
 資料結構
資料結構 網路
網路 關係資料庫管理系統(RDBMS)
關係資料庫管理系統(RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP機器學習中的Mini Batch K-means聚類演算法
介紹
聚類是一種將資料點分組到各個子組的技術,使得每個子組中的每個點都相似。它是一種無監督演算法,沒有標籤或真實值。Mini Batch K Means是K-Means演算法的一個變體,它從記憶體中隨機抽取批次進行訓練。
在本文中,讓我們詳細瞭解Mini Batch K-Means。在繼續Mini Batch K-Means之前,讓我們先看看一般的K-Means。
K-Means聚類方法
K-Means是一種迭代方法,它試圖將資料點分組到K個不同的子組中,使得它們互不重疊。同一個簇內的點儘可能相似,而不同簇之間的點儘可能不同。該演算法還使簇內點與簇中心的距離之和儘可能小,而簇間距離儘可能大。一個點可以屬於一個簇或子組。
Mini Batch K-Means聚類
Mini Batch K-Means聚類的基本概念是在記憶體中儲存固定大小的小批次資料點。在每次迭代中,從資料集中隨機抽取一個mini-batch,並且只使用mini-batch中的資料點來更新聚類的中心點。這使我們避免了像K-Means演算法那樣一次性使用整個資料集,從而解決了任何記憶體問題。該演算法收斂速度更快。學習率通常隨著迭代次數的增加而減小,因為它與分配的資料成反比。在mini-batch中,簇的更新是使用資料和原型的凸組合進行的,並且學習率隨著迭代次數的增加而減小。當重複次數增加時,新增新資料的效應減小,收斂速度加快,並且當連續兩次迭代中質心沒有受到影響時,觀察到收斂。
Mini Batch K-Means聚類的工作原理
隨機初始化簇的中心點。
從原始資料集中隨機選擇一個mini-batch資料。
將每個資料點分配到與其最近的中心點。
使用從mini-batch中分配的點計算簇中心點。
重複步驟2到4,直到中心點位置不再變化。
獲得最終的簇。
Minibatch K-Means的Python實現
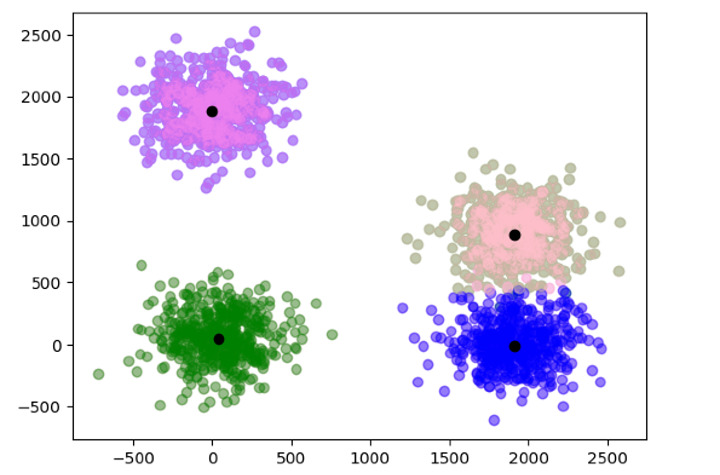
在下面的例子中,我們對2000個數據點使用了帶有mini-batch的KMeans聚類。定義初始聚類中心,然後使用資料訓練模型以找到最終的聚類中心並繪製它們。
from sklearn.cluster import MiniBatchKMeans
from sklearn.datasets import make_blobs as blobs
import matplotlib.pyplot as plt
import timeit as t
c = [[50, 50],[1900, 0],[1900, 900],[0, 1900]]
data, data_labels = blobs(n_samples = 2000, centers = c, cluster_std = 200)
color = ['pink', 'violet', 'green', 'blue']
for i in range(len(data)):
plt.scatter(data[i][0], data[i][1], color = color[data_labels[i]], alpha = 0.4)
k_means = MiniBatchKMeans(n_clusters=4, batch_size = 40)
st = t.default_timer()
k_means.fit(data)
e = t.default_timer()
label_a = k_means.labels_
cnt = k_means.cluster_centers_
print("Time taken : ",e-st)
for i in range(len(data)):
plt.scatter(data[i][0],data[i][1], color = color[label_a[i]], alpha = 0.4)
for i in range(len(cnt)):
plt.scatter(cnt[i][0], cnt[i][1], color = 'black')
輸出
Time taken : 0.01283279599999787
Mini Batch K-means的優勢
與K-Means演算法相比,它可以處理更大的資料集。
它的計算成本更低。
它的收斂速度更快。
結論
Mini-batch K-Means是一種比傳統K-means更好、更新的方法,它解決了一些缺點,例如使用更少的記憶體、在記憶體中處理大型資料集以及更快的收斂速度。

793 次瀏覽
