
 資料結構
資料結構 網路
網路 關係資料庫管理系統
關係資料庫管理系統 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP機器學習中的簡單線性迴歸
簡介:簡單線性迴歸
迴歸的“監督機器學習”演算法用於預測連續特徵。
最簡單的迴歸程式,線性迴歸試圖透過擬合一個線性方程或“最佳擬合線”到觀察到的資料來解釋因變數與一個或多個自變數之間的關係。
根據用作輸入的特徵數量,線性迴歸有兩種版本
多元線性迴歸
簡單線性迴歸
在本文中,我們將探討簡單線性迴歸的概念。
簡單線性迴歸模型
簡單線性迴歸是一種迴歸方法,它模擬給定自變數與因變數之間的關係。簡單線性迴歸模型顯示線性或傾斜的直線關係。
簡單線性迴歸可以使用直線來建立兩個變數之間的關係。繪製直線的第一個步驟是找到斜率和截距,它們都定義了直線並最小化迴歸誤差。
簡單線性迴歸的最基本版本由一個x變數和一個y變數組成。x變數是自變數,因為它不能被因變數預測。y變數是因變數,因為它是我們預測的依賴項。
簡單線性迴歸的因變數必須具有連續或實數值。但是,自變數確實可以在連續或分類值上進行評估。
簡單線性迴歸演算法的兩個主要目標如下
模擬兩個變數之間的關係。例如,收入與支出、經驗與薪酬等之間的關係。
預測新的觀察結果。例如,根據溫度預測天氣,根據公司年度投資計算公司收入等。
下面的等式可以用來說明簡單線性迴歸模型
y= a0+a1x+ ε
其中
迴歸線的截距,用符號a0表示,可以透過令x=0得到。
迴歸線的斜率,或a1,表示線是上升還是下降。
ε = 錯誤項。
SLR 演算法的 Python 實現
在這裡,我們採用一個包含兩個變數的資料集:經驗(自變數)和收入(因變數)。此問題的目標是 -
為了確定這兩個變數是否相關,
將找到資料集的最佳擬合線。
自變數的變化如何影響因變數
在本節中,我們將構建一個簡單線性迴歸模型,以確定哪條線最能代表這兩個變數之間的關係。
在 Python 中實現簡單線性迴歸模型需要執行以下步驟。
步驟 1:資料預處理
資料預處理是建立簡單線性迴歸模型的第一步。本教程之前已經介紹過它。但是,將會有調整,如下面的步驟中所述 -
在匯入資料集、構建圖形和構建簡單線性迴歸模型之前,我們將匯入三個重要的庫。
import numpy as np import matplotlib.pyplot as mtplt import pandas as ps
然後將資料集載入到我們的程式碼中。
data_set= ps.read_csv('Salarynov_Data.csv')
透過執行上面的程式碼(ctrl+ENTER),我們可以透過選擇變數瀏覽器選項在我們的 Spyder IDE 螢幕上訪問資料集。
輸出中顯示了資料集,其中包括兩個變數經驗和薪資。
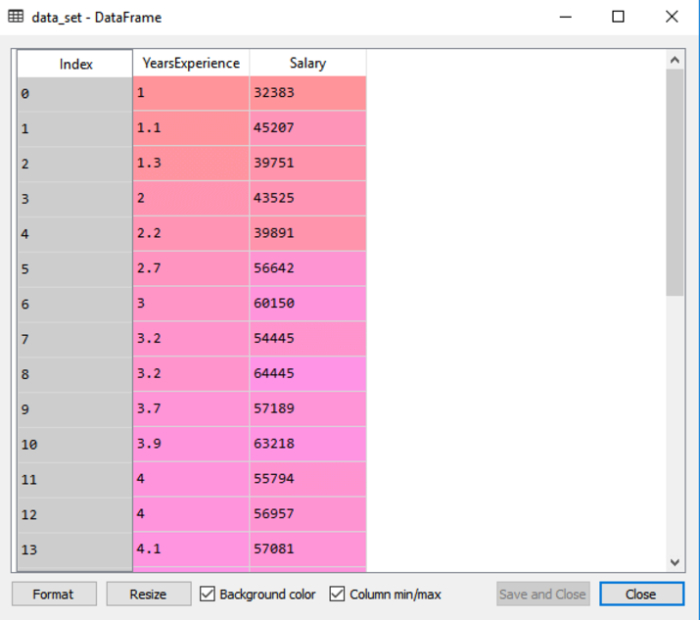
然後必須從提供的資料集中提取因變數和自變數。工作經驗是自變數,而薪資是因變數。程式碼如下
a= data_set.iloc[:, :-1].values b= data_set.iloc[:, 1].values
由於我們希望刪除資料集的最後一列,因此我們在上面的程式碼行中將變數 a 的值設定為 -1。我們為變數 b 使用數字 1,因為我們希望提取第二列,因為索引從 0 開始。
然後將訓練集和測試集分成兩組。在我們擁有的總共 30 個觀察值中,我們將使用 20 個觀察值用於訓練集,10 個觀察值用於測試集。我們將資料集劃分為訓練集和測試集,以便我們可以使用一組進行訓練,另一組進行測試我們的模型。
步驟 2. 將訓練集擬合到 SLR
下一步是將我們的模型擬合到訓練資料集。為此,我們將從 scikit-learn 線性模型包中匯入 Linear Regression 類。在匯入類之後,我們將建立一個迴歸器物件,它是該類的子類。
from sklearn.linear_model import LinearRegressionres regressor= LinearRegressionres() regressor.fit(a_train, b_train)
我們的因變數和自變數的訓練資料集 x_train 和 y_train 已提供給 fit() 函式。為了使模型能夠快速學習預測變數和目標變數之間的關係,我們將我們的迴歸器物件擬合到訓練集。
步驟 3. 測試結果預測
薪資是因變數,然後是自變數(經驗)。因此,我們的模型現在已準備好為新觀察結果預測結果。在此階段,我們將向模型提供一個測試資料集(新觀察結果),以檢視它是否可以預測所需的結果。
步驟 4. 視覺化訓練集的結果
將透過 scatter() 函式生成觀察值的散點圖。
我們將把員工的工作經驗繪製在 x 軸上,並將他們的薪資繪製在 y 軸上。我們將向函式傳遞訓練集的實際值——工作經驗(x_train)、訓練集的薪資(y_train)以及觀察值的顏色。
現在我們需要繪製迴歸線,我們將使用 pyplot 庫的 plot() 方法來做到這一點。將訓練集的工作經驗、訓練集 x_pred 的預期收入和線條顏色傳遞給此函式。
然後將提供繪圖的標題。在本例中,我們將名稱“Salary vs Experience (Training Dataset)”傳遞給 Pyplot 模組的 title() 函式。
最後,我們將使用 show() 建立一個圖形來描繪所有提到的內容。程式碼如下
mtplt.scatter(a_train, b_train, color="green") mtplt.plot(a_train, a_pred, color="red") mtplt.title("Salary vs Experience (Training Dataset)") mtplt.xlabel("Years of Experience") mtplt.ylabel("Salary(In Rupees)") mtplt.show()
輸出
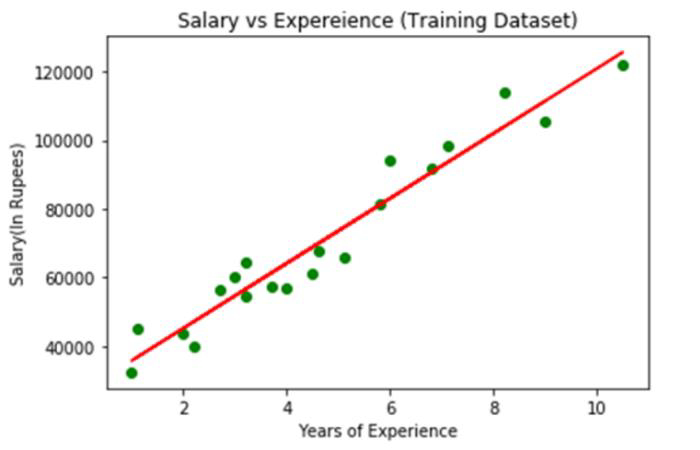
上圖中,觀察到的真實值以綠色點表示,而預期值則用紅色迴歸線包圍。迴歸線描繪了因變數和自變數的關係。
計算實際值和預期值之間的差距,可以瞭解線對資料的擬合程度。但是,正如我們從上圖中看到的那樣,大多數觀察值都靠近迴歸線,因此我們的模型對訓練集效果很好。
步驟 5. 顯示測試集的結果
在前面的階段,我們可視化了模型在訓練集上的效能。現在我們將對測試集重複此過程。整個程式將與上面的程式相同,除了將使用 x_test 和 y_test 代替 x_train 和 y_train。
mtplt.scatter(a_train, b_train, color="blue") mtplt.plot(a_train, a_pred, color="red") mtplt.title("Salary vs Experience (Test Dataset)") mtplt.xlabel("Years of Experience") mtplt.ylabel("Salary(In Rupees)") mtplt.show()
輸出
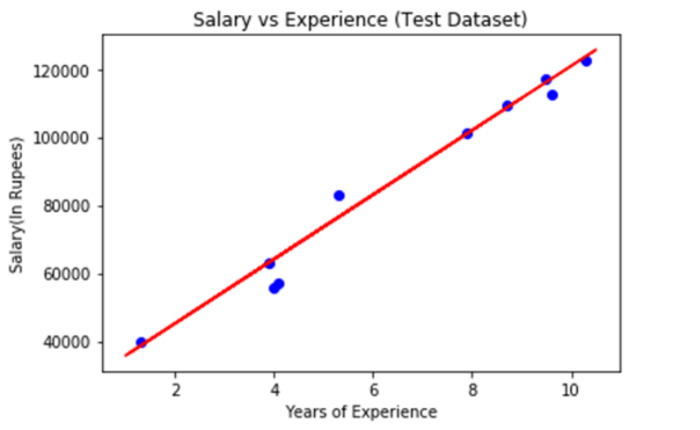
上圖中藍色表示觀察值,紅色迴歸線表示預測值。我們可以說我們的簡單線性迴歸是一個可靠的模型,並且能夠做出良好的預測,因為正如我們所看到的,大多數變數都靠近迴歸線。
結論
每個機器學習愛好者都必須熟悉線性迴歸演算法,機器學習初學者應該從這裡開始。它是一個相當簡單但有用的演算法。我們希望您發現這些資訊有用。

2K+ 閱讀量
