
 資料結構
資料結構 網路
網路 RDBMS
RDBMS 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
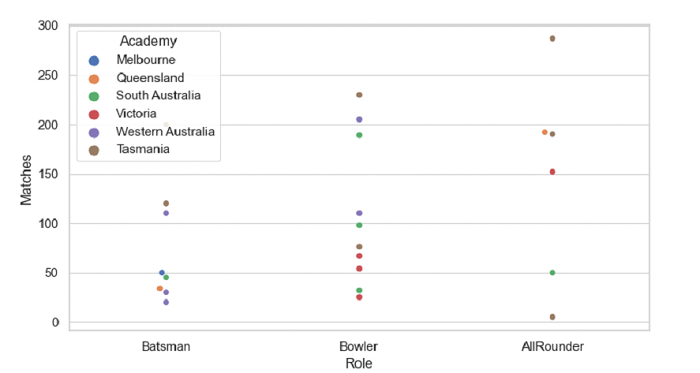
PHPPython Pandas - 使用 Seaborn 按兩個分類變數對群體分組
Seaborn 中的群體圖用於繪製帶有不重疊點的資料分類散點圖。為此,請使用 seaborn.swarmplot()。要按兩個分類變數對群體進行分組,請使用 x、y 或 hue 引數在 swarmplot() 中設定這些變數。
假設以下內容為 CSV 檔案形式的資料集:Cricketers2.csv
首先,匯入所需的庫 -
import seaborn as sb import pandas as pd import matplotlib.pyplot as plt
從 CSV 檔案將資料載入到 Pandas DataFrame -
dataFrame = pd.read_csv("C:\Users\amit_\Desktop\Cricketers2.csv")
按兩個分類變數對群體進行分組 -
sb.swarmplot(x = "Role", y = "Matches", hue = "Academy", data = dataFrame)
示例
以下為程式碼
import seaborn as sb
import pandas as pd
import matplotlib.pyplot as plt
# Load data from a CSV file into a Pandas DataFrame:
dataFrame = pd.read_csv("C:\Users\amit_\Desktop\Cricketers2.csv")
# set the theme
sb.set_theme(style="whitegrid")
sb.swarmplot(x = "Role", y = "Matches", hue = "Academy", data = dataFrame)
# display
plt.show()輸出
這將生成以下輸出

更新於:2021-09-27
353 次瀏覽

廣告