- LightGBM 教程
- LightGBM - 首頁
- LightGBM - 概述
- LightGBM - 架構
- LightGBM - 安裝
- LightGBM - 核心引數
- LightGBM - Boosting 演算法
- LightGBM - 樹生長策略
- LightGBM - 資料集結構
- LightGBM - 二分類
- LightGBM - 迴歸
- LightGBM - 排序
- LightGBM - Python 實現
- LightGBM - 引數調優
- LightGBM - 繪圖功能
- LightGBM - 早停訓練
- LightGBM - 特徵互動約束
- LightGBM 與其他 Boosting 演算法比較
- LightGBM 有用資源
- LightGBM - 有用資源
- LightGBM - 討論
LightGBM - 二分類
什麼是二分類?
二分類是一種機器學習問題,其目標是將資料分類到兩個組或類別之一。使用二分類,模型預測兩個可能結果之一。例如 - 垃圾郵件過濾器可以識別電子郵件為“垃圾郵件”或“非垃圾郵件”。
使用兩個類別中的一種標記資料來訓練模型。透過識別資料中的模式,模型區分這兩個組。模型推斷出新、未知資料的類別。
二分類的評估指標
分析二分類時使用以下指標:
準確率:定義為所有預測中正確預測的百分比。
精確率:精確率是指所有陽性預測中真正屬於陽性預測的比例。
召回率:召回率(靈敏度)是指所有真實陽性中真正陽性預測的比例。
F1 分數:F1 分數是召回率和精確率的調和平均數。
受試者工作特徵 - 曲線下面積:ROC-AUC 衡量模型區分兩個類別的能力。
二分類的例子
以下是一些二分類任務的示例:
郵件過濾:郵件過濾是指將郵件分類為“垃圾郵件”或“非垃圾郵件”。
疾病診斷:疾病診斷是指檢查患者是否患有某種疾病,結果為陽性或陰性。
情感分析:情感分析是指將客戶評論分類為“正面”或“負面”。
二分類的實現
以下是使用 LightGBM 建立基本二分類需要遵循的步驟:
步驟 1:匯入庫
Python 庫允許我們處理資料,並使用一行程式碼執行基本和複雜的任務。使用以下庫,這些庫是資料操作、機器學習和評估所必需的。
import pandas as pd import numpy as np import lightgbm as lgb from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
步驟 2:建立虛擬資料集
建立一個包含 100 行和四列(feature1、feature2、feature3 和 target)的資料框。其中 feature1 和 feature2 是連續變數,feature3 是具有整數值的分類變數。target 是一個二元目標變數。
#Set seed for reproducibility
np.random.seed(42)
#Create a DataFrame with random data
data = pd.DataFrame({
'feature1': np.random.rand(100), #100 random numbers between 0 and 1
'feature2': np.random.rand(100), #100 random numbers between 0 and 1
'feature3': np.random.randint(0, 10, size=100), #100 random integers between 0 and 9
'target': np.random.randint(0, 2, size=100) #Binary target variable (0 or 1)
})
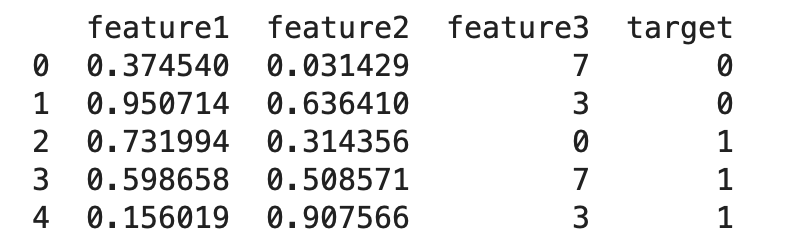
print(data.head())
上述程式碼的結果為:
步驟 3:分割資料
將資料集分成訓練集和測試集。在本例中,30% 的資料將用於測試,70% 用於訓練。
#Split the data into training and testing sets
X = data.drop('target', axis=1) #Features
y = data['target'] #Target variable
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
步驟 4:建立 LightGBM 資料集
將訓練和測試資料轉換為 LightGBM 特定的格式。train_data 用於訓練,test_data 用於評估。
#Create a LightGBM dataset train_data = lgb.Dataset(X_train, label=y_train) test_data = lgb.Dataset(X_test, label=y_test, reference=train_data)
步驟 5:設定 LightGBM 引數
定義 LightGBM 模型的目標函式、度量標準和其他超引數。
#Set LightGBM parameters
params = {
'objective': 'binary', #Binary classification task
'metric': 'binary_error', #Evaluation metric
'boosting_type': 'gbdt', #Gradient Boosting Decision Tree
'num_leaves': 31, #Number of leaves in one tree
'learning_rate': 0.05, #Step size for each iteration
'feature_fraction': 0.9 #Fraction of features used for each iteration
}
步驟 6:訓練模型
使用給定的引數訓練 LightGBM 模型。早停用於在 10 輪內沒有觀察到改進時停止訓練。
#Train the model with early stopping bst = lgb.train(params, train_data, valid_sets=[test_data], early_stopping_rounds=10)
步驟 7:預測和評估
對測試集做出一些假設,將預測機率轉換為二進位制值,然後評估模型的準確性。
#Predict and evaluate the model
y_pred = bst.predict(X_test, num_iteration=bst.best_iteration) #Predict probabilities
y_pred_binary = [1 if x > 0.5 else 0 for x in y_pred] #Convert probabilities to binary predictions
accuracy = accuracy_score(y_test, y_pred_binary) #Calculate accuracy
print(f"Accuracy: {accuracy:.2f}")
這將產生以下結果
Accuracy: 0.50
準確率得分將顯示 LightGBM 模型在測試集上的效能。由於資料集是隨機建立的,因此準確率可能不高;預計它接近 0.5。
總結
LightGBM 是一種解決二分類問題的有效方法。它對於具有高維特徵的大型資料集非常有用。它整合的處理分類特徵的方法最大程度地減少了預處理工作量。