
 資料結構
資料結構 網路
網路 關係型資料庫管理系統
關係型資料庫管理系統 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP機器學習中的TabNet
在本教程中,我們將學習機器學習中的TabNet。據我們所知,深度學習模型越來越受歡迎,被用於解決表格資料問題。由於其選擇的特徵的相關性和有效性,XGBoost、RFE和LightGBM一直主導著這一領域。然而,TabNet改變了這一動態。
谷歌雲的研究人員在2019年提出了TabNet。TabNet背後的理念是成功地將深度神經網路應用於表格資料,而表格資料仍然包含大量使用者和處理後的資料。
TabNet結合了兩個世界的優點:它具有可解釋性(類似於更簡單的基於樹的模型),同時又很快(類似於深度神經網路)。這使得它成為零售、金融和保險等行業的理想選擇,包括預測、欺詐檢測和信用評分預測。
TabNet使用一種稱為順序注意力的機器學習方法,在模型的每個階段選擇要從中得出結論的模型特徵。透過這種方法,模型可以學習更精確的模型,並且可以解釋它是如何生成預測的。除了優於其他神經網路和決策樹之外,TabNet的架構還提供了易於理解的特徵歸因。TabNet實現了表格資料的深度學習,提供卓越的效能和可解釋性。
TabNet 架構
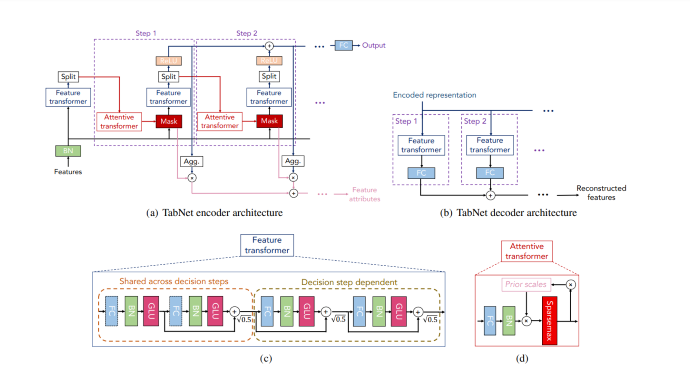
編碼器
因此,該設計主要由幾個連續的階段組成,這些階段將輸入從一個階段傳遞到另一個階段。報告還提供了一些關於如何選擇階段數量的建議。因此,當我們採取一個單一步驟時,會發生三個過程 -
四個連續的 GLU 決策塊構成了特徵轉換器。
一個注意力轉換器,使用稀疏矩陣實現稀疏特徵選擇,增強可解釋性並改進學習,因為容量保留給最重要的特徵。
掩碼與轉換器一起用於輸出決策引數 n(d) 和 n(a),然後將其傳遞到最終階段。
因此,對包含所有特徵的基本資料集沒有進行任何特徵工程。在進行批標準化 (BN) 後,資料被髮送到特徵轉換器,在那裡它經過四個 GLU 決策過程以生成兩個引數。
在迴歸或分類的情況下,提供輸出決策 n(d),它表示連續數字或類別的預測。
下一個注意力轉換器將接收 n(a) 作為輸入,在那裡啟動下一個迴圈。
解碼器
在決策階段,TabNet 解碼器架構包括一個特徵轉換器,後面跟著全連線層。
特徵轉換器
全連線層、批標準化層和 GLU 是特徵轉換器中前四個連續的塊。GLU 代表門控線性單元,它基本上是 x 的 sigmoid 乘以 x。(GLU = σ(x) . x)。因此,它們由兩個共享選擇過程組成,後面跟著兩個獨立的決策階段。由於每個階段使用相同的輸入特徵,因此層在兩個決策階段之間共享以實現穩健學習。透過確保整個網路中的變化不會波動太大,值為 √0.5 的歸一化有助於穩定學習。它產生前面解釋過的兩個輸出 n(d) 和 n(a)。
注意力轉換器
如您所見,注意力轉換器由四個層組成:FC、BN、先驗尺度和 Sparsemax。在批標準化之後,n(a) 輸入被髮送到一個全連線層。之後,它乘以先驗尺度,這是一個函式,指示您從先前階段對特徵的瞭解程度以及在這些階段中使用了多少特徵。如果將其設定為 1,則每個特徵都同等重要。但是,Tabnet 的主要優勢在於它在端到端學習中使用具有受控稀疏性的軟特徵選擇,其中一個模型同時處理特徵選擇和輸出對映。
需要記住的關鍵點
特徵、注意力和特徵掩碼轉換器構成 TabNet 編碼器。一個拆分塊拆分處理後的表示,以便它可以同時用於整體輸出和下一階段的注意力轉換器。特徵選擇掩碼為每個階段提供了有關模型功能的可解釋資料,並且可以組合掩碼以建立全域性特徵重要性歸因。
TabNet 解碼器的每個階段都包含一個特徵轉換器塊。
顯示了一個具有四層網路的特徵轉換器塊示例,其中兩層由所有決策步驟共享,另外兩層取決於決策步驟。每一層都由 BN、GLU 非線性函式和一個全連線 (FC) 層組成。
注意力轉換器塊透過使用過去的尺度資料調製單層對映來說明這一點,該資料聚合了每個特徵在當前決策步驟之前被使用的程度。
TabNet 的主要優勢
編碼多種資料型別,例如影像和表格資料,然後使用非線性函式進行求解。
無需進行特徵工程,可以將所有列都扔給模型,它將選擇最佳屬性,這些屬性也是可解釋的。
實現 TabNet
在本教程中,我們將使用來自“房價:高階迴歸技術”的資料。在這個例子中,我沒有進行任何特徵工程或資料清理,例如異常值去除,而是使用最基本的方法來處理任何缺失值。
您可以從這裡下載資料,並將其用於您的環境中。
安裝和匯入庫
!pip install pytorch-tabnet import pandas as pd import numpy as np from pytorch_tabnet.tab_model import TabNetRegressor from sklearn.model_selection import KFold
資料集 URL
train_data_url = "https://raw.githubusercontent.com/JayS420/Tabnetdataset/main/train.csv" test_data_url = "https://raw.githubusercontent.com/JayS420/Tabnetdataset/main/test.csv"
匯入資料集
train_data = pd.read_csv(train_data_url, error_bad_lines=False) test_data = pd.read_csv(test_data_url, error_bad_lines = False)
選擇一些特徵
features = ['LotArea', 'OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd', 'BsmtFinSF1', 'BsmtFinSF2', 'TotalBsmtSF', '1stFlrSF', 'LowQualFinSF', 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'HalfBath', 'BedroomAbvGr', 'Fireplaces', 'GarageCars', 'GarageArea', 'WoodDeckSF', 'OpenPorchSF', 'EnclosedPorch', 'PoolArea', 'YrSold']
拆分資料集
X = train_data[features] y = np.log1p(train_data["SalePrice"]) X_test = test_data[features] y_test = ["SalePrice"]
填充缺失資料
任何缺失資料都將用簡單的平均值填充。關於在使用交叉驗證之前執行此操作的相對優勢。
X = X.apply(lambda x: x.fillna(x.mean()),axis=0) X_test = X_test.apply(lambda x: x.fillna(x.mean()),axis=0)
將資料轉換為 NumPy
X = X.to_numpy() y = y.to_numpy().reshape(-1, 1) X_test = X_test.to_numpy()
應用 K 折交叉驗證
kf = KFold(n_splits=5, random_state=42, shuffle=True) predictions_array =[] CV_score_array =[] for train_index, test_index in kf.split(X): X_train, X_valid = X[train_index], X[test_index] y_train, y_valid = y[train_index], y[test_index] regressor = TabNetRegressor(verbose=0,seed=42) regressor.fit(X_train=X_train, y_train=y_train, eval_set=[(X_valid, y_valid)], patience=300, max_epochs=2000, eval_metric=['rmse']) CV_score_array.append(regressor.best_cost) predictions_array.append(np.expm1(regressor.predict(X_test))) predictions = np.mean(predictions_array,axis=0)
輸出
Device used : cpu Early stopping occured at epoch 1598 with best_epoch = 1298 and best_val_0_rmse = 0.16444 Best weights from best epoch are automatically used! Device used : cpu Early stopping occured at epoch 1075 with best_epoch = 775 and best_val_0_rmse = 0.12027 Best weights from best epoch are automatically used! Device used : cpu Early stopping occured at epoch 691 with best_epoch = 391 and best_val_0_rmse = 0.16395 Best weights from best epoch are automatically used! Device used : cpu Early stopping occured at epoch 679 with best_epoch = 379 and best_val_0_rmse = 0.16833 Best weights from best epoch are automatically used! Device used : cpu Early stopping occured at epoch 1283 with best_epoch = 983 and best_val_0_rmse = 0.11103 Best weights from best epoch are automatically used!
計算平均交叉驗證分數
print("The CV score is %.5f" % np.mean(CV_score_array,axis=0) )
輸出
The CV score is 0.15161
結論
總而言之,Tabnet 只是將深度學習應用於表格資料。由於學習能力被用於最顯著的特徵,因此它提高了學習效率,並透過使用順序注意力來選擇在每個決策步驟中要推理的特徵,從而實現了可解釋性。

2K+ 瀏覽量
