
 資料結構
資料結構 網路
網路 關係型資料庫管理系統
關係型資料庫管理系統 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP機器學習演算法的統計比較
預測建模和資料驅動決策建立在機器學習演算法之上。這些演算法使計算機能夠透過學習資料中的模式和相關性來提供精確的預測和有見地的資訊。由於存在許多不同的演算法可供選擇,因此瞭解它們的獨特特性併為特定情況選擇最佳演算法非常重要。
透過對每種演算法的效能提供公正的評估,統計比較在演算法選擇中起著至關重要的作用。透過使用統計度量來對比演算法,我們可以評估演算法的優勢、劣勢以及對特定任務的適用性。它使我們能夠將演算法有效性指標(如召回率、精確率和準確率)量化為數值。在本文中,我們將對機器學習演算法進行統計比較。
理解統計比較
統計比較是評估機器學習演算法有效性的一個關鍵組成部分。統計比較是指使用統計指標客觀地評估和對比不同演算法有效性的方法。它使我們能夠公平地進行比較,並從結果中得出有意義的結論。
關鍵指標和評估技術
準確率、精確率、召回率和F1分數:這些指標大多數情況下用於分類任務。準確率評估演算法預測的總體準確性,而精確率則計算正確預測的正例的百分比。召回率,通常稱為靈敏度,衡量演算法識別正例的能力。F1分數透過將準確率和召回率組合成單個統計量來提供對分類能力的全面評估。
混淆矩陣:混淆矩陣提供了演算法分類結果的詳細細分。它顯示了真陽性、真陰性、假陽性、假陰性的數量,從而更深入地瞭解演算法在各個類別中的表現。
ROC曲線和AUC:受試者工作特徵(ROC)曲線以圖形方式顯示了在不同分類閾值下真陽性率和假陽性率之間的權衡。曲線下面積(AUC)表示演算法在所有可能閾值上的效能。更高的AUC值表示更好的分類效能。
交叉驗證:交叉驗證是一種評估演算法在不同資料集子集上的效能的方法。透過將資料集分成多個摺疊並迭代地在不同組合上訓練和評估演算法,交叉驗證有助於評估方法的泛化能力並減少過擬合。
偏差-方差權衡:偏差-方差權衡是統計比較中的一個核心概念。它涉及到在模型識別資料中細微模式的能力(低偏差)和其對噪聲或微小變化的敏感性(高方差)之間取得平衡。找到最佳平衡點對於確保演算法在訓練資料和未知資料上都能有效地執行至關重要。
機器學習演算法的統計比較
線性迴歸
這種技術作為迴歸分析的基本方法,用於模擬因變數與一個或多個自變數之間的關係。線性迴歸試圖透過擬合一條直線到資料點來最小化平方誤差之和。可以使用統計度量(如決定係數(R平方)和係數的p值)來評估模型的顯著性和擬合優度。
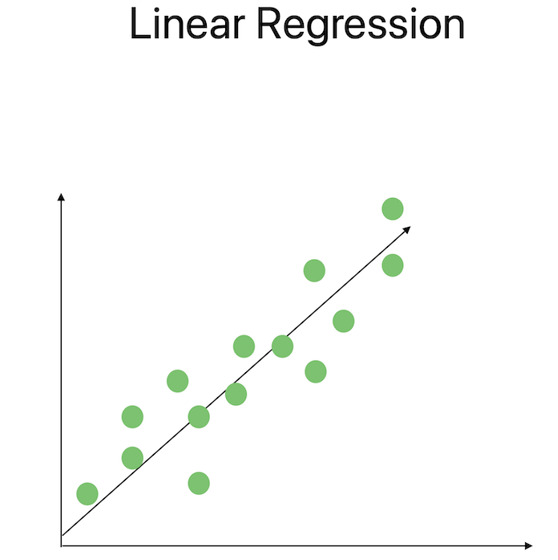
多項式迴歸
當變數之間存在曲線模式時,多項式迴歸很有用。這種方法除了線性項之外,還使用多項式項來捕捉變數之間更復雜的關係。可以使用假設檢驗來評估多項式項的統計顯著性,從而使我們能夠選擇最合適的多項式階數。
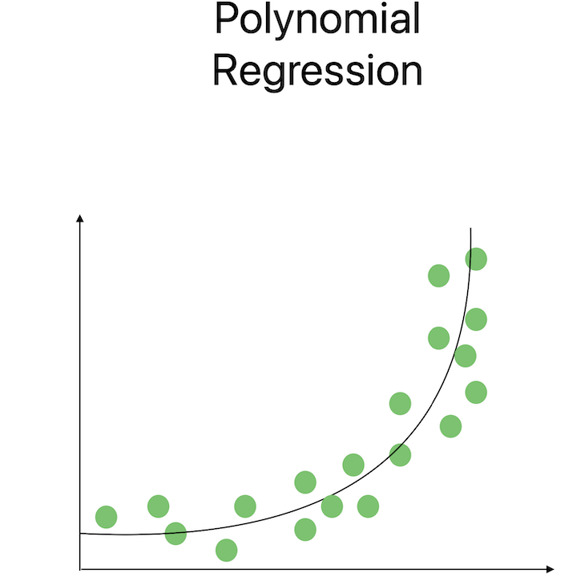
決策樹迴歸
決策樹迴歸透過遞迴地將特徵空間分割成區域為迴歸問題提供非線性解決方案。每個內部節點根據特徵值做出決策,從而產生多個分支。最終的預測值可以透過對與輸入特徵值相對應的區域中的目標值進行平均來獲得。可以使用統計度量(如均方誤差(MSE)和R平方)來評估決策樹迴歸的有效性和可解釋性。
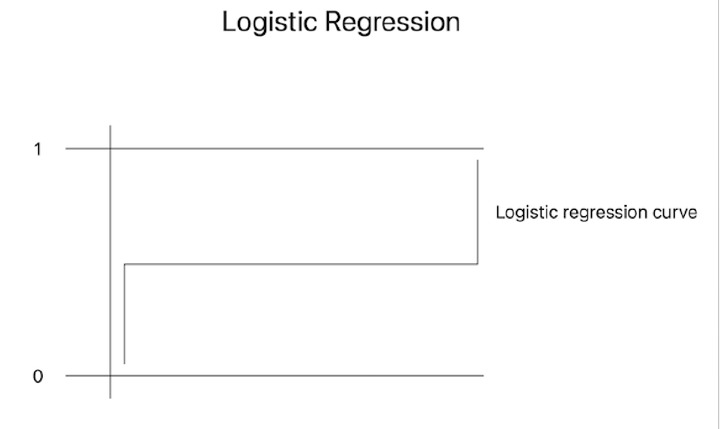
邏輯迴歸
邏輯迴歸是一種通用的方法,用於預測輸入資料與二元或多類目標變數之間的關係。它確定特定例項屬於特定類別的機率。可以使用統計度量(如準確率、精確率、召回率和F1分數)來評估系統的分類效能。
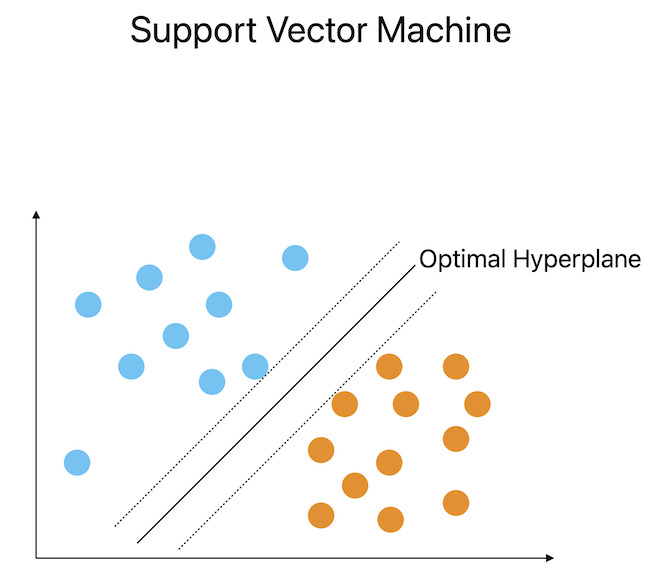
支援向量機
SVM 是一種強大的演算法,它在高維空間中找到最優超平面並將資料分成多個組。SVM 旨在透過最大化類之間的間隔來提供穩健的分類。評估SVM效能的重要統計指標包括準確率、精確率、召回率和F1分數。SVM還可以透過使用核技巧來解決特徵之間的非線性關係。
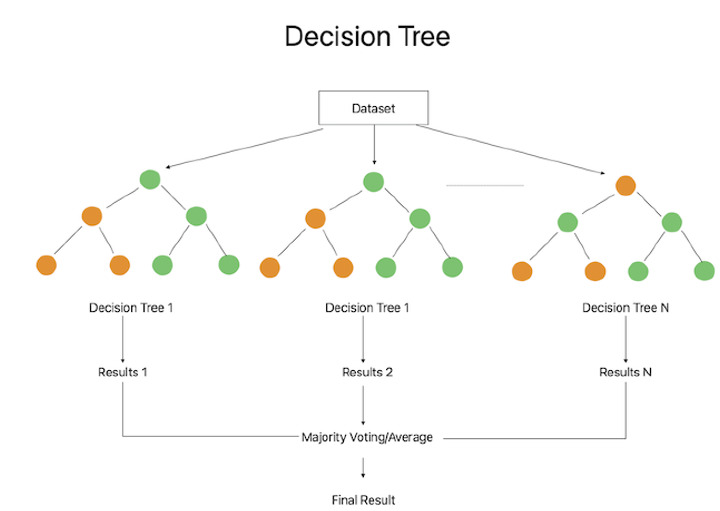
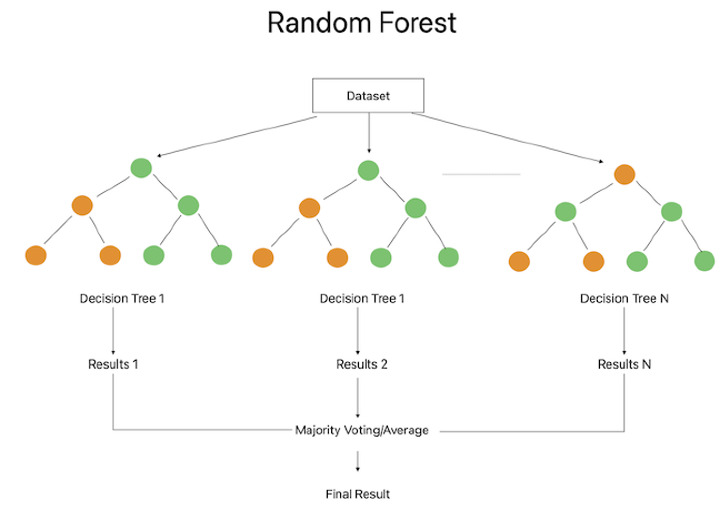
隨機森林
隨機森林整合方法透過組合多個決策樹來獲得預測。每個決策樹都是使用特徵和資料的隨機選取子集建立的。可以使用統計度量(如準確率、精確率、召回率和F1分數)來評估隨機森林分類器的效能。該程式根據基尼指數或資訊增益提供有關特徵重要性的見解。
結論
為特定任務選擇最佳機器學習演算法的過程很大程度上依賴於統計比較。透過進行全面的統計研究,我們可以公正地評估不同演算法的功能和特性。比較統計可以揭示許多引數,包括ROC曲線下面積、F1分數、召回率、準確率和精確率。這些度量使我們能夠評估演算法的預測準確性、對各種資料分佈的適應性以及對噪聲或異常值的魯棒性。我們還可以透過使用諸如交叉驗證之類的統計比較技術來衡量演算法的泛化能力,並確保它在未經測試的資料上也能表現良好。

101 次檢視
