料集的名稱。
變數 是用於繪製直方圖的值。
簡單直方圖
透過指定變數的名稱和要考慮的範圍來對值進行分組,可以建立簡單的直方圖。
示例
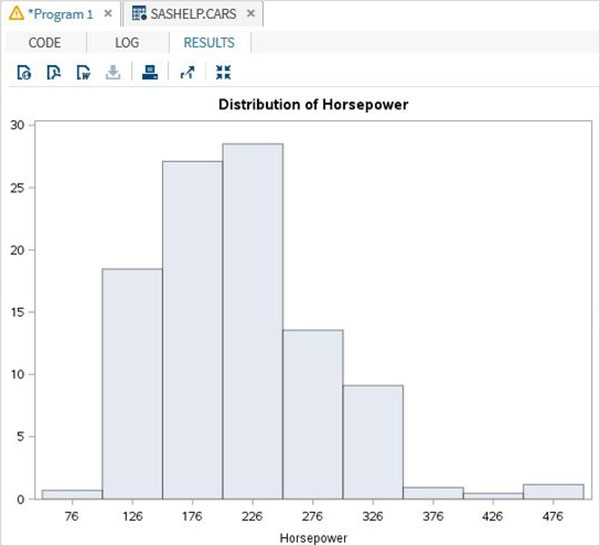
在下面的示例中,我們考慮變數 horsepower 的最小值和最大值,並取 50 的範圍。因此,值以 50 為步長形成一個組。
proc univariate data = sashelp.cars; histogram horsepower / midpoints = 176 to 350 by 50; run;
執行上述程式碼後,我們將獲得以下輸出:
帶曲線擬合的直方圖
我們可以使用其他選項將一些分佈曲線擬合到直方圖中。
示例
在下面的示例中,我們擬合一個分佈曲線,其均值和標準差值分別表示為 EST。此選項使用引數的估計值。
proc univariate data = sashelp.cars noprint; histogram horsepower / normal ( mu = est sigma = est color = blue w = 2.5 ) barlabel = percent midpoints = 70 to 550 by 50; run;
執行上述程式碼後,我們將獲得以下輸出:

SAS - 條形圖
條形圖以矩形條形表示資料,條形的長度與變數的值成正比。SAS 使用PROC SGPLOT 過程建立條形圖。我們可以在條形圖中繪製簡單條形和堆疊條形。在條形圖中,每個條形都可以賦予不同的顏色。
語法
在 SAS 中建立條形圖的基本語法如下:
PROC SGPLOT DATA = DATASET; VBAR variables; RUN;以下是使用引數的描述:
資料集 - 是使用的資料集的名稱。
變數 - 是用於繪製直方圖的值。
簡單條形圖
簡單條形圖是條形圖,其中資料集中的變量表示為條形。
示例
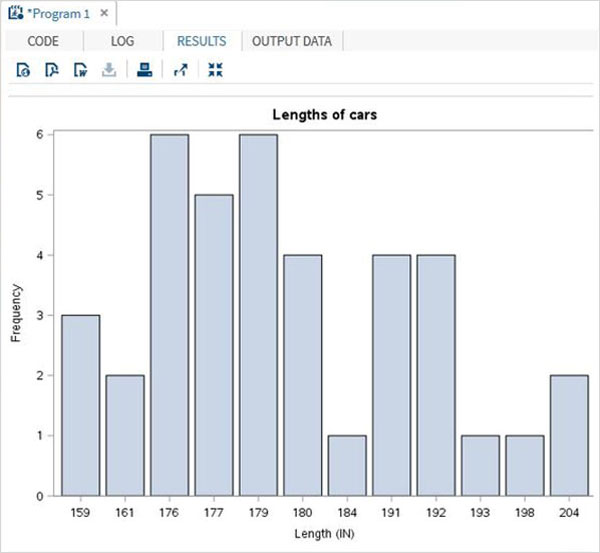
以下指令碼將建立一個條形圖,其中汽車的長度表示為條形。
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc SGPLOT data = work.cars1;
vbar length ;
title 'Lengths of cars';
run;
quit;
執行上述程式碼後,我們將獲得以下輸出:
堆疊條形圖
堆疊條形圖是條形圖,其中資料集中的變數相對於另一個變數進行計算。
示例
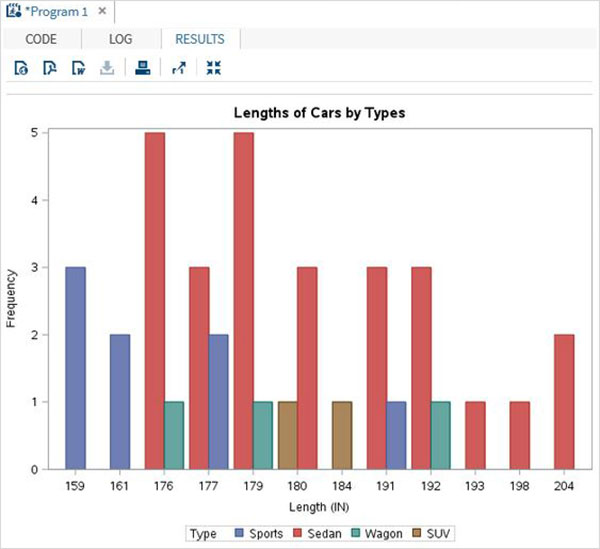
以下指令碼將建立一個堆疊條形圖,其中汽車的長度針對每種汽車型別進行計算。我們使用 group 選項來指定第二個變數。
proc SGPLOT data = work.cars1; vbar length /group = type ; title 'Lengths of Cars by Types'; run; quit;
執行上述程式碼後,我們將獲得以下輸出:

聚類條形圖
建立聚類條形圖是為了顯示變數的值如何在文化中分佈。
示例
以下指令碼將建立一個聚類條形圖,其中汽車的長度圍繞汽車型別進行聚類。因此,我們在長度 191 處看到兩個相鄰的條形,一個用於汽車型別“Sedan”,另一個用於汽車型別“Wagon”。
proc SGPLOT data = work.cars1; vbar length /group = type GROUPDISPLAY = CLUSTER; title 'Cluster of Cars by Types'; run; quit;
執行上述程式碼後,我們將獲得以下輸出:
SAS - 餅圖
餅圖是將值表示為圓的不同顏色切片的表示形式。切片被標記,並且與每個切片相對應的數字也顯示在圖表中。
在 SAS 中,餅圖是使用PROC TEMPLATE 建立的,它接受引數來控制百分比、標籤、顏色、標題等。
語法
在 SAS 中建立餅圖的基本語法如下:
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = variable /
DATALABELLOCATION = OUTSIDE
CATEGORYDIRECTION = CLOCKWISE
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = ' ';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
以下是使用引數的描述:
變數 是我們為其建立餅圖的值。
簡單餅圖
在此餅圖中,我們從資料集中獲取單個變數。餅圖是根據切片的值建立的,這些值表示變數的計數相對於變數的總值的比例。
示例
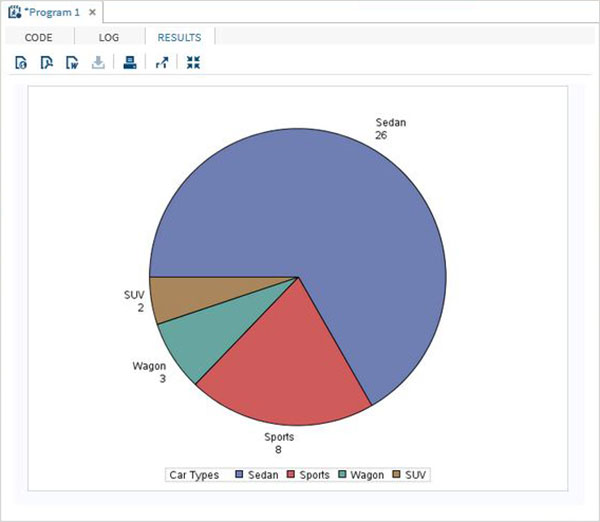
在下面的示例中,每個切片代表汽車型別在汽車總數中的比例。
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type /
DATALABELLOCATION = OUTSIDE
CATEGORYDIRECTION = CLOCKWISE
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;
執行上述程式碼後,我們將獲得以下輸出:
帶資料標籤的餅圖
在此餅圖中,我們表示每個切片的比例值和百分比值。我們還將標籤的位置更改為圖表內部。圖表的顯示樣式透過使用 DATASKIN 選項進行修改。它使用 SAS 環境中可用的內建樣式之一。
示例
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type /
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;
執行上述程式碼後,我們將獲得以下輸出:
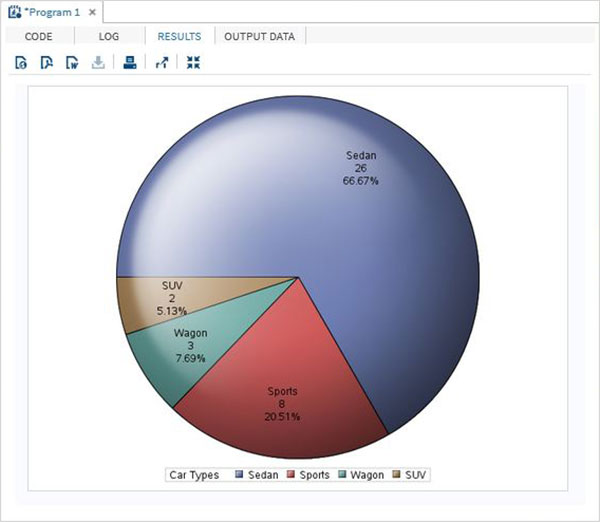
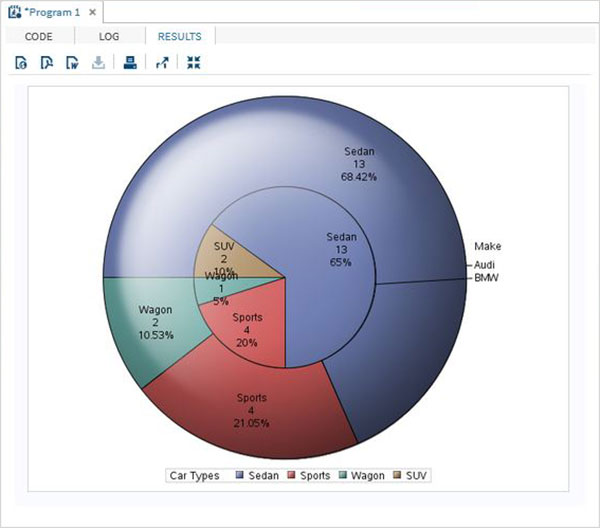
分組餅圖
在此餅圖中,圖中顯示的變數的值相對於同一資料集的另一個變數進行分組。每個組都成為一個圓,圖表中包含與可用組數量一樣多的同心圓。
示例
在下面的示例中,我們根據名為“Make”的變數對圖表進行分組。由於有兩個可用值(“Audi”和“BMW”),因此我們得到兩個同心圓,每個圓代表其自身製造商中的汽車型別切片。
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type / Group = make
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;
執行上述程式碼後,我們將獲得以下輸出:
SAS - 散點圖
散點圖是一種圖表型別,它使用笛卡爾平面中繪製的兩個變數的值。它通常用於找出兩個變數之間的關係。在 SAS 中,我們使用PROC SGSCATTER 建立散點圖。
請注意,我們在第一個示例中建立了名為 CARS1 的資料集,並在所有後續資料集中使用相同的資料集。此資料集在 SAS 會話結束前一直保留在工作庫中。
語法
在 SAS 中建立散點圖的基本語法如下:
PROC sgscatter DATA = DATASET; PLOT VARIABLE_1 * VARIABLE_2 / datalabel = VARIABLE group = VARIABLE; RUN;
以下是使用引數的描述:
資料集是資料集的名稱。
變數是從資料集中使用的變數。
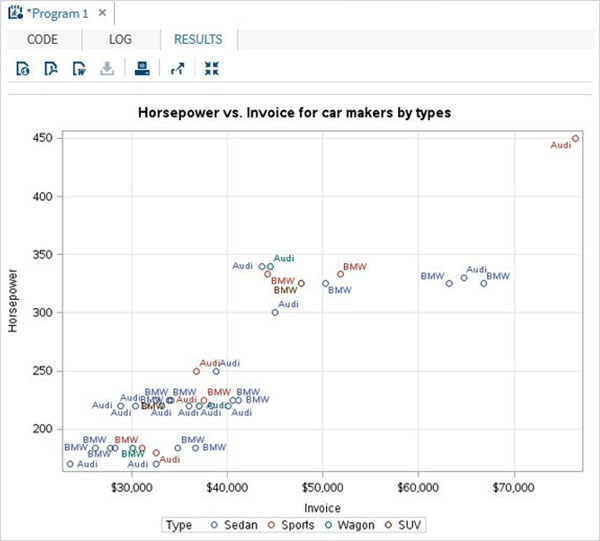
簡單散點圖
在簡單散點圖中,我們從資料集中選擇兩個變數,並根據第三個變數對它們進行分組。我們還可以標記資料。結果顯示了這兩個變數在笛卡爾平面上的散佈情況。
示例
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
TITLE 'Scatterplot - Two Variables';
PROC sgscatter DATA = CARS1;
PLOT horsepower*Invoice
/ datalabel = make group = type grid;
title 'Horsepower vs. Invoice for car makers by types';
RUN;
執行上述程式碼後,我們將獲得以下輸出:
帶預測的散點圖
我們可以使用一個估計引數來預測相關性的強度,方法是在值周圍繪製一個橢圓。我們使用過程中的附加選項來繪製橢圓,如下所示。
示例
proc sgscatter data = cars1;
compare y = Invoice x = (horsepower length)
/ group = type ellipse =(alpha = 0.05 type = predicted);
title
'Average Invoice vs. horsepower for cars by length';
title2
'-- with 95% prediction ellipse --'
;
format
Invoice dollar6.0;
run;
執行上述程式碼後,我們將獲得以下輸出:

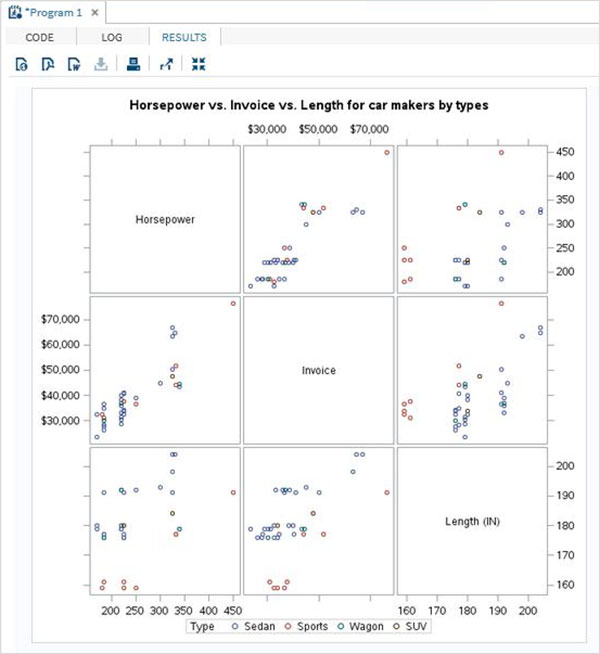
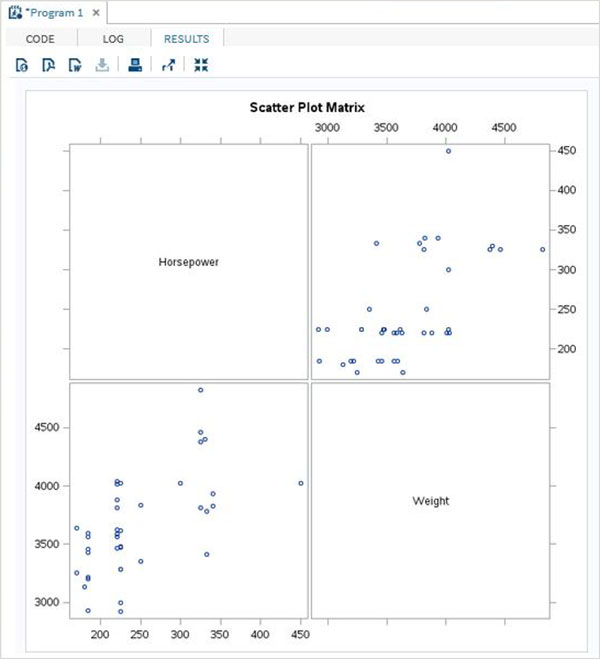
散點矩陣
我們還可以透過將多個變數分組為對來建立包含多個變數的散點圖。在下面的示例中,我們考慮三個變數並繪製一個散點圖矩陣。我們得到 3 對結果矩陣。
示例
PROC sgscatter DATA = CARS1; matrix horsepower invoice length / group = type; title 'Horsepower vs. Invoice vs. Length for car makers by types'; RUN;
執行上述程式碼後,我們將獲得以下輸出:
SAS - 箱線圖
箱線圖是透過其四分位數對數值資料組進行圖形表示。箱線圖也可能在框的垂直方向上延伸線條(須線),表示上四分位數和下四分位數之外的可變性。框的底部和頂部始終是第一和第三四分位數,框內的帶狀區域始終是第二四分位數(中位數)。在 SAS 中,使用PROC SGPLOT建立簡單的箱線圖,使用PROC SGPANEL建立面板箱線圖。
請注意,我們在第一個示例中建立了名為 CARS1 的資料集,並在所有後續資料集中使用相同的資料集。此資料集在 SAS 會話結束前一直保留在工作庫中。
語法
在 SAS 中建立箱線圖的基本語法如下:
PROC SGPLOT DATA = DATASET; VBOX VARIABLE / category = VARIABLE; RUN; PROC SGPANEL DATA = DATASET;; PANELBY VARIABLE; VBOX VARIABLE> / category = VARIABLE; RUN;以下是使用引數的描述:
資料集 - 是使用的資料集的名稱。
變數- 用於繪製箱線圖的值。
簡單箱線圖
在簡單箱線圖中,我們從資料集中選擇一個變數,並選擇另一個變數來形成一個類別。第一個變數的值被分類為與第二個變數中不同值的個數一樣多的組。
示例
在下面的示例中,我們選擇變數 horsepower 作為第一個變數,選擇 type 作為類別變數。因此,我們得到了每種型別的汽車的馬力值分佈的箱線圖。
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
PROC SGPLOT DATA = CARS1;
VBOX horsepower
/ category = type;
title 'Horsepower of cars by types';
RUN;
執行上述程式碼後,我們將獲得以下輸出:

垂直面板中的箱線圖
我們可以將一個變數的箱線圖分成多個垂直面板(列)。每個面板包含所有類別變數的箱線圖。但是,箱線圖將使用另一個第三個變數進一步分組,該變數將圖形劃分為多個面板。
示例
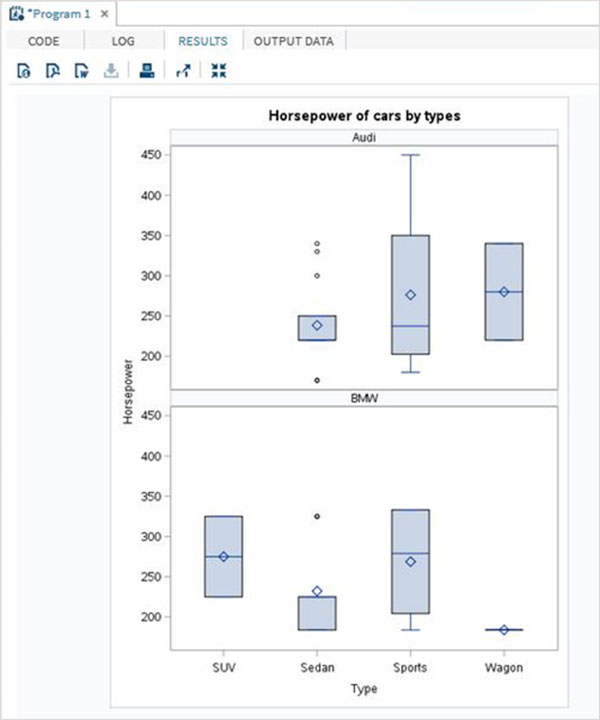
在下面的示例中,我們使用變數“make”對圖形進行了面板化。由於“make”有兩個不同的值,因此我們得到兩個垂直面板。
PROC SGPANEL DATA = CARS1; PANELBY MAKE; VBOX horsepower / category = type; title 'Horsepower of cars by types'; RUN;
執行上述程式碼後,我們將獲得以下輸出:
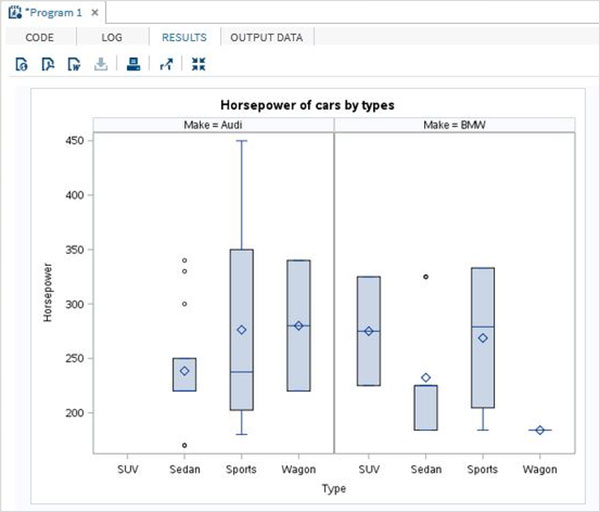
水平面板中的箱線圖
我們可以將一個變數的箱線圖分成多個水平面板(行)。每個面板包含所有類別變數的箱線圖。但是,箱線圖將使用另一個第三個變數進一步分組,該變數將圖形劃分為多個面板。在下面的示例中,我們使用變數“make”對圖形進行了面板化。由於“make”有兩個不同的值,因此我們得到兩個水平面板。
PROC SGPANEL DATA = CARS1; PANELBY MAKE / columns = 1 novarname; VBOX horsepower / category = type; title 'Horsepower of cars by types'; RUN;
執行上述程式碼後,我們將獲得以下輸出:
SAS - 算術平均數
算術平均值是透過對數值變數的值求和,然後將和除以變數個數得到的值。它也稱為平均值。在 SAS 中,算術平均值是使用PROC MEANS計算的。使用此 SAS 過程,我們可以找到所有變數或資料集的一些變數的平均值。我們還可以形成組並找到特定於該組的值的變數的平均值。
語法
在 SAS 中計算算術平均值的基本語法如下:
PROC MEANS DATA = DATASET; CLASS Variables ; VAR Variables;
以下是使用引數的描述:
資料集 - 是使用的資料集的名稱。
變數- 是資料集中的變數名稱。
資料集的平均值
透過僅提供資料集名稱而不提供任何變數,可以使用 PROC 來計算資料集中每個數值變數的平均值。
示例
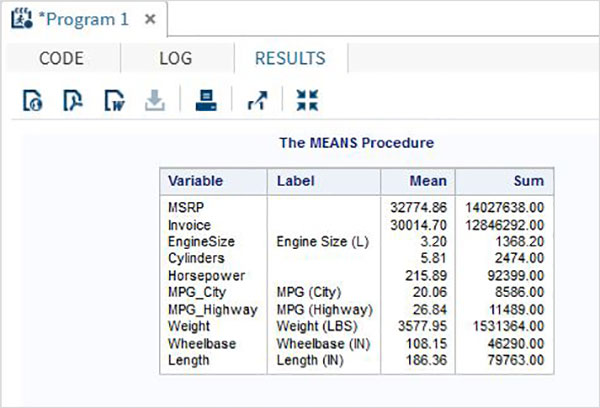
在下面的示例中,我們找到了名為 CARS 的 SAS 資料集中所有數值變數的平均值。我們將小數點後的最大位數指定為 2,並找到這些變數的總和。
PROC MEANS DATA = sashelp.CARS Mean SUM MAXDEC=2; RUN;
執行上述程式碼後,我們將獲得以下輸出:
選擇變數的平均值
我們可以透過在var選項中提供變數名稱來獲取一些變數的平均值。
示例
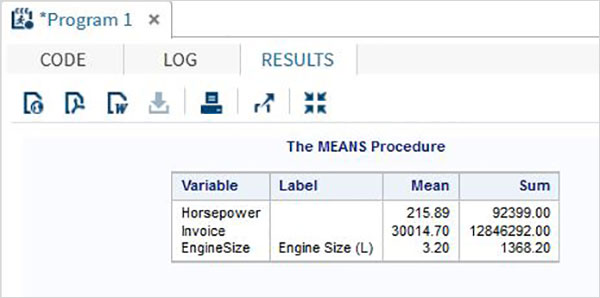
在下面,我們計算三個變數的平均值。
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2 ; var horsepower invoice EngineSize; RUN;
執行上述程式碼後,我們將獲得以下輸出:
按類別計算平均值
我們可以透過使用其他一些變數將數值變數組織成組來找到它們的平均值。
示例
在下面的示例中,我們找到了每種型別的汽車在每種製造商下的馬力變數的平均值。
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2; class make type; var horsepower; RUN;
執行上述程式碼後,我們將獲得以下輸出:

SAS - 標準差
標準差 (SD) 是衡量資料集中資料變化程度的指標。從數學上講,它衡量每個值與資料集的平均值的距離或接近程度。接近 0 的標準差值表示資料點傾向於非常接近資料集的平均值,而較高的標準差值表示資料點分佈在較寬的值範圍內。
在 SAS 中,SD 值是使用 PROC MEAN 和 PROC SURVEYMEANS 測量的。
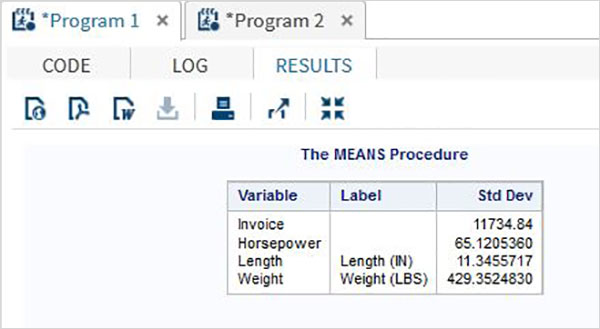
使用 PROC MEANS
要使用proc means測量 SD,我們在 PROC 步驟中選擇 STD 選項。它會顯示資料集中每個數值變數的 SD 值。
語法
在 SAS 中計算標準差的基本語法如下:
PROC means DATA = dataset STD;
以下是所用引數的說明:
資料集- 是資料集的名稱。
示例
在下面的示例中,我們從 SASHELP 庫中的 CARS 資料集中建立 CARS1 資料集。我們在 PROC means 步驟中選擇 STD 選項。
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc means data = CARS1 STD;
run;
當我們執行上述程式碼時,它會給出以下輸出:
使用 PROC SURVEYMEANS
此過程也用於測量 SD,以及一些高階功能,例如測量分類變數的 SD 以及提供方差估計。
語法
使用 PROC SURVEYMEANS 的語法如下:
PROC SURVEYMEANS options statistic-keywords ; BY variables ; CLASS variables ; VAR variables ;
以下是所用引數的說明:
BY- 指示用於建立觀測值組的變數。
CLASS- 指示用於分類變數的變數。
VAR- 指示將為其計算 SD 的變數。
示例
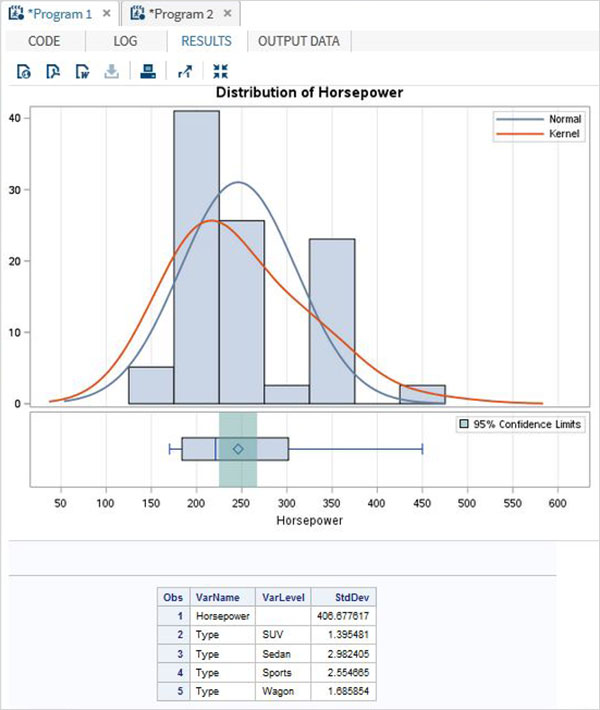
下面的示例描述了class選項的使用,該選項為類別變數中的每個值建立統計資料。
proc surveymeans data = CARS1 STD; class type; var type horsepower; ods output statistics = rectangle; run; proc print data = rectangle; run;
當我們執行上述程式碼時,它會給出以下輸出:
使用 BY 選項
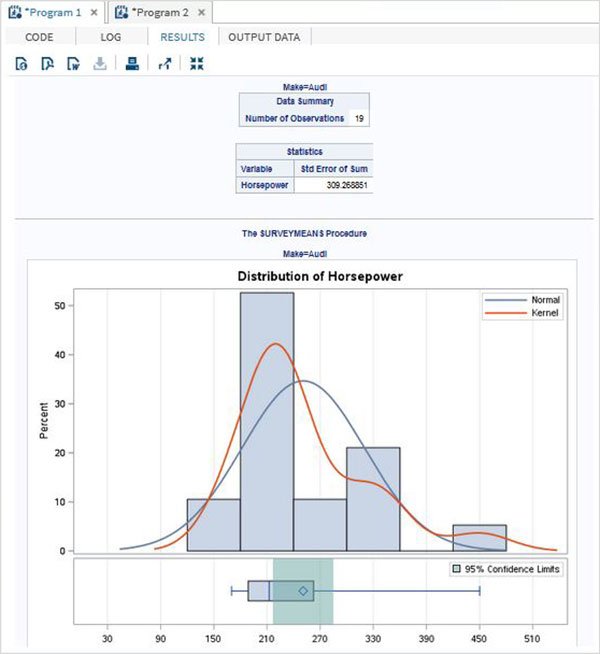
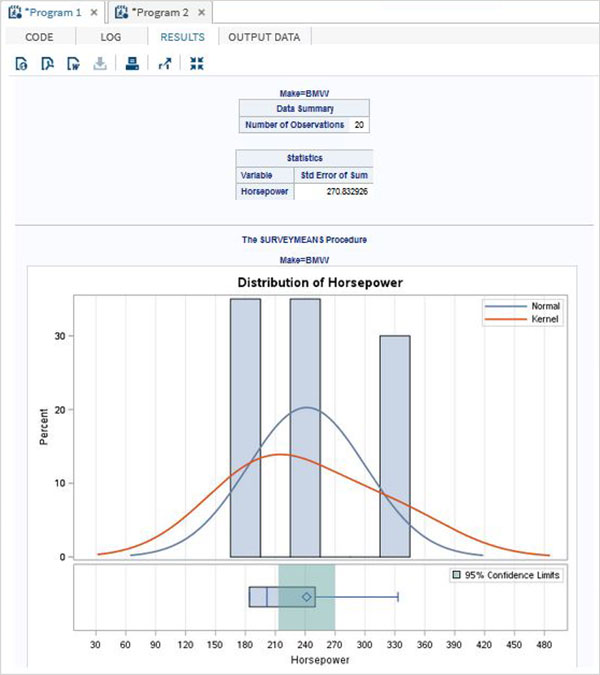
以下程式碼給出了 BY 選項的示例。在其中,結果按 BY 選項中的每個值進行分組。
示例
proc surveymeans data = CARS1 STD; var horsepower; BY make; ods output statistics = rectangle; run; proc print data = rectangle; run;
當我們執行上述程式碼時,它會給出以下輸出:
make = "Audi" 的結果
make = "BMW" 的結果
SAS - 頻率分佈
頻率分佈表顯示了資料集中資料點的頻率。表中的每個條目都包含特定組或區間內值出現的頻率或計數,並以此方式總結樣本中值的分佈。
SAS 提供了一個名為PROC FREQ的過程來計算資料集中資料點的頻率分佈。
語法
在 SAS 中計算頻率分佈的基本語法如下:
PROC FREQ DATA = Dataset ; TABLES Variable_1 ; BY Variable_2 ;
以下是所用引數的說明:
資料集是資料集的名稱。
變數_1是需要計算其頻率分佈的資料集的變數名稱。
變數_2是將頻率分佈結果分類的變數。
單變數頻率分佈
我們可以使用PROC FREQ確定單個變數的頻率分佈。在這種情況下,結果將顯示變數每個值的頻率。結果還顯示百分比分佈、累積頻率和累積百分比。
示例
在下面的示例中,我們找到了名為CARS1的資料集(從庫SASHELP.CARS建立)的變數 horsepower 的頻率分佈。我們可以看到結果分為兩類。一類是每種汽車的製造商。
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1 ;
tables horsepower;
by make;
run;
執行上述程式碼後,我們將獲得以下結果:

多變數頻率分佈
我們可以找到多個變數的頻率分佈,這些變數將它們分組為所有可能的組合。
示例
在下面的示例中,我們計算了汽車製造商的頻率分佈(按汽車型別分組),以及每種型別的汽車的頻率分佈(按每種製造商分組)。
proc FREQ data = CARS1 ; tables make type; run;
執行上述程式碼後,我們將獲得以下結果:
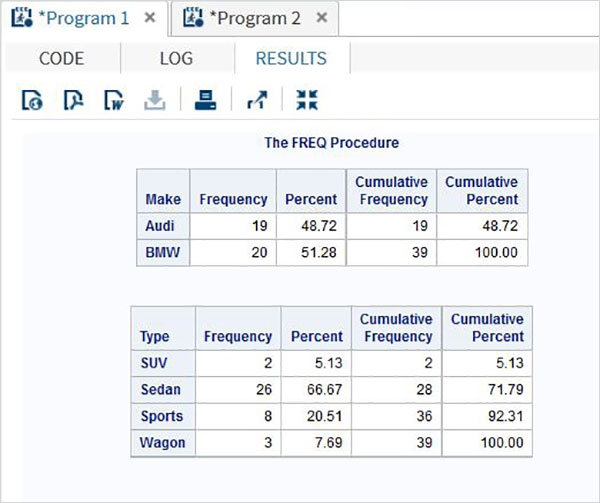
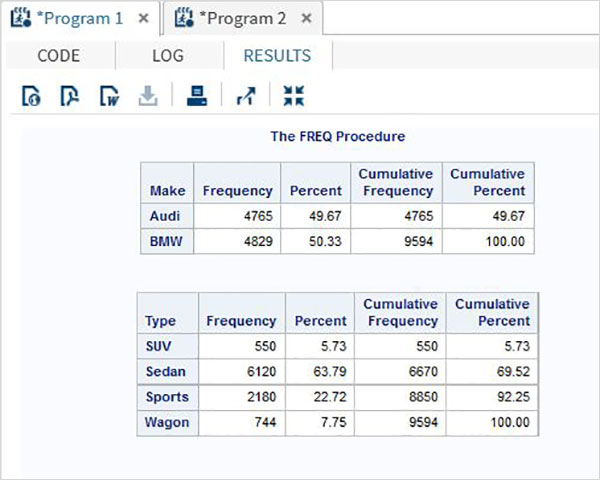
帶權重的頻率分佈
使用權重選項,我們可以計算出受變數權重影響的頻率分佈。在這裡,變數的值被視為觀測值的數量,而不是值的計數。
示例
在下面的示例中,我們計算了變數 make 和 type 的頻率分佈,並將權重分配給 horsepower。
proc FREQ data = CARS1 ; tables make type; weight horsepower; run;
執行上述程式碼後,我們將獲得以下結果:
SAS - 交叉表
交叉表涉及使用兩個或多個變數的所有可能組合生成交叉表,也稱為列聯表。在 SAS 中,它是使用PROC FREQ以及TABLES選項建立的。例如 - 如果我們需要每種型別的汽車中每種製造商的每種型號的頻率,那麼我們需要使用 PROC FREQ 的 TABLES 選項。
語法
在 SAS 中應用交叉表的基本語法如下:
PROC FREQ DATA = dataset; TABLES variable_1*Variable_2;
以下是所用引數的說明:
資料集是資料集的名稱。
變數_1 和變數_2是需要計算其頻率分佈的資料集的變數名稱。
示例
考慮查詢從資料集 cars1(從SASHELP.CARS建立)中每種汽車品牌下有多少種汽車型別的情況,如下所示。在這種情況下,我們需要各個頻率值以及跨製造商和跨型別的頻率值之和。我們可以觀察到結果顯示了跨行和跨列的值。
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1;
tables make*type;
run;
執行上述程式碼後,我們將獲得以下結果:

3 個變數的交叉表
當我們有三個變數時,我們可以將其中兩個變數分組,並將這兩個變數中的每一個與第三個變數進行交叉製表。因此,在結果中,我們有兩個交叉表。
示例
在下面的示例中,我們找到了每種型別的汽車和每種型號的汽車相對於汽車製造商的頻率。此外,我們使用 nocol 和 norow 選項來避免總和和百分比值。
proc FREQ data = CARS2 ; tables make * (type model) / nocol norow nopercent; run;
執行上述程式碼後,我們將獲得以下結果:
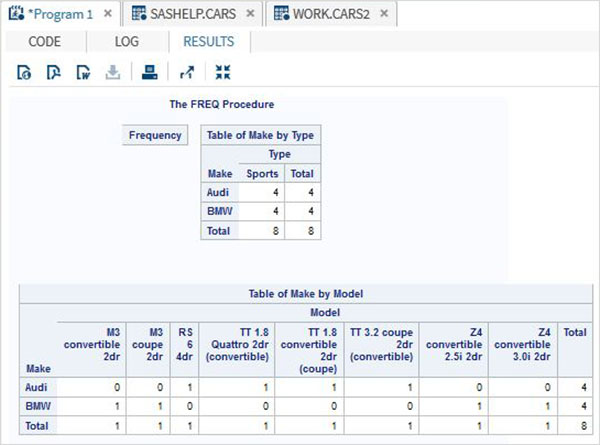
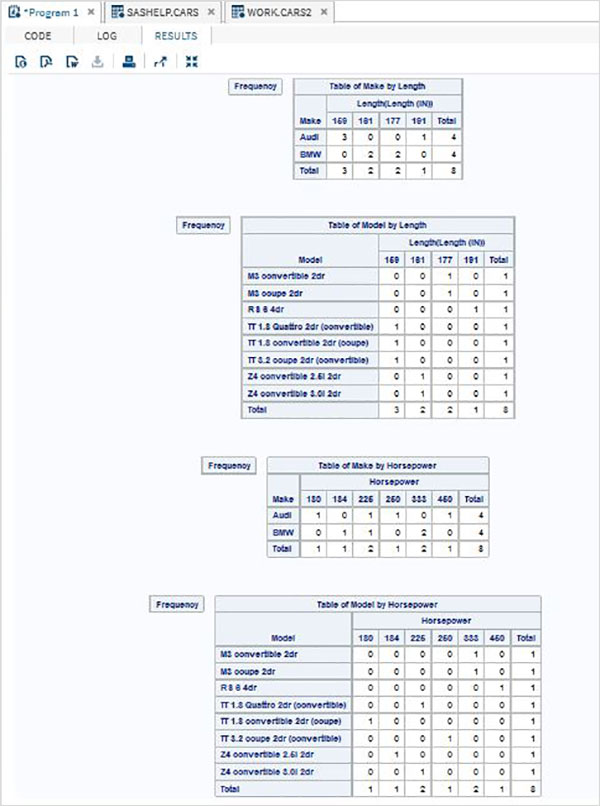
4 個變數的交叉表
對於 4 個變數,配對組合的數量增加到 4。組 1 中的每個變數都與組 2 中的每個變數配對。
示例
在下面的示例中,我們找到了每種製造商和每種型號的汽車長度的頻率。同樣,每種製造商和每種型號的馬力的頻率。
proc FREQ data = CARS2 ; tables (make model) * (length horsepower) / nocol norow nopercent; run;
執行上述程式碼後,我們將獲得以下結果:
SAS - T檢驗
T 檢驗用於透過比較其均值和均值差異來計算一個樣本或兩個獨立樣本的置信限。名為PROC TTEST的 SAS 過程用於對單個變數和變數對執行 t 檢驗。
語法
在SAS中應用PROC TTEST的基本語法如下:
PROC TTEST DATA = dataset; VAR variable; CLASS Variable; PAIRED Variable_1 * Variable_2;
以下是所用引數的說明:
資料集是資料集的名稱。
Variable_1和Variable_2是t檢驗中使用的變數名稱。
示例
下面我們來看一個單樣本t檢驗的例子,其中找到變數horsepower的t檢驗估計值,置信區間為95%。
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc ttest data = cars1 alpha = 0.05 h0 = 0;
var horsepower;
run;
執行上述程式碼後,我們將獲得以下結果:
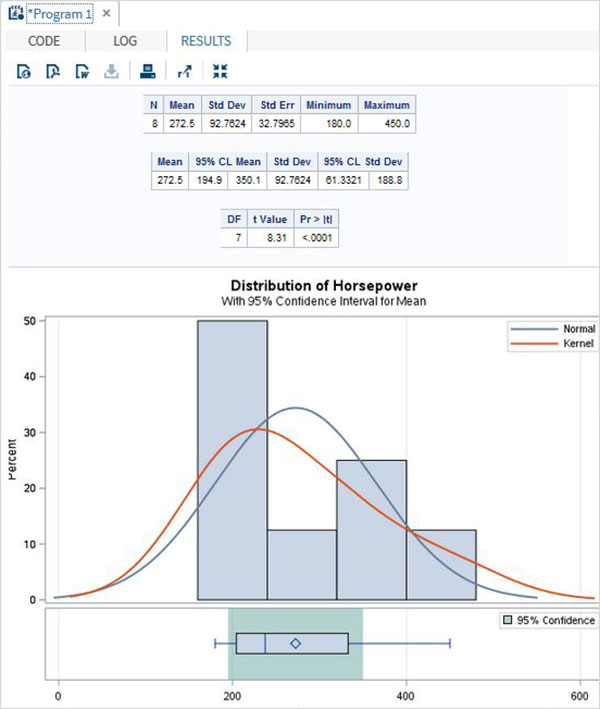
配對t檢驗
配對t檢驗用於檢驗兩個相關變數之間是否存在統計學上的顯著差異。
示例
由於汽車的長度和重量是相互依賴的,因此我們應用配對t檢驗,如下所示。
proc ttest data = cars1 ; paired weight*length; run;
執行上述程式碼後,我們將獲得以下結果:
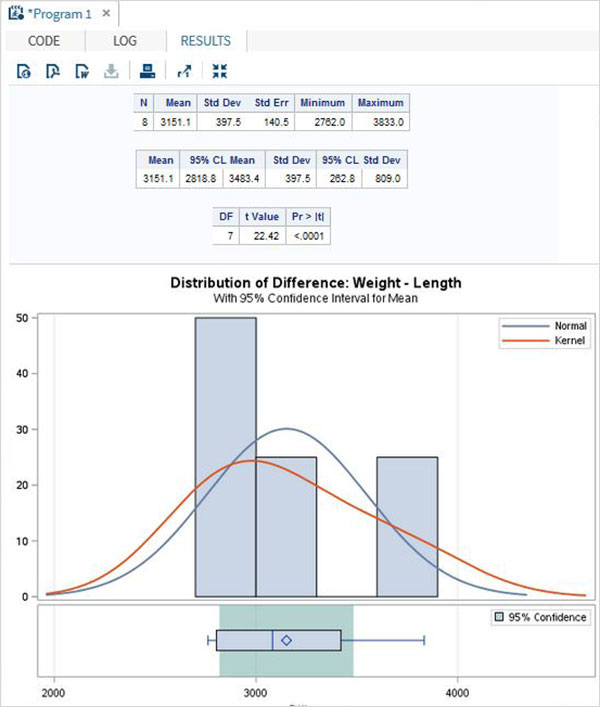
雙樣本t檢驗
此t檢驗旨在比較兩組之間同一變數的均值。
示例
在我們的例子中,我們比較了兩種不同汽車品牌(“奧迪”和“寶馬”)之間變數horsepower的均值。
proc ttest data = cars1 sides = 2 alpha = 0.05 h0 = 0; title "Two sample t-test example"; class make; var horsepower; run;
執行上述程式碼後,我們將獲得以下結果:

SAS - 相關分析
相關分析處理變數之間的關係。相關係數是衡量兩個變數之間線性關聯程度的指標。相關係數的值始終介於-1和+1之間。SAS提供了PROC CORR過程來查詢資料集中的變數對之間的相關係數。
語法
在SAS中應用PROC CORR的基本語法如下:
PROC CORR DATA = dataset options; VAR variable;
以下是所用引數的說明:
資料集是資料集的名稱。
Options是過程的附加選項,例如繪製矩陣等。
Variable是用於查詢相關性的資料集的變數名稱。
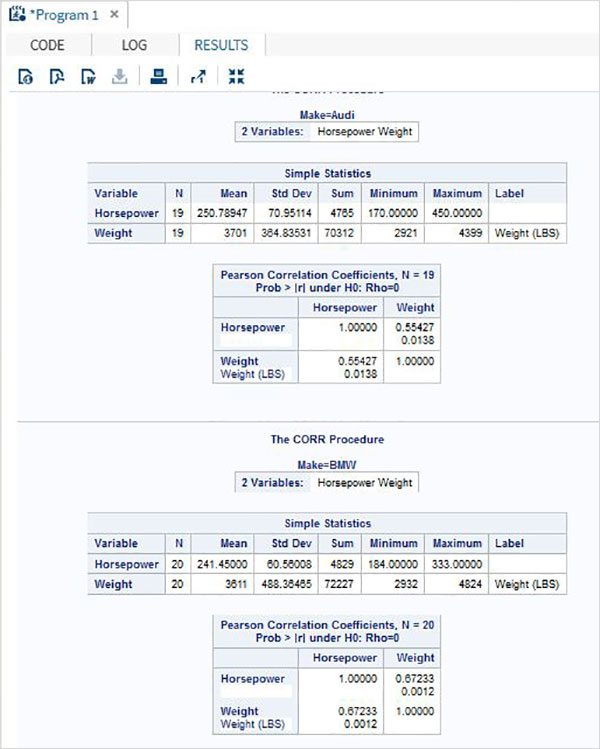
示例
可以透過在VAR語句中使用變數名來獲取資料集中變數對之間的相關係數。在下面的示例中,我們使用資料集CARS1,並獲得結果,顯示horsepower和weight之間的相關係數。
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc corr data = cars1 ;
VAR horsepower weight ;
BY make;
run;
執行上述程式碼後,我們將獲得以下結果:
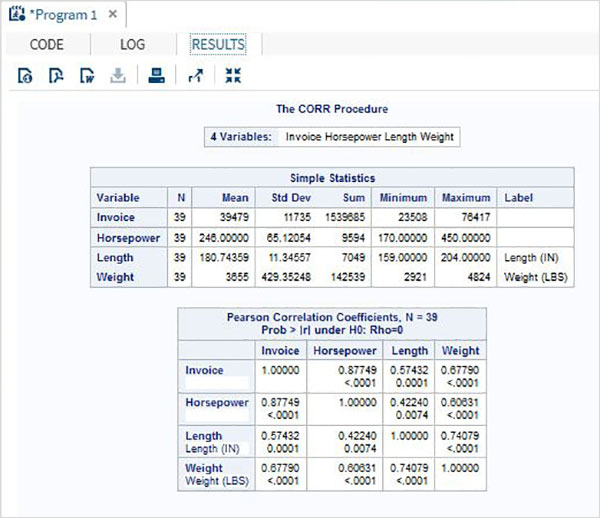
所有變數之間的相關性
可以透過簡單地應用該過程和資料集名稱來獲得資料集中所有可用變數之間的相關係數。
示例
在下面的示例中,我們使用資料集CARS1,並獲得結果,顯示每對變數之間的相關係數。
proc corr data = cars1 ; run;
執行上述程式碼後,我們將獲得以下結果:
相關矩陣
我們可以透過在PROC語句中選擇繪製矩陣選項來獲取變數之間的散點圖矩陣。
示例
在下面的示例中,我們獲取了horsepower和weight之間的矩陣。
proc corr data = cars1 plots = matrix ; VAR horsepower weight ; run;
執行上述程式碼後,我們將獲得以下結果:
SAS - 線性迴歸
線性迴歸用於識別因變數和一個或多個自變數之間的關係。提出了關係模型,並使用引數值的估計來開發估計的迴歸方程。
然後使用各種檢驗來確定模型是否令人滿意。如果是,則可以使用估計的迴歸方程來預測給定自變數值的因變數的值。在SAS中,PROC REG過程用於查詢兩個變數之間的線性迴歸模型。
語法
在SAS中應用PROC REG的基本語法如下:
PROC REG DATA = dataset; MODEL variable_1 = variable_2;
以下是所用引數的說明:
資料集是資料集的名稱。
variable_1和variable_2是用於查詢相關性的資料集的變數名稱。
示例
下面的示例顯示了使用PROC REG查詢汽車的兩個變數horsepower和weight之間相關性的過程。在結果中,我們看到了可以用來形成迴歸方程的截距值。
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc reg data = cars1;
model horsepower = weight ;
run;
執行上述程式碼後,我們將獲得以下結果:

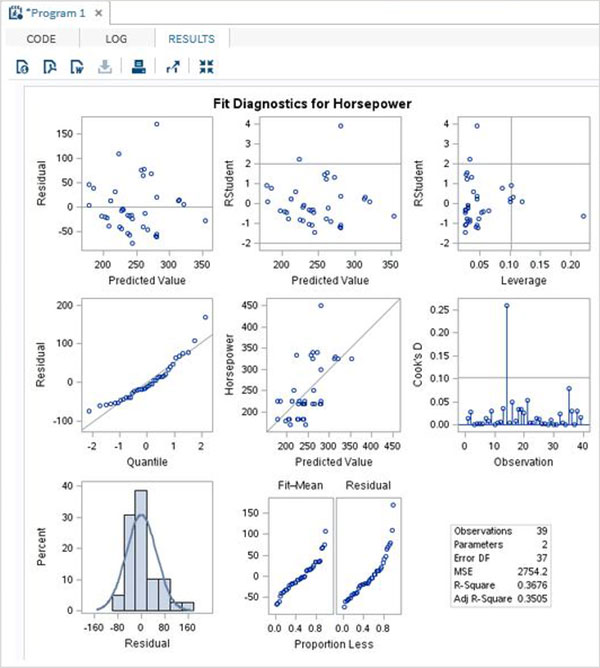
以上程式碼還提供了模型各種估計值的圖形檢視,如下所示。作為高階SAS過程,它不僅提供截距值作為輸出。
SAS - Bland Altman分析
Bland-Altman分析是一個用於驗證兩種旨在測量相同引數的方法之間一致性或不一致程度的過程。方法之間的高度相關性表明在資料分析中選擇了足夠好的樣本。在SAS中,我們透過計算變數值的均值、上限和下限來建立Bland-Altman圖。然後我們使用PROC SGPLOT建立Bland-Altman圖。
語法
在SAS中應用PROC SGPLOT的基本語法如下:
PROC SGPLOT DATA = dataset; SCATTER X = variable Y = Variable; REFLINE value;
以下是所用引數的說明:
資料集是資料集的名稱。
SCATTER語句建立以X和Y形式提供的值的散點圖。
REFLINE建立水平或垂直參考線。
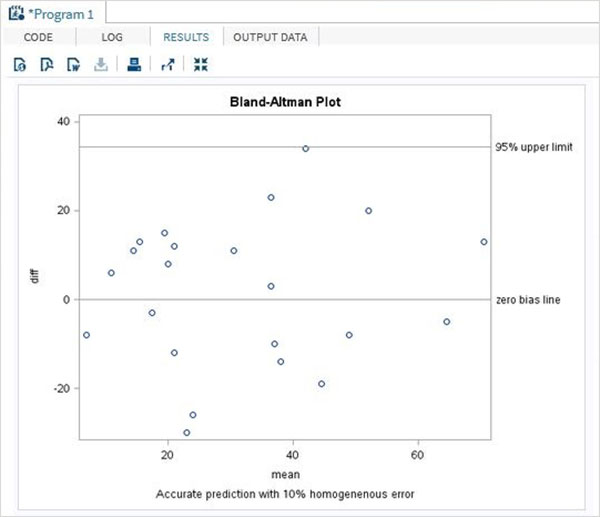
示例
在下面的示例中,我們採用兩種方法(名為new和old)生成的兩組實驗結果。我們計算變數值之間的差異以及相同觀測值的變數均值。我們還計算標準差值,以便用於計算的上限和下限。
結果顯示一個Bland-Altman圖作為散點圖。
data mydata;
input new old;
datalines;
31 45
27 12
11 37
36 25
14 8
27 15
3 11
62 42
38 35
20 9
35 54
62 67
48 25
77 64
45 53
32 42
16 19
15 27
22 9
8 38
24 16
59 25
;
data diffs ;
set mydata ;
/* calculate the difference */
diff = new-old ;
/* calculate the average */
mean = (new+old)/2 ;
run ;
proc print data = diffs;
run;
proc sql noprint ;
select mean(diff)-2*std(diff), mean(diff)+2*std(diff)
into :lower, :upper
from diffs ;
quit;
proc sgplot data = diffs ;
scatter x = mean y = diff;
refline 0 &upper &lower / LABEL = ("zero bias line" "95% upper limit" "95%
lower limit");
TITLE 'Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;
執行上述程式碼後,我們將獲得以下結果:
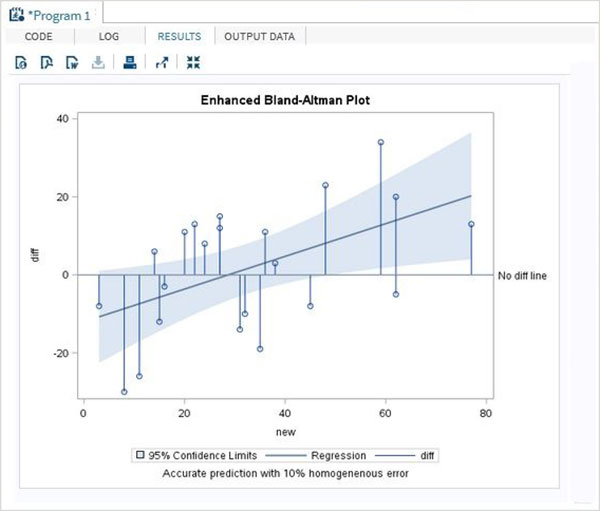
增強模型
在上述程式的增強模型中,我們得到了95%置信水平的曲線擬合。
proc sgplot data = diffs ;
reg x = new y = diff/clm clmtransparency = .5;
needle x = new y = diff/baseline = 0;
refline 0 / LABEL = ('No diff line');
TITLE 'Enhanced Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;
執行上述程式碼後,我們將獲得以下結果:
SAS - 卡方檢驗
卡方檢驗用於檢驗兩個分類變數之間的關聯性。它可以用於檢驗變數之間的依賴程度和獨立程度。SAS使用PROC FREQ以及選項chisq來確定卡方檢驗的結果。
語法
在SAS中應用PROC FREQ進行卡方檢驗的基本語法如下:
PROC FREQ DATA = dataset; TABLES variables /CHISQ TESTP = (percentage values);
以下是所用引數的說明:
資料集是資料集的名稱。
Variables是卡方檢驗中使用的資料集的變數名稱。
TESTP語句中的Percentage Values表示變數水平的百分比。
示例
在下面的示例中,我們考慮對資料集SASHELP.CARS中名為type的變數進行卡方檢驗。此變數有六個水平,我們根據檢驗設計為每個水平分配百分比。
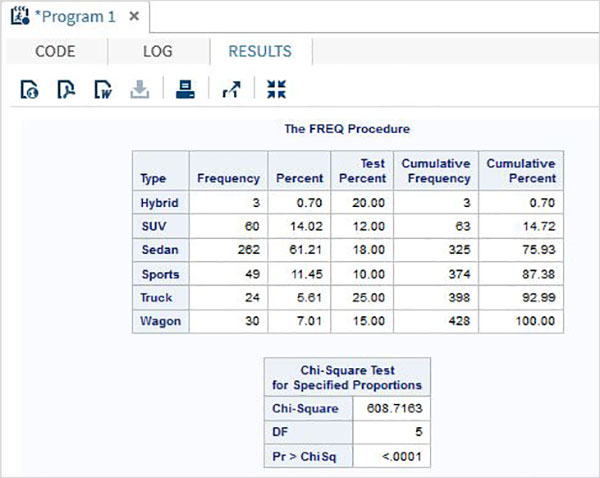
proc freq data = sashelp.cars; tables type /chisq testp = (0.20 0.12 0.18 0.10 0.25 0.15); run;
執行上述程式碼後,我們將獲得以下結果:
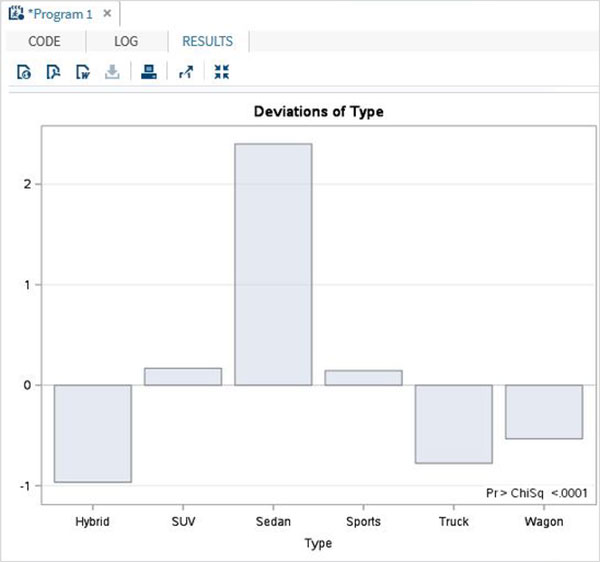
我們還得到了顯示變數type偏差的條形圖,如下面的螢幕截圖所示。
雙因素卡方檢驗
當我們將檢驗應用於資料集的兩個變數時,使用雙因素卡方檢驗。
示例
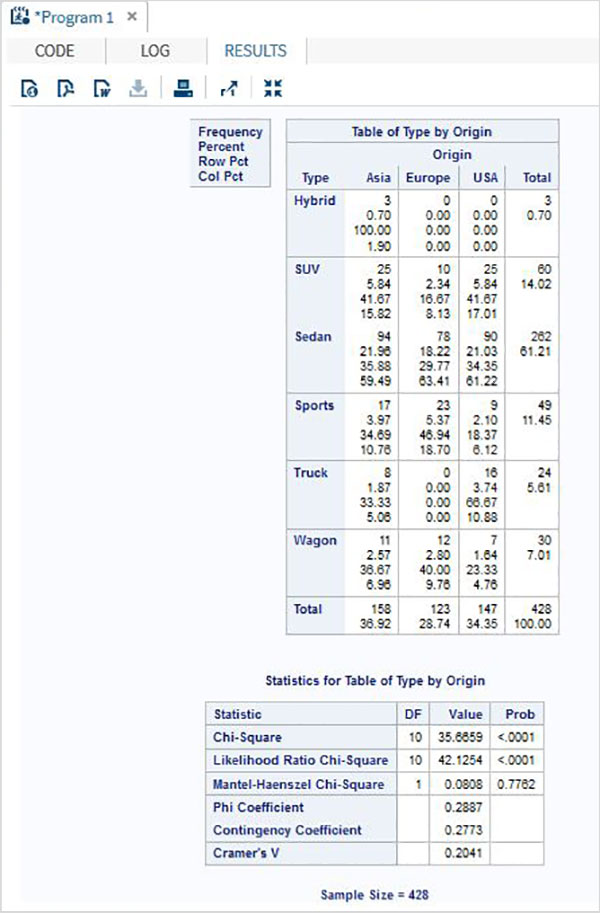
在下面的示例中,我們將卡方檢驗應用於名為type和origin的兩個變數。結果顯示了這兩個變數所有組合的表格形式。
proc freq data = sashelp.cars; tables type*origin /chisq ; run;
執行上述程式碼後,我們將獲得以下結果:
SAS - Fisher 精確檢驗
Fisher精確檢驗是一種統計檢驗,用於確定兩個分類變數之間是否存在非隨機關聯。在SAS中,這可以透過PROC FREQ來完成。我們使用Tables選項來使用進行Fisher精確檢驗的兩個變數。
語法
在SAS中應用Fisher精確檢驗的基本語法如下:
PROC FREQ DATA = dataset ; TABLES Variable_1*Variable_2 / fisher;
以下是所用引數的說明:
dataset是資料集的名稱。
Variable_1*Variable_2是來自資料集的變數。
應用Fisher精確檢驗
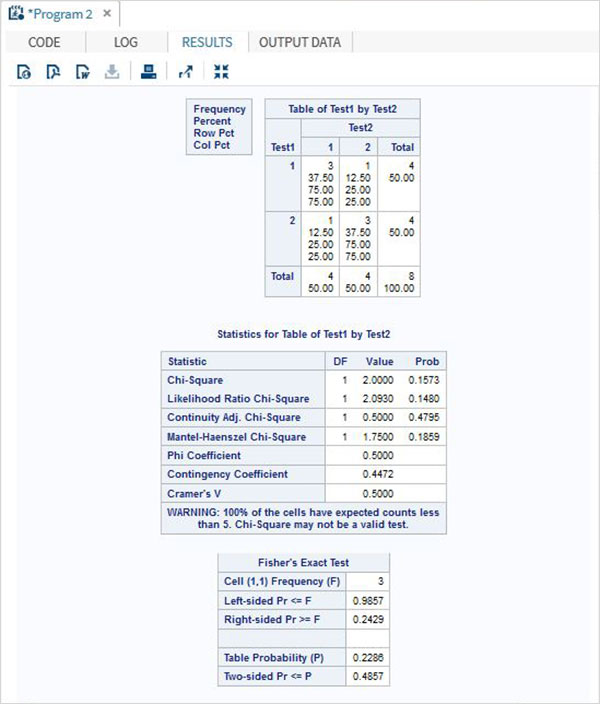
要應用Fisher精確檢驗,我們選擇兩個名為Test1和Test2的分類變數及其結果。我們使用PROC FREQ應用如下所示的檢驗。
示例
data temp; input Test1 Test2 Result @@; datalines; 1 1 3 1 2 1 2 1 1 2 2 3 ; proc freq; tables Test1*Test2 / fisher; run;
執行上述程式碼後,我們將獲得以下結果:
SAS - 重複測量分析
重複測量分析用於當隨機樣本的所有成員都在許多不同的條件下進行測量時。由於樣本依次暴露於每個條件,因此對因變數的測量會重複進行。在這種情況下使用標準方差分析是不合適的,因為它無法對重複測量之間的相關性進行建模。
應該清楚重複測量設計和簡單多元設計之間的區別。對於兩者,樣本成員都在幾個場合或試驗中進行測量,但在重複測量設計中,每個試驗代表在不同條件下對相同特徵的測量。
在SAS中,PROC GLM用於進行重複測量分析。
語法
PROC GLM在SAS中的基本語法如下:
PROC GLM DATA = dataset; CLASS variable; MODEL variables = group / NOUNI; REPEATED TRIAL n;
以下是所用引數的說明:
dataset是資料集的名稱。
CLASS給出用作分類變數的變數。
MODEL定義使用來自資料集的某些變數擬合的模型。
REPEATED定義每組的重複測量次數,以檢驗假設。
示例
考慮下面的例子,其中我們有兩組人進行藥物效果測試。記錄每個人的反應時間,針對測試的四種藥物型別。這裡對每組人進行了5次試驗,以觀察四種藥物型別效果之間相關性的強度。
DATA temp; INPUT person group $ r1 r2 r3 r4; CARDS; 1 A 2 1 6 5 2 A 5 4 11 9 3 A 6 14 12 10 4 A 2 4 5 8 5 A 0 5 10 9 6 B 9 11 16 13 7 B 12 4 13 14 8 B 15 9 13 8 9 B 6 8 12 5 10 B 5 7 11 9 ; RUN; PROC PRINT DATA = temp ; RUN; PROC GLM DATA = temp; CLASS group; MODEL r1-r4 = group / NOUNI ; REPEATED trial 5; RUN;
執行上述程式碼後,我們將獲得以下結果:
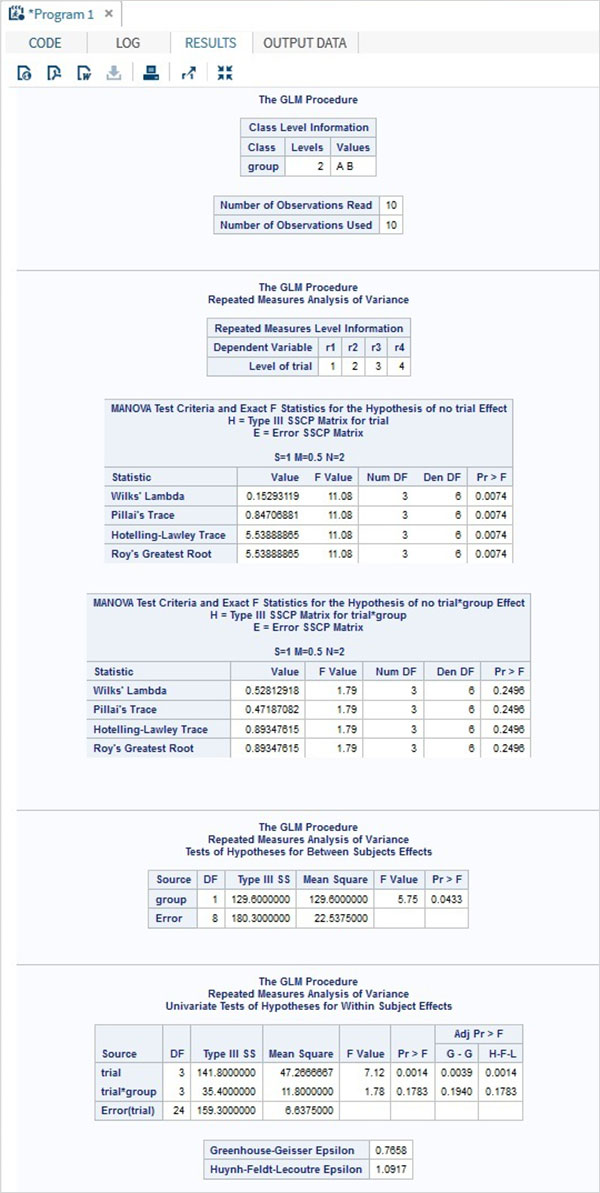
SAS - 單因素方差分析
ANOVA代表方差分析。在SAS中,它是使用PROC ANOVA完成的。它執行來自各種實驗設計的分析資料。在此過程中,在由分類變數(稱為自變數)識別的實驗條件下測量連續響應變數(稱為因變數)。假設響應的變化是由於分類中的影響造成的,隨機誤差解釋了其餘的變化。
語法
在SAS中應用PROC ANOVA的基本語法如下:
PROC ANOVA dataset ; CLASS Variable; MODEL Variable1 = variable2 ; MEANS ;
以下是所用引數的說明:
dataset是資料集的名稱。
CLASS給出用作分類變數的變數。
MODEL定義使用來自資料集的某些變數擬合的模型。
Variable_1和Variable_2是分析中使用的資料集的變數名稱。
MEANS定義均值的計算型別和比較。
應用方差分析
現在讓我們瞭解在SAS中應用方差分析的概念。
示例
讓我們考慮資料集SASHELP.CARS。在這裡,我們研究汽車型別及其馬力之間的依賴關係。由於汽車型別是具有分類值的變數,因此我們將它作為分類變數,並在MODEL中使用這兩個變數。
PROC ANOVA DATA = SASHELPS.CARS; CLASS type; MODEL horsepower = type; RUN;
執行上述程式碼後,我們將獲得以下結果:

使用MEANS應用方差分析
現在讓我們瞭解在SAS中使用MEANS應用方差分析的概念。
示例
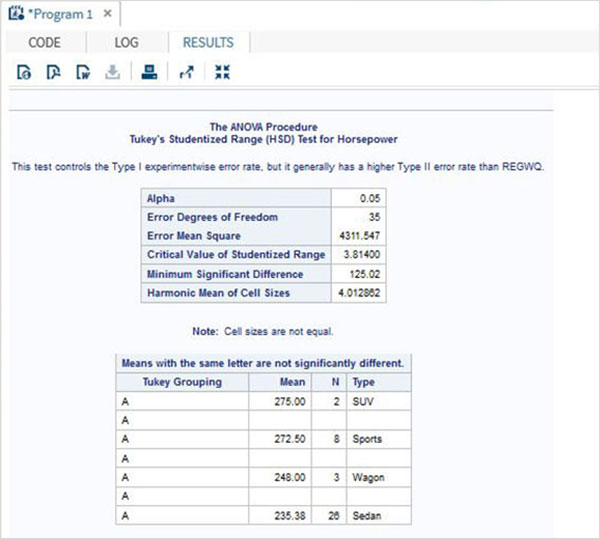
我們還可以透過在其中使用Turkey's Studentized方法比較各種汽車型別的均值來擴充套件模型。列出了汽車型別的類別以及每個類別的馬力均值以及一些附加值,例如誤差均方等。
PROC ANOVA DATA = SASHELPS.CARS; CLASS type; MODEL horsepower = type; MEANS type / tukey lines; RUN;
執行上述程式碼後,我們將獲得以下結果:
SAS - 假設檢驗
假設檢驗是使用統計資料來確定給定假設為真的機率。假設檢驗的常用過程包括以下四個步驟。
步驟1
制定零假設H0(通常,觀測結果是純偶然的結果)和備擇假設H1(通常,觀測結果顯示出真實效應以及偶然變化的成分)。
步驟2
確定可用於評估零假設真值的檢驗統計量。
步驟3
計算P值,它是假設原假設成立的情況下,獲得至少與觀察到的檢驗統計量一樣顯著的檢驗統計量的機率。P值越小,則反對原假設的證據越強。
步驟4
將p值與可接受的顯著性值alpha(有時稱為alpha值)進行比較。如果p <= alpha,則觀察到的效應具有統計學意義,原假設被排除,備擇假設有效。
SAS程式語言具有執行各種假設檢驗的功能,如下所示。
| 檢驗 | 描述 | SAS過程 |
|---|---|---|
| T檢驗 | t檢驗用於檢驗一個變數的均值是否與假設值顯著不同。我們還可以確定兩個獨立組的均值是否顯著不同,以及相關或配對組的均值是否顯著不同。 | PROC TTEST |
| 方差分析(ANOVA) | 它也用於在存在一個獨立分類變數時比較均值。當檢驗區間因變數的均值是否根據獨立分類變數的不同而不同時,我們希望使用單因素方差分析。 | PROC ANOVA |
| 卡方檢驗 | 我們使用卡方擬合優度檢驗來評估分類變數的頻率是否可能是由於偶然性造成的。無論分類變數的比例是否為假設值,都需要使用卡方檢驗。 | PROC FREQ |
| 線性迴歸 | 當想要檢驗一個變數預測另一個變數的程度時,使用簡單線性迴歸。多元線性迴歸允許檢驗多個變數預測感興趣變數的程度。在使用多元線性迴歸時,我們還假設預測變數是獨立的。 | PROC REG |