- SAS 教程
- SAS - 首頁
- SAS - 概述
- SAS - 環境
- SAS - 使用者介面
- SAS - 程式結構
- SAS - 基本語法
- SAS - 資料集
- SAS - 變數
- SAS - 字串
- SAS - 陣列
- SAS - 數值格式
- SAS - 運算子
- SAS - 迴圈
- SAS - 決策
- SAS - 函式
- SAS - 輸入方法
- SAS - 宏
- SAS - 日期和時間
- SAS 資料集操作
- SAS - 讀取原始資料
- SAS - 寫入資料集
- SAS - 合併資料集
- SAS - 合併資料集
- SAS - 子集資料集
- SAS - 排序資料集
- SAS - 格式化資料集
- SAS - SQL
- SAS - 輸出交付系統
- SAS - 模擬
- SAS 基本統計過程
- SAS - 算術平均數
- SAS - 標準差
- SAS - 頻率分佈
- SAS - 交叉表
- SAS - t檢驗
- SAS - 相關分析
- SAS - 線性迴歸
- SAS - Bland-Altman 分析
- SAS - 卡方檢驗
- SAS - Fisher 精確檢驗
- SAS - 重複測量分析
- SAS - 單因素方差分析
- SAS - 假設檢驗
- SAS 有用資源
- SAS - 快速指南
- SAS - 有用資源
- SAS - 問答
- SAS - 討論
SAS - 合併資料集
可以使用 **SET** 語句將多個 SAS 資料集連線起來以生成單個數據集。連線後的資料集中觀察值的總數是原始資料集中觀察值總數的和。觀察值的順序是連續的。第一個資料集中的所有觀察值後跟第二個資料集中的所有觀察值,依此類推。
理想情況下,所有組合資料集都具有相同的變數,但如果它們具有不同數量的變數,則結果中將顯示所有變數,較小資料集的變數將顯示缺失值。
語法
SAS 中 SET 語句的基本語法如下:
SET data-set 1 data-set 2 data-set 3.....;
以下是所用引數的說明:
**data-set1,data-set2** 是一個接一個地寫入的資料集名稱。
示例
考慮一個組織的員工資料,這些資料儲存在兩個不同的資料集中,一個用於 IT 部門,另一個用於非 IT 部門。為了獲取所有員工的完整詳細資訊,我們使用如下所示的 SET 語句連線這兩個資料集。
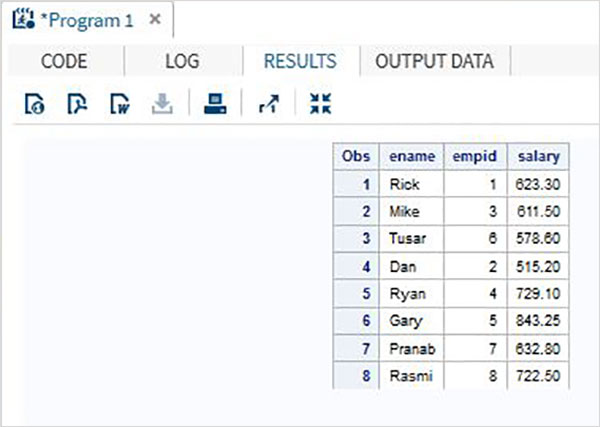
DATA ITDEPT; INPUT empid name $ salary ; DATALINES; 1 Rick 623.3 3 Mike 611.5 6 Tusar 578.6 ; RUN; DATA NON_ITDEPT; INPUT empid name $ salary ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; SET ITDEPT NON_ITDEPT; RUN; PROC PRINT DATA = All_Dept; RUN;
執行上述程式碼後,我們將獲得以下輸出。
場景
當我們在連線資料集時,資料集中存在許多差異,變數的結果可能會有所不同,但連線後的資料集中觀察值的總數始終是每個資料集中觀察值總數的和。我們將考慮以下關於此差異的許多場景。
不同數量的變數
如果其中一個原始資料集比另一個數據集具有更多數量的變數,則資料集仍然會合並,但在較小的資料集中,這些變數將顯示為缺失。
示例
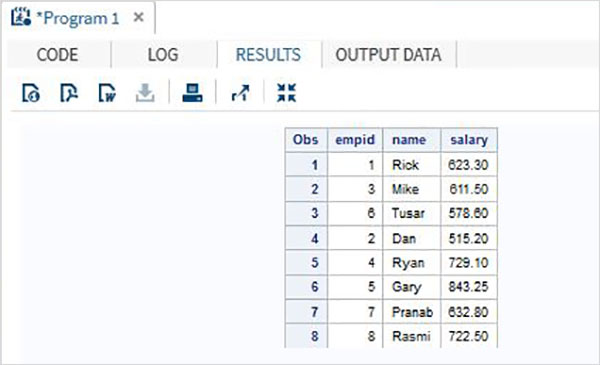
在下面的示例中,第一個資料集有一個名為 DOJ 的額外變數。在結果中,第二個資料集的 DOJ 值將顯示為缺失。
DATA ITDEPT; INPUT empid name $ salary DOJ date9. ; DATALINES; 1 Rick 623.3 02APR2001 3 Mike 611.5 21OCT2000 6 Tusar 578.6 01MAR2009 ; RUN; DATA NON_ITDEPT; INPUT empid name $ salary ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; SET ITDEPT NON_ITDEPT; RUN; PROC PRINT DATA = All_Dept; RUN;
執行上述程式碼後,我們將獲得以下輸出。
不同的變數名
在這種情況下,資料集具有相同數量的變數,但變數名稱之間存在差異。在這種情況下,普通的連線將在結果集中生成所有變數,併為兩個不同的變數提供缺失的結果。雖然我們可能不會更改原始資料集中的變數名稱,但我們可以在建立的連線資料集中應用 RENAME 函式。這將產生與普通連線相同的結果,當然,在一個新變數名稱代替原始資料集中存在的兩個不同變數名稱。
示例
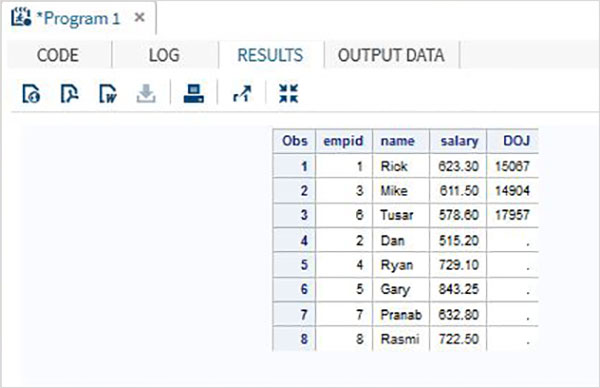
在下面的示例中,資料集 ITDEPT 的變數名為 **ename**,而資料集 **NON_ITDEPT** 的變數名為 **empname**。但這兩個變數都表示相同型別(字元)。我們像下面這樣在 SET 語句中應用 RENAME 函式。
DATA ITDEPT; INPUT empid ename $ salary ; DATALINES; 1 Rick 623.3 3 Mike 611.5 6 Tusar 578.6 ; RUN; DATA NON_ITDEPT; INPUT empid empname $ salary ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) ); RUN; PROC PRINT DATA = All_Dept; RUN;
執行上述程式碼後,我們將獲得以下輸出。
不同的變數長度
如果兩個資料集中變數的長度不同,則連線後的資料集將具有某些資料被截斷的值,用於長度較小的變數。如果第一個資料集的長度較小,就會發生這種情況。為了解決這個問題,我們像下面這樣對兩個資料集都應用較高的長度。
示例
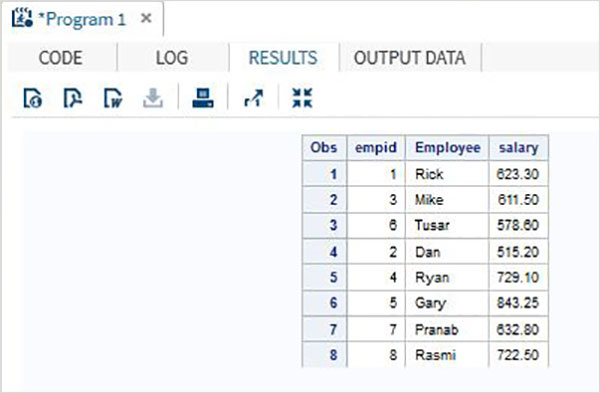
在下面的示例中,變數 **ename** 在第一個資料集中長度為 5,在第二個資料集中長度為 7。連線時,我們在連線後的資料集中應用 LENGTH 語句將 ename 長度設定為 7。
DATA ITDEPT; INPUT empid 1-2 ename $ 3-7 salary 8-14 ; DATALINES; 1 Rick 623.3 3 Mike 611.5 6 Tusar 578.6 ; RUN; DATA NON_ITDEPT; INPUT empid 1-2 ename $ 3-9 salary 10-16 ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; LENGTH ename $ 7 ; SET ITDEPT NON_ITDEPT ; RUN; PROC PRINT DATA = All_Dept; RUN;
執行上述程式碼後,我們將獲得以下輸出。