- LightGBM 教程
- LightGBM - 首頁
- LightGBM - 概述
- LightGBM - 架構
- LightGBM - 安裝
- LightGBM - 核心引數
- LightGBM - Boosting 演算法
- LightGBM - 樹生長策略
- LightGBM - 資料集結構
- LightGBM - 二分類
- LightGBM - 迴歸
- LightGBM - 排序
- LightGBM - Python 實現
- LightGBM - 引數調優
- LightGBM - 繪圖功能
- LightGBM - 早停訓練
- LightGBM - 特徵互動約束
- LightGBM 與其他 Boosting 演算法對比
- LightGBM 有用資源
- LightGBM - 有用資源
- LightGBM - 討論
LightGBM - 引數調優
最佳化 LightGBM 的引數對於提升模型效能至關重要,無論是在速度還是準確性方面。本章詳細介紹如何調整 LightGBM 最必要的引數。
什麼是引數調優?
引數調優是指調整機器學習模型的超引數或引數以最大化效能的過程。在 LightGBM 等模型中,控制模型學習過程的超引數包括葉子節點數量、學習率和樹的深度。
引數調優的必要性在於:
提高準確率 - 在新的、未測試的資料上,經過微調的模型會生成更準確的預測。
防止過擬合/欠擬合 - 它確保模型既不太複雜也不太簡單。
最佳化速度 - 透過使用更少的記憶體或處理器功率,調優可以減少訓練時間而不會影響效能。
因此,讓我們看看如何調整 LightGBM 模型的引數:
1. 控制模型複雜度
這些方法用於調節模型複雜度,透過調整諸如 num_leaves 和 max_depth 等引數來平衡欠擬合和過擬合。調整這些引數有助於我們管理 LightGBM 模型的複雜度。
num_leaves - 用於控制每棵決策樹中葉子節點的數量。更多的葉子節點會增加模型複雜度,但太多可能會導致過擬合。將 num_leaves 設定為小於或等於 2(max_depth)。例如,如果 max_depth = 6,則將 num_leaves 設定為 <= 64。
min_data_in_leaf - 顯示葉子節點可以包含的最小樣本數或資料點數。透過更改此引數,您可以幫助模型減少資料中的噪聲。如果深度太低,樹可能會生長得太深並導致過擬合。對於大型資料集,數百或數千範圍內的值是不錯的選擇。
max_depth - 用於限制樹的深度。這可以透過限制樹可以生長的深度來幫助防止過擬合。因此,結合 num_leaves 使用來控制樹的複雜度。
2. 加速模型
可以透過使用諸如 bagging、特徵子取樣和 max_bin 減少等方法來提高訓練速度,而不會影響準確性。
Bagging - 在每個迴圈中使用資料的一個子集來加速訓練。透過設定引數。變數 bagging_fraction 給出每次迭代中要使用的資料的百分比。bagging_freq 返回每次頻率的 bagging 迭代次數。兩個合適的設定是 bagging_fraction = 0.8 和 bagging_freq = 5,以加速模型而不會顯著影響準確性。
特徵子取樣 - 在每次迭代中隨機選擇特徵的一個子集進行訓練。使用諸如 feature_fraction 等引數。此引數控制用於訓練的特徵的分數。最佳實踐是將 feature_fraction 設定為 0.8 以減少訓練時間。
max_bin - 此引數控制用於連續特徵的 bin 的數量。因此,最佳實踐是減少 max_bin 以加快模型速度並減少記憶體消耗,但可能會影響準確性。
save_binary - 儲存二進位制資料以允許在後續執行中更快地載入。因此,建議在對相同資料集重複執行模型時使用 save_binary=True。
3. 提高準確率
使用更大的資料集、更低的學習率和 Dart 等高階技術可以提高模型的準確性,但可能會以更長的訓練時間為代價。
learning_rate 和 num_iterations - 引數 learning_rate 和 num_iterations 控制模型在每次迭代中進行修改的步數和數量。使用較小的學習率(如 0.01)和較大的 num_iterations(如 1000+)是最佳選擇。
num_leaves - 增加 num_leaves 使模型更復雜。這可能會提高準確性,但如果使用不當,也可能導致過擬合。因此,最佳實踐是在您有足夠資料的情況下增加 num_leaves,但請確保將其與正則化技術結合使用以避免過擬合。
使用更大的資料 - 更多的資料通常會導致更高的準確性,因為模型可以獲取更大範圍的模式。因此,最佳實踐是,如果過擬合是一個問題,請儘可能多地使用資料以提高模型的泛化能力。
Dart(Dropouts meet Multiple Additive Regression Trees) - 這種特殊的梯度提升技術透過在訓練期間隨機刪除樹來提高模型的準確性。因此,最佳實踐是對於您看到過擬合的問題或您正在尋找額外準確性的問題,使用 boosting_type='dart'。
使用類別特徵 - 透過消除將類別特徵轉換為虛擬變數的需要,LightGBM 可以直接處理它們,從而可能提高效能。因此,最好透過使用 categorical_feature 選項來識別哪些屬性是類別屬性來提高模型準確性。
4. 處理過擬合
本節介紹如何使用子取樣技術、樹深度限制和正則化來防止模型過度擬合訓練集。
max_bin - 使用較小的 max_bin 可以減少過擬合,因為它限制了特徵分箱中的細節量。
num_leaves - 減少模型中的葉子節點數量,以防止過度擬合訓練集並防止模型變得過於複雜。
min_data_in_leaf 和 min_sum_hessian_in_leaf - 這些設定透過確保每個葉子節點包含最小二階導數之和(min_sum_hessian_in_leaf)和最小資料點數(min_data_in_leaf)來幫助防止樹變得過深。增加 min_data_in_leaf 和 min_sum_hessian_in_leaf 以避免過擬合,尤其是在小型資料集上。
Bagging 和特徵子取樣 - 使用特徵子取樣(feature_fraction)和 bagging(bagging_fraction 和 bagging_freq)來增加模型中的不確定性並減少過擬合。
正則化 - 定義諸如 lambda_l1(L1 正則化,通常稱為 Lasso)等引數以降低模型的複雜度。lambda_l2 用於透過基於嶺的 L2 正則化來減少過擬合。變數 min_gain_to_split 指示拆分樹節點所需的最小增益。嘗試增加 lambda_l1 和 lambda_l2 以向模型新增正則化,並調整 min_gain_to_split 以控制模型建立新分支的難易程度。
max_depth - 設定合理的 max_depth 以限制樹的深度並避免過擬合,尤其是在較小的資料集上。
Python 中的引數調優示例
以下是在 Python 中執行 LightGBM 引數調優的小示例:
# Import necessary libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, RandomizedSearchCV
import lightgbm as lgb
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
sns.set(style="whitegrid", color_codes=True, font_scale=1.3)
import warnings
warnings.filterwarnings('ignore')
# Load dataset
data = pd.read_csv('/Python/breast_cancer_data.csv')
data.head()
# 1. Preprocessing
# Drop unnecessary columns
data = data.drop(columns=['id', 'Unnamed: 32'])
# Convert 'diagnosis' column to numerical (0: Benign, 1: Malignant)
data['diagnosis'] = data['diagnosis'].map({'B': 0, 'M': 1})
# Split the data into features (X) and target (y)
X = data.drop(columns=['diagnosis'])
y = data['diagnosis']
# Clean column names to avoid LightGBM error
X.columns = X.columns.str.replace('[^A-Za-z0-9_]+', '', regex=True)
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 2. Define parameter grid for tuning
param_grid = {
'learning_rate': [0.01, 0.05, 0.1],
'num_leaves': [20, 31, 40],
'max_depth': [-1, 10, 20],
'feature_fraction': [0.6, 0.8, 1.0],
'bagging_fraction': [0.6, 0.8, 1.0],
'bagging_freq': [0, 5, 10],
'lambda_l1': [0, 1, 5],
'lambda_l2': [0, 1, 5]
}
# 3. Set up the LightGBM model
lgb_estimator = lgb.LGBMClassifier(objective='binary', metric='binary_logloss')
# 4. Perform Randomized Search for parameter tuning
random_search = RandomizedSearchCV(estimator=lgb_estimator, param_distributions=param_grid,
n_iter=50, scoring='accuracy', cv=5, verbose=1, random_state=42)
# 5. Fit the model
random_search.fit(X_train, y_train)
# 6. Get the best parameters
print("Best Parameters:", random_search.best_params_)
# 7. Predict and evaluate the model
y_pred = random_search.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
# Confusion Matrix
conf_matrix = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(conf_matrix)
# Classification report
print("Classification Report:")
print(classification_report(y_test, y_pred))
# Optional: Plot Confusion Matrix for visualization
plt.figure(figsize=(8,6))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=['Benign', 'Malignant'], yticklabels=['Benign', 'Malignant'])
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()
輸出
以下是上述 LightGBM 模型引數調優的輸出:
Accuracy: 97.37%
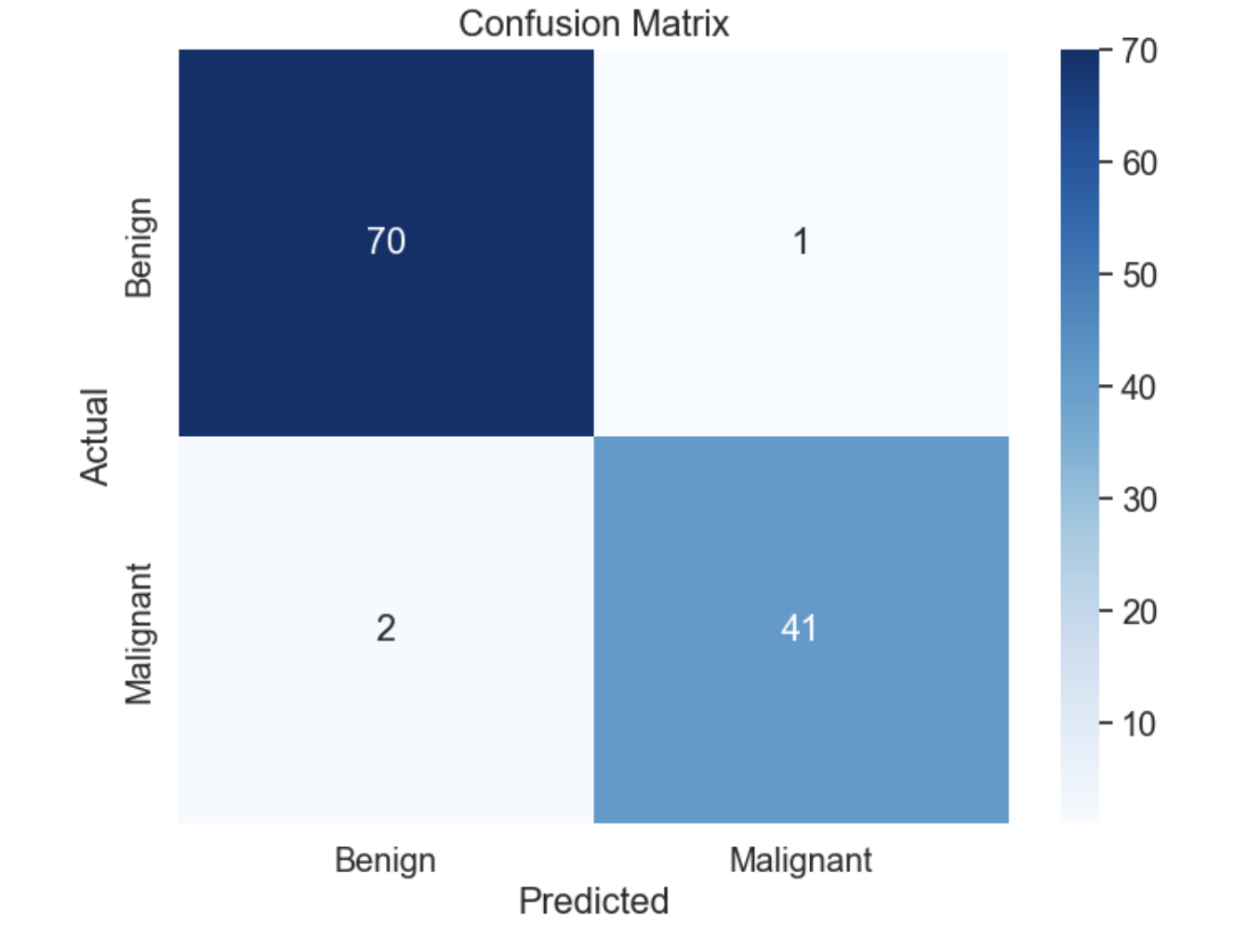
Confusion Matrix:
[[70 1]
[ 2 41]]
Classification Report:
precision recall f1-score support
0 0.97 0.99 0.98 71
1 0.98 0.95 0.96 43
accuracy 0.97 114
macro avg 0.97 0.97 0.97 114
weighted avg 0.97 0.97 0.97 114
混淆矩陣如下:
總結
需要調整 LightGBM 引數以最大化模型效能和訓練速度。在速度、精度、複雜度和防止過擬合之間找到平衡是關鍵。透過仔細調整諸如 num_leaves、min_data_in_leaf、bagging_fraction 和 max_depth 等引數,您可以構建一個在訓練資料和未見資料上都表現良好的模型。在此,L1 和 L2 正則化過程可以幫助進一步防止過擬合併增強模型的泛化能力。