
 資料結構
資料結構 網路
網路 關係型資料庫管理系統 (RDBMS)
關係型資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP機器學習中的非線性SVM
介紹
支援向量機 (SVM) 是最流行的監督式機器學習演算法之一,用於分類和迴歸。SVM演算法力求找到n維資料之間的最佳擬合線,以將它們分成不同的類別。因此,新的資料點可以被分類到這些類別中的一個。
SVM演算法建立兩個超平面,同時最大化它們之間的間隔。位於這些超平面上的點稱為支援向量,因此得名支援向量機。
下圖顯示了用於將資料分類為兩類的 SVM 的決策邊界和超平面。
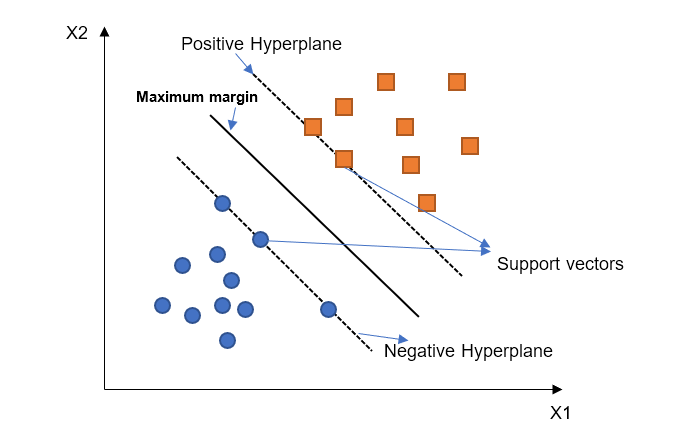
上圖解釋了線性 SVM 的工作原理。該圖顯示了透過最大間隔超平面相互分離的兩類。分離超平面旨在最大化負超平面和正超平面之間的間隔。支援向量分別是負超平面和正超平面上的點。
SVM演算法的一個例子可以是一個分類器,它用於根據包含貓和狗影像的資料集將影像分類為貓和狗。
非線性 SVM
我們在現實世界中接收到的資料並不總是線性可分的。雖然線性 SVM 是線性資料的完美 SVM 演算法型別,但可以使用非線性核的非線性 SVM 來有效地處理非線性資料。
一條直線可以對兩類進行分類,但要對兩類以上進行分類,則需要非線性 SVM,因為資料可能跨越 n 維。
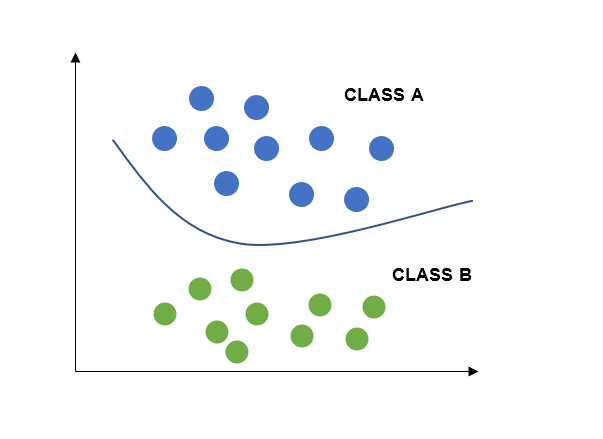
從上圖我們可以看出,在非線性SVM中,分離兩類的超平面是非線性的。在上圖中,兩類A類和B類透過非線性或曲線邊緣或超平面分離,該超平面傾向於最大化兩類之間的間隔。
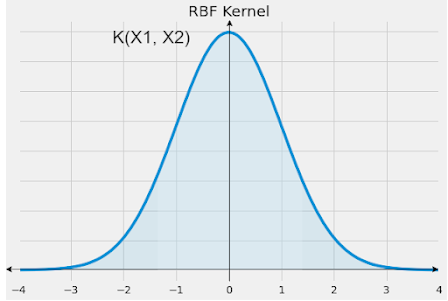
非線性 SVM 最常用的核是徑向基函式 (RBF) 核。但是,還有其他非線性核,例如多項式核。
讓我們進一步瞭解 RBF 核,並瞭解它如何在 SVM 中幫助進行非線性分類。
讓我們進一步瞭解 RBF 核,並瞭解它如何在 SVM 中幫助進行非線性分類。
RBF 核
核是一個函式,它將 n 維輸入資料轉換為 m 維,使得 n >> m。
RBF 核嘗試使用核技巧和資料轉換來使非線性可分資料幾乎線性。
RBF 核表示為。
示例
import numpy as np
from sklearn import datasets as ds
from sklearn import svm
import matplotlib.pyplot as plt
%matplotlib inline
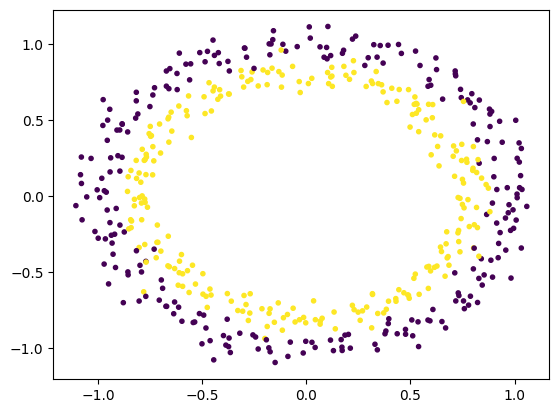
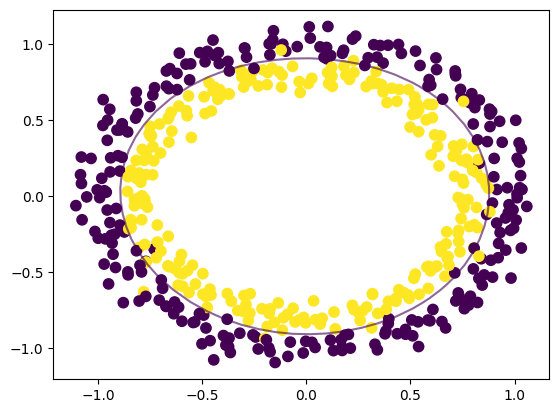
X, y = ds.make_circles(n_samples=500, noise=0.06)
plt.scatter(X[:, 0], X[:, 1], c=y, marker='.')
plt.show()
classifier_non_linear = svm.SVC(kernel='rbf', C=1.0)
classifier_non_linear.fit(X, y)
def boundary_plot(m, axis=None):
if axis is None:
axis = plt.gca()
limit_x = axis.get_xlim()
limit_x_y = axis.get_ylim()
x_lines = np.linspace(limit_x[0], limit_x[1], 30)
y_lines = np.linspace(limit_x_y[0], limit_x_y[1], 30)
Y, X = np.meshgrid(y_lines, x_lines)
xy = np.vstack([X.ravel(), Y.ravel()]).T
Plot = m.decision_function(xy).reshape(X.shape)
axis.contour(X, Y, Plot,
levels=[0], alpha=0.6,
linestyles=['-'])
plt.scatter(X[:, 0], X[:, 1], c=y, s=55)
boundary_plot(classifier_non_linear)
plt.scatter(classifier_non_linear.support_vectors_[:, 0], classifier_non_linear.support_vectors_[:, 1], s=55, lw=1, facecolors='none')
plt.show()
輸出
結論
非線性 SVM 是監督學習中用於分類和迴歸的一種非常方便的工具和高效的演算法。當資料是非線性可分時,它非常有用,它將使用非線性核(如 RBF 核)和任何其他合適的函式應用核技巧。

2K+ 次檢視
