
 資料結構
資料結構 網路
網路 關係資料庫管理系統(RDBMS)
關係資料庫管理系統(RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP機器學習中的聚類
在機器學習中,聚類是一種從資料集中提取知識和發現隱藏模式的基本方法。聚類技術使我們能夠搜尋大量資料並透過將相關資料點組合在一起找到重要的結構。此過程有助於資料探索、細分和理解資料片段之間錯綜複雜的關係。我們可以透過自主定位叢集來從未標記的資料中提取重要見解,而無需預先確定的標籤。客戶細分、異常檢測、影像和文件組織以及基因組學研究只是聚類至關重要的幾個現實世界應用。在本文中,我們將仔細研究機器學習中的聚類。
理解聚類
聚類是根據資料點的內在特性將相關資料點組合在一起的過程,它是一種基本的機器學習方法。聚類旨在無需使用標籤或類別的情況下揭示資料集中潛在的模式、結構和關係。聚類屬於無監督學習的範疇,它使用未標記的資料而不是標記的資料來實現其探索和知識發現的目標。
在聚類的上下文中,資料點是指資料集中特定的例項或觀察結果。一組精確反映這些資料片段特徵的特性或屬性作為其表示。作為聚類中的一個關鍵概念,資料點之間的相似性表示它們基於其特徵值有多相似或相關。在考慮屬性變化的大小和方向的同時,差異性量化了資料點之間差異的程度。
聚類的型別
K均值聚類
K均值聚類是最著名和最簡單的聚類方法之一。資料將被分成K個獨特的叢集,其中K是一個預定的值。該方法迭代地將資料點分配給最接近的質心(代表點),然後更新質心,直到達到收斂。對於大型資料集,K均值聚類效率很高,儘管它對質心的初始選擇很敏感。
這是一個程式碼示例
from sklearn.cluster import KMeans import matplotlib.pyplot as plt # Creating a sample dataset for K-means clustering X = [[1, 2], [1.5, 1.8], [5, 8], [8, 8], [1, 0.6], [9, 11]] # Applying K-means clustering with K=2 kmeans = KMeans(n_clusters=2) kmeans.fit(X) # Visualizing the clustering result labels = kmeans.labels_ centroids = kmeans.cluster_centers_ for i in range(len(X)): plt.scatter(X[i][0], X[i][1], c='blue' if labels[i] == 0 else 'red') plt.scatter(centroids[:, 0], centroids[:, 1], marker='x', s=150, linewidths=5, c='black') plt.show()
輸出
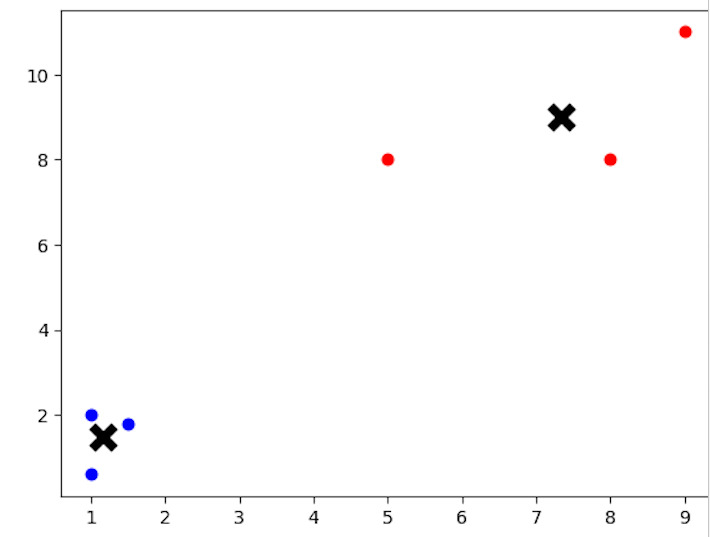
程式碼中,變數X表示的樣本資料集應用了K均值聚類技術。使用scikit-learn工具包中的KMeans類執行聚類。此示例中的資料集包含6個具有二維座標的資料點。我們透過設定n_clusters=2來告訴演算法在資料中查詢兩個叢集。在K均值模型擬合之後,程式碼繪製資料點和質心,每個資料點根據其分配的叢集著色,以顯示聚類結果。
層次聚類
層次聚類透過逐步合併或拆分叢集來組織它們成一個層次結構。它可以分為兩大類:凝聚式聚類和分裂式聚類。凝聚式聚類從將每個資料點視為一個單獨的叢集開始,然後逐漸合併最相似的叢集,直到只剩下一個叢集。
另一方面,分裂式聚類從將整個資料集作為一個單獨的叢集開始,並遞迴地將其分成更小的叢集,從而為每個資料點生成不同的叢集。
這是一個程式碼示例
from sklearn.cluster import AgglomerativeClustering import matplotlib.pyplot as plt import numpy as np # Creating a sample dataset for hierarchical clustering np.random.seed(0) X = np.random.randn(10, 2) # Applying hierarchical clustering hierarchical = AgglomerativeClustering(n_clusters=2) hierarchical.fit(X) # Visualizing the clustering result labels = hierarchical.labels_ for i in range(len(X)): plt.scatter(X[i, 0], X[i, 1], c='blue' if labels[i] == 0 else 'red') plt.show()
輸出

程式碼使用Scikit-Learn的AgglomerativeClustering類來說明層次聚類。它建立一個樣本資料集,由變數X表示,包含10個數據點和2維座標。將所需的叢集數量n_clusters=2應用於層次聚類方法。然後,程式碼繪製資料點,根據其分配的叢集為每個點著色,以檢視聚類結果。
基於密度的聚類 (DBSCAN)
例如,DBSCAN(基於密度的應用空間聚類帶有噪聲)根據特徵空間中資料點的密度查詢叢集。在將稀疏區域中的資料點分類為噪聲或異常值的同時,它將彼此足夠接近且密集的資料點聚類在一起。在處理形狀不規則的叢集和密度變化的叢集時,基於密度的聚類非常有效。
這是一個程式碼示例
from sklearn.cluster import DBSCAN import matplotlib.pyplot as plt import numpy as np # Creating a sample dataset for density-based clustering np.random.seed(0) X = np.concatenate((np.random.randn(10, 2) + 2, np.random.randn(10, 2) - 2)) # Applying DBSCAN clustering dbscan = DBSCAN(eps=0.6, min_samples=2) dbscan.fit(X) # Visualizing the clustering result labels = dbscan.labels_ for i in range(len(X)): plt.scatter(X[i, 0], X[i, 1], c='blue' if labels[i] == 0 else 'red') plt.show()
輸出
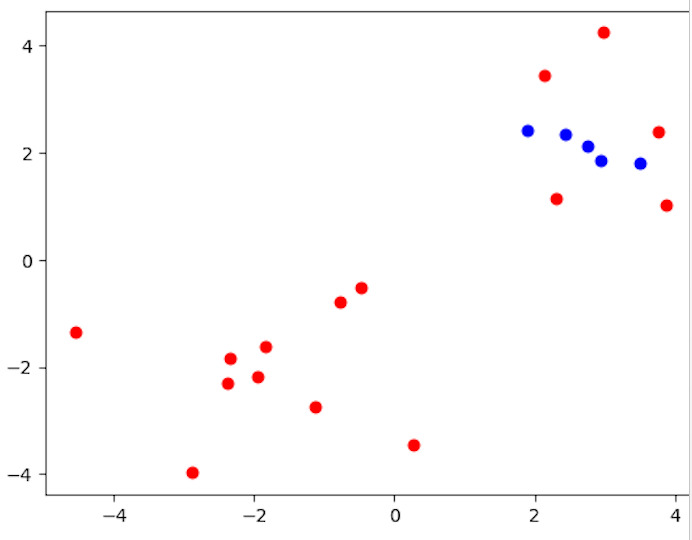
程式碼使用scikit-learn的DBSCAN類來說明基於密度的聚類。它生成一個包含20個二維資料點的樣本資料集,由變數X表示。使用DBSCAN方法時,使用引數eps=0.6(兩個樣本之間被視為屬於同一鄰域的最大距離)和min_samples=2(一個點被視為核心點的鄰域中的最小樣本數)。然後,程式碼繪製資料點,根據其所屬的叢集為每個點著色,以檢視聚類結果。
結論
聚類對於從資料集中獲取有見地的資訊和發現隱藏模式至關重要。聚類技術透過自動分組相關的資料片段,簡化了跨學科的不同應用,並實現了資料驅動的決策。透過理解各種聚類演算法、使用合適的評估指標並在實際情況下應用它們,我們能夠利用機器學習中聚類的潛力,為知識發現和創新開闢新的可能性。

392 次瀏覽
