- ggplot2 教程
- ggplot2 - 首頁
- ggplot2 - 簡介
- ggplot2 - R 的安裝
- ggplot2 - R 中的預設繪圖
- ggplot2 - 使用座標軸
- ggplot2 - 使用圖例
- ggplot2 - 散點圖和抖動圖
- ggplot2 - 條形圖和直方圖
- ggplot2 - 餅圖
- ggplot2 - 邊緣圖
- ggplot2 - 氣泡圖和計數圖
- ggplot2 - 發散圖
- ggplot2 - 主題
- ggplot2 - 多面板圖
- ggplot2 - 多個圖形
- ggplot2 - 背景顏色
- ggplot2 - 時間序列
- ggplot2 有用資源
- ggplot2 - 快速指南
- ggplot2 - 有用資源
- ggplot2 - 討論
ggplot2 - 快速指南
ggplot2 - 簡介
ggplot2 是一個 R 包,專門用於資料視覺化和提供最佳的探索性資料分析。它提供了美觀、無憂的圖形,並處理繪製圖例和表示圖例等細節。圖形可以迭代建立並在以後編輯。此包設計為分層工作,首先顯示在使用 R 進行探索性資料分析期間收集的原始資料,然後添加註釋和統計摘要層。
即使是最有經驗的 R 使用者也需要幫助才能建立優雅的圖形。這個庫是用於在 R 中建立圖形的絕佳工具,但即使經過多年近乎每天的使用,我們仍然需要參考我們的備忘單。
此包在稱為“圖形語法”的深層語法下工作,該語法由一組可以以多種方式建立的獨立元件組成。“圖形語法”是 ggplot2 非常強大的唯一原因,因為 R 開發人員不限於其他包中使用的預先指定圖形集。語法包括一組簡單的核心規則和原則。
2005 年,Wilkinson 建立或起源了圖形語法的概念,以描述所有統計圖形之間包含的深層特徵。它側重於層的首要性,包括適應嵌入 R 的功能。
“圖形語法”與 R 之間的關係
它告訴使用者或開發人員,統計圖形用於將資料對映到美學屬性,例如顏色、形狀、相關幾何物件(如點、線和條)的大小。該圖可能還包含相關資料的各種統計轉換,這些轉換繪製在提到的座標系上。它還包括一個稱為“分面”的功能,通常用於為提到的資料集的不同子集建立相同的圖形。R 包括各種內建資料集。這些獨立元件的組合完全構成一個特定的圖形。
現在讓我們關注可以使用語法建立的不同型別的圖形 -
資料
如果使用者希望視覺化給定的美學對映集,該對映集描述了資料中所需變數如何對映在一起以建立對映的美學屬性。
圖層
它由幾何元素和所需的統計轉換組成。圖層包括幾何物件,簡稱 geom,用於實際表示使用點、線、多邊形等幫助繪製圖形的資料。最好的演示是將觀察結果進行分箱和計數以建立特定的直方圖,以總結特定線性模型的二維關係。
刻度
刻度用於對映資料空間中的值,這些值用於建立值,無論是顏色、大小還是形狀。它有助於繪製圖例或座標軸,這些座標軸需要提供反向對映,從而可以從提到的圖形中讀取原始資料值。
座標系
它描述瞭如何將資料座標對映到圖形的提到的平面。它還提供了座標軸和網格線的資訊,這些資訊是讀取圖形所必需的。通常它用作笛卡爾座標系,包括極座標和地圖投影。
分面
它包括有關如何將資料分解成所需子集並將子集顯示為資料倍數的規範。這也被稱為條件化或格子化過程。
主題
它控制顯示的更細微之處,例如字型大小和背景顏色屬性。為了建立一個吸引人的圖形,最好考慮參考。
現在,討論語法不提供的限制或功能也同樣重要 -
它缺乏關於應該使用哪些圖形或使用者感興趣的圖形的建議。
它沒有描述互動性,因為它只包含靜態圖形的描述。要建立動態圖形,應應用其他替代解決方案。
使用 ggplot2 建立的簡單圖形如下所示 -
ggplot2 - R 的安裝
R 包具有各種功能,例如分析統計資訊或深入研究地理空間資料,或者我們可以建立基本報告。
R 的包可以定義為以良好定義的格式儲存的 R 函式、資料和編譯程式碼。儲存包的資料夾或目錄稱為庫。
如上圖所示,libPaths() 是顯示庫位置的函式,函式 library 顯示庫中儲存的包。
R 包含許多用於操作包的函式。我們將重點關注三個主要函式,它們是 -
- 安裝包
- 載入包
- 瞭解包
在 R 中安裝包的函式語法為 -
Install.packages(“<package-name>”)
下面是安裝包的簡單演示。假設我們需要安裝資料視覺化庫“ggplot2”包,則使用以下語法 -
Install.packages(“ggplot2”)

要載入特定的包,我們需要遵循下面提到的語法 -
Library(<package-name>)
以下顯示了 ggplot2 的相同用法 -
library(“ggplot2”)
輸出顯示在下面的快照中 -

為了理解所需包和基本功能的需求,R 提供了幫助函式,該函式提供了已安裝包的完整詳細資訊。
完整的語法如下所示 -
help(ggplot2)

ggplot2 - R 中的預設繪圖
在本章中,我們將重點介紹如何使用 ggplot2 建立一個簡單的圖形。我們將使用以下步驟在 R 中建立預設圖形。
在工作區中包含庫和資料集
在 R 中包含庫。載入所需的包。現在我們將重點介紹 ggplot2 包。
# Load ggplot2 library(ggplot2)
我們將實現名為“Iris”的資料集。該資料集包含 3 個類別,每個類別 50 個例項,其中每個類別都指一種鳶尾花植物。一個類別與其他兩個類別線性可分;後者彼此之間不線性可分。
# Read in dataset data(iris)
下面列出了資料集中包含的屬性 -
使用屬性進行樣本繪圖
以更簡單的方式使用 ggplot2 繪製鳶尾花資料集圖形涉及以下語法 -
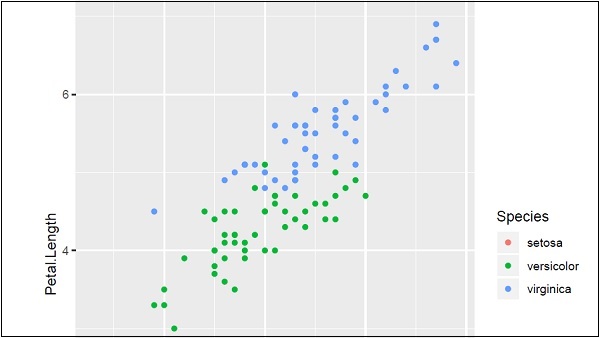
# Plot IrisPlot <- ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + geom_point() print(IrisPlot)
第一個引數將資料集作為輸入,第二個引數提到需要在資料庫中繪製的圖例和屬性。在本例中,我們使用圖例 Species。Geom_point() 表示散點圖,這將在後面的章節中詳細討論。
生成的輸出如下所示 -
在這裡,我們可以修改標題、x 標籤和 y 標籤,這意味著以系統格式修改 x 軸和 y 軸標籤,如下所示 -
print(IrisPlot + labs(y="Petal length (cm)", x = "Sepal length (cm)")
+ ggtitle("Petal and sepal length of iris"))

ggplot2 - 使用座標軸
當我們談論圖形中的座標軸時,它完全是關於以二維方式表示的 x 軸和 y 軸。在本章中,我們將重點關注兩個資料集“Plantgrowth”和“Iris”資料集,這兩個資料集通常由資料科學家使用。
在 Iris 資料集中實現座標軸
我們將使用以下步驟使用 R 的 ggplot2 包處理 x 和 y 座標軸。
載入庫以獲取包的功能始終很重要。
# Load ggplot library(ggplot2) # Read in dataset data(iris)
建立繪圖點
如前一章所述,我們將建立一個包含點的圖形。換句話說,它被定義為散點圖。
# Plot p <- ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + geom_point() p
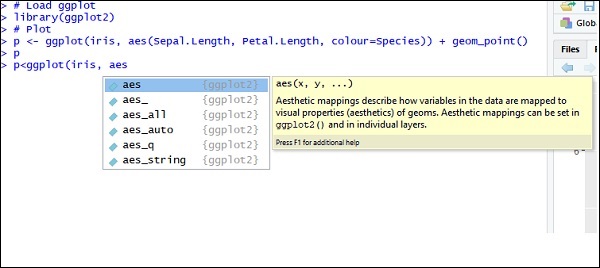
現在讓我們瞭解 aes 的功能,它提到了“ggplot2”的對映結構。美學對映描述了繪圖所需的變數結構以及應以單個圖層格式管理的資料。
輸出如下所示 -

突出顯示和刻度標記
使用提到的 x 和 y 座標軸的座標繪製標記,如下所示。它包括新增文字、重複文字、突出顯示特定區域和新增線段,如下所示 -
# add text
p + annotate("text", x = 6, y = 5, label = "text")
# add repeat
p + annotate("text", x = 4:6, y = 5:7, label = "text")
# highlight an area
p + annotate("rect", xmin = 5, xmax = 7, ymin = 4, ymax = 6, alpha = .5)
# segment
p + annotate("segment", x = 5, xend = 7, y = 4, yend = 5, colour = "black")
新增文字生成的輸出如下所示 -

使用提到的座標重複特定文字會生成以下輸出。文字使用 x 座標從 4 到 6 和 y 座標從 5 到 7 生成 -
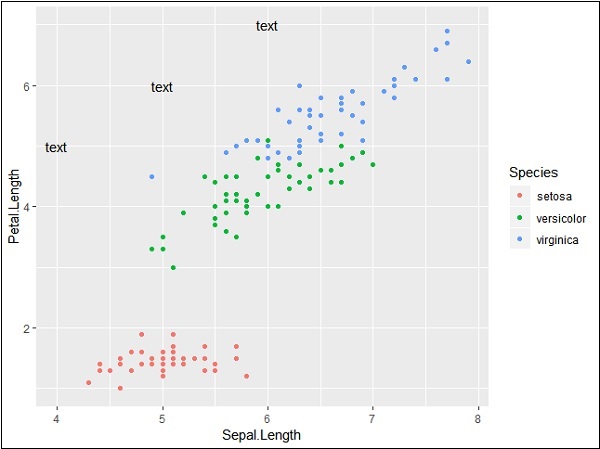
分段和突出顯示特定區域的輸出如下所示 -

PlantGrowth 資料集
現在讓我們專注於使用另一個名為“Plantgrowth”的資料集,以及所需的步驟如下所示。
呼叫庫並檢查“Plantgrowth”的屬性。此資料集包含來自一項實驗的結果,該實驗比較了在對照和兩種不同處理條件下獲得的產量(以植物乾重衡量)。
> PlantGrowth weight group 1 4.17 ctrl 2 5.58 ctrl 3 5.18 ctrl 4 6.11 ctrl 5 4.50 ctrl 6 4.61 ctrl 7 5.17 ctrl 8 4.53 ctrl 9 5.33 ctrl 10 5.14 ctrl 11 4.81 trt1 12 4.17 trt1 13 4.41 trt1 14 3.59 trt1 15 5.87 trt1 16 3.83 trt1 17 6.03 trt1
新增具有座標軸的屬性
嘗試使用圖形所需的 x 和 y 座標軸繪製一個簡單的圖形,如下所示 -
> bp <- ggplot(PlantGrowth, aes(x=group, y=weight)) + + geom_point() > bp
生成的輸出如下所示 -

最後,我們可以根據需要使用基本函式交換 x 和 y 座標軸,如下所示 -
> bp <- ggplot(PlantGrowth, aes(x=group, y=weight)) + + geom_point() > bp

基本上,我們可以使用許多屬性與美學對映一起使用,以使用 ggplot2 處理座標軸。
ggplot2 - 使用圖例
座標軸和圖例統稱為指南。它們允許我們從圖形中讀取觀察結果,並根據原始值將它們映射回。圖例鍵和刻度標籤均由刻度斷點確定。圖例和座標軸是根據所需的刻度和 geom 自動生成的,這些刻度和 geom 是圖形所必需的。
將實施以下步驟以瞭解 ggplot2 中圖例的工作原理 -
在工作區中包含包和資料集
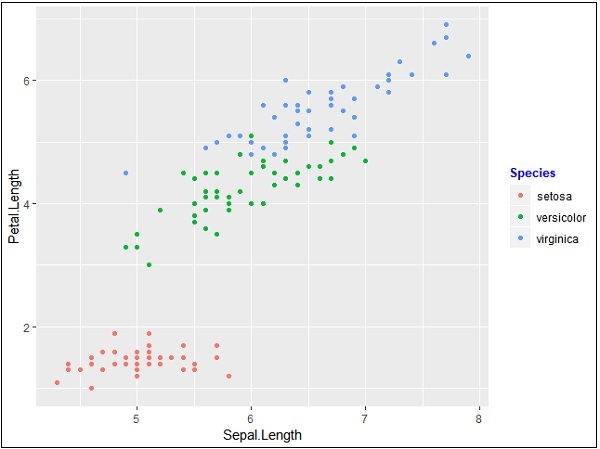
讓我們建立相同的圖形以專注於使用 ggplot2 生成的圖形的圖例 -
> # Load ggplot > library(ggplot2) > > # Read in dataset > data(iris) > > # Plot > p <- ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + geom_point() > p
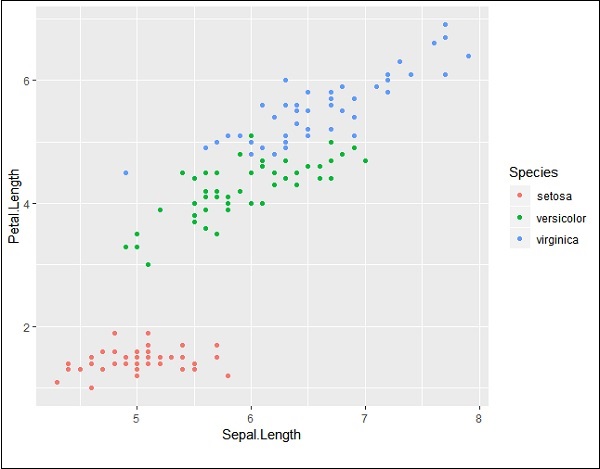
如果觀察圖形,則圖例會建立在最左角,如下所示 -
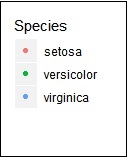
這裡,圖例包括給定資料集的各種型別的物種。
更改圖例的屬性
我們可以使用“legend.position”屬性刪除圖例,然後得到相應的輸出 -
> # Remove Legend > p + theme(legend.position="none")

我們還可以使用屬性“element_blank()”隱藏圖例的標題,如下所示:
> # Hide the legend title > p + theme(legend.title=element_blank())

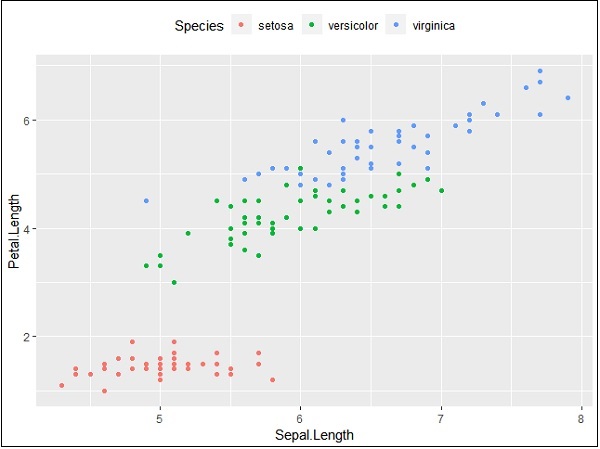
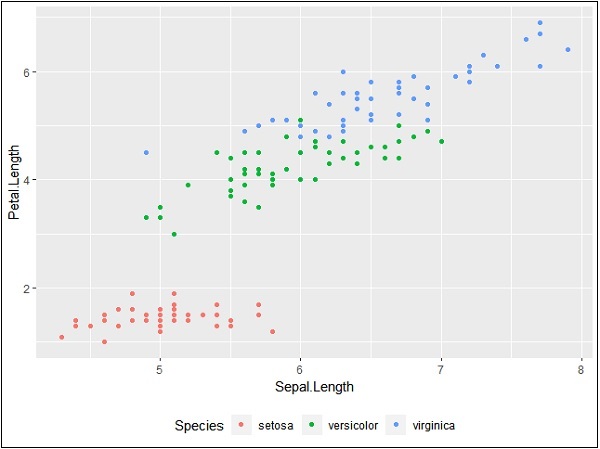
我們也可以根據需要使用圖例位置。此屬性用於生成準確的繪圖表示。
> #Change the legend position > p + theme(legend.position="top") > > p + theme(legend.position="bottom")
頂部表示
底部表示
更改圖例的字型樣式
我們可以更改圖例標題和其他屬性的字型樣式和字型型別,如下所示:
> #Change the legend title and text font styles > # legend title > p + theme(legend.title = element_text(colour = "blue", size = 10, + face = "bold")) > # legend labels > p + theme(legend.text = element_text(colour = "red", size = 8, + face = "bold"))
生成的輸出如下所示 -

接下來的章節將重點介紹各種型別的圖形,以及各種背景屬性(如顏色、主題)以及它們從資料科學角度的重要性。
ggplot2 - 散點圖和抖動圖
散點圖類似於通常用於繪圖的折線圖。散點圖顯示了一個變數與另一個變數的相關程度。變數之間的關係稱為相關性,通常用於統計方法。我們將使用相同的資料集“Iris”,其中包含每個變數之間的許多變化。這是一個著名的資料集,它給出了三種鳶尾屬植物中每種 50 朵花的萼片長度和寬度以及花瓣長度和寬度的釐米測量值。這些物種稱為山鳶尾、變色鳶尾和弗吉尼亞鳶尾。
建立基本散點圖
建立使用“ggplot2”包的散點圖涉及以下步驟:
要建立基本散點圖,執行以下命令:
> # Basic Scatter Plot > ggplot(iris, aes(Sepal.Length, Petal.Length)) + + geom_point()

新增屬性
我們可以使用 geom_point() 函式中的 shape 屬性更改點的形狀。
> # Change the shape of points > ggplot(iris, aes(Sepal.Length, Petal.Length)) + + geom_point(shape=1)
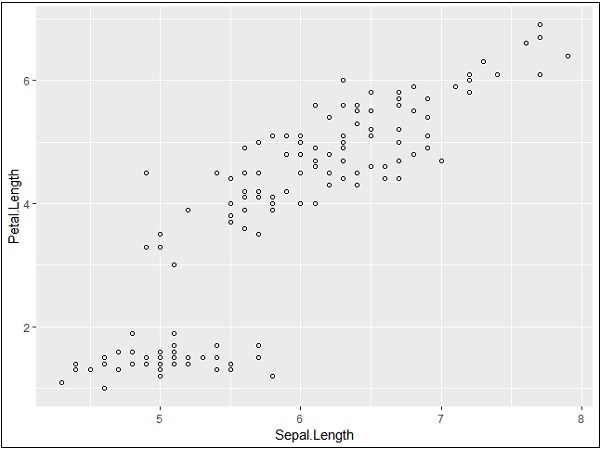
我們可以為點新增顏色,這會新增到所需的散點圖中。
> ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + + geom_point(shape=1)
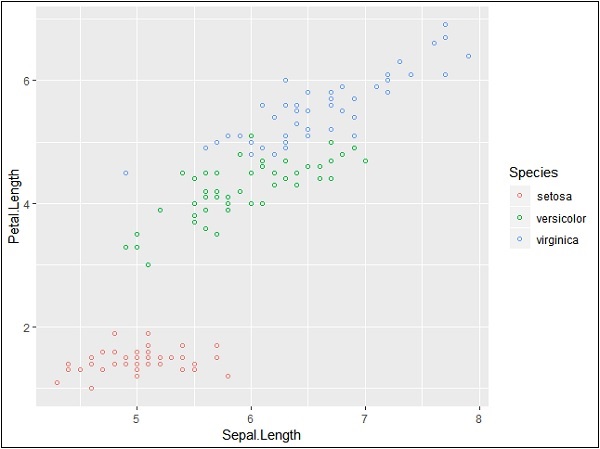
在這個例子中,我們根據圖例中提到的物種建立了顏色。這三種物種在提到的圖中得到了獨特的區分。
現在我們將重點放在建立變數之間的關係上。
> ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + + geom_point(shape=1) + + geom_smooth(method=lm)
geom_smooth 函式有助於重疊模式的建立以及所需變數模式的建立。
屬性方法“lm”提到了需要開發的迴歸線。
> # Add a regression line > ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + + geom_point(shape=1) + + geom_smooth(method=lm)

我們還可以使用下面提到的語法新增沒有陰影置信區域的迴歸線:
># Add a regression line but no shaded confidence region > ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + + geom_point(shape=1) + + geom_smooth(method=lm, se=FALSE)

陰影區域表示置信區域以外的事物。
抖動圖
抖動圖包含特殊效果,可以使用這些效果來描繪散點圖。抖動只不過是分配給點的隨機值,以將它們分開,如下所示:
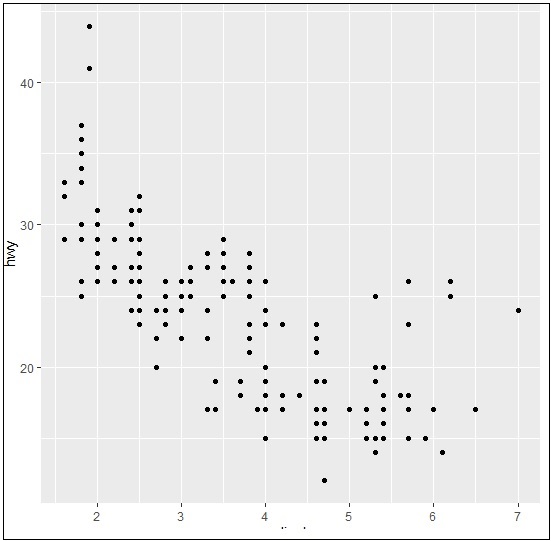
> ggplot(mpg, aes(cyl, hwy)) + + geom_point() + + geom_jitter(aes(colour = class))

ggplot2 - 條形圖和直方圖
條形圖以矩形方式表示分類資料。條形圖可以垂直和水平繪製。高度或長度與圖形中表示的值成正比。條形圖的 x 軸和 y 軸指定特定資料集中包含的類別。
直方圖是一種條形圖,它用清晰的分佈圖表示原始資料。
在本章中,我們將重點介紹如何在 ggplot2 的幫助下建立條形圖和直方圖。
瞭解 MPG 資料集
讓我們瞭解將要使用的資料集。Mpg 資料集包含 EPA 在以下連結中提供的燃油經濟性資料的一個子集:
它包含了 1999 年至 2008 年每年都有新版本釋出的車型。這被用作汽車受歡迎程度的代理。
執行以下命令以瞭解資料集所需的屬性列表。
> library(ggplot2)
附加的包是 ggplot2。
以下物件被 .GlobalEnv 掩蓋:
mpg
警告訊息
- 包 arules 是在 R 版本 3.5.1 下構建的
- 包 tuneR 是在 R 版本 3.5.3 下構建的
- 包 ggplot2 是在 R 版本 3.5.3 下構建的
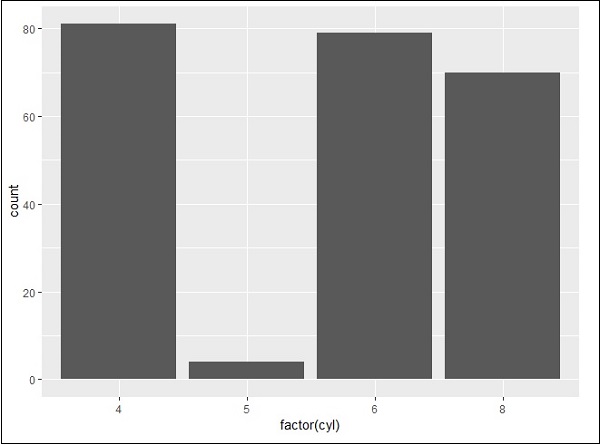
建立條形計數圖
可以使用以下圖建立條形計數圖:
> # A bar count plot > p <- ggplot(mpg, aes(x=factor(cyl)))+ + geom_bar(stat="count") > p

geom_bar() 是用於建立條形圖的函式。它採用稱為 count 的統計值的屬性。
直方圖
可以使用以下圖建立直方圖計數圖:
> # A historgram count plot > ggplot(data=mpg, aes(x=hwy)) + + geom_histogram( col="red", + fill="green", + alpha = .2, + binwidth = 5)
geom_histogram() 包含建立直方圖所需的所有屬性。在這裡,它採用 hwy 屬性及其相應的計數。顏色根據需要選擇。
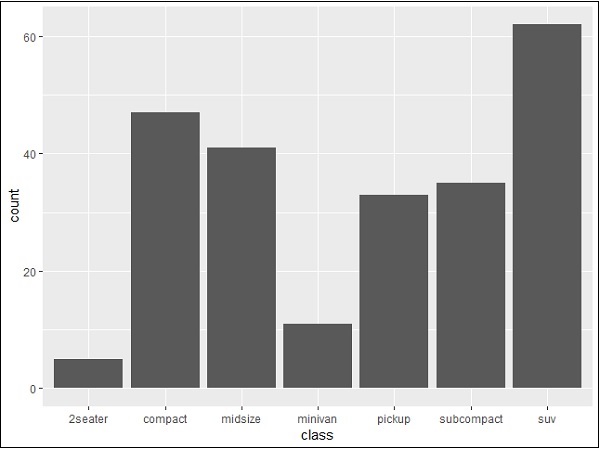
堆疊條形圖
條形圖和直方圖的一般圖可以如下建立:
> p <- ggplot(mpg, aes(class)) > p + geom_bar() > p + geom_bar()
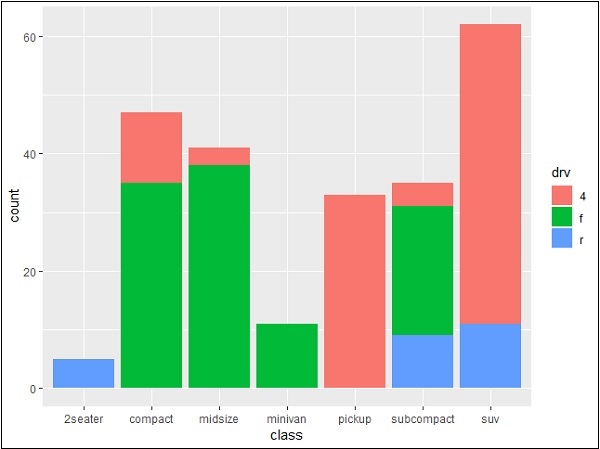
此圖包含條形圖中定義的所有類別及其相應的類。此圖稱為堆疊圖。
ggplot2 - 餅圖
餅圖被認為是一種圓形統計圖,它被分成多個扇形以說明數值比例。在提到的餅圖中,每個扇形的弧長與其表示的數量成正比。弧長表示餅圖的角度。餅圖的總度數為 360 度。半圓或半餅圖包含 180 度。
建立餅圖
將包載入到提到的工作區中,如下所示:
> # Load modules
> library(ggplot2)
>
> # Source: Frequency table
> df <- as.data.frame(table(mpg$class))
> colnames(df) <- c("class", "freq")

可以使用以下命令建立示例圖表:
> pie <- ggplot(df, aes(x = "", y=freq, fill = factor(class))) + + geom_bar(width = 1, stat = "identity") + + theme(axis.line = element_blank(), + plot.title = element_text(hjust=0.5)) + + labs(fill="class", + x=NULL, + y=NULL, + title="Pie Chart of class", + caption="Source: mpg") > pie
如果您觀察輸出,則圖表的建立方式不是圓形,如下所示:

建立座標
讓我們執行以下命令以建立所需的餅圖,如下所示:
> pie + coord_polar(theta = "y", start=0)

ggplot2 - 邊緣圖
在本章中,我們將討論邊際圖。
瞭解邊際圖
邊際圖用於評估兩個變數之間的關係並檢查它們的分佈。當我們談論建立邊際圖時,它們只不過是在各自的 x 軸和 y 軸的邊距中具有直方圖、箱線圖或點圖的散點圖。
以下步驟將用於使用 R 和“ggExtra”包建立邊際圖。此包旨在增強“ggplot2”包的功能,幷包含各種用於建立成功邊際圖的函式。
步驟 1
使用以下命令安裝“ggExtra”包以成功執行(如果您的系統中未安裝此包)。
> install.packages("ggExtra")
步驟 2
將所需庫包含在工作區中以建立邊際圖。
> library(ggplot2) > library(ggExtra)
步驟 3
讀取我們在前幾章中使用過的所需資料集“mpg”。
> data(mpg) > head(mpg) # A tibble: 6 x 11 manufacturer model displ year cyl trans drv cty hwy fl class <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr> 1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa~ 2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa~ 3 audi a4 2 2008 4 manual(m6) f 20 31 p compa~ 4 audi a4 2 2008 4 auto(av) f 21 30 p compa~ 5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa~ 6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa~ >
步驟 4
現在讓我們使用“ggplot2”建立一個簡單的圖,這將幫助我們理解邊際圖的概念。
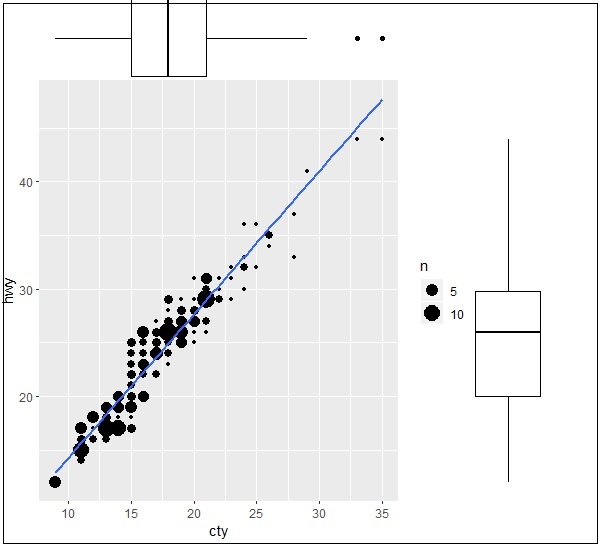
> #Plot > g <- ggplot(mpg, aes(cty, hwy)) + + geom_count() + + geom_smooth(method="lm", se=F) > g

變數之間的關係
現在讓我們使用 ggMarginal 函式建立邊際圖,該函式有助於生成兩個屬性“hwy”和“cty”之間的關係。
> ggMarginal(g, type = "histogram", fill="transparent") > ggMarginal(g, type = "boxplot", fill="transparent")
直方圖邊際圖的輸出如下所示:

箱線圖邊際圖的輸出如下所示:
ggplot2 - 氣泡圖和計數圖
氣泡圖只不過是氣泡圖,它基本上是散點圖,其中第三個數值變數用於圓圈大小。在本章中,我們將重點介紹條形計數圖和直方圖計數圖的建立,它們被認為是氣泡圖的副本。
使用提到的包建立氣泡圖和計數圖涉及以下步驟:
瞭解資料集
載入相應的包和所需資料集以建立氣泡圖和計數圖。
> # Load ggplot > library(ggplot2) > > # Read in dataset > data(mpg) > head(mpg) # A tibble: 6 x 11 manufacturer model displ year cyl trans drv cty hwy fl class <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr> 1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa~ 2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa~ 3 audi a4 2 2008 4 manual(m6) f 20 31 p compa~ 4 audi a4 2 2008 4 auto(av) f 21 30 p compa~ 5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa~ 6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa~
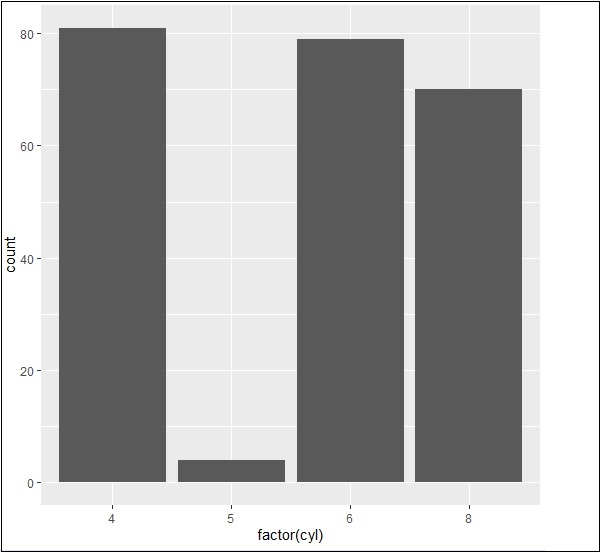
可以使用以下命令建立條形計數圖:
> # A bar count plot > p <- ggplot(mpg, aes(x=factor(cyl)))+ + geom_bar(stat="count") > p
使用直方圖進行分析
可以使用以下命令建立直方圖計數圖:
> # A historgram count plot > ggplot(data=mpg, aes(x=hwy)) + + geom_histogram( col="red", + fill="green", + alpha = .2, + binwidth = 5)

氣泡圖
現在讓我們使用所需屬性建立最基本的氣泡圖,這些屬性會增加散點圖中提到的點的維度。
ggplot(mpg, aes(x=cty, y=hwy, size = pop)) +geom_point(alpha=0.7)

該圖描述了圖例格式中包含的製造商的性質。表示的值包括“hwy”屬性的各種維度。
ggplot2 - 發散圖
在前面的章節中,我們瞭解了使用“ggplot2”包可以建立的各種型別的圖表。我們現在將重點關注相同型別的變體,例如發散條形圖、棒棒糖圖等等。首先,我們將從建立發散條形圖開始,並說明以下步驟:
瞭解資料集
載入所需的包並在 mpg 資料集中建立一個名為“car name”的新列。
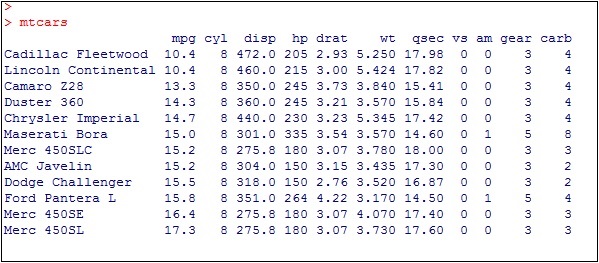
#Load ggplot > library(ggplot2) > # create new column for car names > mtcars$`car name` <- rownames(mtcars) > # compute normalized mpg > mtcars$mpg_z <- round((mtcars$mpg - mean(mtcars$mpg))/sd(mtcars$mpg), 2) > # above / below avg flag > mtcars$mpg_type <- ifelse(mtcars$mpg_z < 0, "below", "above") > # sort > mtcars <- mtcars[order(mtcars$mpg_z), ]
上述計算涉及為汽車名稱建立新列,並在 round 函式的幫助下計算歸一化資料集。我們還可以使用高於和低於平均值的標誌來獲取“type”功能的值。之後,我們對值進行排序以建立所需的資料集。
接收到的輸出如下所示:
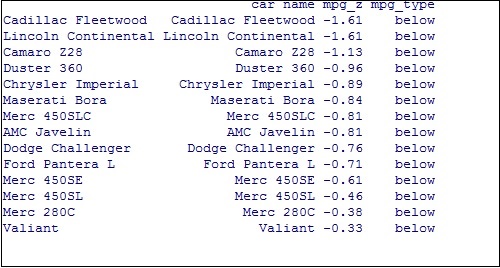
將值轉換為因子以在特定圖中保留排序順序,如下所示:
> # convert to factor to retain sorted order in plot. > mtcars$`car name` <- factor(mtcars$`car name`, levels = mtcars$`car name`)
獲得的輸出如下所示:
發散條形圖
現在使用提到的屬性建立發散條形圖,這些屬性作為所需的座標。
> # Diverging Barcharts
> ggplot(mtcars, aes(x=`car name`, y=mpg_z, label=mpg_z)) +
+ geom_bar(stat='identity', aes(fill=mpg_type), width=.5) +
+ scale_fill_manual(name="Mileage",
+ labels = c("Above Average", "Below Average"),
+ values = c("above"="#00ba38", "below"="#f8766d")) +
+ labs(subtitle="Normalised mileage from 'mtcars'",
+ title= "Diverging Bars") +
+ coord_flip()
注意 - 發散條形圖示記某些維度成員相對於提到的值向上或向下指向。
發散條形圖的輸出如下所示,其中我們使用函式 geom_bar 建立條形圖:

發散棒棒糖圖
使用相同的屬性和座標建立發散棒棒糖圖,只需更改要使用的函式,即 geom_segment(),這有助於建立棒棒糖圖。
> ggplot(mtcars, aes(x=`car name`, y=mpg_z, label=mpg_z)) + + geom_point(stat='identity', fill="black", size=6) + + geom_segment(aes(y = 0, + x = `car name`, + yend = mpg_z, + xend = `car name`), + color = "black") + + geom_text(color="white", size=2) + + labs(title="Diverging Lollipop Chart", + subtitle="Normalized mileage from 'mtcars': Lollipop") + + ylim(-2.5, 2.5) + + coord_flip()

發散點圖
以類似的方式建立發散點圖,其中點以更大的維度表示散點圖中的點。
> ggplot(mtcars, aes(x=`car name`, y=mpg_z, label=mpg_z)) +
+ geom_point(stat='identity', aes(col=mpg_type), size=6) +
+ scale_color_manual(name="Mileage",
+ labels = c("Above Average", "Below Average"),
+ values = c("above"="#00ba38", "below"="#f8766d")) +
+ geom_text(color="white", size=2) +
+ labs(title="Diverging Dot Plot",
+ subtitle="Normalized mileage from 'mtcars': Dotplot") +
+ ylim(-2.5, 2.5) +
+ coord_flip()

這裡,圖例分別用綠色和紅色表示“高於平均值”和“低於平均值”。點圖傳達靜態資訊。原理與發散條形圖中的原理相同,只是使用了點。
ggplot2 - 主題
在本章中,我們將重點介紹使用自定義主題,該主題用於更改工作區的視覺外觀。我們將使用“ggthemes”包來理解 R 工作區中主題管理的概念。
讓我們實施以下步驟以在提到的資料集中使用所需的主題。
GGTHEMES
在 R 工作區中使用所需的包安裝“ggthemes”包。
> install.packages("ggthemes")
> Library(ggthemes)

實施新主題以生成具有生產年份和排量的製造商圖例。
> library(ggthemes)
> ggplot(mpg, aes(year, displ, color=factor(manufacturer)))+
+ geom_point()+ggtitle("This plot looks a lot different from the default")+
+ theme_economist()+scale_colour_economist()

可以觀察到,使用以前的主題管理,刻度文字、圖例和其他元素的預設大小有點小。更改所有文字元素的大小非常容易。這可以在建立自定義主題時完成,我們可以在下面的步驟中觀察到所有元素的大小相對於 base_size 是相對的 (rel())。
> theme_set(theme_gray(base_size = 30)) > ggplot(mpg, aes(x=year, y=class))+geom_point(color="red")

ggplot2 - 多面板圖
多面板圖表示在單個圖中一起建立多個圖形。我們將使用 par() 函式透過傳遞圖形引數 mfrow 和 mfcol 將多個圖形放入單個圖中。
在本節中,我們將使用“AirQuality”資料集來實現多面板圖。讓我們先了解一下資料集,以便了解多面板圖的建立過程。該資料集包含了在義大利某個城市現場部署的氣體多感測器裝置的響應資料。記錄了每小時的平均響應值,以及來自認證分析儀的氣體濃度參考值。
par() 函式的簡介
瞭解 par() 函式以建立所需多面板圖的維度。
> par(mfrow=c(1,2)) > # set the plotting area into a 1*2 array
這將建立一個空白圖,其維度為 1*2。
現在,使用以下命令建立上述資料集的條形圖和餅圖。使用圖形引數 mfcol 也可以實現同樣的效果。
建立多面板圖
兩者之間的唯一區別在於,mfrow 按行填充子圖區域,而 mfcol 按列填充子圖區域。
> Temperature <- airquality$Temp > Ozone <- airquality$Ozone > par(mfrow=c(2,2)) > hist(Temperature) > boxplot(Temperature, horizontal=TRUE) > hist(Ozone) > boxplot(Ozone, horizontal=TRUE)
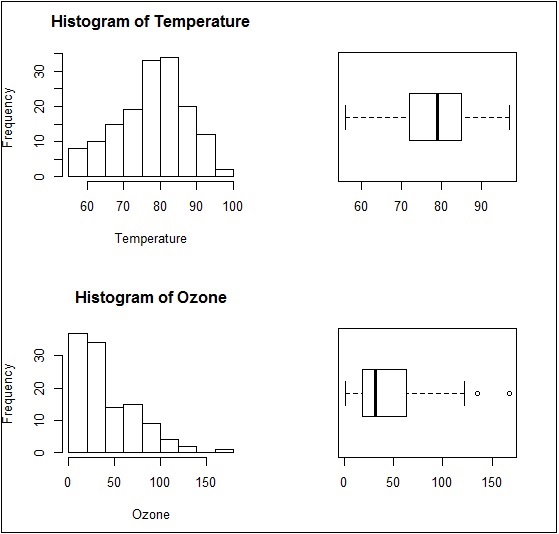
箱線圖和條形圖在一個視窗中建立,基本上建立了一個多面板圖。
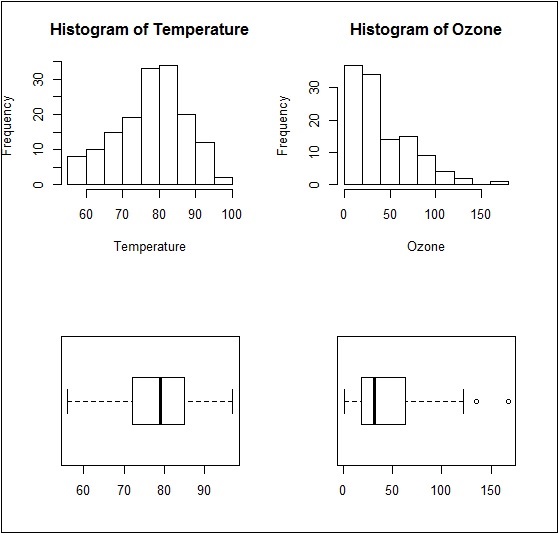
如果在 par 函式中更改維度,則圖形如下所示:
par(mfcol = c(2, 2))
ggplot2 - 多個圖形
在本章中,我們將重點介紹多個圖形的建立,這些圖形可以進一步用於建立三維圖形。將涵蓋的圖形列表包括:
- 密度圖
- 箱線圖
- 點圖
- 小提琴圖
我們將使用前面章節中使用的“mpg”資料集。該資料集提供了 1999 年和 2008 年 38 種流行汽車型號的燃油經濟性資料。該資料集與 ggplot2 包一起提供。建立不同型別的圖形,務必遵循以下步驟。
> # Load Modules > library(ggplot2) > > # Dataset > head(mpg) # A tibble: 6 x 11 manufacturer model displ year cyl trans drv cty hwy fl class <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr> 1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa~ 2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa~ 3 audi a4 2 2008 4 manual(m6) f 20 31 p compa~ 4 audi a4 2 2008 4 auto(av) f 21 30 p compa~ 5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa~ 6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa~
密度圖
密度圖是任何數值變數在指定資料集中分佈的圖形表示。它使用核密度估計來顯示變數的機率密度函式。
“ggplot2”包包含一個名為 geom_density() 的函式來建立密度圖。
我們將執行以下命令來建立密度圖:
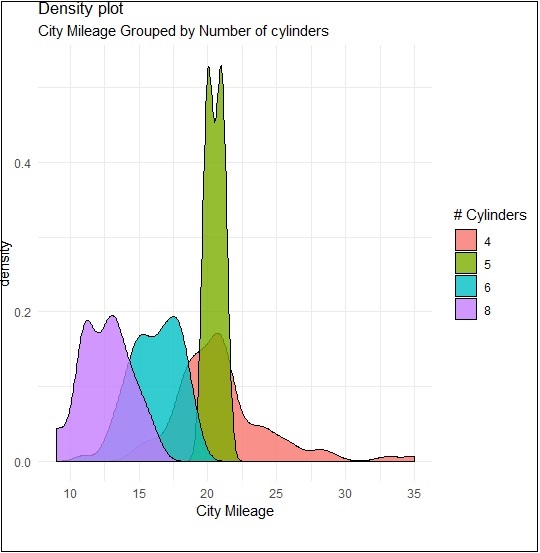
> p −- ggplot(mpg, aes(cty)) + + geom_density(aes(fill=factor(cyl)), alpha=0.8) > p
我們可以從下面建立的圖中觀察各種密度:

我們可以透過重新命名 x 軸和 y 軸來建立圖形,這透過包含標題和圖例以及不同的顏色組合來保持更好的清晰度。
> p + labs(title="Density plot", + subtitle="City Mileage Grouped by Number of cylinders", + caption="Source: mpg", + x="City Mileage", + fill="# Cylinders")
箱線圖
箱線圖也稱為盒須圖,表示資料的五數概括。五數概括包括最小值、第一四分位數、中位數、第三四分位數和最大值等值。穿過箱線圖中間部分的垂直線被認為是“中位數”。
我們可以使用以下命令建立箱線圖:
> p <- ggplot(mpg, aes(class, cty)) + + geom_boxplot(varwidth=T, fill="blue") > p + labs(title="A Box plot Example", + subtitle="Mileage by Class", + caption="MPG Dataset", + x="Class", + y="Mileage") >p
在這裡,我們根據 class 和 cty 屬性建立箱線圖。

點圖
點圖類似於散點圖,只是維度不同。在本節中,我們將向現有的箱線圖新增點圖,以獲得更好的影像和清晰度。
可以使用以下命令建立箱線圖:
> p <- ggplot(mpg, aes(manufacturer, cty)) + + geom_boxplot() + + theme(axis.text.x = element_text(angle=65, vjust=0.6)) > p

點圖的建立如下所示:
> p + geom_dotplot(binaxis='y', + stackdir='center', + dotsize = .5 + )

小提琴圖
小提琴圖也以類似的方式建立,只是結構改為小提琴而不是箱子。輸出在下面清楚地說明了:
> p <- ggplot(mpg, aes(class, cty)) > > p + geom_violin()

ggplot2 - 背景顏色
有一些方法可以使用一個函式來更改整個圖形的外觀,如下所示。但是,如果您只想更改面板的背景顏色,可以使用以下方法:
實現面板背景
我們可以使用以下命令更改背景顏色,這有助於更改面板 (panel.background):
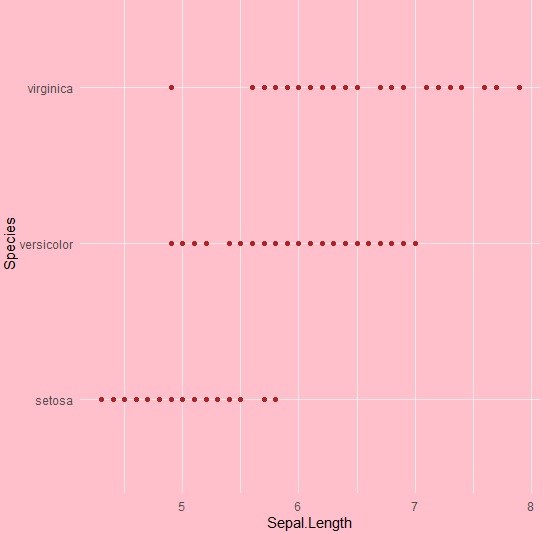
> ggplot(iris, aes(Sepal.Length, Species))+geom_point(color="firebrick")+ + theme(panel.background = element_rect(fill = 'grey75'))
顏色變化在下面的圖片中清楚地顯示:

實現 Panel.grid.major
我們可以使用以下命令中提到的“panel.grid.major”屬性更改網格線:
> ggplot(iris, aes(Sepal.Length, Species))+geom_point(color="firebrick")+ + theme(panel.background = element_rect(fill = 'grey75'), + panel.grid.major = element_line(colour = "orange", size=2), + panel.grid.minor = element_line(colour = "blue"))

我們甚至可以更改圖形背景,尤其是排除面板,使用以下提到的“plot.background”屬性:
ggplot(iris, aes(Sepal.Length, Species))+geom_point(color="firebrick")+ + theme(plot.background = element_rect(fill = 'pink'))
ggplot2 - 時間序列
時間序列是一種圖形圖,它以特定的時間順序表示一系列資料點。時間序列是在連續等間距的時間點上獲取的一系列序列。時間序列可以被視為離散時間資料。我們將在本章中使用的資料集是“economics”資料集,其中包含美國經濟時間序列的所有詳細資訊。
資料框包含以下屬性,如下所示:
| 日期 | 資料收集的月份 |
| Psavert | 個人儲蓄率 |
| Pce | 個人消費支出 |
| Unemploy | 失業人數(以千計) |
| Unempmed | 失業的中位數持續時間 |
| Pop | 總人口(以千計) |
載入所需的包並將預設主題設定為建立時間序列。
> library(ggplot2) > theme_set(theme_minimal()) > # Demo dataset > head(economics) # A tibble: 6 x 6 date pce pop psavert uempmed unemploy <date> <dbl> <dbl> <dbl> <dbl> <dbl> 1 1967-07-01 507. 198712 12.6 4.5 2944 2 1967-08-01 510. 198911 12.6 4.7 2945 3 1967-09-01 516. 199113 11.9 4.6 2958 4 1967-10-01 512. 199311 12.9 4.9 3143 5 1967-11-01 517. 199498 12.8 4.7 3066 6 1967-12-01 525. 199657 11.8 4.8 3018
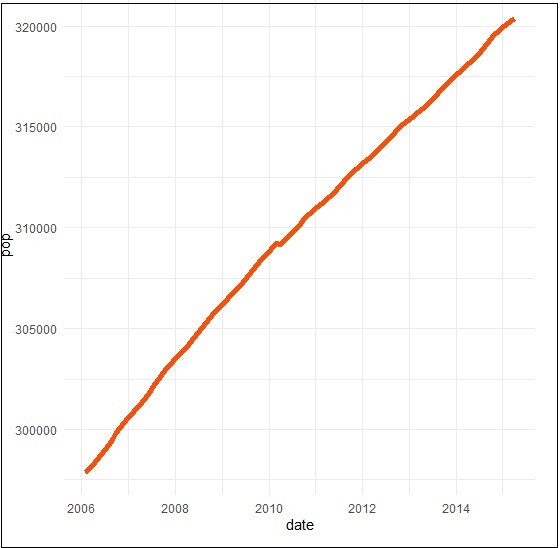
建立一個基本的線形圖,它建立了一個時間序列結構。
> # Basic line plot > ggplot(data = economics, aes(x = date, y = pop))+ + geom_line(color = "#00AFBB", size = 2)

我們可以使用以下命令繪製資料集的子集:
> # Plot a subset of the data
> ss <- subset(economics, date > as.Date("2006-1-1"))
> ggplot(data = ss, aes(x = date, y = pop)) +
+ geom_line(color = "#FC4E07", size = 2)
建立時間序列
在這裡,我們將根據日期繪製變數 psavert 和 uempmed。這裡我們必須使用 tidyr 包重塑資料。這可以透過將 psavert 和 uempmed 值摺疊到同一列(新列)中來實現。R 函式:gather()[tidyr]。下一步涉及建立一個分組變數,其級別為 psavert 和 uempmed。
> library(tidyr) > library(dplyr) Attaching package: ‘dplyr’ The following object is masked from ‘package:ggplot2’: vars The following objects are masked from ‘package:stats’: filter, lag The following objects are masked from ‘package:base’: intersect, setdiff, setequal, union > df <- economics %>% + select(date, psavert, uempmed) %>% + gather(key = "variable", value = "value", -date) > head(df, 3) # A tibble: 3 x 3 date variable value <date> <chr> <dbl> 1 1967-07-01 psavert 12.6 2 1967-08-01 psavert 12.6 3 1967-09-01 psavert 11.9
使用以下命令建立多條線形圖,以瞭解“psavert”和“unempmed”之間的關係:
> ggplot(df, aes(x = date, y = value)) +
+ geom_line(aes(color = variable), size = 1) +
+ scale_color_manual(values = c("#00AFBB", "#E7B800")) +
+ theme_minimal()
