估算技術速查
估算技術 - 概述
估算是指尋找一個估計值或近似值的過程,即使輸入資料可能不完整、不確定或不穩定,該值也可以用於某種目的。
估算確定構建特定系統或產品需要多少資金、努力、資源和時間。估算基於:
- 過去的資料/過去的經驗
- 可用文件/知識
- 假設
- 已識別的風險
軟體專案估算的四個基本步驟是:
- 估算開發產品的規模。
- 估算以人月或人時為單位的工作量。
- 估算以日曆月為單位的進度。
- 估算以約定的貨幣為單位的專案成本。
關於估算的觀察
估算不必是專案中的一次性任務。它可以在以下階段進行:
- 獲取專案。
- 計劃專案。
- 根據需要執行專案。
在估算過程開始之前,必須瞭解專案範圍。擁有歷史專案資料將很有幫助。
專案指標可以提供歷史視角和生成定量估算的寶貴輸入。
計劃需要技術經理和軟體團隊做出初步承諾,因為它會導致責任和問責制。
過去的經驗可以極大地幫助。
至少使用兩種估算技術得出估算值,並協調結果值。請參閱下一節中的分解技術,瞭解如何協調估算值。
計劃應該具有迭代性,並允許隨著時間的推移和更多細節的瞭解而進行調整。
通用專案估算方法
廣泛使用的專案估算方法是分解技術。分解技術採用分而治之的方法。規模、工作量和成本估算透過將專案分解成主要功能或相關的軟體工程活動,以逐步的方式進行。
步驟 1 - 瞭解要構建的軟體的範圍。
步驟 2 - 生成軟體規模的估算。
從範圍說明開始。
將軟體分解成可以分別估算的各個功能。
計算每個功能的規模。
透過將規模值應用於您的基線生產力指標來推匯出工作量和成本估算。
組合功能估算以生成整個專案的總體估算。
步驟 3 - 生成工作量和成本的估算。您可以透過將專案分解成相關的軟體工程活動來得出工作量和成本估算。
確定專案完成所需執行的活動順序。
將活動分解成可以衡量的任務。
估算完成每個任務所需的工作量(以人時/天為單位)。
組合活動任務的工作量估算以生成該活動的估算。
從資料庫中獲取每個活動的成本單位(即,成本/單位工作量)。
計算每個活動的工作量和成本總額。
組合每個活動的工作量和成本估算以生成整個專案的總體工作量和成本估算。
步驟 4 - 協調估算:將步驟 3 中的結果值與步驟 2 中獲得的結果值進行比較。如果兩組估算值一致,則您的數字非常可靠。否則,如果出現差異很大的估算值,則應進一步調查以下問題:
專案的範圍沒有得到充分理解或已被誤解。
功能和/或活動分解不準確。
用於估算技術的歷史資料不適用於該應用程式,或已過時,或已被誤用。
步驟 5 - 確定差異的原因,然後協調估算。
估算精度
精度是指某事物與現實有多接近的指標。每當您生成估算值時,每個人都想知道這些數字與現實有多接近。您希望在生成估算值時,根據當時擁有的資料,每個估算值都儘可能準確。當然,您不希望以一種會讓人對數字產生錯誤的信心感的方式來呈現估算值。
影響估算精度的重要因素包括:
所有估算輸入資料的準確性。
任何估算計算的準確性。
用於校準模型的歷史資料或行業資料與您正在估算的專案匹配的程度。
您組織的軟體開發過程的可預測性。
產品需求和支援軟體工程工作的環境的穩定性。
實際專案是否經過精心計劃、監控和控制,以及是否發生導致意外延誤的重大意外。
以下是實現可靠估算的一些指南:
- 將估算基於已經完成的類似專案。
- 使用相對簡單的分解技術來生成專案成本和工作量估算。
- 使用一個或多個經驗估算模型進行軟體成本和工作量估算。
請參閱本章中關於估算指南的部分。
為確保準確性,始終建議使用至少兩種技術進行估算並比較結果。
估算問題
通常,專案經理會採用跳過規模估算而直接估算進度的做法。這可能是由於高層管理或營銷團隊設定的時間表所致。但是,無論原因是什麼,如果這樣做,那麼在後期階段,要估算進度以適應範圍變更將會非常困難。
在估算過程中,可能會做出某些假設。重要的是在估算表中記錄所有這些假設,因為有些人仍然不會在估算表中記錄假設。
即使是良好的估算也存在固有的假設、風險和不確定性,但它們通常卻被視為準確的。
表達估算的最佳方式是作為一系列可能的結果,例如,說專案將需要 5 到 7 個月,而不是說它將在特定日期完成或將在固定數量的月份內完成。要注意避免承諾過於狹窄的範圍,因為這等同於承諾一個確定的日期。
您還可以將不確定性作為伴隨的機率值包含在內。例如,專案在特定日期或之前完成的機率為 90%。
組織不收集準確的專案資料。由於估算的準確性取決於歷史資料,這將是一個問題。
對於任何專案,都有一個最短的可能進度,這將允許您包含所需的功能併產生高質量的輸出。如果管理層和/或客戶有進度限制,您可以協商要交付的範圍和功能。
與客戶就處理範圍蔓延達成一致,以避免進度延誤。
在最終估算中未能考慮意外情況會導致問題。例如,會議、組織活動。
資源利用率應考慮小於 80%。這是因為資源只有 80% 的時間才能有效率。如果您分配的資源利用率超過 80%,則必然會發生延誤。
估算指南
在估算專案時,應牢記以下指南:
在估算過程中,詢問其他人的經驗。此外,也要運用你自己的經驗。
假設資源只有 80% 的時間才能有效率。因此,在估算過程中,將資源利用率設定為低於 80%。
同時參與多個專案的資源由於在專案之間切換而花費的時間損失,導致完成任務所需的時間更長。
在任何估算中都應包括管理時間。
始終為解決問題、會議和其他意外事件留出足夠的時間。
留出足夠的時間來進行適當的專案估算。倉促的估算是準確性低、風險高的估算。對於大型開發專案,估算步驟實際上應該被視為一個小型專案。
如果可能,使用貴組織類似過去專案的已記錄資料。這將產生最準確的估算。如果貴組織沒有保留歷史資料,現在是開始收集的好時機。
使用基於開發人員的估算,因為由非執行人員編制的估算將不太準確。
使用幾個人進行估算,並使用幾種不同的估算技術。
協調估算。觀察估算結果的收斂或差異。收斂意味著您已經獲得了一個良好的估算。寬頻德爾菲法可用於使用一群人收集和討論估算,其目的是產生準確、無偏見的估算。
在專案生命週期的多個時間點重新估算專案。
估算技術 - 功能點
功能點 (FP) 是一個計量單位,用於表達資訊系統(作為產品)向用戶提供的業務功能量。FP 衡量軟體規模。它們被廣泛接受為功能規模測量的行業標準。
對於基於 FP 的軟體規模計算,已經出現了一些公認的標準和/或公共規範。截至 2013 年,這些標準包括:
ISO 標準
COSMIC - ISO/IEC 19761:2011 軟體工程。一種功能規模測量方法。
FiSMA - ISO/IEC 29881:2008 資訊科技 - 軟體和系統工程 - FiSMA 1.1 功能規模測量方法。
IFPUG - ISO/IEC 20926:2009 軟體和系統工程 - 軟體測量 - IFPUG 功能規模測量方法。
Mark-II - ISO/IEC 20968:2002 軟體工程 - Ml II 功能點分析 - 計數實踐手冊。
NESMA - ISO/IEC 24570:2005 軟體工程 - NESMA 功能規模測量方法 2.1 版 - 功能點分析應用的定義和計數指南。
物件管理組織 (OMG) 自動化功能點規範
物件管理組織 (OMG) 是一個開放式會員制且非營利的計算機行業標準協會,它已經採用了由 IT 軟體質量聯盟牽頭的自動化功能點 (AFP) 規範。它提供了一個根據國際功能點使用者組 (IFPUG) 的指南自動執行 FP 計數的標準。
功能點分析 (FPA) 技術根據對軟體使用者有意義的術語量化軟體中包含的功能。FP 考慮根據需求規格說明開發的功能數量。
功能點 (FP) 計數受國際功能點使用者組 (IFPUG) 定義的一套標準規則、流程和指南的約束。這些內容釋出在《計數實踐手冊》(CPM) 中。
功能點分析的歷史
函式點概念由IBM的Alan Albrecht於1979年提出。1984年,Albrecht對該方法進行了改進。首個函式點指南於1984年釋出。國際函式點使用者組 (IFPUG) 是一個總部位於美國的全球性組織,其成員是函式點分析度量軟體的使用者。**國際函式點使用者組 (IFPUG)**是一個成立於1986年的非營利性會員管理組織。IFPUG擁有ISO標準20296:2009中定義的函式點分析 (FPA),該標準規定了應用IFPUG功能規模度量(FSM)方法的定義、規則和步驟。IFPUG維護著函式點計數實踐手冊 (CPM)。CPM 2.0於1987年釋出,此後經歷了多次迭代。CPM 4.3版釋出於2010年。
包含ISO編輯修訂的CPM 4.3.1版於2010年釋出。ISO標準 (IFPUG FSM) - 功能規模度量是CPM 4.3.1的一部分,是一種根據軟體交付的功能來衡量軟體的技術。CPM是ISO/IEC 14143-1資訊科技——軟體度量下的國際認可標準。
基本過程 (EP)
基本過程是功能使用者需求的最小單位,其:
- 對使用者有意義。
- 構成一個完整的交易。
- 是自包含的,並使被計數的應用程式業務處於一致狀態。
功能
有兩種型別的功能:
- 資料功能
- 事務功能
資料功能
有兩種型別的資料功能:
- 內部邏輯檔案
- 外部介面檔案
資料功能由影響系統的內部和外部資源組成。
內部邏輯檔案
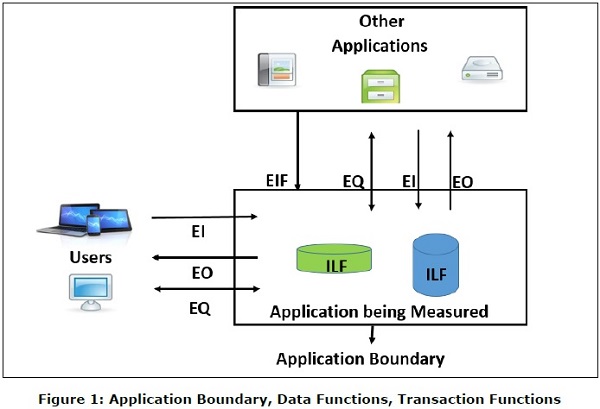
內部邏輯檔案 (ILF) 是使用者可識別的、邏輯相關的組資料或控制資訊,完全駐留在應用程式邊界內。ILF的主要目的是儲存透過被計數應用程式的一個或多個基本過程維護的資料。ILF具有其固有的含義,即它是內部維護的,具有某種邏輯結構,並存儲在檔案中。(參見圖1)
外部介面檔案
外部介面檔案 (EIF) 是使用者可識別的、邏輯相關的組資料或控制資訊,應用程式僅用於參考目的。資料完全駐留在應用程式邊界之外,並由另一個應用程式在ILF中維護。EIF具有其固有的含義,即它是外部維護的,需要開發一個接口才能從檔案中獲取資料。(參見圖1)
事務功能
有三種類型的事務功能。
- 外部輸入
- 外部輸出
- 外部查詢
事務功能由使用者、外部應用程式和被測應用程式之間交換的過程組成。
外部輸入
外部輸入 (EI) 是一種事務功能,其中資料從邊界外部“進入”應用程式內部。此資料來自應用程式外部。
- 資料可能來自資料輸入螢幕或其他應用程式。
- EI是應用程式獲取資訊的方式。
- 資料可以是控制資訊或業務資訊。
- 資料可用於維護一個或多個內部邏輯檔案。
- 如果資料是控制資訊,則不必更新內部邏輯檔案。(參見圖1)
外部輸出
外部輸出 (EO) 是一種事務功能,其中資料從系統“輸出”。此外,EO可以更新ILF。資料建立報告或傳送到其他應用程式的輸出檔案。(參見圖1)
外部查詢
外部查詢 (EQ) 是一種事務功能,具有輸入和輸出元件,用於資料檢索。(參見圖1)
RET、DET、FTR的定義
記錄元素型別
記錄元素型別 (RET) 是ILF或EIF中使用者可識別的最大元素子組。最好檢視資料的邏輯分組以幫助識別它們。
資料元素型別
資料元素型別 (DET) 是FTR中的資料子組。它們是唯一且使用者可識別的。
檔案型別引用
檔案型別引用 (FTR) 是EI、EO或EQ中使用者可識別的最大子組,被引用到。
事務功能EI、EO、EQ透過計數它們包含的FTR和DET(遵循計數規則)來衡量。同樣,資料功能ILF和EIF透過計數它們包含的DET和RET(遵循計數規則)來衡量。事務功能和資料功能的度量用於FP計數,從而得出功能規模或函式點。
估算技術 - FP計數過程
FP計數過程包括以下步驟:
步驟1 - 確定計數型別。
步驟2 - 確定計數邊界。
步驟3 - 識別使用者所需的每個基本過程 (EP)。
步驟4 - 確定唯一的EP。
步驟5 - 測量資料功能。
步驟6 - 測量事務功能。
步驟7 - 計算功能規模(未調整的函式點計數)。
步驟8 - 確定價值調整因子 (VAF)。
步驟9 - 計算調整後的函式點計數。
注意 - CPM 4.3.1中通用系統特性 (GSCs) 變為可選,並移至附錄。因此,可以跳過步驟8和步驟9。
步驟1:確定計數型別
有三種類型的函式點計數:
- 開發函式點計數
- 應用函式點計數
- 增強函式點計數
開發函式點計數
函式點可以在開發專案的各個階段(從需求到實施階段)進行計數。此計數型別與新開發工作相關,可能包括可能作為臨時解決方案所需的原型,這些原型支援轉換工作。此計數型別稱為基線函式點計數。
應用函式點計數
應用計數計算為交付的函式點,不包括任何轉換工作(原型或臨時解決方案)和可能已存在的現有功能。
增強函式點計數
生產後對軟體進行更改時,這些更改被視為增強功能。為了確定此類增強專案的規模,應用程式中的函式點計數將被新增、更改或刪除。
步驟2:確定計數邊界
邊界表示被測應用程式與外部應用程式或使用者域之間的界限。(參見圖1)
要確定邊界,請了解:
- 函式點計數的目的
- 被測應用程式的範圍
- 哪些應用程式如何維護哪些資料
- 支援這些應用程式的業務領域
步驟3:識別使用者所需的每個基本過程
將功能使用者需求分解成最小的活動單元,該單元滿足以下所有條件:
- 對使用者有意義。
- 構成一個完整的交易。
- 是自包含的。
- 使被計數的應用程式業務處於一致狀態。
例如,功能使用者需求 - “維護員工資訊”可以分解成更小的活動,例如新增員工、更改員工、刪除員工和查詢員工。
因此識別的每個活動單元都是一個基本過程 (EP)。
步驟4:確定唯一的基本過程
比較兩個已識別的EP,如果它們:
- 需要相同的DET集。
- 需要相同的FTR集。
- 需要相同的處理邏輯來完成EP。
不要將具有多種處理邏輯的EP拆分成多個EP。
例如,如果您已將“新增員工”標識為EP,則不應將其分成兩個EP來解釋員工可能有也可能沒有家屬這一事實。EP仍然是“新增員工”,並且處理邏輯和DET存在差異以解釋家屬。
步驟5:測量資料功能
將每個資料功能分類為ILF或EIF。
資料功能應分類為:
內部邏輯檔案 (ILF),如果它是被測應用程式維護的。
外部介面檔案 (EIF),如果它是被引用的,但不是被測應用程式維護的。
ILF和EIF可以包含業務資料、控制資料和基於規則的資料。例如,電話交換由所有三種類型組成 - 業務資料、規則資料和控制資料。業務資料是實際的呼叫。規則資料是呼叫如何透過網路路由,控制資料是交換機如何相互通訊。
考慮以下文件來計算ILF和EIF:
- 擬議系統的目標和約束。
- 關於當前系統的文件(如果存在這樣的系統)。
- 使用者感知的目標、問題和需求的文件。
- 資料模型。
步驟5.1:計算每個資料功能的DET
應用以下規則來計算ILF/EIF的DET:
為透過執行EP在ILF或EIF中維護或檢索的每個唯一使用者可識別、非重複欄位計算一個DET。
當兩個或多個應用程式維護和/或引用相同的資料功能時,僅計算被測應用程式使用的那些DET。
為使用者建立與另一個ILF或EIF關係所需的每個屬性計算一個DET。
檢查相關屬性以確定它們是分組並計算為單個DET,還是計算為多個DET。分組將取決於EP在應用程式中如何使用這些屬性。
步驟5.2:計算每個資料功能的RET
應用以下規則來計算ILF/EIF的RET:
- 為每個資料功能計算一個RET。
- 為以下每個附加的DET邏輯子組計算一個附加的RET。
- 具有非鍵屬性的關聯實體。
- 子型別(除第一個子型別外)。
- 屬性實體,在非強制性1:1關係中。
步驟5.3:確定每個資料功能的功能複雜性
| RETs | 資料元素型別 (DETs) | ||
|---|---|---|---|
| 1-19 | 20-50 | >50 | |
| 1 | L | L | A |
| 2 到 5 | L | A | H |
| >5 | A | H | H |
功能複雜度:L = 低;A = 中;H = 高
步驟 5.4:衡量每個資料功能的功能規模
| 功能複雜度 | 內部邏輯檔案 (ILF) 的功能點數 | 外部介面檔案 (EIF) 的功能點數 |
|---|---|---|
| 低 | 7 | 5 |
| 中 | 10 | 7 |
| 高 | 15 | 10 |
步驟 6:衡量事務功能
衡量事務功能需要以下步驟:
步驟 6.1:對每個事務功能進行分類
事務功能應分類為外部輸入、外部輸出或外部查詢。
外部輸入
外部輸入 (EI) 是一個基本過程,它處理來自邊界外部的資料或控制資訊。EI 的主要目的是維護一個或多個 ILF 和/或改變系統的行為。
必須應用以下所有規則:
資料或控制資訊是從應用程式邊界外部接收的。
如果進入邊界的資料不是改變系統行為的控制資訊,則至少維護一個 ILF。
對於已識別的基本過程 (EP),必須應用以下三個陳述之一:
處理邏輯與應用程式中其他 EI 執行的處理邏輯不同。
已識別的的資料元素集與應用程式中其他 EI 的已識別的資料元素集不同。
引用的 ILF 或 EIF 與應用程式中其他 EI 引用的檔案不同。
外部輸出
外部輸出 (EO) 是一個基本過程,它將資料或控制資訊傳送到應用程式邊界之外。EO 包括超出外部查詢的額外處理。
EO 的主要目的是透過除檢索資料或控制資訊之外或除了檢索資料或控制資訊之外的處理邏輯向用戶呈現資訊。
處理邏輯必須:
- 包含至少一個數學公式或計算。
- 建立派生資料。
- 維護一個或多個 ILF。
- 改變系統的行為。
必須應用以下所有規則:
- 將資料或控制資訊傳送到應用程式邊界之外。
- 對於已識別的基本過程 (EP),必須應用以下三個陳述之一:
- 處理邏輯與應用程式中其他 EO 執行的處理邏輯不同。
- 已識別的的資料元素集與應用程式中其他 EO 的資料元素集不同。
- 引用的 ILF 或 EIF 與應用程式中其他 EO 引用的檔案不同。
此外,必須應用以下規則之一:
- 處理邏輯包含至少一個數學公式或計算。
- 處理邏輯至少維護一個 ILF。
- 處理邏輯改變系統的行為。
外部查詢
外部查詢 (EQ) 是一個基本過程,它將資料或控制資訊傳送到邊界之外。EQ 的主要目的是透過檢索資料或控制資訊向用戶呈現資訊。
處理邏輯不包含數學公式或計算,也不建立派生資料。在處理過程中不維護任何 ILF,也不改變系統的行為。
必須應用以下所有規則:
- 將資料或控制資訊傳送到應用程式邊界之外。
- 對於已識別的基本過程 (EP),必須應用以下三個陳述之一:
- 處理邏輯與應用程式中其他 EQ 執行的處理邏輯不同。
- 已識別的的資料元素集與應用程式中其他 EQ 的資料元素集不同。
- 引用的 ILF 或 EIF 與應用程式中其他 EQ 引用的檔案不同。
此外,必須應用以下所有規則:
- 處理邏輯從 ILF 或 EIF 檢索資料或控制資訊。
- 處理邏輯不包含數學公式或計算。
- 處理邏輯不改變系統的行為。
- 處理邏輯不維護 ILF。
步驟 6.2:計算每個事務功能的 DET
應用以下規則來計算 EI 的 DET:
檢查所有跨越(進入和/或退出)邊界的內容。
為每個唯一使用者可識別、非重複的屬性計數一個 DET,這些屬性在事務功能處理期間跨越(進入和/或退出)邊界。
對於傳送應用程式響應訊息的能力,每個事務功能只計算一個 DET,即使有多個訊息。
對於啟動操作的能力,每個事務功能只計算一個 DET,即使有多種方法可以這樣做。
不要將以下專案計為 DET:
由事務功能在邊界內生成並儲存到 ILF 而無需離開邊界的屬性。
文字,例如報表標題、螢幕或面板識別符號、列標題和屬性標題。
應用程式生成的標記,例如日期和時間屬性。
分頁變數、頁碼和定位資訊,例如“211 行中的第 37 行到第 54 行”。
導航輔助工具,例如使用“上一個”、“下一個”、“第一個”、“最後一個”及其圖形等效項在列表中導航的能力。
應用以下規則來計算 EO/EQ 的 DET:
檢查所有跨越(進入和/或退出)邊界的內容。
為每個唯一使用者可識別、非重複的屬性計數一個 DET,這些屬性在事務功能處理期間跨越(進入和/或退出)邊界。
對於傳送應用程式響應訊息的能力,每個事務功能只計算一個 DET,即使有多個訊息。
對於啟動操作的能力,每個事務功能只計算一個 DET,即使有多種方法可以這樣做。
不要將以下專案計為 DET:
在邊界內生成而不跨越邊界的屬性。
文字,例如報表標題、螢幕或面板識別符號、列標題和屬性標題。
應用程式生成的標記,例如日期和時間屬性。
分頁變數、頁碼和定位資訊,例如“211 行中的第 37 行到第 54 行”。
導航輔助工具,例如使用“上一個”、“下一個”、“第一個”、“最後一個”及其圖形等效項在列表中導航的能力。
步驟 6.3:計算每個事務功能的 FTR
應用以下規則來計算 EI 的 FTR:
- 為維護的每個 ILF 計算一個 FTR。
- 為在 EI 處理期間讀取的每個 ILF 或 EIF 計算一個 FTR。
- 對於同時維護和讀取的每個 ILF,只計算一個 FTR。
應用以下規則來計算 EO/EQ 的 FTR:
- 為在 EP 處理期間讀取的每個 ILF 或 EIF 計算一個 FTR。
此外,應用以下規則來計算 EO 的 FTR:
- 為在 EP 處理期間維護的每個 ILF 計算一個 FTR。
- 對於 EP 同時維護和讀取的每個 ILF,只計算一個 FTR。
步驟 6.4:確定每個事務功能的功能複雜度
| FTR | 資料元素型別 (DETs) | ||
|---|---|---|---|
| 1-4 | 5-15 | >=16 | |
| 0-1 | L | L | A |
| 2 | L | A | H |
| >=3 | A | H | H |
功能複雜度:L = 低;A = 中;H = 高
確定每個 EO/EQ 的功能複雜度,但 EQ 必須至少有 1 個 FTR:
EQ 必須至少有 1 個 FTR FTR |
資料元素型別 (DETs) | ||
|---|---|---|---|
| 1-4 | 5-15 | >=16 | |
| 0-1 | L | L | A |
| 2 | L | A | H |
| >=3 | A | H | H |
功能複雜度:L = 低;A = 中;H = 高
步驟 6.5:衡量每個事務功能的功能規模
根據其功能複雜度衡量每個 EI 的功能規模。
| 複雜度 | 功能點數 |
|---|---|
| 低 | 3 |
| 中 | 4 |
| 高 | 6 |
根據其功能複雜度衡量每個 EO/EQ 的功能規模。
| 複雜度 | EO 的功能點數 | EQ 的功能點數 |
|---|---|---|
| 低 | 4 | 3 |
| 中 | 5 | 4 |
| 高 | 6 | 6 |
步驟 7:計算功能規模(未調整的功能點計數)
要計算功能規模,應遵循以下步驟:
步驟 7.1
回顧在步驟 1 中找到的內容。確定計數型別。
步驟 7.2
根據型別計算功能規模或功能點計數。
- 對於開發功能點計數,請轉到步驟 7.3。
- 對於應用程式功能點計數,請轉到步驟 7.4。
- 對於增強功能點計數,請轉到步驟 7.5。
步驟 7.3
開發功能點計數包含兩個功能元件:
專案使用者需求中包含的應用程式功能。
專案使用者需求中包含的轉換功能。轉換功能僅在安裝時提供,用於轉換資料和/或提供其他使用者指定的轉換需求,例如特殊轉換報表。例如,現有應用程式可以用新系統替換。
DFP = ADD + CFP
其中:
DFP = 開發功能點計數
ADD = 開發專案交付給使用者的函式規模
CFP = 轉換功能的規模
ADD = ILF 功能點數 + EIF 功能點數 + EI 功能點數 + EO 功能點數 + EQ 功能點數
CFP = ILF 功能點數 + EIF 功能點數 + EI 功能點數 + EO 功能點數 + EQ 功能點數
步驟 7.4
計算應用程式功能點計數
AFP = ADD
其中:
AFP = 應用程式功能點計數
ADD = 開發專案交付給使用者的函式規模(不包括任何轉換功能的規模),或應用程式計數時存在的任何功能。
ADD = ILF 功能點數 + EIF 功能點數 + EI 功能點數 + EO 功能點數 + EQ 功能點數
步驟 7.5
增強功能點計數考慮以下四個功能元件:
- 新增到應用程式的功能。
- 在應用程式中修改的功能。
- 轉換功能。
- 從應用程式中刪除的功能。
EFP = ADD + CHGA + CFP + DEL
其中:
EFP = 增強功能點計數
ADD = 增強專案新增的功能規模
CHGA = 增強專案更改的功能規模
CFP = 轉換功能的規模
DEL = 增強專案刪除的功能規模
ADD = ILF 功能點數 + EIF 功能點數 + EI 功能點數 + EO 功能點數 + EQ 功能點數
CHGA = ILF 功能點數 + EIF 功能點數 + EI 功能點數 + EO 功能點數 + EQ 功能點數
CFP = ILF 功能點數 + EIF 功能點數 + EI 功能點數 + EO 功能點數 + EQ 功能點數
DEL = ILF 功能點數 + EIF 功能點數 + EI 功能點數 + EO 功能點數 + EQ 功能點數
步驟 8:確定價值調整因子
在 CPM 4.3.1 中,GSC 成為可選,並移至附錄。因此,可以跳過步驟 8 和步驟 9。
價值調整因子 (VAF) 基於 14 個 GSC,這些 GSC 對正在計算的應用程式的一般功能進行評級。GSC 是獨立於技術的使用者業務約束。每個特徵都有相關的描述來確定影響程度。
| 一般系統特性 | 簡要描述 |
|---|---|
| 資料通訊 | 有多少通訊設施可以幫助與應用程式或系統傳輸或交換資訊? |
| 分散式資料處理 | 如何處理分散式資料和處理功能? |
| 效能 | 使用者是否需要響應時間或吞吐量? |
| 高使用率配置 | 應用程式將在其上執行的當前硬體平臺的使用率如何? |
| 事務速率 | 每天、每週、每月等執行事務的頻率是多少? |
| 線上資料輸入 | 線上輸入的資訊百分比是多少? |
| 終端使用者效率 | 應用程式是否針對終端使用者效率而設計? |
| 線上更新 | 有多少 ILF 由線上事務更新? |
| 複雜處理 | 應用程式是否具有廣泛的邏輯或數學處理? |
| 可重用性 | 應用程式是否為滿足一個或多個使用者的需求而開發的? |
| 安裝簡易性 | 轉換和安裝有多難? |
| 操作簡易性 | 啟動、備份和恢復程式的有效性和/或自動化程度如何? |
| 多個站點 | 該應用程式是否專門設計、開發和支援在多個組織的多個站點進行安裝? |
| 促進變更 | 該應用程式是否專門設計、開發和支援以促進變更? |
影響程度範圍為零到五,從無影響到強烈影響。
| 評級 | 影響程度 |
|---|---|
| 0 | 不存在,或無影響 |
| 1 | 偶然影響 |
| 2 | 中等影響 |
| 3 | 平均影響 |
| 4 | 顯著影響 |
| 5 | 始終強烈影響 |
確定每個14個GSC的影響程度。
由此獲得的14個GSC值的總和稱為總影響程度(TDI)。
TDI = ∑14影響程度
接下來,計算價值調整因子(VAF)為
VAF = (TDI × 0.01) + 0.65
每個GSC可以從0到5變化,TDI可以從(0 × 14)到(5 × 14)變化,即0(當所有GSC都較低時)到70(當所有GSC都較高時),即0 ≤ TDI ≤ 70。因此,VAF的範圍可以從0.65(當所有GSC都較低時)到1.35(當所有GSC都較高時),即0.65 ≤ VAF ≤ 1.35。
步驟9:計算調整後的功能點計數
根據使用VAF的功能點分析法(V4.3.1之前的CPM版本),這是由以下公式確定的:
調整後的功能點計數 = 未調整的功能點計數 × VAF
其中,未調整的功能點計數是在步驟7中計算的功能規模。
由於VAF可以在0.65到1.35之間變化,因此VAF對最終調整後的功能點計數的影響為±35%。
功能點的優勢
功能點很有用,因為:
用於衡量解決方案的規模,而不是問題的規模。
因為只需要需求就能計算功能點。
因為它獨立於技術。
因為它獨立於程式語言。
用於估算測試專案。
用於估算專案的總成本、進度和工作量。
在合同談判中,因為它提供了一種與業務部門更容易溝通的方法。
因為它量化併為軟體中功能的實際用途、介面和目的賦值。
用於建立與其他指標(如工時、成本、人員數量、持續時間和其他應用程式指標)的比率。
功能點庫
國際軟體基準標準組織(ISBSG)建立並維護兩個IT資料儲存庫。
- 開發和增強專案
- 維護和支援應用程式
開發和增強專案儲存庫中包含6000多個專案。
資料以Microsoft Excel格式提供,方便您進行進一步分析,或者您可以將資料用於其他目的。
ISBSG儲存庫許可證可從以下網址購買:http://www.isbsg.com/
ISBSG為IFPUG會員提供線上購買10%的折扣,使用折扣碼“IFPUGMembers”。
ISBSG軟體專案資料釋出更新可在以下網址找到:http://www.ifpug.org/isbsg/
COSMIC和IFPUG合作編寫了軟體非功能性和專案需求術語表。可從此處下載:cosmic-sizing.org
估算技術 - 用例點
用例是一系列使用者和系統之間的相關互動,使使用者能夠實現目標。
用例是捕獲系統功能需求的一種方式。系統的使用者被稱為“參與者”。用例基本上是文字形式的。
用例點 – 定義
用例點(UCP)是一種軟體估算技術,用於使用用例衡量軟體規模。UCP的概念類似於功能點。
專案中的UCP數量基於以下因素:
- 系統中用例的數量和複雜性。
- 系統中參與者的數量和複雜性。
各種未作為用例編寫的非功能性需求(例如可移植性、效能、可維護性)。
專案將要開發的環境(例如語言、團隊的積極性等)。
使用UCP進行估算需要所有用例都以目標編寫,並且大致處於同一級別,提供相同程度的細節。因此,在估算之前,專案團隊應確保他們已經編寫了具有明確目標和詳細級別的用例。用例通常在一個會話中完成,並且在目標實現後,使用者可能會繼續執行其他活動。
用例點歷史
用例點估算方法由Gustav Karner於1993年提出。這項工作後來被Rational Software授權,後者併入IBM。
用例點計數過程
用例點計數過程包含以下步驟:
- 計算未調整的UCP
- 針對技術複雜性進行調整
- 針對環境複雜性進行調整
- 計算調整後的UCP
步驟1:計算未調整的用例點。
首先,透過以下步驟計算未調整的用例點:
- 確定未調整的用例權重
- 確定未調整的參與者權重
- 計算未調整的用例點
步驟1.1 – 確定未調整的用例權重。
步驟1.1.1 – 查詢每個用例中的事務數量。
如果用例是用使用者目標級別編寫的,則事務相當於用例中的一個步驟。透過計算用例中的步驟數來查詢事務數。
步驟1.1.2 – 根據用例中的事務數量,將每個用例分類為簡單、平均或複雜。此外,分配用例權重,如下表所示:
| 用例複雜性 | 事務數量 | 用例權重 |
|---|---|---|
| 簡單 | ≤3 | 5 |
| 中 | 4 到 7 | 10 |
| 複雜 | >7 | 15 |
≥8
步驟1.1.4 − 使用下表查詢未調整的用例權重 (UUCW):
| 用例複雜性 | 用例權重 | 用例數量 | 乘積 |
|---|---|---|---|
| 簡單 | 5 | NSUC | 5 × NSUC |
| 中 | 10 | NAUC | 10 × NAUC |
| 複雜 | 15 | NCUC | 15 × NCUC |
| 未調整的用例權重 (UUCW) | 5 × NSUC + 10 × NAUC + 15 × NCUC | ||
其中:
NSUC 是簡單用例的數量。
NAUC 是平均用例的數量。
NCUC 是複雜用例的數量。
步驟1.2 – 確定未調整的參與者權重。
用例中的參與者可能是個人、另一個程式等。某些參與者,例如具有已定義 API 的系統,其需求非常簡單,只會略微增加用例的複雜性。
某些參與者,例如透過協議互動的系統,具有更多需求,並在一定程度上增加了用例的複雜性。
其他參與者,例如透過 GUI 互動的使用者,會對用例的複雜性產生重大影響。基於這些差異,您可以將參與者分類為簡單、平均和複雜。
步驟1.2.1 – 將參與者分類為簡單、平均和複雜,並分配參與者權重,如下表所示:
| 參與者複雜性 | 示例 | 參與者權重 |
|---|---|---|
| 簡單 | 具有已定義 API 的系統 | 1 |
| 中 | 1 | 2 |
| 複雜 | 透過協議互動的系統 | 3 |
2
透過 GUI 互動的使用者
| 參與者複雜性 | 參與者權重 | 3 | 乘積 |
|---|---|---|---|
| 簡單 | 1 | 步驟1.2.2 – 對每個參與者重複此步驟,並獲取所有參與者權重。未調整的參與者權重 (UAW) 是所有參與者權重的總和。 | 步驟1.2.3 – 使用下表查詢未調整的參與者權重 (UAW): |
| 中 | 2 | 參與者數量 | NSA |
| 複雜 | 3 | 1 × NSA | NAA |
| 2 × NAA | NCA | ||
其中:
3 × NCA
未調整的參與者權重 (UAW)
1 × NSA + 2 × NAA + 3 × NCA
NSA 是簡單參與者的數量。
NAA 是平均參與者的數量。
NCA 是複雜參與者的數量。
步驟1.3 – 計算未調整的用例點。
未調整的用例權重 (UUCW) 和未調整的參與者權重 (UAW) 一起給出系統的未調整規模,稱為未調整的用例點。
未調整的用例點 (UUCP) = UUCW + UAW
| 接下來的步驟是針對技術複雜性和環境複雜性調整未調整的用例點 (UUCP)。 | 步驟2:針對技術複雜性進行調整 | 步驟2.1 – 考慮以下表格中給出的 13 個影響專案技術複雜性對用例點的影響的因素及其相應的權重: |
|---|---|---|
| 因素 | 描述 | 2.0 |
| 權重 | T1 | 1.0 |
| 分散式系統 | 7 | 1.0 |
| T2 | 響應時間或吞吐量效能目標 | 1.0 |
| 5 | T3 | 1.0 |
| 終端使用者效率 | 4 | .5 |
| T4 | 複雜的內部處理 | .5 |
| 6 | T5 | 2.0 |
| 程式碼必須可重用 | 4 | 1.0 |
| T6 | 易於安裝 | 1.0 |
| 2 | T7 | 1.0 |
| 易於使用 | 2 | 1.0 |
| T8 | 可移植的 | 1.0 |
4
T9
易於更改
3
T10
| 接下來的步驟是針對技術複雜性和環境複雜性調整未調整的用例點 (UUCP)。 | 步驟2:針對技術複雜性進行調整 | 併發 | 6 | T11 |
|---|---|---|---|---|
| 因素 | 描述 | 2.0 | ||
| 權重 | T1 | 1.0 | ||
| 分散式系統 | 7 | 1.0 | ||
| T2 | 響應時間或吞吐量效能目標 | 1.0 | ||
| 5 | T3 | 1.0 | ||
| 終端使用者效率 | 4 | .5 | ||
| T4 | 複雜的內部處理 | .5 | ||
| 6 | T5 | 2.0 | ||
| 程式碼必須可重用 | 4 | 1.0 | ||
| T6 | 易於安裝 | 1.0 | ||
| 2 | T7 | 1.0 | ||
| 易於使用 | 2 | 1.0 | ||
| T8 | 可移植的 | 1.0 | ||
| 包含特殊安全目標 | ||||
6
T12
為第三方提供直接訪問
5
| 接下來的步驟是針對技術複雜性和環境複雜性調整未調整的用例點 (UUCP)。 | 步驟2:針對技術複雜性進行調整 | 步驟2.1 – 考慮以下表格中給出的 13 個影響專案技術複雜性對用例點的影響的因素及其相應的權重: |
|---|---|---|
| T13 | 需要特殊的使用者培訓設施 | 1.5 |
| 3 | 這些因素中的許多都代表專案的非功能性需求。 | .5 |
| 步驟2.2 – 對於這 13 個因素中的每一個,評估專案並從 0(無關)到 5(非常重要)進行評分。 | 步驟2.3 – 從因素的影響權重和專案的評級值計算因素的影響: | 1.0 |
| 因素的影響 = 影響權重 × 評級值 | 步驟 (2.4) – 計算所有因素影響的總和。這將得到下表中給出的總技術因素 (TFactor): | .5 |
| 權重 (W) | 評級值 (0 到 5) (RV) | 1.0 |
| 影響 (I = W × RV) | 總技術因素 (TFactor) | 2.0 |
| 步驟2.5 – 計算技術複雜性因素 (TCF): | TCF = 0.6 + (0.01 × TFactor) | -1.0 |
| 步驟3:針對環境複雜性進行調整 | 步驟3.1 – 考慮以下表格中給出的 8 個可能影響專案執行的環境因素及其相應的權重: | -1.0 |
F1
熟悉所使用的專案模型
3
步驟 3.4 − 計算所有因素影響力的總和。這得出總環境因素 (EFactor),如下表所示:
| 接下來的步驟是針對技術複雜性和環境複雜性調整未調整的用例點 (UUCP)。 | 步驟2:針對技術複雜性進行調整 | 併發 | 6 | T11 |
|---|---|---|---|---|
| T13 | 需要特殊的使用者培訓設施 | 1.5 | ||
| 3 | 這些因素中的許多都代表專案的非功能性需求。 | .5 | ||
| 步驟2.2 – 對於這 13 個因素中的每一個,評估專案並從 0(無關)到 5(非常重要)進行評分。 | 步驟2.3 – 從因素的影響權重和專案的評級值計算因素的影響: | 1.0 | ||
| 因素的影響 = 影響權重 × 評級值 | 步驟 (2.4) – 計算所有因素影響的總和。這將得到下表中給出的總技術因素 (TFactor): | .5 | ||
| 權重 (W) | 評級值 (0 到 5) (RV) | 1.0 | ||
| 影響 (I = W × RV) | 總技術因素 (TFactor) | 2.0 | ||
| 步驟2.5 – 計算技術複雜性因素 (TCF): | TCF = 0.6 + (0.01 × TFactor) | -1.0 | ||
| 步驟3:針對環境複雜性進行調整 | 步驟3.1 – 考慮以下表格中給出的 8 個可能影響專案執行的環境因素及其相應的權重: | -1.0 | ||
| 總環境因素 (EFactor) | ||||
步驟 3.5 − 計算環境因素 (EF) 為:
1.4 + (-0.03 × EFactor)
步驟 4:計算調整後的用例點數 (UCP)
計算調整後的用例點數 (UCP) 為:
UCP = UUCP × TCF × EF
用例點數的優缺點
用例點數的優點
UCP 基於用例,可以在專案生命週期的早期進行衡量。
UCP(規模估算)將獨立於實施專案的團隊規模、技能和經驗。
經驗豐富的人員進行估算時,基於 UCP 的估算結果與實際結果非常接近。
UCP 易於使用,無需額外分析。
用例已被廣泛用作描述需求的首選方法。在這種情況下,UCP 是最合適的估算技術。
用例點數的缺點
只有當需求以用例的形式編寫時,才能使用 UCP。
依賴於目標導向、編寫良好的用例。如果用例結構不好或不統一,則生成的 UCP 可能不準確。
技術和環境因素對 UCP 有很大影響。分配技術和環境因素的值時需要謹慎。
UCP 有助於初步估算專案總規模,但在指導團隊的迭代工作方面作用較小。
估算技術 - 廣域德爾菲法
德爾菲法是一種結構化溝通技術,最初開發為一種系統的、互動式的預測方法,它依賴於專家小組。專家們會進行兩輪或多輪問卷調查。每輪之後,主持人都會提供專家們上一輪預測的匿名摘要以及他們判斷的原因。然後鼓勵專家們根據小組其他成員的回覆修改他們之前的答案。
人們認為,在這個過程中,答案的範圍會縮小,小組會趨向於“正確”的答案。最後,當預定義的停止標準(例如輪數、達成共識和結果穩定性)滿足後,該過程就會停止,最後一輪的平均分或中位數分數將決定結果。
德爾菲法於 20 世紀 50 年代至 60 年代在蘭德公司開發。
廣域德爾菲技術
在 20 世紀 70 年代,Barry Boehm 和 John A. Farquhar 發明了德爾菲法的廣域變體。之所以使用“廣域”一詞,是因為與德爾菲法相比,廣域德爾菲技術涉及參與者之間更多的互動和溝通。
在廣域德爾菲技術中,估算團隊由專案經理、主持人、專家和開發團隊代表組成,團隊人數為 3-7 人。共有兩次會議:
- 啟動會議
- 估算會議
廣域德爾菲技術 - 步驟
步驟 1 − 選擇估算團隊和主持人。
步驟 2 − 主持人主持啟動會議,會上向團隊介紹問題規範和高階任務列表、任何假設或專案約束條件。團隊討論問題和估算問題(如果有)。他們還決定估算單位。主持人指導整個討論,監控時間,並在啟動會議後準備一份結構化文件,其中包含問題規範、高階任務列表、假設和確定的估算單位。然後,他將此文件的副本轉發給下一步。
步驟 3 − 然後,每個估算團隊成員分別生成詳細的 WBS,估算 WBS 中的每個任務,並記錄所做的假設。
步驟 4 − 主持人召集估算團隊參加估算會議。如果任何估算團隊成員回覆說估算未準備好,主持人會給予更多時間並重新發送會議邀請。
步驟 5 − 整個估算團隊聚集在一起參加估算會議。
步驟 5.1 − 在估算會議開始時,主持人從每個團隊成員那裡收集初始估算。
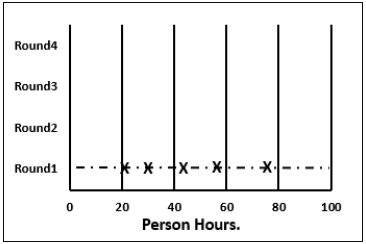
步驟 5.2 − 然後,他在白板上繪製圖表。他將每個成員的專案總估算作為 X 繪製在第 1 輪線上,而不公開相應的姓名。估算團隊瞭解估算範圍,最初可能範圍很大。
步驟 5.3 − 每個團隊成員大聲朗讀他/她制定的詳細任務列表,確定所做的任何假設並提出任何問題。任務估算未公開。
組合後的各個詳細任務列表構成更完整的任務列表。
步驟 5.4 − 然後,團隊討論他們對已完成的任務、所做的假設和估算問題存在的任何疑問/問題。
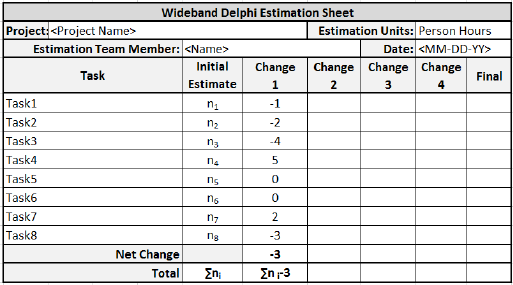
步驟 5.5 − 然後,每個團隊成員重新審視他/她的任務列表和假設,如有必要進行更改。任務估算也可能需要根據討論進行調整,記為 +N 小時(更多工作量)和 -N 小時(更少工作量)。
然後,團隊成員將任務估算中的更改合併起來,得出專案總估算。
步驟 5.6 − 主持人從所有團隊成員那裡收集更改後的估算,並將其繪製在第 2 輪線上。
在本輪中,與上一輪相比,範圍將更窄,因為它更基於共識。
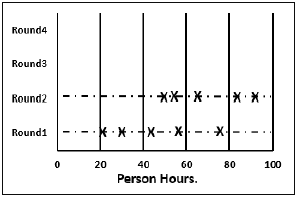
步驟 5.7 − 然後,團隊討論他們所做的任務修改和假設。
步驟 5.8 − 然後,每個團隊成員重新審視他/她的任務列表和假設,如有必要進行更改。任務估算也可能需要根據討論進行調整。
然後,團隊成員再次將任務估算中的更改合併起來,得出專案總估算。
步驟 5.9 − 主持人再次從所有成員那裡收集更改後的估算,並將其繪製在第 3 輪線上。
同樣,在本輪中,與上一輪相比,範圍將更窄。
步驟 5.10 − 重複步驟 5.7、5.8、5.9,直到滿足以下標準之一:
- 結果收斂到可接受的窄範圍。
- 所有團隊成員都不願更改他們最新的估算。
- 分配的估算會議時間已結束。
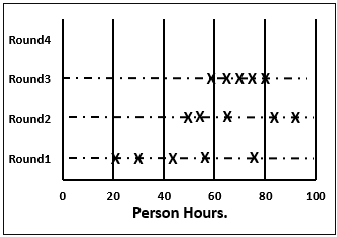
步驟 6 − 然後,專案經理收集估算會議的結果。
步驟 6.1 − 他將各個任務列表和相應的估算合併到單個主任務列表中。
步驟 6.2 − 他還將各個假設列表合併。
步驟 6.3 − 然後,他與估算團隊一起審查最終任務列表。
廣域德爾菲技術的優缺點
優點
- 廣域德爾菲技術是一種基於共識的估算技術,用於估算工作量。
- 在估算完成一項任務所需時間時很有用。
- 經驗豐富的人員參與,他們分別進行估算,將得出可靠的結果。
- 進行工作的人員正在進行估算,從而得出有效的估算。
- 始終保持匿名性,使每個人都能自信地表達自己的結果。
- 一種非常簡單的技術。
- 假設已記錄、討論和商定。
缺點
- 需要管理層的支援。
- 估算結果可能並非管理層想要聽到的結果。
估算技術 - 三點估算
三點估算考慮三個值:
- 最樂觀估計 (O),
- 最可能估計 (M),以及
- 悲觀估計(最不可能估計 (L))。
業界對三點估算和 PERT 存在一些混淆。但是,這些技術是不同的。學習這兩種技術時,您會看到它們的區別。此外,在 PERT 技術結束時,會整理並呈現差異。如果您想首先了解它們,可以。
三點估算 (E) 基於簡單平均值,遵循三角分佈。
E = (O + M + L) / 3
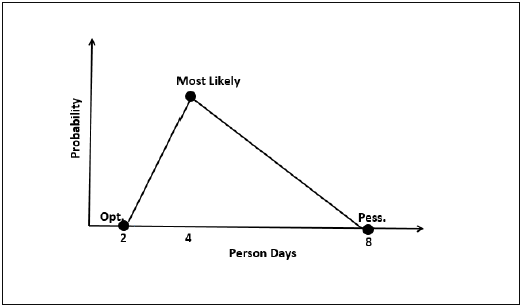
標準差
在三角分佈中,
平均值 = (O + M + L) / 3
標準差 = √[((O − E)2 + (M − E)2 + (L − E)2) / 2]
三點估算步驟
步驟 1 − 得出 WBS。
步驟 2 − 對於每個任務,找到三個值:最樂觀估計 (O)、最可能估計 (M) 和悲觀估計 (L)。
步驟 3 − 計算三個值的平均值。
平均值 = (O + M + L) / 3
步驟 4 − 計算任務的三點估算。三點估算即平均值。因此,
E = 平均值 = (O + M + L) / 3
步驟 5 − 計算任務的標準差。
標準差 (SD) = √[((O − E)2 + (M − E)2 + (L - E)2)/2]
步驟 6 − 對 WBS 中的所有任務重複步驟 2、3、4。
步驟 7 − 計算專案的三個點估計。
E(專案)= ∑ E(任務)
步驟 8 − 計算專案的標準差。
SD(專案)= √(∑SD(任務)2)
將專案估算轉換為置信水平
這樣計算出的三點估算 (E) 和標準差 (SD) 用於將專案估算轉換為“置信水平”。
轉換基於:
- E ± SD 的置信水平約為 68%。
- E 值 ± 1.645 × SD 的置信水平約為 90%。
- E 值 ± 2 × SD 的置信水平約為 95%。
- E 值 ± 3 × SD 的置信水平約為 99.7%。
通常,所有專案和任務估算都使用 95% 的置信水平,即 E 值 + 2 × SD。
估算技術 - PERT(計劃評審技術)
專案評估與評審技術 (PERT) 估算考慮三個值:最樂觀估計 (O)、最可能估計 (M) 和悲觀估計(最不可能估計 (L))。行業中關於三點估算和 PERT 存在一些混淆。然而,這兩種技術是不同的。在學習這兩種技術時,您將看到它們的區別。此外,本章結尾將對這些區別進行整理和呈現。
PERT 基於三個值——最樂觀估計 (O)、最可能估計 (M) 和悲觀估計(最不可能估計 (L))。最可能估計的權重是其他兩個估計值(樂觀和悲觀)的 4 倍。
PERT 估計 (E) 基於加權平均值並遵循 beta 分佈。
E = (O + 4 × M + L)/6
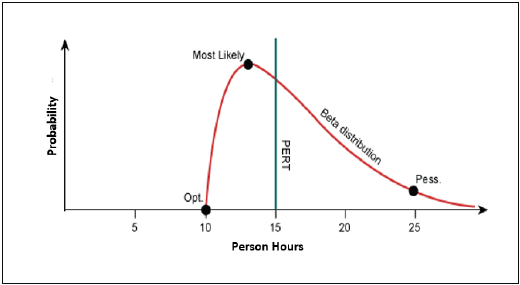
PERT 經常與關鍵路徑法 (CPM) 一起使用。CPM 指出專案中哪些任務至關重要。如果這些任務延誤,專案就會延誤。
標準差
標準差 (SD) 衡量估算中的變異性或不確定性。
在 beta 分佈中,
均值 = (O + 4 × M + L)/6
標準差 (SD) = (L − O)/6
PERT 估算步驟
步驟 (1) - 制定工作分解結構 (WBS)。
步驟 (2) - 對於每個任務,找到三個值:最樂觀估計 (O)、最可能估計 (M) 和悲觀估計 (L)。
步驟 (3) - PERT 均值 = (O + 4 × M + L)/6
PERT 均值 = (O + 4 × M + L)/3 (此處原文存在錯誤,應為/6)
步驟 (4) - 計算任務的標準差。
標準差 (SD) = (L − O)/6
步驟 (6) - 對 WBS 中的所有任務重複步驟 2、3、4。
步驟 (7) - 計算專案的 PERT 估計值。
E(專案)= ∑ E(任務)
步驟 (8) - 計算專案的標準差。
SD (專案) = √ (ΣSD (任務)2)
將專案估算轉換為置信水平
由此計算出的 PERT 估計值 (E) 和標準差 (SD) 用於將專案估算轉換為置信水平。
轉換基於以下原則:
- E ± SD 的置信水平約為 68%。
- E 值 ± 1.645 × SD 的置信水平約為 90%。
- E 值 ± 2 × SD 的置信水平約為 95%。
- E 值 ± 3 × SD 的置信水平約為 99.7%。
通常,所有專案和任務估算都使用 95% 的置信水平,即 E 值 + 2 × SD。
三點估算和 PERT 的區別
以下是三點估算和 PERT 的區別:
| 三點估算 | PERT |
|---|---|
| 簡單平均值 | 加權平均值 |
| 遵循三角分佈 | 遵循 beta 分佈 |
| 用於小型重複性專案 | 用於大型非重複性專案,通常是研發專案。與關鍵路徑法 (CPM) 一起使用。 |
E = 均值 = (O + M + L)/3 這是簡單平均值 |
E = 均值 = (O + 4 × M + L)/6 這是加權平均值 |
| SD = √ [((O − E)2 + (M − E)2 + (L − E)2)/2] | SD = (L − O)/6 |
估算技術 - 類比估算
類比估算使用類似的過去專案資訊來估算當前專案的持續時間或成本,因此得名“類比”。當關於您當前專案的可用資訊有限時,您可以使用類比估算。
很多時候,專案經理會被要求為新專案提供成本和持續時間估算,因為管理人員需要決策資料來決定該專案是否值得進行。通常,專案經理或組織中的任何其他人從未做過類似於新專案這樣的專案,但管理人員仍然希望獲得準確的成本和持續時間估算。
在這種情況下,類比估算是不二之選。它可能並不完美,但它很準確,因為它基於過去的資料。類比估算是易於實施的技術。與初始估算相比,專案成功率可高達 60%。
類比估算 – 定義
類比估算是一種技術,它使用歷史資料的引數值作為估算未來活動類似引數的基礎。引數示例:範圍、成本和持續時間。規模度量示例 - 尺寸、重量和複雜性。
由於專案經理以及可能團隊的經驗和判斷都應用於估算過程,因此它被認為是歷史資訊和專家判斷的結合。
類比估算要求
類比估算需要以下條件:
- 來自過去和正在進行的專案的資料
- 每位團隊成員每週的工作時間
- 完成專案所涉及的成本
- 與當前專案相近的專案
- 如果當前專案是新的,並且沒有類似的過去專案
- 與當前專案中相似的模組來自過去專案
- 與當前專案中相似的活動來自過去專案
- 從這些選定專案中收集資料
- 專案經理和估算團隊的參與,以確保對估算進行經驗豐富的判斷。
類比估算步驟
專案經理和團隊必須共同進行類比估算。
步驟 1 - 確定當前專案的領域。
步驟 2 - 確定當前專案的技術。
步驟 3 - 檢視組織資料庫中是否有類似的專案資料。如果有,請轉至步驟 (4)。否則,請轉至步驟 (6)。
步驟 4 - 將當前專案與已識別的過去專案資料進行比較。
步驟 5 - 得出當前專案的持續時間和成本估算。這結束了專案的類比估算。
步驟 6 - 檢視組織資料庫中是否有任何過去的專案具有與當前專案中相似的模組。
步驟 7 - 檢視組織資料庫中是否有任何過去的專案具有與當前專案中相似的活動。
步驟 8 - 收集所有這些資訊,並利用專家判斷來確定當前專案的持續時間和成本估算。
類比估算的優點
在專案初期,當對專案的瞭解非常有限時,類比估算是一種更好的估算方法。
該技術簡單易行,估算所需時間非常短。
由於該技術基於組織過去的專案資料,因此可以預期組織的成功率較高。
類比估算也可用於估算單個任務的工作量和持續時間。因此,在 WBS 中估算任務時,可以使用類比。
估算技術 - 工作分解結構 (WBS)
在專案管理和系統工程中,工作分解結構 (WBS) 是將專案分解成較小組成部分的可交付成果導向的分解。WBS 是一個關鍵的專案可交付成果,它將團隊的工作組織成可管理的部分。《專案管理知識體系》(PMBOK) 將 WBS 定義為“專案團隊要執行的工作的可交付成果導向的分層分解”。
WBS 元素可以是產品、資料、服務或它們的任何組合。WBS 還提供了詳細的成本估算和控制的必要框架,併為進度制定和控制提供了指導。
WBS 的表示
WBS 表示為專案工作活動的層次列表。WBS 有兩種格式:
- 大綱檢視(縮排格式)
- 樹形結構檢視(組織結構圖)
讓我們首先討論如何使用大綱檢視來準備 WBS。
大綱檢視
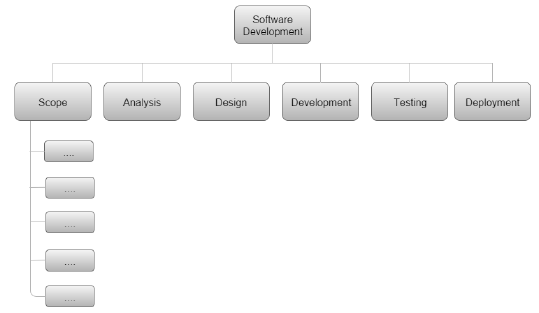
大綱檢視是一種非常使用者友好的佈局。它提供了整個專案的良好檢視,並允許輕鬆修改。它使用數字記錄專案的各個階段。它看起來有點像這樣:
軟體開發
範圍
- 確定專案範圍
- 確保專案贊助
- 定義初步資源
- 確保核心資源
- 範圍完成
分析/軟體需求
- 進行需求分析
- 起草初步軟體規格說明
- 制定初步預算
- 與團隊一起審查軟體規格說明/預算
- 結合對軟體規格說明的反饋
- 制定交付時間表
- 獲得繼續進行的批准(概念、時間表和預算)
- 確保所需資源
- 分析完成
設計
- 審查初步軟體規格說明
- 制定功能規格說明
- 獲得繼續進行的批准
- 設計完成
開發
- 審查功能規格說明
- 確定模組化/分層設計引數
- 開發程式碼
- 開發人員測試(主要除錯)
- 開發完成
測試
- 使用產品規格說明開發單元測試計劃
- 使用產品規格說明開發整合測試計劃
培訓
- 為終端使用者制定培訓規範
- 確定培訓交付方法(線上、課堂等)
- 開發培訓材料
- 完成培訓材料
- 開發培訓交付機制
- 培訓材料完成
部署
- 確定最終部署策略
- 制定部署方法
- 確保部署資源
- 培訓支援人員
- 部署軟體
- 部署完成
現在讓我們來看看樹形結構檢視。
樹形結構檢視
樹形結構檢視提供了整個專案的非常易於理解的檢視。下圖顯示了樹形結構檢視的外觀。可以使用 MS-Word 中提供的功能輕鬆繪製這種組織結構圖結構。
WBS 的型別
WBS 有兩種型別:
功能性 WBS - 在功能性 WBS 中,系統是根據要開發的應用程式中的功能來分解的。這對於估算系統規模很有用。
活動 WBS - 在活動 WBS 中,系統是根據系統中的活動來分解的。活動進一步分解成任務。這對於估算系統中的工作量和進度很有用。
規模估算
步驟 1 - 從功能性 WBS 開始。
步驟 2 - 考慮葉節點。
步驟 3 - 使用類比法或廣域德爾菲法來確定規模估算。
工作量估算
步驟 1 - 使用廣域德爾菲技術構建 WBS。我們建議任務不應超過 8 小時。如果任務持續時間較長,請將其拆分。
步驟 2 - 使用廣域德爾菲技術或三點估演算法來確定任務的工作量估算。
排程
一旦 WBS 準備就緒並且已知規模和工作量估算,您就可以開始安排任務了。
安排任務時,應考慮以下幾點:
優先順序 - 必須在另一個任務之前發生的任務被稱為具有另一個任務的優先順序。
併發 - 併發任務是可以同時(並行)發生的任務。
關鍵路徑 - 專案完成日期所依賴的一組特定順序任務。
- 所有專案都有關鍵路徑。
- 加快非關鍵任務不會直接縮短進度。
關鍵路徑法
關鍵路徑法 (CPM) 是確定和最佳化關鍵路徑的過程。非關鍵路徑任務可以提前或推遲開始,而不會影響完成日期。
請注意,當您縮短當前關鍵路徑時,關鍵路徑可能會更改為另一個。例如,對於上圖中的 WBS,關鍵路徑如下:

由於專案完成日期基於一組順序任務,因此這些任務稱為關鍵任務。
專案完成日期不基於培訓、文件和部署。這些任務稱為非關鍵任務。
任務依賴關係
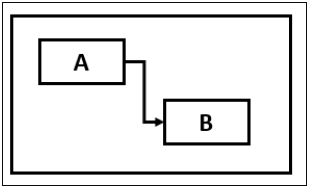
在進度安排過程中,有時需要考慮任務依賴關係。重要的任務依賴關係包括:
- 結束-開始 (FS)
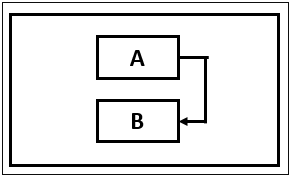
- 結束-結束 (FF)
結束-開始 (FS)
在結束-開始 (FS) 任務依賴關係中,任務 B 只有在任務 A 完成後才能開始。
結束-結束 (FF)
在結束-結束 (FF) 任務依賴關係中,任務 B 只有在任務 A 完成後才能結束。
甘特圖
甘特圖是一種條形圖,由 Karol Adamiecki 於 1896 年改進,Henry Gantt 於 20 世紀 10 年代獨立改進,用於展示專案進度。甘特圖說明了專案終端元素和彙總元素的開始和結束日期。
您可以將圖 2 中的提綱格式匯入 Microsoft Project 以獲得甘特圖檢視。
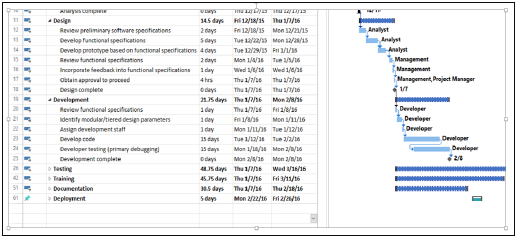
里程碑
里程碑是進度表中的關鍵階段。它們的持續時間為零,用於標誌已完成某些任務集。里程碑通常用菱形表示。
例如,在上圖的甘特圖中,“設計完成”和“開發完成”顯示為里程碑,用菱形表示。
里程碑可以與合同條款掛鉤。
使用 WBS 進行估算的優勢
WBS 在很大程度上簡化了專案估算過程。與其他估算技術相比,它具有以下優勢:
在 WBS 中,識別了專案所有需要完成的工作。因此,透過與專案干係人一起審查 WBS,您不太可能遺漏交付所需專案可交付成果的任何工作。
WBS 可得出更準確的成本和進度估算。
專案經理獲得團隊參與以最終確定 WBS。團隊的參與會在專案中產生熱情和責任感。
WBS 為任務分配提供了基礎。因為精確的任務被分配給特定的團隊成員,他們將對完成任務負責。
WBS 能夠在任務級別進行監控和控制。這使您可以衡量進度並確保專案按時交付。
估算技術 - 撲克計劃
撲克計劃估算
撲克計劃是一種基於共識的估算技術,主要用於估算 Scrum 中使用者故事的工作量或相對大小。
撲克計劃結合了三種估算技術:寬頻德爾菲技術、類比估算和使用 WBS 進行估算。
撲克計劃最初由 James Grenning 於 2002 年定義和命名,後來由 Mike Cohn 在他的著作《敏捷估算與規劃》中推廣,他的公司對該術語進行了商標註冊。
撲克計劃估算技術
在撲克計劃估算技術中,使用者故事的估算值是透過玩撲克計劃得出的。整個 Scrum 團隊都參與其中,這使得估算快速且可靠。
撲克計劃使用一副牌進行。由於使用了斐波那契數列,卡片上的數字為 - 1、2、3、5、8、13、21、34 等。這些數字代表“故事點”。每個估算者都有一副牌。當其中一名團隊成員舉起一張牌時,卡片上的數字應該足夠大,以便所有團隊成員都能看到。
選擇一名團隊成員作為主持人。主持人閱讀正在進行估算的使用者故事的描述。如果估算者有任何疑問,產品負責人將解答。
每個估算者私下選擇一張代表其估算值的牌。在所有估算者都做出選擇之前,不顯示牌。此時,所有牌同時翻轉並舉起,以便所有團隊成員都能看到每個估算值。
在第一輪中,估算值很可能會有所不同。估算值最高和最低的估算者解釋他們估算值的原因。需要注意的是,所有討論都只為了理解,不要把任何事情放在心上。主持人必須確保這一點。
團隊可以再討論幾分鐘關於故事及其估算值。
主持人可以記錄討論內容,這在開發特定故事時會有所幫助。討論結束後,每個估算者透過再次選擇一張牌進行重新估算。牌再次保密,直到每個人都估算完畢,然後同時翻轉。
重複此過程,直到估算值收斂到一個可以用於該故事的單一估算值。估算輪數因使用者故事而異。
撲克計劃估算的益處
撲克計劃結合了三種估算方法:
專家意見 - 在基於專家意見的估算方法中,會詢問專家某事需要多長時間或規模有多大。專家根據其經驗、直覺或直覺提供估算值。專家意見估算通常不需要花費太多時間,並且與某些分析方法相比更準確。
類比 - 類比估算使用使用者故事的比較。將待估算的使用者故事與之前實現的類似使用者故事進行比較,由於估算是基於已驗證的資料,因此結果準確。
分解 - 分解估算透過將使用者故事分解成更小、更容易估算的使用者故事來完成。衝刺中包含的使用者故事通常在開發時間為 2 到 5 天的範圍內。因此,可能需要較長時間的使用者故事需要分解成更小的用例。這種方法還確保會有許多可比較的故事。
估算技術 - 測試
測試工作量並非基於任何確定的時間框架。無論測試是否完成,工作都會持續到設定某些預先確定的時間線為止。
這主要是因為傳統上,測試工作量估算是開發工作量估算的一部分。只有在使用 WBS 的估算技術(例如寬頻德爾菲、三點估算、PERT 和 WBS)的情況下,才能獲得測試活動估算值。
如果您已獲得功能點 (FP) 的估算值,則根據 Caper Jones 的說法:
測試用例數量 = (功能點數量) × 1.2
獲得測試用例數量後,您可以從組織資料庫中獲取生產力資料,並得出測試所需的工作量。
開發工作量百分比法
所需的測試工作量與開發工作量成正比或百分比關係。可以使用程式碼行數 (LOC) 或功能點 (FP) 來估算開發工作量。然後,從組織資料庫中獲取測試工作量的百分比。獲得的百分比用於得出測試工作量的估算值。
測試專案估算
現在,一些組織為客戶提供獨立的驗證和確認服務,這意味著專案活動將完全是測試活動。
測試專案估算需要對軟體測試生命週期中各種專案的經驗。估算測試專案時,請考慮:
- 團隊技能
- 領域知識
- 應用程式的複雜性
- 歷史資料
- 專案的缺陷週期
- 資源可用性
- 生產力差異
- 系統環境和停機時間
測試估算技術
以下測試估算技術已被證明是準確的,並且被廣泛使用:
- PERT 軟體測試估算技術
- UCP 方法
- WBS
- 寬頻德爾菲技術
- 功能點/測試點分析
- 百分比分配
- 基於經驗的測試估算技術
PERT 軟體測試估算技術
PERT 軟體測試估算技術基於統計方法,其中每個測試任務都被分解成子任務,然後對每個子任務進行三種類型的估算。
該技術使用的公式為:
測試估算 = (O + (4 × M) + E)/6
其中:
O = 樂觀估算(最佳情況,沒有任何問題,所有條件都最佳)。
M = 最可能估算(最可能的持續時間,可能存在一些問題,但大多數事情都會順利進行)。
E = 悲觀估算(最壞情況,所有事情都出問題)。
該技術的標準差計算如下:
標準差 (SD) = (E − O)/6
用例點法
UCP 方法基於用例,我們計算未調整的參與者權重和未調整的用例權重以確定軟體測試估算。
用例是一個文件,它指定不同的使用者、系統或其他干係人與相關應用程式互動。它們被稱為“參與者”。互動透過稱為場景的不同行為或流程來完成某些定義的目標,從而保護所有利益相關者的利益。
步驟 1 - 統計參與者數量。參與者包括正向、負向和例外。
步驟 2 - 計算未調整的參與者權重為
未調整的參與者權重 = 參與者總數
步驟 3 - 統計用例數量。
步驟 4 - 計算未調整的用例權重為
未調整的用例權重 = 用例總數
步驟 5 - 計算未調整的用例點為
未調整的用例點 = (未調整的參與者權重 + 未調整的用例權重)
步驟 6 - 確定技術/環境因素 (TEF)。如果不可用,則取 0.50。
步驟 7 - 計算調整後的用例點為
調整後的用例點 = 未調整的用例點 × [0.65 + (0.01 × TEF)]
步驟 8 - 計算總工作量為
總工作量 = 調整後的用例點 × 2
工作分解結構
步驟 1 - 透過將測試專案分解成小塊來建立 WBS。
步驟 2 - 將模組分成子模組。
步驟 3 - 將子模組進一步分解成功能。
步驟 4 - 將功能分解成子功能。
步驟 5 - 檢查所有測試需求,確保它們已新增到 WBS 中。
步驟 6 - 確定團隊需要完成的任務數量。
步驟 7 - 估算每個任務的工作量。
步驟 8 - 估算每個任務的持續時間。
廣域德爾菲技術
在寬頻德爾菲方法中,WBS 分發給由 3-7 名成員組成的團隊,以對任務進行重新估算。最終估算值是基於團隊共識的彙總估算值的結果。
此方法更側重於經驗,而不是任何統計公式。Barry Boehm 推廣了這種方法,以強調團隊迭代以達成共識,團隊在估算測試工作量時設想了問題的不同方面。
功能點/測試點分析
功能點(FP)從使用者的角度指示軟體應用程式的功能,並用作估算軟體專案規模的技術。
在測試中,估算基於需求規格說明書或先前建立的應用程式原型。要計算專案的FP,需要一些主要元件。它們是:
**未調整的資料功能點** − i)內部檔案,ii)外部介面
**未調整的事務功能點** − i)使用者輸入,ii)使用者輸出,iii)使用者查詢
**Capers Jones基本公式** −
測試用例數量 = (功能點數量) × 1.2
**總實際工作量 (TAE)** −
(測試用例數量) × (開發工作量百分比 /100)
百分比分佈
在這種技術中,軟體開發生命週期 (SDLC) 的所有階段都分配了百分比的工作量。這可以基於來自類似專案的過去資料。例如:
| 階段 | 工作量百分比 |
|---|---|
| 專案管理 | 7% |
| 需求分析 | 9% |
| 設計 | 16% |
| 編碼 | 26% |
| 測試(所有測試階段) | 27% |
| 文件編制 | 9% |
| 安裝和培訓 | 6% |
接下來,所有測試階段的測試工作量百分比將進一步分配給所有測試階段:
| 所有測試階段 | 工作量百分比 |
|---|---|
| 元件測試 | 16 |
| 獨立測試 | 84 |
| 總計 | 100 |
| 獨立測試 | 工作量百分比 |
|---|---|
| 整合測試 | 24 |
| 系統測試 | 52 |
| 驗收測試 | 24 |
| 總計 | 100 |
| 系統測試 | 工作量百分比 |
|---|---|
| 功能系統測試 | 65 |
| 非功能系統測試 | 35 |
| 總計 | 100 |
| 測試計劃和設計架構 | 50% |
| 評審階段 | 50% |
基於經驗的測試估算技術
此技術基於類比和專家意見。該技術假設您已經在之前的專案中測試過類似的應用程式,並從這些專案中收集了指標。您還從之前的測試中收集了指標。從非常瞭解應用程式(以及測試)的主題專家那裡獲取輸入,並使用您收集的指標來確定測試工作量。