- Keras深度學習教程
- Keras深度學習 - 首頁
- Keras深度學習 - 簡介
- 深度學習
- 專案設定
- 匯入庫
- 建立深度學習模型
- 編譯模型
- 準備資料
- 訓練模型
- 評估模型效能
- 測試資料預測
- 儲存模型
- 載入模型進行預測
- 結論
- Keras深度學習資源
- Keras深度學習快速指南
- Keras深度學習 - 有用資源
- Keras深度學習 - 討論
Keras深度學習快速指南
Keras深度學習 - 簡介
近年來,深度學習已成為人工智慧(AI)領域的一個熱門詞彙。多年來,我們一直使用機器學習(ML)來賦予機器智慧。近年來,由於深度學習在預測方面優於傳統的機器學習技術,因此變得越來越流行。
深度學習本質上意味著使用海量資料訓練人工神經網路(ANN)。在深度學習中,網路可以自我學習,因此需要海量資料進行學習。而傳統的機器學習本質上是一組解析資料並從中學習的演算法。然後,它們利用這些學習成果做出明智的決策。
現在,談到Keras,它是一個高階神經網路API,執行在TensorFlow之上——一個端到端的開源機器學習平臺。使用Keras,您可以輕鬆定義複雜的人工神經網路架構,以在您的海量資料上進行實驗。Keras還支援GPU,這對於處理海量資料和開發機器學習模型至關重要。
在本教程中,您將學習如何在構建深度神經網路中使用Keras。我們將透過實踐示例進行教學。手頭的問題是使用經過深度學習訓練的神經網路識別手寫數字。
為了讓您對深度學習更加興奮,以下是Google趨勢中關於深度學習的截圖:
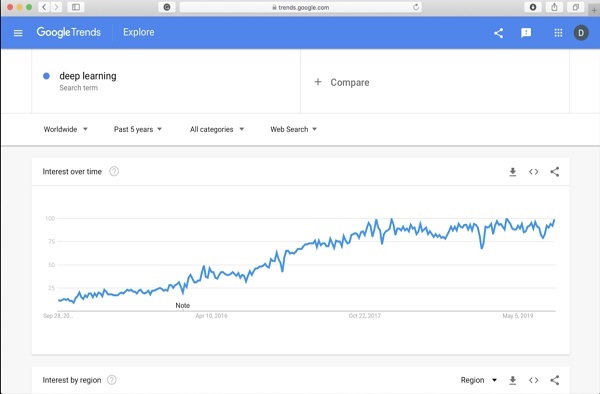
從圖中可以看出,過去幾年人們對深度學習的興趣穩步增長。深度學習已成功應用於許多領域,例如計算機視覺、自然語言處理、語音識別、生物資訊學、藥物設計等等。本教程將幫助您快速入門深度學習。
所以請繼續閱讀!
Keras深度學習 - 深度學習
如引言中所述,深度學習是使用海量資料訓練人工神經網路的過程。訓練完成後,網路將能夠對未見資料進行預測。在進一步解釋深度學習是什麼之前,讓我們快速瞭解一下訓練神經網路中使用的一些術語。
神經網路
人工神經網路的想法源於我們大腦中的神經網路。典型的神經網路包含三層——輸入層、輸出層和隱藏層,如下面的圖片所示。

這也被稱為淺層神經網路,因為它只包含一層隱藏層。您可以在上述架構中新增更多隱藏層以建立更復雜的架構。
深度網路
下圖顯示了一個包含四個隱藏層、一個輸入層和一個輸出層的深度網路。
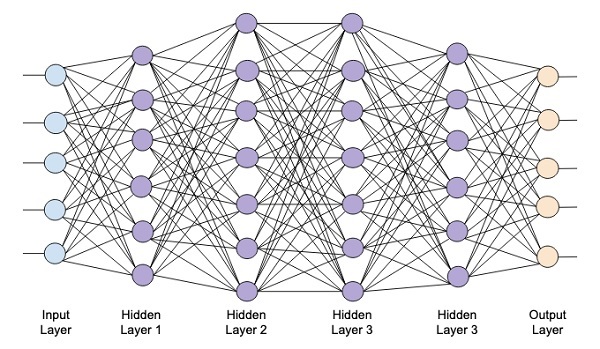
隨著向網路新增更多隱藏層,其訓練在所需資源和完全訓練網路所需的時間方面變得更加複雜。
網路訓練
定義網路架構後,您需要對其進行訓練以執行某些型別的預測。訓練網路是一個為網路中每個連結找到合適權重的過程。在訓練期間,資料透過各個隱藏層從輸入層流向輸出層。由於資料始終沿一個方向從輸入到輸出移動,因此我們將此網路稱為前饋網路,並將資料傳播稱為前向傳播。
啟用函式
在每一層,我們計算輸入的加權和並將其饋送到啟用函式。啟用函式為網路引入了非線性。它只是一個將輸出離散化的數學函式。一些最常用的啟用函式包括sigmoid、雙曲正切(tanh)、ReLU和Softmax。
反向傳播
反向傳播是一種用於監督學習的演算法。在反向傳播中,誤差從輸出層反向傳播到輸入層。給定一個誤差函式,我們計算誤差函式相對於分配給每個連線的權重的梯度。梯度的計算從網路向後進行。首先計算最後一層權重的梯度,最後計算第一層權重的梯度。
在每一層,梯度的部分計算都會在計算前一層的梯度時重複使用。這稱為梯度下降。
在本專案教程中,您將定義一個前饋深度神經網路,並使用反向傳播和梯度下降技術對其進行訓練。幸運的是,Keras為我們提供了所有高階API,用於定義網路架構並使用梯度下降對其進行訓練。接下來,您將學習如何在Keras中做到這一點。
手寫數字識別系統
在這個小型專案中,您將應用前面描述的技術。您將建立一個深度學習神經網路,用於訓練識別手寫數字。在任何機器學習專案中,第一個挑戰都是收集資料。特別是對於深度學習網路,您需要海量資料。幸運的是,對於我們試圖解決的問題,有人已經建立了一個用於訓練的資料集。這稱為mnist,它作為Keras庫的一部分提供。資料集包含多個28x28畫素的手寫數字影像。您將在該資料集的大部分資料上訓練您的模型,其餘資料將用於驗證您訓練的模型。
專案描述
mnist資料集包含70000張手寫數字影像。這裡複製了一些示例影像供您參考

每張影像的大小為28 x 28畫素,總共有768個不同灰度級別的畫素。大多數畫素傾向於黑色陰影,而只有少數畫素傾向於白色。我們將這些畫素的分佈放入陣列或向量中。例如,典型數字4和5影像的畫素分佈如下圖所示。
每張影像的大小為28 x 28畫素,總共有768個不同灰度級別的畫素。大多數畫素傾向於黑色陰影,而只有少數畫素傾向於白色。我們將這些畫素的分佈放入陣列或向量中。例如,典型數字4和5影像的畫素分佈如下圖所示。
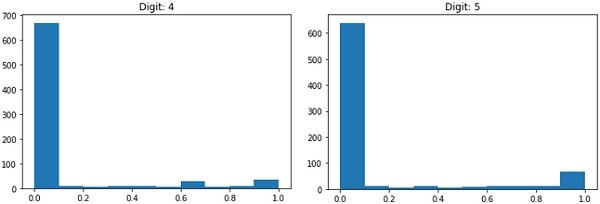
顯然,您可以看到畫素的分佈(特別是那些傾向於白色色調的畫素)有所不同,這區分了它們所代表的數字。我們將這784個畫素的分佈作為輸入饋送到我們的網路。網路的輸出將包含10個類別,表示0到9之間的數字。
我們的網路將包含4層——一個輸入層、一個輸出層和兩個隱藏層。每個隱藏層將包含512個節點。每一層都完全連線到下一層。當我們訓練網路時,我們將計算每個連線的權重。我們透過應用前面討論的反向傳播和梯度下降來訓練網路。
Keras深度學習 - 專案設定
有了這些背景知識,讓我們現在開始建立專案。
專案設定
我們將透過Anaconda導航器使用Jupyter來進行我們的專案。由於我們的專案使用TensorFlow和Keras,您需要在Anaconda設定中安裝它們。要在控制檯視窗中安裝Tensorflow,請執行以下命令
>conda install -c anaconda tensorflow
要安裝Keras,請使用以下命令:
>conda install -c anaconda keras
您現在可以開始使用Jupyter了。
啟動Jupyter
當您啟動Anaconda導航器時,您將看到以下啟動螢幕。
單擊“Jupyter”以啟動它。螢幕將顯示驅動器上現有的專案(如果有)。
啟動新專案
透過選擇以下選單選項,在Anaconda中啟動一個新的Python 3專案:
File | New Notebook | Python 3
選單選擇的螢幕截圖顯示在下面,供您快速參考:
一個新的空白專案將顯示在您的螢幕上,如下所示:
透過單擊並編輯預設名稱“UntitledXX”將專案名稱更改為DeepLearningDigitRecognition。
Keras深度學習 - 匯入庫
我們首先匯入專案程式碼中所需的各種庫。
陣列處理和繪圖
像往常一樣,我們使用numpy進行陣列處理,使用matplotlib進行繪圖。這些庫使用以下import語句匯入到我們的專案中
import numpy as np import matplotlib import matplotlib.pyplot as plot
抑制警告
由於Tensorflow和Keras不斷更新,如果您沒有在專案中同步其相應的版本,則在執行時您會看到大量警告錯誤。由於它們會分散您學習的注意力,因此我們將在本專案中抑制所有警告。這可以透過以下程式碼行完成:
# silent all warnings
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='3'
import warnings
warnings.filterwarnings('ignore')
from tensorflow.python.util import deprecation
deprecation._PRINT_DEPRECATION_WARNINGS = False
Keras
我們使用Keras庫匯入資料集。我們將使用mnist資料集進行手寫數字識別。我們使用以下語句匯入所需的包
from keras.datasets import mnist
我們將使用Keras包定義深度學習神經網路。我們匯入Sequential、Dense、Dropout和Activation包以定義網路架構。我們使用load_model包儲存和檢索我們的模型。我們還使用np_utils進行專案中需要的一些實用程式。這些匯入透過以下程式語句完成:
from keras.models import Sequential, load_model from keras.layers.core import Dense, Dropout, Activation from keras.utils import np_utils
執行此程式碼時,您將在控制檯上看到一條訊息,指出Keras使用TensorFlow作為後端。此階段的螢幕截圖顯示如下:
現在,由於我們已經擁有專案所需的所有匯入,我們將繼續為深度學習網路定義架構。
建立深度學習模型
我們的神經網路模型將包含一個線性層堆疊。要定義這樣的模型,我們呼叫Sequential函式:
model = Sequential()
輸入層
我們使用以下程式語句定義輸入層,它是網路中的第一層:
model.add(Dense(512, input_shape=(784,)))
這會建立一個包含 512 個節點(神經元)的層,以及 784 個輸入節點。如下圖所示:
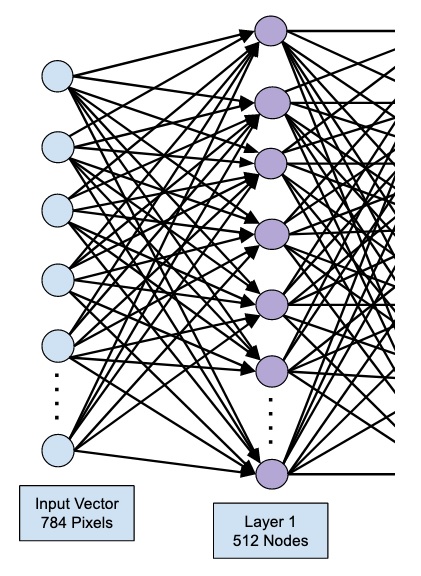
請注意,所有輸入節點都完全連線到第一層,即每個輸入節點都連線到第一層的全部 512 個節點。
接下來,我們需要為第一層的輸出新增啟用函式。我們將使用 ReLU 作為我們的啟用函式。啟用函式使用以下程式語句新增:
model.add(Activation('relu'))
接下來,我們使用下面的語句新增 20% 的 Dropout。Dropout 是一種用於防止模型過擬合的技術。
model.add(Dropout(0.2))
至此,我們的輸入層已完全定義。接下來,我們將新增一個隱藏層。
隱藏層
我們的隱藏層將包含 512 個節點。隱藏層的輸入來自我們之前定義的輸入層。所有節點都像之前的情況一樣完全連線。隱藏層的輸出將傳遞到網路中的下一層,這將是我們的最終輸出層。我們將使用與上一層相同的 ReLU 啟用函式和 20% 的 Dropout。新增此層的程式碼如下所示:
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.2))
此時,網路可以視覺化為:
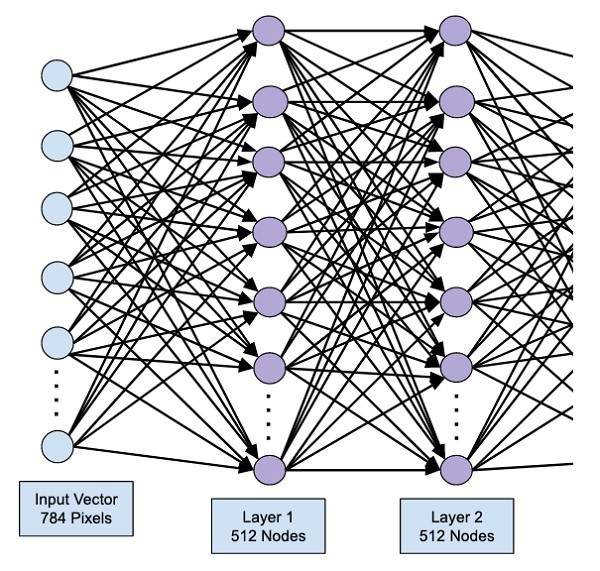
接下來,我們將向我們的網路新增最終層,即輸出層。請注意,您可以使用類似於此處使用的程式碼新增任意數量的隱藏層。新增更多層會使網路訓練變得複雜;但是,在許多情況下(儘管並非所有情況)都能帶來更好的結果的顯著優勢。
輸出層
輸出層僅包含 10 個節點,因為我們希望將給定的影像分類為 10 個不同的數字。我們使用以下語句新增此層:
model.add(Dense(10))
由於我們希望將輸出分類為 10 個不同的單元,因此我們使用 softmax 啟用函式。在 ReLU 的情況下,輸出是二進位制的。我們使用以下語句新增啟用函式:
model.add(Activation('softmax'))
此時,我們的網路可以視覺化為下圖所示:

此時,我們的網路模型已在軟體中完全定義。執行程式碼單元,如果沒有任何錯誤,您將在螢幕上看到確認訊息,如下面的螢幕截圖所示:

接下來,我們需要編譯模型。
使用 Keras 進行深度學習 - 編譯模型
編譯是使用一個名為 **compile** 的方法呼叫執行的。
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')
**compile** 方法需要幾個引數。loss 引數指定為型別 **'categorical_crossentropy'**。metrics 引數設定為 **'accuracy'**,最後我們使用 **adam** 最佳化器來訓練網路。此階段的輸出如下所示:

現在,我們準備將資料饋送到我們的網路中。
載入資料
如前所述,我們將使用 Keras 提供的 **mnist** 資料集。當我們將資料載入到我們的系統中時,我們將將其拆分為訓練資料和測試資料。資料透過呼叫 **load_data** 方法載入,如下所示:
(X_train, y_train), (X_test, y_test) = mnist.load_data()
此階段的輸出如下所示:

現在,我們將瞭解載入資料集的結構。
提供給我們的資料是大小為 28 x 28 畫素的圖形影像,每個影像包含 0 到 9 之間的單個數字。我們將在控制檯上顯示前十張影像。執行此操作的程式碼如下所示:
# printing first 10 images
for i in range(10):
plot.subplot(3,5,i+1)
plot.tight_layout()
plot.imshow(X_train[i], cmap='gray', interpolation='none')
plot.title("Digit: {}".format(y_train[i]))
plot.xticks([])
plot.yticks([])
在 10 次計數的迭代迴圈中,我們在每次迭代中建立一個子圖,並在其中顯示來自 **X_train** 向量的影像。我們從相應的 **y_train** 向量為每個影像新增標題。請注意,**y_train** 向量包含 **X_train** 向量中相應影像的實際值。我們透過呼叫兩個方法 **xticks** 和 **yticks** 並使用空引數來刪除 x 和 y 軸標記。執行程式碼時,您將看到以下輸出:

接下來,我們將準備資料以將其饋送到我們的網路中。
使用 Keras 進行深度學習 - 準備資料
在將資料饋送到網路之前,必須將其轉換為網路所需的形式。這稱為為網路準備資料。它通常包括將多維輸入轉換為一維向量並標準化資料點。
重塑輸入向量
我們資料集中影像包含 28 x 28 個畫素。這必須轉換為大小為 28 * 28 = 784 的一維向量,以便將其饋送到我們的網路中。我們透過對向量呼叫 **reshape** 方法來做到這一點。
X_train = X_train.reshape(60000, 784) X_test = X_test.reshape(10000, 784)
現在,我們的訓練向量將包含 60000 個數據點,每個資料點包含一個大小為 784 的一維向量。類似地,我們的測試向量將包含 10000 個數據點,每個資料點包含一個大小為 784 的一維向量。
標準化資料
輸入向量當前包含的資料具有 0 到 255 之間的離散值 - 灰度級。將這些畫素值標準化為 0 到 1 之間有助於加快訓練速度。由於我們將使用隨機梯度下降,因此標準化資料還有助於減少陷入區域性最優解的可能性。
為了標準化資料,我們將其表示為浮點型別並將其除以 255,如下面的程式碼片段所示:
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
現在讓我們看看標準化後的資料是什麼樣子。
檢查標準化資料
要檢視標準化後的資料,我們將呼叫直方圖函式,如下所示:
plot.hist(X_train[0])
plot.title("Digit: {}".format(y_train[0]))
在這裡,我們繪製了 **X_train** 向量第一個元素的直方圖。我們還列印了此資料點表示的數字。執行上述程式碼的輸出如下所示:
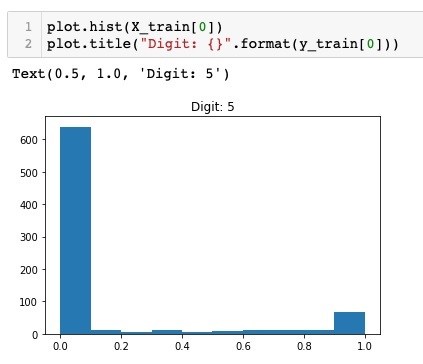
您會注意到值接近零的點的密度很大。這些是影像中的黑點,顯然是影像的主要部分。其餘的灰度點,即接近白色,表示數字。您可以檢視另一個數字的畫素分佈。以下程式碼列印訓練資料集中索引為 2 的數字的直方圖。
plot.hist(X_train[2])
plot.title("Digit: {}".format(y_train[2])
執行上述程式碼的輸出如下所示:

比較以上兩張圖,您會注意到兩張影像中白色畫素的分佈不同,表明表示不同的數字 - 上述兩張圖片中的“5”和“4”。
接下來,我們將檢查完整訓練資料集中資料的分佈。
檢查資料分佈
在使用我們的資料集中訓練機器學習模型之前,我們應該瞭解資料集中唯一數字的分佈。我們的影像表示 10 個不同的數字,範圍從 0 到 9。我們想知道資料集中數字 0、1 等的數量。我們可以使用 NumPy 的 **unique** 方法獲取此資訊。
使用以下命令列印唯一值的個數以及每個值的出現次數
print(np.unique(y_train, return_counts=True))
執行上述命令時,您將看到以下輸出:
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([5923, 6742, 5958, 6131, 5842, 5421, 5918, 6265, 5851, 5949]))
它顯示有 10 個不同的值 - 0 到 9。數字 0 出現了 5923 次,數字 1 出現了 6742 次,依此類推。此處顯示輸出的螢幕截圖:

作為資料準備的最後一步,我們需要對資料進行編碼。
編碼資料
我們的資料集中有十個類別。因此,我們將使用獨熱編碼將我們的輸出編碼為這十個類別。我們使用 NumPy 實用程式的 to_categorial 方法執行編碼。輸出資料編碼後,每個資料點將轉換為大小為 10 的一維向量。例如,數字 5 現在將表示為 [0,0,0,0,0,1,0,0,0,0]。
使用以下程式碼段對資料進行編碼:
n_classes = 10 Y_train = np_utils.to_categorical(y_train, n_classes)
您可以透過列印分類後的 Y_train 向量的前 5 個元素來檢視編碼結果。
使用以下程式碼列印前 5 個向量:
for i in range(5): print (Y_train[i])
您將看到以下輸出:
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.] [1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 1. 0. 0. 0. 0. 0.] [0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
第一個元素表示數字 5,第二個元素表示數字 0,依此類推。
最後,您還必須對測試資料進行分類,這可以透過以下語句完成:
Y_test = np_utils.to_categorical(y_test, n_classes)
此時,您的資料已完全準備好饋送到網路中。
接下來,是最重要的部分,即訓練我們的網路模型。
使用 Keras 進行深度學習 - 訓練模型
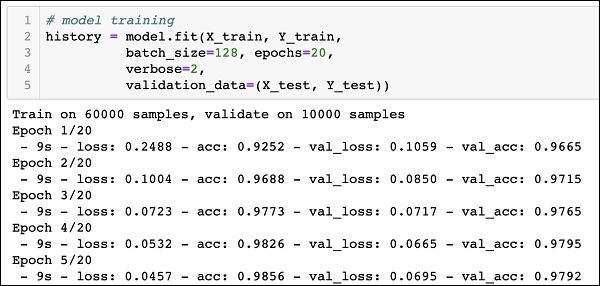
模型訓練在一個名為 fit 的方法呼叫中完成,該方法採用以下程式碼中所示的一些引數:
history = model.fit(X_train, Y_train, batch_size=128, epochs=20, verbose=2, validation_data=(X_test, Y_test)))
fit 方法的前兩個引數指定訓練資料集的特徵和輸出。
**epochs** 設定為 20;我們假設訓練將在最多 20 個 epochs(迭代)內收斂。訓練後的模型在測試資料上進行驗證,如最後一個引數中指定的那樣。
執行上述命令的部分輸出如下所示:
Train on 60000 samples, validate on 10000 samples Epoch 1/20 - 9s - loss: 0.2488 - acc: 0.9252 - val_loss: 0.1059 - val_acc: 0.9665 Epoch 2/20 - 9s - loss: 0.1004 - acc: 0.9688 - val_loss: 0.0850 - val_acc: 0.9715 Epoch 3/20 - 9s - loss: 0.0723 - acc: 0.9773 - val_loss: 0.0717 - val_acc: 0.9765 Epoch 4/20 - 9s - loss: 0.0532 - acc: 0.9826 - val_loss: 0.0665 - val_acc: 0.9795 Epoch 5/20 - 9s - loss: 0.0457 - acc: 0.9856 - val_loss: 0.0695 - val_acc: 0.9792
為了方便參考,下面給出了輸出的螢幕截圖:
現在,由於模型已在我們的訓練資料上進行了訓練,我們將評估其效能。
評估模型效能
為了評估模型效能,我們呼叫 **evaluate** 方法,如下所示:
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)
為了評估模型效能,我們呼叫 **evaluate** 方法,如下所示:
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)
我們將使用以下兩個語句列印損失和準確率:
print("Test Loss", loss_and_metrics[0])
print("Test Accuracy", loss_and_metrics[1])
執行上述語句時,您將看到以下輸出:
Test Loss 0.08041584826191042 Test Accuracy 0.9837
這表明測試準確率為 98%,這對我們來說應該是可以接受的。這意味著在 2% 的情況下,手寫數字將無法正確分類。我們還將繪製準確率和損失指標,以檢視模型在測試資料上的表現。
繪製準確率指標
我們使用訓練期間記錄的 **history** 來獲取準確率指標的圖表。以下程式碼將繪製每個 epoch 的準確率。我們選擇訓練資料準確率 (“acc”) 和驗證資料準確率 (“val_acc”) 進行繪圖。
plot.subplot(2,1,1)
plot.plot(history.history['acc'])
plot.plot(history.history['val_acc'])
plot.title('model accuracy')
plot.ylabel('accuracy')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='lower right')
輸出圖如下所示:
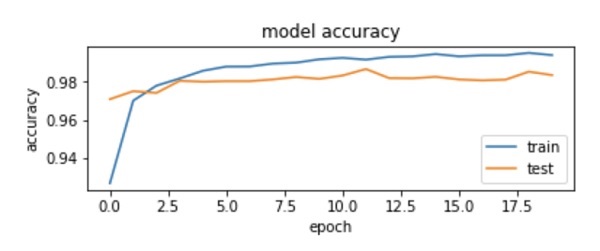
如您在圖中看到的,準確率在前兩個 epoch 中迅速提高,表明網路學習速度很快。之後,曲線趨於平緩,表明不需要太多 epoch 來進一步訓練模型。通常,如果訓練資料準確率 (“acc”) 持續提高,而驗證資料準確率 (“val_acc”) 卻變差,則說明您遇到了過擬合。這表明模型開始記憶資料。
我們還將繪製損失指標來檢查模型的效能。
繪製損失指標
同樣,我們繪製訓練 (“loss”) 和測試 (“val_loss”) 資料上的損失。這是使用以下程式碼完成的:
plot.subplot(2,1,2)
plot.plot(history.history['loss'])
plot.plot(history.history['val_loss'])
plot.title('model loss')
plot.ylabel('loss')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='upper right')
此程式碼的輸出如下所示:

如您在圖中看到的,訓練集上的損失在前兩個 epoch 中迅速下降。對於測試集,損失下降的速度不如訓練集,但在多個 epoch 中保持幾乎平坦。這意味著我們的模型能夠很好地推廣到未見過的資料。
現在,我們將使用訓練好的模型來預測測試資料中的數字。
測試資料預測
預測未見過資料中的數字非常簡單。您只需呼叫 **model** 的 **predict_classes** 方法,並將包含未知資料點的向量傳遞給它即可。
predictions = model.predict_classes(X_test)
方法呼叫會將預測結果返回到一個向量中,可以針對實際值測試 0 和 1。這是使用以下兩個語句完成的:
correct_predictions = np.nonzero(predictions == y_test)[0] incorrect_predictions = np.nonzero(predictions != y_test)[0]
最後,我們將使用以下兩個程式語句列印正確預測和錯誤預測的次數:
print(len(correct_predictions)," classified correctly") print(len(incorrect_predictions)," classified incorrectly")
執行程式碼後,您將獲得以下輸出:
9837 classified correctly 163 classified incorrectly
現在,由於您已經成功訓練了模型,我們將儲存它以備將來使用。
使用 Keras 進行深度學習 - 儲存模型
我們將訓練後的模型儲存在本地驅動器中的 models 資料夾中,該資料夾位於當前工作目錄中。要儲存模型,請執行以下程式碼:
directory = "./models/"
name = 'handwrittendigitrecognition.h5'
path = os.path.join(save_dir, name)
model.save(path)
print('Saved trained model at %s ' % path)
執行程式碼後的輸出如下所示:

現在,由於您已儲存了一個訓練好的模型,您可以稍後使用它來處理未知資料。
載入模型進行預測
要預測未見資料,您首先需要將訓練好的模型載入到記憶體中。這可以透過以下命令完成:
model = load_model ('./models/handwrittendigitrecognition.h5')
請注意,我們只是將 .h5 檔案載入到記憶體中。這會在記憶體中設定整個神經網路,以及分配給每一層的權重。
現在,要對未見資料進行預測,請將資料(可以是一個或多個專案)載入到記憶體中。對資料進行預處理以滿足模型的輸入要求,就像您之前對訓練和測試資料所做的那樣。預處理後,將其饋送到您的網路。模型將輸出其預測結果。
使用 Keras 進行深度學習 - 結論
Keras 提供了一個高階 API 用於建立深度神經網路。在本教程中,您學習瞭如何建立一個用於查詢手寫文字中數字的深度神經網路。為此建立了一個多層網路。Keras 允許您在每一層定義您選擇的啟用函式。使用梯度下降,網路在訓練資料上進行了訓練。在測試資料上測試了訓練後的網路預測未見資料的準確性。您學習瞭如何繪製準確性和誤差指標。網路完全訓練後,您將網路模型儲存以備將來使用。